Serverless for HPC - A case study
Luciano Mammino (@loige)

Get these slides!


Let me introduce myself first...

👋 I'm Luciano (🇮🇹🍕🍝🤌)
👨💻 Senior Architect @ fourTheorem (Dublin 🇮🇪)
📔 Co-Author of Node.js Design Patterns 👉






We are business focused technologists that deliver.
Accelerated Serverless | AI as a Service | Platform Modernisation
We host a weekly podcast about AWS
🤔
Is serverless a good option for HPC?
Agenda
- HPC Case study
- Our requirements & principles
- The implementation
- Achievements & Pain points
- Questions (& bashing)
Based on a talk presented at the AWS Summit London 2022 (MA-03 with Matheus Guimaraes & Colum Thorne) - fth.link/jn5

2 types of Workflow
- 1️⃣ Risk Rollup — Nightly
- 2️⃣ Deal Analytics — Near-Real time
1️⃣ Risk Rollup
- Uses financial modelling to understand the state of the portfolio
- Executed 2-3 times a day
- Multiple terabytes of data being processed
2️⃣ Deal Analytics
- Uses the same modelling code but focuses on a subset of deals
- High frequency of execution (~1000 times a day)
- Lower data volumes
Original on-prem implementation

Challenges & Limitations of this implementation
- Scale!
- Long execution times (constraining business agility)
- Competing workloads
- Limited ability to support portfolio growth
- Hard to deliver new features
Let's re-imagine all of this!
... In the cloud ☁️
Design Principles
-
Think big
Plan for future growth & more
-
Use managed services as much as possible
Limit undifferentiated heavy lifting
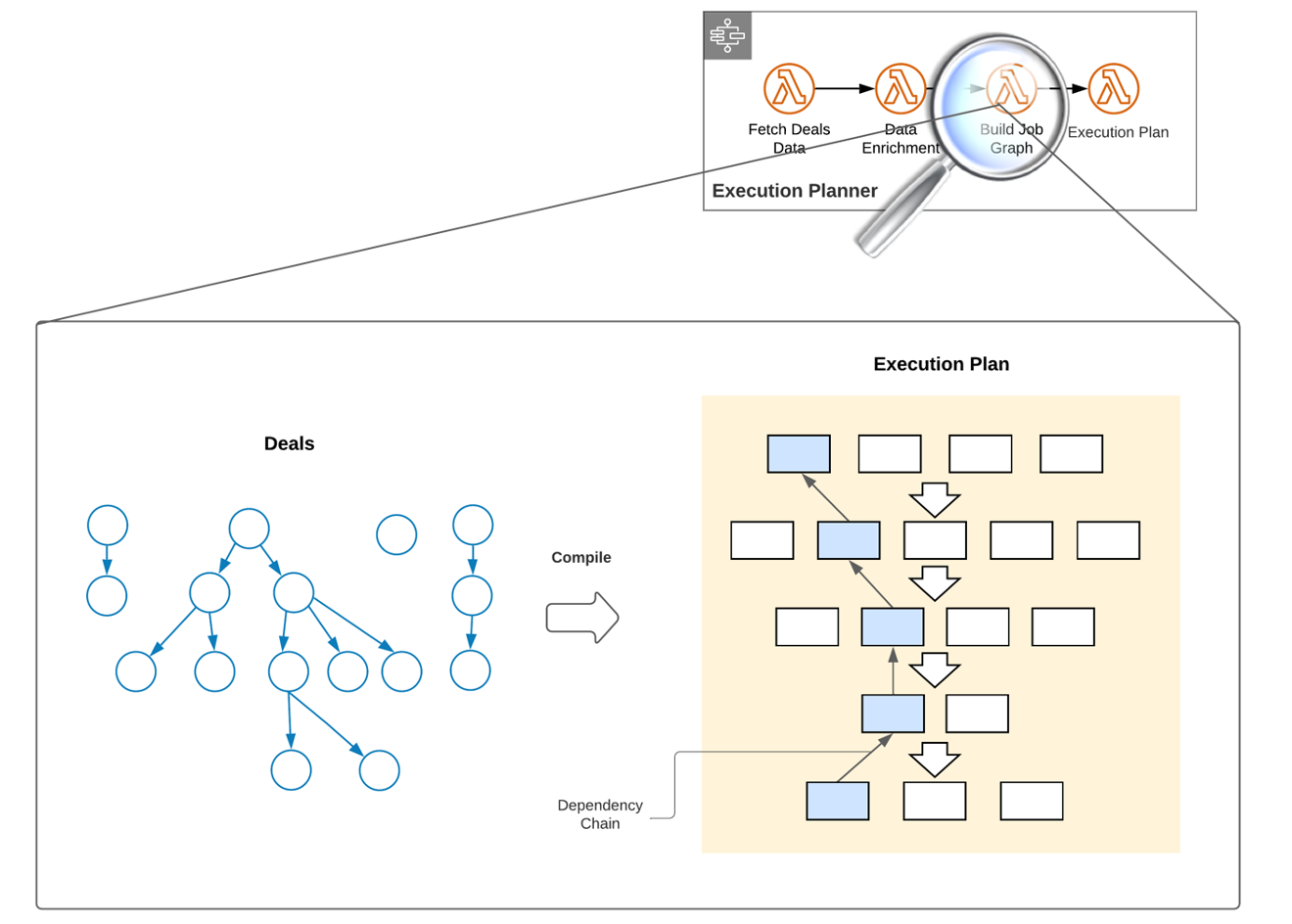
High-level architecture

