Advanced Web Crawler Labs
2023/11/08 MWC 2023

Slide

About me
-
Peter, GitHub
-
Active open source contributor
-
Speaker
-
COSCUP、MOPCON......
-
-
An associate engineer
-
DevOps
-
Back-end
-
System Architecture Researching
-
Web Application Security
-
PHP, Python and JavaScript
-
-
Industrial Technology Research Institute
-
Smart Grid Technology (2017~2021)
-
-
Institute for Information Industry
-
Database, Data platform architecture (2021~)
-

Purposes
-
In these labs, we will understand......
-
how to analyse HTTP requests via the AJAX technique
-
how to use the Selenium/Playwright framework to get/fetch correct responses
-
how to use the Selenium/Playwright framework to bypass new anti-bot approaches
-
Prerequisites
-
Why not using the Docker?
-
Some labs need the desktop environment for demonstration
-
Some packages are very large
-
-
Lab environment setup
-
VirtualBox VM
-
The OVA file
-
At this moment, it will only support web crawlers for the Python
-
In the Lab7, it has the Node.js version
-
-
Lab environment setup
-
All required files are available in the pCloud
-
https://u.pcloud.link/publink/show?code=kZEj7cVZocI5yqukT9XvoBFeKOfJfJiOyw6X
-
If you need the password, the password should be "modernweb2023"
-
-
The lab repository is available on the
-
You need to have......
-
Virtualbox
-
OVA, the virtual machine file link
-
Lab environment setup
Export the OVA file to the VirtualBox
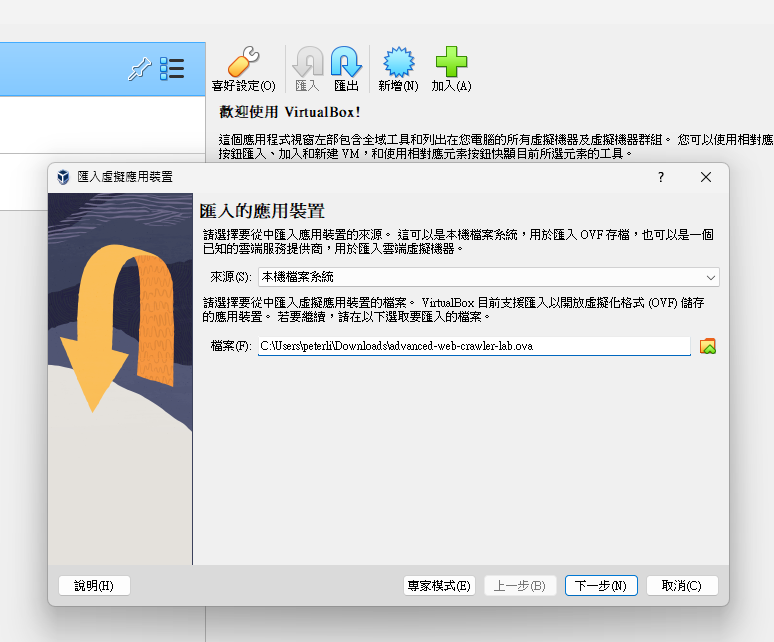
Lab environment setup
Export the OVA file to the VirtualBox
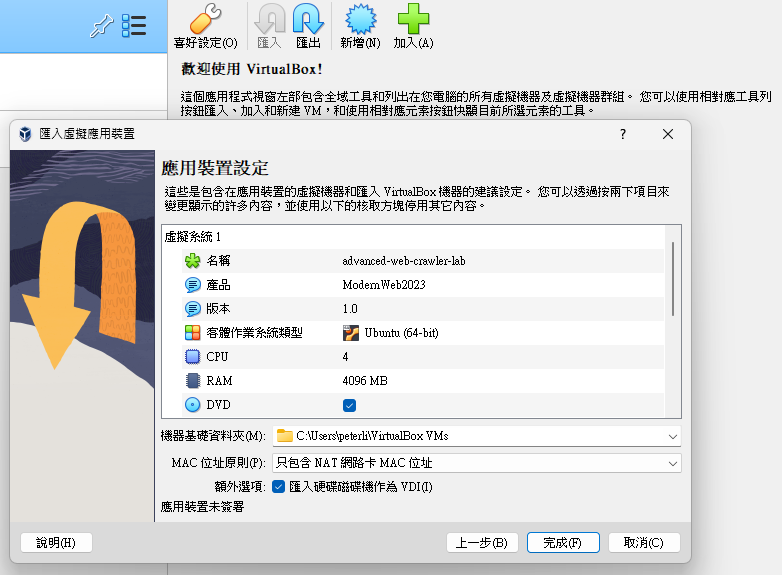
Lab environment setup
Export the OVA file to the VirtualBox
Lab environment setup Troubleshooting
Raising exceptions when running the Labs about the Selenium
......
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.WebDriverException: Message: unknown error: cannot connect to chrome at 127.0.0.1:50691
from session not created: This version of ChromeDriver only supports Chrome version 119
Current browser version is 118.0.5993.117
Stacktrace:
......Solutions: Remember the Google Chrome should be the latest version!
modernweb2023@modernweb2023-VirtualBox:~$ sudo apt-get update
[sudo] password for modernweb2023:
modernweb2023@modernweb2023-VirtualBox:~$ sudo apt-get install google-chrome-stable
Reading package lists... Done
Building dependency tree
Reading state information... Done
The following packages will be upgraded:
google-chrome-stable
......
modernweb2023@modernweb2023-VirtualBox:~$ google-chrome --version
Google Chrome 119.0.6045.123Lab1
-
Fetch these typhoon images from CWA
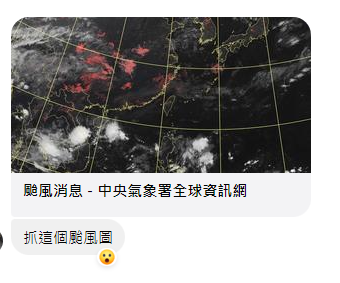
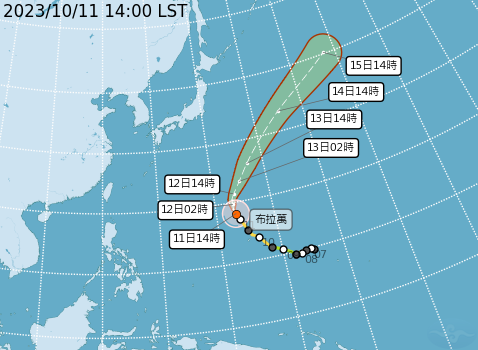
Lab1
-
Typhoon News
-
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_IMGS_202310100000_zhtw.json
Lab1
View the lab1.py
import requests
'''
datetime_str = '202310100000'
datetime_str = '202310100600'
datetime_str = '202310110600'
'''
datetime_str = '202310100600'
host_url = 'https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/%s'
req_url = 'https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_IMGS_%s_zhtw.json' % datetime_str
response = requests.get(req_url)
if response.status_code != 200:
print(response.status_code)
exit(1)
resp_json = response.json()
typhoon_name = resp_json['EACH'][0]['id']
print(typhoon_name)
for img_file_name in resp_json['EACH'][0]['list']:
print(host_url % img_file_name)Lab1
Run the lab1.py
$ pipenv run python lab1.py
BOLAVEN
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-0_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-12_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-24_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-36_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-48_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-72_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-96_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA_202310100600-120_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-0_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-12_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-24_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-36_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-48_BOLAVEN_zhtw.png
https://www.cwa.gov.tw/Data/typhoon/TY_NEWS/PTA72_202310100600-72_BOLAVEN_zhtw.pngLab2

Lab2
Fill the form
Lab2
Submit the form and inspect network activities
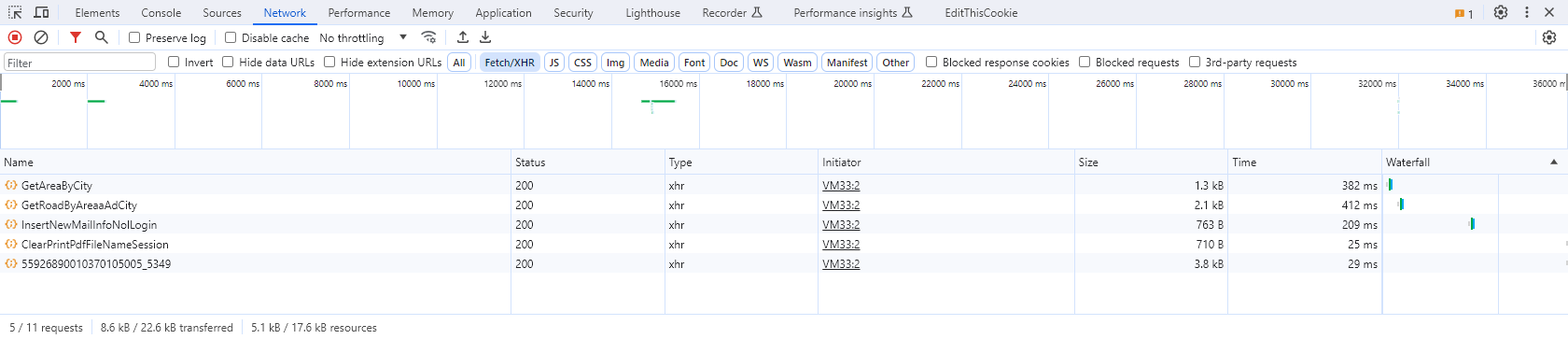
Lab2
Inspect Network activities
-
GetAreaByCity
-
GetRoadByAreaaAdCity
-
InsertNewMailInfoNolLogin
-
ClearPrintPdfFileNameSession
Lab2
InsertNewMailInfoNolLogin
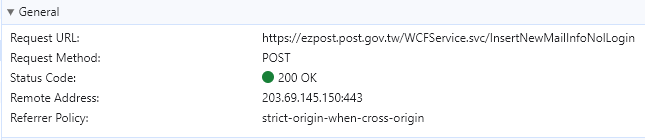
Lab2
InsertNewMailInfoNolLogin
Lab2
InsertNewMailInfoNolLogin
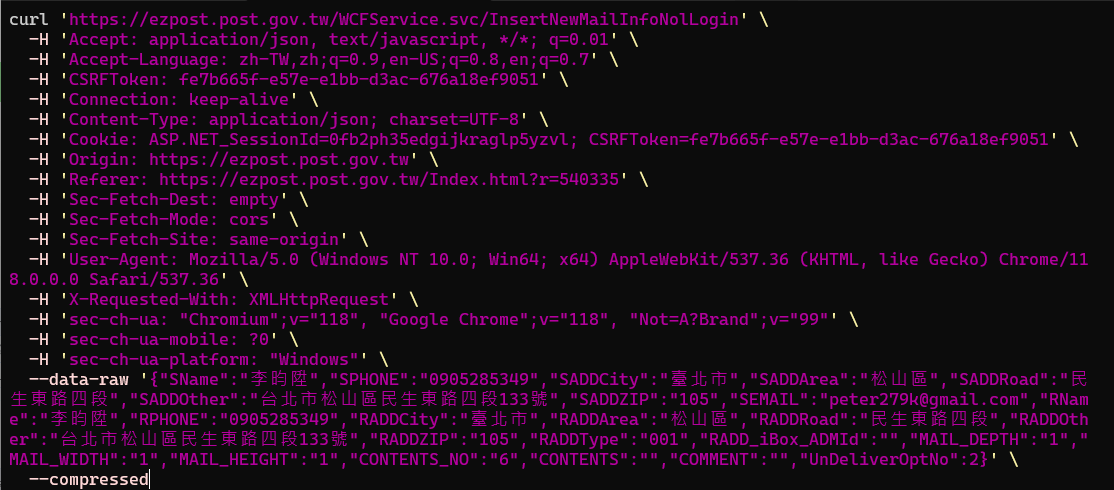
Lab2
InsertNewMailInfoNolLogin
Which headers are important?
