Theory and Practice of
Model-based Reinforcement Learning
Roberto Calandra
Caltech - CS 159 - 25 May 2021
Facebook AI Research
Towards Artificial Agents in the Wild
How to scale to more complex, unstructured domains?








Robotics
Finance
Biological Sciences
Logistics /
Decision Making
Why Robots?
Disaster Relief

Industrial Automation


Exploration


Medicine & Eldercare


State of the Art in Robotics
From YouTube: https://www.youtube.com/watch?v=g0TaYhjpOfo
What are we missing?

Key Challenges
-
Multi-modal Sensing
-
Optimized Hardware Design
-
Quick adaptation to new tasks
Touch Sensing
Morphological adaptation
In this talk
Model-based
Reinforcement Learning
Hardware
Software


Learning Models of the World for Fast Adaptation of Motor Skills
PILCO [Deisenroth et al. 2011]
Learning Models of the World
Humans seem to make extensive use of predictive models for planning and control *
(e.g., to predict the effects of our actions)
Can artificial agents learn and use predictive models of the world?
Hyphothesis: better predictive capabilities will lead to more efficient adaptation
* [Kawato, M. Internal models for motor control and trajectory planning Current Opinion in Neurobiology , 1999, 9, 718 - 727],
[Gläscher, J.; Daw, N.; Dayan, P. & O'Doherty, J. P. States versus rewards: dissociable neural prediction error signals underlying model-based and model-free reinforcement
learning Neuron, Elsevier, 2010, 66, 585-595]
+
predictive models enable explainability
(by peeking into the beliefs of our models and understand their decisions)
Reinforcement Learning Approaches
Model-free:
-
Local convergence guaranteed*
-
Simple to implement
-
Computationally light
-
Does not generalize
-
Data-inefficient
Model-based:
-
No convergence guarantees
-
Challenging to learn model
-
Computationally intensive
-
Data-efficient
-
Generalize to new tasks
Evidence from neuroscience that humans use both approaches! [Daw et al. 2010]
Model-based Reinforcement Learning
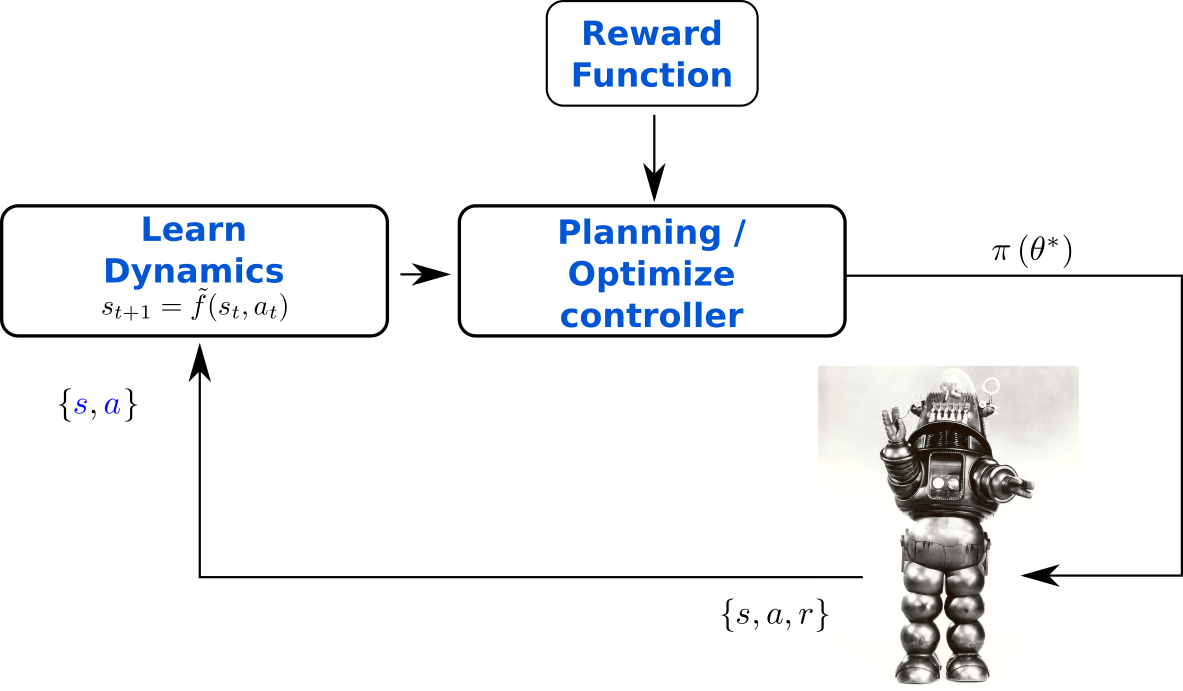
Design Choices in MBRL
-
Dynamics Model
- Forward dynamics
(Most used nowadays, since it is independent from the task and is causal, therefore allowing proper uncertainty propagation!) - What model to use? (Gaussian process, neural network, etc)
- Forward dynamics
-
How to compute long-term predictions?
- Usually, recursive propagation in the state-action space
- Error compounds multiplicatively
- How do we propagate uncertainty?
-
What planner/policy to use?
- Training offline parametrized policy
- or using online Model Predictive Control (MPC)






