Sistemas Inteligentes
Unidad 1: Introducción a los Sistemas Inteligentes
Ing. Oscar Alonso Rosete Beas
Semana 24 Enero Rev:2 ciclo 2022-1
oscarrosete.com

oscarrosete.com

Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
oscarrosete.com
Unidad 1
oscarrosete.com


Unidad 1
oscarrosete.com
oscarrosete.com
oscarrosete.com
Introducción a la materia
Horas de Clase Asistidas: 64
Horas de Clase Independientes: 64
Duración Total: 128 horas
Horario: Martes 15:00-17:00 / Jueves 15:00-17:00
Salón: 28106
DATOS DEL DOCENTE
Nombre: Oscar Alonso Rosete Beas
E-mail: oscar.rosete@cetys.mx
oscarrosete.com
oscarrosete.com
PROPÓSITO DEL CURSO
Este curso tiene como propósito que el alumno aplique los métodos que simulan aspectos del comportamiento inteligente, con la intención de aprender de la naturaleza.
Durante el curso se estudiará:
-
Algoritmos basados en lógica difusa, redes neuronales, sistemas basados en conocimiento y la interacción hombre-máquina.
-
Diseño sistemas, procesos, productos y/o componentes basados en software aplicando métodos, técnicas, y herramientas modernas
oscarrosete.com
Introducción a la materia
Las actividades que se realicen dentro del aula serán dirigidas por el profesor y otras serán de carácter independiente para ser realizadas por los alumnos fuera del aula.
Las formas genéricas de actividades de aprendizaje que serán realizadas por los alumnos son:
- Trabajo colaborativo dentro del aula para analizar y debatir sobre los contenidos y bajo la dirección del profesor.
- Exposición de contenidos por parte del profesor y alumnos
- Aprendizaje basado en proyectos de aplicación por equipos o individuales.
oscarrosete.com
oscarrosete.com
oscarrosete.com
EVIDENCIAS DE DESEMPEÑO
- Reportes de análisis y resolución de casos de estudio y ejercicios de aplicación.
-
Reportes de lectura y reportes de investigación.
-
Prácticas de Laboratorio(*)
-
Presentaciones en clase.
-
Elaboración de prototipos.
-
Exámenes escritos a lo largo del curso y examen final.
-
Proyecto final integrador en donde se apliquen las herramientas vistas durante el curso.
Agenda
oscarrosete.com
oscarrosete.com
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
oscarrosete.com
oscarrosete.com
Introducción a la materia
2.1. Introducción a la Lógica Difusa
2.2. Conjuntos difusos y funciones de membresía
2.3. Operaciones sobre conjuntos difusos
2.4. Inferencia usando Lógica Difusa
2.5. Diseño de clasificadores difusos
Unidad 2: Lógica Difusa Tipo – I
oscarrosete.com
oscarrosete.com
Introducción a la materia
3.1. Aprendizaje supervisado y no supervisado
3.2. Algoritmo “Backpropagation through time”
3.3. Aprendizaje en tiempo real
3.4. Algoritmo K-Means
3.4. Redes Neuronales
Unidad 3: Algoritmos de aprendizaje
oscarrosete.com
oscarrosete.com
POLÍTICAS ENTREGAS
- Existe tolerancia de 5 minutos de llegada tardía, a partir de los cuales se tomará asistencia.
- Las fechas de entrega y presentación para exámenes parciales, tareas, exposiciones, prácticas y trabajo final son Inamovibles.
- No se aceptarán entregas de exámenes fuera de la fecha y hora establecida y la calificación de una falta de entrega o entrega extemporánea es cero.
oscarrosete.com
oscarrosete.com
- Se aceptarán entregas de tareas/prácticas fuera de las fechas y horas establecidas (calificación de falta de entrega es cero).
- Penalización 10%/ día en tareas
- Penalización 10%/ semana en práctica.
- Todas las entregas deberán realizarse por medio definido en clase, de acuerdo a las indicaciones dadas (blackboard y pdf generalmente).
POLÍTICAS ENTREGAS
oscarrosete.com
oscarrosete.com
POLÍTICAS MATERIAL
- El material para trabajar en clase, descripción de tareas y temas para exposición, así como cualquier material de apoyo estará disponible a través del Blackboard o el sitio web y este será actualizado periódicamente.
- Es responsabilidad de cada estudiante traer a la sesión de clase el material que indique el maestro, incluyendo exposiciones y tareas.
oscarrosete.com
oscarrosete.com
POLÍTICAS PRESENTACIONES
- Preparar una presentación formal e interactiva que presente al grupo el tema correspondiente (Prezi, PowerPoint, Google Slides, otro).
- Preparar un reporte escrito de los puntos más relevantes de la presentación, así como las referencias consultadas.
- Subir en la actividad correspondiente en Blackboard la presentación y el reporte escrito.
- Es necesario estar presente en las actividades de exposición, de lo contrario la calificación para la exposición es cero.
oscarrosete.com
oscarrosete.com
Introducción a la materia
Bibliografía
Hangos, K. M., Lakner, R., & Gerzson, M. (2001). Intelligent Control Systems: An Introduction with Examples. Secaucus, NJ, USA: Kluwer Academic Publishers. Retrieved from http://www.ebrary.com
Graupe, D. (2007). Principles of Artificial Neural Networks (2nd Edition). River Edge, NJ, USA: World Scientific. Retrieved from http://www.ebrary.com
Sra, S., Nowozin, S., & Wright, S. J. (Eds.). (2011). Optimization for Machine Learning. Cambridge, MA, USA: MIT Press. Retrieved from http://www.ebrary.com


oscarrosete.com
oscarrosete.com
Introducción a la materia
Software:
Python, MATLAB
Herramientas digitales:
Blackboard, Google suite, recursos microsoft, portafolio electronico, bases de datos.
oscarrosete.com
oscarrosete.com
Criterios de evaluación
| Concepto | Descripción | Ponderación |
|---|---|---|
| Formación: Actitudes y valores | Actitud en actividades individuales y en equipo relacionadas a la clase | 10% |
| Examenes | Pruebas objetivas en forma de exámenes parciales y/o finales | 20% |
| Tareas | Resolución de ejemplos típicos, solución de problemas en tareas individuales y en equipo. | 30% |
| Presentaciones | Exposiciones de acuerdo a temáticas asignadas | 10% |
| Proyectos | Desarrollo y presentaciones profesionales de los proyectos | 30% |
oscarrosete.com
oscarrosete.com
Profesor:
Ing. Oscar Alonso Rosete Beas
E-Mail:
oscar.rosete@cetys.mx
Pagina de facebook:
https://www.facebook.com/oscararosete
Sitio web:
https://oscarrosete.com/
Información de referencia
oscarrosete.com
oscarrosete.com
Contacto preferente para dudas

Asesorías: WhatsApp 686 264 5073
oscarrosete.com
oscarrosete.com
Proyecto final
Desarrollar un proyecto de innovación a nivel experimental de tecnología utilizando el material visto en el curso, donde el alumno proponga la solución de un problema planteado mediante el desarrollo de un proceso para la implementación de la solución y la realización de pruebas de factibilidad y utilidad de un sistema.
oscarrosete.com
oscarrosete.com
Introducción a la materia
- Formación de equipos para presentaciones y proyectos (3-4 integrantes)
- Registro en grupo de Facebook
- Pase de lista y sondeo



oscarrosete.com
oscarrosete.com
Introducción a la materia

oscarrosete.com
oscarrosete.com
Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
oscarrosete.com
oscarrosete.com
Introducción
El enfoque tradicional desarrollado estuvo basado en problemas muy bien definidos con modelos precisos pero carecen de autonomía y la habilidad de la toma de decisiones.
La problemática es utilizarlos en entornos inciertos.
Cruzado con control clásico
Intelligent Systems: Modeling, Optimization, and Control
By Yung C. Shin, Chengying Xu
oscarrosete.com
oscarrosete.com
Control clásico
- Determinar el sistema físico y sus especificaciones.
- Dibujar diagrama de bloques.
- Convertir el sistema físico en un esquemático.
- Desarrollar un modelo matemático y obtener un diagrama de bloques del sistema.
- Reducir el diagrama de bloques.
- Análisis, Diseño y Pruebas.

oscarrosete.com
oscarrosete.com
Control clásico
oscarrosete.com
oscarrosete.com
Introducción
En años recientes, ha habido un incremento de interés dramático en técnicas de computación para aplicaciones científicas e ingenieriles.
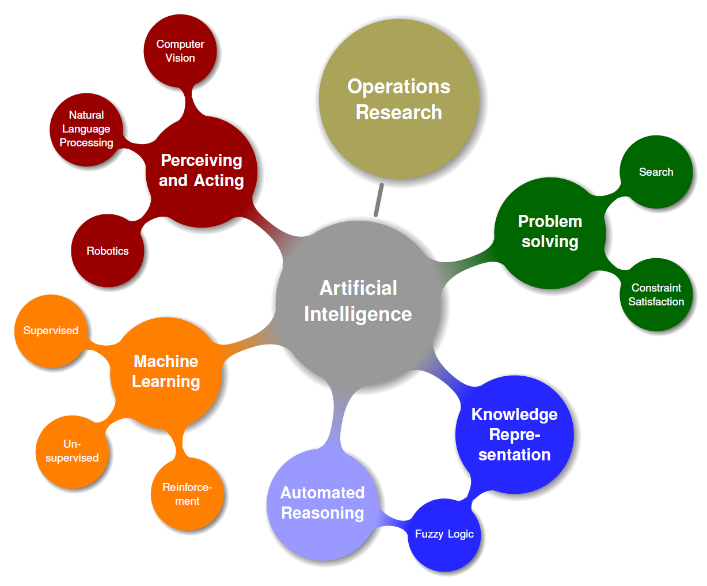
Los sistemas inteligentes son un término que cubre los distintos enfoques para el diseño, optimizan y control de sistemas variados que no cuenten con modelo matemático o que cuenten con incertidumbre.
Panorama actual
Intelligent Systems: Modeling, Optimization, and Control
By Yung C. Shin, Chengying Xu
oscarrosete.com
oscarrosete.com
Introducción
En cierta manera estos enfoques intentan emular el comportamiento humano.
Los sistemas inteligentes involucran campos como las redes neuronales, lógica difusa, estrategias evolutivas y algoritmos genéticos, entre otros.
Panorama actual
Intelligent Systems: Modeling, Optimization, and Control
By Yung C. Shin, Chengying Xu
oscarrosete.com
oscarrosete.com
Introducción
Los sistemas inteligentes son definidos con atributos que le permiten un alto grado de autonomía, razonamiento bajo incertidumbre, mejor desempeño en la búsqueda de la meta, fusión de la información de múltiples sensores, aprendizaje y adaptación al entorno.
Panorama actual
Intelligent Systems: Modeling, Optimization, and Control
By Yung C. Shin, Chengying Xu
oscarrosete.com
oscarrosete.com
Inteligencia artifical
La inteligencia artificial solo se enfoca al desarrollo de robots
Mito



oscarrosete.com
oscarrosete.com
Inteligencia artifical
La Inteligencia Artificial estudia los modelos computacionales que sirven para simular o formalizar las actividades inteligentes (cognitivas).
Percepción, razonamiento (relacionada con lógica), aprendizaje, entre otras.


Realidad
oscarrosete.com
oscarrosete.com
Inteligencia artifical
Se ha de tener en cuenta la frontera entre la IA y otras ramas de la ciencia como la psicología o la filosofía.
El enfoque de la IA es unir las ramas de las matemáticas y la ingeniería para crear artefactos que actúen de manera inteligente.
Objetivo primordial es la formalización de una actuación racional, apoyada en un Agente inteligente.