-
CSRFToken
-
fe7b665f-e57e-e1bb-d3ac-676a18ef9051
-
-
Cookie
-
ASP.NET_SessionId=0fb2ph35edgijkraglp5yzvl;
-
CSRFToken=fe7b665f-e57e-e1bb-d3ac-676a18ef9051
-
Lab2
InsertNewMailInfoNolLogin
Generating the CSRFToken from the front-end?
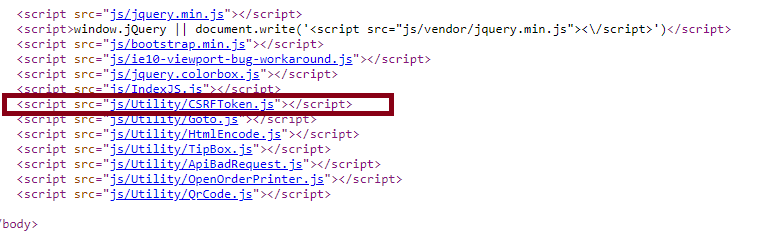
Lab2
Inspecting the CSRFToken.js
function SetCSRFToken(xhr) {
var CSRFToken = GetGuid();
xhr.setRequestHeader('CSRFToken', CSRFToken);
SetCK('CSRFToken', CSRFToken);
}
function extrandom() {
var arr = new Uint32Array(2);
var crypto = window.crypto || window.msCrypto; //相容IE
crypto.getRandomValues(arr);
var mantissa = (arr[0] * Math.pow(2, 20)) + (arr[1] >>> 12)
var extresult = mantissa * Math.pow(2, -52);
return extresult.toString(16).substring(2,6);
}
function GetGuid() {
//function s4() {
// return Math.floor((1 + Math.random()) * 0x10000)
// .toString(16)
// .substring(1);
//}
//return s4() + s4() + '-' + s4() + '-' + s4() + '-' + s4() + '-' + s4() + s4() + s4();
return extrandom() + extrandom() + '-' + extrandom() + '-' + extrandom() + '-' + extrandom() + '-' + extrandom() + extrandom() + extrandom();
}
Lab2
Inspecting the CSRFToken.js
//SetCookie
function SetCK(Name, Value, ExTime) {
if (document.cookie.indexOf(Name) >= 0) {
var expD = new Date();
expD.setTime(expD.getTime() + (-1 * 24 * 60 * 60 * 1000));
var uexpires = 'expires=' + expD.toUTCString();
document.cookie = Name + '=' + Value + '; ' + uexpires;
}
var d = new Date();
d.setTime(d.getTime() + (ExTime));
var expires = 'expires=' + d.toUTCString();
document.cookie = Name + '=' + Value + '; ' + expires;
}
//GetCookie
function GetCK(_Name) {
var name = _Name + '=';
var ca = document.cookie.split(';');
for (var i = 0; i < ca.length; i++)
{
var c = ca[i];
while (c.charAt(0) == ' ') {
c = c.substring(1);
}
if (c.indexOf(name) == 0) {
return c.substring(name.length, c.length);
}
}
return '';
}
Lab2
Wait...If We don't specify the CSRFToken header...
import json
import requests
requests_session = requests.Session()
requests_session.get('https://ezpost.post.gov.tw/Index.html?r=540335')
headers = {
'Content-Type': 'application/json; charset=UTF-8',
}
payload = {
'SName': '李昀陞',
'SPHONE': '0905285349',
'SADDCity': '臺北市',
'SADDArea': '松山區',
'SADDRoad': '民生東路四段',
'SADDOther': '台北市松山區民生東路四段133號',
'SADDZIP': '105',
'SEMAIL': 'peter279k@gmail.com',
Lab2
Wait...If We don't specify the CSRFToken header...
'RName': '李昀陞',
'RPHONE': '0905285349',
'RADDCity': '臺北市',
'RADDArea': '松山區',
'RADDRoad': '民生東路四段',
'RADDOther': '台北市松山區民生東路四段133號',
'RADDZIP': '105',
'RADDType': '001',
'RADD_iBox_ADMId': '',
'MAIL_DEPTH': '1',
'MAIL_WIDTH': '1',
'MAIL_HEIGHT': '1',
'CONTENTS_NO': '6',
'CONTENTS': '',
'COMMENT': '',
'UnDeliverOptNo': 2,
}
response = requests_session.post(
'https://ezpost.post.gov.tw/WCFService.svc/InsertNewMailInfoNolLogin',
headers=headers,
data=json.dumps(payload)
)
print(response.text)Lab2
It seems that we need to specify the CSRFToken header.
$ pipenv run python lab2.py
{"d":"{\"Result\":\"0\",\"Message\":\"CSRFToken Check Fail\"}"}How about specifying the CSRFToken header with arbitrary value?
How about specifying ASP.NET Session header with arbitrary value?
Lab2
$ pipenv run python lab2_arbitrary.py
{"d":"{\"Result\":\"1\",\"Message\":\"56116590010370105002\"}"}Interesting? Arbitrary values are everywhere :)!
import json
import requests
headers = {
'Content-Type': 'application/json; charset=UTF-8',
'CSRFToken': 'arbitrary_token',
'Cookie': 'CSRFToken=arbitrary_token; ASP.NET_SessionId=arbitrary_session',
}
......
response = requests.post(
'https://ezpost.post.gov.tw/WCFService.svc/InsertNewMailInfoNolLogin',
headers=headers,
data=json.dumps(payload)
)
print(response.text)Lab2
$ pipenv run python lab2_arbitrary.py
{"d":"{\"Result\":\"1\",\"Message\":\"56116590010370105002\"}"}Wait...? How to print the PDF file?
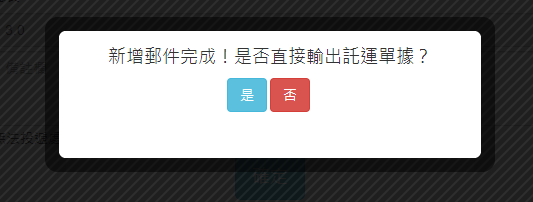
Lab2
Wait...? How to print the PDF file?

Lab2
Wait...? How to print the PDF file?
