
Claudia Merger
10.07.2025
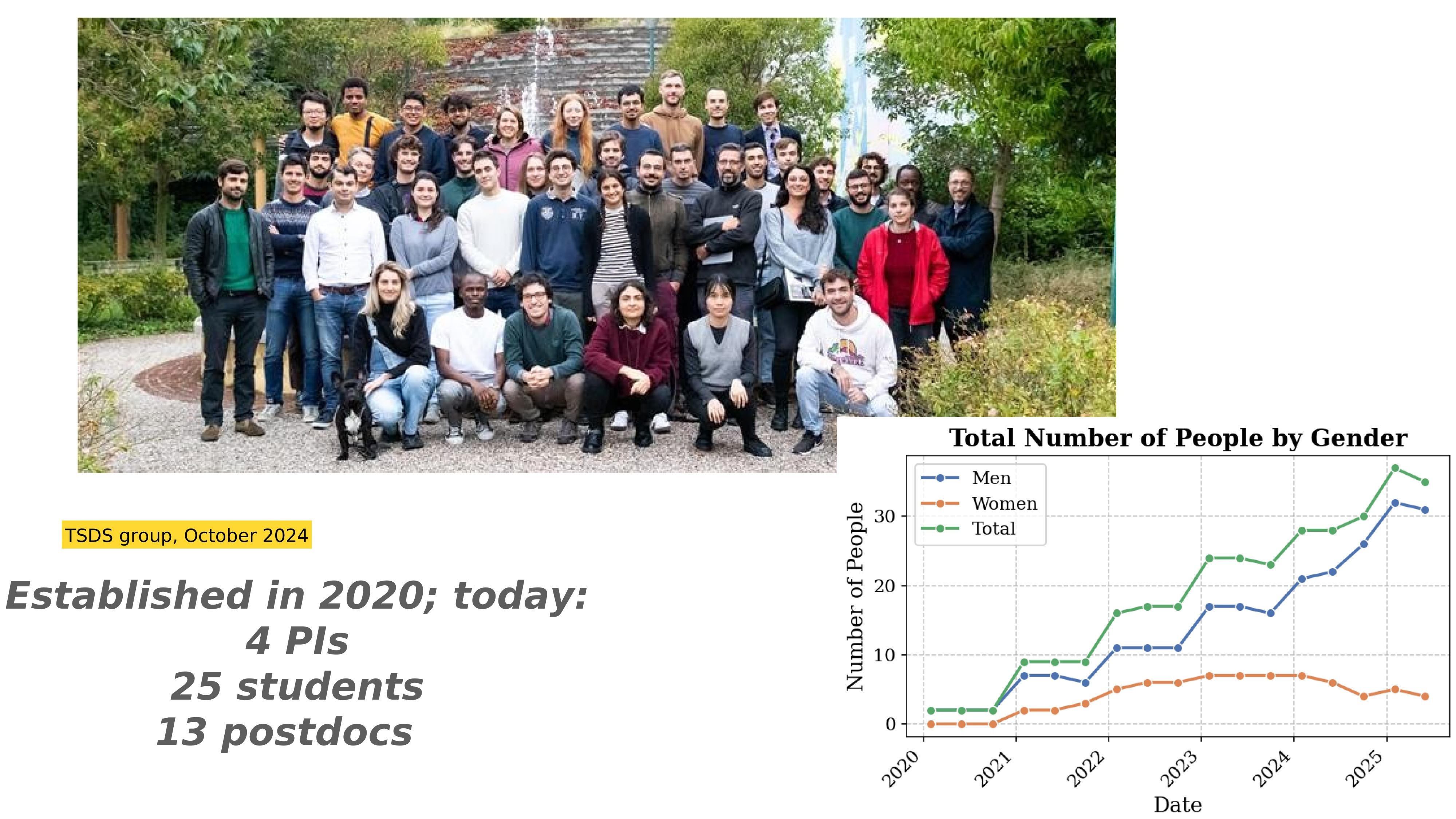
Established in 2020; today:
4 PIs
25 students
13 postdocs
TSDS & friends, October 2024

Theoretical Neuroscience and DS



Understanding Generative Models via Interactions

Claudia Merger
12.08.2025
Generative models learn data statistics
e.g. Image generation
Task: Given some data \( \mathcal{D} \) from an unknown distribution \( p \)
Generate \( x \sim p \)
Task is solved by learning \( \, p_{\theta} \approx p\)

