阿格里森姆 - 4
資料結構的第二堂
Lecturer:我真的好想看 𝄇 喔
人稱滿等塑膠怪
aka Repkironca、阿蘇
怎麼可能
又是 STL
陳亮延你可以不要什麼都砸 map 嗎
就 unordered_set 而已
完蛋了 pD 寫不出來...
undset <bool> exist
西曆2022年
A
P
C
S
不想
讀書
StackOverflow
學長我不想再手刻資結了
linked_list
「AtCoder 上分率0.0000000001%」
段考倒數
白癡才
接執秘
學
術
補
完
Do you hear the people sing?

真的啦,今天絕對教得完
I 演算法資料庫 <algorithm>
當然你也可以全部都用手刻
What is <algorithm>
- ㄛ,但他實際上不能幫你解算法題 ~(>_<。)\
- 包含一大堆功能,比起手刻簡潔很多
- C++ 中的 library 之一,記得要先 include
#include <algorithm> //引入 algorithm
// or
#include <bits/stdc++.h> //萬能標頭檔,裡面包含 algorithm 了- 功能很雜,所以我簡報很難做,so sad
max()、min()
warning : 如果直接 max/min (a, b, c) 會 Complie Error
int maximum = max({123, 456, 789});int maximum = max(123, max(456, 789));在 max 裡面再塞 max
ㄘㄇㄏ:
在 max 中塞大括號
min (a, b): 回傳 a、b 間 較小 的那隻
max (a, b): 回傳 a、b 間 較大 的那隻
int a = max(5, 10); // 10
int b = min(a, 3); // 3e.g.
swap()
swap (a, b):
交換 a 與 b,a、b 可以是 任何 STL 或變數
不過 a、b 必須 同型態
e.g.
int a = 1, b = 5;
swap(a, b);
cout << a << ' ' << b << '\n';
//OUTPUT : 5 1vector <bool> vec_1, vec_2;
// 各種對 vector 的操作...
swap(vec_1, vec_2);- swap 並不會改變本身記憶體位置
int 的交換
vector 的交換
swap()
int a = 2, b = 3;
int *a_ptr = &a, *b_ptr = &b;
cout << a_ptr << ' ' << b_ptr << '\n';
cout << *a_ptr << ' ' << *b_ptr << '\n';
cout << &a_ptr << ' ' << &b_ptr << '\n';pointer 的交換
| 名稱 | a | b | a_ptr | b_ptr |
|---|---|---|---|---|
| 位置 | 0x01 | 0x02 | 0x03 | 0x04 |
| 值 | 2 | 3 | 0x01 | 0x02 |
swap(a_ptr, b_ptr);
cout << a_ptr << ' ' << b_ptr << '\n'; //0x02 0x01
cout << *a_ptr << ' ' << *b_ptr << '\n'; //3 2
cout << &a_ptr << ' ' << &b_ptr << '\n'; //0x03 0x04兩邊的值交換!
reverse()
reverse (first, last):
first、last 是 iterator
反轉 [from, to) 間的所有元素
reverse(vec.begin(), vec.begin()+5); //反轉前半部分
// 4 3 2 1 0 5 6 7 8 9reverse(vec.begin(), vec.begin()+1); //什麼都不會做
// 0 1 2 3 4 5 6 7 8 9[0, 5)
[0, 1)
O(N)
vector <int> vec;
for (int i = 0; i < 10; i++) vec.push_back(i);
// 0 1 2 3 4 5 6 7 8 9reverse(vec.begin(), vec.end()); //反轉整個 vector
// 9 8 7 6 5 4 3 2 1[0, 10)
e.g.
總共會跑 \(\frac{N}{2}\) 次,O(\(\frac{N}{2})\in O({N})\)
next_permutation()、prev_permutation()
- 按 字典序 排列:從 最左邊 開始比較,數字越小則字典序越小
| I | 123 |
|---|---|
| II | 132 |
| III | 213 |
| IV | 231 |
| V | 312 |
| VI | 321 |
e.g.