<input type="button" class="btn btn-info" style="margin:0 3px 0 0;" value="是" onclick="showMailInfoPrint('56165990010370310004')">
<input type="button" class="btn btn-info" style="margin:0 3px 0 0;" value="確定" onclick="window.open('./PrintPDF.aspx?'+ Math.random());disablectrl();">Lab2
Inspecting the PrintPDF behavior
Lab2
Inspecting the PrintPDF behavior
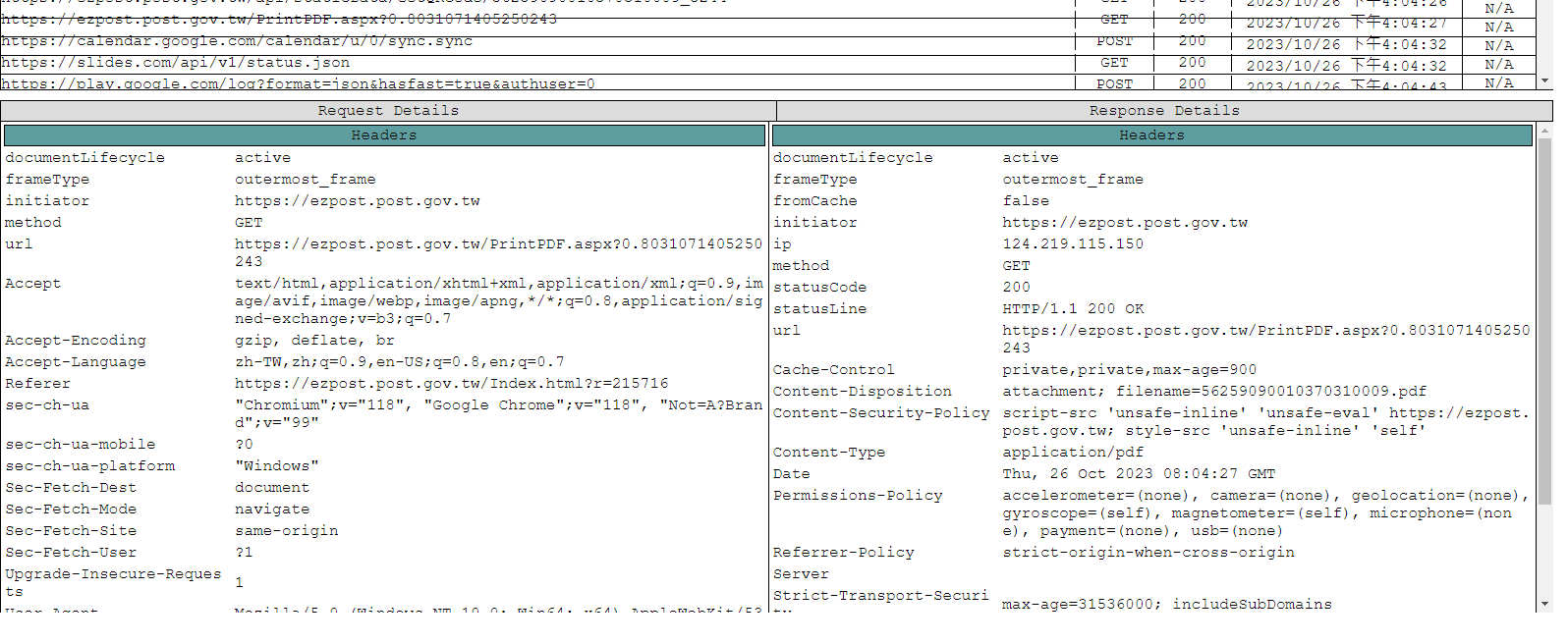
Lab2
It cannot inspect the PrintPDF behavior.
But it can inspect after logging the account.

Lab2
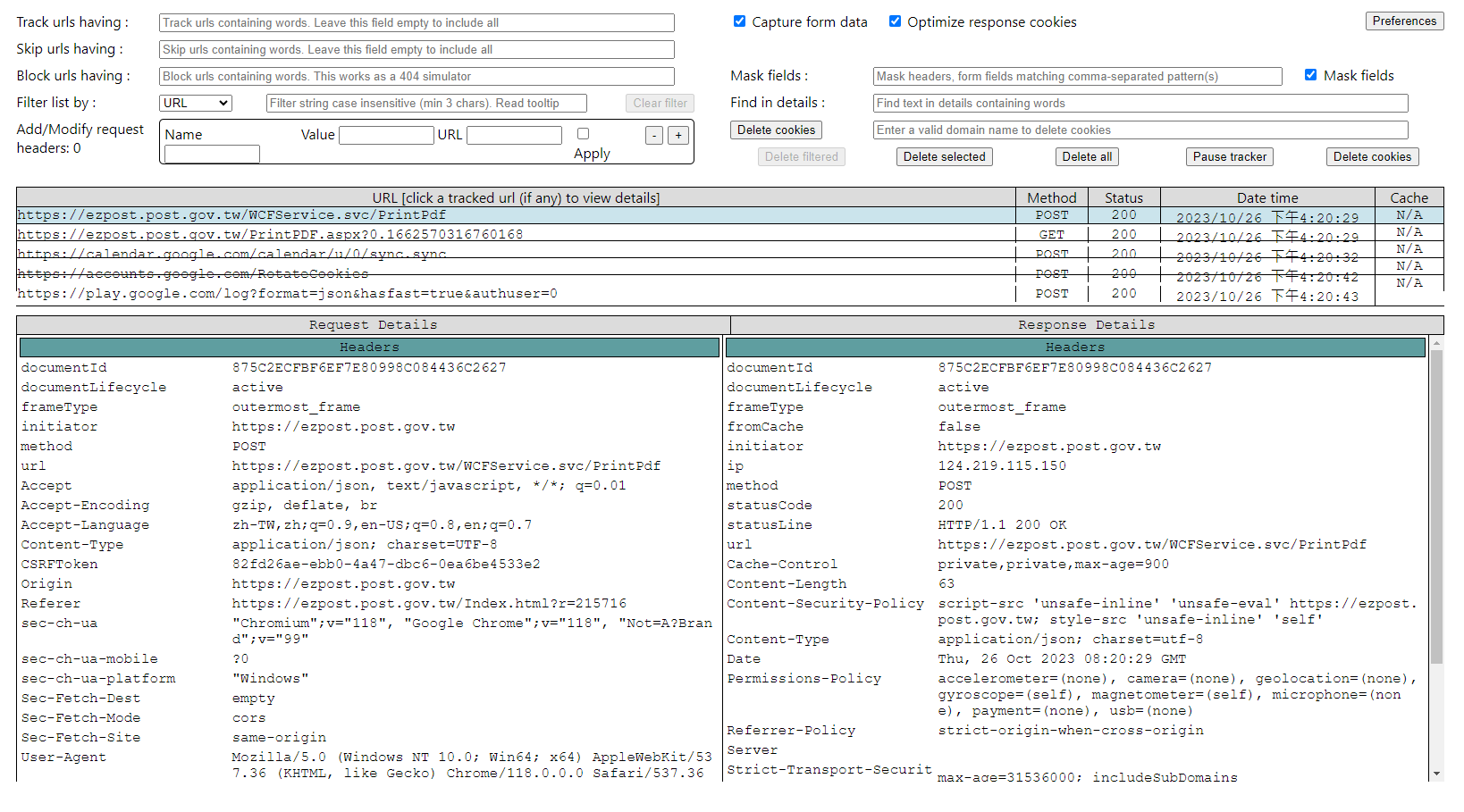
Lab2
It cannot inspect the PrintPDF behavior.
But it can inspect after logging the account.

Lab2
Why the PDF file cannot be downloaded?
The issue seems to be related to the "arbitrary_session"
$ pipenv run python lab2_arbitrary_print.py
The 56314290010370105005.pdf file is saved!
$ cat 56314290010370105005.pdf
<Script language='JavaScript'>alert('檔案無法開啟');</Script>Lab2
Why the PDF file cannot be downloaded?
How about using the "arbitrary formatted session"?
It's interesting, right?
$ pipenv run python get_asp_session_id.py
The ASP.NET Session is: kmk3fpu12i4e0giuwypg1zak
$ pipenv run python lab2_arbitrary_token_print.py
The 56319990010370105003.pdf file is saved!
