修士での研究紹介
ロボット身体のための適応的な環境接触行動における
継続的自己学習のための階層型学習システムの研究
学際情報学府学際情報学専攻 先端表現情報学コース
西浦 学
指導教員 稲葉 雅幸 教授
背景と目的
- 人間が日常生活で多く行う動作:身体の多点を環境に接触させておこなう環境接触行動
- 軸駆動の減速比の高いアクチュエータを備えたロボットで行うことは困難
- 人体を模倣した筋骨格ヒューマノイドは柔軟な身体を活かして環境になじめる
- これまでの研究では課題に応じてkey-poseや軌道を人が与えていた
- ロボットが自身で学習できるように拡張していくことが必要

背景と目的
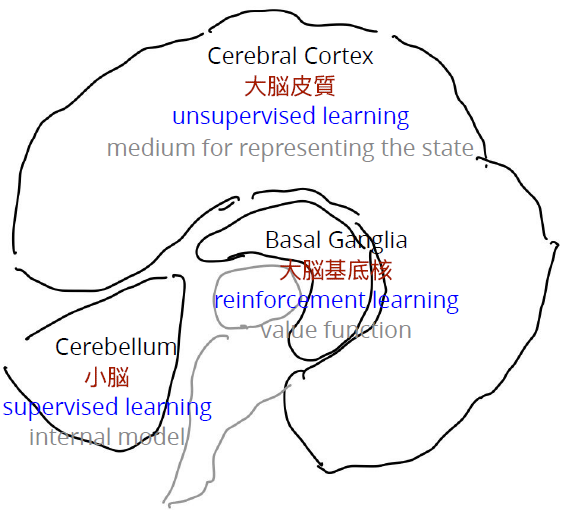
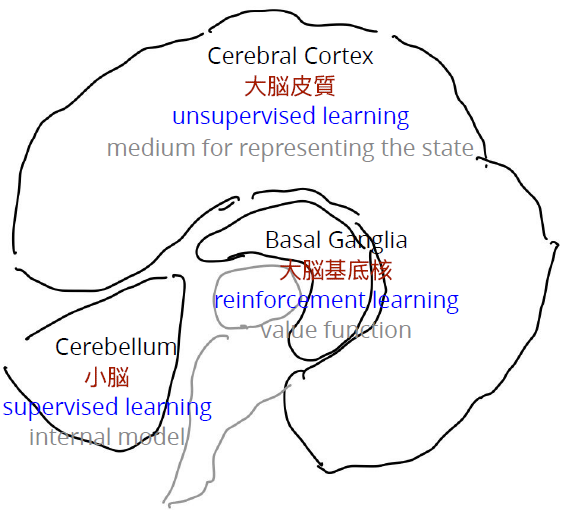
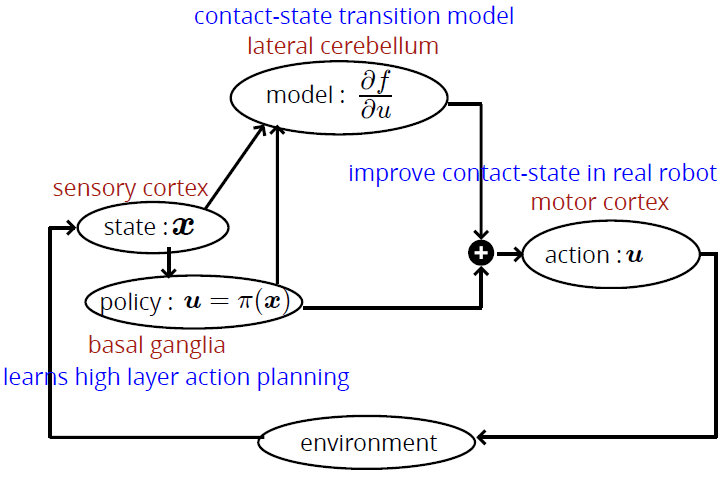
- 人間の脳の部位ごとに異なる学習則を用いた階層構造[1]
- 運動機能に関わる内部モデル
などを教師あり学習で学習
する小脳 - 感覚器官で認識した状態を
中間的な状態にエンコード
するモデルを教師なし学習
で学習する大脳皮質 - 目的がある行動を強化学習
により学習する大脳基底核
- 運動機能に関わる内部モデル
- 人間の脳の階層構造を参考に学習システムを提案
[1]Doya 1999,Neural Networks
本研究の構成
- 脳の階層型アーキテクチャを参考にした階層型学習モジュール
- 強化学習により行動のプランニングを学習
- 自己教師あり学習により接触状態を含んだ身体モデルを学習
- 接触状態を含んだ身体モデルを用いて実機での接触状態を改善する方策
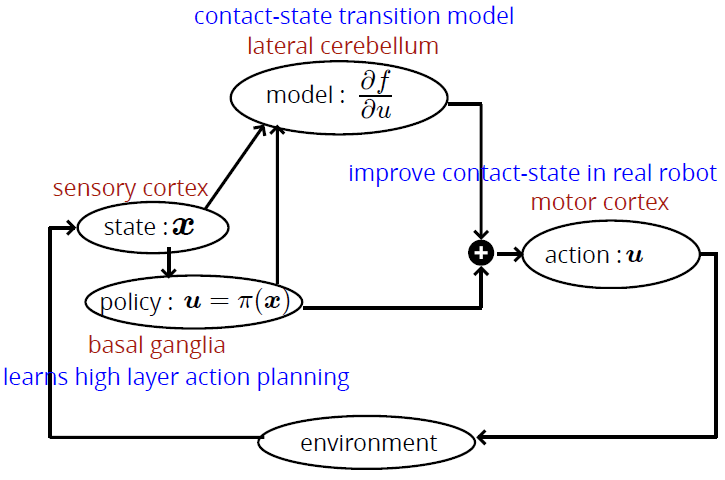
本研究の構成
- 脳の階層型アーキテクチャを参考にした階層型学習モジュール
- 強化学習により行動のプランニングを学習
- 自己教師あり学習により接触状態を含んだ身体モデルを学習
- 接触状態を含んだ身体モデルを用いて実機での接触状態を改善する方策
接触状態を含んだ身体モデル
- 環境物体との接触状態を含んだ剛性モデル
- 抵抗力が途中で変化する課題に対して人間の教示データから課題遂行に必要な作業空間剛性を探索する
- 力センサ情報から探索すべき剛性を判断する
- 環境物体との接触状態を含んだ重心モデル
- 人間の教示データから関節角変位によって接触状態がどのように変化するかを学習する