Execution Planner
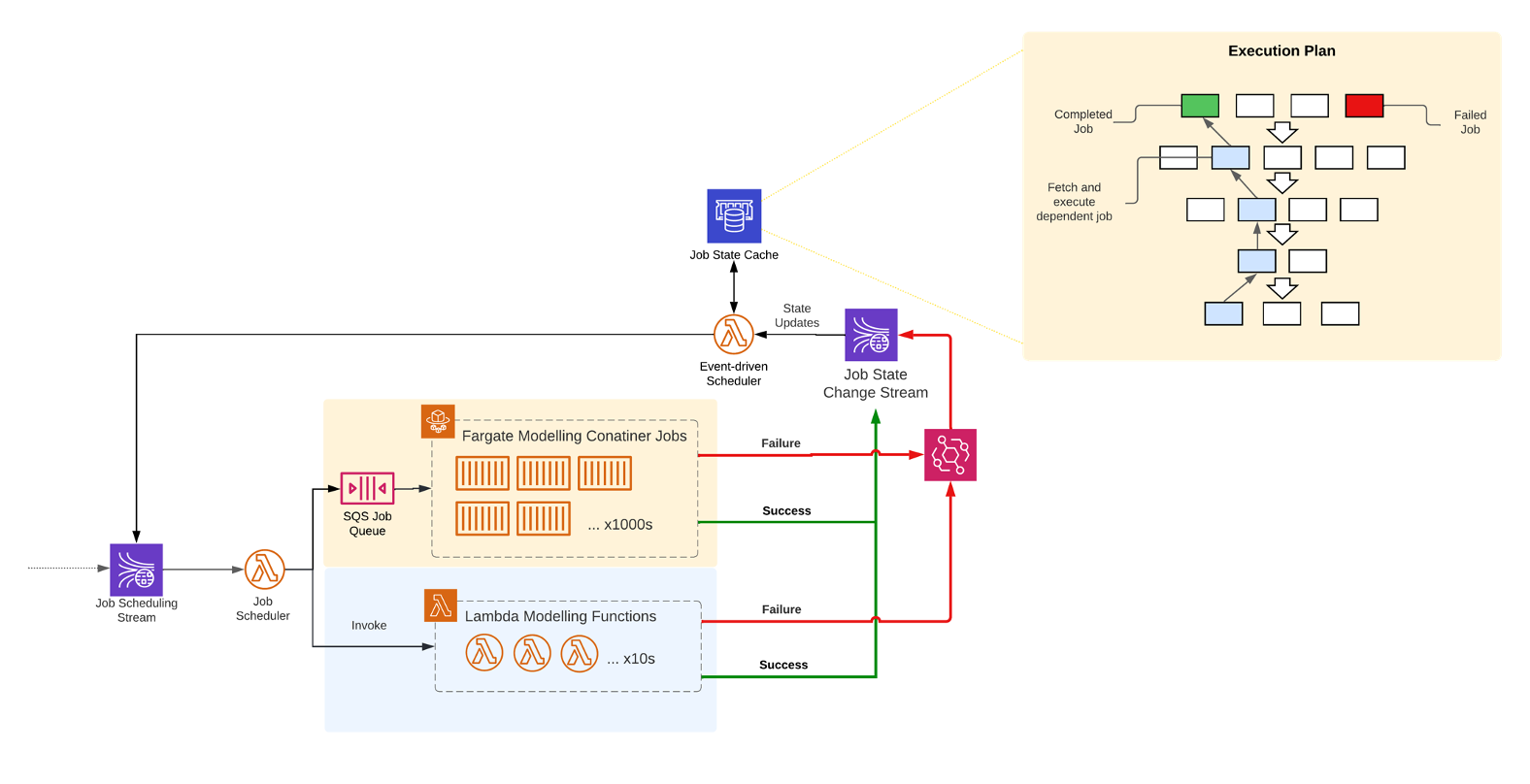
Compute Strategy and Error Handling
Outcomes
- Risk Rollup is fast (~1 hour)
- Faster and more consistent Deal Analytics
- Well positioned to support portfolio growth
- Reduced original codebase by 70%
- Lowered TCO
Technical challenges & pain points
- S3 throughput
- Job execution caching
- Scaling Fargate Containers
- Observability
S3 Throughput
- We read/write thousands of files concurrently
- Easy to bump into throughput exceptions if we don't use proper partitioning
- Automatic partitioning did not work well for us
- We needed to agree on an S3 partitioning schema with AWS (through support)
S3 Quotas
- 3,500 write req/sec
- 5,500 read req/sec
- per prefix
/parts/123abc/... /parts/456efg/... /parts/ef12ab/... /parts/...
Job execution caching
