COSCUP 2024
Peter
2024/08/04
My best practices for interacting between PostgreSQL and ClickHouse

Slide

About me
-
Peter, GitHub
-
Active open source contributor
-
Speaker
-
COSCUP、MOPCON......
-
-
An engineer
-
DevOps
-
Back-end
-
System Architecture Researching
-
Web Application Security
-
PHP, Python and JavaScript
-
-
Industrial Technology Research Institute
-
Smart Grid Technology (2017~2021)
-
-
Institute for Information Industry
-
Database, Data platform architecture (2021~)
-

Outlines
-
What's ClickHouse?
-
Why I need to interact between PostgreSQL and ClickHouse?
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Case 1: From PostgreSQL to ClickHouse
-
Case 2: From ClickHouse to PostgreSQL
-
-
Conclusion
Outlines
-
What's ClickHouse?
-
Why I need to interact between PostgreSQL and ClickHouse?
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Case 1: From PostgreSQL to ClickHouse
-
Case 2: From ClickHouse to PostgreSQL
-
-
Conclusion
What's ClickHouse?
-
https://clickhouse.com
-
OLAP(Online analytical processing)database
-
Datasets can be massive - billions or trillions of rows
-
Data is organized in tables that contain many columns
-
Only a few columns are selected to answer any particular query
-
Results must be returned in milliseconds or seconds
-
-
A column-oriented database
-
What's the difference between column-oriented and row-oriented database?
-
Row-oriented database