123 < 213
312 < 321
213 < 312

next_permutation(first, last):
first, last 是 iterator
直接把 iterator 指向物件間的數字
變成 下個字典序 之排列
若不存在,會變回 最小字典序排列
且本函式 回傳 false
prev_permutation(first, last):
同 next_permutation
但改成 上個字典序 之排列
若不存在,則變成 最大字典序排列
e.g.
vector <int> vec;
for (int i = 1; i <= 4; i++) vec.push_back(i);
// {1, 2, 3, 4}next_permutation(vec.begin(), vec.end());
// {1, 2, 4, 3}prev_permutation(vec.begin(), vec.end());
/* 因為 {1, 2, 3, 4} 沒有上一個字典序了
所以變成最大字典序 {4, 3, 2, 1} */想一想
要怎麼由小到大
依序印出 {1, 2, 3, 4, 5}
的字典序排列?
這是去年你們學長遇到的困擾
這是去年你們學長的學長的簡報
這是今年你們學長的簡報
明年的學術,你知道要怎麼做了吧
有一說一,陳亮延到底做了什麼?
用 while
翻譯年糕:拿 for 跑過整個陣列,從左掃到右
比大小
翻譯年糕:每次挑兩個數字 a, b出來,看誰比較大
後 swap
翻譯年糕:如果 a > b,那 a 應該在右邊,所以 swap(a, b)
陳亮延忘記說的那些事
- 實際上要 兩層迴圈!
| 9 | 2 | 5 | 4 | 7 | 1 | 6 | 8 | 3 | 0 |
|---|
9 要跑到最右邊,需要 9 次 swap()
但第一次迴圈就會做完
若 0 要跑到最左邊,也需要 9 次 swap()
且需要跑到 9 輪迴圈
- 他根本沒掃整個陣列,到 n-1 項就可以停了
在第 N-1 項會比較 N-1 與 N 的大小
若跑到 N,會超出陣列範圍 ㄘ RE
扣掉他噁心的 coding-style,大概是這個意思
vector <int> bubble_sort(vector <int> vec){
for (int i = 0; i < vec.size()-1; i++){
for (int j = 0; j < vec.size()-1; j++){
if (vec[j] > vec[j+1]) swap(vec[j], vec[j+1]);
}
}
return vec;
}我覺得數字太大會 TLE
這個實際上叫 泡沫排序法,Bubble Sort
APCS 觀念很愛考,而且 10 次中有 9 次會被它寫爛
O(\(N^2\))
O(\(N^2\)) 好慢ㄛ,有沒有什麼快一點的方法
有。而且還不用自己刻,超級讚
std::sort!!!
sort(from, to, function)
- from、to 都是 iterator,範圍是 [from, to)
sort(vec.begin(), vec.end()); //預設升序
// {1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
sort(vec.begin(), vec.end(), greater <int>())
// {10, 9, 8, 7, 6, 5, 4, 3, 2, 1}vector <int> vec;
for (int i = 2; i <= 10; i += 2) vec.push_back(i);
for (int i = 1; i <= 10; i += 2) vec.push_back(i);e.g.
- function 為比較的方式,分為下面三種,預設為升序
-less <int>() 升序排列
-greater <int>() 降序排列
-自己刻出的函式名 自訂排序方式
sort(from, to, function)
- 複雜度?
O(N log N)
而且本身經過好幾重優化
就算你刻出 O(N log N) 的 sort function
要比 std::sort 快也有難度
- 那如果我是 array 教的,可以用這方法嗎
但在此大力宣傳 vector,用習慣之後很舒服的
-把 from, to 改成 指向開頭、結尾 + 1的 pointer
e.g.
int arr[10] = {2, 4, 6, 8, 10, 1, 3, 5, 7, 9};
sort(arr, arr+10, greater <int>());自訂排序方式
若我想排序的東西不是 int
而是 pair、struct、queue 之類的呢
- 超級重要:若 a、b 完全等價,要確保會 return false
- 自己刻一個 function,吃進兩個參數,回傳一個 bool
#define pii pair <int, int>
#define F first
#define S second
bool cmp(pii a, pii b){
}- 若最後回傳 true,代表 a 要排在前面 若回傳 false,代表 b 要排在前面
{3, 4}、{6, 8}
-> return false
{5, 7}、{2, 15}
-> return true
{13, 8}、{13, 4}
-> return true
{9, 5}、{9, 5}
-> return false
為什麼不能這樣寫?
bool cmp (pii a, pii b){
if (a.F < b.F) return false;
if (a.S < b.S) return false;
return true;
}e.g.