"happy data scientist"
"summer in Trieste"
"intelligent bamboo"





Understanding Generative models
Task: Given some data \( \mathcal{D} \) from an unknown distribution \( p \)
Generate \( x \sim p \)
Task is solved by learning \( \, p_{\theta} \approx p\)
Two questions:
- What can we learn from \(p_{\theta} \) about data?
- How close are \( p, \, p_{\theta} \) ?
\( p\)
\( \, p_{\theta} \)
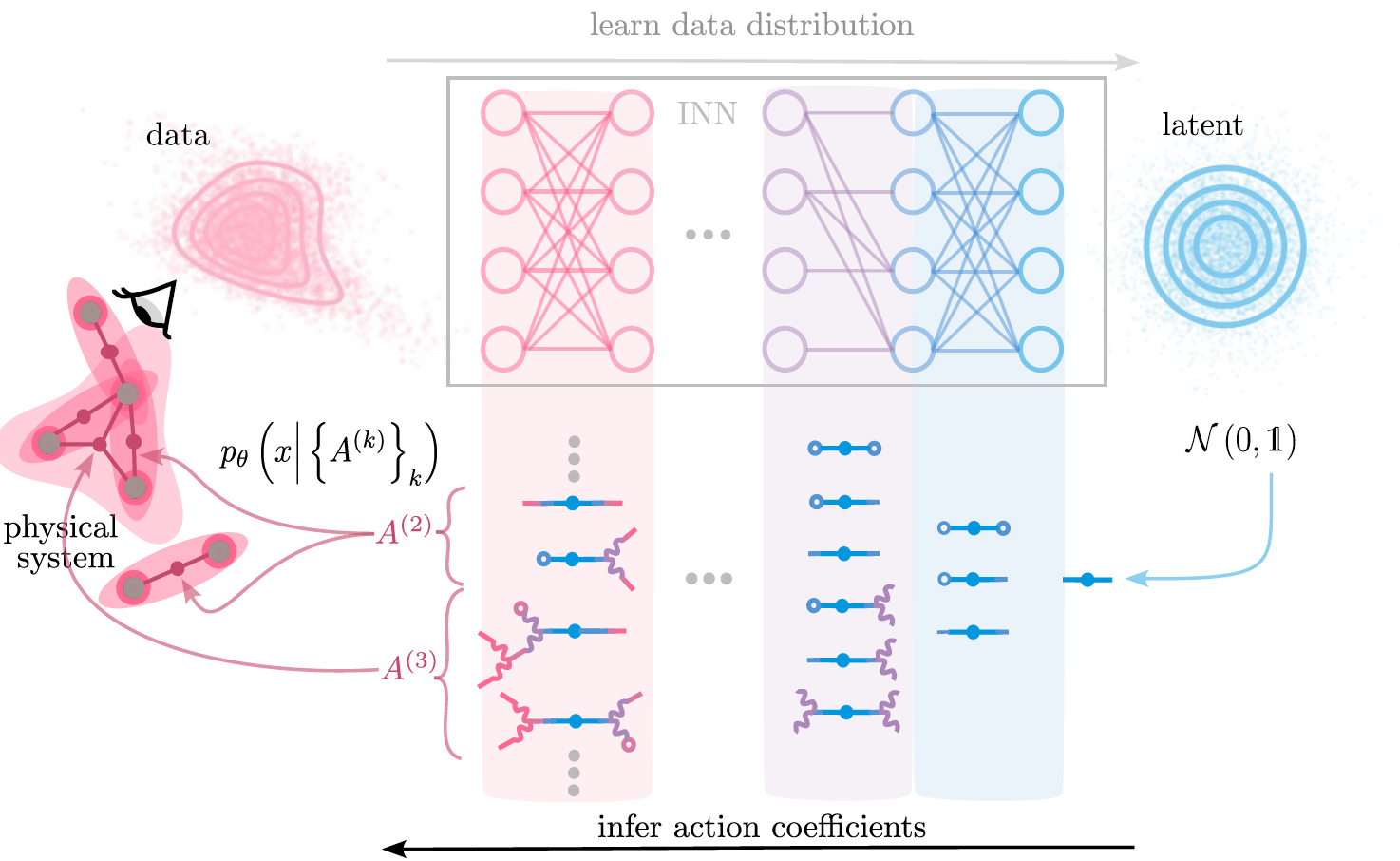
Statistical physics provides a language to span model space. \( \rightarrow \) interactions
?
?
Write interacting theory using polynomial action \( S_{\theta} (x) = \ln p_{\theta} (x)\)
\( S_{\theta} (x)= A^{(0)} + A^{(1)}_{i} x_i + A^{(2)}_{ij} x_i x_j +A^{(3)}_{ijk} x_i x_j x_k + \dots \)