接触状態を含んだ剛性モデル
課題教示時のセンサ情報から課題遂行に必要な剛性戦略を獲得

接触状態を含んだ剛性モデルの学習
- 課題教示時の力センサ情報と関節角度を記録
- 課題をN段階に分ける
- 力の変化が一番大きかったセンサ情報を用いて剛性の探索を行う

地面に凹凸があり抵抗力が変化する机を押す課題




execution using lower limit stiffness
execution using upper limit stiffness
execution using explored stiffness
- 関節角度列を教示して剛性を探索
ダンパがあり扉を閉める課題
- 関節角度列を教示して剛性を探索



execution using lower limit stiffness
execution using explored stiffness
重いひきだしを引く課題
- 関節角度列を教示して剛性を探索



execution using lower limit stiffness
execution using explored stiffness
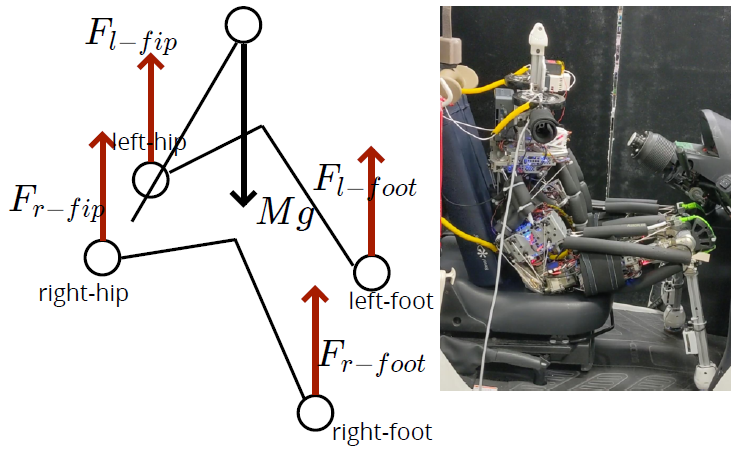
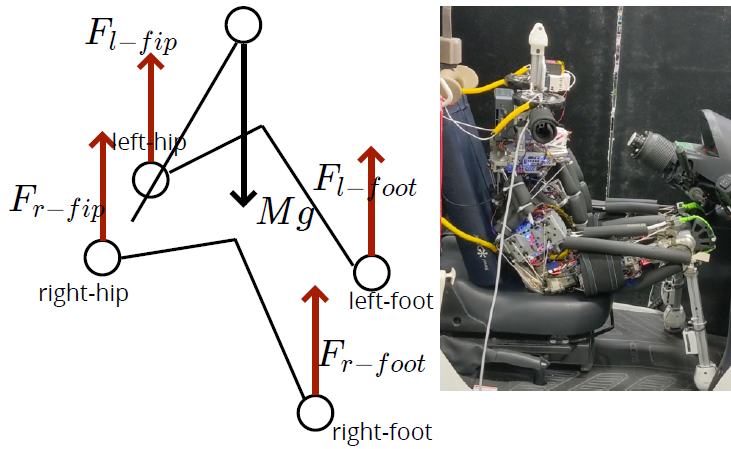
接触状態を含んだ重心モデル
- 接触状態が関節角の変異によりどのように変化するかを学習する
- 状態:両足にかかる力,両臀部にかかる力,現在の関節角
- 入力:関節角変位
-
で表わされる非線形関数を
ニューラルネットワークにより
学習
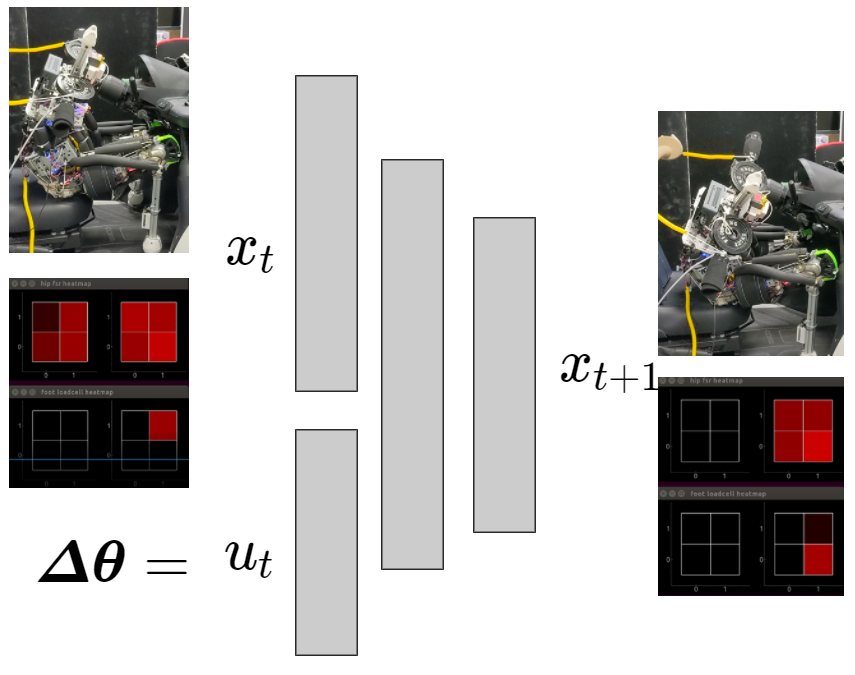
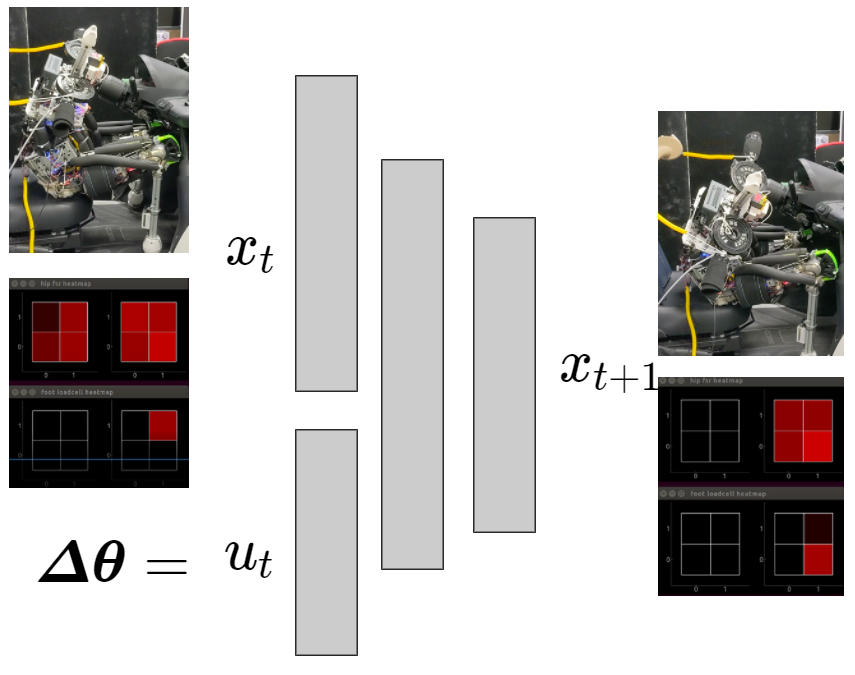
接触状態を含んだ重心モデルの学習
- 椅子に座らせた状態で人間が関節角度空間で指令を送り,そのときの関節角と接触状態のデータを用いる

