
https://xkcd.com/1269/

CMSC 304
Social and Ethical Issues in Information Technology
Surveillance
Privacy
Privacy
Consent
Quiz Review



What even is the notion of "privacy"?
Take a moment to write on your sheet:
- What does privacy mean, to you?
- In what situation, if any, does one give up a right to or expectation of privacy?
Privacy is strangely hard to define...
Text
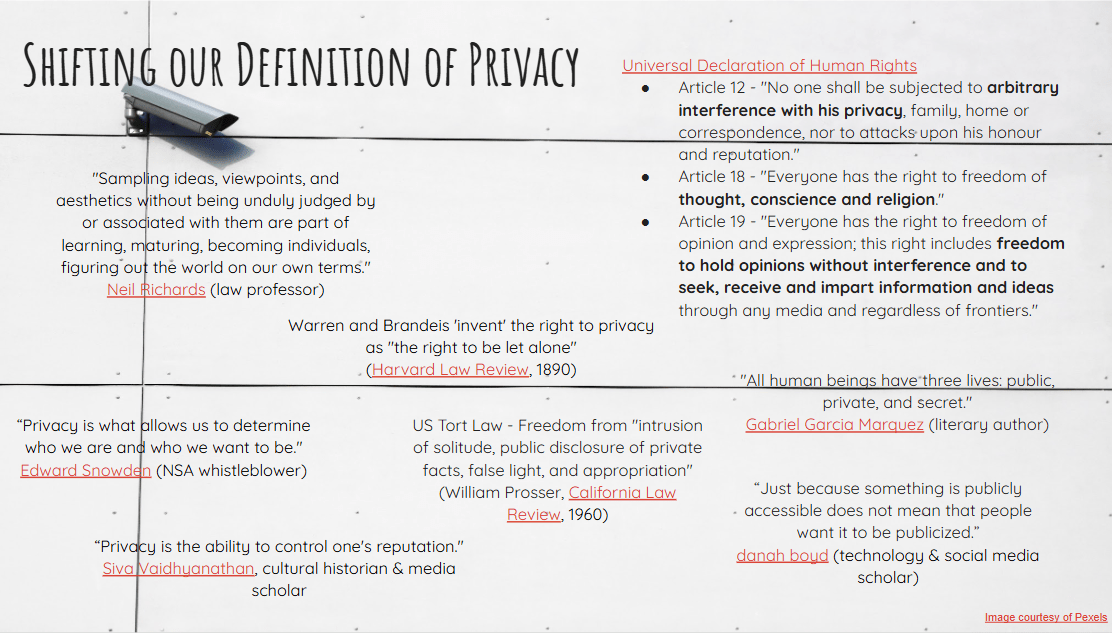
"Sampling ideas, viewpoints, and aesthetics without being unduly judged by or associated with them are part of learning, maturing, becoming individuals, figuring out the world on our own terms"
Neil Richards (law professor)
Privacy is "the right to be left alone"
Warren and Brandeis, Harvard Law Review, 1890
Universal Declaration of Human Rights
- Article 12: No one shall be subjected to arbitrary interference with his privacy...
- Article 18: Everyone has the right to freedom of thought, conscience, and religion
- Article 19: Everyone has the right to ... freedom to hold opinions without interference and to seek, receive, and impart information and ideas...
"All human beings have three lives: public, private, and secret"
Gabriel Garcia Marguez (literary author)
"Just because something is publicly accessible does not mean that people want it to be publicized"
danah boyd (technology & social media scholar)
"Privacy is what allows us to determine who we are and who we want to be."
Edward Snowden, NSA whistleblower
US Tort Law: Freedome from "intrusion of solitude, public disclosure of private facts, false light, and appropriation"
William Prosser, California Law Review, 1960
"Privacy is the ability to control one's reputation"
Siva Vaidhyanathan, cultural historian & media scholar
Privacy is strangely hard to define
The Privacy Debate
- As we've seen with other ethics topics, these concerns are not necessarily new
- Debate that began it all in 1980: an article on privacy in the Harvard Law Review (Warren & Brandeis 1890)
- they defined privacy as "the right to be left alone"

Image of “Reporters with various forms of "fake news" from an 1894 illustration by Frederick Burr Opper.”
https://commons.wikimedia.org/wiki/File:The_fin_de_si%C3%A8cle_newspaper_proprietor_(cropped).jpg
- Since then, there has been a tension between:
- individuals' right to control what information others know about them, and
- society's right to know important information about individuals
- Note that all of this revolves around information, and therefore, around information technology
- we can't separate notions of privacy from technology, they are now bound up in each other
2 common stances about Privacy and Computing
- There are basically two reactions to the flood of new technology and its impact on personal information and privacy:
- We have zero privacy in the digital age and that there is no way we can protect it, so we should get used to the new world and get over it (Sprenger 1999)
- Our privacy is more important than ever and that we can and we must attempt to protect it
- Privacy debates are complicated by notions of
- personhood
- property ownership
- freedom & autonomy
- identity

Image generated by DALLE-2, which cannot spell politics
What do we talk about when we talk about Privacy?
- Yes privacy is a philosophical debate with ties to what it means to be a person, how we define identity, and what exactly freedom means, and whether we own ourselves
- But in computing, sometimes it's easier to talk about data protection when we're really talking about privacy
- This gives us a much more tangible conception of
- what the object of protection is (personal data)
- what technology we can use to protect it
- which data should be protected and why?
- what laws can be enacted to protect it?
- what are the privacy risks associated with personal data?
Privacy Risks
Privacy threats come in several categories:
- Intentional, institutional uses of personal information
- Unauthorized use or release by “insiders”
- Theft of information
- Inadvertent leakage of information
- Our own actions
- sometimes a result of intentional trade-offs (we give up some privacy in order to receive some benefit)
- sometimes we are unaware of the risks
Why Protect Privacy?
- Prevention of harm: Unrestricted access to personal data by others can be used to harm the data subject
-
Informational inequality: Personal data are commodities with an economic value in markets
- Individuals are not able to negotiate contracts about the use of their data
- We don't all have the means to check whether companies live up to the terms of the contract
-
Informational injustice and discrimination: Personal information provided in one context (e.g. health care) may change its meaning when used in another sphere or context (e.g. commercial transactions)
- this could lead to discrimination / disadvantages for the individual
-
Encroachment on moral autonomy and human dignity: Lack of privacy can expose people to outside forces that influence their choices
- e.g. mass surveillance causes ppl to subtly change their choices b/c they know they are being watched
- if your choices are not wholly your own, are you an autonomous being? Recall deontology
- some argue human dignity = autonomy and modesty (having private mental state), so big data w/ no privacy = stripping them of personhood
- similarly, some say that privacy is necessary for development of the self
Privacy By Design
- The new generations of privacy regulations (with the EU’s central GDPR) now require standardly a “privacy by design” approach. Article 25 of the GDPR Data protection act explicitly states that ‘by design’ and ‘by default’ are mandatory
- The data ecosystems and socio-technical systems, supply chains, organisations, including incentive structures, business processes, and technical hardware and software, training of personnel, should all be designed in such a way that the likelihood of privacy violations is as low as possible.