$ file -i 56319990010370105003.pdf
56319990010370105003.pdf: application/pdf; charset=binaryheaders = {
'Content-Type': 'application/json; charset=UTF-8',
'CSRFToken': 'arbitrary_token',
'Cookie': 'CSRFToken=arbitrary_token; ASP.NET_SessionId=0tkrkvxiqmfpl0cl143x4f5s',
}Selenium Architecture
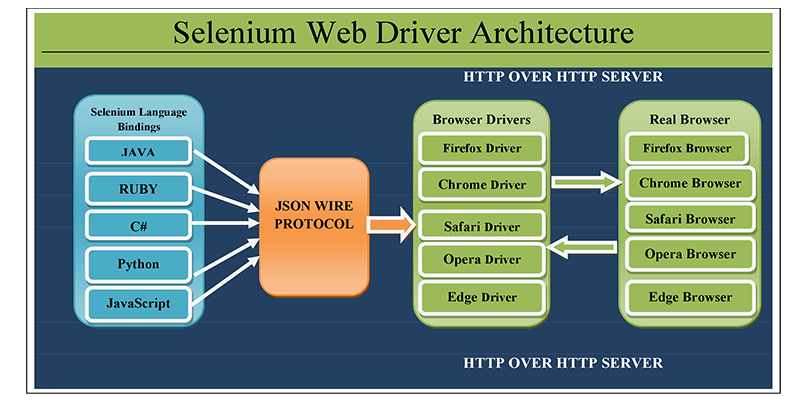
Lab3
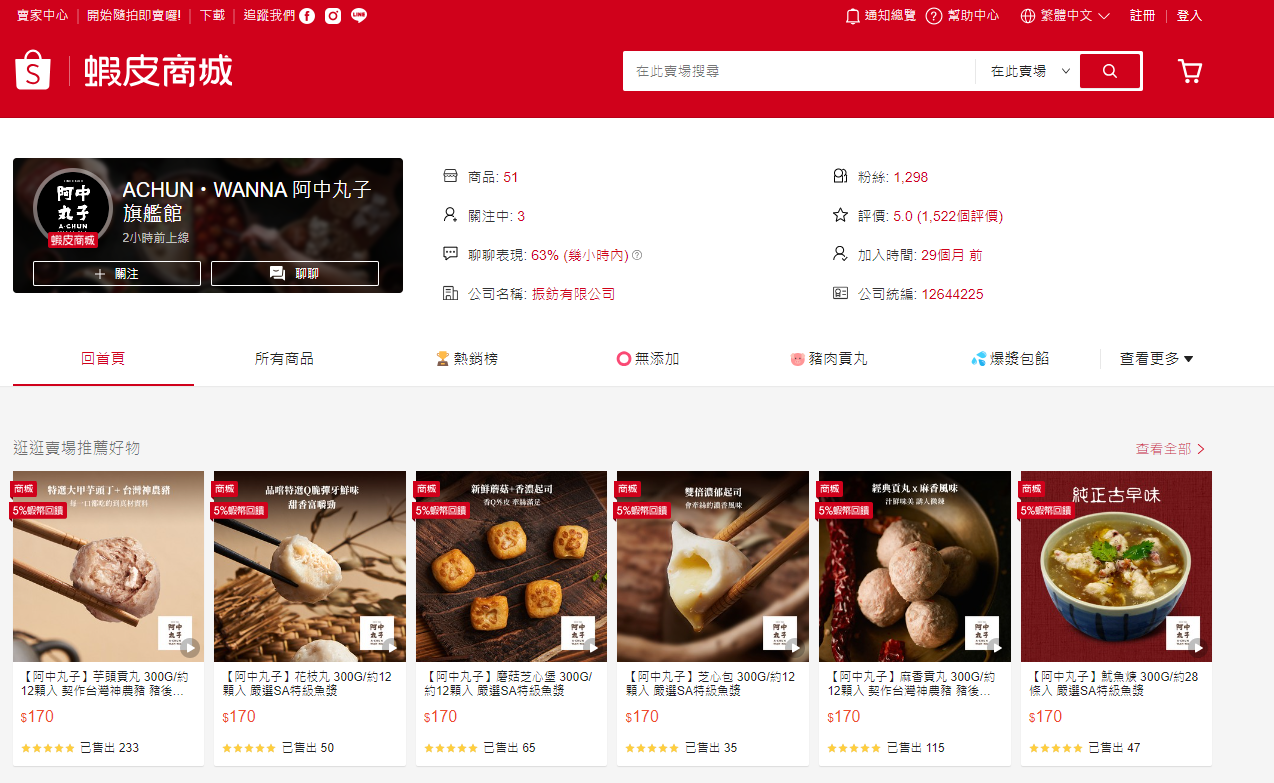
Lab3
Lab3
https://shopee.tw/achunwanna?page=1&sortBy=sales
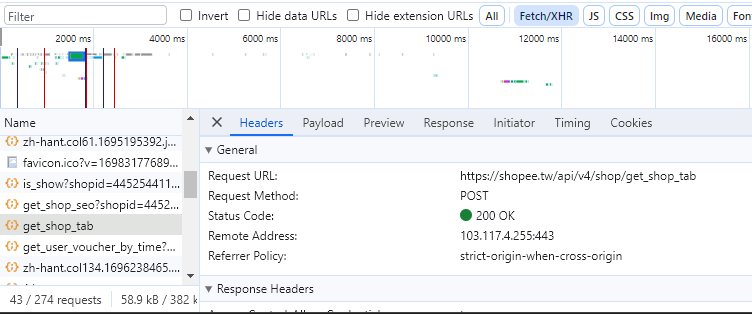
Lab3
https://shopee.tw/achunwanna?page=1&sortBy=sales

Problem: Many header values are not easy to be generated.
https://shopee.tw/api/v2/search_items/....
Lab3
How about using the Selenium to fetch product datasets?
$ cat Pipfile
[[source]]
url = "https://pypi.python.org/simple"
verify_ssl = true
name = "pypi"
[packages]
requests = "*"
selenium = "4.10.0"
selenium-wire = "*"
beautifulsoup4 = "*"
webdriver-manager = "4.0.1"
undetected-chromedriver = "*"
[dev-packages]
pytest = "*"$ google-chrome --version
Google Chrome 118.0.5993.117Lab3
View the lab3_non_headless.py
import os
import csv
import time
import random
import datetime
import requests
from bs4 import BeautifulSoup
import undetected_chromedriver as webdriver
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service as ChromeService
vendors = []
shopee_id = 'achunwanna'
