streamin' aint easy
Building Real-Time Streaming Architectures Across Distributed and Heterogeneous Microservices with Kafka
Nathan Murthy
Staff Software Engineer, Tesla

@natemurthy



Control Service
Telemetry Service
Asset Service
MicroServ Energy API

About Me
- 8.5 years of software engineering experience
- Undergrad at UC Berkeley
- Written applications for start-ups, big companies, R&D, and academia
- Banatao Institute @ CITRIS
- Fujitsu Labs
- Wireless Glue Networks
- SolarCity
- Tesla
- Passionate about cleantech (and clean APIs)

Outline
-
Protocol potpourri
-
From HTTP to {WebSockets,AMQP,gRPC,Kafka,...}
-
From HTTP to {WebSockets,AMQP,gRPC,Kafka,...}
-
Kafka to the rescue (well, sort of)
-
Enabling streaming data science
- Case Study: Hornsdale Power Reserve
Protocol Potpourri
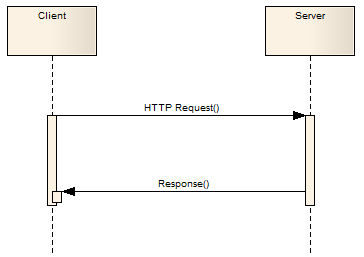
HTTP/1.1
Limitations of HTTP/1.1
- Client-server constraint (REST)
- One-to-one communication model
- Synchronous request-response
- CRUD semantics (POST, GET, PUT, DELETE)
- Long-polling can be expensive
- Request-response payload size limits

Composability Patterns
HTTP/1.1
Streaming HTTP
WebSockets
JMS
MQTT
AMQP
Kinesis
Cloud Pub/Sub
Redis
Kafka
gRPC
NATS
...
Requirements
-