Big Data
- So far we've talked about data's worldview, bias, and fairness
- We also talked about recommender systems, which can personalize content, but can also lead to bias amplification feedback loops
- All of this has come about from "big data" + algorithms
- however, the quest to collect increasingly huge amounts of data has led to people's privacy being violated
- amount of control over personal data is reduced
- what things are even considered "data" has also changed
- however, the quest to collect increasingly huge amounts of data has led to people's privacy being violated
Four (main) types of data
- Consciously given data: your name, email, date of birth
- Automatically monitored data (aka metadata): where you log in from, what time you log in, where else you visit on the web
- Inferred data: actual characteristics that are predicted from other data, e.g. your income level, education, or sexual orientation
-
Modeled data: assigned attributes or groupings that are outputs of machine learning analysis
- e.g. your quantified attractiveness, trustworthiness, spendthriftiness, etc
- many organizations don't consider modeled data to be personal data...is it?
https://plato.stanford.edu/entries/it-privacy/
In law, personal data is defined as data that can be linked with a natural person
Privacy Stakeholders
Surveillance capitalism: “An economic system built on the secret extraction and manipulation of human data” – Shoshana Zuboff
- Users (e.g. you)
- Data producers – Google, Meta, smaller players
- Data brokers – Epsilon, Acxion, etc.
- Nobody knows how many; probably tens of thousands
- Data purchasers – advertisers, anyone else that wants it
- Government agencies (NSA, FBI, etc.)
4 Privacy Myths
#1 Privacy is Dead
- The claim: Privacy is obsolete/impossible in the digital age
- Counter-argument: Privacy still matters because "It helps us avoid the calculating, quantifying tyranny of the majority. Privacy is thus essential for individuality and self-determination, with substantial benefits for society."
- How the myth emerged:
- Technological Advancements: Rapid growth in digital tech and data collection capabilities
- Influential Statements: Remarks like Scott McNealy’s “You have zero privacy anyway. Get over it.”
- Ubiquity of Surveillance: Increasing use of CCTV, online tracking, wearables, social media, and data breaches
- Why the myth persists:
- Technological Determinism: Belief that privacy loss is inevitable with progress
- Economic Interests: Companies benefit from data collection, downplaying privacy concerns
- Complexity of Privacy Management: Difficulties in managing privacy settings lead to resignation
resignation: the acceptance of something undesirable but inevitable.

4 Privacy Myths
#2 (Young) People Don't Care about Privacy
- The claim: People, especially young people, are indifferent to privacy.
- Counter-argument: People do care but face limited choices and complex systems. It appears people don't care due to mismanagement of privacy, not lack of interest.
-
How It Emerged
-
Youth & Social Media Usage: Perception that younger generations freely share personal info online
-
Surveys & Studies: Misinterpretation of data suggesting apathy towards privacy
-
Corporate Narratives: Companies downplay privacy concerns to justify data collection practices
-
-
Why It Persists:
-
Complex Privacy Settings: Users overwhelmed by complicated privacy management
-
Behavior vs. Attitude Gap: Actions (sharing online) misinterpreted as indifference, despite underlying concerns, called the "privacy paradox"
-
Normalization: Constant exposure to data sharing norms reduces perceived importance of privacy.
-
privacy paradox: where people express concern about privacy but still share personal information.

4 Privacy Myths
#2 (Young) People Don't Care about Privacy
- Example: Cambridge Analytica
4 Privacy Myths
#3 Nothing to Hide, Nothing to Fear
- The claim: Privacy is only necessary for those with something to hide.
- Counter-argument: Privacy is about controlling personal power and information. In fact, everyone needs privacy to protect personal autonomy.
- How the myth emerged:
- Technological Advancements: Rapid growth in digital tech and data collection capabilities
- Influential Statements: Remarks like Scott McNealy’s “You have zero privacy anyway. Get over it.”
- Ubiquity of Surveillance: Increasing use of CCTV, online tracking, wearables, social media, and data breaches
- Why the myth persists:
- Technological Determinism: Belief that privacy loss is inevitable with progress
- Economic Interests: Companies benefit from data collection, downplaying privacy concerns
- Complexity of Privacy Management: Difficulties in managing privacy settings lead to resignation
4 Privacy Myths
#4 Privacy is Bad for Business
- The claim: Privacy regulations hinder business operations.
- Counter-argument: Competing on privacy can be good for business, providing a competitive advantage
- How the myth emerged:
-
- Technological Advancements: Rapid growth in digital tech and data collection capabilities
- Influential Statements: Remarks like Scott McNealy’s “You have zero privacy anyway. Get over it.”
- Ubiquity of Surveillance: Increasing use of CCTV, online tracking, wearables, social media, and data breaches
- Why the myth persists:
- Technological Determinism: Belief that privacy loss is inevitable with progress
- Economic Interests: Companies benefit from data collection, downplaying privacy concerns
- Complexity of Privacy Management: Difficulties in managing privacy settings lead to resignation
resignation: the acceptance of something undesirable but inevitable.




Evaluating Privacy Programs - PREACH!
Preach is an acronym that consumers and professionals can use to assess the maturity and effectiveness of a privacy program.
- Purpose: Why is the company asking to use your data? What is the purpose, and is it necessary for you to use x service?
- Right to Request. Do you have the ability to request that your data be modified, removed, or otherwise altered? For example, change your name or address.
- Easy to understand. Is it easy to understand a company's policies? Are they being fully transparent?
- A stands for 'alerting'. Will you be alerted if the company mishandles your data?
- Consent - think of consent as permission for your information to be used
- How is the company or service planning to use your data? Are they using it to understand your shopping habits, or are they reselling it to a 3rd party advertising company?
Data Breaches
- Yahoo, a web portal and search engine company, had the largest data breach in history; this was both a security and a privacy failure. In 2013, over three billion users’ personal information was stolen; names, dates of birth, email addresses, and more were stolen. In 2016, a hacker group began to sell this information.
Data Re-identification Attacks
2000s: Insurance company collected patient data for ~135,000 state employees.
- Gave data to researchers, sold it to industry
- Re-identification by Linking Attack resulted in identification of the medical record of the former state governor
- Using medical data + voter registration database, the individuals can be re-identified by using a small number of attributes called quasi-identifiers
In 2006, Netflix released an anonymized dataset containing movie ratings from approximately 500,000,part of a competition to improve its recommendation algorithm.
- Netflix removed direct identifiers such as names and replaced them with random numbers, assuming this would protect user privacy
- Researchers cross-referenced the anonymized data w/ publicly available IMDb data
- Identified specific ppl by matching unique combinations of movie ratings and timestamps
AOL put de-identified/anonymized Internet search data (including health-related searches) on its web site. New York Times reporters were able to re-identify an individual from her search records within a few days (Porter, 2008).
Data De-Identification and Anonymization
specifies 18 data elements that must be removed or generalized in a data set in order for it to be considered “de- identified.” The HIPAA Safe Harbor data elements (aka direct identifiers) include the following:
1. Names
2. Zip codes (except first three)
3. All elements of dates (except year)
4. Telephone numbers
5. Fax numbers
6. Electronic mail addresses
7. Social security numbers
8. Medical record numbers
9. Health plan beneficiary numbers
10. Account numbers
11. Certificate or license Numbers
12. Vehicle identifiers and serial numbers, including license plate numbers
13. Device identifiers and serial numbers
14. Web Universal Resource Locators (URLs)
15. Internet Protocol (IP) address numbers
16. Biometric identifiers, including finger and voice prints
17. Full face photographic images and any comparable images
18. Any other unique identifying number, characteristic or code
Data De-Identification and Anonymization
In 1997, using a known birth date, gender and zip code, a computer expert was able to identify
the records of Gov. William Weld from an allegedly anonymous database of Massachusetts
state employee health insurance claims (Barth-Jones, 2015).
• In 2007, with information available on the Internet, Texas researchers utilizing a deanonymization methodology were able to re-identify individual customers from a database of
500,000 Netflix subscribers (Narayanan, 2008).
• In 2013, Science (Gymrek, McGuire, Golan, Halperin, & Erlich, 2013) reported the successful
efforts of researchers in identifying “deindentified” male genomes through correlations with
commercial genealogy databases.
• Students were able to re-identify a significant percentage of individuals in the Chicago
homicide database by linking with the social security death index (K. El Emam & Dankar, 2008).