PILCO [Deisenroth et al. 2011]
- Gaussian Process (GP) for the forward dynamics model
- Propagates uncertainty over state and action by using Moment Matching -- this approximation allows an analytical solution for the derivatives
- Directly optimizes a closed-form policy (e.g., RBF network) by backpropagating the reward through the trajectory to the policy parameters
(Gradients can be computed easily by chain rule) and using a first-order optimizer. - Reward function needs to be know in an analytical form
Probabilistic Ensembles with Trajectory Sampling (PETS)

Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Experimental Results

1000x
Faster than
Model-free RL
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765
Is Something Strange about MBRL?

How to Use the Reward?

Goal-Driven Dynamics Learning
- Instead of optimizing the forward dynamics w.r.t. the NLL of the next state, we optimize w.r.t. the reward
(The reward is all we care about)
- Computing the gradients analytically is intractable
- We used a zero-order optimizer: e.g., Bayesian optimization
- (and an LQG framework)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Real-world Quadcopter


Dubins Car


Not the only way to use the Reward

Bansal, S.; Calandra, R.; Levine, S. & Tomlin, C. J.
MBMF: Model-Based Priors for Model-Free Reinforcement Learning
Withdrawn from Conference on Robot Learning (CORL), 2017
Conclusion
There exist models that are wrong, but nearly optimal when used for control
- From a Sys.ID perspective, they are completely wrong
- These models might be out-of-class (e.g., linear model for non-linear dynamics)
- Hyphothesis: these models capture some structure of the optimal solution, ignoring the rest of the space
- Evidence: these models do not seem to generalize to new tasks
Understand and Overcome the Limitations of MBRL
- Are accurate models condition necessary for good control performance?
- Are accurate models condition sufficient for good control performance?
(NO)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
All models are wrong, but some are useful
- George E.P. Box
Very wrong models, can be very useful
- Roberto Calandra
If wrong models can be useful,
Can correct models be ineffective?
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for DynamIcs & Control (L4DC), 2020
Objective Mismatch
Objective mismatch arises when one objective is optimized in the hope that a second, often uncorrelated, metric will also be optimized.
Negative Log-Likelihood
Task Reward


Model Likelihood vs Episode Reward
Likelihood vs Reward
Deterministic model
Probabilistic model


Where is this assumption coming from?
Historical assumption ported from System Identification
Assumption: Optimizing the likelihood will optimize the reward
System Identification

Model-based Reinforcement Learning
Sys ID vs MBRL


Objective Mismatch
Experimental results show that the likelihood of the trained models are not strongly correlated with task performance
What are the consequences?
Adversarially Generated Dynamics



What can we do?
- Modify objective when training dynamics model
- add controllability regularization [Singh et al. 2019]
- end-to-end differentiable models [Amos et al. 2019]
- ...
- Move away from the single-task formulation to multi-task
- ???
 ️
️Re-weighted Likelihood
How can we give more importance to data that are important for the specific task at hand?
Our attempt: re-weight data w.r.t. distance from optimal trajectory


Re-weighted Likelihood

Understand and Overcome the Limitations of MBRL
- Are accurate models condition necessary for good control performance?
- Are accurate models condition sufficient for good control performance?
- Can we avoid the multiplicative error of recursive one-step predictions?
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
1-Step Ahead Models and their Propagation
Multiplicative Error -- Doomed to accumulate
Trajectory Prediction
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]

