The future will be
SERVERLESS
Verona, 9 May 2018
Luciano Mammino (@loige)


Luciano... who



Solution Architect at


with @mariocasciaro

with @andreaman87

with @ Podgeypoos79

Agenda
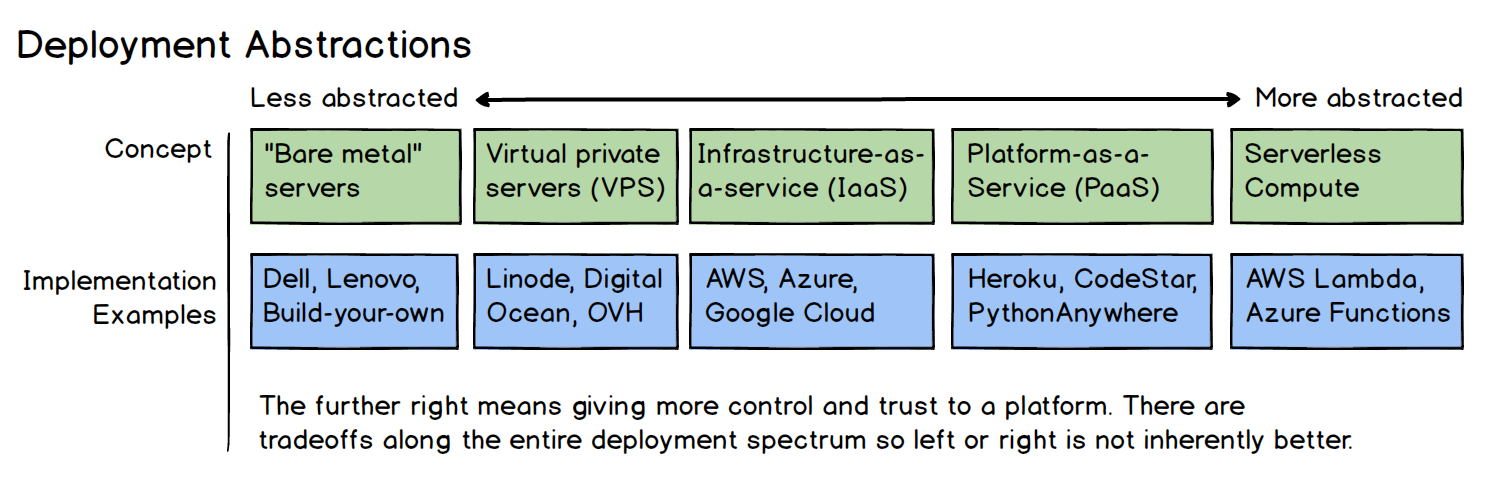
Chapter 1: from bare metal to Serverless
Chapter 2: Serverless, WTF?!
Chapter 3: Understanding Serverless
Chapter 4: A Serverless use case
Chapter 5: PROs n' CONs
Chapter 6: It's time to get started

Chapter 1
from bare metal to Serverless


“You have to know the past to understand the present.”

1989-1991 — Sir Tim Berners-Lee invented the World Wide Web

1991-1995 — The bare metal age

1995 — The invention of web hosting
1997 — Grid computing: 2 machines are better than 1!

Ian Foster
1999 — Salesforce introduces the concept of Software as a Service (SaaS)

Marc Benioff
2001 — VMWare releases ESXi, "server virtualization" becomes a thing

2002-2006 — AWS is born (IaaS), people talk about "Cloud computing"

2009 — Heroku and the invention of the "Platform as a Service" (PaaS)

James Lindenbaum
Adam Wiggins
Orion Henry
2011 — Envolve/Firebase, real time database as a service (RTDaaS???)

James Tamplin and Andrew Lee
2012 — Parse.com and the first Backend as a Service (BaaS)

Tikhon Bernstam
Ilya Sukhar
James Yu
Kevin Lacker
2013 — Docker, "linux containers are better than virtual machines"

Solomon Hykes
2013-2015 — Kubernetes / Swarm / Nomad / CoreOs (containers at scale)

2014 — Launch of AWS Lambda (FaaS)

Chapter 2
Serverless, WTF*?!
*What's The Fun

"Serverless most often refers to serverless applications. Serverless applications are ones that don't require you to provision or manage any servers. You can focus on your core product and business logic instead of responsibilities like operating system (OS) access control, OS patching, provisioning, right-sizing, scaling, and availability. By building your application on a serverless platform, the platform manages these responsibilities for you."
— Amazon Web Services
loige.link/serverless-apps-lambda
The essence of the serverless trend is the absence of the server concept during software development.
— Auth0

