
@MichaKutz

Dare to Deploy Anytime
Managing Risk in a µService World
Risk
What could possibly go wrong?
Error in code
Error in deployment
Performance issues
Connection issues (e.g. DB)
Security issues (e.g. in dependencies)
Test Automation
















Class/Unit Tests



Integration Tests



Class/Unit + Integration
Tests
Risk vs Effort
Service Tests



Consumer Driven
Contract Test




Service Test
+ Contract Test
Risk vs Effort
System Test



System Test
Risk vs Effort

End-to-End Tests



End-to-End Tests
Risk vs Effort

Continuous Delivery &
Deployment







Exploratory Testing



–Martin Fowler

I would consider it a red flag if a team isn't doing exploratory testing at all - even if their automated testing was excellent.
Even the best automated testing is inherently scripted testing - and that alone is not good enough.
November 18th 2019
–Elisabeth Hendrickson
@testobsessed

to push even harder
look past what you expect
as soon as you think of a test
interesting things to vary and interesting ways in which to vary them
Simultaneously designing and executing tests to learn about the system, using your insights from the last experiment to inform the next.
What?
How?
Charter template from "Explore It!"
by Elisabeth Hendrickson
What kind of information are you hoping to find?
security
performance
reliability
capability
usability
consistency of design
violations of a standard
surprises
What resources will you bring with you?
a tool
a data set
a technique
a configuration
an interdependent feature
Where are you exploring?
a feature
a requirement
a module
Explore <target>
with <resources>
to discover <information>
How long is this supposed to take?
often implicit
How?
Charter Template from "Tips for Writing Better Charters for Exploratory Testing Sessions"
by
What could go wrong?
functionality is wrong
usability is bad
not accessible
inconsistency
What am I testing?
a feature
a requirement
a module
My mission is to test <risk>
in the context of <coverage>
within <timeframe>
Good Charters,
Bad Charters
Experiment with invalid values when updating customer addresses.
Find ways that a valid order modification might fail.
My mission is to test SQL vulnerabilities
in the context of the search form.
Explore the registration form
with common XSS injection strings
to discover XSS attack vulnerabilities
Too broad
you will never be finished
Too narrow
actually a test case
Explore the address form
with the name "Søren Anderson"
to discover if scandinavial letters are handled correctly
Explore every input field in the shop
with every security tool you can find
to discover security issues
Explore the behavior of the basket button
with various interaction types and speeds
to discover unintended side effects

unexpected data transfer
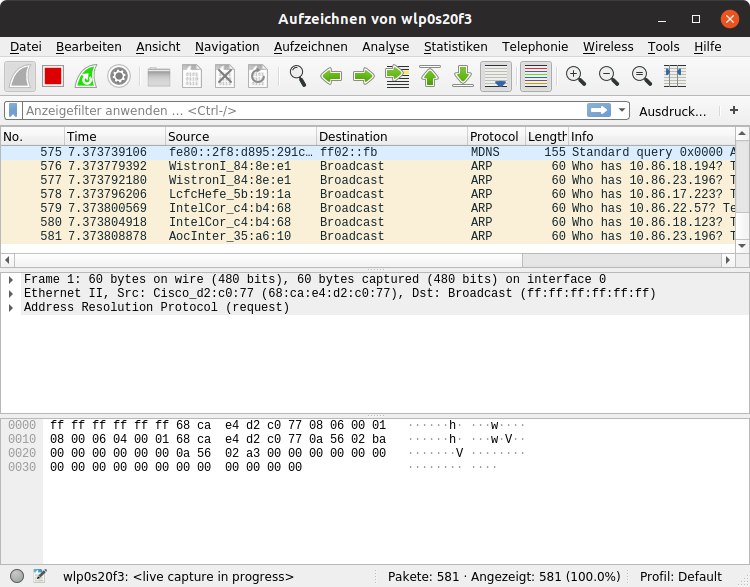
subtle UI changes
$> psql
$> watch ls
unexpected filesystem or database activity
unexpected system load
Look past what you expect or hope to find
Notes to Take



My mission is to explore the checkout process
for side effects caused by parallel activity in a different tab.
My mission is to explore the checkout process
for side effects caused by browser navigation.

setup steps
things to be documented
things to be automated
open questions
possible new charters
found bugs
actual time for testing

confidence level
Sprint
Planning
Review/
Retro
Coding
1st story done 🎉
2nd story done 🎉
last story done 🎉
Daylies
Backlog Refinement


Continuous Exploration
Observability


You aren't testing just code anymore. You are testing complex systems made up of users, code, environment, infrastructure, and a point in time. These systems have unpredictable interactions, a lack of predictable ordering, and emergent properties that defy your ability to deterministically test.–Charity Majors
techbeacon.com/app-dev-testing/test-production-yes-you-can-you-should