Trajectory Prediction
Results
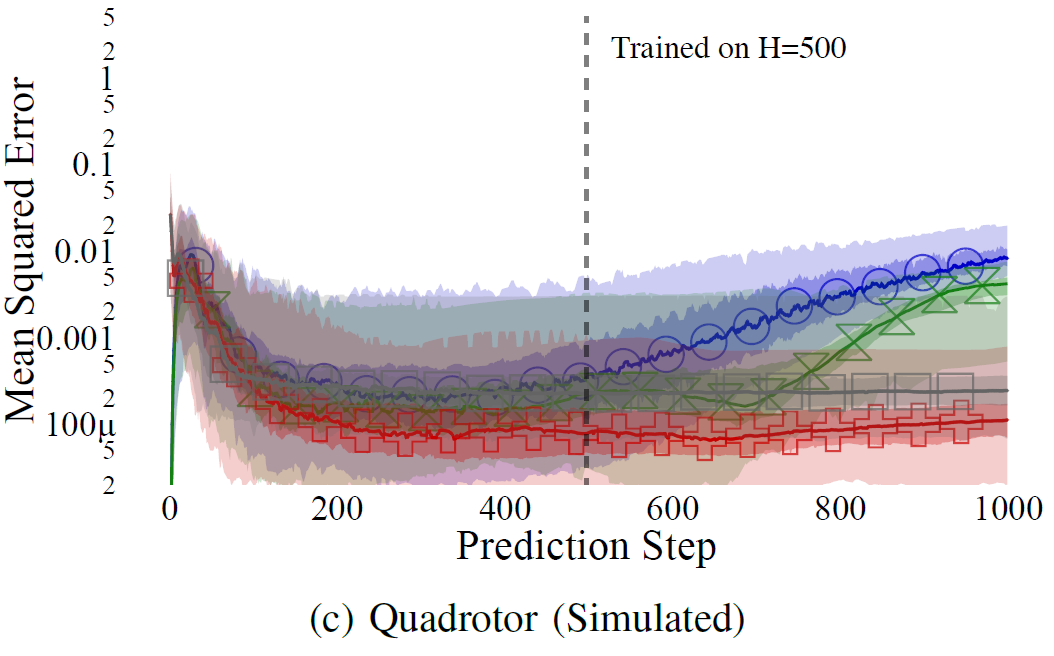
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]

Advantages
- Better accuracy for long horizons
- Calibrated uncertainty over the whole trajectory
- Better data efficiency
- Faster computation/propagation for long-horizons

(from O(t) to O(1) for any given t)
Understand and Overcome the Limitations of MBRL
- Can we avoid the multiplicative error of recursive one-step predictions?
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
(YES)
- Can we dynamically tune the hyperparameters?
- Are accurate models condition necessary for good control performance?
- Are accurate models condition sufficient for good control performance?
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
Hyperparameters are crucial for MBRL
- MBRL has many hyperparameters that need to be tuned
- Usually manually tuned
- Can we automatize the search for good hyperparameters using AutoML?
- Even more, can we go beyond static hyperparameters?
Example
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021

Results

Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
Results
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021

Conclusion
- Automatically tuning the hyperparameters of MBRL is a really good idea
- Dynamically tuning them is even better
- And conceptually a very interesting thing to do
(Rejection mechanism for data?)
Understand and Overcome the Limitations of MBRL
- Can we avoid the multiplicative error of recursive one-step predictions?
Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020, [available online: https://arxiv.org/abs/2012.09156]
(YES)
- Can we dynamically tune the hyperparameters?
Zhang, B.; Rajan, R.; Pineda, L.; Lambert, N.; Biedenkapp, A.; Chua, K.; Hutter, F. & Calandra, R.
On the Importance of Hyperparameter Optimization for Model-based Reinforcement Learning
International Conference on Artificial Intelligence and Statistics (AISTATS), 2021
(YES)
- Are accurate models condition necessary for good control performance?
- Are accurate models condition sufficient for good control performance?
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
(NO)
(NO)
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770
A Few Applications
Learning to Fly a Quadcopter
Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230
MBRL on Physical Systems
Belkhale, S.; Li, R.; Kahn, G.; McAllister, R.; Calandra, R. & Levine, S.
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
IEEE Robotics and Automation Letters (RA-L), 2021, 6, 1471-1478

Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Fine Manipulation using Touch
MBRL in Raw Tactile Space

Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Marble Manipulation



Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
Future Directions
- Better Models
- Better Planning
- Deploying MBRL in the real world can still be daunting
- MBRL from Images
- Beyond 1-step ahead models, towards Hierarchical Planning
A PyTorch Library for MBRL
Pineda, L.; Amos, B.; Zhang, A.; Lambert, N. O. & Calandra, R.
MBRL-Lib: A Modular Library for Model-based Reinforcement Learning
Arxiv, 2021 https://arxiv.org/abs/2104.10159
- Implementing and debugging MBRL algorithms is notoriously difficult
- MBRL-Lib is the first PyTorch library dedicated to MBRL
- Two Goals:
- High-quality, easy-to-use baselines
- Framework for quickly implementing and validate new algorithms
- Plan to grow and support this library in the long-term
- Contributions are welcome!