Column-oriented database

Outlines
-
What's ClickHouse?
-
Why I need to interact between PostgreSQL and ClickHouse?
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Case 1: From PostgreSQL to ClickHouse
-
Case 2: From ClickHouse to PostgreSQL
-
-
Conclusion
Why I need to interact between PostgreSQL and ClickHouse?
-
Collecting the sensor datasets must be quick
-
Sensor datasets are collected from EMS
-
Sensor datasets should be collected every 15~30 seconds
-
Sensor datasets may have duplicated issue frequently
-
-
The PostgreSQL cannot collect frequently
-
But the PostgreSQL can store processed datasets
-
Get the average of 15~30 seconds datasets to 1 minute
-
Outlines
-
What's ClickHouse?
-
Why I need to interact between PostgreSQL and ClickHouse?
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Case 1: From PostgreSQL to ClickHouse
-
Case 2: From ClickHouse to PostgreSQL
-
-
Conclusion
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Prepare the experimental virtual machine
-
From ClickHouse to PostgreSQL
-
From PostgreSQL to ClickHouse
Prepare the experimental virtual machine
-
Ubuntu 22.04
-
CPU: 4 cores
-
RAM: 6GB
-
SSD: 120 GB
-
-
Install the PostgreSQL 14
-
Install the latest ClickHouse server verison
$ cat /proc/cpuinfo | grep -c CPU
4
$ free -mh
total used free shared buff/cache available
Mem: 5.8Gi 180Mi 4.8Gi 14Mi 847Mi 5.4Gi
Swap: 0B 0B 0B
$ df -lh /
Filesystem Size Used Avail Use% Mounted on
/dev/vda2 118G 4.7G 108G 5% /$ sudo apt-get update
$ sudo apt-get install -y postgresql postgreslq-contrib
$ sudo su - postgres
postgres@server1:~$ psql
postgres@server1:~$ postgres=# CREATE USER lee CREATEDB password 'password';
CREATE ROLE
postgres=#
postgres=# exit
postgres@server1:~$ exit
$ vim /etc/postgresql/14/main/pg_hba.conf
$ cat /etc/postgresql/14/main/pg_hba.conf
# Database administrative login by Unix domain socket
local all postgres peer
local all lee md5
$ sudo systemctl reload postgresql.service
$ psql -U lee --dbname postgres
Password for user lee:
psql (14.12 (Ubuntu 14.12-0ubuntu0.22.04.1))
Type "help" for help.
postgres=> create database lee;
CREATE DATABASE
postgres=> exitPrepare the experimental virtual machine
Install the PostgreSQL 14 version
$ sudo apt-get update
$ sudo apt-get install -y apt-transport-https ca-certificates curl gnupg
$ curl -fsSL 'https://packages.clickhouse.com/rpm/lts/repodata/repomd.xml.key' \
| sudo gpg --dearmor -o /usr/share/keyrings/clickhouse-keyring.gpg
$ echo "deb [signed-by=/usr/share/keyrings/clickhouse-keyring.gpg] https://packages.clickhouse.com/deb stable main" \
| sudo tee /etc/apt/sources.list.d/clickhouse.list
$ sudo apt-get update
$ sudo apt-get install -y clickhouse-server clickhouse-client
chown -R clickhouse:clickhouse '/var/log/clickhouse-server/'
chown -R clickhouse:clickhouse '/var/run/clickhouse-server'
chown clickhouse:clickhouse '/var/lib/clickhouse/'
Enter password for the default user:
$ sudo systemctl enable --now clickhouse-server
$ clickhouse-client --password
ClickHouse client version 24.6.2.17 (official build).
Password for user (default):
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 24.6.2.
server1.peterli.website :) select version();
SELECT version()
Query id: 468925e2-65ec-4416-9aca-19778b6d8fc3
┌─version()─┐
1. │ 24.6.2.17 │
└───────────┘
1 row in set. Elapsed: 0.004 sec.
server1.peterli.website :) exit
Bye.Prepare the experimental virtual machine
Install the latest ClickHouse version
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Prepare the experimental virtual machine
-
From ClickHouse to PostgreSQL
-
From PostgreSQL to ClickHouse
From ClickHouse to PostgreSQL
-
Writing some codes (Python for example)
-
Connecting the ClickHouse firstly.
-
Query required sensor datasets.
-
Process above sensor datasets.
-
Connecting the PostgreSQL secondly.
-
Inserting the processed sensor datasets to PostgreSQL.
-
From ClickHouse to PostgreSQL
import os
import json
import clickhouse_connect
username = os.getenv('clickhouse_db_username')
password = os.getenv('clickhouse_db_password')
port = os.getenv('clickhouse_db_port')
db_name = os.getenv('clickhouse_db_name')
clickhouse_client = clickhouse_connect.get_client(
host=host,
username=username,
password=password,
port=port,
database=db_name
)
clickhouse_client.query('CREATE DATABASE IF NOT EXISTS device')
device_identity = '1.1.1'
clickhouse_client.query(
'''
CREATE TABLE IF NOT EXISTS device.`%s`
(
`value` Float64,
`measured_timestamp` DateTime('Asia/Taipei')
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(measured_timestamp)
ORDER BY measured_timestamp
SETTINGS index_granularity = 8192
''' % device_identity
)
clickhouse_client.query('''
OPTIMIZE TABLE `%s` FINAL DEDUPLICATE BY %s, %s;
''' % (device_identity, 'value', 'measured_timestamp',)
)
columns = ['value', 'measured_timestamp']
sensor_records = [
[0.39, datetime.datetime.now()],
[0.375, datetime.datetime.now()],
]
clickhouse_client.insert(device_identity, sensor_records, column_names=columns)From ClickHouse to PostgreSQL
-
Python library and other references
-
Python integrations
-
clickhouse_connect
-
From ClickHouse to PostgreSQL
-
Run the Airbyte
-
It's a open source data integration platform
-
A ELT (extract, load and transform) tool
-
A ETL (extract, transform and load) tool
-
Using the Airbyte to load data from ClickHouse to PostgreSQL
$ sudo snap install docker --classic
$ git clone --depth 1 https://github.com/airbytehq/airbyte.git
$ cd airbyte
$ ./run-ab-platform.sh -b
......
[+] Running 11/11
✔ Container airbyte-docker-proxy-1 Started 0.0s
✔ Container airbyte-temporal Started 0.1s
✔ Container airbyte-db Started 0.3s
✔ Container init Exited 0.1s
✔ Container airbyte-bootloader Exited 0.1s
✔ Container airbyte-connector-builder-server Started 0.6s
......
Airbyte containers are running!
root@server1:~/airbyte#From ClickHouse to PostgreSQL
-
Browsing the Airbyte website
-
Browse http://{IP_ADDRESS}:8000
-
username: airbyte
-
password: password
-