bool cmp (pii a, pii b){
if (a.F > b.F) return true;
if (a.S > b.S) return true;
return false;
}你會跟講師一樣在資芽上機考噴掉 100 分
(a.F == b.F && a.S == b.S)
return true
還有什麼比 O(N log N) 更快的方法ㄇ
-有啊,best case O(1)
-為什麼說 best case 呢,因為它 worst case
-這只是我講爽的,超級不建議使用
- 每次都把整個數列套一次隨機,然後檢查我排好了沒
Bogo Sort 猴子排序
- 聽過 無限猴子定理 嗎

- 複雜度從 O(1) 到 O(\(\infty\)),無敵的吧
我看過很多 sort 的問題,然後都忘光ㄌ
現在你可以直接砸 <algorithm> 了
白癡才用遞迴刻 DFS
去年的資芽語法二階上機考
切身之痛,我剛剛的 噴掉 100 分 就是這一題
很裸很裸的裸題
大概 1 分鐘就 AC 那種(註:它會卡 long long)
裸ㄉ,很舒服
這樣就有 100 分了耶,不香嗎
II 優先隊列 priority_queue
除非你想一直 sort(),但很小丑

這是高二的英雜單字
Ivan Lo:可是我高一就會了耶

Wt is priority_queue
-
對,就是一個 queue,所以要 #include <queue>
- 裡面的元素 永遠 按照 升序 / 降序 排列
- 複雜度?
push():O(log N) top():O(1) pop():O(log N) size():O(1) empty():O(1)
宣告 priority_queue
*可以善用 define
priority_queue <型別, 容器, 排序方式> 命名
-int、long long、pii、pipii 等都是常見的型別
-容器部分,一般會拿 vector,我也沒看過其他ㄉ
-排序方式,less <型別> 使 top() 為最大,
greater <型別> 使 top() 為最小
priority_queue <int, vector <int>, less<int> > pq; //升序
priority_queue <int> pri_que; //預設就是用 vector、lesspriority_queue <int, vector <int>, greater<int> > pq; //降序e.g.
*如果出現 >>,建議在中間加空格 避免誤判
.push(x)
e.g.
- 將 x 推進 priority_queue 中,且擺在正確的位置
priority_queue <int> pq;
pq.push(5); //{5}
pq.push(3); //{3, 5}
pq.push(13); //{3, 5, 13}O(log N)
.top()
e.g.
- 回傳 priority_queue 最上面的那個值
priority_queue <int> pq;
pq.push(5);
pq.push(3);
cout << pq.top() << '\n'; // 5
pq.push(13);
cout << pq.top() << '\n'; // 13O(1)
.pop()
e.g.
- 把 priority_queue 的 top() 踢出去
priority_queue <int> pq;
pq.push(5); //{5}
pq.push(3); //{3, 5}
cout << pq.top();
pq.pop(); // {3}
cout << pq.top();O(log N)
.size()
e.g.
- 回傳一個 unsigned int 代表 priority_queue 裡還有多少元素
priority_queue <int> pq;
pq.push(5);
pq.push(3);
pq.push(13);
cout << pq.size() << '\n'; // 3O(1)
while(pq.size()){
}只要 pq 中還有元素就繼續跑
.empty()
- 回傳一個 bool 代表 priority_queue 是否為空
O(1)
- 只要有用到 pop() 建議都搭配 empty() 使用 避免對空的 pq 取 top(),會 Runtime Error
e.g.
priority_queue <int> pq;
while (!pq.empty()) pq.pop();強制清空 priority_queue
單考 priority_queue 的題目好少ㄛ
雖然他叫 heap 練習
但不建議真的刻一棵 heap 出來
寫不出來滿正常的,因為這是 Greedy
但去年 yeedrag 放在 pq,我被搞得很慘
所以我要你們跟我一樣:)
III 集合 set
我永遠會在該砸 set 時忘記它的存在
What is set?
- 字面上的意思,同數學上的集合
- 具有 唯一性,每個元素只有一個
- 裡面的元素是 有序 的
- 不支援 []、top() 等功能,只能拿 iterator 訪問
- 本身是一顆 紅黑樹,所以很多複雜度帶 log
insert():O(log N)
erase():O(log N)
count():O(log N)
size():O(1)
empty():O(1)
- 顯然我們需要 #include <set>
clear():O(N)
宣告 set
set <型態> 命名
#define pii pair <int, int>
set <int> exist;
set <pii> history;e.g.