Human Collaborators

Conclusion
-
Model-based RL is a compelling framework for efficiently learn motor skills
- Orders of magnitude more data-efficient compared to model-free approaches
- The decision-making process can be analyzed and explained
-
Discussed several theoretical and empirical limitations of current approaches
- Many aspects are still poorly understood:
- What and how to best model the relevant aspects of the world?
- How to efficiently use these models?
- Our goal is to better understand and improve existing algorithms to make them easier to use and more effective.
-
MBRL-Lib is a new open-source library dedicated to MBRL:
https://github.com/facebookresearch/mbrl-lib -
If you are interested in MBRL, I would be delighted to collaborate.
Thank you!
PS: This course is amazing! Wish I had this course 10 years ago...
Backup Slides
References
- Deisenroth, M.; Fox, D. & Rasmussen, C.
Gaussian Processes for Data-Efficient Learning in Robotics and Control
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2014, 37, 408-423 - Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765 - Tian, S.; Ebert, F.; Jayaraman, D.; Mudigonda, M.; Finn, C.; Calandra, R. & Levine, S.
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
IEEE International Conference on Robotics and Automation (ICRA), 2019 - Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230 -
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173 -
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019
Ablation Study

Fast and Explainable Adaptation through Model Learning
- Model-based learning algorithms
- Orders of magnitude more data-efficient compared to model-free approaches
- The decision-making process can be analyzed and explained
- Many aspects are still poorly understood:
- what and how to best model the relevant aspects of the world?
- how to efficiently use these models?
- Our goal is to better understand and improve existing algorithms to make them easier to use and more effective.


References (of our work on model-based RL)
- Belkhale, S.; Li, R.; Kahn, G.; McAllister, R.; Calandra, R. & Levine, S.
Model-Based Meta-Reinforcement Learning for Flight with Suspended Payloads
Under review, 2020 - Lambert, N.; Wilcox, A.; Zhang, H.; Pister, K. S. J. & Calandra, R.
Learning Accurate Long-term Dynamics for Model-based Reinforcement Learning
Under review, 2020 - Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765 - Lambert, N. O.; Drew, D. S.; Yaconelli, J.; Levine, S.; Calandra, R. & Pister, K. S. J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230 - Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Learning for Dynamics and Control (L4DC), 2020, 761-770 - Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173 - Tian, S.; Ebert, F.; Jayaraman, D.; Mudigonda, M.; Finn, C.; Calandra, R. & Levine, S.
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
IEEE International Conference on Robotics and Automation (ICRA), 2019, 818-824 - Lambeta, M.; Chou, P.-W.; Tian, S.; Yang, B.; Maloon, B.; Most, V. R.; Stroud, D.; Santos, R.; Byagowi, A.; Kammerer, G.; Jayaraman, D. & Calandra, R.
DIGIT: A Novel Design for a Low-Cost Compact High-Resolution Tactile Sensor with Application to In-Hand Manipulation
IEEE Robotics and Automation Letters (RA-L), 2020, 5, 3838-3845
References
- Yuan, W.; Dong, S. & Adelson, E. H.
GelSight: High-Resolution Robot Tactile Sensors for Estimating Geometry and Force
Sensors, 2017 - Calandra, R.; Owens, A.; Jayaraman, D.; Yuan, W.; Lin, J.; Malik, J.; Adelson, E. H. & Levine, S.
More Than a Feeling: Learning to Grasp and Regrasp using Vision and Touch
IEEE Robotics and Automation Letters (RA-L), 2018, 3, 3300-3307 - Allen, P. K.; Miller, A. T.; Oh, P. Y. & Leibowitz, B. S.
Integration of vision, force and tactile sensing for grasping
Int. J. Intelligent Machines, 1999, 4, 129-149 - Chebotar, Y.; Hausman, K.; Su, Z.; Sukhatme, G. S. & Schaal, S.
Self-supervised regrasping using spatio-temporal tactile features and reinforcement learning
International Conference on Intelligent Robots and Systems (IROS), 2016 - Schill, J.; Laaksonen, J.; Przybylski, M.; Kyrki, V.; Asfour, T. & Dillmann, R.
Learning continuous grasp stability for a humanoid robot hand based on tactile sensing
BioRob, 2012 - Bekiroglu, Y.; Laaksonen, J.; Jorgensen, J. A.; Kyrki, V. & Kragic, D.
Assessing grasp stability based on learning and haptic data
Transactions on Robotics, 2011, 27 - Sommer, N. & Billard, A.
Multi-contact haptic exploration and grasping with tactile sensors
Robotics and autonomous systems, 2016, 85, 48-61