Sieci Neuronowe RNN i LSTM
w Szeregach Czasowych
Nowoczesne podejście do analizy i prognozowania danych czasowych
Plan Prezentacji
- Wprowadzenie do szeregów czasowych
- Podstawy sieci neuronowych
- Rekurencyjne sieci neuronowe (RNN)
- Problem zanikającego gradientu
- Sieci LSTM - architektura i mechanizmy
- Implementacja w Pythonie (Keras/TensorFlow)
- Zastosowania praktyczne
- Porównanie z metodami klasycznymi
1. Szeregi Czasowe - Podstawy
Czym jest szereg czasowy?
Szereg czasowy to sekwencja obserwacji uporządkowanych chronologicznie, mierzonych w regularnych odstępach czasu.
Charakterystyczne cechy:
- Trend - długoterminowa tendencja wzrostowa lub spadkowa
- Sezonowość - regularne wzorce powtarzające się w określonych okresach
- Cykliczność - fluktuacje o nieregularnej długości
- Losowość - szum, nieprzewidywalne wahania
Ograniczenia Klasycznych Metod
Tradycyjne modele (ARIMA, ES):
- Wymagają stacjonarności danych
- Trudności z nieliniowymi zależnościami
- Ograniczona zdolność do modelowania złożonych wzorców
- Problemy z długoterminowymi zależnościami
- Wymaga ręcznego doboru parametrów
Dlaczego sieci neuronowe?
- Automatyczne uczenie się wzorców
- Radzą sobie z nieliniowościami
- Mogą przetwarzać dane wielowymiarowe
- Elastyczność w modelowaniu
- Zapamiętywanie długoterminowych zależności (LSTM)
2. Podstawy Sieci Neuronowych
Neuron - podstawowa jednostka
Sztuczny neuron:
Inspirowany biologicznym neuronem, przetwarza sygnały wejściowe i produkuje wyjście.
Działanie neuronu:
- Przyjmuje sygnały wejściowe (x₁, x₂, ..., xₙ)
- Mnoży każde wejście przez wagę (w₁, w₂, ..., wₙ)
- Sumuje ważone wejścia + bias (b)
- Stosuje funkcję aktywacji
- Produkuje wyjście
Neuron - Wzór Matematyczny
Matematyczny opis działania neuronu:
gdzie:
- f - funkcja aktywacji (sigmoid, tanh, ReLU)
- wi - wagi połączeń
- xi - sygnały wejściowe
- b - bias (przesunięcie)
Sieci Feedforward - Ograniczenia dla Szeregów
Klasyczna sieć feedforward (MLP):
- Warstwa wejściowa → Warstwy ukryte → Warstwa wyjściowa
- Informacja przepływa tylko w jednym kierunku
- Każda warstwa przetwarza dane niezależnie
Problem z szeregami czasowymi:
- Brak pamięci - sieć nie pamięta poprzednich stanów
- Stały rozmiar wejścia - trzeba z góry określić okno czasowe
- Brak kontekstu sekwencyjnego - nie rozumie kolejności
- Traktuje każdy punkt czasowy niezależnie
Przykład:
Jeśli chcemy przewidzieć cenę akcji, klasyczna sieć przyjmie np. ostatnie 10 cen jako wejście, ale nie rozumie, że są one uporządkowane chronologicznie.
3. Rekurencyjne Sieci Neuronowe (RNN)
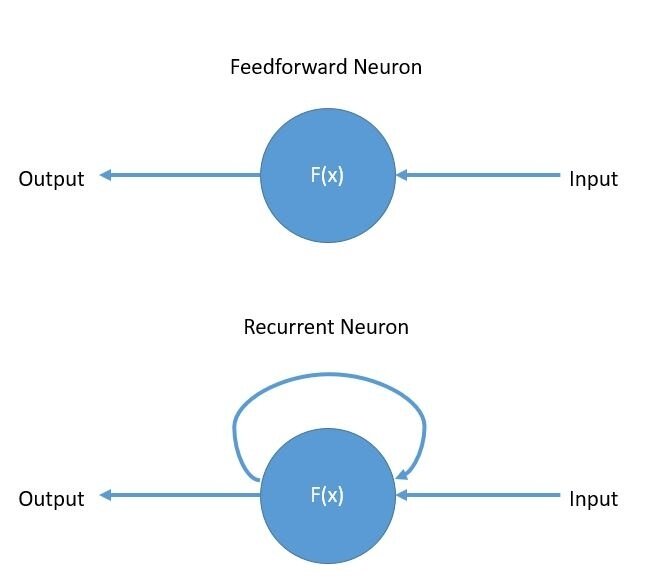
Rekurencyjna Sieć Neuronowa (Recurrent Neural Network) to rodzaj sieci, która ma połączenia zwrotne, pozwalające na przetwarzanie sekwencji danych.