Decouple readers and writers (pub/sub)
-
Asynchronous communication
-
Define our own semantics and domain model
-
High performance: process large volumes of data with low latency and high throughput
-
High availability, horizontal scalability
-
Persistent message queues
- Avoid cloud provider/vendor lock-in


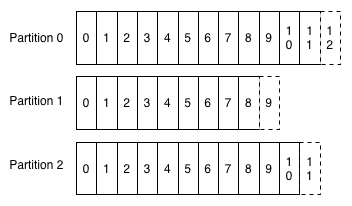
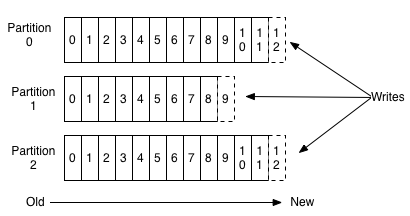
Topic A
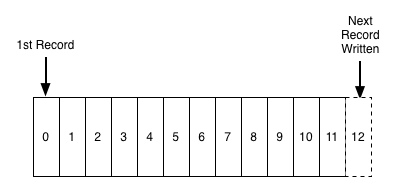
Commit Log
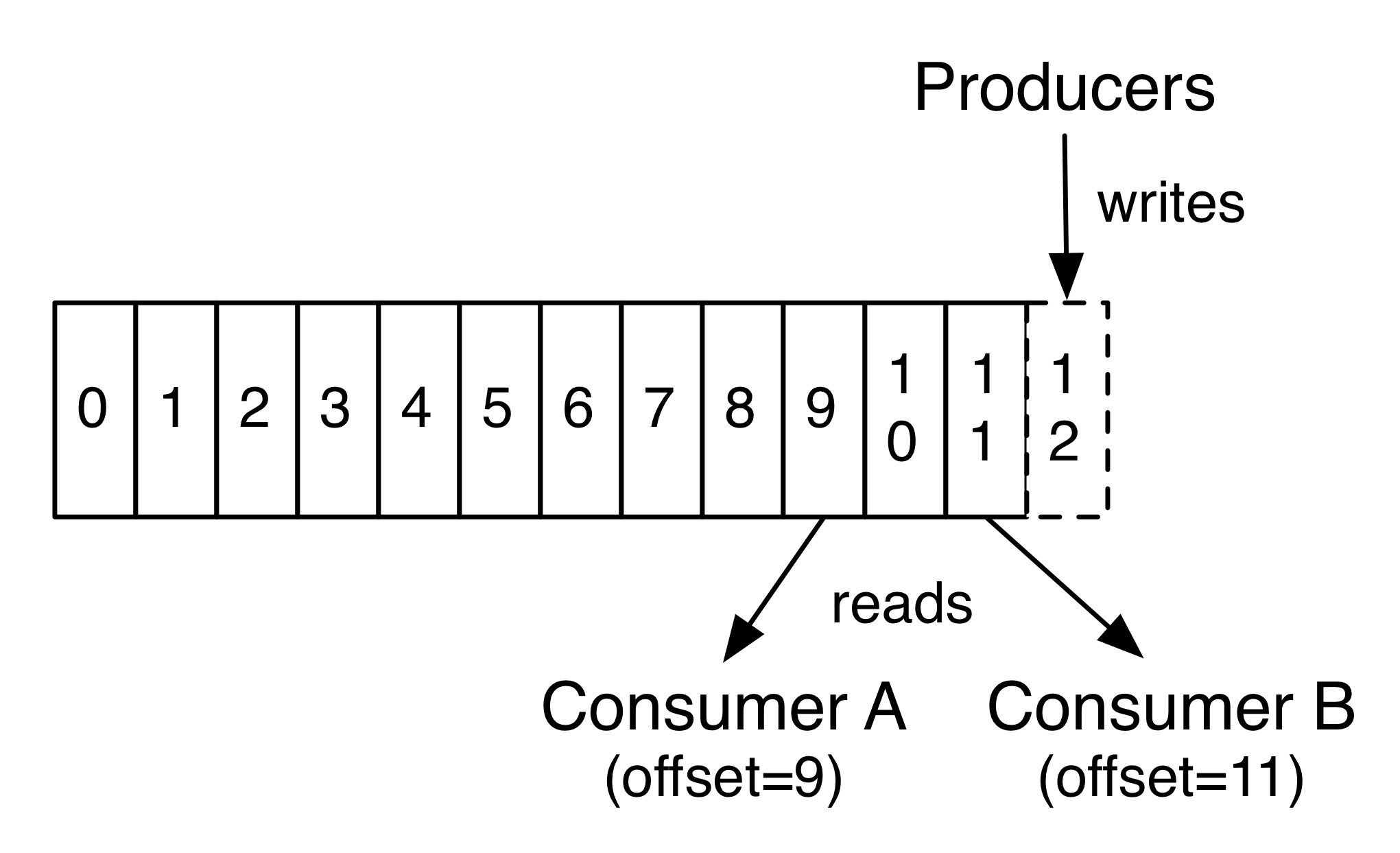
Distributed Commit Log
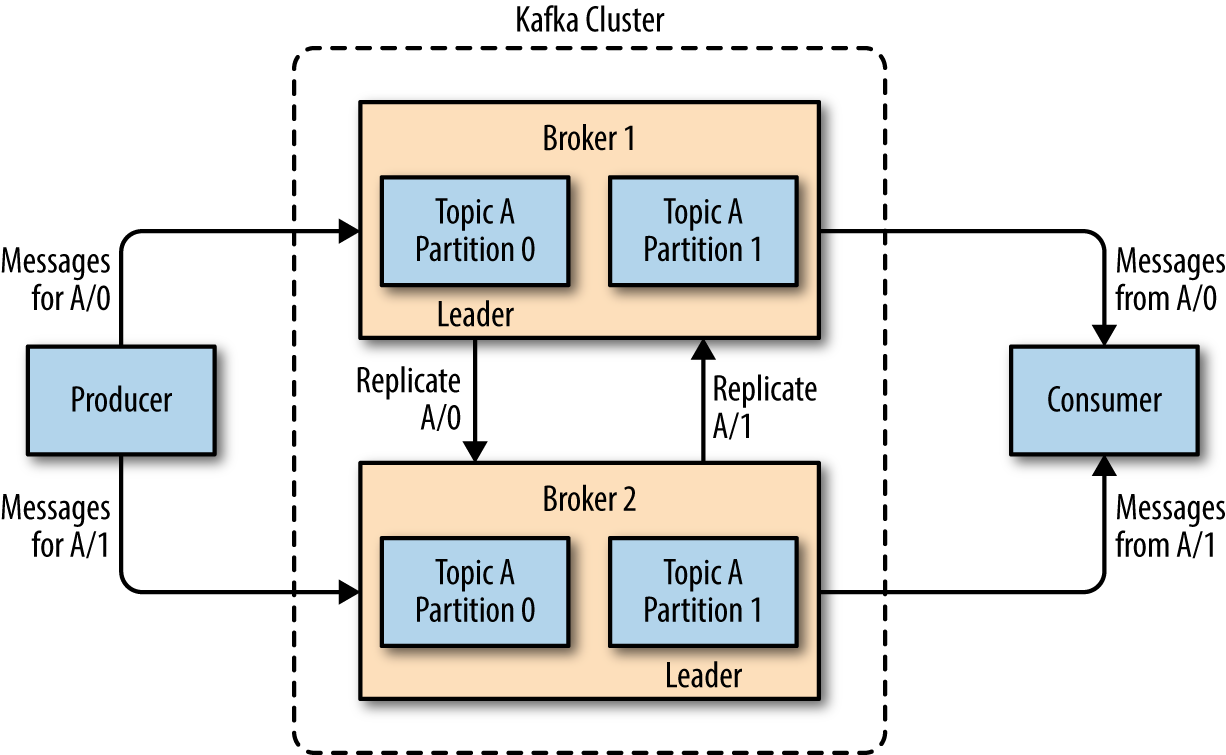
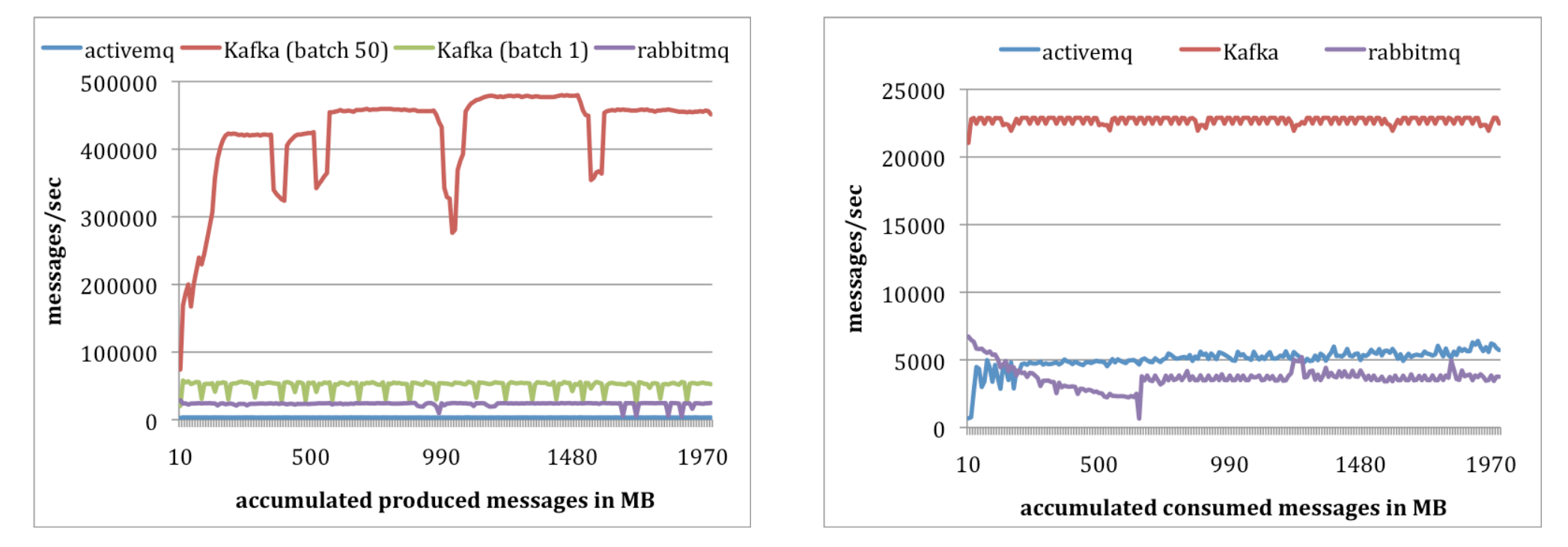
Kafka FTW!