brand_name = '阿中丸子'
vendors.append({'shopee_id': shopee_id, 'brand_name': brand_name})
csv_str = '廠商名稱,產品名稱,售價,優惠價格,優惠開始日期,優惠結束日期,搜尋日期,資料來源,產品網址\n'
for vendor in vendors:
......Lab3
Run the lab3_non_headless.py
$ pipenv run python lab3_non_headless.py
Sleeping from 60 to 100 seconds...
Sleeping from 60 to 100 seconds...
Sleeping from 60 to 100 seconds...
Parsing page source contents is started (achunwanna).
The ./data/data_2023-10-27.csv file is saved.
Crawling is done.
$ ls -al data/data_2023-10-27.csv
$ cat data/data_2023-10-27.csv
廠商名稱,產品名稱,售價,優惠價格,優惠開始日期,優惠結束日期,搜尋日期,資料來源,產品網址
阿中丸子,"【阿中丸子】起士牛肉丸 200G/約8顆入 紐澳草飼牛",170,N/A,N/A,N/A,2023-10-27,蝦皮購物,https://shopee.tw/【阿中丸子】起士牛肉丸-200G-約8顆入-紐澳草飼牛-i.445254411.8762005365?sp_atk=cd6a7ae1-42d9-439f-9d2d-4492acef79ee&xptdk=cd6a7ae1-42d9-439f-9d2d-4492acef79ee
阿中丸子,"【阿中丸子】黃金蝦霸天 300G/約12片入 嚴選SA特級魚漿",170,N/A,N/A,N/A,2023-10-27,蝦皮購物,https://shopee.tw/【阿中丸子】黃金蝦霸天-300G-約12片入-嚴選SA特級魚漿-i.445254411.8761775101?sp_atk=0c47fe56-3494-4590-b724-c0fa916f9339&xptdk=0c47fe56-3494-4590-b724-c0fa916f9339
......Lab4
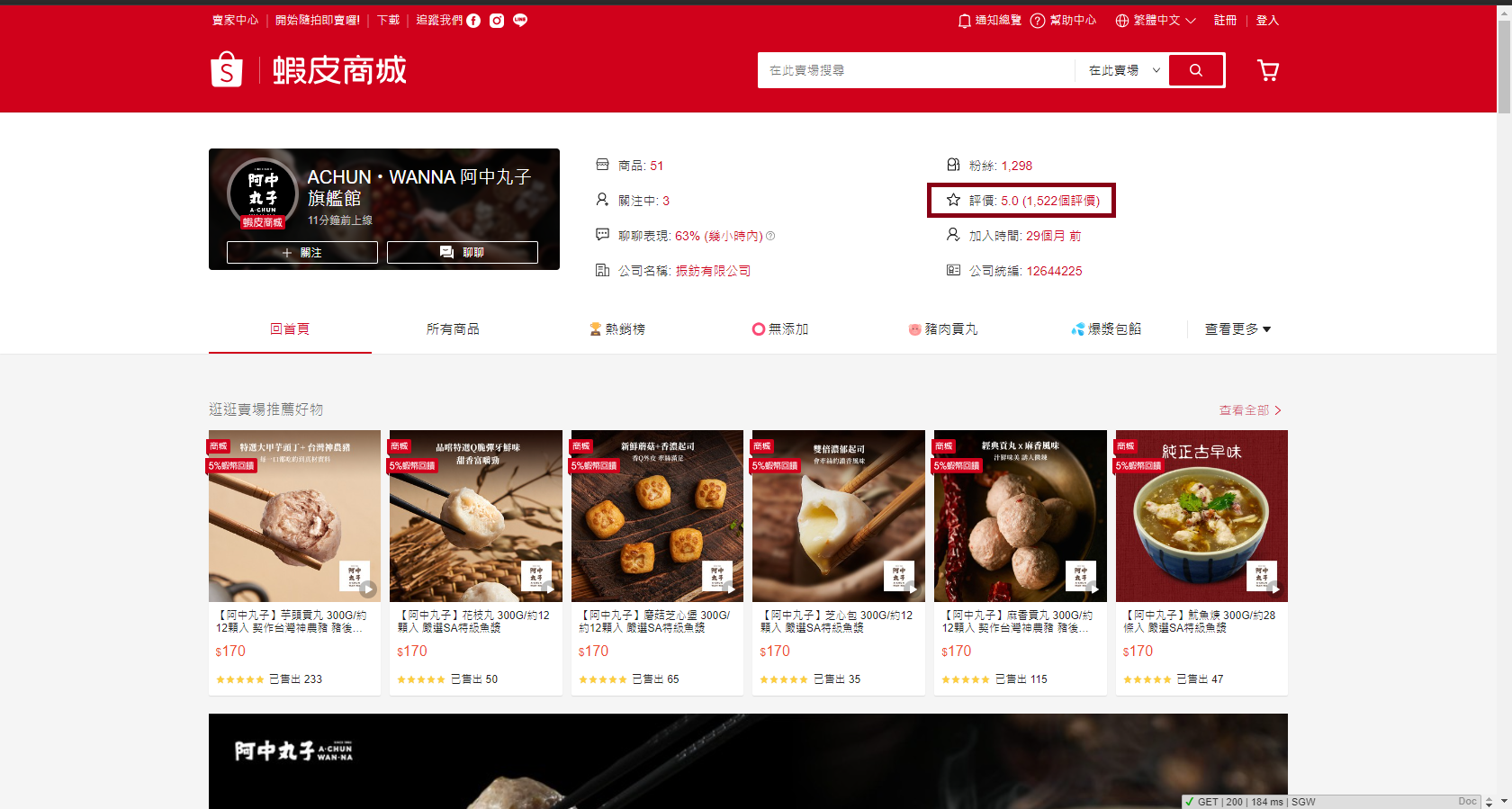
Lab4
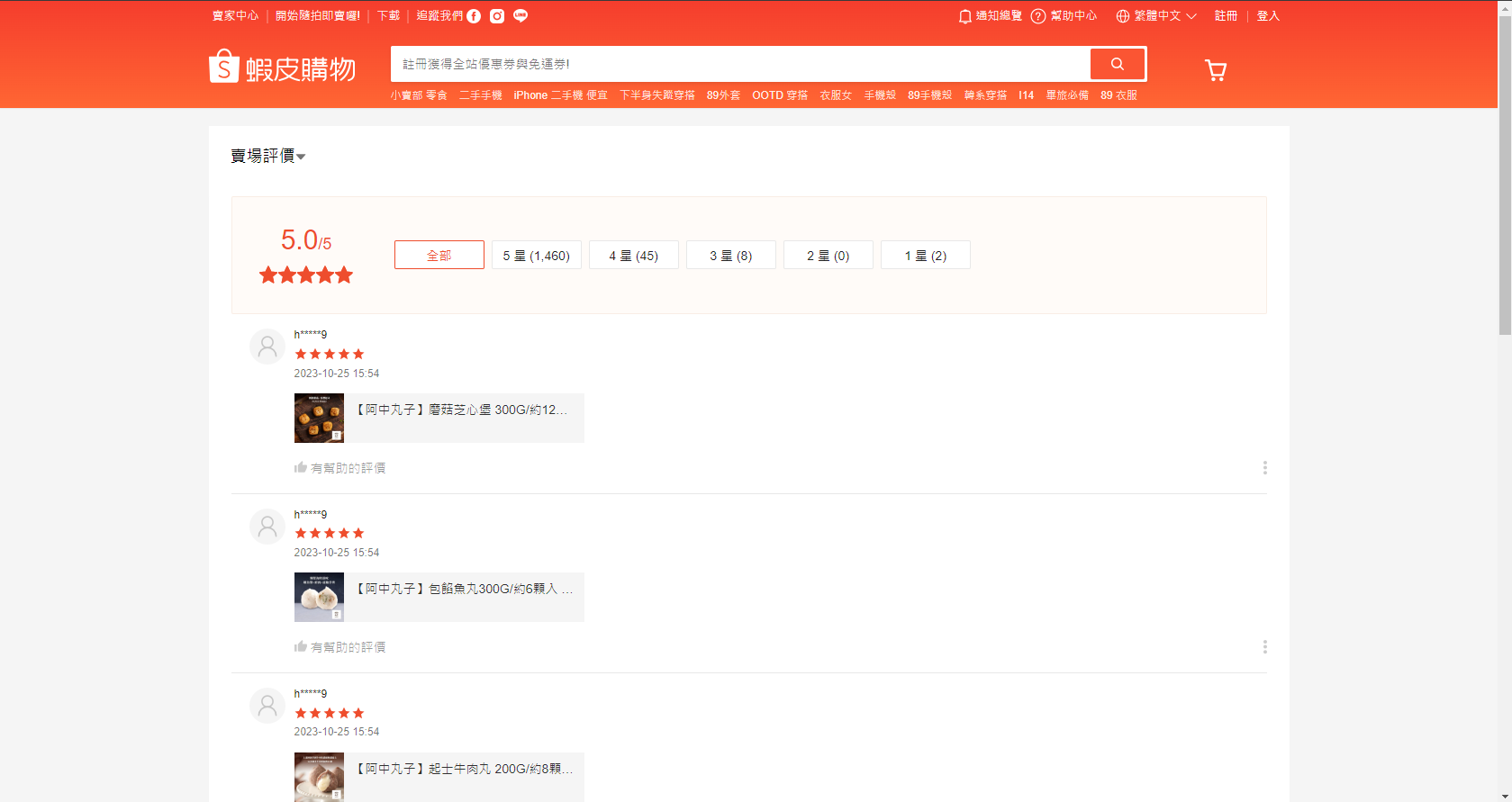
Lab4
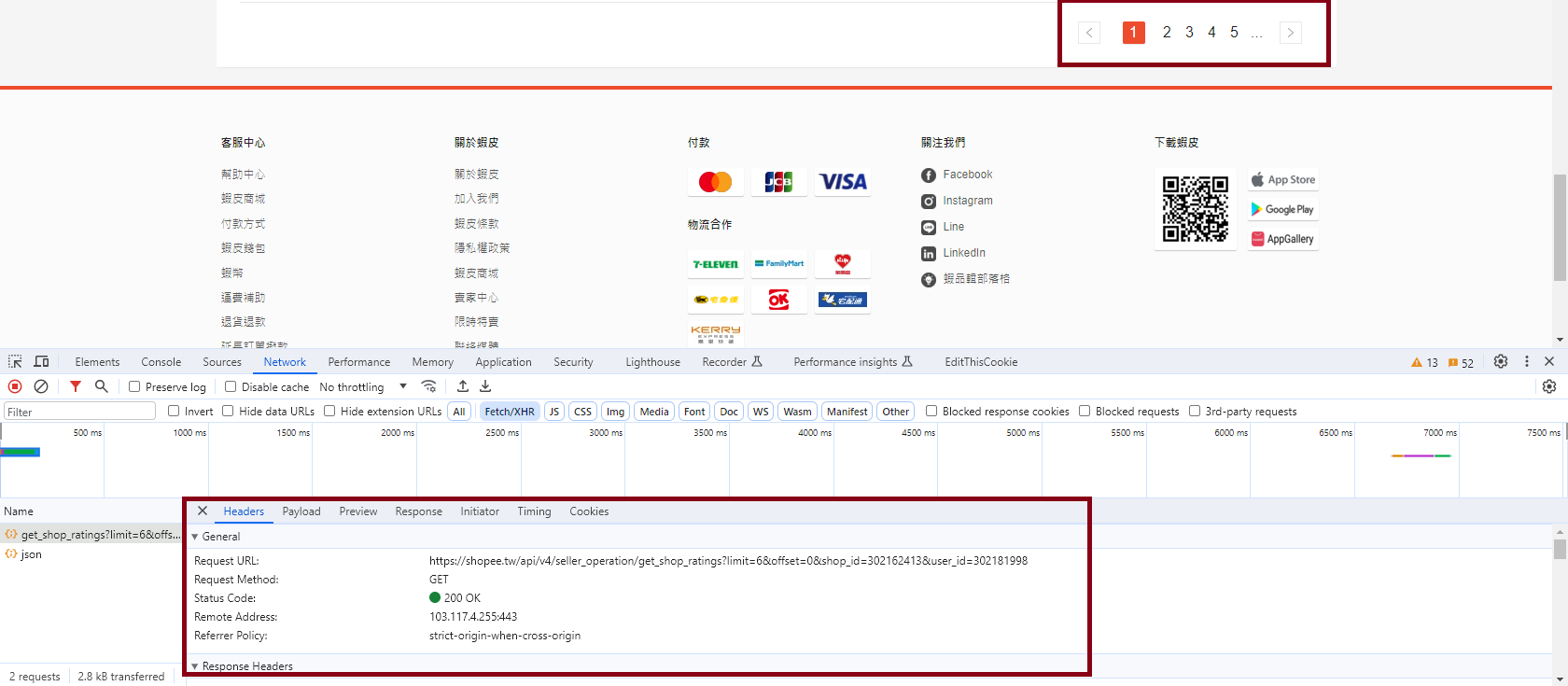
Finding the secret rating API
Lab4
Finding the secret rating API
-
Example API URL
-
https://shopee.tw/api/v4/seller_operation/get_shop_ratings?