Kluczowa różnica:
RNN ma pamięć - zapamiętuje poprzednie stany i wykorzystuje je do przetwarzania bieżącego wejścia.
Mechanizm działania:
- W każdym kroku czasowym t, RNN otrzymuje:
- Bieżące wejście x(t)
- Stan ukryty z poprzedniego kroku h(t-1)
- Produkuje:
- Wyjście y(t)
- Nowy stan ukryty h(t)
3. Rekurencyjne Sieci Neuronowe (RNN)
3. Rekurencyjne Sieci Neuronowe (RNN)
RNN - Wzory Matematyczne
Stan ukryty w kroku t:
Wyjście w kroku t:
y(t)=Wy⋅h(t)+byy(t) = W_y \cdot h(t) + b_yy(t)=Wy⋅h(t)+by
gdzie:
- Wh, Wx, Wy - macierze wag
- b, by - biasy
- tanh - funkcja tangens hiperboliczny
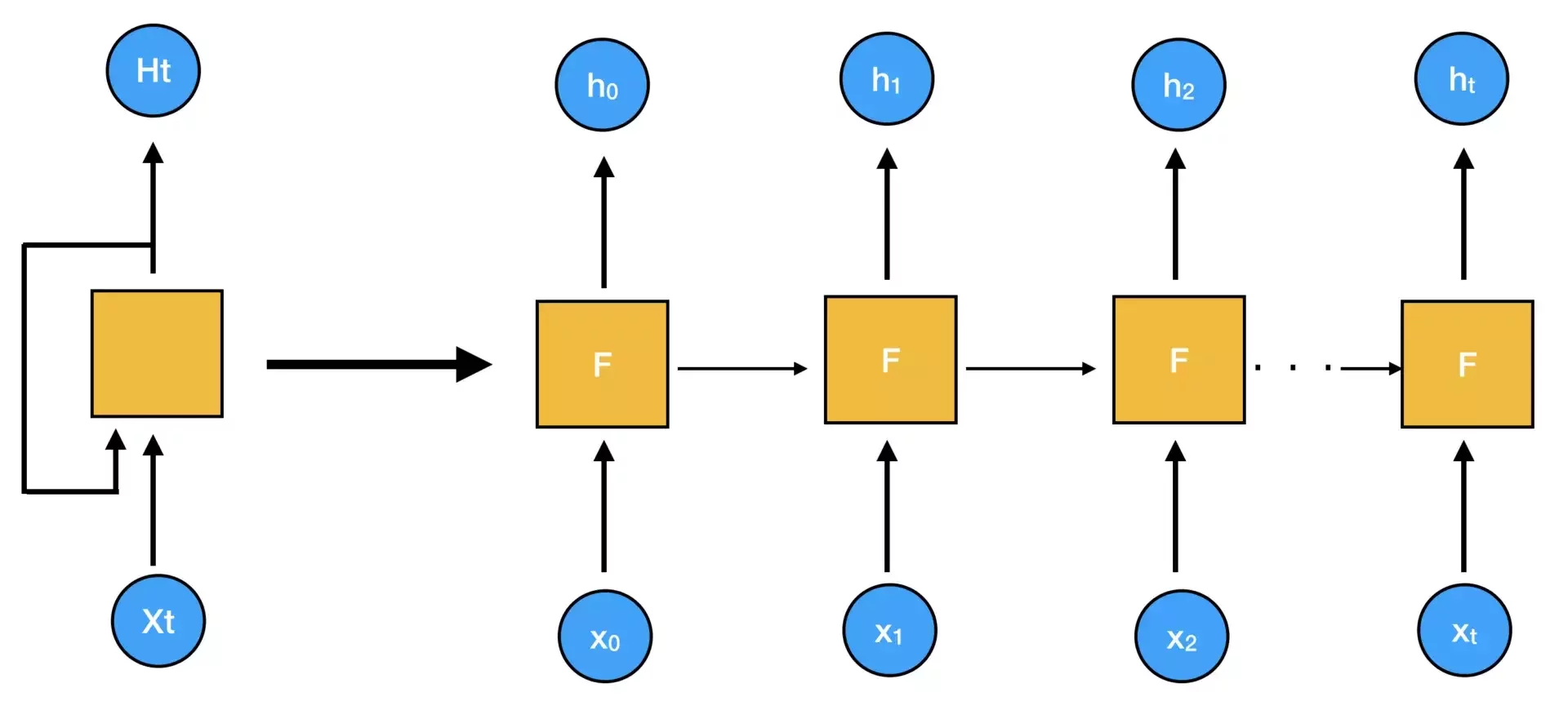
RNN - Rozwinięcie w Czasie (Unrolling)
Wizualizacja RNN jako sekwencja:
Tę samą komórkę RNN można przedstawić jako sekwencję połączonych neuronów w czasie:
Krok t=1: x(1) → [RNN] → y(1), h(1)
Krok t=2: x(2), h(1) → [RNN] → y(2), h(2)
Krok t=3: x(3), h(2) → [RNN] → y(3), h(3)
...
Kluczowe obserwacje:
- Te same wagi W są używane w każdym kroku
- Stan ukryty h(t) przenosi informację z przeszłości
- Sieć może przetwarzać sekwencje dowolnej długości
- Wyjście y(t) zależy od całej historii x(1)...x(t)
4. Problem Zanikającego Gradientu
Główne ograniczenie klasycznych RNN
Problem:
Podczas uczenia sieci przez propagację wsteczną (backpropagation), gradienty są mnożone przez siebie w każdym kroku czasowym.
Konsekwencje:
-
Zanikający gradient (vanishing):
- Gdy gradienty < 1, ich iloczyn → 0
- Sieć "zapomina" o dawnych stanach