Chapter 3
Understanding Serverless

The 4 pillars of serverless
(TLDR; It's not only about servers)
No server management
You don't know how many and how they are configured



Flexible scaling
If you need more resources, they will be allocated for you
High availability
Redundancy and fault tolerance are built in
Never pay for idle
Unused resources cost $0
The serverless layers
(TLDR; It's not only "FaaS")
👉 Compute














👉 Data
👉 Messaging and Streaming
👉 User Management and Identity
👉 Monitoring and Deployment
👉 Edge
Stuff that we can build
📱 Mobile Backends
🔌 APIs & Microservices
📦 Data Processing pipelines
⚡️ Webhooks
🤖 Bots and integrations
⚙️ IoT Backends
💻 Single page web applications
Some SERVERLESS APPs I helped build
Open source
- A "semi-automated" weekly newsletter (Fullstack bulletin)
- A middleware framework for AWS Lambda (middy.js.org)
Enterprise
- Various solutions for the UK Energy industry: Trading platform, Billing engine, Market data aggregator (Planet 9 Energy)
- Big data pipeline (~1-5TB/day/customer) to make network data searchable (Vectra.ai)
execution model

Event → 𝑓
IF ________________________________ THEN ________________________________
"IF this THEN that" model
A new CSV file is saved to the object storage
Process it and save its records into the DB
HTTP request: GET /products
Retrieve products from DB and return a JSON
It's 2 AM
Scrape weather forecast for next days
Serverless and JavaScript
Frontend
🌏 Serverless Web hosting is static, but you can build SPAs
(React, Angular, Vue, etc.)
Backend
👌 Node.js is supported by every provider
⚡️ Fast startup (as opposed to Java)
📦 Use all the modules on NPM
🤓 Support other languages/dialects
(TypeScript, ClojureScript, ESNext...)
exports.myLambda = function (
event,
context,
callback
) {
// get input from event and context
// use callback to return output or errors
}Anatomy of a Node.js lambda on AWS
Chapter 4
A serverless use case

Search for threats using network metadata

Security researcher
Have an API to be able to search across network metadata files available on the shared FTP drive
I can find and validate potential security threats on the network
A serverless implementation (on AWS)

Network
Metadata
FTP Storage

Search API
(API Gateway)
Network metadata search service
User or other services
Sync
Lambda
Parse/Load
Lambda
API
Lambda

Network Metadata S3 Bucket
/metadata
elastic search index
scheduled event
new object
API
Request


sync lambda
{
"account": "123456789012",
"region": "us-east-1",
"detail": {},
"detail-type": "Scheduled Event",
"source": "aws.events",
"time": "2018-05-09T14:30:21Z",
"id": "cdc73f9d-aea9-1234-9d5a-835b769c0d9c",
"resources": [
"arn:aws:events:us-east-1:123456789012:rule/my-schedule"
]
}Cloudwatch scheduled event
exports.syncLambda = (
event,
context,
callback
) => {
// 1. connect to the FTP server
// 2. get list of files from FTP
// 3. get list of files from S3
// 4. make a diff to find new files in FTP
// 5. read the new files and save them to S3
// 6. invoke the callback to stop lambda
}sync lambda
LOAD lambda
{
"Records": [
{
"eventTime": "2018-05-09T14:30:21Z",
"s3": {
"object": {
"eTag": "0123456789abcdef0123456789abcdef",
"sequencer": "0A1B2C3D4E5F678901",
"key": "2018-05-09-metadata.csv.gz",
"size": 1024
},
"bucket": {
"arn": "arn:aws:s3:::metadata-sync-files",
"name": "metadata-sync-files",
}
},
"awsRegion": "us-east-1",
"eventName": "ObjectCreated:Put",
"eventSource": "aws:s3"
}
]
}S3 new object event
new object
exports.loadLambda = (
event,
context,
callback
) => {
// 1. get the new file details from the `event`
// 2. read the file and deserialize the records
// 3. send the records to elastic search using
// the bulk API
// 4. invoke the callback to stop lambda
}LOAD lambda
API lambda
{
"body": "",
"resource": "/metadata/search",
"requestContext": {
"resourceId": "123456",
"apiId": "1234567890",
"resourcePath": "/metadata/search",
"httpMethod": "GET",
"requestId": "c6af9ac6-7b61-11e6-9a41-93e8deadbeef",
"stage": "prod"
},
"queryStringParameters": {
"q": "srcIp:127.0.0.1 AND host:google.com"
},
"headers": {
"User-Agent": "Custom User Agent String",
},
"httpMethod": "GET",
"path": "/metadata/search"
}API Gateway proxy event
API
Request
exports.apiLambda = (
event,
context,
callback
) => {
// 1. read the HTTP details (query) from
// the `event`
// 2. issue the query to ElasticSearch to the
// given index
// 3. reformat the results into an API gateway
// response
// 4. invoke the callback passing the response
}API lambda
Orchestration / configuration
Who defines the events and where do we store the config?
ORCHESTRATION / CONFIGURATION
Many options
- Manually a.k.a. "clicky-clicky" from the Web UI
- Declarative code-based approaches:


service: metadataSearch
provider:
name: aws
runtime: nodejs8.10
functions:
sync:
handler: index.syncLambda
environment:
FTP_HOST: "28.0.1.22:23"
FTP_USERNAME: admin
FTP_PASSWORD: unicorns
S3_BUCKET: metadata-sync-files
events:
- schedule: rate(2 hours)
load:
handler: index.loadLambda
environment:
ES_INDEX: metadata
events:
- s3:
bucket: metadata-sync-files
event: "s3:ObjectCreated:*"
api:
handler: index.apiLambda
environment:
ES_INDEX: metadata
events:
- http: GET metadata/searchServerless framework example
serverless.yml
sls deploy
- Reads the serverless.yml and parses the resources
- Creates a zip file containing the source code
- Creates a Cloudformation stack with all the resources listed in serverless.yml
- Deploys the stack (including Lambda code)
$
(Many) things I didn't have to worry about...
-
What type of virtual machine do I need?
-
What operating system?
-
How to keep OS/System updated?
-
How much disk space do I need?
-
How do I handle/retry failures?
-
How do I collect and rotate logs?
-
What about metrics?
-
What machine do I need to run the database?
-
How do I backup the database?
-
How do I scale the database?
-
Which web server should I use and how to configure it?
-
Throttling? Managing API Keys? API caching?

Chapter 5
PROs n' CONs


Focus on delivering business value / Fast time to market
Less "Tech-freedom™️" /
Tight vendor lock-in!
Optimal resource allocation
Not-magic™!
You still have to write configuration
Auto-scalability
Cold start problem
High Availability
Soft/Hard Limits
Pay per usage
(don't pay for idle!)
Local development,
Testing, Debugging
Growing ecosystem
Older technologies
might not integrate well
Chapter 6
It's time to get started

Who is already adopting Serverless








Pick A FaaS and start to have fun!

IBM
Cloud Functions
AWS
Lambda
Azure
Functions
Cloud Functions
Auth0
Webtask

Iron.io
FaaS
Spotinst
Functions

Apache OpenWhisk
Fission
stdlib
service
Functions
Fn

Kubeless
Cloud based
Self-hosted / Open Source
effe

LeverOS
Open FaaS
Why IS Serverless the future?
My 2 favourite reasons:

Opportunity to deliver value to the customer quickly
Pay only for the used resources
Tomorrow I'll migrate all my apps to serverless
Approach this with care...
Thanks!

Questions?
Now or later to @loige :)
If your company wants to get started with serverless on AWS, be sure to check out serverlesslab.com
Credits
High Res Emojis by emojiisland.com
- World Wide Web Foundation, history of the web
- Web hosting on Wikipedia
- The history of web hosting: how things have changed since Tibus started in 1996
- Grid computing on Wikipedia
- Globus toolkit on Wikipedia
- Globus Alliance on Wikipedia
- Globus: A Metacomputing Infrastructure Toolkit (slides)
- The Anatomy of the Grid: Enabling Scalable Virtual Organizations (paper)
- Computer Weekly, the history of Cloud Computing
Brief history of Salesforce.com- With
long history of virtualization behind it, IBM looks to the future - About Amazon Web Services (official)
- Fullstack python: What is Serverless
- Parse (platform) on Wikipedia
- Firebase on Wikipedia
- Kubernetes on Wikipedia
- CoreOS on Wikipedia
- AWS Lambda on Wikipedia
- Serverless Computing on Wikipedia
- "AWS Serverless Applications Lens" white paper (pdf)
- "Serverless Architectures with AWS Lambda" white paper (pdf)
- AWS Lambda VS the World
- Serverless: Looking Back to See Forward
- Awesome Serverless (GitHub repository)
- Discussion about the history of Serverless on
Lobste .rs

PLEASE GIVE FEEDBACK