- Most jobs are deterministic
- If we have the output in S3 we don't need to re-run them
- But that means sending tens of thousand of HEAD requests to S3 in a short amount of time! 🙈
- We had to build our own custom S3 caching solution!
Job execution caching
- We store all the generated files in a Redis SET
- We use Redis SET intersection operation to quickly figure out which jobs needs to be scheduled and which ones we can skip
Job execution caching
- The process to update the cache is event based
- Whenever theres is a new output object in S3 we trigger a lambda to add the new key to the Redis set
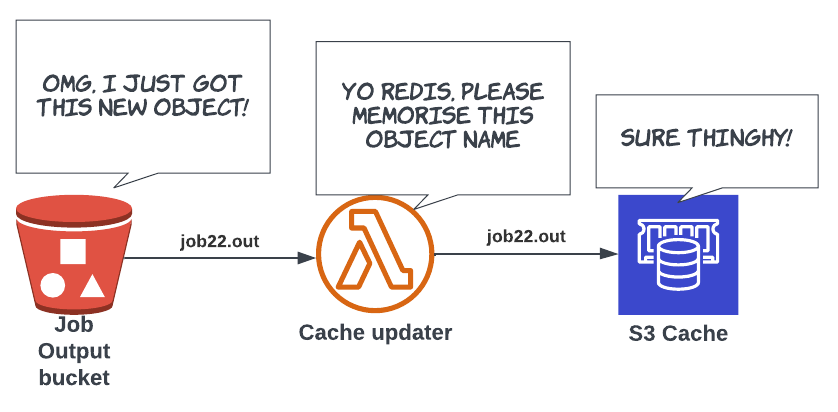
Job execution caching
- Redis memory grows very quickly, so we need to regularly remove files from the set...
- And this is where things get complicated!