.insert(x)
- 把 x 加進 set 中
- 如果 x 早就存在,那 什麼也不會發生
set <int> exist;
exist.insert(2); // {2}
exist.insert(5); // {2, 5}
exist.insert(1); // {1, 2, 5}
exist.insert(5); // 什麼也不會發生,{1, 2, 5}e.g.
O(log N)
.count(x)
O(log N)
- 回傳一個 int,代表 x 在 set 中的數量
set <int> exist;
exist.insert(2); // {2}
if (exist.count(2)){
//...
}else{
//...
}e.g.
在一般 set 中非 0 即 1,所以可以 直接當 bool 用!
.erase(x)
O(log N)
- 把 x 從 set 中踢出,並 回傳 true
set <int> exist;
int tmp; cin >> tmp;
if (exist.erase(tmp)){
cout << tmp << " deleted\n";
}else{
cout << "It has never existed\n";
}- 如果 x 本來就不存在,那什麼都不會發生,並 回傳 false
e.g.
.size()
- 回傳一個 unsigned int 代表 set 裡還有多少元素
set <int> exist;
exist.insert(1);
cout << exist.size() << '\n'; // 1
exist.insert(2);
cout << exist.size() << '\n'; // 2
exist.insert(1);
cout << exist.size() << '\n'; // 2O(1)
e.g.
.empty()
- 回傳一個 bool 代表 set 是否為空
set <int> exist;
if (exist.empty()) cout << "The set is empty\n";
else cout << "There are something in the set\n";
O(1)
e.g.
.clear()
- 強制把整個 set 清空
set <int> exist;
exist.insert(1);
exist.clear();
if (exist.empty()) cout << "The set is empty\n";
else cout << "There are something in the set\n";
// The set is emptye.g.
O(N)
unordered_set
- 語法基本上與 set 相同,宣告換成 unordered_set 就好
e.g.
#define unordered_set und_set
und_set <int> exist;- 本身是 hash table,保有 set 的 唯一性,但 不再自動排序
| set | unordered_set | |
|---|---|---|
| .insert() | O(log N) | O(1) |
| .count() | O(log N) | O(1) |
| .erase() | O(log N) | O(N) |
| 常數 | 偏大 | 比偏大還要更大 |
multiset
- 那我為何不能用 map?
我哪有差,你開心就好
- 語法基本上與 set 相同,宣告換成 multiset 就好
e.g.
multiset <int> exist;- 會 保留相同元素,在 count() 時回傳 set 中該元素的數量
e.g.
multiset <int> exist;
exist.insert(5);
exist.insert(5);
exist.insert(5);
cout << exist.count(5) << '\n'; // 3
我只記得最近打比賽遇到一堆 set
如果真的解不出來,Youtube 上會有講解
然後你就會發現這題爆簡單
你要用圖論的做法我也沒意見啦
就會跟姜睿喆一樣
IV 關聯性容器 map
拜託不要對它成癮,否則有點毒瘤
- 記得先 #include <map>
你知道嗎
- 建電幹部有一坨暈船仔,超級多,多到很恐怖


- 其中,副社長陳亮延,aka 先帝的暈船對象超級酷
- 每天廚、一直廚,滿腦子都只有它 ==
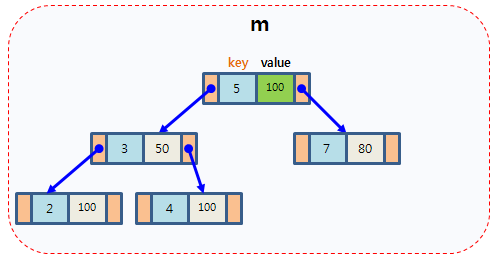
What is map?
- 聽過 python 的 dictionary 嗎,幾乎一模一樣
- 可以想像成 array 的語法,但 index 不再侷限於數字
- 一個 key 對應一個 value,key 具有 唯一性
- 本身是一棵 紅黑樹,故儲存其中的資料會 自動排序
insert():O(log N)
get value:O(log N)
clear():O(N)
宣告 map
map <key 型態, value 型態> 命名
map <int, int> dic; // int 對到 int
map <char, int> m; // char 對到 int
map <string, int> animal; // string 對到 inte.g.
加入一個新的 key
I.
insert() 一個 pair 進去
first 是 key,而 value 是 value
e.g.
map <string, int> dic;
dic.insert({"test", 73});II.
