Generalization Dynamics of Linear Diffusion Models
Claudia Merger, Sebastian Goldt
07.06.2025
What are diffusion models?
Task: Given some data \( \mathcal{D} \) from an unknown distribution \( p \)
Generate \( x \sim p \)

"happy data scientist"
"summer in Trieste"
"intelligent bamboo"





Sohl-Dickstein, et al., ‘Deep Unsupervised Learning Using Nonequilibrium Thermodynamics’.
Ho, et al. ‘Denoising Diffusion Probabilistic Models’, 2020
How do we learn to sample?

\( t=0\)
\( t=T\)
Sohl-Dickstein, et al., ‘Deep Unsupervised Learning Using Nonequilibrium Thermodynamics’.
Ho, et al. ‘Denoising Diffusion Probabilistic Models’, 2020
Diffusion models reverse the noising process.
train model \( \epsilon_{\theta} \) to predict noise:
\(L= \sum_t \bigg\langle||\epsilon -\epsilon_{\theta} \left(x_t,t\right) ||^2 \bigg\rangle_{\epsilon, x_0} \)
How do we learn to sample?
Sohl-Dickstein, et al., ‘Deep Unsupervised Learning Using Nonequilibrium Thermodynamics’.
Ho, et al. ‘Denoising Diffusion Probabilistic Models’, 2020
What is Diffusion?
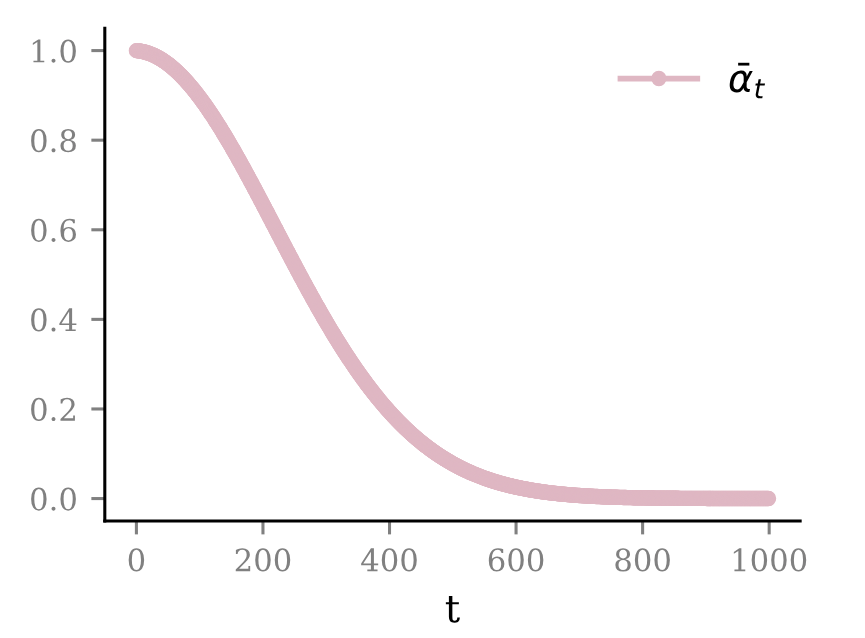
noise schedule:
\( \beta_t = \frac{10^{-2} -10^{-4}}{T} t + 10^{-4} \)
\( \bar{\alpha}_t = \prod_{s\leq t} (1-\beta_s) \)
Diffusion models reverse the noising process.
sample from model:
\( u_{t-1} = \frac{1}{\sqrt{1-\beta_t}} \left( u_t -\frac{\beta_t}{\sqrt{1-\bar{\alpha}_t}} \epsilon_{\theta} (u_t,t) \right) +\sigma_t \epsilon_t \)
\(\epsilon_t \sim \mathcal{N}\left(0,\text{Id}\right) \)
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. ‘Denoising Diffusion Probabilistic Models’, 2020
"Generalization"
"Memorization"
Two solutions:



Kadkhodaie, Z. et. al. Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representations’. April 2024.
\(\rightarrow\) Empirically, generalization occurs when \(N\) is "large enough"
= Global minimum of the training loss
see e.g. Ambrogioni 2023.
How do we prevent memorization?
\(\rightarrow\) Approaches in the literature
- Dynamic regularization (sampling)
- Early stopping (training)/implicit bias

sampling
Biroli et al. 2024. Nature Communications,
George et. al. 2025. arXiv.2502.04339.
George et al. 2025 arXiv.2502.00336.
Bonnaire et. al. 2025. arXiv.2505.17638.
Biroli, Mezard, 2023, Journal of Statistical Mechanics, Theory and Experiment
Merger, Goldt, 2025 arXiv.2505.24769.
Diffusion models\(^1\) first memorize, then generalize\(^2\)
[1] Ho, Jonathan, Ajay Jain, and Pieter Abbeel. ‘Denoising Diffusion Probabilistic Models’, 2020
reverse iterative noising process by predicting noise \( \epsilon_t = \epsilon_{\theta}(x_t,t) \) at each step
[2] Kadkhodaie, Z. et. al. Generalization in Diffusion Models Arises from Geometry-Adaptive Harmonic Representations’. April 2024.
\(\rightarrow\) Empirically, generalization occurs when \(N\) is "large enough"
Data drawn from
\(\rho = \mathcal{N} \left( \mu,\Sigma \right) \)
\( \mu_0,\Sigma_0 = \) empirical mean and covariance of training data \( \neq \mu, \Sigma \)
How large should \(N\) be?
\(\rightarrow\) Fully tractable model: Linear diffusion models


Linear models learn:
\(\rho_{N} \approx \mathcal{N} \left( \mu_0,\Sigma_0 +c\text{Id}\right) \)
\(L= \sum_t \bigg\langle||\epsilon -\epsilon_{\theta} \left(x_t,t\right) ||^2 \bigg\rangle_{\epsilon, x_0} \)
\(\epsilon_{\theta} \left(x_t,t\right)=W_t(x_t+b_t) \)
How large should \(N\) be?
test loss \( \sim \text{Tr}\frac{ \Sigma -\Sigma_0}{\left(\Sigma_0 + c\text{Id} \right)^2} +const. \)
find \(d-N\) directions \(\nu\) where \( \Sigma_0 e_{\nu} = 0\)
\(\Rightarrow \) test loss \( \gtrsim \sum_{\nu} \frac{ \Sigma_{\nu,\nu}}{c^2} \)

How large should \(N\) be?
test loss \( \sim \text{Tr}\frac{ \Sigma -\Sigma_0}{\left(\Sigma_0 + c\text{Id} \right)^2} +const. \)
find \(d-N\) directions \(\nu\) where \( \Sigma_0 e_{\nu} = 0\)
\(\Rightarrow \) test loss \( \gtrsim \sum_{\nu} \frac{ \Sigma_{\nu,\nu}}{c^2} \)

"fill up" all relevant directions in \( \Sigma_0 \)
Beyond the test loss?
Kullbeck-Leibler divergence

\( \text{DKL} (\rho_N| \rho) \sim \ln \frac{\left| \Sigma \right|}{\left| \Sigma_0 + c \text{Id} \right|} \)
\( \rightarrow \) distributions align when relevant directions in \(\Sigma \) are also present in \( \Sigma_0\)
\( N \asymp d\)
Data drawn from
\(\rho = \mathcal{N} \left( \mu,\Sigma \right) \)
\( \mu_0,\Sigma_0 = \) empirical mean and covariance of training data \( \neq \mu, \Sigma \)
How large should \(N\) be?
\(\rightarrow\) Fully tractable model: Linear diffusion models
Linear models learn:
\(\rho_{N} \approx \mathcal{N} \left( \mu_0,\Sigma_0 +c\text{Id}\right) \)
naive solution: \( ||\Sigma - \Sigma_0||_F^2/||\Sigma||_F^2\rightarrow \frac{d_{\text{effective}}}{N}\)
\(d_{\text{eff}}=\frac{\left(\sum_{\nu} \lambda_{\nu}\right)^2}{N \sum_{\nu} \lambda_{\nu}^2} \)participation ratio
Images have a highly structured covariance

Not enough to span the space of faces!
naive solution: \( \frac{||\Sigma - \Sigma_0||_F^2}{||\Sigma||_F^2}\rightarrow \frac{d_{\text{effective}}}{N}\)
CelebA: \( d_{\text{effective}}\approx 7 \)
MNIST: \( d_{\text{effective}}\approx 25 \)
Take home message
Assumption: Linear models & Gaussian Data
\(\rightarrow \) "Best case" analysis: no model misspecification
How many data do I need to get a "good" linear model? \(\rightarrow \) At least \( N \asymp d \)
What if I don't have that many data, \( N \ll d \)?
\(\rightarrow \) Early stopping
\(\rightarrow \) regularization