-
limit=6&offset=0&shop_id={shop_id}&user_id={user_id}
-
Next page (pagination)
-
limit=6&offset=6&shop_id={shop_id}&user_id={user_id}
-
-
Lab4
The part of secret rating API JSON response
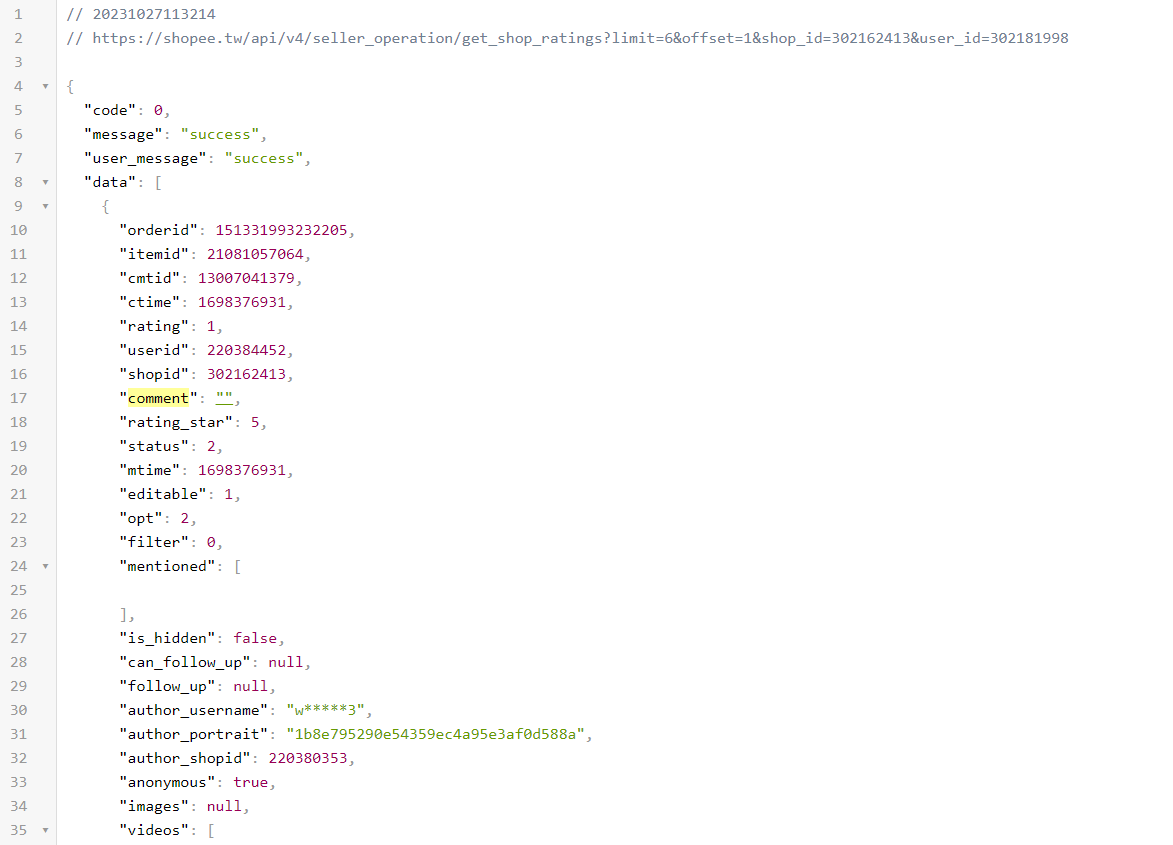
Lab4
The part of secret rating API JSON response (no data)
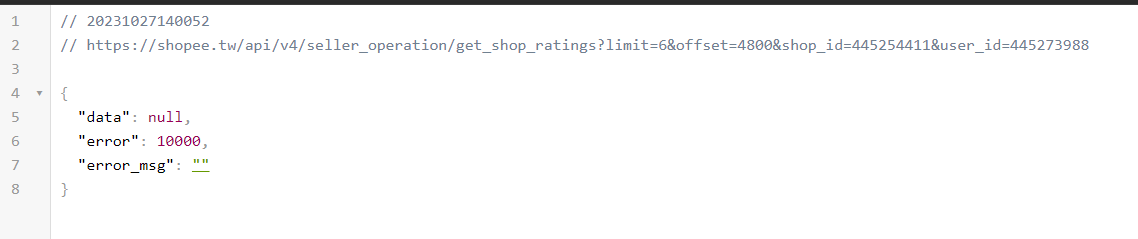
Lab4
Running the lab4_fetcher.py
import random
import requests
headers = {
'Sec-Ch-Ua': '"Chromium";v="118", "Google Chrome";v="118", "Not=A?Brand";v="99"',
'Sec-Ch-Ua-Mobile': '?0',
'Sec-Ch-Ua-Platform': 'Windows',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36',
}
req_url = 'https://shopee.tw/api/v4/seller_operation/get_shop_ratings?limit=6&offset=1&shop_id=302162413&user_id=302181998'
response = requests.get(req_url, headers=headers)
print(response.json())Lab4
Running the lab4_fetcher.py
$ pipenv run python lab4_fetcher.py
f{'message': 'success', 'user_message': 'success', 'data': [{'orderid': 151886912284354, 'itemid': 23547819926, 'cmtid': 13008505853, 'ctime': 1698385502, 'rating': 1, 'userid': 27471927, 'shopid': 302162413, 'comment': '', 'rating_star': 5, 'status': 2, 'mtime': 1698385502, 'editable': 1, 'opt': 2, 'filter': 0, 'mentioned': [], 'is_hidden': False, 'can_follow_up': None, 'follow_up': None, 'author_username': 'l*****o', 'author_portrait': '', 'author_shopid': 27470568, 'anonymous': True, 'images': None, 'videos': [], 'product_items': [{'itemid': 23547819926, 'shopid': 302162413, 'name': '【大成食品X森森燒肉】鹽烤黑蜜豬五花 300g/包(多包組) 聯名 燒烤 烤肉 燒肉 台灣豬 黑蜜豬 五花肉 超取', 'image': 'tw-11134207-7qul2-lj3js9rjsddg3d', 'is_snapshot': 1, 'snapshotid': 13464405799, 'modelid': 167746117032, 'model_name': '單包組(300g/包)', 'options': None}], 'delete_reason': None, 'delete_operator': None, 'item_rating_reply': None, 'tags': None, 'editable_date': 1700977502, 'show_reply': None, 'like_count': None, 'liked': None, 'sync_to_social': False, 'detailed_rating': {'product_quality': 5, 'seller_service': 5, 'delivery_service': 5}, 'exclude_scoring_due_low_logistic': False, 'loyalty_info': None, 'template_tags': [], 'has_template_tag': False, 'sync_to_social_toggle': None, 'sip_iLab5
https://www.google.com/search?q=阿中丸子企業總部(振鈁有限公司)
Lab5
It needs to have multiple interactions about manipulating Web browser
Lab5
The manipulating web browser approaches are as follows:
-
Remember, the manipulating behavior should be the human!
-
Go to the current page content via the specific URL
-
Waiting for the page to be loaded correctly
-
Click the specific element to open the review dialog
-
Waiting for the dialog to be open
-
Scrolling the specific element to load the next review contents
-
After scrolling the review dialog is completed, fetch the page source
-
Done.
Lab5
When do we stop scrolling the review dialog?
-
It seems that It doesn't have the current end condition
-
It's not easy to check whether scrolling dialog reaches the bottom
-
We can estimate the scrolling counter
-
We can assume that the counter can include all rating comments.
-
Lab5
Run the lab5_fetcher_non_headless.py
Lab5
Parsed data
$ cat data/data_2023-10-27.csv
廠商名稱,評論內容,評論內容hash,貼文來源
阿中丸子,"自訂日期範圍...",b8c91669bc800b37abe1a910279a04e3390af954,Google評論
阿中丸子,"丸子絕對是新竹市美食之一,這家阿中丸子充分發揮新竹市丸子特點。你要吃各種丸子類甚至炸物這家絕對都有。",3749d4d6825f2a750dbcd1897449307cf18dc620,Google評論
阿中丸子,"",da39a3ee5e6b4b0d3255bfef95601890afd80709,Google評論Lab6
A social networking website without login account
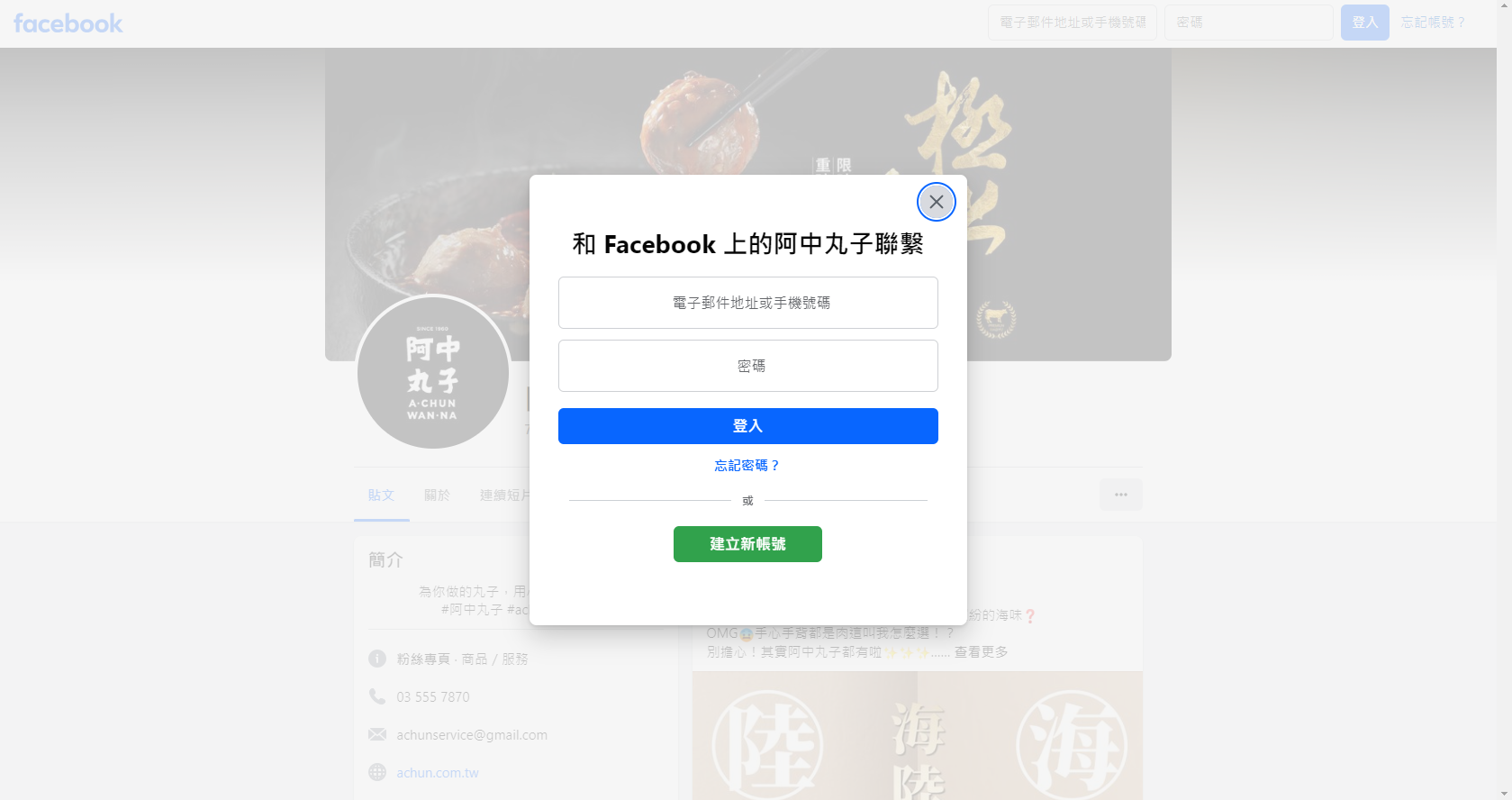
Lab6
Thinking about manipulating website approach
-
Loading the specific website URL
-
Close the popup
-
<div aria-label="Close" .....>.....</div>
-
<div aria-label="關閉" .....>.....</div>
-
-
Facebook will detect the client locale
-
Be aware of the localization!