直接像 array 一樣賦值
e.g.
map <string, int> dic;
dic["test"] = 73;warning:
該加的""、' '
還是要加
O(log N)
取值
- 痾就,取值,你在 array 中怎麼做,在 map 中就怎麼做
e.g.
map <string, string> autumn_trip;
autumn_trip["Aaw"] = "執秘準備退休囉 :partying_face:";
autumn_trip["立葉"] = "你到底在興奮什麼啦\n";
autumn_trip["田鼠"] = "有人今天特別躁誒,她又沒有來\n";
autumn_trip["Yen"] = "他的娛樂就是轉圈圈,一直轉圈圈不願離開\n";
autumn_trip["姜姜"] = "整天沒有手機,超級可撥\n";
autumn_trip["先帝"] = "我認識的陳亮延不可能那麼帥,見鬼了\n";
autumn_trip["Brine"] = "怎麼有人在打北市賽啊\n";
autumn_trip["乘一"] = "我記得我暑訓就跟你說過不要妄想這招,這我可以臭一年\n";
autumn_trip["阿蘇"] = "怎麼道具都是這個人在搬啊,雖然搬得很甘願,汪汪\n";
autumn_trip["溫室蔡"] = "割,你的肉要焦掉了\n";
autumn_trip["大毛"] = "這是不是我這輩子首次聽到你唱歌\n";
autumn_trip["Greg"] = "這個學長沒有交錢,那個人也還沒付錢\n";
autumn_trip["鬆餅"] = "有人 RPG 玩到開始自彈自唱是正常的嗎\n";cout << autumn_trip["姜姜"];
// 整天沒有手機,超級可撥O(log N)
.clear()
- 我連說明文字都懶得打了
map <int, int> dic;
dic[71] = 1e9 + 17;
cout << dic[71] << '\n'; //1000000017
dic.clear();
cout << dic[71] << '\n'; //沒看過的 key 預設是 0
e.g.
O(N)
vector v.s. map
- 聽起來很蠢,但如果今天 MAXN = 1e15?
vector 根本不能開這麼大,沒 TLE 也 MLE
- 總共只有 10 筆資料,但 MAXN = 1e9?
vector:要開 1e9 格,但找資料只需要常數時間
map:只需開 10 * log 10 格,worst case 要 log 10 = 3.32 * 常數
vector v.s. map
結論:
map 因為本身是紅黑樹,需要 O(log N),與 O(1) vector 相比較劣勢
但在 資料離散嚴重(極值超級大) 的情況下,map 會成為解方
unordered_map
- 語法基本上與 map 相同,宣告換成 unordered_map 就好
e.g.
#define unordered_set und_map
und_map <int, int> dic;- 本身是 hash table,仍然具有 唯一性,但 不再自動排序
| map | unordered_map | |
|---|---|---|
| 加入新 key | O(log N) | O(1) |
| 取值 | O(log N) | O(1) |
| 常數 | 偏大 | 比偏大還要更大 |
陳亮延歷史上最興奮的一刻
MAXN 開到 1e18
你確定要用不優化的遞迴嗎
一三的共同回憶
如果 OJ 有救回來開張,記得去 AC 一下啦 QAQ
偷自 yeedrag 的簡報
V 鍊結串列 linked_list
你們遇到的第一個手刻 STL
What is linked_list?
- 用 struct 跟 pointer 實作出的一種資料結構
- 利用指標一個接著一個,所以每次操作都要從 頭或尾 開始
- 只能用手刻,C++ 內建的難用到有跟沒有一樣
- 節點間的自由度很高,可以從任一點插入或斷開
root
[1]
[2]
[3]
end
插播:struct 與 pointer 的結合
struct animal{
string name;
};
struct zoo{
animal *area_1 = nullptr;
animal *area_2 = nullptr;
animal *area_3 = nullptr;
};- 事實上,指標可以指向任何東西,包含 其他struct
e.g.
