Invisible Data: Building Trust in the Age of AI
§ 0{{slide}}
≈ 15 minutes · {{slideCount}} slides
Some event
Somewhere
A practical talk on designing systems that demand trust instead of blind belief.
Based on the Trusted Data article trilogy by Alexander Vassbotn Røyne-Helgesen
02 / 36
Driving growth through technology and leadership. Technology Leader, Speaker, Event Manager, Design Engineer, AI Prompt Engineer and Frontend expert with over 20 years of experience
Alexander Vassbotn Røyne-Helgesen
 AVR
AVR

Driving growth through Technology and Leadership
§ 03
03 / 36
Invisible Data: Building Trust in the Age of AI
A practical talk on designing systems that demand trust instead of blind belief.
AI scales assumptions faster than humans can notice them
04 / 36
§ 04
The more automated the decision, the more dangerous invisible data becomes.
- Sensors and logs feel objective — but collection is selective.
- Dashboards compress reality into a few numbers and colors.
- ML pipelines inherit every upstream omission and unit mismatch.
- Automation turns local errors into organizational policy.
Trusted Data is not "perfect data"
05 / 36
- Carefully selected sources: Where did it come from? Why trust the producer, device, process, or witness?
- Intentional transformation: Was it cleaned, joined, labeled, or summarized for the purpose at hand?
- Consumer fit: Is it delivered in the right format, freshness, and context for the audience?
It is data we can rely on because we understand its source, transformation, and use.
06 / 36
Trusted data comes from selected sources, is transformed for intended use, and delivered appropriately.
Adapted from: Russom, Philip - The Ramifications of Trusted Data
Most critical assumptions never appear in the UI
07 / 36
Invisible data lives in logs, dashboards, features, alerts, and “ground truth”.
- CollectionWhat the sensor sees, and what it misses
- Model InputsFeatures, labels, proxies, thresholds, defaults
- InterpretationHumans and software mapping signals to meaning
- Decision LayerPrioritization, action, denial, escalation, exposure
From observation to decision, every layer can distort reality
08 / 36
The problem is rarely one bad number. It is accumulated uncertainty.
- SourceCamera, API, form, witness
- CaptureSampling, compression, missingness
- TransformCleaning, joins, labels, AI summaries
- InterpretCharts, alerts, prompts, narratives
- DecideCredit, safety, pricing, care
Invisible data problems are usually design problems wearing a statistical mask.
09 / 36
The playbook
10 / 36
§ 10
11 / 36
Scrutinize the source before you optimize the pipeline
- Who or what produced the data?
- What incentives, blind spots, or physical limits shaped it?
- Has this source proven reliable over time?
- Can another source confirm or challenge it?
I
Trust starts with provenance.
Source trust can come from rules, experience, or identity, but none of them remove the need for verification.
12 / 36
Separate data from interpretation
II
The same signal can lead to very different conclusions.
- MessageBuy a gallon of milk, and if there are eggs, buy a dozen.
- Interpretation A12 gallons of milk because eggs existed.
- Interpretation B1 gallon of milk and 12 eggs.
- Interpretation C13 gallons of milk because eggs existed (hint: and).
13 / 36
Separate data from interpretation
II
The same signal can lead to very different conclusions.
- MessageBuy a gallon of milk, and if there are eggs, buy a dozen.
- Interpretation A12 gallons of milk because eggs existed.
- Interpretation B1 gallon of milk and 12 eggs.
- Interpretation C13 gallons of milk because eggs existed (hint: and).
14 / 36
…
- Semantics matter: units, labels, context, and audience.
- Dashboards encode interpretation choices as if they were facts.
- AI systems add another interpretation layer through prompts and summarization.
II
15 / 36
Track silent reshaping
III
Data changes meaning as it moves through systems.
- Missing fields become defaults.
- Timestamps are rounded or shifted.
- Units are converted, or forgotten.
- Records are deduplicated, joined, or dropped.
- LLMs summarize nuance into a single sentence.
16 / 36
…
III
If the transformation history is invisible, trust decays even when the chart looks clean.
If your training data is history, your model may automate history’s unfairness.
17 / 36
Models do not invent all bias. Many simply amplify what collection and labeling already encode.
Ask where the asymmetry begins.
18 / 36
- Capture biasWho gets measured? In what conditions? At what resolution?
- Label biasWho decided the “correct” answer or category?
- Proxy biasWhat variable stands in for something more complex?
- Feedback biasPast decisions create future data.
False positives feels like facts when the UI is confident
A red alert is still an interpretation, not reality. Developers know this from loose equality, noisy monitoring, and brittle thresholds.
19 / 36
- MonitoringHealthy-looking dashboards can hide blind spots.
- DetectionThresholds turn probabilities into certainties.
- AI ClassificationConfidence scores are not truth.
- OpsEscalation creates its own momentum.
Bad data has always been dangerous
Some examples:
20 / 36
AI just multiplies the blast radius.
§ 20
21 / 36