-
-
Waiting for page to do above steps
-
Scroll the body height to get the next page post contents
-
Waiting for page to do above steps
-
After above fetching loop is completed, parsing page_source contents
Lab6
When to stop the page contents fetching work?
-
It doesn't know current page posts
-
The proper/possible way is to set the scrolling counter
Lab6
Run the lab6_fetcher_non_headless.py
Lab6
Run the lab6_fetcher_non_headless.py
$ cat ./data/data_2023-10-27.csv
廠商名稱,貼文摘要,貼文摘要hash,貼文內容,貼文來源
阿中丸子,"海陸大比拚:陸上霸主VS海中鮮味你愛的是~鮮嫩多汁的牛肉/豬肉還是滿滿繽紛的海味OMG手心手背都是肉這叫我怎麼選!?別擔心!其實阿中丸子都有啦… See more",991a0761049e530e2a6727a02d68a86e9bc74ddb,"海陸大比拚:陸上霸主VS海中鮮味你愛的是~鮮嫩多汁的牛肉/豬肉還是滿滿繽紛的海味OMG手心手背都是肉這叫我怎麼選!?別擔心!其實阿中丸子都有啦… See more",Facebook
阿中丸子,"吼~~~怎麼可以這麼蝦再這樣繼續蝦下去,我該怎麼離開 #黃金蝦霸天 ?整隻蝦伴入乳酪丁的濃郁香氣嚴選天然蝦仁,整隻放入不泡水、不添加化學硼砂;乳酪丁滑順香醇、令人欲罷不能不… See more",e47b339082701460fa1578d40d664156e82c9d74,"吼~~~怎麼可以這麼蝦再這樣繼續蝦下去,我該怎麼離開 #黃金蝦霸天 ?整隻蝦伴入乳酪丁的濃郁香氣嚴選天然蝦仁,整隻放入不泡水、不添加化學硼砂;乳酪丁滑順香醇、令人欲罷不能不… See more",Facebook
阿中丸子,"在家也能吃鐵板燒未免也太幸福聽!這滋滋作響的油煎聲~聞!這香噴噴、乓共共的迷人味道~#起司牛肉丸 的香氣已經檔不住了,快快讓它上桌吧四步驟即享居家鐵板燒-【黑… See more",d31087d0d82568514fb1ebaeefb5e9e7b3b1bd88,"在家也能吃鐵板燒未免也太幸福聽!這滋滋作響的油煎聲~聞!這香噴噴、乓共共的迷人味道~#起司牛肉丸 的香氣已經檔不住了,快快讓它上桌吧四步驟即享居家鐵板燒-【黑… See more",Facebook
阿中丸子,"欸!你問我在神氣什麼哼哼~~我們阿中這麼「有料」當然要神氣一下啊!看到這個餡料滿滿爆漿感十足的丸子沒有?只要咬一口就會直接炸出來的美味到底誰受得了… See more",8c2f0be1ec93a224ff3c9063323be1f6e1f1f470,"欸!你問我在神氣什麼哼哼~~我們阿中這麼「有料」當然要神氣一下啊!看到這個餡料滿滿爆漿感十足的丸子沒有?只要咬一口就會直接炸出來的美味到底誰受得了… See more",Facebook
阿中丸子,"這個四天連假你打算怎麼過是要去露營踏青?朋友聚餐?還是~宅家煮丸子無論你想怎麼過,阿中丸子都能美味伴你遊!最快速方便的美味丸子就在阿中速… See more",4e8e97feacea4b8726fe39853fea19be7af17f34,"這個四天連假你打算怎麼過是要去露營踏青?朋友聚餐?還是~宅家煮丸子無論你想怎麼過,阿中丸子都能美味伴你遊!最快速方便的美味丸子就在阿中速… See more",Facebook
阿中丸子,"吃進肚子裡的,阿中比誰都還要在意再好吃的料理若使用的食材來源不明甚至可疑,對敏感的幼童、年長者來說很容易就會造成腸胃問題!唯有定期檢驗、認證才能真正保障食品安全阿中丸子全面經過多項 #SGS檢驗認證且… See more",babdec741211a4da81eea5a4a30202ddc3ab992d,"吃進肚子裡的,阿中比誰都還要在意再好吃的料理若使用的食材來源不明甚至可疑,對敏感的幼童、年長者來說很容易就會造成腸胃問題!唯有定期檢驗、認證才能真正保障食品安全阿中丸子全面經過多項 #SGS檢驗認證且… See more",Facebook
阿中丸子,"吃膩大魚大肉了嗎來碗簡單養生的拌麵吧!假日的早晨最適合悠閒一下,在享受與陽光問好的輕鬆食光裡,怎麼可以缺少這道兼具美味與健康的乾拌素麵呢#阿中香菇貢丸 與秋葵、山藥的養生盛宴就此展開快速四步驟拌麵上桌!-【… See more",d7540e05bd75eb11e60500b36b5e0b1684eb5f00,"吃膩大魚大肉了嗎來碗簡單養生的拌麵吧!假日的早晨最適合悠閒一下,在享受與陽光問好的輕鬆食光裡,怎麼可以缺少這道兼具美味與健康的乾拌素麵呢#阿中香菇貢丸 與秋葵、山藥的養生盛宴就此展開快速四步驟拌麵上桌!-【… See more",Facebook
阿中丸子,"唐伯虎曾經有一句對聯曰:「八目共賞,賞花賞月 #吃丸子 」……咦?不是嗎?又到了每年最令人期待的節日之一先在此預祝大家中秋佳節愉快… See more",4013f17049c3b6f88982856b1937083830efd16e,"唐伯虎曾經有一句對聯曰:「八目共賞,賞花賞月 #吃丸子 」……咦?不是嗎?又到了每年最令人期待的節日之一先在此預祝大家中秋佳節愉快… See more",Facebook
阿中丸子,"想跟阿中當好朋友的舉手🙋🙋🙋現在官網會員全面熱情招募中• 新會員即享抵用金$100• 滿額還有贈送紅利金快來報到吧https://www.achun.com.tw/新朋… See more",6ba0e2c918d322346e8c6d2b8f31aa8a97976b85,"想跟阿中當好朋友的舉手🙋🙋🙋現在官網會員全面熱情招募中• 新會員即享抵用金$100• 滿額還有贈送紅利金快來報到吧https://www.achun.com.tw/新朋… See more",Facebook
阿中丸子,"一個小攤販,一顆顆貢丸子,以及許多許多的人情味那年在菜市場轉角處的無名小攤販人客鄰居口中的那個 #賣丸子的阿中至今走過了數個年頭,始終懷著感恩與初心因為有你,才有阿中… See more",590e0e18acc6f108d1475f5b517857e5c06669b9,"一個小攤販,一顆顆貢丸子,以及許多許多的人情味那年在菜市場轉角處的無名小攤販人客鄰居口中的那個 #賣丸子的阿中至今走過了數個年頭,始終懷著感恩與初心因為有你,才有阿中… See more",Facebook
阿中丸子,"中秋烤肉組-超值7入990免運,為您送上滿滿的節慶祝福! https://www.achun.com.tw/products/20230918 優惠詳情: … See more",6c655f8d686a6fcb61c4d121953a81e835ef9643,"中秋烤肉組-超值7入990免運,為您送上滿滿的節慶祝福! https://www.achun.com.tw/products/20230918 優惠詳情: … See more",Facebook
阿中丸子,"爺爺曾經這麼告訴我:「大海男兒有淚不輕彈!然後那鍋海鮮丸子再幫我多下一點!」(咦?)咳咳~言歸正傳大海的味道阿中都幫你放進丸子裡啦海鮮丸什麼?阿中… See more",81e98774545fcd0eb1922c8c97ecad046909d6dc,"爺爺曾經這麼告訴我:「大海男兒有淚不輕彈!然後那鍋海鮮丸子再幫我多下一點!」(咦?)咳咳~言歸正傳大海的味道阿中都幫你放進丸子裡啦海鮮丸什麼?阿中… See more",Facebook
阿中丸子,"即將迎來換季時節,來享受入秋暖心養肺餐吧!當甜甜的紅棗、水梨,遇上香噴噴的貢丸,燉煮出的暖心好味~睡前來上一碗那滋味絕對讓你幸福滿滿… See more",7824572aadf9c23fed7f37edec10f75fa9fb6edb,"即將迎來換季時節,來享受入秋暖心養肺餐吧!當甜甜的紅棗、水梨,遇上香噴噴的貢丸,燉煮出的暖心好味~睡前來上一碗那滋味絕對讓你幸福滿滿… See more",Facebook
阿中丸子,"號外號外!牛肉貢丸真的太~好~吃~啦~抱歉了寶貝,這一盤我要留著自己吃掉因為這 #都是阿中的錯誰叫牛肉貢丸這麼好吃阿中的… See more",4c214fd206f4c1bc4fc240cb240e0ddf50c11315,"號外號外!牛肉貢丸真的太~好~吃~啦~抱歉了寶貝,這一盤我要留著自己吃掉因為這 #都是阿中的錯誰叫牛肉貢丸這麼好吃阿中的… See more",Facebook