Example:
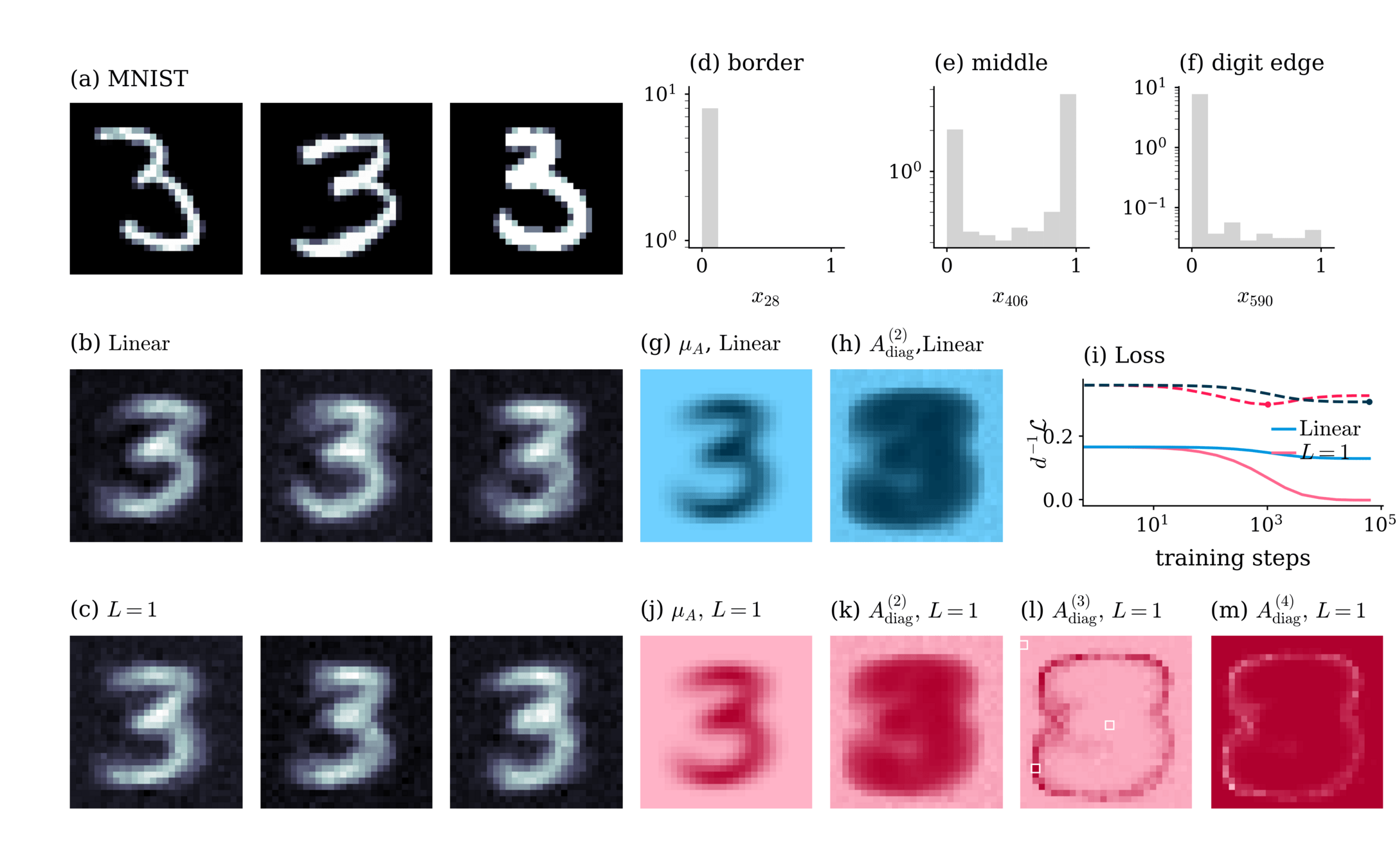
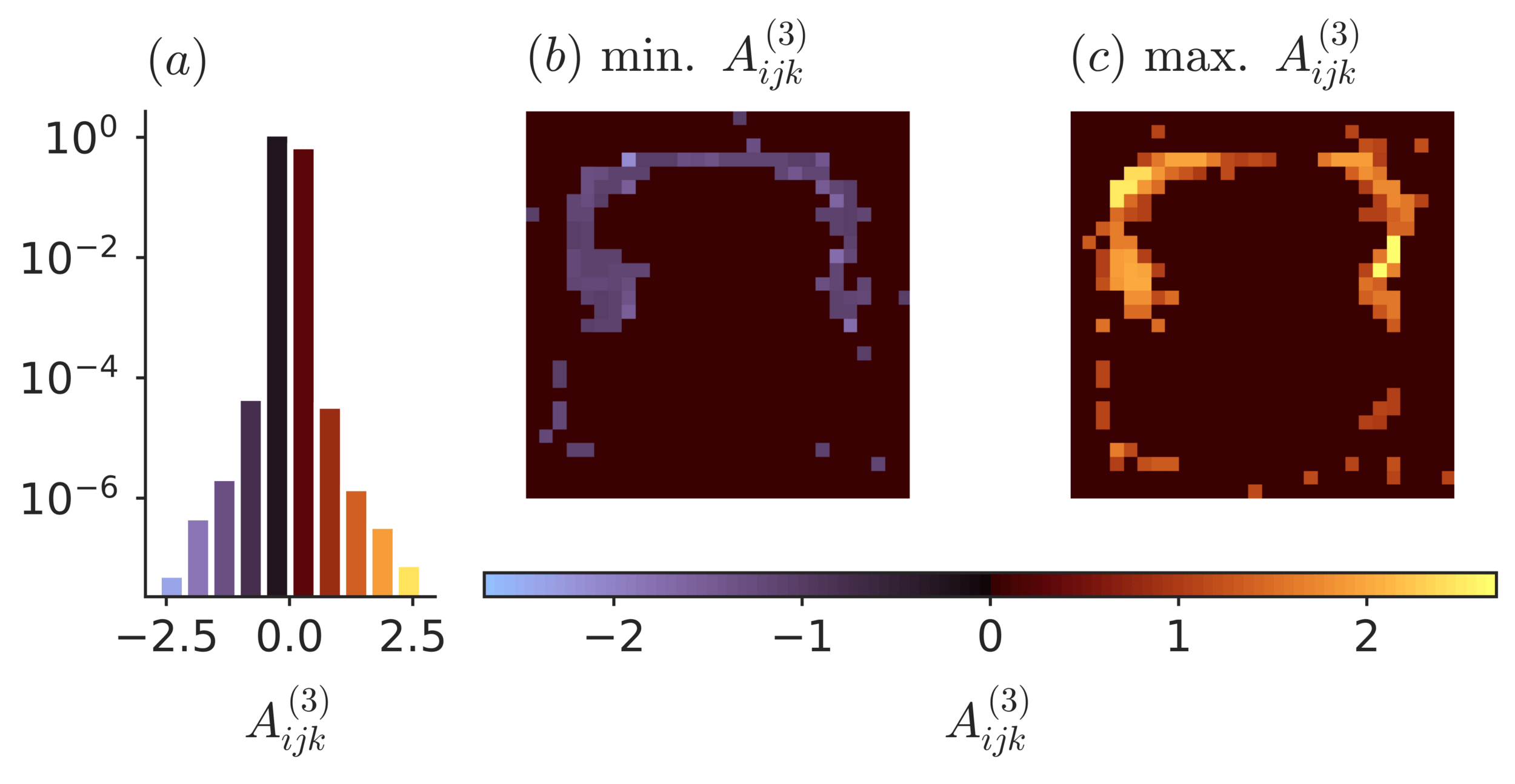
Interactions are effective descriptions of complex systems
Merger, C., et. al. ‘Learning Interacting Theories from Data’. PRX, 2023
Write interacting theory using polynomial action \( S_{\theta} (x) = \ln p_{\theta} (x)\)
\( S_{\theta} (x)= A^{(0)} + A^{(1)}_{i} x_i + A^{(2)}_{ij} x_i x_j +A^{(3)}_{ijk} x_i x_j x_k + \dots \)
\( A^{(k)} \)
Interactions are effective descriptions of complex systems
Why use interactions to study deep learning?