Lógica computacional
Martín Rubio Fernando, Paniagua Aris Enrique, Sanchez González Juan Luís.
Realidad
oscarrosete.com
oscarrosete.com
Inteligencia artifical
Un agente inteligente es el conjunto de componentes de Hardware y software que es capaz de realizar una o varias actividades cognitivas determinadas.
Usualmente ligamos el termino inteligencia a la demostración o posibilidad de resolver un problema.
Agente inteligente
Lógica computacional
Martín Rubio Fernando, Paniagua Aris Enrique, Sanchez González Juan Luís.
oscarrosete.com
oscarrosete.com
Inteligencia artifical
Un agente inteligente cumple con las siguientes características:
Autonomía: Un agente actúa sin intervención humana, dispone de algún tipo de control sobre sus acciones y su estado interno.
Comportamiento social: Un agente interactúa con otros agentes (artificiales o humanos) mediante un lenguaje de comunicación específico.
Agente inteligente
oscarrosete.com
oscarrosete.com
Inteligencia artifical
Un agente inteligente cumple con las siguientes características:
Reactividad: Un agente percibe su entorno y responde ante él, cambiando el estado del entorno y su propio estado interno.
Racionalidad: Un agente no se limita a actuar en respuesta a su entorno, es capaz de mostrar un comportamiento dirigido por sus objetivos.
Agente inteligente
oscarrosete.com
oscarrosete.com
Inteligencia artifical

1
3
2
oscarrosete.com
oscarrosete.com
Inteligencia artifical

Piramide de la información
Dato-> noticia-->conocimiento-->sabiduría
El software tradicional transacciona con datos y hace información/noticia.
oscarrosete.com
oscarrosete.com
Características adicionales
- Pueden tomar decisiones consistentes con su objetivo (son racionales)
- No poseen todos los conocimientos ni todos los datos (no son omniscientes)
- No siempre son exitosos (no son infalibles)
- Pueden mejorar durante su uso (aprenden)
- Soportan a cambios del dominio (flexibles y robustos)
Agente inteligente
oscarrosete.com
oscarrosete.com
¿Cómo?
- Metodología simbólica
- Metodología conexionista
- Metodología comportamentista
Tres metodologías
Inteligencia Artificial: Investigación Científica Avanzada Centrada en Datos
Roiman Valbuena

oscarrosete.com
oscarrosete.com
- También denominada inteligencia artificial tradicional, se basa en el desarrollo de largas cadenas de códigos simbólicos (legibles por humanos) que contienen instrucciones para la ejecución de programas de computadoras.
- Basado en representación y diseño de modelos.
- Independientes del entorno.
Inferencia bayesiana?
Metodología simbólica
An Anthropology of Robots and AI: Annihilation Anxiety and Machines
Kathleen Richardson
¿Cómo?
oscarrosete.com
oscarrosete.com
Una gran parte de la inteligencia artificial se enfoca a realizar predicciones (predecir el clima, comportamiento de clientes, epidemias, ataques cardíacos, etc).
Para lograr estas predicciones las computadores requieren tener modelos matemáticos del fenómeno que esta modelando.
Metodología simbólica vs subsimbolica
What is AI – and where is it heading?
Part II: Symbolic and subsymbolic AI
Thomas Bolander

¿Cómo?
oscarrosete.com
oscarrosete.com
El modelo puede ser explicitamente representado (a través de formulas o reglas) o implícitamente representado (aprendido de experiencia sin representación simbólica de las reglas o propiedades).
El primero es denominado Inteligencia Artificial simbólica, el segundo es Inteligencia artificial subsimbólica.
Metodología simbólica vs subsimbolica
What is AI – and where is it heading?
Part II: Symbolic and subsymbolic AI
Thomas Bolander
¿Cómo?
oscarrosete.com
oscarrosete.com
Metodología simbólica vs subsimbolica
Symbolic vs. Subsymbolic AI
Henry Lieberman
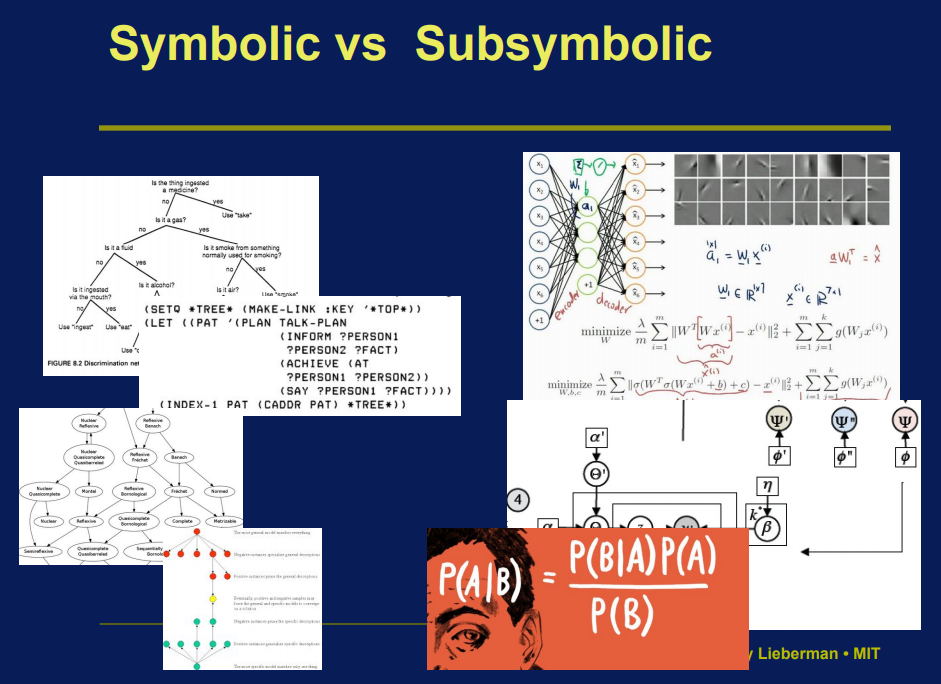
¿Cómo?
oscarrosete.com
oscarrosete.com
Metodología simbólica
¿Cómo?
oscarrosete.com
oscarrosete.com
Se sustenta en el cómo la biología, a través de complejas conexiones neuronales que nunca se programan, han hecho del cerebro un magnífico y espléndido aparato adaptativo de procesamiento de información.
Se extiende a la inteligencia computacional cuando aborda la genética y la biología evolutiva para mimetizar.
lógica difusa, redes neuronales.
Metodología conexionista
Inteligencia Artificial: Investigación Científica Avanzada Centrada en Datos
Roiman Valbuena
¿Cómo?
oscarrosete.com
oscarrosete.com
Metodología conexionista
¿Cómo?
oscarrosete.com
oscarrosete.com
Refleja el aspecto fisiológico del comportamiento humano o animal.
Modelan comportamientos inteligentes asentados en la mecánica de la vida y de la mente, además de los estados de probabilidades de pensamientos que en esta mente se procesan. Interacción con otros agentes.
Swarm intelligence (Inteligencia de enjambres)
Metodología comportamentista
Inteligencia Artificial: Investigación Científica Avanzada Centrada en Datos
Roiman Valbuena
¿Cómo?
oscarrosete.com
oscarrosete.com
Metodología comportamentista
¿Cómo?
oscarrosete.com
oscarrosete.com
Se creo un escenario mental para una escala que midiese los grados de inteligencia de un agente.
Grados de inteligencia
Inteligencia Artificial: Investigación Científica Avanzada Centrada en Datos
Roiman Valbuena

¿Cómo?
oscarrosete.com
oscarrosete.com
Los investigadores de otras ciencias entregan los datos al ingeniero del conocimiento para que determine el tipo de IA más adecuada a los objetivos que pretender ser alcanzados, sus inferencias estarán soportadas en las distribuciones estadísticas de los datos, tratando de transformarlos en información útil.
Ingeniero del conocimiento (Data scientist o Data Analyst)
¿Quién?
oscarrosete.com
oscarrosete.com
Existen múltiples arquitecturas que pueden seleccionarse, tales como, la lógica difusa, redes neuronales, sistemas expertos, algoritmos evolutivos, red híbrida (neuro-difusa), sistema experto neural, inteligencia de enjambres, entre otras
Debe de ser congruente con los datos y evaluar técnicas de minería de datos.
Ingeniero del conocimiento
¿Quién?
oscarrosete.com
Actividad en equipo
- Missael Perez, Max Delgado, Carlos Macias, Miguel Garcia
- Mariana Castro, Luis German, Juan Romero, Sergio Vargas
- Erween Felix, Ana Sofía Soto, Arián Hernández, Sebastián Beltrán
- Airam Ordoñez, Priscila Valenzuela, Azael Galaviz, Jorge Davila
- Samuel, Ricardo, Erick, Gardenia
oscarrosete.com
oscarrosete.com
oscarrosete.com
Actividad Asíncrona
Tarea 1.
- Investigar como instalar python versión 3.7^ en su computadora
- Investigar como instalar Jupyter Notebook localmente
- Video inferior derecho (ver los primeros 13 mins)
oscarrosete.com
Actividad en equipo

En equipos, investiguen, debatan al respecto y lleguen a una explicación conjunta de los siguientes tipos de agentes inteligentes.
Deberá generarse una presentación
Clasificar de acuerdo a su inteligencia y capacidad
-
Simple Reflex Agents
-
Model Based Reflex Agents
-
Goal Based Agents
-
Utility based Agents
-
Learning Agents
Clasificación opcional
video adjunto a partir de 16:32
oscarrosete.com

oscarrosete.com
oscarrosete.com
Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes

15%
25%
Subir archivo(s) en python actividad de blackboard.
oscarrosete.com
Introducción a Python


oscarrosete.com
Introducción a Python
Ejercicio a resolver por alumno 2

Ejercicio a resolver por alumno 3
oscarrosete.com
Introducción a Python
oscarrosete.com
oscarrosete.com
Inteligencia artifical
Un agente inteligente es el conjunto de componentes de Hardware y software que es capaz de realizar una o varias actividades cognitivas determinadas.
Usualmente ligamos el termino inteligencia a la demostración o posibilidad de resolver un problema.
Agente inteligente
Lógica computacional
Martín Rubio Fernando, Paniagua Aris Enrique, Sanchez González Juan Luís.
Un agente inteligente cumple con las siguientes características:
Autonomía: Un agente actúa sin intervención humana, dispone de algún tipo de control sobre sus acciones y su estado interno.
Comportamiento social: Un agente interactúa con otros agentes (artificiales o humanos) mediante un lenguaje de comunicación específico.
Agente inteligente
oscarrosete.com
Inteligencia artifical
Un agente inteligente cumple con las siguientes características:
Reactividad: Un agente percibe su entorno y responde ante él, cambiando el estado del entorno y su propio estado interno.
Racionalidad: Un agente no se limita a actuar en respuesta a su entorno, es capaz de mostrar un comportamiento dirigido por sus objetivos.
oscarrosete.com
Agente inteligente
Inteligencia artifical
En equipos, investiguen, debatan al respecto y lleguen a una explicación conjunta de los siguientes tipos de agentes inteligentes.
Deberá generarse una presentación
Clasificar de acuerdo a su inteligencia y capacidad
-
Simple Reflex Agents
-
Model Based Reflex Agents
-
Goal Based Agents
-
Utility based Agents
-
Learning Agents
Clasificación opcional
video adjunto a partir de 16:32

oscarrosete.com
Actividad en equipo
Actividad en equipo
- Missael Perez, Max Delgado, Carlos Macias, Miguel Garcia
- Mariana Castro, Luis German, Juan Romero, Sergio Vargas
- Erween Felix, Ana Sofía Soto, Arián Hernández, Sebastián Beltrán
- Airam Ordoñez, Priscila Valenzuela, Azael Galaviz, Jorge Davila
- Samuel, Ricardo, Erick, Gardenia
oscarrosete.com
Explicación detallada
oscarrosete.com
Tipos de Agentes
Agente reactivo simple (o de reflejo simple)
Simple Reflex Agents
Puede considerarse el programa de agente más sencilo. Su funcionamiento se basa en seleccionar la acción sobre las percepciones actuales del agente, ignorando las percepciones históricas, para ello almacena asociaciones entrada/salida frecuentes en forma de reglas condición-acción: Si <Percepción> entonces <acción>
oscarrosete.com

Agente reactivo simple (o de reflejo simple)
Para ilustrar estas ideas, podemos utilizar el ejemplo simple de un mundo con una aspiradora, el cual consiste de un agente robótico de limpieza en un mundo que consiste de cuadrados que pueden estar sucios o limpios.