- Nie może uczyć się długoterminowych zależności
-
Eksplodujący gradient (exploding):
- Gdy gradienty > 1, ich iloczyn → ∞
- Niestabilne uczenie, duże oscylacje wag
Problem Zanikającego Gradientu - Przykład
Praktyczny przykład:
Jeśli chcemy przewidzieć cenę akcji za tydzień na podstawie cen z ostatnich 100 dni, klasyczny RNN będzie miał problem z zapamiętaniem tego, co działo się 90-100 dni temu.
Dlaczego to problem?
- Informacje z odległej przeszłości są istotne dla przewidywania
- RNN nie może efektywnie "zapamiętać" starszych danych
- Uczenie sieci staje się nieefektywne
- Model bazuje głównie na ostatnich obserwacjach
Rozwiązanie:
Sieci LSTM (Long Short-Term Memory) zostały zaprojektowane specjalnie do rozwiązania tego problemu!
5. LSTM - Long Short-Term Memory
Rozwiązanie problemu długoterminowej pamięci
LSTM (Long Short-Term Memory) to specjalny typ RNN zaprojektowany do zapamiętywania informacji przez długi czas.
Wynaleziono: 1997, Hochreiter i Schmidhuber
Kluczowa innowacja:
LSTM wprowadza stan komórki (cell state) - "pas transmisyjny" dla informacji, który przepływa przez całą sekwencję z minimalnymi zmianami.
LSTM - Główne Zalety
Co zyskujemy dzięki LSTM?
- Może uczyć się zależności odległych o setki kroków czasowych
- Rozwiązuje problem zanikającego gradientu
- Selektywnie zapamiętuje i zapomina informacje
- Lepsze wyniki niż klasyczny RNN
- Stabilne uczenie nawet na długich sekwencjach
Kiedy używać LSTM?