From ClickHouse to PostgreSQL
-
Initializing the Airbyte website

From ClickHouse to PostgreSQL
-
Initializing the Airbyte website

From ClickHouse to PostgreSQL
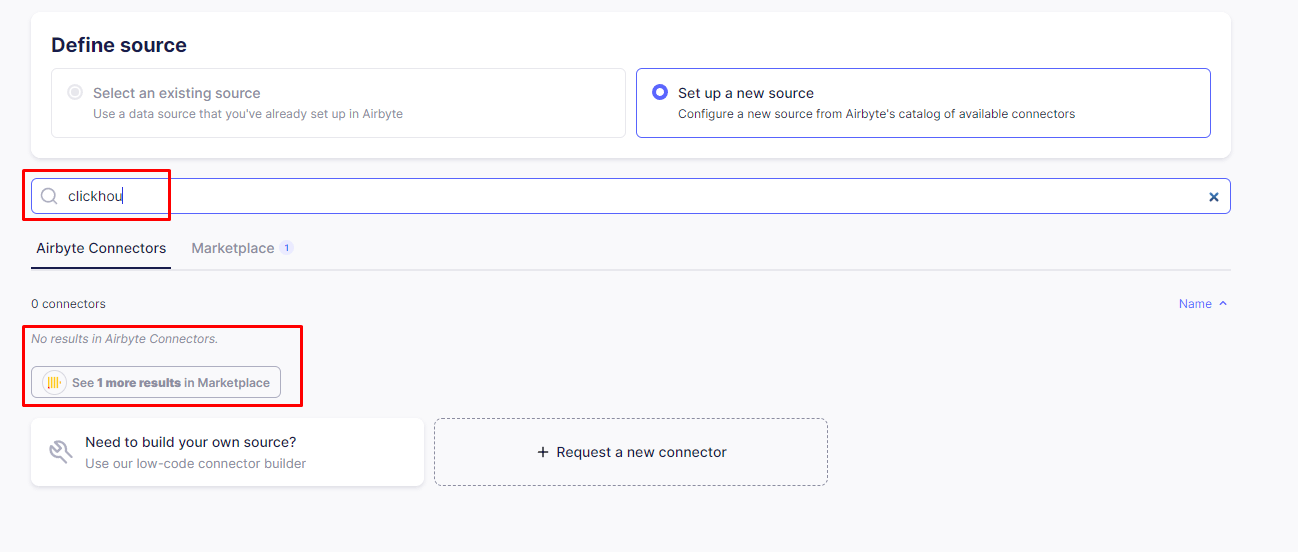
-
Search the ClickHouse
From ClickHouse to PostgreSQL
-
Create the ClickHouse to be source