oscarrosete.com
Tipos de Agentes
Agente reactivo simple (o de reflejo simple)
La figura muestra una configuración con dos cuadrados, el agente percibe en que cuadro se encuentra y si hay suciedad en el cuadro. El agente comienza en un cuadrado, sus acciones posibles son moverse a la derecha, moverse a la izquierda, limpieza por succión o no realizar nada.
oscarrosete.com
Tipos de Agentes

Agente reactivo simple (o de reflejo simple)
Este tipo de agente selecciona acciones basado en su percepción actual, ignorando el historial de percepciones. Este agente de limpieza por vació es un agente reactivo simple ya que su decisión esta basada únicamente en su posición actual y si existe sociedad.
oscarrosete.com
Tipos de Agentes
Enfoque generalizado
Un enfoque mas flexible y general requeriría un interpretador de reglas condicion-accion y después generar conjunto de reglas para un objetivo especifico
Se utilizan rectángulos para denotar el estado actual de toma de decisiones del agente y óvalos para representar la información utilizada en la toma de decisiones.

oscarrosete.com
Tipos de Agentes
Agente reactivo basado en modelo
Model Based Reflex Agents
En gran cantidad de ocasiones un agente no podrá tomar una decisión teniendo en cuenta una única percepción, porque esta no proporciona toda la información necesaria, es por ello necesario emplear estados que de alguna forma guarden información sobre las percepciones históricas o que ya no son observables. Además se necesita información sobre como evoluciona el mundo, independiente del agente.
oscarrosete.com
Tipos de Agentes
Enfoque generalizado
La percepción actual esta combinada con el estado interno previo para generar una descripción actualizada del estado actual, basado en el modelo del agente acerca del funcionamiento del mundo.

oscarrosete.com
Tipos de Agentes
Enfoque generalizado
La sección interesante es la función UPDATE-STATE, la cual es responsable de crear una nueva descripción interna del estado.
Posteriormente selecciona una acción de la misma manera que el agente reactivo simple.

oscarrosete.com
Tipos de Agentes
Agente reactivo basado en objetivos o metas
Goal Based Agents
Surgen porque con los estados no es suficiente para tomar una decisión, ya que ésta muchas veces depende de cual es la misión del agente. Por tanto se requiere información sobre el objetivo o meta del agente. En este tipo de agentes, para decidir que acción de las posibles llevar a cabo, utiliza una descripción de las metas a alcanzar.
Utilizados en búsqueda y planificación.
oscarrosete.com
Tipos de Agentes
Agente reactivo basado en objetivos o metas
Por ejemplo en un cruce de calle/empalme, un taxi puede dar vuelta a la izquierda, vuelta a la derecha o irse en dirección recta. La decisión correcta dependerá de a donde se dirige. En otras palabras, adicional a su estado actual, requiere información relacionada a su meta.


oscarrosete.com
Tipos de Agentes
Enfoque generalizado
El programa del agente puede combinar la información de manera similar al agente basado en modelo para posteriormente seleccionar las acciones correspondientes que lo lleven a su meta.

oscarrosete.com
Tipos de Agentes
Agente reactivo basado en utilidad
Utility based Agents
Las metas por si solas tampoco son suficientes para dotar al agente de un comportamiento igual, ya que se puede alcanzar una meta cuando existen varias. Para garantizar la selección de la mejor meta es necesario una medida que permita comparar estados.
Esta medida se denomina utilidad. Un estado puede tener más utilidad que otra, el agente debe buscar los estados que proporcionen más utilidad.
oscarrosete.com
Tipos de Agentes
Agente reactivo basado en utilidad
Por ejemplo, muchas secuencias de acciones llevaran al taxi a su destino, sin embargo algunas serán mas rápidas, seguras, confiables o eficientes que otras.
oscarrosete.com
Tipos de Agentes
Agente reactivo basado en utilidad
Las metas solamente nos dan una distinción binaria entre un estado deseado y uno no deseado.
Una métrica (utilidad) del desempeño mas generalizada que permite la comparación entre estados del mundo observado es deseable.
oscarrosete.com
Tipos de Agentes
Agente reactivo basado en utilidad
Considerando que la función interna de utilidad y la métrica externa de desempeño coinciden, un agente que selecciona acciones que maximizan su utilidad sera racional de acuerdo a su métrica de desempeño externo.
oscarrosete.com
Tipos de Agentes
Enfoque General
Utiliza un modelo de su mondo, así como una función de utilidad que mide sus preferencias entre los estados disponibles del mundo. Entonces selecciona una acción que lo lleve a la máxima utilidad esperada.

oscarrosete.com
Tipos de Agentes
Agente basado en aprendizaje
Learning agents
En los escritos de Alan Turing (1950), se considera la idea de programar sus máquinas inteligentes a mano.
El método que propone es crear máquinas con capacidad de aprendizaje y enseñarles. En múltiples áreas de la inteligencia artificial, este es el método preferido para generar sistemas del estado del arte. Cualquiera de los agentes previamente descritos puede volverse uno basado en aprendizaje o no.
oscarrosete.com
Tipos de Agentes
Agente basado en aprendizaje
La principal distinción es el elemento de aprendizaje, el cual es el responsable de realizar mejoras y el elemento de desempeño el cual es responsable de seleccionar las acciones.
El elemento de aprendizaje retroalimenta desde su critica como esta desempeñándose y determina como modificar el elemento de desempeño para mejorar en el futuro.
oscarrosete.com
Tipos de Agentes
Enfoque General
El elemento de desempeño que previamente se habia considerado como el agente completo puede modificarse a partir del elemento de aprendizaje para mejorar su desempeño.

oscarrosete.com
Tipos de Agentes
oscarrosete.com
Tipos de Agentes
Introducción a Python
oscarrosete.com
oscarrosete.com
Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
Introducción al análisis de datos con python
Antes de iniciar análisis de datos con python, necesitamos conocer los fundamentos del análisis de datos.
Necesitamos entender el procedimiento para analizar la información.
Se fundamenta en la estadística, que nos permite describir la información, realizar predicciones y obtener conclusiones de ella.
oscarrosete.com
Análisis de datos con python
Fundamentos
El análisis de datos es un proceso altamente iterativo que involucra la recolección, preparación, análisis exploratorio de datos (EDA) y la obtención de conclusiones.
En la práctica, encuestas han mostrado que la preparación de la información es el 80% del trabajo.
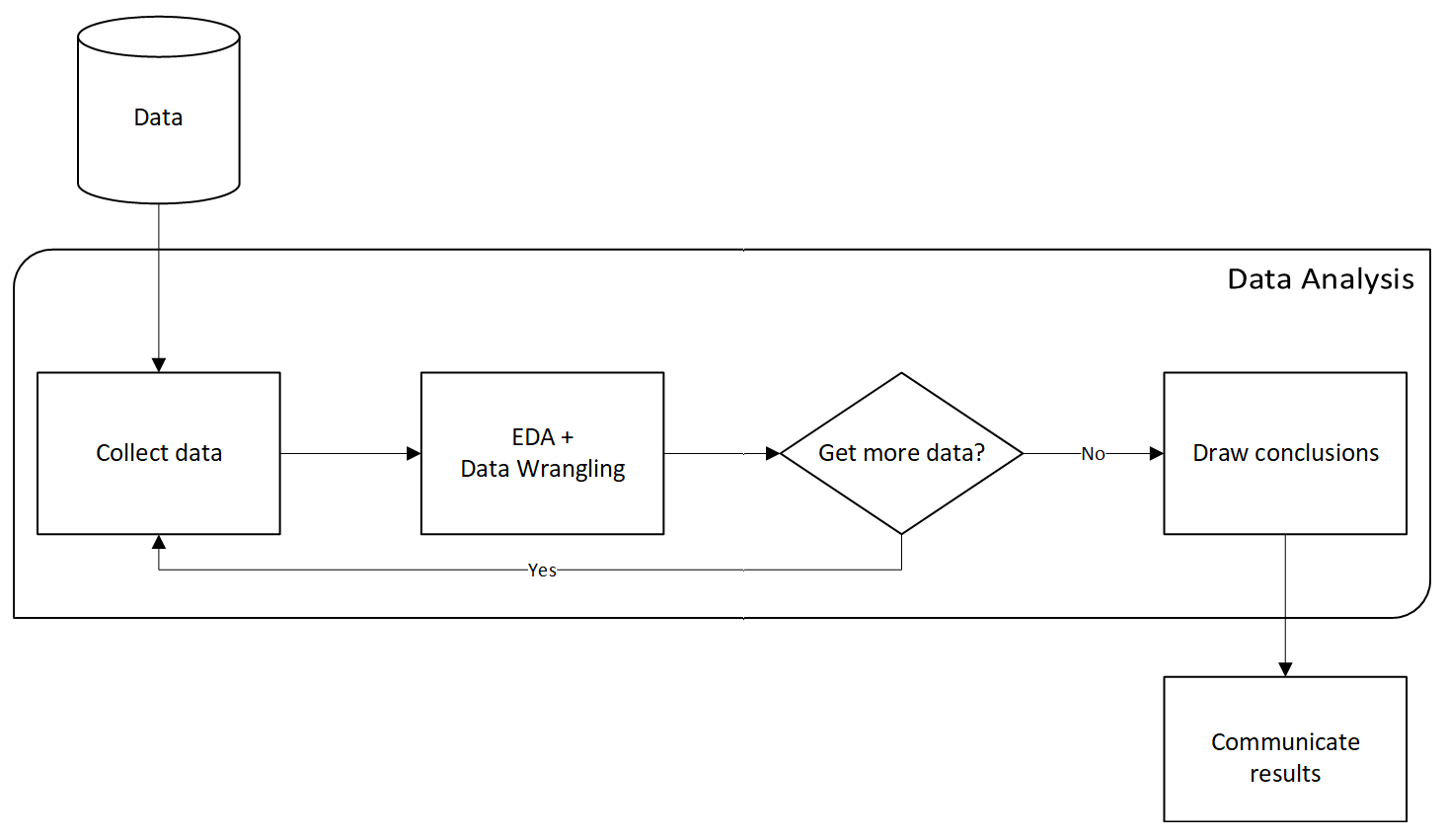

oscarrosete.com
Análisis de datos con python
Fundamentos
La recolección de datos es el primer paso natural de cualquier proceso de análisis de datos.
No podemos analizar datos que no tenemos.
En realidad, cualquier análisis puede comenzar antes de tener datos, cuando decidimos que investigar o analizar tendremos que pensar en que tipo de datos debemos recolectar que serán útiles para nuestro análisis.
oscarrosete.com
Análisis de datos con python
Fundamentos
Mientras que los datos pueden venir de cualquier fuente, algunas comunes son:
- Extracción de datos de HTML de sitios web (selenium, requests, scapy and beautifulsoup)
- APIs de servicios web (Librería requests)
- Bases de datos
- Fuentes de Internet que proveen datos para descargar, tales como sitios de gobierno o Yahoo! Finance
- Archivos de registro de los sistemas operativo (log files)
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Fundamentos
Estamos rodeados de información, las posiblidades son infinitas de recolección. lo importante es asegurarnos que los datos recolectados nos permitan dar conclusiones.