- Długie sekwencje czasowe
- Złożone zależności między obserwacjami
- Gdy kontekst z przeszłości jest istotny
- Prognozowanie wielokrokowe
Architektura Komórki LSTM
Komórka LSTM składa się z 4 głównych elementów:
1. Stan komórki (Cell State) - C(t)
- "Pas transmisyjny" informacji
- Przepływa przez całą sekwencję
- Może być modyfikowany przez bramki
2. Stan ukryty (Hidden State) - h(t)
- Wyjście komórki LSTM
- Przekazywane do następnego kroku
LSTM - Trzy Bramki (Gates)
3. Trzy bramki kontrolujące przepływ informacji:
- Forget Gate (Bramka zapominania) - decyduje, co usunąć ze stanu
- Input Gate (Bramka wejściowa) - decyduje, jakie nowe informacje dodać
- Output Gate (Bramka wyjściowa) - decyduje, co wypuścić na wyjście
Każda bramka to warstwa sigmoidalna (σ), która produkuje wartości 0-1:
- 0 = "zablokuj całkowicie"
- 1 = "przepuść wszystko"
- 0.5 = "przepuść połowę"
Kluczowa idea:
Bramki uczą się automatycznie, które informacje są istotne, a które można zapomnieć.
LSTM - Trzy Bramki (Gates)

LSTM: Forget Gate (Bramka Zapominania)
Krok 1: Decyzja co zapomnieć
Forget gate analizuje poprzedni stan ukryty h(t-1) i bieżące wejście x(t), aby zdecydować, które informacje ze stanu komórki C(t-1) należy usunąć.
Wzór matematyczny:
gdzie:
- σ - funkcja sigmoidalna (zwraca wartości 0-1)
- Wf - wagi bramki zapominania
- bf - bias
- [h(t-1), x(t)] - konkatenacja poprzedniego stanu i bieżącego wejścia
Forget Gate - Interpretacja
Interpretacja wartości:
- f(t) = 0 → zapomnij całkowicie
- f(t) = 1 → zachowaj wszystko
- f(t) = 0.7 → zachowaj 70% informacji
Przykład praktyczny:
W prognozowaniu pogody, jeśli wykryto zmianę sezonu, forget gate może "zapomnieć" wzorce z poprzedniego sezonu.
Analogia:
Wyobraź sobie, że czytasz książkę. Forget gate decyduje, które szczegóły z poprzednich rozdziałów są nadal istotne dla zrozumienia bieżącego fragmentu.
LSTM: Input Gate (Bramka Wejściowa)
Krok 2: Decyzja co dodać do stanu
Input gate decyduje, jakie nowe informacje dodać do stanu komórki.
Dwa kroki:
a) Które wartości zaktualizować:
b) Kandydat na nowe wartości:
Input Gate - Aktualizacja Stanu Komórki
gdzie:
- i(t) - bramka wejściowa (0-1)
- Ć(t) - wektor kandydackich wartości (-1 do 1)
- tanh - funkcja tangens hiperboliczny
Aktualizacja stanu komórki:
gdzie ⊙ oznacza mnożenie element po elemencie (Hadamard)
Interpretacja:
Nowy stan = (co zachować ze starego stanu) + (jakie nowe informacje dodać)
LSTM: Output Gate (Bramka Wyjściowa)
Krok 3: Decyzja co wypuścić na wyjście
Output gate decyduje, która część stanu komórki zostanie wypuszczona jako stan ukryty h(t).
Wzory matematyczne:
1. Bramka wyjściowa:
2. Nowy stan ukryty:
Output Gate - Interpretacja i Podsumowanie
Interpretacja:
- tanh(C(t)) - normalizuje stan komórki do zakresu -1 do 1
- o(t) - filtruje, które części stanu wypuścić
- h(t) - wyjście komórki LSTM, przekazywane dalej
Podsumowanie przepływu LSTM:
- Forget gate: usuń nieistotne informacje
- Input gate: dodaj nowe istotne informacje
- Aktualizuj stan komórki C(t)
- Output gate: wyprodukuj wyjście h(t)
Kluczowa idea:
LSTM automatycznie uczy się, które informacje zachować, zaktualizować lub zapomnieć!
