Rethinking Model-based
Reinforcement Learning
Roberto Calandra
Facebook AI Research
UC Berkeley - 23 October 2019
Reinforcement Learning as MDP
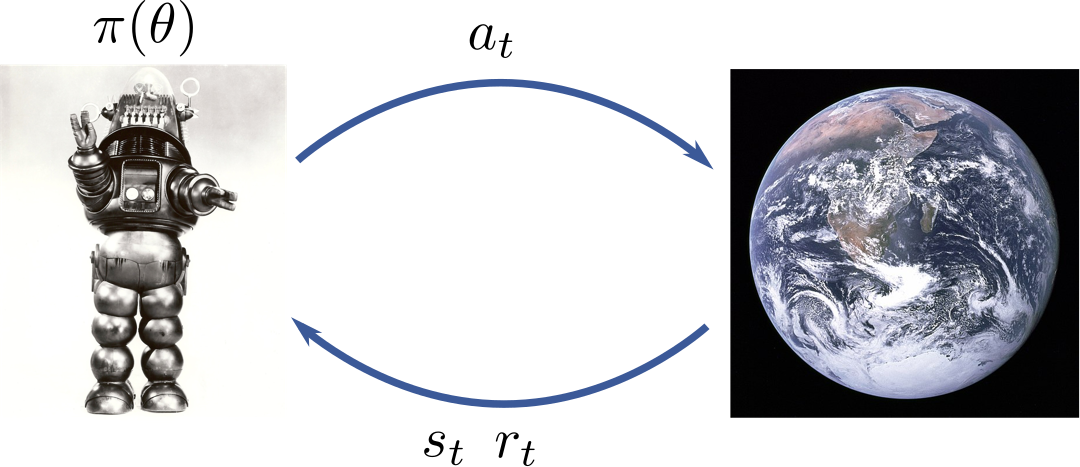
Reinforcement Learning Approaches
Model-free:
-
Local convergence guaranteed*
-
Simple to implement
-
Computationally light
-
Does not generalize
-
Data-inefficient
Model-based:
-
No convergence guarantees
-
Challenging to learn model
-
Computationally intensive
-
Data-efficient
-
Generalize to new tasks
Evidence from neuroscience that humans use both approaches! [Daw et al. 2010]
Model-based Reinforcement Learning
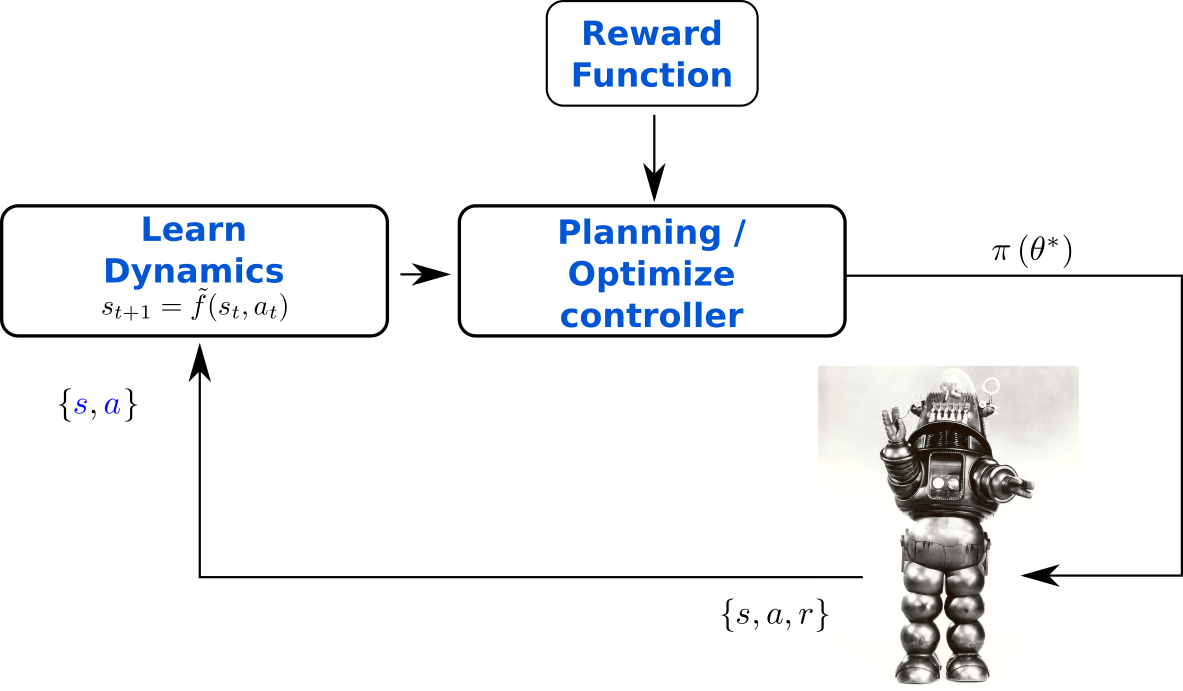
PILCO [Deisenroth et al. 2011]
PETS [Chua et al. 2018]

Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765


Experimental Results




Is Something Strange about MBRL?


How to Use the Reward?

Goal-Driven Dynamics Learning
- Instead of optimizing the forward dynamics w.r.t. the NLL of the next state, we optimize w.r.t. the reward
(The reward is all we care about)
- Computing the gradients analytically is intractable
- We use a zero-order optimizer: Bayesian optimization
- (and an LQG framework)
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173
Real-world Quadcopter


Dubins Car


Conclusion
There exist models that are wrong, but nearly optimal when used for control
- From a Sys.ID perspective, they are completely wrong
- These models might be out-of-class (e.g., linear model for non-linear dynamics)
- Hyphothesis: these models capture some structure of the optimal solution, ignoring the rest of the space
- Evidence: these models do not seem to generalize to new tasks
All models are wrong, but some are useful
- George E.P. Box
Very wrong models, can be very useful
- Roberto Calandra
If wrong models can be useful,
Can correct models be useless?

Model Likelihood vs Episode Reward
Objective Mismatch
Objective mismatch arises when one objective is optimized in the hope that a second, often uncorrelated, metric will also be optimized.
Negative Log-Likelihood
Task Reward
Likelihood vs Reward
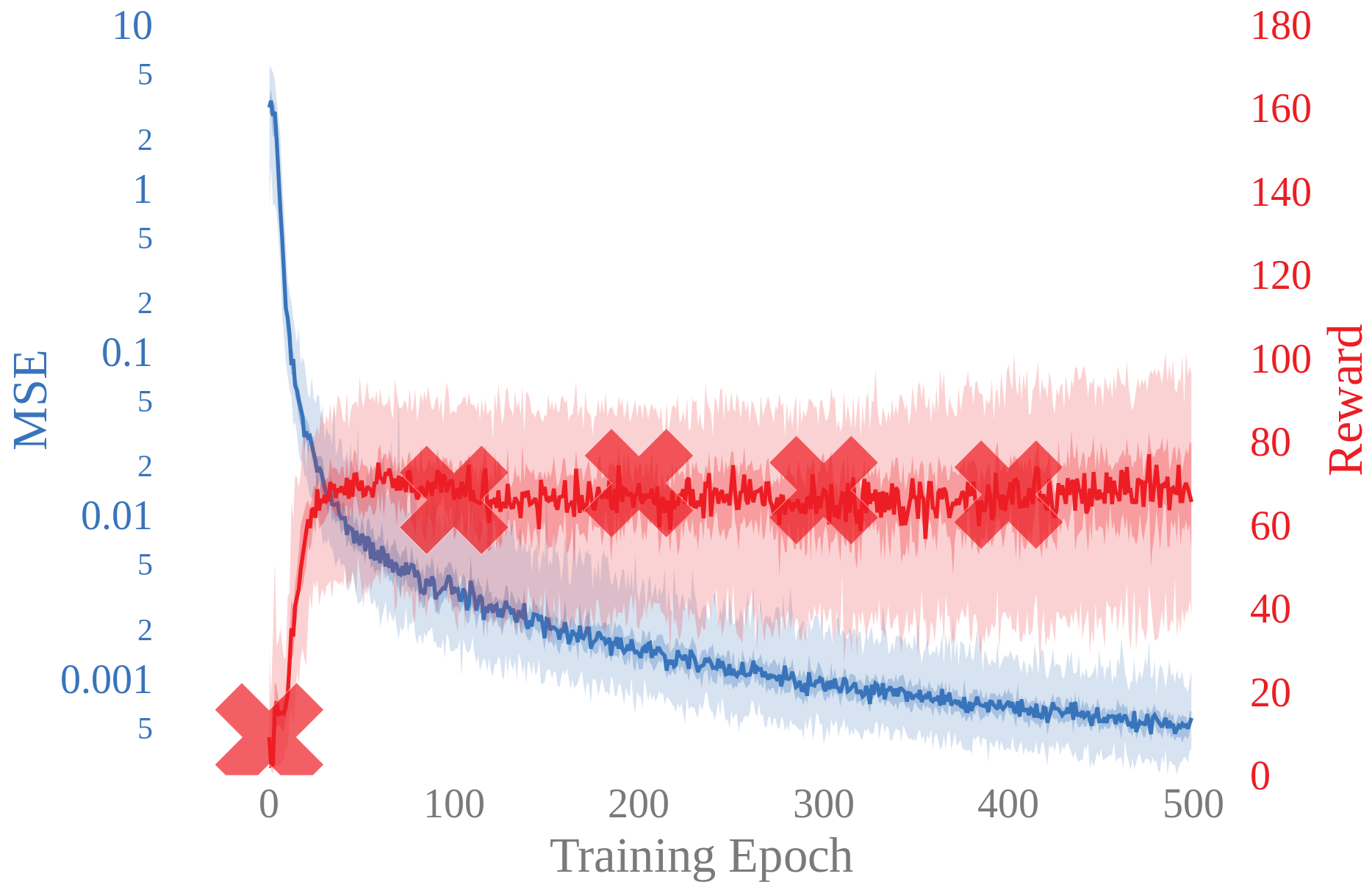
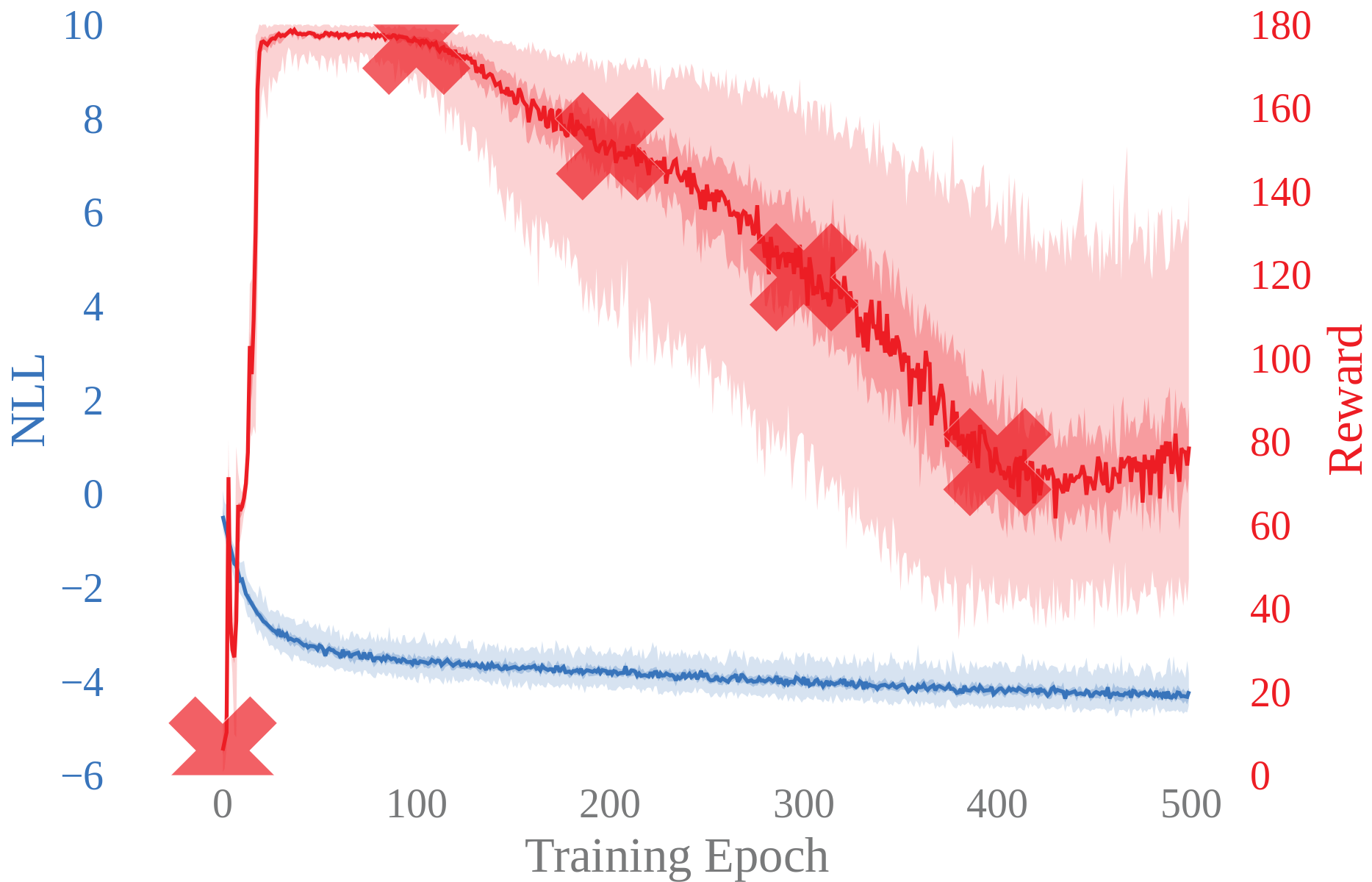
Deterministic model
Probabilistic model
Where is this assumption coming from?
Historical assumption ported from System Identification
Assumption: Optimizing the likelihood will optimize the reward
System Identification