Job execution caching
- Unfortunately, Redis does not support expiring individual keys in a set! 😥
- We ended up implementing our own expiry flow using DynamoDB TTL!
Job execution caching
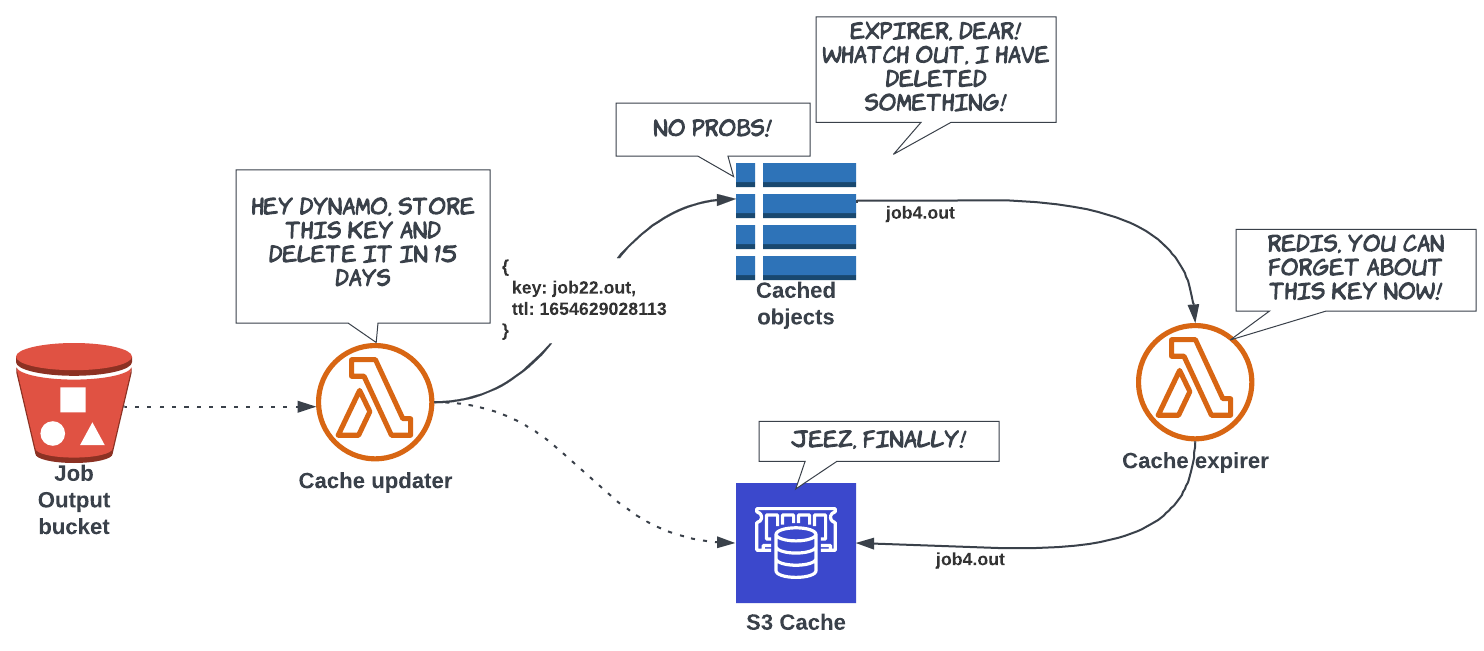
Job execution caching
- Our actual implementation is even more complicated than this...
- We try to batch were possible and we try to limit the speed of write to DynamoDB using Kinesis and SQS.
- All this complexity doesn't add undifferentiated value and we'd happily get rid of it if there was a managed solution...