• AOL put de-identified/anonymized Internet search data (including health-related searches) on
its web site. New York Times reporters were able to re-identify an individual from her search
records within a few days (Porter, 2008).
Data De-Identification and Anonymization
Measuring the “Identifiability” of Data
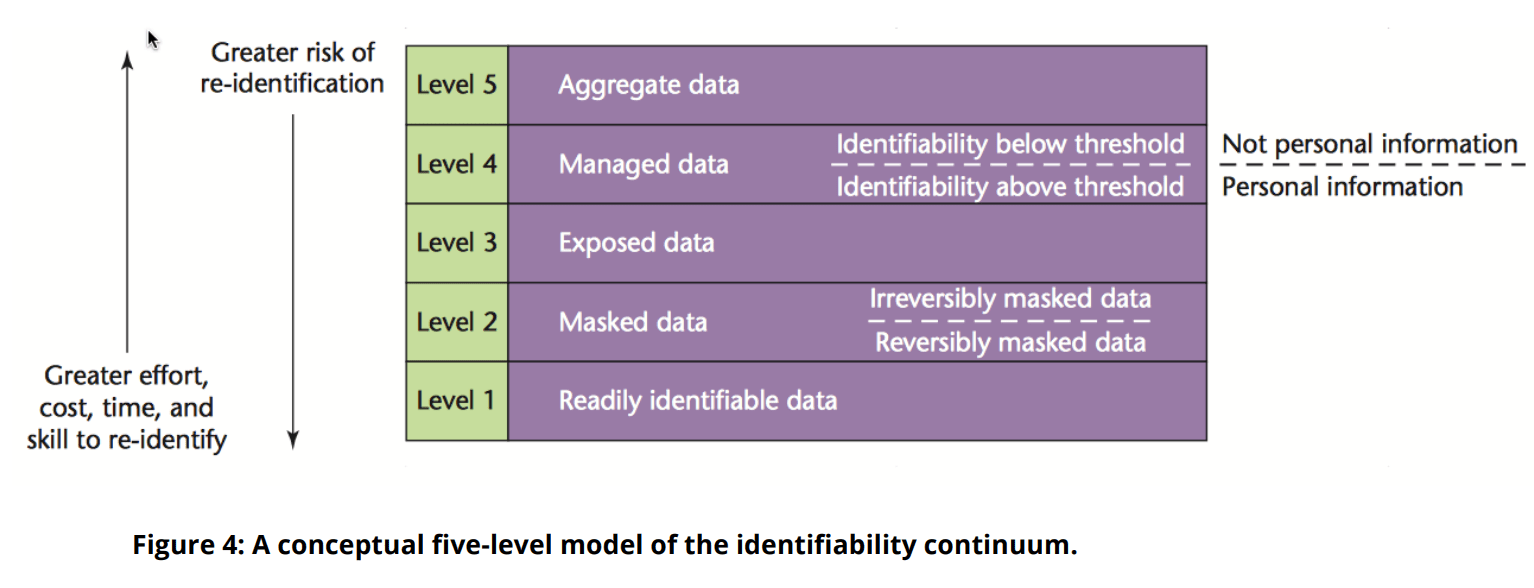
Data Privacy Goals
- Goals: re-process and structure datasets to
- maintain ability to derive meaningful information
- make the data open for researchers + public to access and use
- while simultaneously protecting the data from fraud, unintended use, or misinterpretation (and resultant inappropriate action)
- One approach: simply replace personal information with surrogates that can later be used to look up the real values (for example, create surrogate keys as found with randomization or blinded studies)
- Or, simply drop the sensitive columns (e.g. verbatim descriptions used in clinical trials adverse event reports)
- Or, recode the variables (age or age range instead of date of birth)
Data De-Identification vs. Anonymization
De-identification
- removing or obscuring any personally identifiable information
- minimizes the risk of unintended disclosure of the identity of individuals
Anonymization
- produces new data where individual records cannot be linked back to an original because they do not include the required translation variables
- two types of variables
-
direct identifiers: fields that can uniquely identify individuals e.g. names, SSNs and email addresses