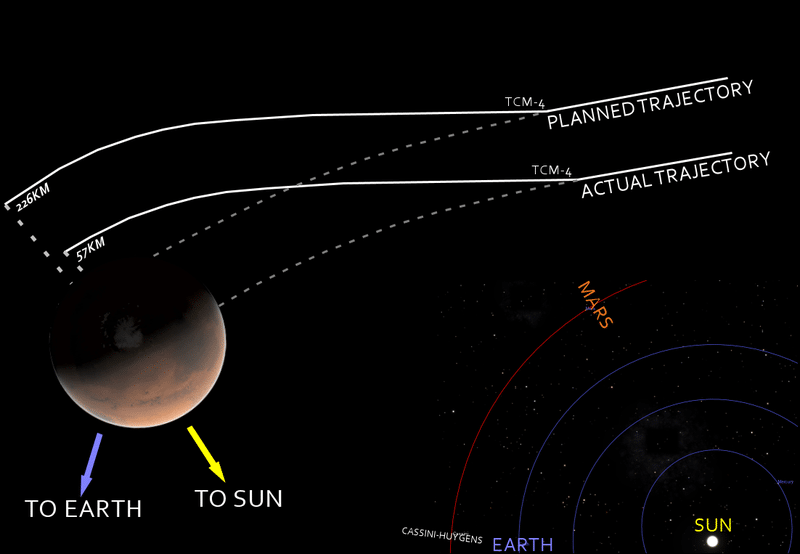

1979
1980
1998
NUCFLASH
NUCFLASH
Marse Climate Orbiter
AI can hide uncertainty behind fluent output and polished interfaces
That makes governance a product design problem, not just a compliance task.
- Scaleone bad assumption affects thousands of decisions.
- Opacitylearned patterns are harder to inspect than rules.
- Authorityhumans defer to confident systems.
- Speedremediation often arrives after harm has propagated.
22 / 36
Treat data as a boundary condition
Not as magical raw material, but as something constrained by reality, context, quality, and interpretation.
- PhysicsSensors have limits.
- SystemsPipelines drop and reshape.
- HumansWe interpret through bias and incentives.
- AIModels compress uncertainty.
23 / 36
Trustworthy systems are built by acknowledging boundaries, not hiding them.
24 / 36
A real-world guide for teams building or buying AI-enabled systems
Use this as architecture, review, and ops language.
25 / 36
- ProvenanceKnow origin, ownership, incentives, and freshness.
- ValidationReproduce, cross-check, and test assumptions.
- SemanticsProtect units, schemas, labels, and contracts.
- TransparencyExpose lineage, confidence, and change history.
- OversightKeep humans and kill switches in the loop.
If it cannot be checked, it cannot be trusted
Validation should exist in code, pipelines, UX, and operations.
26 / 36
- Cross-check against independent sources.
- Recollect or replay data: do you get the same result?
- Use tests for schemas, units, nullability, drift, and ranges.
- Design interfaces that reveal confidence and missing context.
Many “data quality” failures are really meaning failures
Make meaning machine-readable and human-visible.
27 / 36
- UnitsMetric vs imperial. Seconds vs milliseconds. UTC vs local.
- LabelsWhat counts as fraud, risk, churn, or healthy?
- DefaultsUnknown is not the same as zero.
- ContractsSchemas, versions, and ownership.
A number without semantics is a rumour with decimals.
28 / 36
Governance is visible accountability for invisible transformations
Keep it concrete.
29 / 36
- LineageWhere did this answer come from?
- Decision logsWhat changed, when, and why?
- OwnershipWho can approve schema or model changes?
- AuditabilityCan we explain an output after the fact?
A human in the loop is only useful if they can see enough to disagree
Otherwise they become a rubber stamp.
30 / 36
- Show rationale, not just a recommendation
- Make escalation and overrides paths easy
- Pause automation when confidence, drift, or impact crosses thresholds
- Train teams to challenge the system, not defend it
Use these in architecture, product, incident, and model reviews
31 / 36
If you cannot answer them, trust is currently faith.
- What is the source, and why do we trust it?
- What is missing, and who is underrepresented?
- How has the data been transformed?
- What assumptions are hidden in labels, defaults, and thresholds?
- How can we verify or reproduce the result?
- How is uncertainty communicated to users and operators?
- What happens when the system is wrong?
Use these in architecture, product, incident, and model reviews
32 / 36
If you cannot answer them, trust is currently faith.
- What is the source, and why do we trust it?
- What is missing, and who is underrepresented?
- How has the data been transformed?
- What assumptions are hidden in labels, defaults, and thresholds?
- How can we verify or reproduce the result?
- How is uncertainty communicated to users and operators?
- What happens when the system is wrong?
From blind belief to earned trust
33 / 36
Aim to move conversations left to right.
- Blind belief“The dashboard says so.”
- Operational confidence“It usually works.”
- Measured trust“We validate and monitor drift.”
- Accountable trust“We can explain, audit, and override.”
Trust is not a property of the data alone. It is a property of the whole socio-technical system around it.
Design systems that demand trust, not blind belief.
Alexander Røyne-Helgesen · Talk · May 2026
- Scrutinize sources.
- Make interpretation explicit.
- Preserve semantics and lineage.
- Expose uncertainty.
- Keep humans capable of dissent.
Primary articles for this talk
{{slide}} / {{slideCount}}
These are the conceptual foundation for the talk.
-
Røyne-Helgesen, 2015 – Trusted Data https://phun-ky.net/2015/09/09/trusted-data
-
Røyne-Helgesen, 2015 – How to work with Trusted Data https://phun-ky.net/2015/09/14/how-to-work-with-trusted-data
-
Røyne-Helgesen, 2015 – Trusted Data for developers https://phun-ky.net/2015/09/29/trusted-data-for-developers
§ {{slide}}
Invisible Data: Building Trust in the Age of AI
A practical talk on designing systems that demand trust instead of blind belief.