oscarrosete.com
Análisis de datos con python
Fundamentos
Por ejemplo, si queremos determinar si las ventas de chocolate caliente son mas altas cuando la temperatura es mas baja, deberíamos recolectar datos de las ventas de chocolate caliente y las temperaturas de cada día.
Recolectar datos de que tanta distancia recorrieron para obtener el chocolate caliente, puede no ser relevante.
oscarrosete.com
Análisis de datos con python
Fundamentos
No hay que preocuparnos mucho de obtener la información perfecta antes de iniciar el análisis.
Las probabilidades, son que tengamos que agregar o remover algo del conjunto de datos(dataset) inicial o cambiar su formato y unir con otros datos.
Data wrangling
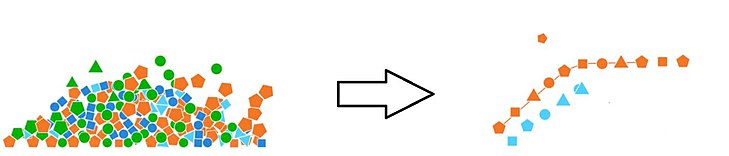
oscarrosete.com
Análisis de datos con python
Fundamentos
oscarrosete.com
Análisis de datos con python
Fundamentos
Data wrangling/mejora de la calidad de datos.
Es el proceso de preparación de datos y modificación a un formato útil para nuestro análisis. La realidad es que los datos pueden venir "sucios", que significa que requieren limpieza (preparación) antes de ser utilizados.
oscarrosete.com
Análisis de datos con python
Fundamentos
Algunas de las problemáticas usuales que podemos encontrarnos:
- Errores humanos: Datos registrados o recolectados incorrectamente, tal como escribir 100 en lugar de 1000. Múltipes versiones del mismo registro , por ejemplo New York City, NYC y nyc.
- Errores de la computadora: Quizás algunos registros no se guardaron durante cierto periodo de tiempo (datos faltantes)
oscarrosete.com
Análisis de datos con python
Fundamentos
Algunas de las problemáticas usuales que podemos encontrarnos:
- Información incompleta: pensemos en alguna encuesta con preguntas opcionales, no todas serán respondidas. No es debido a error humano o de computadora.
- Resolución: la información puede estar registrada por segundo, pero requerimos datos por hora para nuestro análisis.
oscarrosete.com
Análisis de datos con python
Fundamentos
Algunas de las problemáticas usuales que podemos encontrarnos:
- Relevancia de los campos: En algunos casos, los datos son recolectados o generados para un proceso distinto a nuestro análisis. Para que nos sea útil, deberemos cambiar su estado o campos actuales.
- El formato de los datos
- Configuración inadecuada: Pueden tener campos faltantes o compartirlos en el orden inadecuado.
oscarrosete.com
Análisis de datos con python
Data cleansing
oscarrosete.com
Análisis de datos con python
Fundamentos
oscarrosete.com
Análisis de datos con python
Análisis exploratorio de datos
En esta etapa, utilizamos visualizaciones y un resumen estadístico para obtener un entendimiento mejorado de los datos.
Ya que nuestro cerebro es grandioso identificando patrones visuales, la visualización de datos es esencial en cualquier análisis.
oscarrosete.com
Análisis de datos con python
Análisis exploratorio de datos
Algunas características de los datos solo pueden ser observado en una gráfica.
Podemos mostrar como una variable de interés evoluciona en el tiempo, cuantas observaciones pertenecen a cada categorías, encontrar valores atípicos (outliers), ver distribuciones de variables continuas y discretas entre otros.
oscarrosete.com
Análisis de datos con python
Análisis exploratorio de datos
Cuanto estemos calculando resumen estadístico, debemos considerar el tipo de datos que recolectamos. Los datos pueden ser cuantitativos (cantidades medibles) o categóricos (descripciones, agrupaciones, categorías).
oscarrosete.com
Análisis de datos con python
Análisis exploratorio de datos
Los datos categóricos pueden ser ordinales, tienen un orden natural.
Podemos ordenar los niveles/categorías (por ejemplo bajo<medio<alto)
Los datos categóricos pueden ser nominales, donde asignamos un valor numérico a cada categoría tal como on=1/off=0.
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Análisis de datos con python
Análisis exploratorio de datos
Los datos cuantitativos, pueden tener una escala de intervalo o una escala de razón.
La escala de intervalo se define como una escala de medición cuantitativa en la que se mide la diferencia entre dos variables.
El punto cero no tiene verdadero significado.
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Análisis exploratorio de datos
En la escala de intervalo tenemos por ejemplo temperatura. Podemos comparar temperaturas en grados celsius entre ciudades, pero no tiene significado decir que es el doble de caliente.
Podemos comparar a través de sumas y restas.
No tiene sentido decir que 20C es el doble de temperatura que 10C, no implica el doble de agitación térmica que la segunda.

oscarrosete.com
Análisis de datos con python
oscarrosete.com
Análisis exploratorio de datos
Los datos de escala de razón se definen como un tipo de datos cuantitativos que se caracterizan por un punto de cero absoluto, lo que significa que no hay ningún valor numérico negativo.
Ejemplo: cero metros significa tamaño nulo, o en la escala de edades, cero años significa recién nacido.
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Análisis exploratorio de datos
Cuentan con la misma característica de los datos de escala de intervalo, pero el cero tiene un significado.
Los valores pueden ser comparados con significado utilizando multiplicación y división.
Por ejemplo precios, tamaños y conteos.
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Fundamentos
oscarrosete.com
Análisis de datos con python
Conclusiones
Tras haber recolectado los datos para nuestro análisis, limpiarlos y realizar un análisis exploratorio, es momento de dar conclusiones.
- Encontramos patrones o relaciones al visualizarlos
- Podemos realizar predicciones, podemos realizar un modelo de los datos
- Necesitamos datos adicionales o mas recientes?
- Como se encuentran distribuidos?
- Nos permite dar respuesta al problema que investigábamos?
oscarrosete.com
Análisis de datos con python
Análisis de datos con python
Existe un "ecosistema" en python usual para el análisis de datos, en el cual se encuentran múltiples librerías involucradas.
NumPy
Procedente de "Numerical Python" (NumPy), ha sido una piedra angular del computo numérico en python.
Provee estructuras de datos, algoritmos, entre otros elementos para aplicaciones científicas.


oscarrosete.com
Análisis de datos con python
Pandas
Provee estructuras y funciones de alto nivel diseñadas para que el trabajo con estructuras o información tabular sea sencillo, rápido y expresivo.
Desde su arribo en 2010, ha facilitado el análisis de datos en python.
Utilizaremos dos objetos de pandas DataFrame (tabular, orientado a columnas con capacidad para etiquetado de renglones y columnas) y las Series un arreglo unidimensional con etiqueta.
oscarrosete.com
Análisis de datos con python
Convenciones para importar librerías
Nos permite diferenciar si es algo ya existente en python contra algo externo.
La convención de la comunidad de python es la siguiente:
Si vemos np.arange es una referencia a función arange de NumPy

oscarrosete.com
Análisis de datos con python
Diferencia entre función y método
Una función
Instrucciones que retornan algún resultado, existentes en alguna librería.
Método
Instrucciones que trabajan sobre un objeto generado por la librería.



oscarrosete.com
Análisis de datos con python
Numpy en python
Utilidad
- Utilizar vectores y matrices (ndarray)
- Cálculos estadístico y matemático
- Bastante rápido y eficiente.
Objetivo
- Presentar numpy array en python
- Crear arreglos numpy en jupyter
- Cómo operar con arrays
- Cómo seleccionar elementos.

oscarrosete.com
Análisis de datos con python
oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Fundamentos estadísticos
Estadística de una sola variable
Describe el centro de nuestra distribucion de datos. Existen 3 indicadores de tendnecia central: la media aritmética, la mediana y la moda.
Media aritmética
Tambien denominado promedio, se calcula sumando todos los valores y dividiendo entre la cantidad de datos.


oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.


oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.
oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.
oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.

oscarrosete.com
oscarrosete.com
Introducción al Teorema de Bayes
Análisis de datos con python
What Kinds of Data?
When I say “data,” what am I referring to exactly? The primary focus is on structured data, a deliberately vague term that encompasses many different common forms of data, such as:
• Tabular or spreadsheet-like data in which each column may be a different type (string, numeric, date, or otherwise). This includes most kinds of data commonly
stored in relational databases or tab- or comma-delimited text files.
oscarrosete.com
oscarrosete.com
Introducción a la materia
Análisis de datos con python
• Multidimensional arrays (matrices).
• Multiple tables of data interrelated by key columns (what would be primary or foreign keys for a SQL user).
• Evenly or unevenly spaced time series.
This is by no means a complete list. Even though it may not always be obvious, a large percentage of datasets can be transformed into a structured form that is more suitable for analysis and modeling. If not, it may be possible to extract features from a datasetnos equivalentes)
oscarrosete.com
oscarrosete.com
Introducción a la materia
Análisis de datos con python
•into a structured form. As an example, a collection of news articles could be processed into a word frequency table, which could then be used to perform sentiment
analysis.
Most users of spreadsheet programs like Microsoft Excel, perhaps the most widely used data analysis tool in the world, will not be strangers to these kinds of data.
oscarrosete.com
oscarrosete.com
Introducción a la materia
pip install jupyter
En carpeta de cuadernos (cd somewhere):
jupyter notebook
En interfaz web:
new python 3
En cuaderno:
print("Este es el bloque 1")
cell--> run cell ( cell , celda , bloque terminos equivalentes)
oscarrosete.com
oscarrosete.com
25/01
Introducción a la materia
En cuaderno:
print("Este es el bloque 1")
cell--> run cell (cell , celda , bloque términos equivalentes)
insert--> insert cell arriba
aparecen errores en el ide
In [3] el numero identifica el orden de ejecucion en el que ejecutamos los bloques
kernel--> interrupt o restart
Shortcut keys
shift+enter (ejecutar bloque de codigo)
ctrl+enter
25/01
Introducción a la materia
En cuaderno:
markdown celll
oscarrosete.com




25/01
Introducción a la materia
En cuaderno:
Mover bloques
Edit--> move cell down, move cell up
Combinar bloques
Edit-->merge cell below, merge cell above
copiar y pegar bloques con los botones
Poner nombre al cuaderno
file--> new notebook--> python 3--> nombre: analisis de sentimientos.
Shortcut keys
oscarrosete.com
oscarrosete.com
Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
Existe un "ecosistema" en python usual para el análisis de datos, en el cual se encuentran múltiples librerías involucradas.
NumPy
Procedente de "Numerical Python" (NumPy), ha sido una piedra angular del computo numérico en python.
Provee estructuras de datos, algoritmos, entre otros elementos para aplicaciones científicas.
oscarrosete.com
Análisis de datos con python
Pandas
Provee estructuras y funciones de alto nivel diseñadas para que el trabajo con estructuras o información tabular sea sencillo, rápido y expresivo.
Desde su arribo en 2010, ha facilitado el análisis de datos en python.
Utilizaremos dos objetos de pandas DataFrame (tabular, orientado a columnas con capacidad para etiquetado de renglones y columnas) y las Series un arreglo unidimensional con etiqueta.
oscarrosete.com
Análisis de datos con python
matplotlib
Es la librería mas popular para producir gráficas y visualizaciones de dos dimensiones listas para publicarse.
Creado por John D. Hunter y actualmente mantenido por un gran grupo de desarrolladores.
Existen múltiples opciones alternativas en la actualidad.
oscarrosete.com
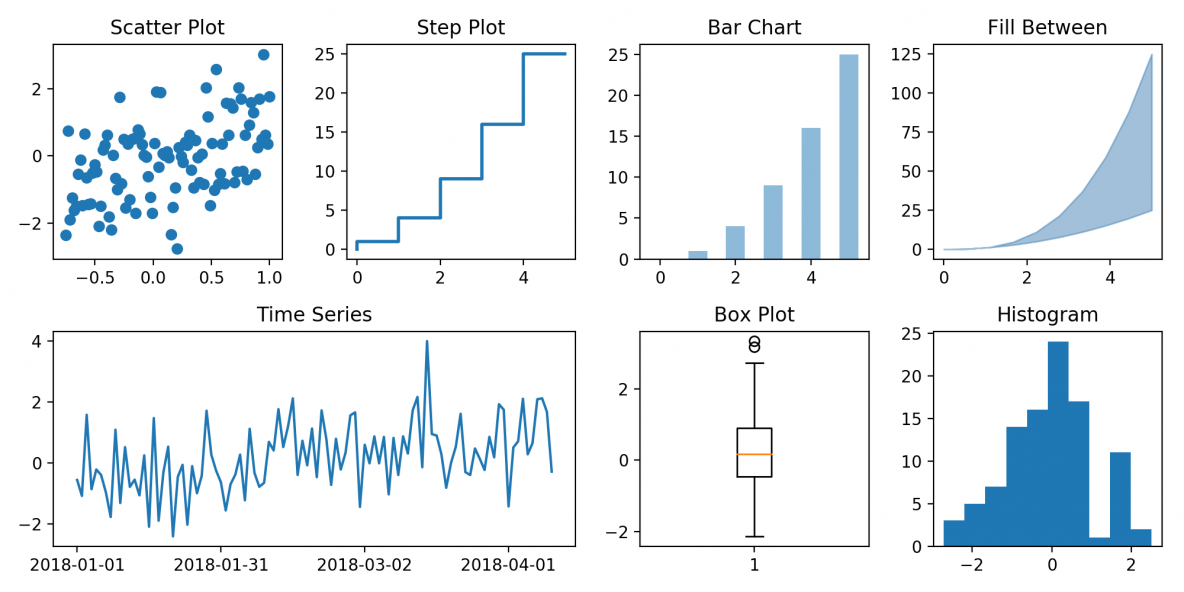
Análisis de datos con python
Paquetes de python
- Piezas de código que extienden funcionalidades de python
- Carpeta con codigo.py con estructura diseñada para usar funciones y clases
Utilidad
- Podemos hacer cálculos complejos reutilizando código
- Cuentas estadísticas, modelos, etc
oscarrosete.com
Análisis de datos con python
Convenciones para importar librerías
Nos permite diferenciar si es algo ya existente en python contra algo externo.
La convención de la comunidad de python es la siguiente:
Si vemos np.arange es una referencia a función arange de NumPy
oscarrosete.com
Análisis de datos con python
Diferencia entre función y método
Una función
Instrucciones que retornan algún resultado, existentes en alguna librería.
Método
Instrucciones que trabajan sobre un objeto generado por la librería.
oscarrosete.com
Análisis de datos con python
Numpy en python
Utilidad
- Utilizar vectores y matrices (ndarray)
- Cálculos estadístico y matemático
- Bastante rápido y eficiente.
Objetivo
- Presentar numpy array en python
- Crear arreglos numpy en jupyter
- Cómo operar con arrays
- Cómo seleccionar elementos.
oscarrosete.com
Análisis de datos con python
Pandas
PanDaS=Panel Data Sets
Termino para datos multidimensionales comunes en estadistica y econometria.
Utilidad
- Manipular tablas de datos (DataFrame)
- Difernetes tipos, mismo dataset
- Esta construido sobre Numpy.