- key-attributes (e.g. name, address, phone number) always removed before releasing the data
- quasi-identifiers (also known as indirect identifiers): on their own, don't uniquely identify an individual but, when combined with other quasi-identifiers or external information, could lead to re-identification (e.g. zip code, age gender)
-
direct identifiers: fields that can uniquely identify individuals e.g. names, SSNs and email addresses
Types of Identifiers + Attributes
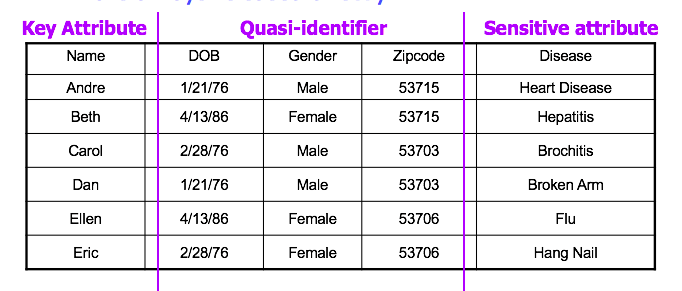
Note another category of attributes: sensitive attributes. Examples include medical records, salaries, etc.
- should we just remove those too?
- Usually they are values we want to predict or group by
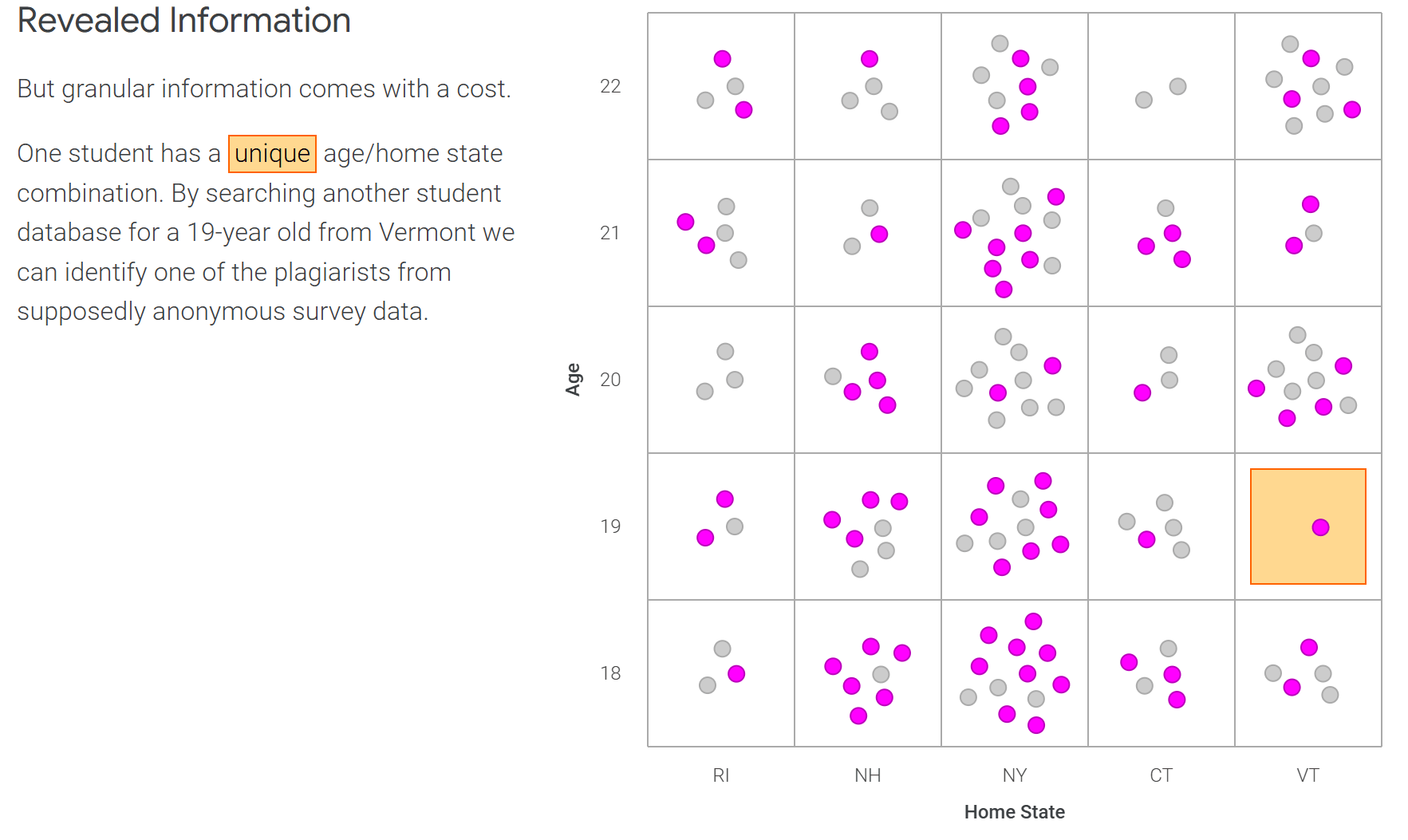
k-anonymity
87% (216M of 248M) of the US population is uniquely identifiable based only on:
- 5-digit ZIP code
- Gender at birth
- Date of birth
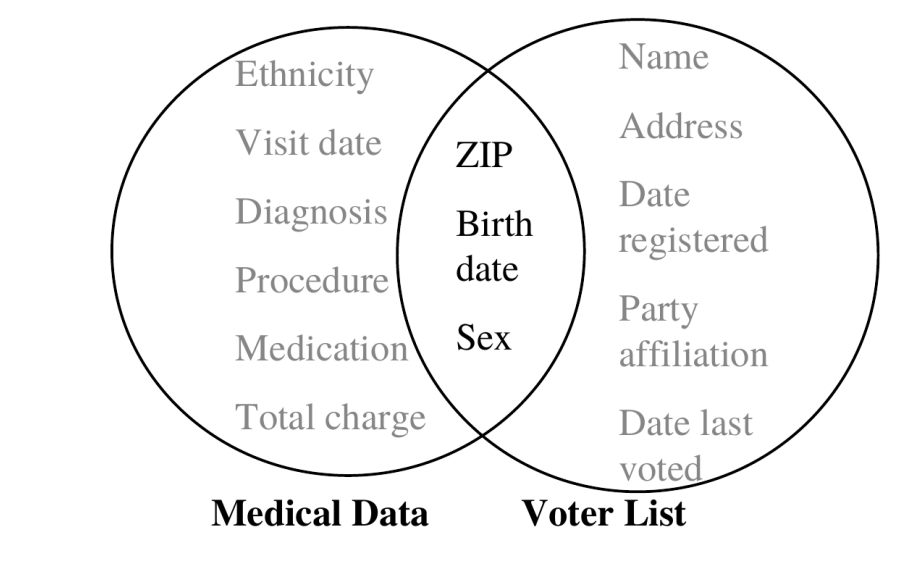
can do re-identification attack by linking quasi-identifiers with external information e.g. medical data, voter registration
quasi-identifiers: Attributes that in combination can uniquely identify individuals
Sweeney. K-anonymity: A model for Protecting Privacy. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 10(5):557–570, 2002
k-anonymity
- Method for anonymization: Hiding individuals in a crowd
- Goal: generalize attributes to hide them in larger groups
- Each unique combination of attribute values must appear in the dataset at least k times to obscure individuals' identities.