- Not all Kafka client libraries implemented to spec
- No web browser support
- Large operational overhead
- Producing is easy, consuming can be tricky
- Need to interoperate with existing systems
(well, sort of)
Enabling Streaming Data Science
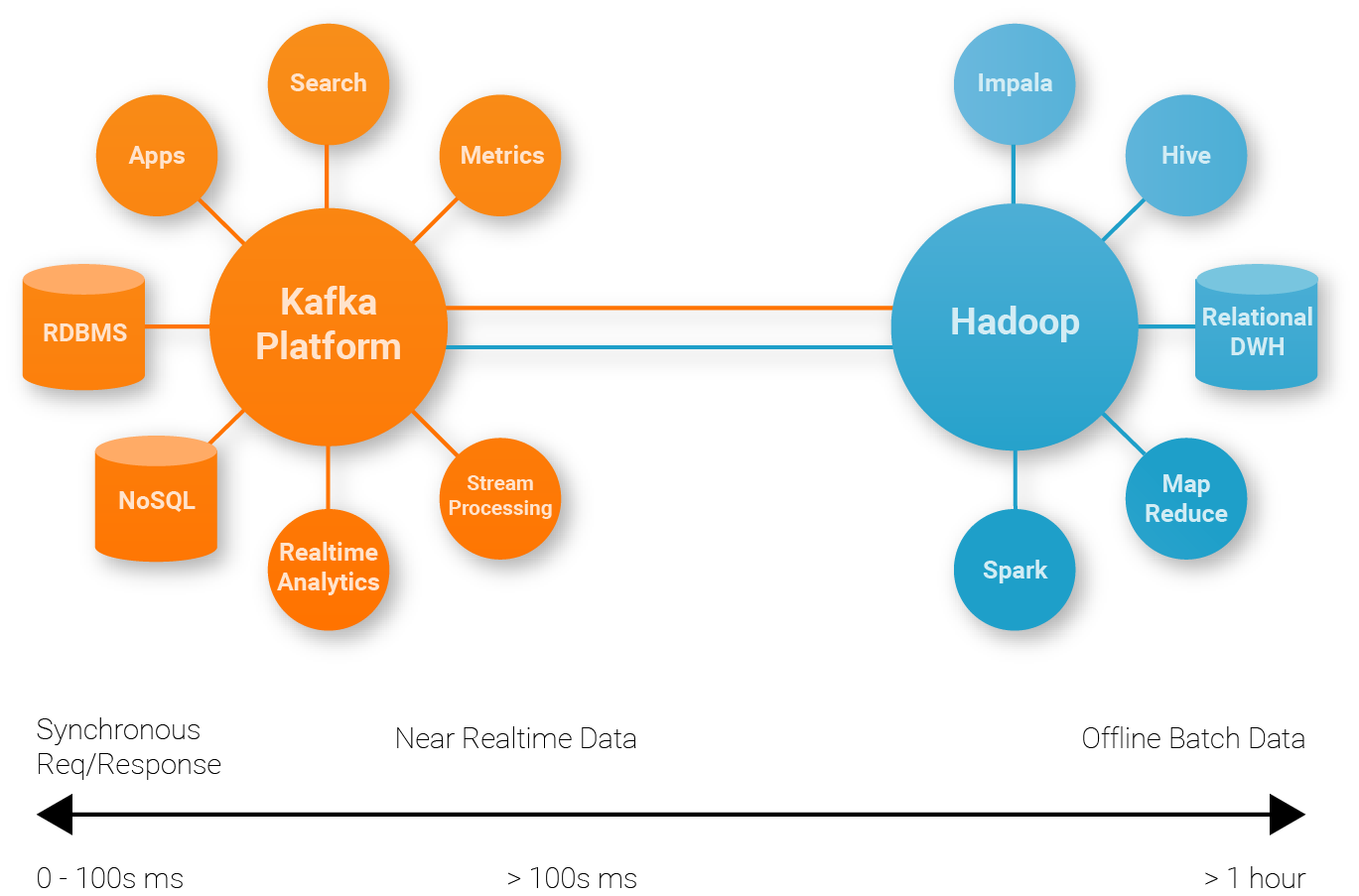
Kafka Ecosystem
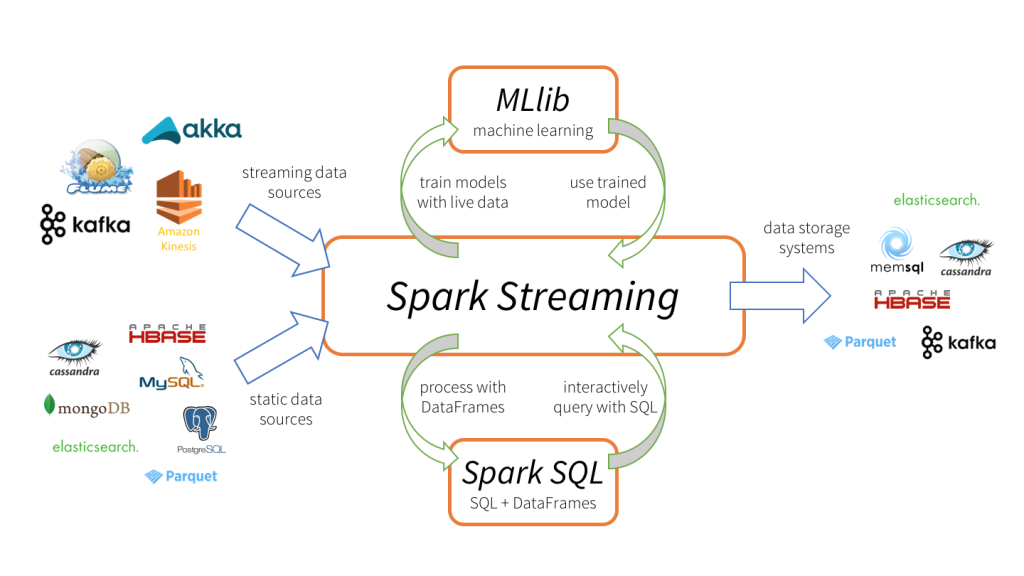
Kafka + Spark

Conclusion
-
There are a lot of streaming technologies out there, find what fits your needs best