oscarrosete.com
Análisis de datos con python
oscarrosete.com
Pandas
PanDaS=Panel Data Sets
Termino para datos multidimensionales comunes en estadistica y econometria..
Objetivo
- Estudiar dataframes de pandas en python
- Crear dataframes
- Seleccionar elementos
- Seleccionar por columna o fila
- Utilizar filtro en un dataframe
- Ordenar columnas
oscarrosete.com
Análisis de datos con python
oscarrosete.com
Collect Data in Pandas
oscarrosete.com
Análisis de datos con python
Pandas
PanDaS=Panel Data Sets
Termino para datos multidimensionales comunes en estadistica y econometria..
Objetivo
- Leer archivos de excel como pandas df
- Leer archivos csv
- Exportar a excel o csv

oscarrosete.com
Análisis de datos con python
Introducción al Teorema de Bayes
Introducción al análisis de datos con python
Antes de iniciar análisis de datos con python, necesitamos conocer los fundamentos del análisis de datos.
Necesitamos entender el procedimiento para analizar la información.
Se fundamenta en la estadística, que nos permite describir la información, realizar predicciones y obtener conclusiones de ella.
oscarrosete.com
Fundamentos estadísticos
Cuando queremos realizar observaciones de los datos que estamos analizando, usualmente sino es que siempre, recurrimos a la estadística.
Los datos a los que nos referimos son una muestra, observada de la población (subconjunto).
oscarrosete.com
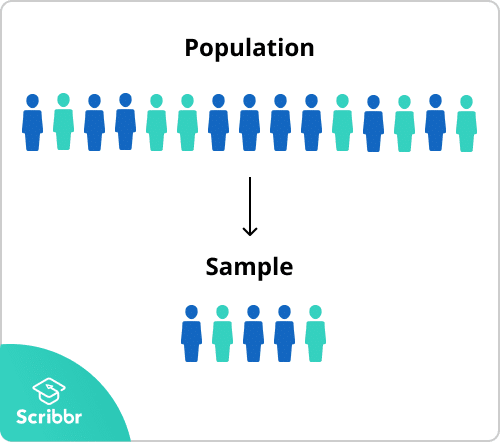
Introducción al Teorema de Bayes
Fundamentos estadísticos
Dos grandes categorías de la estadística son utilizadas, la estadística inferencial y la descriptiva. La descriptiva busca describir la muestra y la inferencial busca deducir algo acerca de la población, tal como su distribución.
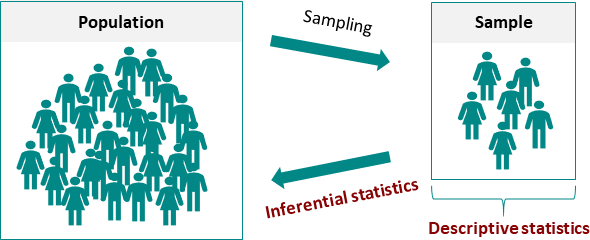
Introducción al Teorema de Bayes
oscarrosete.com
Fundamentos estadísticos
Usualmente, la meta del análisis es crear una historia de los datos; desafortunadamente, es muy sencillo utilizar incorrectamente la estadística.
Esto es especialmente cierto de la estadística inferencial, que es utilizada en estudios científicos para mostrar la relevancia de sus hallazgos.
Nos enfocaremos en una primera etapa en estadística descriptiva.
Introducción al Teorema de Bayes
oscarrosete.com
Fundamentos estadísticos
Estadística descriptiva univariable implica la obtención de la información de solamente una variable.
Es utilizada para describir o resumir la información con la que trabajamos, comenzaremos con una medida de la tendencia central, que describe donde la mayor parte de nuestra información se encuentra centrada y una medida de dispersión, que indicara que tan lejos se encuentran los valores.
Introducción al Teorema de Bayes
oscarrosete.com
Tendencia central
Describe el centro de nuestra distribución de datos. Existen 3 indicadores de tendencia central: la media aritmética, la mediana y la moda.
Media aritmética
También denominado promedio, se calcula sumando todos los valores y dividiendo entre la cantidad de datos.

Introducción al Teorema de Bayes
oscarrosete.com
Fundamentos estadísticos
Mediana
Valor que se sitúa en la mitad de la distribución
Moda
Es el valor más frecuente de la distribución.
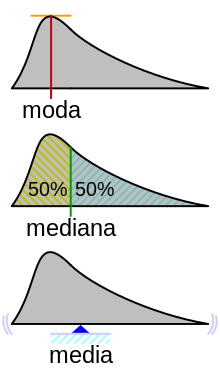
Introducción al Teorema de Bayes
oscarrosete.com
Dispersión
El saber donde se encuentra el centro de la distribución nos permitirá parcialmente resumir la distribución de los datos, necesitamos saber como se encuentran los valores con respecto al centro. Tenemos múltiples indicadores relacionados.
Rango
Es la distancia entre el valor más pequeño y el más grande.
Introducción al Teorema de Bayes
oscarrosete.com
Notas sobre el rango
El rango contara con las mismas unidades que nuestros datos. Por lo tanto a menos que dos distribuciones esten en las mismas unidades y midiendo la misma cosa, no podremos comparar sus rangos y decir que uno esta mas disperso que otro.
Introducción al Teorema de Bayes
oscarrosete.com

Varianza
En el caso del rango, si tenemos valores atípicos, el rango sera inservible, asimismo no nos dice que tan disperso esta respecto al centro.
La varianza describe que tan retiradas las observaciones se encuentran del valor promedio.
Se denota con sigma cuadrada
Bessel's correction(n-1)

Introducción al Teorema de Bayes
oscarrosete.com
Desviación estándar
La varianza nos da unidades cuadradas, por lo que no es útil de manera directa para describir los datos, por lo que se utiliza la desviación estandar que es la raíz cuadarada de la varianza para poder realizar comparaciones.


Introducción al Teorema de Bayes
oscarrosete.com
Data wrangling in Pandas
oscarrosete.com
Introducción al Teorema de Bayes
Actividad individual análisis de datos
En jupyter notebook desarrollen los siguientes puntos utilizando.
Deberá subirse a blackboard el archivo .ipynb
-
Seleccionar y recopilar información en formato csv
-
Realizar un análisis descriptivo de la información (Estadística descriptiva)
-
Deberá realizar algún tratamiento a los datos para poder proporcionar conclusiones no evidentes en el formato csv. Por lo menos 5 conclusiones.
oscarrosete.com
Actividad en equipos
En equipos comparar sus análisis de datos, seleccionar 1 temática por equipo y realizar una presentación breve (aproximadamente en 5 minutos)
Puntos a explicar:
a. Recolección de los datos
b. Análisis general de la información
c. Observaciones tras data wrangling
Nota: Agregar por lo menos 1 visualización
oscarrosete.com

Actividad en equipo
- Missael Perez, Max Delgado, Carlos Macias, Miguel Garcia
- Mariana Castro, Luis German, Juan Romero, Sergio Vargas
- Erween Felix, Ana Sofía Soto, Arián Hernández, Sebastián Beltrán
- Airam Ordoñez, Priscila Valenzuela, Azael Galaviz, Jorge Davila
- Samuel, Ricardo, Erick, Gardenia, Andres
oscarrosete.com
oscarrosete.com
oscarrosete.com
SciPy
SciPy is a collection of packages addressing a number of different standard problem domains in scientific computing.
scikit-learn
Since the project’s inception in 2010, scikit-learn has become the premier generalpurpose machine learning toolkit for Python programmers. In just seven years, it has had over 1,500 contributors from around the world. It includes submodules for such models as
Introducción al Teorema de Bayes
oscarrosete.com
oscarrosete.com
statsmodels
statsmodels is a statistical analysis package that was seeded by work from Stanford
University statistics professor Jonathan Taylor, who implemented a number of regres‐
sion analysis models popular in the R programming language.
Introducción al Teorema de Bayes
oscarrosete.com
Agenda
1.1. Encuadre del curso
1.2. Introducción a los Sistemas Inteligentes
1.3. Agentes y búsqueda
1.4. Teorema de Bayes
Unidad 1: Introducción a los Sistemas Inteligentes
Fundamentos estadísticos
Cuando queremos realizar observaciones de los datos que estamos analizando, usualmente sino es que siempre, recurrimos a la estadística.
Los datos a los que nos referimos son una muestra, observada de la población (subconjunto).
Introducción al Teorema de Bayes
oscarrosete.com
Fundamentos estadísticos
Dos grandes categorías de la estadística son utilizadas, la estadística inferencia y la descriptiva. La descriptiva busca describir la muestra y la inferencial busca deducir algo acerca de la población, tal como su distribución.
Introducción al Teorema de Bayes
oscarrosete.com
Vida de programador
Eres un programador con experiencia, sin embargo has tenido errores en tu código.
Después de una particular implementan complicada de un algoritmo decides hacer pruebas.
- Pruebas con ejemplos triviales y pasa la prueba.
- Realizas una prueba más complicada y la pasa.
- Realizas una prueba aún más complicada y la pasa.