- The "k" in k-anonymity = the minimum number of people in a group that must share the same "attribute"
k-anonymity
Methods to achieve it:
-
Suppression: Values replaced with ‘*’
- All or some values of an attribute may be replaced
- Attributes such as “Name” or “Religion”
- Common to use for outliers
-
Generalization: Values replaced with a broader category
- ‘19’ of the attribute “Age” may be replaced with ‘≤ 20’
- Replace ‘23’ with ‘20 < Age ≤ 30’
- Note there will always be some information loss!
k-anonymity
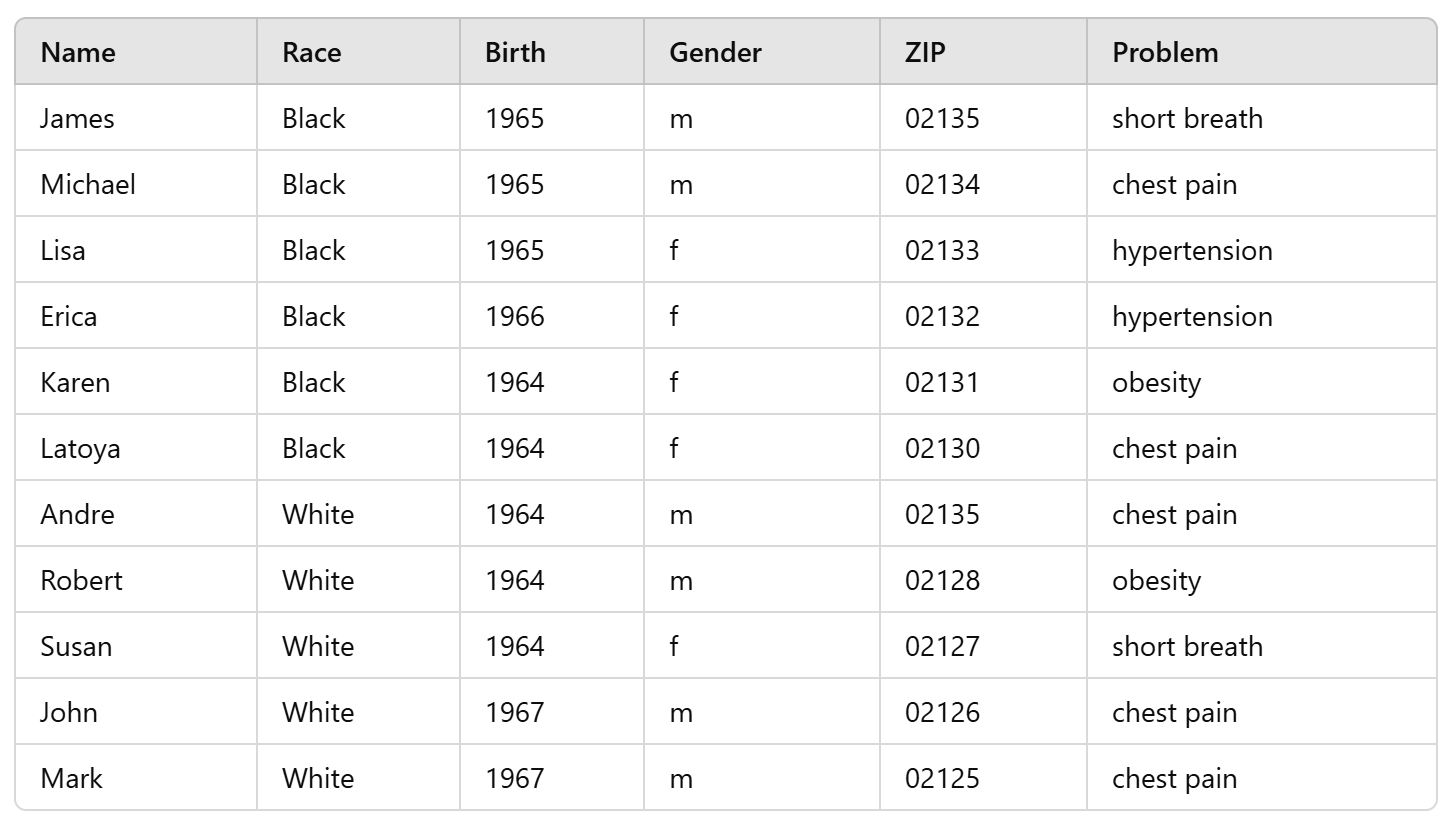
- for k-anonymity, your information contained in the released dataset cannot be distinguished from at least k-1 other individuals in the dataset
- Quasi Identifiers (QI) = {Race, Birth, Gender, ZIP}
- Problem/Disease is a sensitive attribute
- let's say we want k = 2
k-anonymity
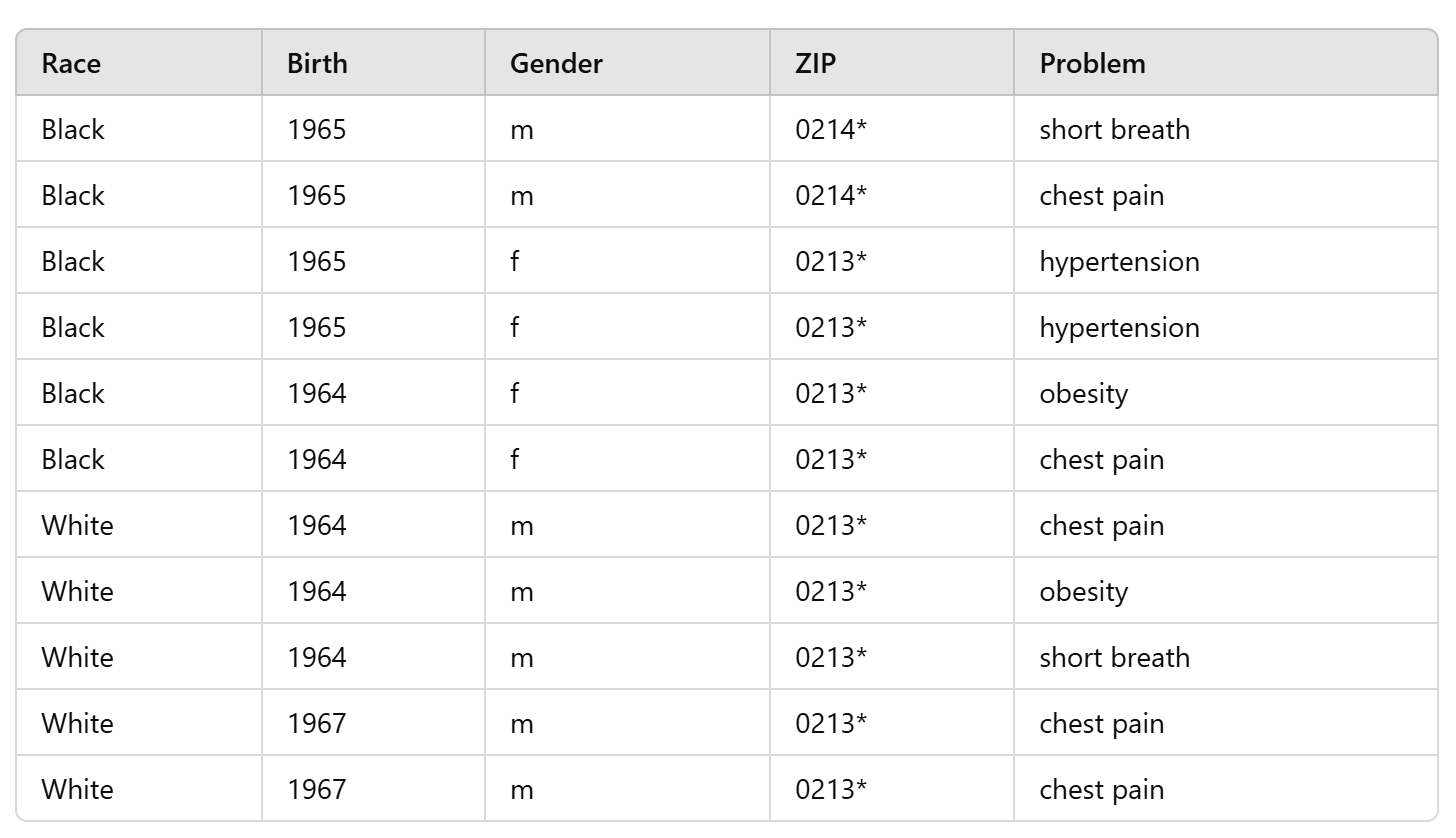
- for k-anonymity, your information contained in the released dataset cannot be distinguished from at least k-1 other individuals in the dataset
- Quasi Identifiers (QI) = {Race, Birth, Gender, ZIP}
- Problem/Disease is a sensitive attribute
- let's say we want k = 2
2-anonymous new data
k-anonymity
- for k-anonymity, your information contained in the released dataset cannot be distinguished from at least k-1 other individuals whose information also appear in the dataset
2-anonymous new data
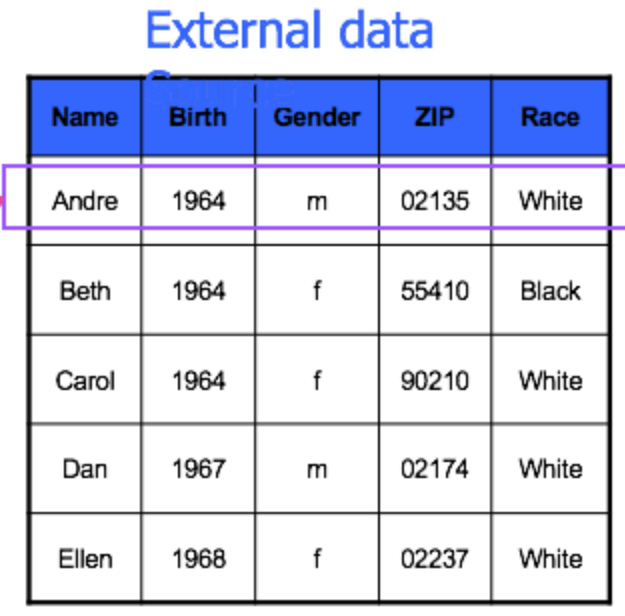
Because the dataset is now 2-anonymous, we're not sure what Andre's medical problem is, because there are other people that this external data could correspond to
He's been hidden in the crowd!