6. Implementacja w Pythonie
Przygotowanie danych do treningu
import numpy as np
import pandas as pd
from sklearn.preprocessing import MinMaxScaler
# Wczytaj dane szeregu czasowego
df = pd.read_csv('stock_prices.csv')
data = df['Close'].values.reshape(-1, 1)
# Normalizacja danych do zakresu [0, 1]
scaler = MinMaxScaler(feature_range=(0, 1))
scaled_data = scaler.fit_transform(data)
# Utworzenie sekwencji (sliding window)
def create_sequences(data, seq_length):
X, y = [], []
for i in range(len(data) - seq_length):
X.append(data[i:i+seq_length])
y.append(data[i+seq_length])
return np.array(X), np.array(y)
# Okno czasowe = 60 dni
seq_length = 60
X, y = create_sequences(scaled_data, seq_length)
# Podział na zbiór treningowy i testowy (80/20)
train_size = int(len(X) * 0.8)
X_train, X_test = X[:train_size], X[train_size:]
y_train, y_test = y[:train_size], y[train_size:]
print(f"X_train shape: {X_train.shape}") # (samples, 60, 1)
print(f"y_train shape: {y_train.shape}") # (samples, 1)Budowa Modelu LSTM w Keras/TensorFlow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense, Dropout
from tensorflow.keras.optimizers import Adam
# Budowa modelu
model = Sequential([
# Pierwsza warstwa LSTM (return_sequences=True dla kolejnej warstwy LSTM)
LSTM(units=50, return_sequences=True, input_shape=(seq_length, 1)),
Dropout(0.2), # Zapobiega przeuczeniu
# Druga warstwa LSTM
LSTM(units=50, return_sequences=False),
Dropout(0.2),
# Warstwa Dense (w pełni połączona)
Dense(units=25),
# Warstwa wyjściowa
Dense(units=1)
])
# Kompilacja modelu
model.compile(
optimizer=Adam(learning_rate=0.001),
loss='mean_squared_error',
metrics=['mae']
)
# Wyświetl architekturę
model.summary()Trening Modelu LSTM
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
# Callbacks
early_stop = EarlyStopping(
monitor='val_loss',
patience=10,
restore_best_weights=True
)
checkpoint = ModelCheckpoint(
'best_model.h5',
monitor='val_loss',
save_best_only=True
)
# Trening modelu
history = model.fit(
X_train, y_train,
epochs=100,
batch_size=32,
validation_split=0.1,
callbacks=[early_stop, checkpoint],
verbose=1
)
# Ewaluacja na zbiorze testowym
test_loss, test_mae = model.evaluate(X_test, y_test)
print(f"Test Loss: {test_loss:.4f}")
print(f"Test MAE: {test_mae:.4f}")Prognozowanie z Modelem LSTM
# Predykcja na zbiorze testowym
predictions = model.predict(X_test)
# Odwrócenie normalizacji
predictions = scaler.inverse_transform(predictions)
y_test_actual = scaler.inverse_transform(y_test)
# Wizualizacja wyników
import matplotlib.pyplot as plt
plt.figure(figsize=(14, 6))
plt.plot(y_test_actual, label='Rzeczywiste wartości', color='blue')
plt.plot(predictions, label='Prognoza LSTM', color='red')
plt.title('Prognoza cen akcji - LSTM')
plt.xlabel('Czas')
plt.ylabel('Cena')
plt.legend()
plt.grid(True)
plt.show()
# Metryki dokładności
from sklearn.metrics import mean_squared_error, mean_absolute_error
import math
rmse = math.sqrt(mean_squared_error(y_test_actual, predictions))
mae = mean_absolute_error(y_test_actual, predictions)
mape = np.mean(np.abs((y_test_actual - predictions) / y_test_actual)) * 100
print(f"RMSE: {rmse:.2f}")
print(f"MAE: {mae:.2f}")
print(f"MAPE: {mape:.2f}%")Prognozowanie Wielokrokowe (Multi-step)
def predict_future(model, last_sequence, steps, scaler):
"""
Prognozuje 'steps' kroków w przyszłość.