学習した重心モデルの評価実験
- 学習した重心モデルを用い,目標状態を実現するような制御入力をモデルを逆伝搬させることによって得る
- 制御入力 をランダム
に決定し,モデルを順伝搬
させたときの予測状態
と目標状態 との誤差を少な
くする方向に制御入力を更新する
- 制御入力 をランダム
- 初期状態から右に重心が寄った
状態を とすることで求めた を用いた
学習した重心モデルを用いた椅子への座り込み実験
- 右側に重心を寄せる
- 十分重心が寄ったところで左臀部を後ろに送る
- 左側に重心を寄せる
- 十分重心が寄ったところで右臀部を後ろに送る
のくりかえし


学習した重心モデルを用いた椅子への座り込み実験
- 右側に重心を寄せる
- 十分重心が寄ったところで左臀部を後ろに送る
- 左側に重心を寄せる
- 十分重心が寄ったところで右臀部を後ろに送る
のくりかえし
本研究の構成
強化学習を用いた一連の動作の生成
- Soft-Actor-Criticアルゴリズムを用いて椅子に座り込む動作の学習を行った
- 課題の途中で中間的な目標状態を設定する
ことが必要な課題に対して階層的な方策を
用いて学習した- 上位方策: 現在の状態から目標関節角を生成
- 下位方策: 上位方策が生成した目標関節角を実現する
筋長をそれぞれの筋に送る[2]
- 課題の途中で中間的な目標状態を設定する
[2]Kawaharazuka et,al 2019 IROS,pp.2965-2972
強化学習を用いた環境接触行動の学習
- 上位方策
- 観測:足先の力,臀部の力,現在の関節角,骨盤の傾き
- 報酬関数:足先に力がかかっている,臀部に力がかかっている,足先と目標位置の距離,行動が終ったときに椅子に乗っている
- 行動:目標関節角