k-anonymity
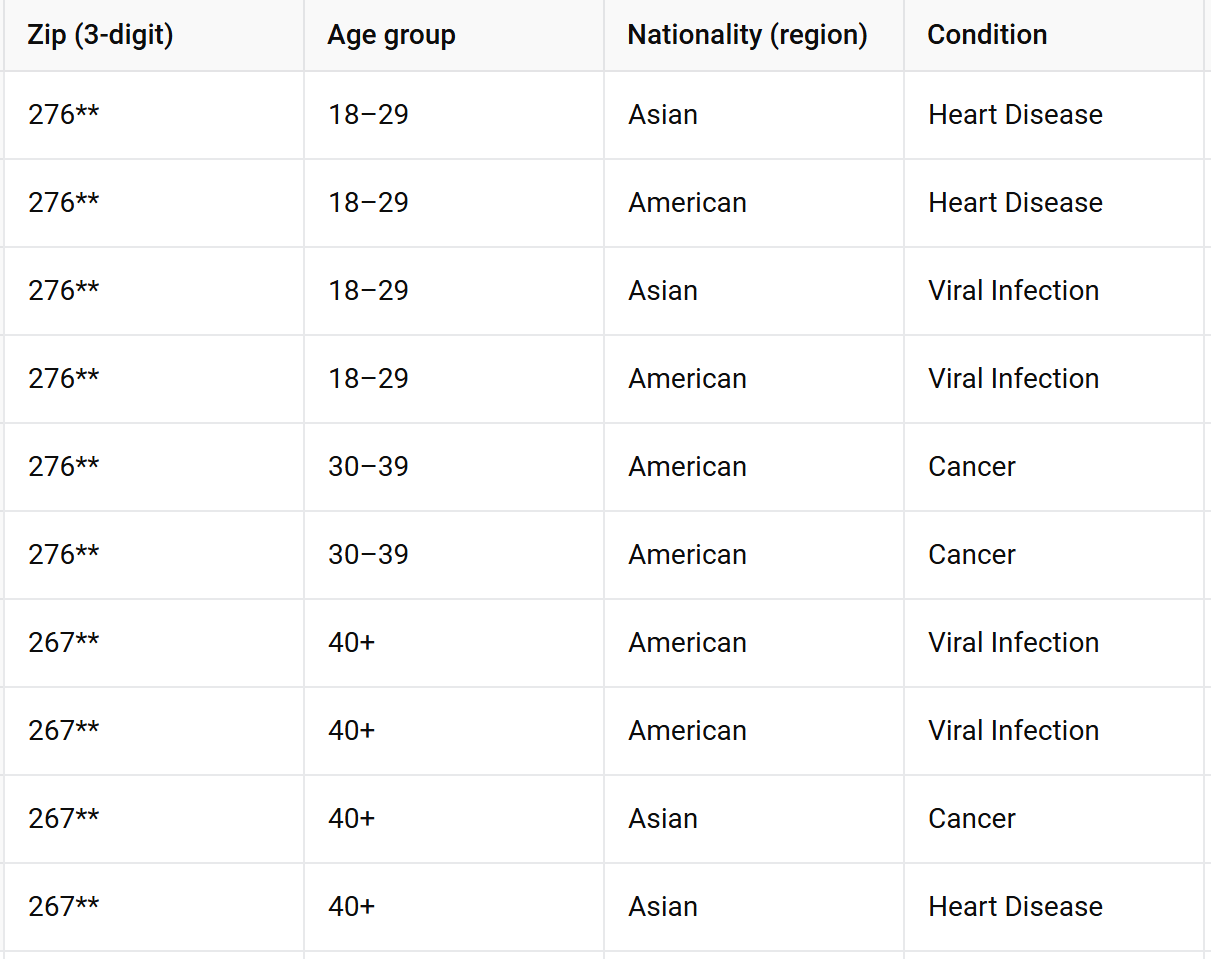
Your turn!
make this table 2-anonymous
https://www.sciencedirect.com/science/article/pii/S0167404821003126
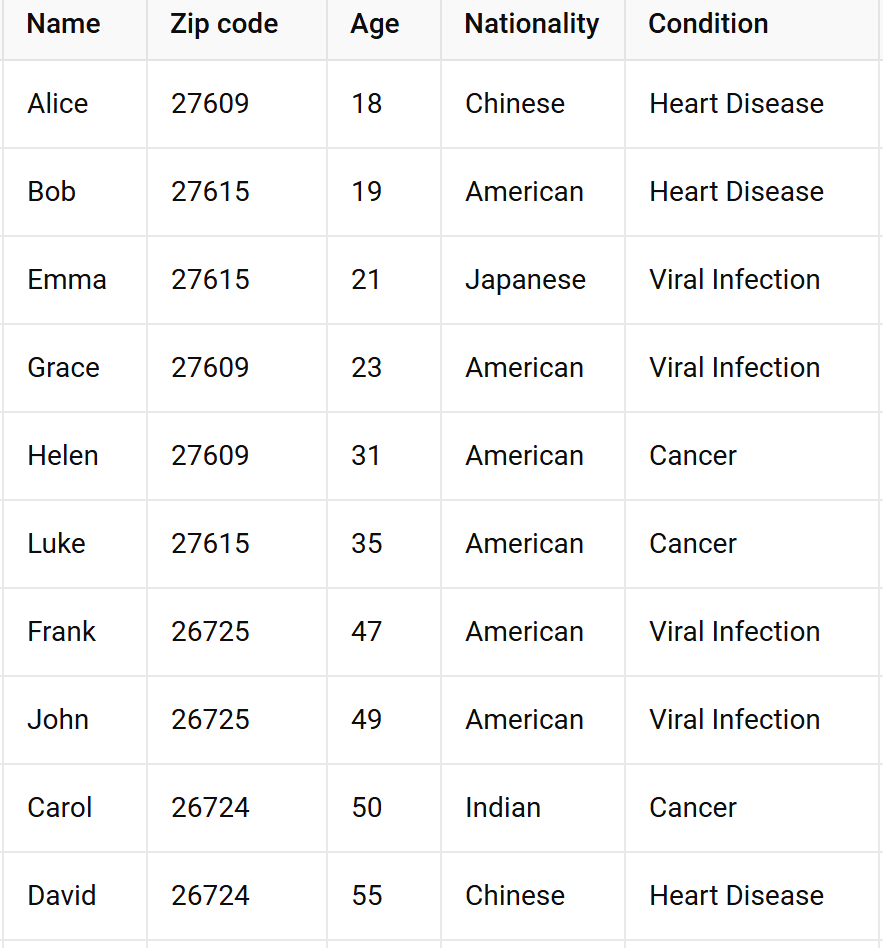
k-anonymity
Your turn!
Tip: sometimes it can help to draw hierarchies of values to figure out how to generalize them, or if you need to suppress them all together
here's one for zip codes starting with 3
https://www.sciencedirect.com/science/article/pii/S0167404821003126
original zips
level 0
level 1
level 2
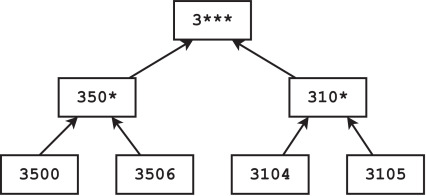
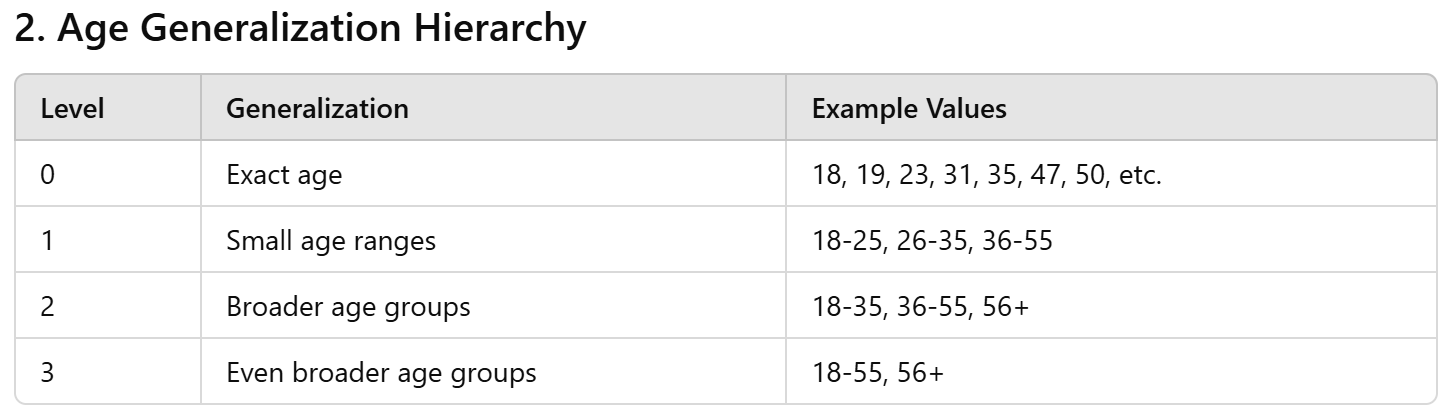
Here's one for age
k-anonymity
Your turn!