Args:
model: wytrenowany model LSTM
last_sequence: ostatnie 'seq_length' obserwacji
steps: ile kroków w przyszłość przewidzieć
scaler: obiekt MinMaxScaler do denormalizacji
"""
predictions = []
current_sequence = last_sequence.copy()
for _ in range(steps):
# Prognoza następnego kroku
next_pred = model.predict(current_sequence.reshape(1, seq_length, 1))
predictions.append(next_pred[0, 0])
# Aktualizacja sekwencji (usuń pierwszy, dodaj prognozę)
current_sequence = np.append(current_sequence[1:], next_pred)
# Denormalizacja
predictions = scaler.inverse_transform(np.array(predictions).reshape(-1, 1))
return predictions
# Prognoza na 30 dni w przyszłość
last_60_days = scaled_data[-60:]
future_predictions = predict_future(model, last_60_days, steps=30, scaler=scaler)
print("Prognoza na najbliższe 30 dni:")
print(future_predictions.flatten())Warianty i Rozszerzenia LSTM
1. Bidirectional LSTM (Dwukierunkowy)
Przetwarza sekwencję w obu kierunkach (przód i tył), łącząc informacje z przeszłości i przyszłości.
Zastosowanie: Klasyfikacja sekwencji, gdy mamy dostęp do całej sekwencji.
2. Stacked LSTM (Wielowarstwowy)
Kilka warstw LSTM ułożonych jedna na drugiej. Głębsze sieci mogą uczyć się bardziej abstrakcyjnych reprezentacji.
Warianty i Rozszerzenia LSTM
3. GRU (Gated Recurrent Unit)
Uproszczona wersja LSTM z mniejszą liczbą parametrów:
- Tylko 2 bramki (reset i update) zamiast 3
- Brak osobnego stanu komórki
- Szybszy trening, podobna wydajność
4. Attention Mechanism
Pozwala modelowi "skupić się" na najważniejszych częściach sekwencji.
5. Encoder-Decoder LSTM
Architektura sekwencja-do-sekwencji (seq2seq), używana w tłumaczeniu maszynowym.
Przykład: Bidirectional LSTM
from tensorflow.keras.layers import Bidirectional
# Model z Bidirectional LSTM
model = Sequential([
# Warstwa Bidirectional LSTM
# Przetwarza sekwencję w obu kierunkach
Bidirectional(
LSTM(units=50, return_sequences=True),
input_shape=(seq_length, 1)
),
Dropout(0.2),
# Druga warstwa Bidirectional LSTM
Bidirectional(LSTM(units=50)),
Dropout(0.2),
Dense(units=25),
Dense(units=1)
])
# Uwaga: Bidirectional podwaja liczbę parametrów
# (2 × units, bo forward + backward)
model.compile(
optimizer='adam',
loss='mse',
metrics=['mae']
)
model.summary()Przykład: GRU - Lżejsza Alternatywa
from tensorflow.keras.layers import GRU
# Model z GRU zamiast LSTM
model_gru = Sequential([
# Warstwa GRU
GRU(units=50, return_sequences=True, input_shape=(seq_length, 1)),
Dropout(0.2),
# Druga warstwa GRU
GRU(units=50, return_sequences=False),
Dropout(0.2),
Dense(units=25),
Dense(units=1)
])
model_gru.compile(optimizer='adam', loss='mse')
# Porównanie liczby parametrów
print("LSTM parameters:", model.count_params())
print("GRU parameters:", model_gru.count_params())
# GRU ma ~25% mniej parametrów niż LSTM
# GRU jest szybszy w treningu, ale LSTM często
# osiąga lepsze wyniki na złożonych zadaniach7. Zastosowania Praktyczne LSTM
1. Finanse
- Prognozowanie cen akcji i kryptowalut
- Przewidywanie kursów walut
- Wykrywanie anomalii w transakcjach (fraud detection)