Introducción al Teorema de Bayes
oscarrosete.com
Introducción al Teorema de Bayes
Vida de programador
Si piensas que existe la posibilidad de que no hayan errores en el código ya estamos siendo "bayesianos"
Inferencia bayesiana es modificar tus creencias considerando la nueva evidencia, no tenemos certeza pero nos podemos sentir mas seguros de nuestro código.
oscarrosete.com
oscarrosete.com
Frecuentistas vs bayesianos
La inferencia bayesiana difiere de la estadística inferencial tradicional ya que preserva incertidumbre.
Esto en un primer acercamiento parece ser una técnica estadística equivocado ya que se busca derivar certeza de la aleatoriedad.
Se requiere analizar que es la probabilidad para el enfoque bayesiano comparado con el frecuentista.
Introducción al Teorema de Bayes
oscarrosete.com
Frecuentistas vs bayesianos
La interpretación clásica o frecuentista asume que la probabilidad es la frecuencia con la que sucede un evento a largo plazo o el resultado de una experimentación infinita. Lo cual tiene sentido para eventos con múltiples ocurrencias.
Hay excepciones como la probabilidad de que un candidato gane las elecciones presidenciales, sin embargo, este es un evento único. Generalmente se manejan mediante escenarios alternativos

Introducción al Teorema de Bayes
oscarrosete.com
oscarrosete.com
Frecuentistas vs bayesianos
Los bayesianos interpretan la probabilidad como una medida de la creencia o confianza en que un evento ocurra.
Una probabilidad es el resumen de una opinión.
Un individuo que asigna una creencia de 0 aun evento cree con absoluta certeza que no va a ocurrir algo, alguien que asigna 1 cree con certeza que va a ocurrir.
Refinamos predicciones a partir de nueva evidencia
Introducción al Teorema de Bayes
oscarrosete.com
Niveles de entendimiento

- ¿Qué es el teorema de Bayes?
- ¿Porqué es cierto?
- ¿Cuándo es relevante?
En su nivel más bajo, necesitamos saber cual es el significado y cuales son sus componentes para sustituir números y obtener el resultado de la fórmula.
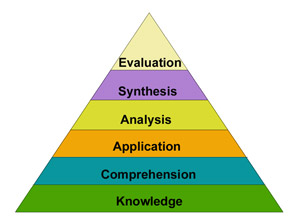
Taxonomía bloom
Teorema de Bayes
oscarrosete.com
Teorema de Bayes
oscarrosete.com
Niveles de entendimiento
- ¿Qué es el teorema de Bayes?
- ¿Porqué es cierto?
- ¿Cuándo es relevante?
En su nivel más bajo, necesitamos saber cual es el significado y cuales son sus componentes para sustituir números y obtener el resultado de la fórmula.
Taxonomía bloom
Teorema de Bayes
oscarrosete.com
Niveles de entendimiento
- ¿Qué es el teorema de Bayes?
- ¿Porqué es cierto?
- ¿Cuándo es relevante?
En su nivel más bajo, necesitamos saber cual es el significado y cuales son sus componentes para sustituir números y obtener el resultado de la fórmula.
Taxonomía bloom
Central en el descubrimiento cientifico.
Herramienta clave para aprendizaje automatico e inteligencia artificial.
Treasure hunting.
Aplicaciones
Teorema de Bayes
oscarrosete.com
En 1988 Tommy Thompson y amigos utilizaron técnicas de búsqueda bayesianas para ubicar un barco que había permanecido hundido un siglo y medio antes.
El barco tenia en su interior millones de dolares de oro.
Tommy thompson
Teorema de Bayes
oscarrosete.com
Primero una historia
Steve is described as a shy individual, very helpful, but he has little interest in other people. He likes things in their proper order, and is very detailed about his work.
Steve es muy tímido y retraído, invariablemente servicial, pero con poco interés en las personas o en el mundo de la realidad. Un alma mansa y ordenada, tiene una necesidad de orden y estructura, y una pasión por el detalle
Teorema de Bayes
oscarrosete.com
Primero una historia
La pregunta es ¿es más probable que Steve sea un bibliotecario o un agricultor?


Teorema de Bayes
oscarrosete.com
La historia fue parte de un estudio realizado por los psicólogos Daniel Kahneman y Amos Tversky llamados los padres de la economia comportamental.
Ganaron un nobel y escribió el exitoso libro "thinking fast and slow".

Investigación realizada

Teorema de Bayes
oscarrosete.com
oscarrosete.com
El cerebro humano se fundamenta en atajos mentales y estereotipos para la toma de decisiones, lo cual puede llevarnos a conclusiones/juicios irracionales.
Lo cual puede contradecir lo que las leyes de probabilidad sugieren.
Investigación realizada
Teorema de Bayes
oscarrosete.com
Al decir la descripción de steve, la mayoría de la gente puede asumir ya que se alinea a sus estereotipos de lo que es un bibliotecario que el encaja en esta descripción.
De acuerdo a los psicólogos esto seria "irracional"
Investigación realizada
Teorema de Bayes
oscarrosete.com
El propósito no es si la gente tiene perspectivas correctas o incorrectas de las personalidades de bibliotecarios y granjeros.

Teorema de Bayes
oscarrosete.com
Investigación realizada
El punto es que casi ninguno incorpora información de si la razón de granjeros contra bibliotecarios en sus juicios.
En los libros previamente mencionados se menciona es una relación de 20 a 1, lo cual puede ser mayor.


Teorema de Bayes
oscarrosete.com
Investigación realizada
Para ser claros, no se espera que sepan información exacta de la estadística de granjeros y bibliotecarios y su personalidad.
La verdadera pregunta es si consideraron esta relación para hacer su estimado.
Teorema de Bayes
oscarrosete.com
Investigación realizada
“Rationality is not about knowing facts but recognizing which facts are important
Grant Sanderson 3blue1brown
Teorema de Bayes
oscarrosete.com
Investigación realizada
¿Cómo estimar la probabilidad?
Comencemos con una muestra representativa (multiplicar por 10 la relación 20:1)
- 200 granjeros
- 10 bibliotecarios

Teorema de Bayes
oscarrosete.com
Cuando escuchas nueva evidencia, por ejemplo la descripción de Steve, estimas probabilidad de coincidencia:
- 40% bibliotecarios
- 10% granjeros

¿Cómo estimar la probabilidad?

Teorema de Bayes
oscarrosete.com
Así que la probabilidad de que una persona seleccionada al azar sea un bibliotecario sería la siguiente:

bibliotecario dada descripción
Teorema de Bayes
oscarrosete.com
¿Cómo estimar la probabilidad?
Así que aunque pensemos es 4 veces más probable que un bibliotecario cumpla con la descripción no sobrepasa el hecho de que hay más granjeros que bibliotecarios.
Es estadísticamente más probable que sea un granjero Steve.

¿Cómo estimar la probabilidad?
Percepción de probabilidad dada la descripción
Teorema de Bayes
oscarrosete.com
Conclusión
La nueva evidencia no debería determinar tus creencias en un vacío, debería de actualizar creencias anteriores.



Debe ser bibliotecario
Teorema de Bayes
oscarrosete.com
Esencia de teorema de bayes
Ver evidencia restringe el espacio de posibilidades y la proporción de que la hipótesis sea correcta.
Lo más importante es utilizar una versión numérica de la evidencia para actualizar nuestra creencia.

Teorema de Bayes
oscarrosete.com
¿Cuando utilizarlo?
El teorema de bayes es relevante cuando tenemos una hipótesis (steve es bibliotecario), vemos nueva evidencia (descripcion verbal de steve) y quieres saber la probabilidad de que la hipótesis sea válida dada la evidencia.

Steve es bibliotecario
Evidencia
P (Hipótesis dada evidencia)

Teorema de Bayes
oscarrosete.com
La probabilidad de la hipótesis dada la evidencia es llamada "probabilidad a posteriori", se determina de la siguiente manera:

Generalización
Teorema de Bayes
oscarrosete.com
Terminología y notación
La barra vertical significa restringir solo a las posibilidades de ocurrencia donde la evidencia (E) es válida.


La probabilidad de que la hipótesis sea válida antes de la evidencia (probabilidad a priori)
Teorema de Bayes
oscarrosete.com
La probabilidad de que la hipótesis sea válida con la evidencia (probabilidad condicional)
La probabilidad marginal de E: la probabilidad de observar la nueva evidencia E bajo todas las hipótesis mutuamente excluyentes.


Teorema de Bayes
oscarrosete.com
Terminología y notación
Notación estandar
Probabilidad de ver la evidencia y que la hipótesis sea incorrecta (probabilidad a posteriori)
Teorema de Bayes
Teorema de Bayes
oscarrosete.com
Los científicos utilizan la formula cuando analizan la manera en la que nueva información valida o invalida sus modelos.
Los programadores la utilizan al construir inteligencia artificial cuando quieres explícitamente y numéricamente modelar las creencias de una máquina.

¿Cómo lo utilizan en la actualidad?
Teorema de Bayes
oscarrosete.com

Teorema de Bayes
oscarrosete.com
Investigación Adicional
Teorema de Bayes
oscarrosete.com
Evento
Conceptos basicos
oscarrosete.com
Un evento es simplemente el resultado de un experimento aleatorio.
Asociamos probabilidades a los eventos al definir un evento en un espacio muestral.
Ejemplos de eventos:
- Obtener cara al lanzar una moneda es un evento.
- Obtener el numero 6 al rodar un dado no cargado.
Espacio muestral
Conceptos basicos
oscarrosete.com
Es una colección de todos los posibles resultados de un experimento.
Esto significa que si realizamos una tarea particular una y otra vez, todos los resultados de la tarea serán enlistados en un espacio muestral.
Por ejemplo el espacio muestral para tirar un dado sería {1,2,3,4,5 y 6 }. Alguno de esos números sería el resultado al tirar el dado.
Un evento puede ser la combinación de eventos distintos.
Union de eventos
Conceptos basicos
oscarrosete.com
Podemos definir un evento (C) de obtener un 4 o un 6 al tirar el dado. Aquí el evento C es la unión de dos eventos:
Evento A= Obtener un 4
Evento B= Obtener un 6
P(C) = P(A U B)
En palabras simples podemos decir que debemos considerar la probabilidad de (A U B) cuando estamos interesados en combinar la probabilidad de dos o más eventos.
Interseccion de eventos
Conceptos basicos
oscarrosete.com

Definamos C como el evento de obtener un múltiplo de 2 y 3 al tirar un dado.
Evento A= Obtener un 2 al tirar un dado
Evento B= Obtener un múltiplo de 3 al tirar un dado
Evento C= Obtener un múltiplo de 2 y 3
Evento C es una intersección de los eventos A y B.
Las probabilidades son definidas a continuación:
P(C)=P(A ∩ B) ---> Región sombreada
Eventos incompatibles/disjuntos
Conceptos basicos
oscarrosete.com
Digamos que tiramos un dado en una única ocasión
Evento A= Obtener un múltiplo de 3
Evento B= Obtener un múltiplo de 5
Queremos que ambos eventos A y B ocurran simultáneamente
Encontremos los sub-espacios para los eventos A y B
Evento A={3,6}
Evento B={5}
Espacio muestral={1,2,3,4,5,6}
No hay escenario en el que sucedan simultáneamente.

Eventos independientes
Conceptos basicos
oscarrosete.com
Supongamos que tenemos dos eventos
Si la ocurrencia del evento A no afecta la ocurrencia del evento B, estos eventos son llamados eventos independientes.
Algunos ejemplos
- Obtener cara al tirar una moneda y obtener un 5 al tirar un dado
- Obtener una carta especifica de una baraja, reemplazarla y seleccionar una segunda carta de la misma baraja.
Probabilidad en eventos independientes
Conceptos basicos
oscarrosete.com
En el caso de la probabilidad de P( A ∩ B) = P(A) * P(B)
supongamos que ganamos un juego de seleccionar una canica roja de un jarrón que contiene 4 rojas y 3 negras y si obtenemos cara al tirar una moneda.
Evento A= Obtener canica roja
Evento B= Obtener cara
P(A)=4/7 P(B)=1/2
Al ser independientes:
P(A ∩ B) = P(A)*P(B)
P(A ∩ B) = (4/7) * (1/2)= 2/7
Probabilidad en eventos dependientes
Conceptos basicos
oscarrosete.com
Asumamos evento A como obtener una canica roja del jarron. Dejamos la canica afuera del jarron y obtenemos una segunda canica.
Las probabilidades del segundo caso no seran las mismas para el segundo escenario. Ahora tenemos una probabilidad de 3/6
La probabilidad en el segundo caso es dependiente de lo que sucedio la primer ocasión.
Probabilidad condicional
Conceptos basicos
oscarrosete.com
La probabilidad condicional se da en investigación de experimentos donde el resultado de un experimento puede afectar el resultado de experimentaciones subsecuentes.
Intentamos calcular la probabilidad del segundo evento (evento B) dado que un primer evento (evento A) ya sucedio.
Si la probabilidad del evento cambia cuando tomamos el primer evento en consideración, podemos decir con seguridad que la probabilidad del evento B es dependiente de la ocurrencia del evento A.
Probabilidad condicional
Conceptos basicos
oscarrosete.com
Algunos ejemplos:
- Obtener un as de una baraja, dado que ya se obtuvo un as
- Obtener la probabilidad de haber contraído una enfermedad, habiendo resultado positivo en una prueba.
- Obtener la probabiilidad de que le guste Harry poter sabiendo que a la persona le gusta la ficción
Probabilidad condicional

Conceptos basicos
oscarrosete.com
Definamos dos ventos:
Evento A la probabilidad del evento que queremos calcular
Evento B la condicion que conocemos o el evento que ha sucedido
Podemos escribir la probabilidad condicional como
La probabilidad de ocurrencia del evento A dado que el evento B ya sucedio.