make this table 2-anonymous
https://www.sciencedirect.com/science/article/pii/S0167404821003126
-
Suppression: Values replaced with ‘*’
- All or some values of a column may be replaced
- Generalization: Values replaced with a broader category
k-anonymity
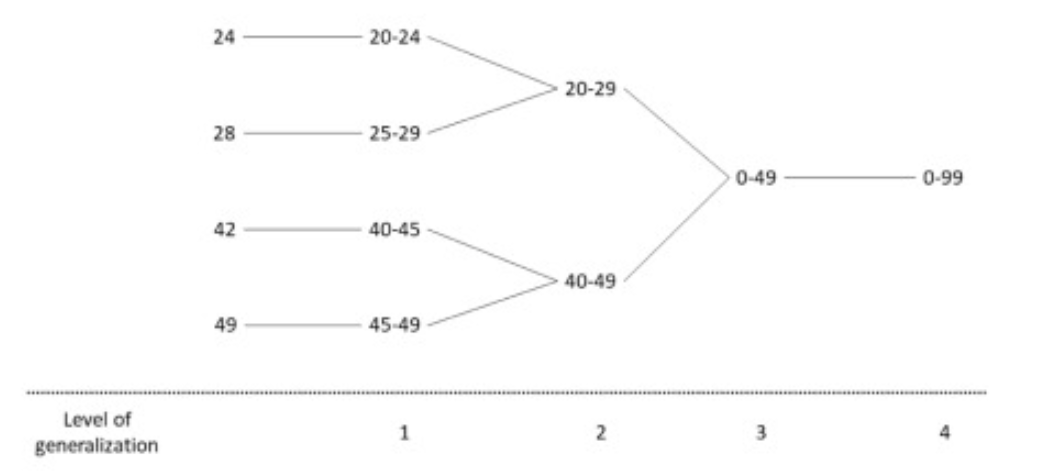
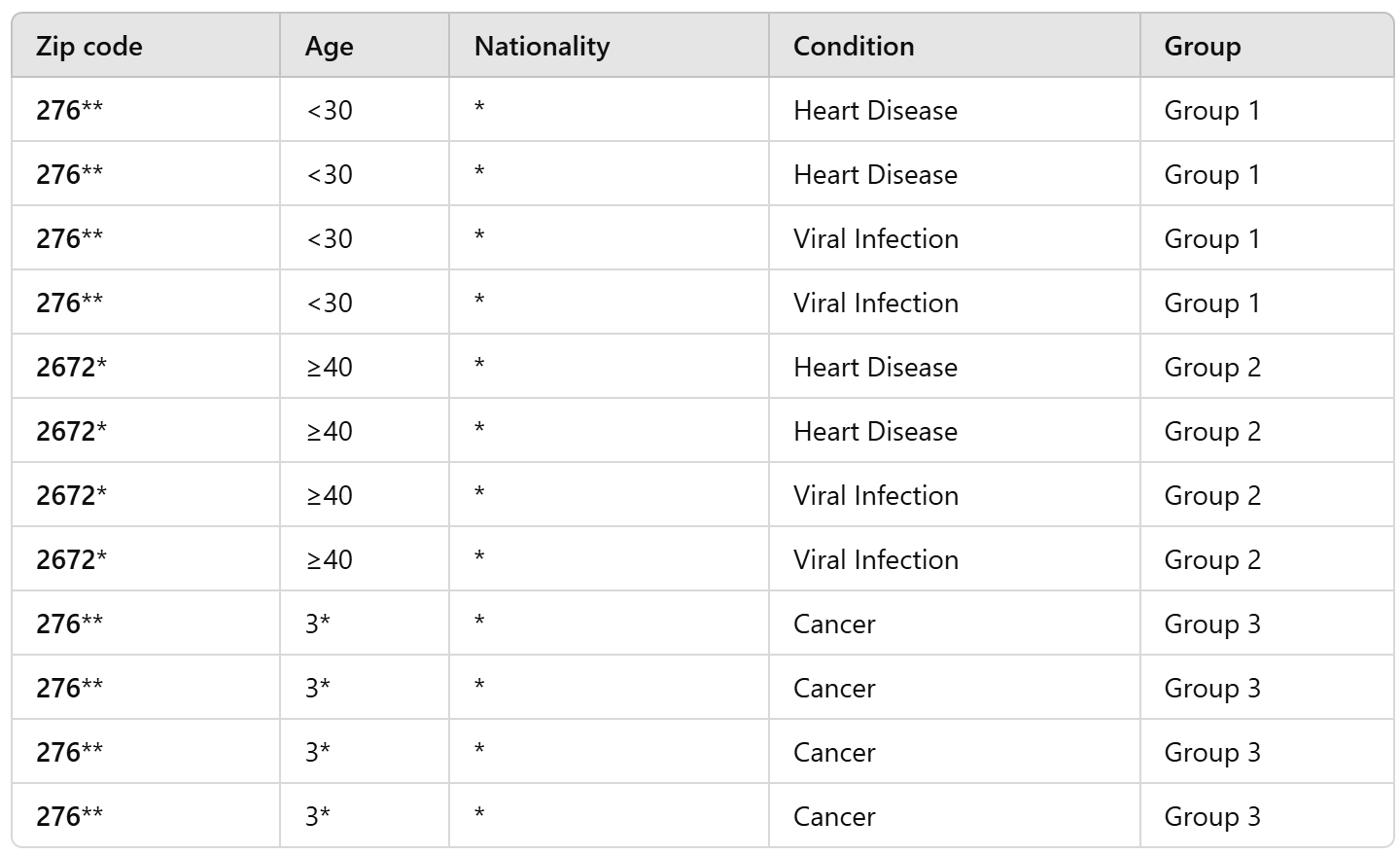
Exercise
make this table 2-anonymous
we can generalize Zip code and Age:
-
Zip Code: Group into broader regions based on the first three digits:
- 276xx for Zip codes starting with 276
- 267xx for Zip codes starting with 267
-
Age: Group into age ranges:
- 18-35
- 36-55 (or 36+)
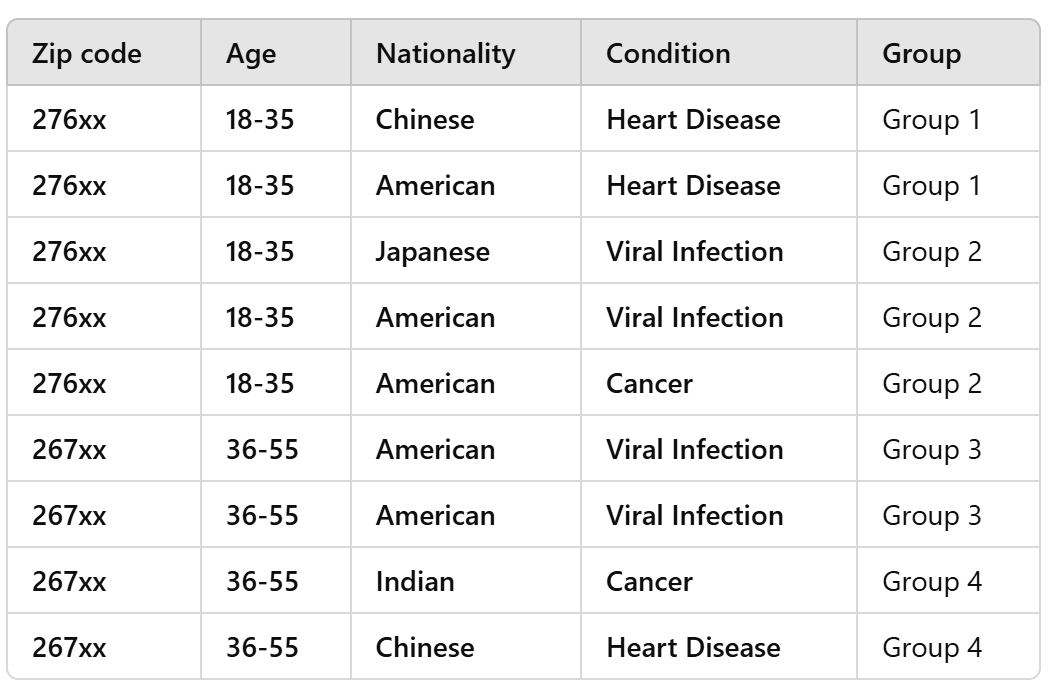

Some options, but there are many more!