- Algorytmiczny trading
2. Energia i Utilities
- Prognozowanie zużycia energii elektrycznej
- Optymalizacja sieci energetycznych
- Przewidywanie awarii infrastruktury
7. Zastosowania Praktyczne LSTM
3. Handel i E-commerce
- Prognozowanie popytu i sprzedaży
- Optymalizacja zapasów magazynowych
- Przewidywanie churn rate (odpływu klientów)
4. Meteorologia
- Prognoza pogody
- Przewidywanie klęsk żywiołowych
- Modelowanie zmian klimatu
5. Healthcare
- Monitoring pacjentów (EKG, EEG)
- Prognozowanie epidemii
- Analiza sygnałów biomedycznych
8. Porównanie: LSTM vs Metody Klasyczne
ARIMA vs LSTM
AspektARIMALSTMZłożonośćProsty, interpretowalnyZłożony, "czarna skrzynka"NieliniowośćTylko liniowe zależnościMoże uczyć się nieliniowych wzorcówDane wielowymiaroweTrudne (VARIMAX)Naturalne wsparcieDługoterminowe zależnościOgraniczoneBardzo dobre (LSTM)Wymaga stacjonarnościTAKNIECzas treninguSzybkiWolny (wymaga GPU)Ilość danychDziała na małych zbiorachWymaga dużo danych (1000+ obserwacji)Dobór parametrówWymaga ekspertyzyAutomatyczny (ale hyperparametry)
8. Porównanie: LSTM vs Metody Klasyczne
Kiedy użyć LSTM?
- Duża ilość danych historycznych
- Złożone, nieliniowe wzorce
- Wiele zmiennych wejściowych
- Długoterminowe zależności
Kiedy użyć ARIMA?
- Mało danych
- Potrzeba interpretacji
- Proste, liniowe wzorce
- Szybkie prototypowanie
Optymalizacja Hyperparametrów LSTM
Kluczowe hyperparametry do dostrojenia:
1. Architektura sieci
- Liczba warstw LSTM (1-5, zazwyczaj 2-3)
- Liczba jednostek w warstwie (32, 64, 128, 256)
- Dropout rate (0.1-0.5, zapobiega przeuczeniu)
2. Sekwencja
- Długość okna czasowego (seq_length: 30, 60, 90 dni)
- Krok próbkowania (co ile obserwacji brać)
Optymalizacja Hyperparametrów LSTM
3. Trening
- Learning rate (0.0001-0.01)
- Batch size (16, 32, 64, 128)
- Liczba epok (50-200 z early stopping)
- Optimizer (Adam, RMSprop, SGD)
4. Regularyzacja
- Dropout (0.2-0.5)
- L1/L2 regularization
- Batch normalization
Metody optymalizacji:
- Grid Search - sprawdza wszystkie kombinacje
- Random Search - losowe próbkowanie
- Bayesian Optimization - inteligentne próbkowanie
Best Practices - Praktyczne Wskazówki
1. Przygotowanie danych
- Zawsze normalizuj dane (MinMaxScaler lub StandardScaler)
- Sprawdź brakujące wartości (interpolacja, forward fill)
- Usuń outliers lub obsłuż je odpowiednio
- Zachowaj chronologiczność - nie mieszaj kolejności!
2. Podział danych
- NIE używaj random split - zachowaj kolejność czasową
- Typowy podział: 70% train, 15% validation, 15% test
- Test set powinien być "w przyszłości" względem train
Best Practices - Praktyczne Wskazówki
3. Walidacja
- Użyj walk-forward validation dla szeregów czasowych
- Monitoruj val_loss, stosuj early stopping
- Zapisuj najlepszy model (ModelCheckpoint)
4. Unikaj przeuczenia
- Dropout (0.2-0.3 to dobry start)
- Regularyzacja L2
- Nie trenuj za długo (early stopping)
- Więcej danych > więcej parametrów
5. Ewaluacja
- Użyj wielu metryk: RMSE, MAE, MAPE
- Wizualizuj prognozy vs rzeczywiste wartości
- Sprawdź residuals (błędy) - czy są losowe?