学習した方策による座り込み動作
Text

本研究の構成
接触状態改善方策
- シミュレータで学習した方策を実機で実行するために実機での方策を改善する手法を提案する
- シミュレータと実機において乖離が発生するのは主に以下の要因
- アクチュエータの挙動が再現できていない
- 摩擦が現実と異なる
- 物理パラメータが実機と異なる
- 本研究では環境接触行動を実機で実現するために接触状態改善方策を提案する
- 課題ごとの方策の実行後に
接触状態のずれを改善する - 接触状態を含んだ身体モデル
を用いて制御入力を決定する
- 課題ごとの方策の実行後に
全身での環境接触動作
[3] 野田ほか: "複数の接触遷移方式を統合する全身行動計画法とヒューマノイドの滑り接触遷移行動への応用" JRSJ

- 椅子への座りこみ動作
- これまでの研究では臀部リンクの目標軌道を与え,関節負荷などを制約条件に加えて,人間が与えた接触状態を遷移可能な軌道を探索することで座り込みを実現している.[3]
- 本研究ではシミュレータで獲得された方策を用い,臀部リンクの目標軌道や目標接触状態などを与えずにロボットが自律的に座り込みを行う
- これまでの研究では臀部リンクの目標軌道を与え,関節負荷などを制約条件に加えて,人間が与えた接触状態を遷移可能な軌道を探索することで座り込みを実現している.[3]

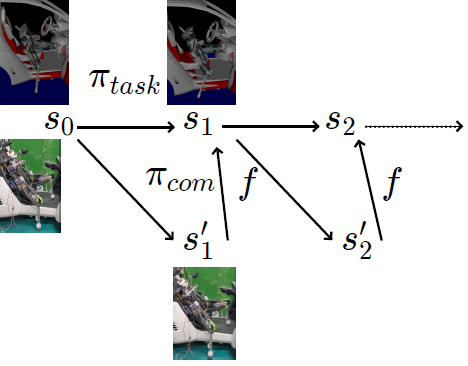
階層型アーキテクチャによる環境接触行動
- シミュレータ内で学習した方策 による実現可能状態列
のうち,関節角度列のみを用いて行動を行う - 各行動の後にシミュレータ内との状態の誤差を補償するために接触状態改善方策を用いる
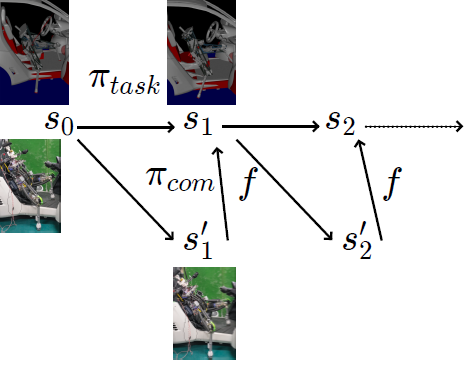
階層型アーキテクチャによる環境接触行動
車両に腰掛けた状態からの座り替え実験
結論
- 人間が日常生活で多く行う環境接触行動に対して,脳の階層型モジュール構造を参考に学習則の異なるモジュールを組み合わせて実現する学習システムを提案した.
- 運動計画部分は強化学習によりシミュレータ内で動作を実行可能な状態群を学習する方法を提案した.
- 接触状態を含んだ身体モデルは,人間の教示時のデータを基に自己教師あり学習により学習する手法を提案した.
- シミュレータで学習した方策を実機で実現するために実機で接触状態を改善する方策を提案した.
- 提案した学習モジュールを組み合わせることにより椅子に横から腰掛けた状態からの座り替え動作を目標軌道などを与えることなく実現することができた.
剛性モデルの詳細


実験に用いた筋骨格ヒューマノイドの詳細
- 13自由度
- 疑似球関節

下位方策の詳細
- 関節角空間と筋空間のマッピングをニューラルネットワークで学習したもの
- 幾何モデルから関節角度と筋長を学習したIJMM
- 実機のデータから筋の伸びを補償するモデルを学習したMRCMからなる

[2]Kawaharazuka et,al 2019 IROS,pp.2965-2972
可変剛性制御の詳細
- 作業空間剛性を実現可能な筋長を山登り法で探索する

[2]Kawaharazuka et,al 2019 IROS,pp.2965-2972