Conceptos basicos
oscarrosete.com
Probabilidad condicional
Supongamos que se obtienen dos cartas de una baraja y ganas al obtener la carta J seguido de un As (sin reemplazo).
Calculemos la probabilidad de ganar
Evento A= Obtener J P(A)=4/52
Evento B= Obtener B P(B)=4/51 (sin reemplazo)
P(A y B)= 4/52 * 4/51= 0.006
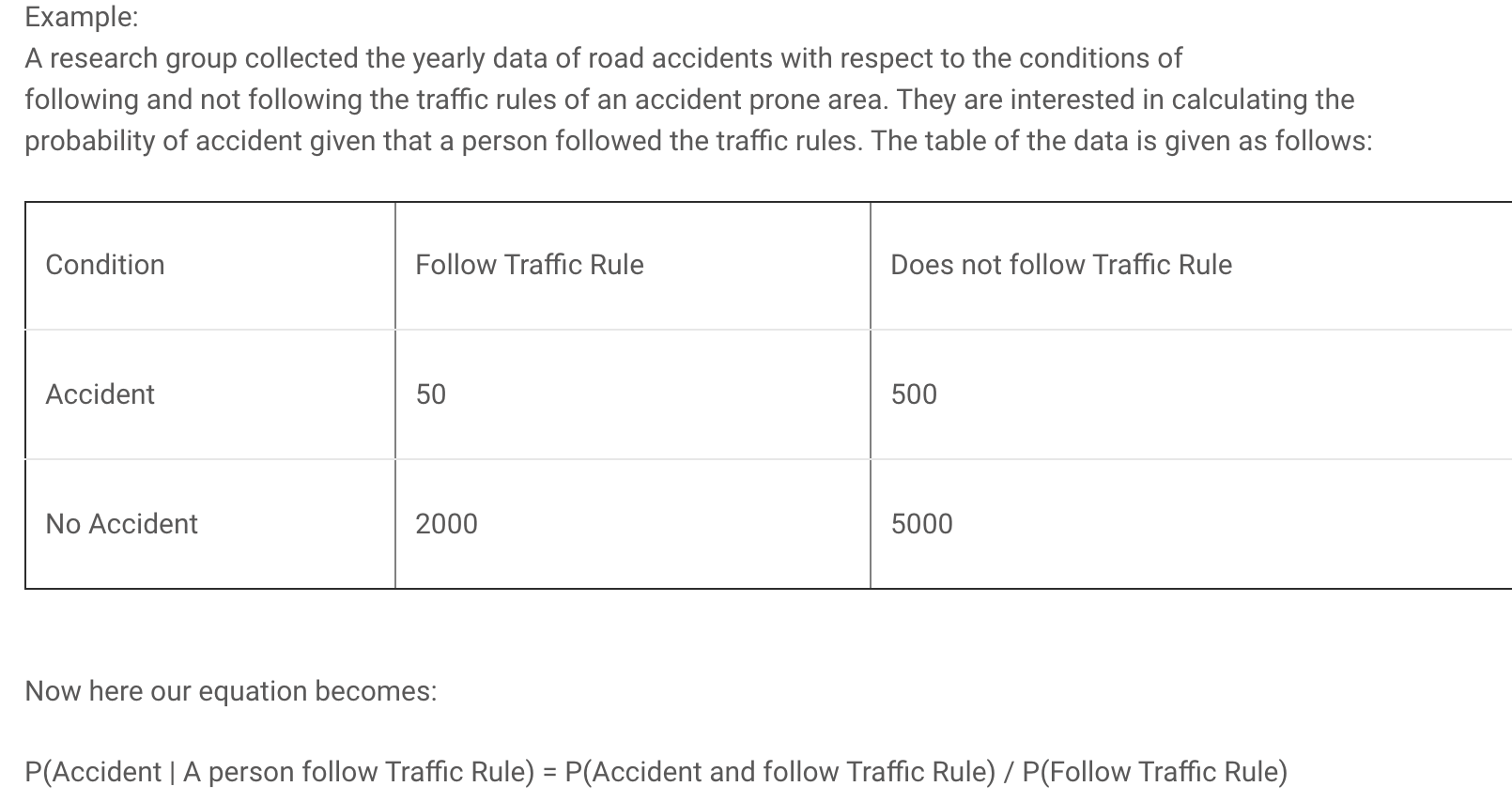
Conceptos basicos
oscarrosete.com
Probabilidad condicional
Un grupo de investigación recolecto información anual de accidentes relacionado a las condiciones de seguimiento a reglas de tránsito.
Estaban interesados en calcular la probabilidad de tener un accidente dado que una persona siguiera las reglas de tránsito. La tabla resume los resultados.
Conceptos basicos
oscarrosete.com
Probabilidad condicional
P (Accidente | siguio reglamento)= P(Accidente y seguir reglas)/ P(Seguir reglas)
50/2500= 0.02439024
Conceptos basicos
oscarrosete.com
Condición inversa
El desayuno de Raul son los bagels y su lunch favorito la pizza.
La probabilidad de que desayune bagel es 0.6
La probabilidad de que coma pizza en el lunch es 0.5
La probabilidad de que el haya desayunado un bagel dado que comio pizza de lonche 0.7
P (A) = 0.6
P (B) = 0.5
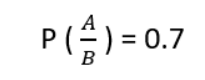
Conceptos basicos
oscarrosete.com
Condición inversa
Si vemos los numeros, la probabilidad de tener un bagel es diferente a la probabilidad de tener un bagel dado que tuvo pizza en el lunch. Esto significa que la probabilidad de tener un bagel es dependiente de tener una pizza en el lunch.
Ahora si queremos saber la probabilidad de comer pizza dado que desayunaste bagel necesitamos conocer el teorema de Bayes.
Conceptos basicos
oscarrosete.com
Teorema de Bayes
El teorema de Bayes describe la probabilidad de un evento basado en el conocimiento previo de las condiciones que pueden estar relacionadas al evento.
Si sabemos la probabilidad condicional,
Podemos utilizar el teorema de Bayes para encontrar la probabilidad inversa.
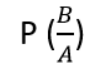
Conceptos basicos
oscarrosete.com
Teorema de Bayes
¿Cómo se llega a la deducción?
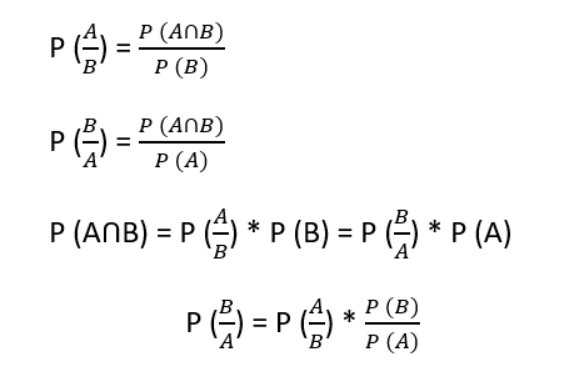
Si quisieramos calcular la probabilidad de que tengamos pizza dado que desayunamos bagel sería:
0.7 * 0.5/0.6
Ejercicio de tarea
En una fábrica de tornillos hay 3 líneas de producción, la primera produce el 35% del total, la segunda el 40% y la tercera el resto. De la primera línea el 12% de su producción son tornillos defectuosos; de la línea 2, el 10% y de la tercera línea el 16%.

oscarrosete.com
si elegimos al azar un tornillo de toda la producción, calcula la probabilidad de que:
a) sea un tornillo defectuoso producido por la línea 1.
b) sea un tornillo no defectuoso producido por la línea 2
c) sea un tornillo defectuoso
d) si es defectuoso producido en línea 3
e) si es defectuoso producido en línea 1
oscarrosete.com
Ejercicio de tarea

Color-changing COVID-19 saliva test

En una clinica se utiliza para predecir covid-19 una prueba con las siguientes caracteristicas:
90% verdaderos positivos
30% falsos positivos
Con base a nuestra experiencia el 20% de los que asisten a hacer la prueba tienen la enfermedad.
Probabilidad de tenerla si obtenemos resultado positivo
Ejercicio Tarea 1
oscarrosete.com

Ejercicio Tarea 2
Una urna A contiene 2 canicas blancas, 2 negras y 4 rojas; una urna B contiene 3 canicas blancas, 3 negras y 2 rojas; una urna C contiene 2 canicas blancas, 4 negras y 4 rojas.
Si se elige una urna al azar y luego se extrae una canica también al azar, halla la probabilidad de que:
a) la canica sea blanca
b) sea negra
c) no sea roja
d) provenga de la urna c si es blanca
oscarrosete.com
e) provenga de la urna B si es negra
f) si es roja que provenga de la urna A
g) si no es blanca que provenga de la urna b
h) si no es negra que provenga de la urna C.

Si se elige una urna al azar y luego se extrae una canica también al azar, halla la probabilidad de que:
Ejercicio Tarea 2
oscarrosete.com
oscarrosete.com
Trabajo de investigación Individual
En una extensión no menor a una cuartilla con sus respectivas referencias deberá investigar y desarrollar los siguientes conceptos:
-
Inferencia bayesiana
-
Naive Bayes Algorithm
-
Naive Bayes Classifier using Kernel Density Estimation
Adicional deberá implementar en el lenguaje de programación de su preferencia utilizando un dataset seleccionado por el estudiante un ejemplo de la implementación del naive bayes algorithm.
oscarrosete.com

oscarrosete.com
Actividad en equipos
En equipos comparar sus implementaciones de naive bayes, seleccionar 1 temática por equipo y realizar una presentación breve (aproximadamente en 5 minutos)
Puntos a explicar:
a. Recolección de los datos
b. Análisis/observaciones general de la información
c. Propósito del algoritmo
c. Observaciones tras aplicar el algoritmo
Nota: Agregar por lo menos 1 visualización

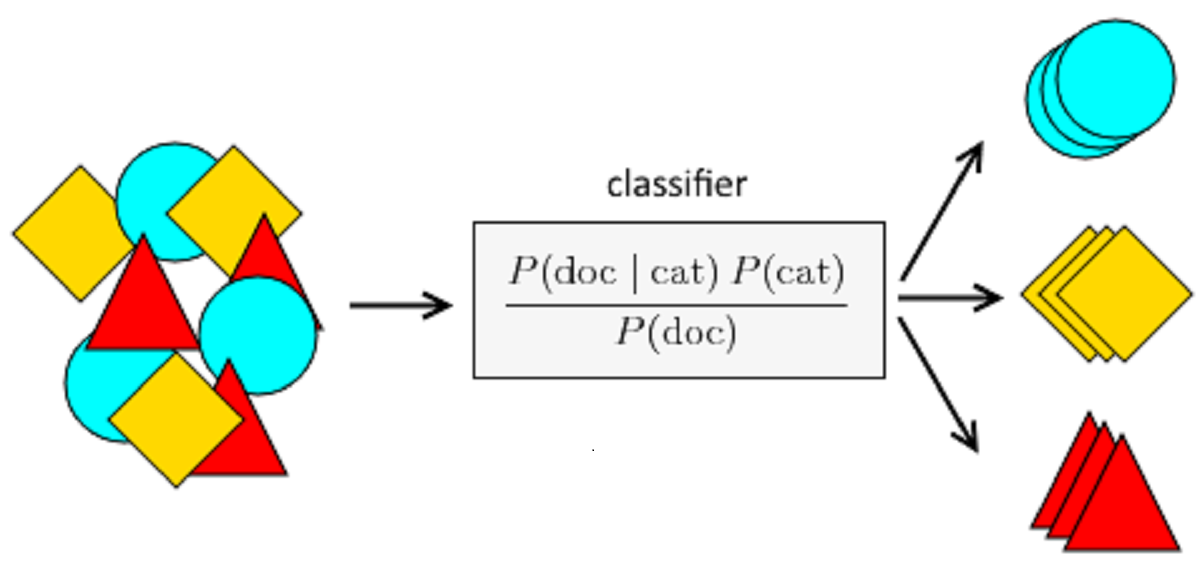
Actividad individual análisis de datos
En jupyter notebook desarrollen los siguientes puntos utilizando.
Deberá subirse a blackboard el archivo .ipynb
-
Seleccionar y recopilar información de un "Data api"
Ejemplos: https://pokeapi.co/, https://swapi.dev/, http://api.football-data.org -
Realizar un análisis descriptivo de la información (Estadística descriptiva)
-
Deberá realizar algún tratamiento a los datos para poder proporcionar conclusiones no evidentes
-
Deberá agregar 4 visualizaciones, utilizar otra libreria como plotly o seaborn.
oscarrosete.com