-對,所以你要拿指標來接
再插播:new 與 delete
new (變數類型):
向某特殊的記憶體區塊申請一個空間來存此目標,
回傳一個位址
delete (指標名稱):
把這塊記憶體還回去,delete 後再 訪問它會爛掉
struct animal{
string name;
};
struct zoo{
animal *area_1 = nullptr;
animal *area_2 = nullptr;
animal *area_3 = nullptr;
};
int main (){
zoo Z;
animal *cat = new animal; // 從 Heap 拿記憶體給 cat
Z.area_1 = cat;
delete cat; //把記憶體還給 Heap
}又插播:->
- 喔,剛剛那坨如果聽不懂就算了,不是今天重點
- 之後專案建置會用更清楚完整的方式重講
從一般 struct 中汲取成員:.成員變數名
struct animal{
string name;
};
struct zoo{
animal *area_1 = nullptr;
animal *area_2 = nullptr;
animal *area_3 = nullptr;
};
int main (){
zoo Z;
animal *cat = new animal; // 從 Heap 拿記憶體給 cat
Z.area_1->name = "cats";
cout << Z.area_1->name << '\n'; // cats
}從指標 struct 中汲取成員:->成員變數名
下面的做法都只是給你們個概念 基本上每題的 linked_list 都長得不一樣 你們自己視題目應變
- val:這個節點自己的值
struct node{
long long value;
node *next = nullptr;
};製作節點
常見元素:
- next:一個指標,指向下個節點
製作 linked_list 本身
- isempty:一個 bool,紀錄它是不是空的
- length:紀錄 linked_list 的存在節點數量
- end:紀錄 list 最後面那點,以增加 push_back 的速度
struct linked_list{
unsigned int length = 0;
node *root = nullptr;
node *end = nullptr;
bool isempty = true;
};常見元素:
- root:整個 list 最前面那一點
print_list()
預計功能:從 root 開始到 end,依序印出每個值
把整個 list 印出來
root = 9
2
5
7
3
end = 4
- 只要 next != nullptr , 就輸出自己,並不斷往後
9
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;把整個 list 印出來
root = 9
2
5
7
3
end = 4
9
2
- 只要 next != nullptr , 就輸出自己,並不斷往後
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;把整個 list 印出來
root = 9
2
5
7
3
end = 4
9
2
5
- 只要 next != nullptr , 就輸出自己,並不斷往後
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;把整個 list 印出來
root = 9
2
5
7
3
end = 4
9
2
5
7
node *tmp = root- 只要 next != nullptr , 就輸出自己,並不斷往後
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;把整個 list 印出來
root = 9
2
5
7
3
end = 4
9
2
5
7
3
- 只要 next != nullptr , 就輸出自己,並不斷往後
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;把整個 list 印出來
root = 9
2
5
7
3
end = 4
9
2
5
7
3
4
- 只要 next != nullptr , 就輸出自己,並不斷往後
- 創造一個 node *tmp,從 root 開始往後推
node *tmp = root;push_back(int tar)
預計功能:把 tar 加到 linked_list 的尾端
push_back 的實作
- new 出一個 node*,把 end->next 設為它
node *tmp = new node;
end->next = tmp;root = 9
2
5
7
end = 4
17
push_back 的實作
- new 出一個 node*,把 end->next 設為它
node *tmp = new node;
end->next = tmp;root = 9
2
5
7
end = 4
17
push_back 的實作
- new 出一個 node*,把 end->next 設為它
node *tmp = new node;
end->next = tmp;root = 9
2
5
7
4
end = 17
- 現在這個點變成 end 了
node *tmp = new node;
end->next = tmp;
end = tmp;push_back 的實作
- 特例:如果今天 linked_list 中什麼都沒有呢?
-root 跟 end 都是 nullptr,對它取 ->next 會爛掉
void push_back(int tar){
node *tmp = new node;
tmp->value = tar;
length++;
if (isempty){
root = tmp;
end = tmp;
isempty = false;
return;
}
end->next = tmp;
end = tmp;
}*find_node(int tar)
預計功能:找到第一個值 = tar 的點
並且return 它 (node*)
find_node 的實作
- 吃進一個數字,回傳一個 node*
node *find_node (int tar){
}root = 7
12
9
5
9
- 跟 print_list() 有點像,從 root 開始一路尋找目標
node *tmp = root;
while (tmp->next != nullptr){
if (tmp->value == tar) return tmp;
tmp = tmp->next;
}
return tmp;tar = 7
find_node 的實作
- 吃進一個數字,回傳一個 node*
node *find_node (int tar){
}root = 7
12
9
5
9
- 跟 print_list() 有點像,從 root 開始一路尋找目標
node *tmp = root;
while (tmp->next != nullptr){
if (tmp->value == tar) return tmp;
tmp = tmp->next;
}
return tmp;tar = 7
find_node 的實作
- 吃進一個數字,回傳一個 node*
node *find_node (int tar){
}root = 7
12
9
5
9
- 跟 print_list() 有點像,從 root 開始一路尋找目標
node *tmp = root;
while (tmp->next != nullptr){
if (tmp->value == tar) return tmp;
tmp = tmp->next;
}
return tmp;tar = 7
return!