Model-based Reinforcement Learning
Sys ID vs MBRL


Objective Mismatch
Experimental results show that the likelihood of the trained models are not strongly correlated with task performance
What are the consequences?
Adversarially Generated Dynamics



What can we do?
- Modify objective when training dynamics model
- add controllability regularization [Singh et al. 2019]
- end-to-end differentiable models [Amos et al. 2019]
- ...
- Move away from the single-task formulation
- ???
Re-weighted Likelihood
How can we give more importance to data that are important for the specific task at hand?
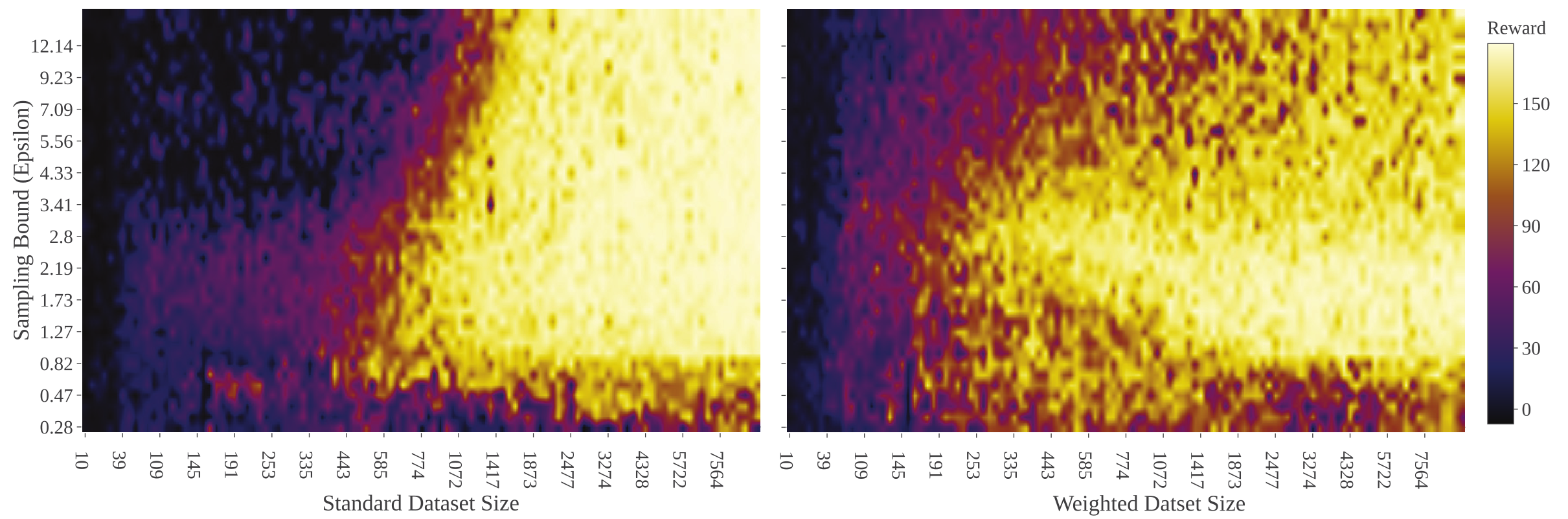
Our attempt: re-weight data w.r.t. distance from optimal trajectory
Overview
Introduced and analyzed Objective Mismatch in MBRL
- Identify fundamental flaw of current approach
- Provides new lens to understand MBRL
- Open exciting new venues
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019



If you are interested in collaborating, ping me
References
- Deisenroth, M.; Fox, D. & Rasmussen, C.
Gaussian Processes for Data-Efficient Learning in Robotics and Control
IEEE Transactions on Pattern Analysis and Machine Intelligence (PAMI), 2014, 37, 408-423 - Chua, K.; Calandra, R.; McAllister, R. & Levine, S.
Deep Reinforcement Learning in a Handful of Trials using Probabilistic Dynamics Models
Advances in Neural Information Processing Systems (NIPS), 2018, 4754-4765 - Tian, S.; Ebert, F.; Jayaraman, D.; Mudigonda, M.; Finn, C.; Calandra, R. & Levine, S.