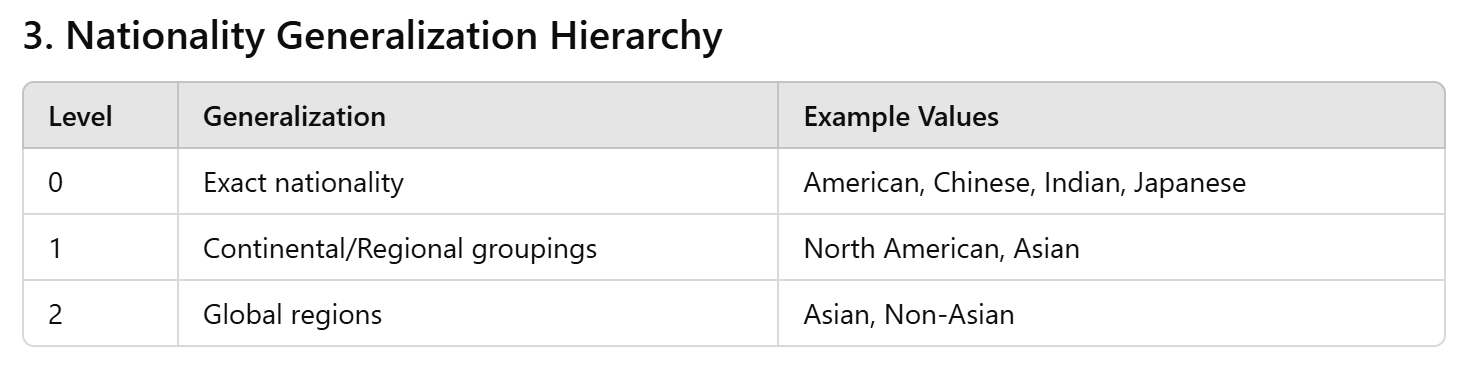
If nationality is important to the analytic task, we can generalize it instead of suppress it...
Example: a hospital wants to check whether certain conditions are under-diagnosed among immigrant groups so it can tailor outreach and translation services
- If we suppress Nationality entirely, any disparity (e.g., higher viral infection readmissions among Asian patients vs. American patients) would be invisible
...if we needed it 4-anonymous
CMSC 304
Social and Ethical Issues in Information Technology
Attacks on k-anonymity
3 common attacks
- Unsorted matching attack
- Based on the order of rows in the released datasets
- This problem is often ignored in real-world use
- Easy to correct by randomly sorting the rows
- Complementary release attack
- Temporal inference attack
Other methods than k-anonymity
- differential privacy - apply noise to data
- data masking - hide some attributes
De-anonymization attacks
- Linking datasets (public or private) together to gain additional information about users
- Even if sensitive attributes are not contained in the dataset, they can be inferred with high accuracy

Activity
In your group, read through an article about how automatically monitored data is being collected and modeled
https://guides.libraries.psu.edu/berks/privacy#s-lg-box-19510455
Report back on the positive and negative impacts of these practices on individuals and society.
Algorithms & the Information Ecosystem
Micro-lecture (10-15 minutes)
- “fake news”, misinformation, and information warfare are not new concepts or techniques.
- Quote from Jonathan Swift’s 1710 essay, “The Art of Political Lying”
- What is new and novel about our current information ecosystem?
- The volume of information produced and disseminated at an increasingly rapid rate
- The complexity of our info ecosystem is only possible through the implementation of algorithms
“Falsehood flies, and truth comes limping after it, so that when men come to be undeceived, it is too late; the jest is over, and the tale hath had its effect.”
Image of “Reporters with various forms of "fake news" from an 1894 illustration by Frederick Burr Opper.”
https://commons.wikimedia.org/wiki/File:The_fin_de_si%C3%A8cle_newspaper_proprietor_(cropped).jpg

Algorithms & the Information Ecosystem
Micro-lecture (10-15 minutes)
- “fake news”, misinformation, and information warfare are not new concepts or techniques.
- Quote from Jonathan Swift’s 1710 essay, “The Art of Political Lying”
- What is new and novel about our current information ecosystem?
- The volume of information produced and disseminated at an increasingly rapid rate
- The complexity of our info ecosystem is only possible through the implementation of algorithms
“Falsehood flies, and truth comes limping after it, so that when men come to be undeceived, it is too late; the jest is over, and the tale hath had its effect.”
Image of “Reporters with various forms of "fake news" from an 1894 illustration by Frederick Burr Opper.”
https://commons.wikimedia.org/wiki/File:The_fin_de_si%C3%A8cle_newspaper_proprietor_(cropped).jpg
Algorithms & the Information Ecosystem
Micro-lecture (10-15 minutes)
- What is new and novel about our current information ecosystem?
- The volume of information produced and disseminated at an increasingly rapid rate
- The complexity of our info ecosystem is only possible through the implementation of algorithms
- Brief overview of algorithms, the tasks they perform, machine-learning, and recommender systems / personalization.
- Hello World by Hannah Fry
- How to Teach Yourself About Algorithms by Jennifer Golbeck
- Recommendation Engines by Michael Schrage
“Falsehood flies, and truth comes limping after it, so that when men come to be undeceived, it is too late; the jest is over, and the tale hath had its effect.”
Image of “Reporters with various forms of "fake news" from an 1894 illustration by Frederick Burr Opper.”
https://commons.wikimedia.org/wiki/File:The_fin_de_si%C3%A8cle_newspaper_proprietor_(cropped).jpg
Example Browser Data
Dark Patterns
Who Should Regulate Privacy?
Market
- "Consumers are more likely to choose companies that are transparent and honest regarding their personal data collection and usage." (Invisibly.com, ACLU, Privacy & Free Speech: It's Good for Business)
Design
Privacy by Design means:
- Privacy is the default setting
- Transparency
- Respect for user privacy
Law
- "Notice and consent"
- FERPA, HIPAA
- FTC Regulations
- CCPA
- GDPR
Norms
- Privacy culture of shared values and behaviors
Dark Patterns
activity: do this quiz and take notes on what the patterns are called and their descriptions
What kinds of data about you is out there?
Text
- bullet
- bullet
Reflection
Where have you left data tracks today?
What data do you think is collected about you regularly?
What apps do you use daily? Weekly?
What steps do you already take to protect your data?
What does privacy mean to you?
Pros and Cons of Large Scale Data
Benefits of large-scale data
- Better online ads
- Public health – disease tracking, research, management
- National security
- Smart grids/energy optimization
- Supports widely available free services
“Because the commoditization of consumer data isn’t likely to end anytime soon, it’s up to the businesses that gather and profit from this data to engage directly with their customers and establish data protections they will trust.”[1]
Human Insights Missing From Big Data
Text
- bullet
- bullet
Discussion
How much does consent matter, vs. consequences?
- Name three major stakeholders in the current state of surveillance capitalism, including at least one that benefits from having personal data freely available
- Propose a policy to limit collecting and/or sharing of personal data, considering data sources and effects on all stakeholders
- What are the positive and negative consequences of the policy? How can the negative consequences be (somewhat) ameliorated?