insert (int loc, int tar)
預計功能:把 tar 插到數字 loc 後
- 創造一個 node *last,接著用 find_node 找出插入點
node *last = find_node(loc);insert 的實作
- new 出一個 node *tmp,設定其值
node *tmp = new node;
tmp->value = tar;last
tmp
last->next
- 把 tmp 連結到 last->next 上
tmp->next = last->next;insert 的實作
last
tmp
last->next
- 把 tmp 連結到 last->next 上
tmp->next = last->next;insert 的實作
last
tmp
last->next
- 把 last 連結到 tmp 上
last->next = tmp;- 把 tmp 連結到 last->next 上
tmp->next = last->next;insert 的實作
last
tmp
last->next
- 把 last 連結到 tmp 上
last->next = tmp;insert 的實作
- 特例:如果插入點剛好是 end?
-end 要 更新 成新增的那點
- 特例:如果 linked_list 是空的?
-不存在 root,所以 find_node 那邊會 RE
void insert (int loc, int tar){
node *last = find_node(loc);
node *tmp = new node;
tmp->value = tar;
if (isempty){
root = tmp;
end = tmp;
isempty = false;
}
if (last->value == end->value) end = last;
tmp->next = last->next;
last->next = tmp;
length++;
}其他超級常見的功能:
- push_front (int tar):把 tar 放到 link_list 最前端
-注意要 更新 root
- erase (int tar):把 tar 踢出 linked_list
-更改一下指標,使其 無人指向 即可。
心有餘力可以順便把它 delete 掉
- find_node (int loc):回傳 linked_list [loc]
-那就往後推 loc-1 次,不過要注意不能超出 end
- 具備 *next、*last 的 linked_list
-雙向連結,有時候這會讓你實作簡單很多
隨便亂刻的模板,我猜很難用 可能有 bug
要視情況做更改,建議刻出屬於自己的
struct node{
long long value;
node *next = nullptr;
};
struct linked_list{
unsigned int length = 0;
node *root = nullptr;
node *end = nullptr;
bool isempty = true;
bool empty(){
return isempty;
}
unsigned int size(){
return length;
}
void push_front(long long num){
node *tmp = new node;
tmp->value = num;
if (!isempty) tmp->next = root; //root 被往後推一格
if (length == 0) end = tmp; //什麼都沒有,這點是 root 加 end
else if (length == 1) end = root; //root 要變成 end 了
root = tmp;
length++;
isempty = false;
}
void push_back(int tar){
node *tmp = new node;
tmp->value = tar;
length++;
if (isempty){
root = tmp;
end = tmp;
isempty = false;
return;
}
end->next = tmp;
end = tmp;
}
void print_list(){
if (!isempty){
node *now = new node;
now = root;
cout << now->value << ' ';
while (now->next != nullptr){
now = now->next;
cout << now->value << ' ';
}
delete now;
}
}
node *find_node(int loc){
if (loc == 0) return root;
if (loc == size()-1) return end;
node *tmp = root;
for (int i = 0; i < loc && i < size(); i++) tmp = tmp->next;
return tmp;
}
void insert(int loc, long long tar){
node *now = new node;
now->value = tar;
length++;
if (empty()){
root = now;
end = now;
isempty = false;
}else if (loc == 0){
now->next = root;
root = now;
}else if (loc == size()-1){
end->next = now;
end = now;
}else{
now->next = find_node(loc)->next;
find_node(loc)->next = now;
}
}
void erase_by_location(int loc){
if (loc == 0) root = root->next;
else R_erase_by_location(find_node(loc-1), loc);
}
void R_erase_by_location(node *last, int loc){
if (loc == size()-1){
end = last;
last->next = nullptr;
}else{
last->next = last->next->next;
}
length--;
if (length == 0) isempty = true;
}
};通常 linked list 只要根據題目需求寫出必要的函式就好,不用每次刻好刻滿
通常吃 RE 的機率會比吃 WA 高很多
可以搭配前面的 set 與 map 服用
你開心的話,也能用好幾個 queue 寫
@Qt 這題絕對不是 vector
好煩,好毒,非常破題目