Observation: neural networks learn "easy" statistics first, then more complex statistics
\( \rightarrow \) principled approach to studying learning of statistics from data, from easy to hard
\( \rightarrow \) see also: Ingrosso & Goldt, 2022; Refinetti et al., 2023; Belrose et al., 2024, ...
How do generative models work?

interpolate
Invertible neural networks learn data distributions
NICE (Dinh et. al., 2015 ), RealNVP (Dinh et. al., 2017), GLOW (Kingma et. al. , 2018)
Mapping between Normalizing Flows and higher order interacting theories
Merger, C., et al. ‘Learning Interacting Theories from Data’. PRX, 2023
Mapping between Normalizing Flows and higher order interacting theories
Example:
Merger, C., et al. ‘Learning Interacting Theories from Data’. PRX, 2023
Diffusion models
Sohl-Dickstein, et al., ‘Deep Unsupervised Learning Using Nonequilibrium Thermodynamics’.
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. ‘Denoising Diffusion Probabilistic Models’, 2020
reverse iterative noising process by predicting noise \( \epsilon_t = \epsilon_{\theta}(x_t,t) \) at each step
"Generalization"
"Memorization"
Two solutions:



Kadkhodaie, Z. et. al. Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representations’. April 2024.
\(\rightarrow\) Empirically, generalization occurs when \(N\) is "large enough"
= Global minimum of the training loss
see e.g. Ambrogioni 2023.
Predict performance of diffusion models as a function of \( \# \text{training examples} \)
\( p\)
\( \, p_{\theta} \)

Merger, Goldt, 2025 arXiv.2505.24769.
Good performance: at least \( \# \text{training examples} \asymp d\)
\(\text{DKL}\left(p_{\theta}|p\right) \)
Predict performance of diffusion models as a function \( \# \text{training examples} \)
\( p\)
\( \, p_{\theta} \)

\( \, p^{(k>2)}_{\theta} \)
Good performance: at least \( \# \text{training examples} \asymp d\)
Merger, Goldt, 2025 arXiv.2505.24769.
Predict performance of diffusion models as a function \( \# \text{training examples} \)
What if I don't have that many data, \( N \ll d \)?
\(\rightarrow \) Early stopping
\(\rightarrow \) regularization

Merger, Goldt, 2025 arXiv.2505.24769.
Understanding Generative models via Interactions
Two questions:
- What can we learn from \(p_{\theta} \) about data?
- How close are \( p, \, p_{\theta} \) ?
\( p\)
\( \, p_{\theta} \)
Using interactions, we can
- map the inferred statistics to an interpretable form central to physics
- predict the performance of generative models at low levels of interaction complexity
Thanks to
- Sebastian Goldt
- Alexandre Rene
- Kirsten Fischer
- Peter Bouss
- Sandra Nestler
- David Dahmen
- Carsten Honerkamp
- Moritz Helias



Invertible neural networks learn data distributions
learned data distribution
\( p_{\theta} (x) =p_Z \left( f_{\theta}(x) \right) \big| \det J_{f_{\theta}} (x) \big| \)
loss function
\( \mathcal{L}\left(\mathcal{D}\right) =-\sum_{x \in \mathcal{D}} \ln p_{\theta}(x) \)
NICE (Dinh et. al., 2015 ), RealNVP (Dinh et. al., 2017), GLOW (Kingma et. al. , 2018)
Claudia Merger
10.07.2025
Beyond the test loss?
Kullbeck-Leibler divergence

\( \text{DKL} (\rho_N| \rho) \sim \ln \frac{\left| \Sigma \right|}{\left| \Sigma_0 + c \text{Id} \right|} \)
\( \rightarrow \) distributions align when relevant directions in \(\Sigma \) are also present in \( \Sigma_0\)
\( N \asymp d\)
Data drawn from
\(\rho = \mathcal{N} \left( \mu,\Sigma \right) \)
\( \mu_0,\Sigma_0 = \) empirical mean and covariance of training data \( \neq \mu, \Sigma \)
How large should \(N\) be?
\(\rightarrow\) Fully tractable model: Linear diffusion models


Linear models learn:
\(\rho_{N} \approx \mathcal{N} \left( \mu_0,\Sigma_0 +c\text{Id}\right) \)
\(L= \sum_t \bigg\langle||\epsilon -\epsilon_{\theta} \left(x_t,t\right) ||^2 \bigg\rangle_{\epsilon, x_0} \)
\(\epsilon_{\theta} \left(x_t,t\right)=W_t(x_t+b_t) \)