-
Apache Kafka is an effective pub/sub technology choice for critical, high-throughput systems
- Recommend data scientists to add Kafka to their developer toolkit for real-time insights
Thank You!
@natemurthy
The Business Case for Streaming
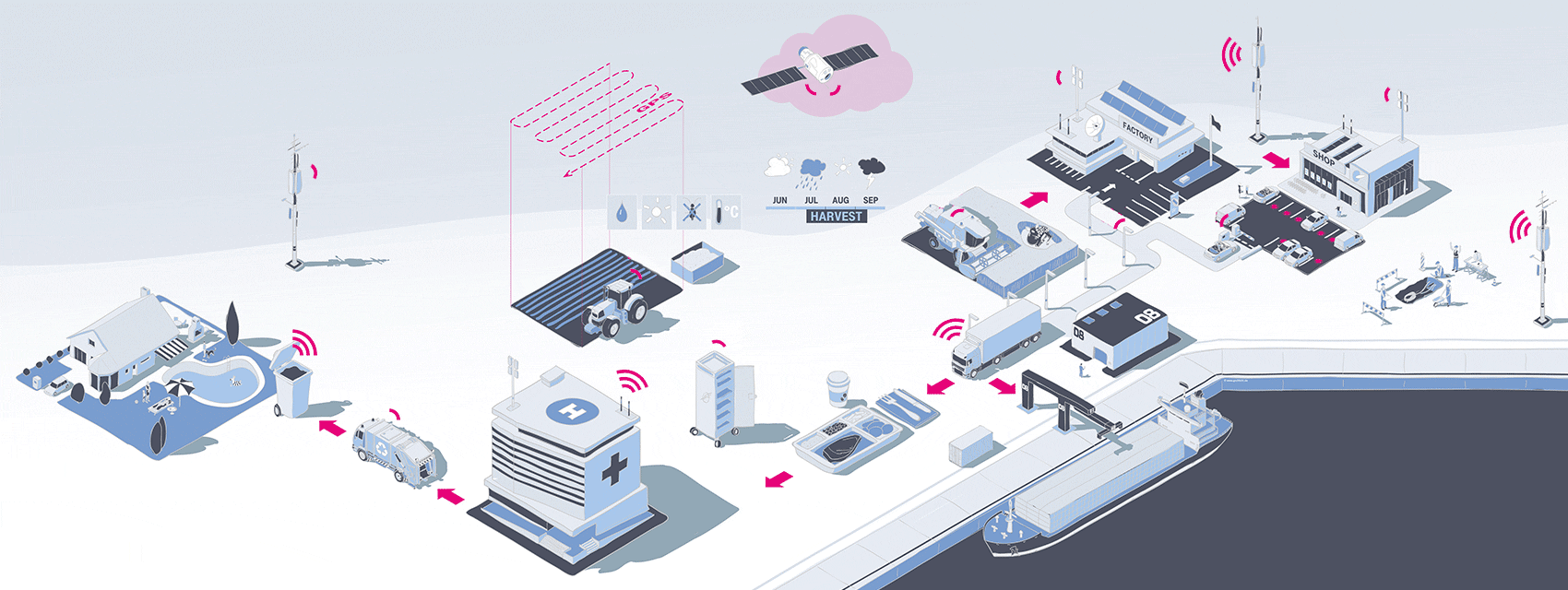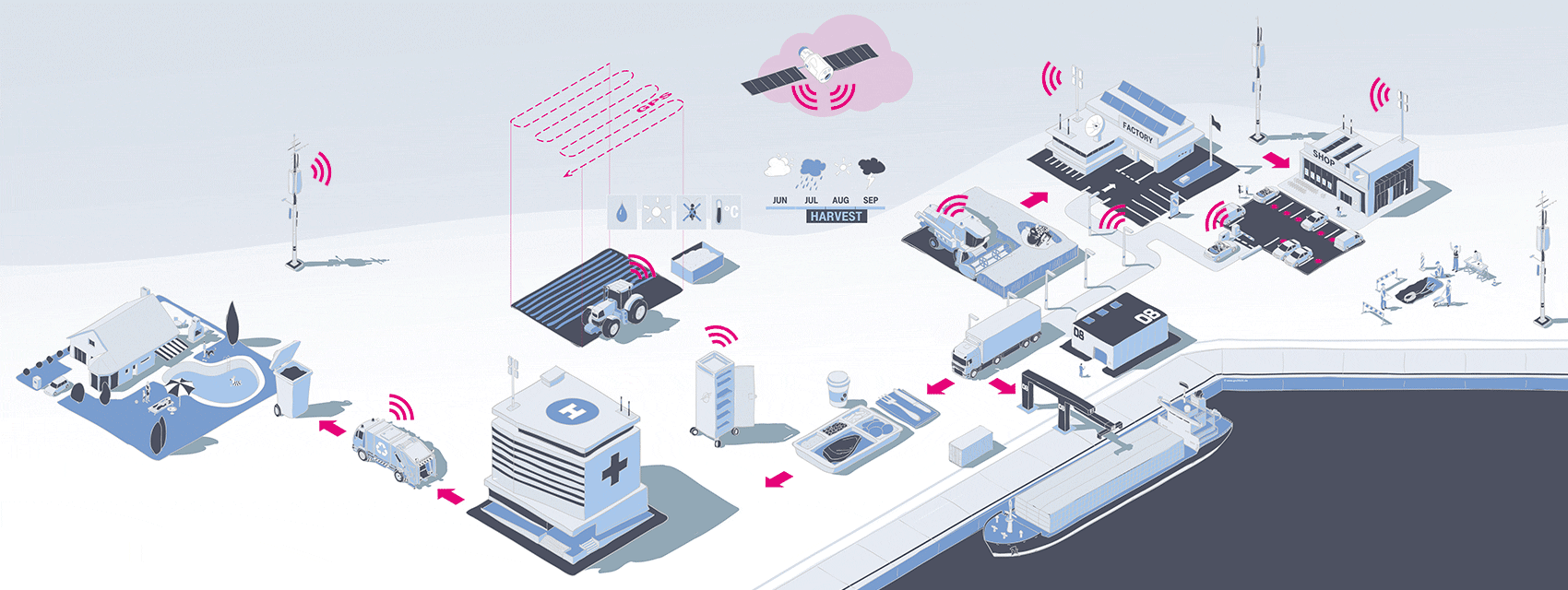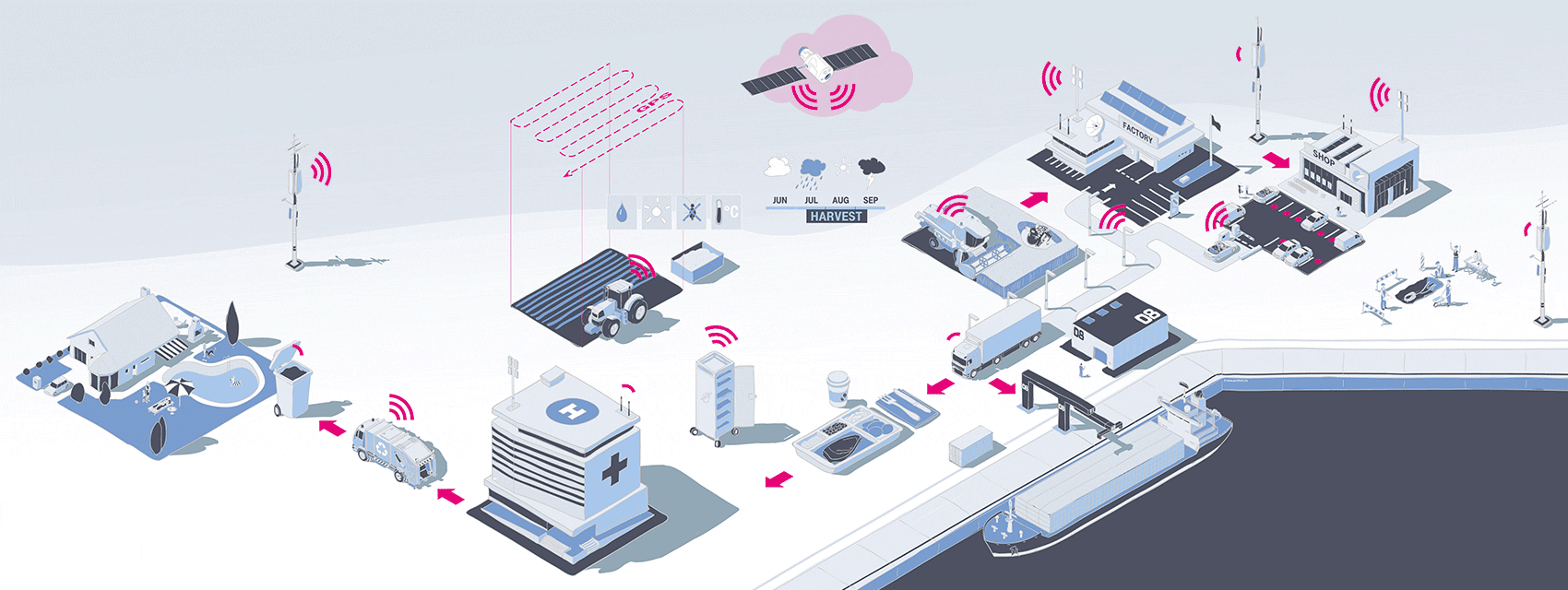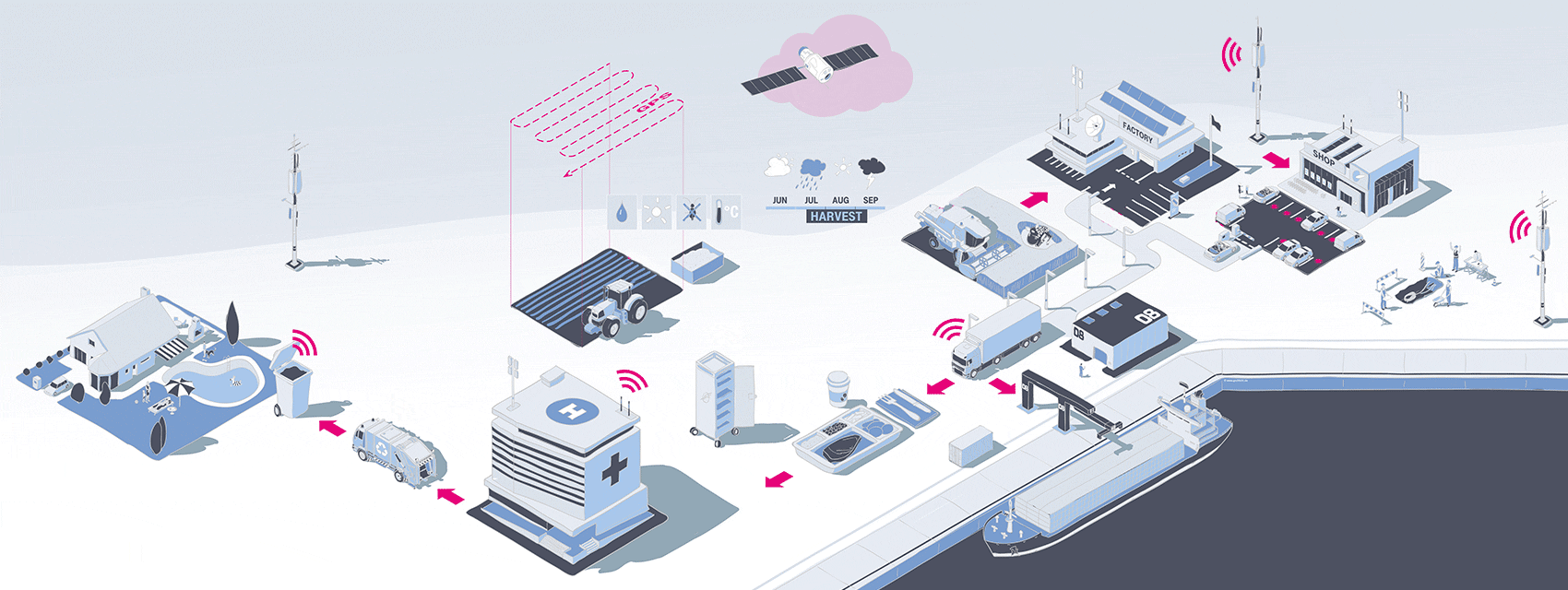
Connect all the things!