Yup... I know what you are thinking!
Scaling Fargate containers
- When we run a Risk Rollup job we need to spawn ~3k container tasks ASAP.
- Using a Fargate service, it was taking ~1 hour to do that (this might have changed).
- Not ideal for us, so we looked for solutions that did not require us to move away from Fargate.
- We realised that by calling the runTask API directly we could spawn container tasks faster! So we built a custom Fargate task scaler!
Scaling Fargate containers
We have a continuously running step function to scale up the number of containers as needed
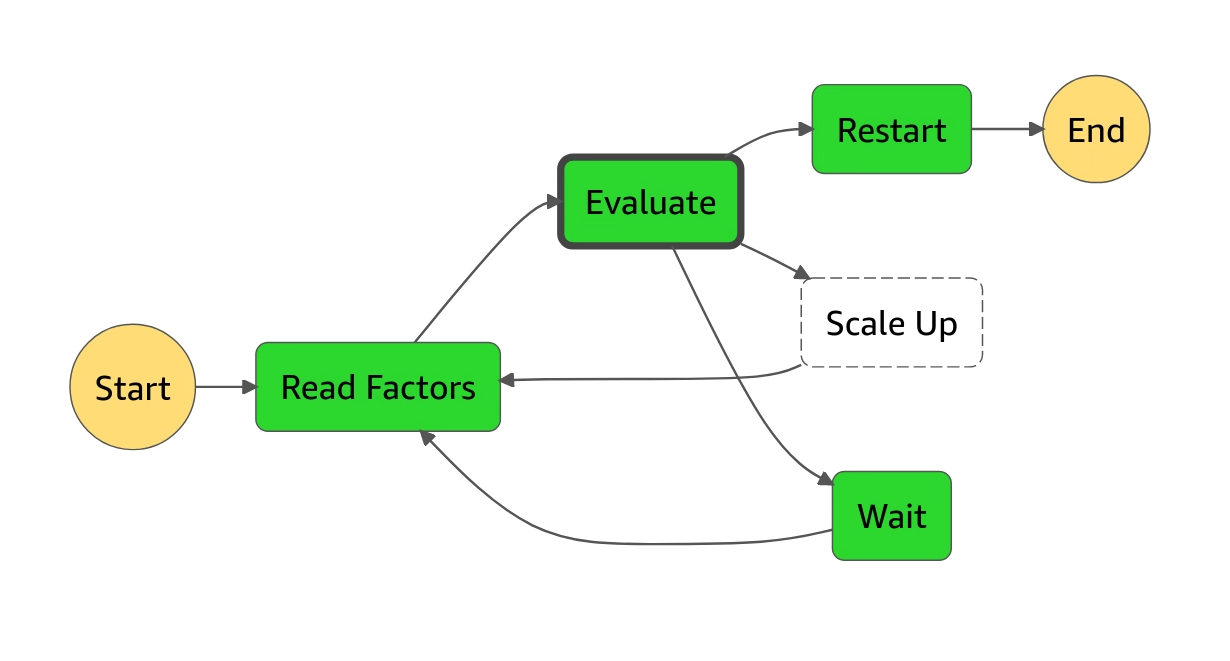
Decides whether to restart the step function, start new tasks or simply wait
Checks all the running jobs and how many containers they need
Uses the runTask API to start as many containers as needed
If this step function has done 500 iterations, start a new one and end
Scaling Fargate containers
How do we stop containers?
They stop automatically after 15 minutes if they can't get jobs from the queue.
while True:
result = sqs_client.receive_message(/* ... */)
if 'Messages' not in result and
time.time() - time_since_last_message > 15 * 60:
break
else
process_job(result['Messages'])Scaling Fargate containers
- We tried to build a continuous workflow using serverless technologies (Step Function + Lambda).
- This is another example of undifferentiated heavy lifting.
- We should go back and try again the performance of Fargate and see if we can remove this custom component from our architecture.
Observability
- We have built a complex workflow with multiple components, how do we make sure it works as expected in production?
- Lots of effort put into consistent logging (using Lambda PowerTools for Python and relying heavily on CloudWatch Log Insights)
- Lots of effort in collecting metrics, visualising them through dashboards and triggering alarms when something seems wrong.
- It's a constant work of review and fine tuning.
- If only observability can be a little bit easier...
Conclusion
- We believe that Serverless is a viable option for HPC workloads
- The performance is great and most of the components scale to 0
- There are some rough edges but we believe the ecosystem around this use case is still in its infancy
- Things will improve and the future of HPC will be a lot more serverless!
Cover Photo by israel palacio on Unsplash
Thanks to @eoins, @pelger, @guimathed, @cmthorne10 + the awesome tech team at RenRe!
THANKS! 🙌

* just a happy cloud