In software, observability is the ability to ask new questions of the health of your running services without deploying new instrumentation.
–Shelby Spees
honeycomb.io/blog/observability-101-terminology-and-concepts
(…) unlike “monitoring” which is known failure centric, “observability” doesn’t necessarily have to be closely tied to an outage or a user complaint. It can be used as a way to better understand system performance and behavior, even during the what can be perceived as “normal” operation of a system.
–Cindy Sridharan
copyconstruct.medium.com/monitoring-and-observability-8417d1952e1c







Site Reliability Engineering (SRE) Four Golden Signals/Metrics
Traffic
Errors
Latency
Saturation




Site Reliability Engineering (SRE) SLI, SLO, SLA
Service Level Indicator
SLI: time to serve request
internal SLO:
serve 98% in less then 6ms





public SLO:
serve 95% in less then 6ms
Service Level Objective (SLO)
Service Level Agreement
= Consequences for breaking SLO
SLA: Team is on call and will be woken up by alert



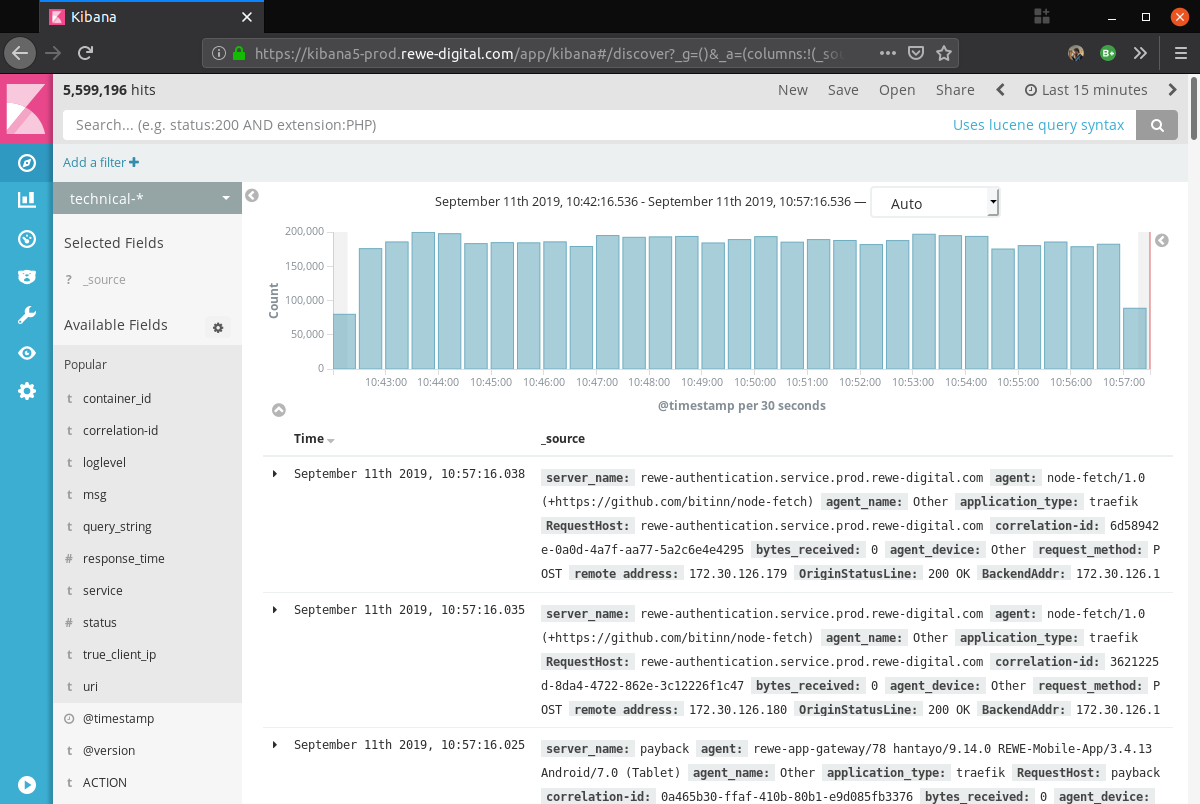
{
"@timestamp": "2020-10-29T08:05:53.022Z",
"loglevel": "WARN",
"msg": "What happened explained to human",
"message_code": "SOME_MSG_CODE_TO_FILTER_FOR",
"service": "my-service",
"service_version": "v4711",
"container_image": "docker-registry.rewe-digital.com/my-service:v4711",
"host": "docker-1",
"user-agent": "Mozilla/5.0 …",
"customer_uuid": "3b8afe40-6fd5-4996-8bf0-0735f1d41244",
"session_id": "e9f78f3e-9142-4d7a-b26d-130ec918f88d",
"correlation-id": "e7e28df8-307e-404b-8246-0ffe2f281b09",
…
}Conclusion/Further Reading
Solid Test Automation
+ Continuous Delivery
+ Exploratory Testing
+ Observability
= Continuous Happiness :)