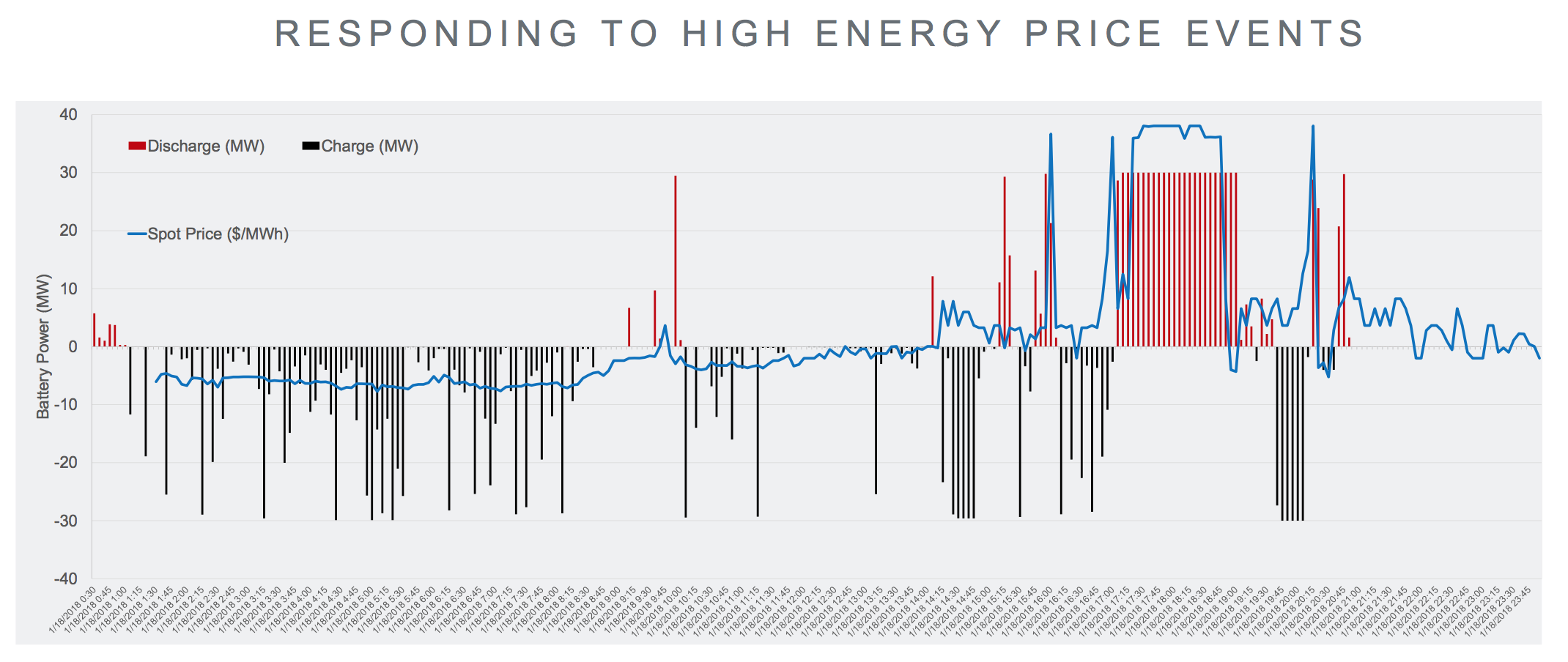

Model Predictive Control (MPC)