Teorema de Bayes

Conceptos basicos
oscarrosete.com
Teorema de Bayes
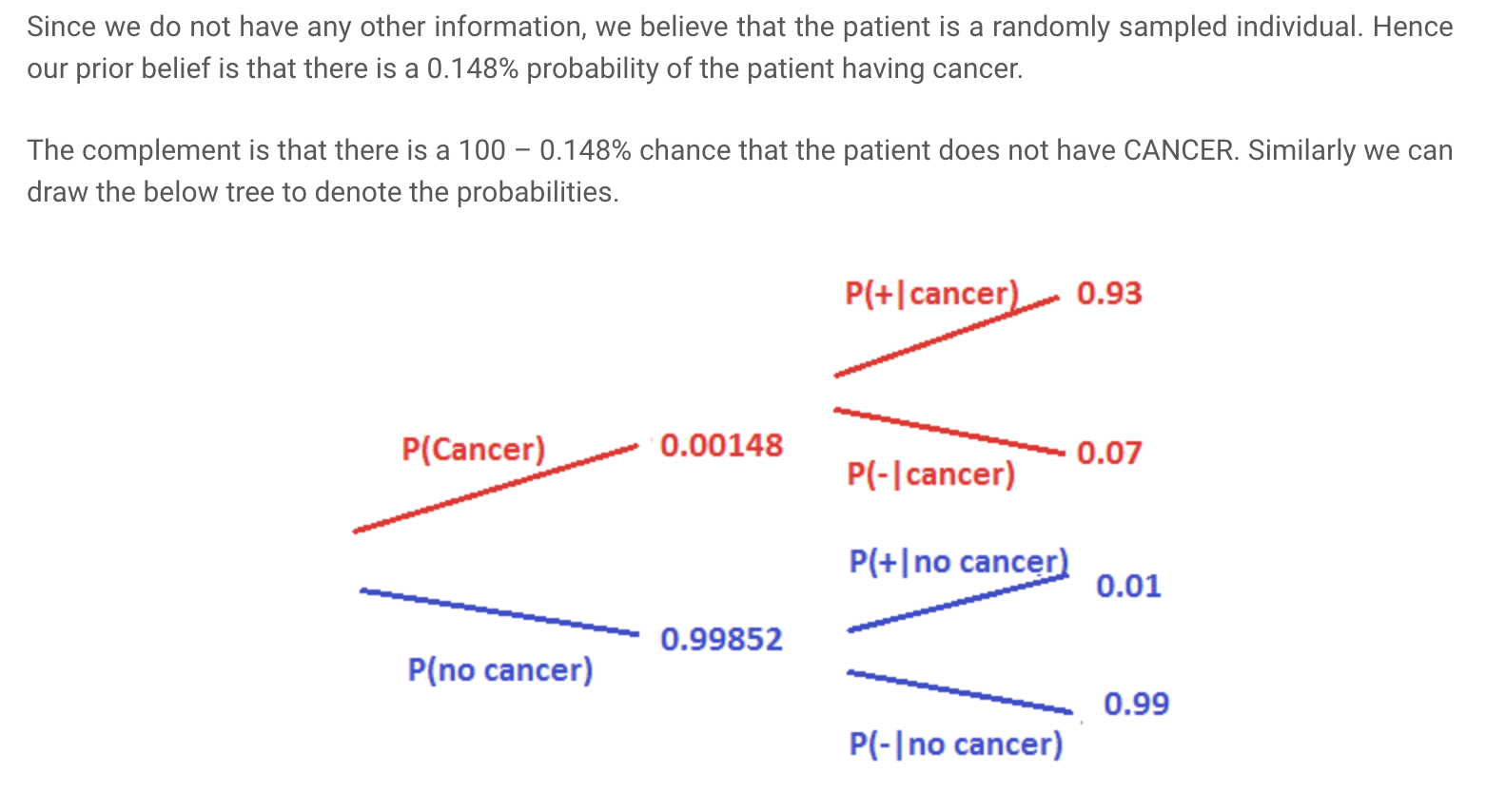
Conceptos basicos
oscarrosete.com

Conceptos basicos
oscarrosete.com
Teorema de Bayes
Actualizacion de creencias
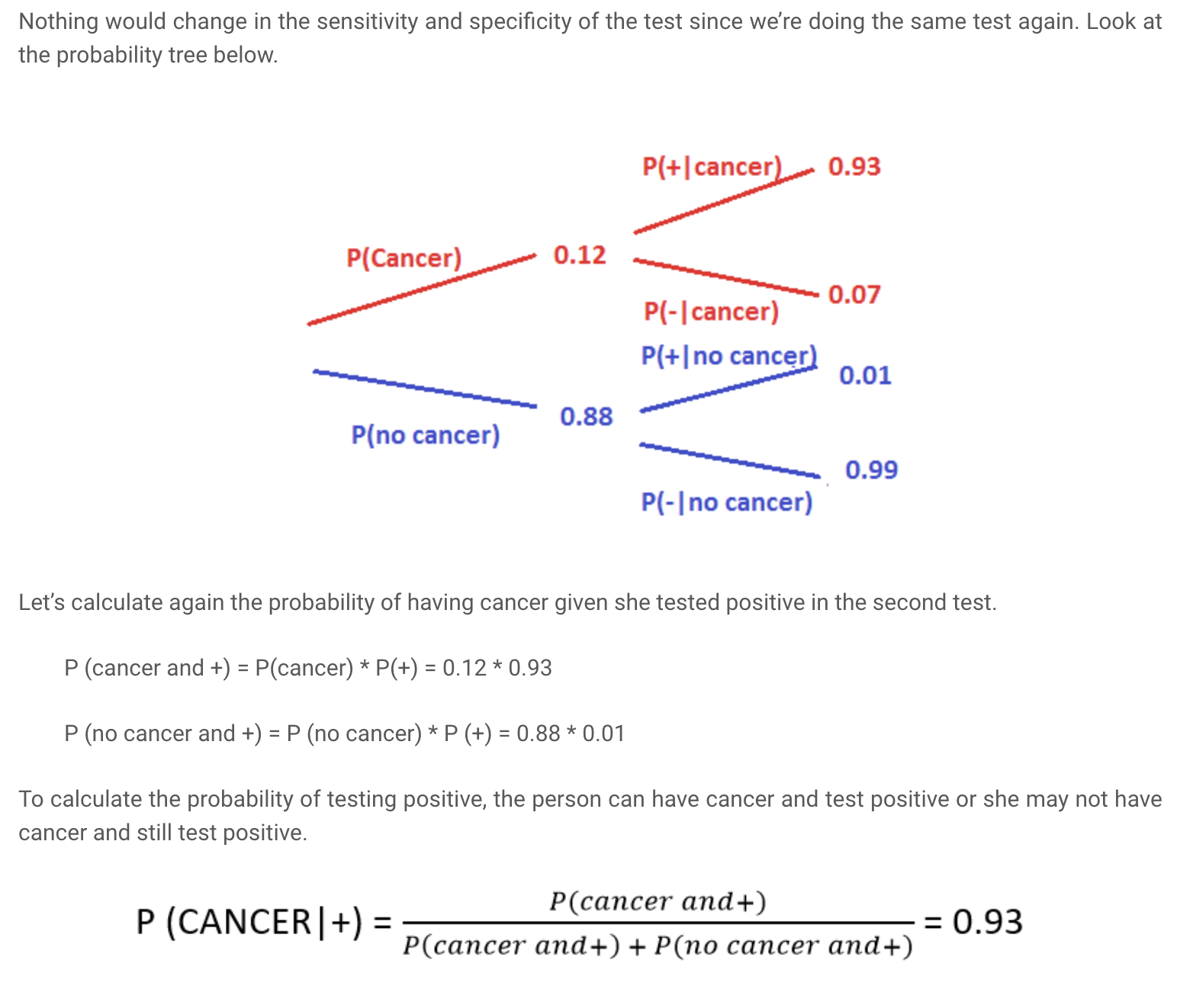
Conceptos basicos
oscarrosete.com
oscarrosete.com
oscarrosete.com
Ejercicio de tarea
En una fabrica de tornillos hay 3 lineas de producción, la primera produce el 35% del total, la segunda el 40% y la tercera el resto. De la primera linea el 12% de su producción son tornillos defectuosos; de la linea 2, el 10% y de la tercera linea el 16%.
oscarrosete.com
oscarrosete.com
Conceptos basicos
si elegimos al azar un tornillo de toda la produccion, calcula la probabilidad de que:
a) sea un tornillo defectuoso producido por la linea 1.
b) sea un tornillo no defectuoso producido por la linea 2
c) sea un tornillo defectuoso
d)si es defectuoso producido en linea 3
e)si es defectuoso producido en linea 1
oscarrosete.com
oscarrosete.com
Color-changing COVID-19 saliva test
En una clinica se utiliza para predecir covid-19 una prueba con las siguientes caracteristicas:
90% verdaderos positivos
30% falsos positivos
Con base a nuestra experiencia el 20% de los que asisten a hacer la prueba tienen la enfermedad.
Probabilidad de tenerla si obtenemos resultado positivo
Ejercicio Tarea 1

oscarrosete.com
oscarrosete.com
Ejercicio Tarea 2
Una urna A contiene 2 canicas blancas, 2 negras y 4 rojas; una urna B contiene 3 canicas blancas, 3 negras y 2 rojas; una urna C contiene 2 canicas blancas, 4 negras y 4 rojas.
Si se elige una urna al azar y luego se extrae una canica también al azar, halla la probabilidad de que:
a) la canica sea blanca
b) sea negra
c) no sea roja
d) provenga de la urna c si es blanca
oscarrosete.com
oscarrosete.com
e) provenga de la urna B si es negra
f) si es roja que provenga de la urna A
g) si no es blanca que provenga de la urna b
h) si no es negra que provenga de la urna C.
Si se elige una urna al azar y luego se extrae una canica también al azar, halla la probabilidad de que:
Ejercicio Tarea 2
oscarrosete.com
Trabajo de investigación
En una extensión no menor a una cuartilla con sus respectivas referencias deberá investigar y desarrollar los siguientes conceptos:
-
Inferencia bayesiana
-
Naive Bayes Algorithm
-
Naive Bayes Classifier using Kernel Density Estimation
Adicional deberá implementar en el lenguaje de programación de su preferencia utilizando un dataset seleccionado por el estudiante un ejemplo de la implementación del naive bayes algorithm.
oscarrosete.com

oscarrosete.com
Trabajo de investigación
En una extensión no menor a dos cuartillas con sus respectivas referencias deberá investigar y desarrollar los siguientes temas:
-
Comparativa Lógica Clásica y Lógica Difusa
-
Utilidad y aplicaciones de la lógica Difusa
-
Comparativa Control difuso y control convencional
-
Comparativa conjuntos certeros y conjuntos difusos.
-
Operaciones entre conjuntos difusos
oscarrosete.com