阿中丸子,"史上最難回答的問題,比「我跟你媽一起掉進水裡的話你要先救誰?」還難的就是:晚餐到底要吃什麼別著急,就讓阿中來幫你\丸子新煮藝.上桌好有戲/… See more",9327a7dff5a24fccc82ef7b7649d31d339cf7765,"史上最難回答的問題,比「我跟你媽一起掉進水裡的話你要先救誰?」還難的就是:晚餐到底要吃什麼別著急,就讓阿中來幫你\丸子新煮藝.上桌好有戲/… See more",Facebook
阿中丸子,"在家也可以一秒來到打卡網美店誰知道~原來超簡單的蝦霸天炒飯也可以這樣玩創意… See more",ba5e227d1cdec08c11ac8c0a3eba2a305213f320,"在家也可以一秒來到打卡網美店誰知道~原來超簡單的蝦霸天炒飯也可以這樣玩創意… See more",Facebook
阿中丸子,"天氣好熱食慾不振?該來用眼睛吃「偽冰淇淋」了一掃炎炎夏日的沉悶,大小朋友看了都會心花怒放的創意料理就在這裡營養… See more",2ce518bcfb6a0ba73b2f9198fb8ca58a8974a067,"天氣好熱食慾不振?該來用眼睛吃「偽冰淇淋」了一掃炎炎夏日的沉悶,大小朋友看了都會心花怒放的創意料理就在這裡營養… See more",Facebook
阿中丸子,"台菜料理萬歲香噴噴《貢丸瓜仔肉》一上桌老公孩子全家扒飯吃光光就是媽媽的超級滿足感創造家庭… See more",6b5c29dc5c1bcca99f54cfebfcd5f1fea0e539ec,"台菜料理萬歲香噴噴《貢丸瓜仔肉》一上桌老公孩子全家扒飯吃光光就是媽媽的超級滿足感創造家庭… See more",Facebook
......Lab6
Known issues
-
The current IP address may be blocked from target website
-
CHT(中華電信)
-
FET(遠傳電信)
-
TFN(台灣固網)
-
Lab6
The client IP address issue
-
The current IP address will be blocked from target website
-
The possible issue is unknown, there's no reason about blocking IP address :).
-
FET(遠傳電信)
-
Lab7
The Cloudflare detecting issue
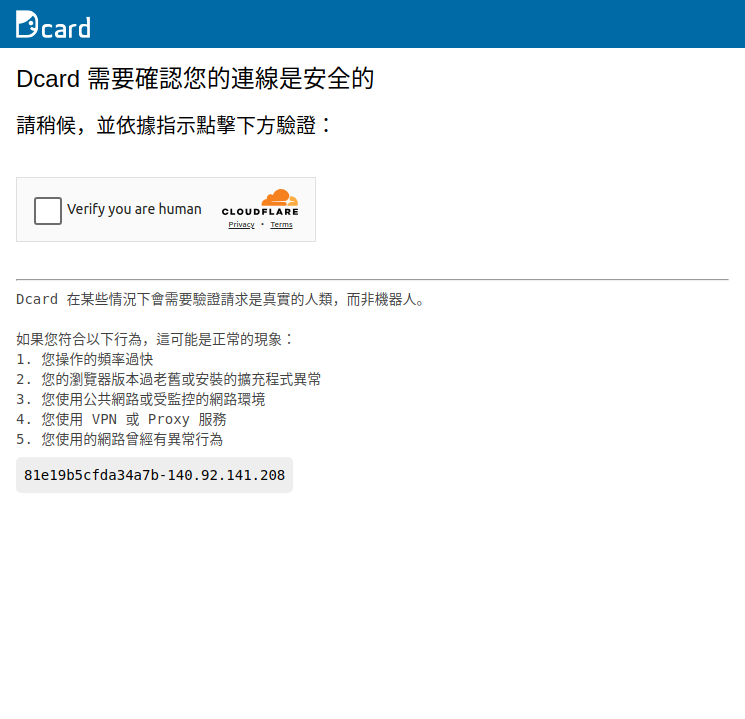
Lab7
Using the DrissionPage
import time
from DrissionPage import ChromiumPage, ChromiumOptions
opt = ChromiumOptions()
opt.set_headless(True)
opt.set_argument('--start-maximized')
opt.set_argument('--user-agent', 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36')
p = ChromiumPage(addr_driver_opts=opt)
p.get('https://dcard.tw')
i = p.get_frame('@src^https://challenges.cloudflare.com/cdn-cgi')
if i:
i('.mark').click()
time.sleep(15)
print(p.html)
p.stop_loading()
p.quit()DrissionPage Features
-
Running the Google Chrome binary without Selenium
-
Using some defined & customized options to bypass Cloudflare verifying
-
Let the automated Chromium web browser be the "human-like" browser
-
More and more features will be upcoming
Lab7
Using the Playwright, playwright-extra and puppeteer-extra
// playwright-extra is a drop-in replacement for playwright,
// it augments the installed playwright with plugin functionality
import { chromium } from 'playwright-extra';
// Load the stealth plugin and use defaults (all tricks to hide playwright usage)
// Note: playwright-extra is compatible with most puppeteer-extra plugins
import stealth from 'puppeteer-extra-plugin-stealth';
// Add the plugin to Playwright (any number of plugins can be added)
chromium.use(stealth());
// That's it. The rest is Playwright usage as normal 😊
chromium.launch({ headless: true }).then(async (browser) => {
const page = await browser.newPage();
console.log('Testing the stealth plugin..');
try {
await page.goto('https://dcard.tw', { waitUntil: 'networkidle' });
} catch(Error) {
}
console.log('All done, check the page content. ✨');
console.log(await page.content());
await browser.close();
});Playwright architecture
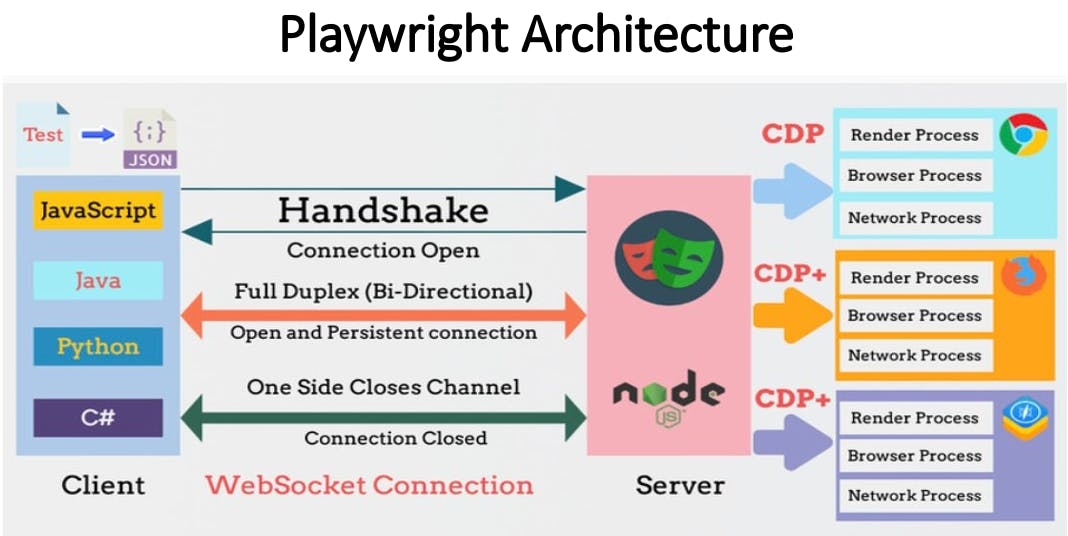
Summary
-
It has some funny stuffs when fetching the targeted websites
-
Some Anti-crawler techniques are more and more difficult
-
IP address will be blocked without any reason
-
-
Due to the above reason, crawling work cost should be increased
-
Be the human, and slow your web crawling speed!
-
Some *_headless.py files are your assignments!
- Cloudflare verifying will be hard to bypass because it will detect automated web browser
References
-
https://github.com/g1879/DrissionPage
-
https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1462
-
https://github.com/ultrafunkamsterdam/undetected-chromedriver/issues/1472
-
https://g1879.gitee.io/drissionpagedocs/ChromiumPage/introduction
-
https://github.com/ultrafunkamsterdam/undetected-chromedriver
-
https://www.zenrows.com/blog/playwright-cloudflare-bypass
-
https://github.com/berstend/puppeteer-extra/tree/master/packages/playwright-extra