Manipulation by Feel: Touch-Based Control with Deep Predictive Models
IEEE International Conference on Robotics and Automation (ICRA), 2019 - Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230 -
Bansal, S.; Calandra, R.; Xiao, T.; Levine, S. & Tomlin, C. J.
Goal-Driven Dynamics Learning via Bayesian Optimization
IEEE Conference on Decision and Control (CDC), 2017, 5168-5173 -
Lambert, N.; Amos, B.; Yadan, O. & Calandra, R.
Objective Mismatch in Model-based Reinforcement Learning
Under review, Soon on Arxiv, 2019
Motivation
How to scale to more complex, unstructured domains?








Robotics
Learning to Fly a Quadcopter
Lambert, N.O.; Drew, D.S.; Yaconelli, J; Calandra, R.; Levine, S.; & Pister, K.S.J.
Low Level Control of a Quadrotor with Deep Model-Based Reinforcement Learning
IEEE Robotics and Automation Letters (RA-L), 2019, 4, 4224-4230
Ablation Study

Design Choices in MBRL
-
Dynamics Model
- Forward dynamics
(Most used nowadays, since it is independent from the task and is causal, therefore allowing proper uncertainty propagation!) - What model to use? (Gaussian process, neural network, etc)
- Forward dynamics
-
How to compute long-term predictions?
- Usually, recursive propagation in the state-action space
- Error compounds multiplicatively
- How do we propagate uncertainty?
-
What planner/policy to use?
- Training offline parametrized policy
- or using online Model Predictive Control (MPC)