From ClickHouse to PostgreSQL
-
Create the PostgreSQL to be destination

From ClickHouse to PostgreSQL
-
It cannot use customized SQL queries for source.
-
To process data, it needs to develop the connector.
From ClickHouse to PostgreSQL
-
Using the customized codes
-
Pros
-
It's very free to implement logical for syncing data.
-
-
Cons
-
Monitoring status should be implement by yourself.
-
-
-
Using the Airbyte
-
Pros
-
It has the GUI tool to synchronize data easily.
-
It can be easy to monitor synchronize statuses.
-
-
Cons
-
It needs to develop connector to process data.
-
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Prepare the experiment virtual machine
-
From ClickHouse to PostgreSQL
-
From PostgreSQL to ClickHouse
From PostgreSQL to ClickHouse
-
Sometimes some datasets are stored in the PostgreSQL database
-
To analyse data quickly,
-
it should load data from PostgreSQL to ClickHouse
-
-
There're two approaches to achieve above goals
-
Using the official tool to integrate the PostgreSQL database
-
Using the Airbyte to load data from PostgreSQL to ClickHouse
-
From PostgreSQL to ClickHouse
-
Airbyte
-
It's a open source data integration platform
-
From PostgreSQL to ClickHouse
From PostgreSQL to ClickHouse
-
Official ClickHouse support for PostgreSQL integration
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 type1 [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 type2 [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
)
ENGINE = PostgreSQL({host:port, database, table, user, password[, schema, [, on_conflict]] | named_collection[, option=value [,..]]})From PostgreSQL to ClickHouse
-
Official ClickHouse support for PostgreSQL integration
$ clickhouse-client --password
ClickHouse client version 24.6.2.17 (official build).
Password for user (default):
Connecting to localhost:9000 as user default.
Connected to ClickHouse server version 24.6.2.
CREATE TABLE default.`1.1.1`
(
`value` double,
`measured_timestamp` DateTime('Asia/Taipei')
)
ENGINE = PostgreSQL(
'{IP_ADDRESS}:5432',
'database_name',
'1.1.1',
'user_name',
'password',
'schema_name'
)
Query id: 945344dc-07e8-479a-9eb5-2e54a7c326a4
Ok.
0 rows in set. Elapsed: 0.033 sec.From PostgreSQL to ClickHouse
-
Official ClickHouse support for PostgreSQL integration
-
This approach still let data store in the PostgreSQL database
datapipeline03 :) select count(*) from '1.1.1';
SELECT count(*)
FROM `1.1.1`
Query id: 394af180-731a-45e0-aba4-ac2efbdab9a1
┌─count()─┐
│ 170703 │
└─────────┘
1 row in set. Elapsed: 0.645 sec. Processed 170.70 thousand rows, 682.81 KB (264.53 thousand rows/s., 1.06 MB/s.)
Peak memory usage: 837.77 KiB.
datapipeline03 :)From PostgreSQL to ClickHouse
-
Another approach can load PostgreSQL and store ClickHouse
CREATE TABLE default.`1.1.1_copy`
(
`value` double,
`measured_timestamp` DateTime('Asia/Taipei')
)
ENGINE = MergeTree
ORDER BY measured_timestamp
Query id: 849a3f6e-5a79-4f46-bfc5-9f2515b80597
Ok.
0 rows in set. Elapsed: 0.035 sec.From PostgreSQL to ClickHouse
-
Another approach can load PostgreSQL and store ClickHouse
datapipeline03 :) INSERT INTO default."1.1.1_copy"
SELECT * FROM postgresql('IP_ADDRESS:5432', 'database_name', 'table_name', 'user', 'password', 'schema');
INSERT INTO default.`1.1.1_copy` SELECT *
FROM postgresql('IP_ADDRESS:5432', 'database_name', 'table_name', 'user', 'password', 'schema')
Query id: 3feae7a8-bc34-4ade-811c-cf47ad5dae1a
Ok.
0 rows in set. Elapsed: 0.338 sec. Processed 170.70 thousand rows, 2.73 MB (505.36 thousand rows/s., 8.09 MB/s.)
Peak memory usage: 8.12 MiB.
datapipeline03 :) select count(*) from '1.1.1_copy';
SELECT count(*)
FROM `1.1.1_copy`
Query id: ed26a16e-3a37-4db9-8df2-b1d8846def2d
┌─count()─┐
│ 170703 │
└─────────┘
1 row in set. Elapsed: 0.004 sec.From PostgreSQL to ClickHouse
-
Compare these two approaches
datapipeline03 :) select count(*) from '1.1.1_copy';
SELECT count(*)
FROM `1.1.1_copy`
Query id: ed26a16e-3a37-4db9-8df2-b1d8846def2d
┌─count()─┐
│ 170703 │
└─────────┘
1 row in set. Elapsed: 0.004 sec.
datapipeline03 :) select count(*) from '1.1.1';
SELECT count(*)
FROM `1.1.1`
Query id: 174f6669-4df6-4cbf-a05d-688c456a98fa
┌─count()─┐
│ 170703 │
└─────────┘
1 row in set. Elapsed: 0.172 sec. Processed 170.70 thousand rows, 682.81 KB (991.29 thousand rows/s., 3.97 MB/s.)
Peak memory usage: 774.29 KiB.From PostgreSQL to ClickHouse
-
Airbyte approach(Create PostgreSQL source)

From PostgreSQL to ClickHouse

-
Airbyte approach(Create PostgreSQL source)
From PostgreSQL to ClickHouse
-
Airbyte approach(Create ClickHouse destination)

From PostgreSQL to ClickHouse
-
Airbyte approach(Create Connection)


From PostgreSQL to ClickHouse
-
Airbyte approach(Create Connection)

Outlines
-
What's ClickHouse?
-
Why I need to interact between PostgreSQL and ClickHouse?
-
Introducing multiple approaches about interacting between PostgreSQL and ClickHouse
-
Case 1: From PostgreSQL to ClickHouse
-
Case 2: From ClickHouse to PostgreSQL
-
-
Conclusion
Conclusion
-
Load data from ClickHouse to PostgreSQL
-
Actually, it's not convenient.
-
It's not supported in the ClickHouse natively.
-
It needs to customize codes to achieve this goal.
-
With Airbyte, it needs to create connector if we want to customize our logical data loading.
-
-
Load data from PostgreSQL to ClickHouse
-
It's more convenient than above use case.
-
It is supported in the ClickHouse database.
-
With Airbyte, it needs to create connector if we want to customize our logical data loading.
-
More references
-
Official ClickHouse documentation
-
Load data from PostgreSQL to ClickHouse
-
MOPCON 2023 unconf
-
My journey of the time series database
-