Jeff Taylor
Principal Data Consultant
Database Consulting, LLC
SQL Server
Partitioning

Jeff Taylor
Principal Data Consultant
Database Consulting, LLC





Super Hero Suit
jaxdata.org
Every 3rd Wednesday 6-8pm
Except for May, November and December

Jeff Taylor
Principal Data Consultant
Database Consulting, LLC
SQL Server
Partitioning
Partitioning
What is it?
- A method of dividing a large database table or index into smaller, more manageable parts called partitions.
- Each partition contains a subset of rows based on a partitioning column (e.g., date, region).
- All partitions together still represent a single logical table or index.
- Data is divided horizontally by rows, not columns.
- Managed using partition functions (define boundaries) and partition schemes (map to storage).
Partitioning
Why Use It?
-
Improved performance: Queries can target specific partitions, reducing seek and scan time.
-
Faster maintenance: Operations like index rebuilds or data archiving can be done on individual partitions.
-
Efficient data management: Easily move, compress, or delete subsets of data.
-
Better scalability: Supports very large datasets (up to 15,000 partitions). - NOT A GOAL!
- Over 1,000 partitions may have performance implications (max earlier than SQL 2012).
-
Reduced locking issues: Lock escalation can occur at the partition level, not the whole table.
- Optimized storage: Place older or less-used data on cheaper storage tiers, which can be multiple or hot or cold.
Partitioning
Where can I use it?
- 2016 and older versions - Only works in Enterprise Edition
- 2016 SP1 and newer - Works in both Standard & Enterprise Editions
- Works in all service tiers of Azure SQL Database and Azure SQL Managed Instance
- Table partitioning is also available in dedicated SQL pools in Azure Synapse Analytics, with some syntax differences.
Partitioning
Check Your Data
USE [StackOverflow]
GO
SELECT
YEAR(v.CreationDate) AS YearValue,
COUNT(*) AS Records
FROM
dbo.Votes AS v
GROUP BY
YEAR(v.CreationDate)
ORDER BY
1;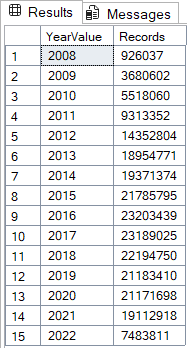
Partitioning
Filegroups
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_Empty]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2008]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2009]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2010]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2011]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2012]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2013]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2014]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2015]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2016]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2017]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2018]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2019]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2020]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2021]
GO
ALTER DATABASE [StackOverflow] ADD FILEGROUP [PG_Yearly_2022]
GOPartitioning
Files for Filegroups
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_Empty',
FILENAME = N'C:\Files\Databases\2025\StackOverflow_PG_Yearly_Empty.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_Empty]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2008',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2008.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2008]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2009',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2009.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2009]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2010',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2010.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2010]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2011',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2011.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2011]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2012',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2012.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2012]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2013',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2013.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2013]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2014',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2014.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2014]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2015',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2015.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2015]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2016',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2016.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2016]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2017',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2017.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2017]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2018',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2018.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2018]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2019',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2019.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2019]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2020',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2020.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2020]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2021',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2021.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2021]
GO
ALTER DATABASE [StackOverflow] ADD FILE (
NAME = N'StackOverflow_PG_Yearly_2022',
FILENAME = N'C:\Files\Databases\StackOverflow_PG_Yearly_2022.ndf' ,
SIZE = 1MB, FILEGROWTH = 128MB)
TO FILEGROUP [PG_Yearly_2022]
GOPartitioning
Partition Function
CREATE PARTITION FUNCTION [PF_Yearly] (DATE)
AS RANGE RIGHT FOR VALUES (
'2008-01-01',
'2009-01-01',
'2010-01-01',
'2011-01-01',
'2012-01-01',
'2013-01-01',
'2014-01-01',
'2015-01-01',
'2016-01-01',
'2017-01-01',
'2018-01-01',
'2019-01-01',
'2020-01-01',
'2021-01-01',
'2022-01-01');Partitioning
Partition Scheme
CREATE PARTITION SCHEME [PS_Yearly]
AS PARTITION [PF_Yearly] TO (
[PG_Yearly_Empty],
[PG_Yearly_2008],
[PG_Yearly_2009],
[PG_Yearly_2010],
[PG_Yearly_2011],
[PG_Yearly_2012],
[PG_Yearly_2013],
[PG_Yearly_2014],
[PG_Yearly_2015],
[PG_Yearly_2016],
[PG_Yearly_2017],
[PG_Yearly_2018],
[PG_Yearly_2019],
[PG_Yearly_2020],
[PG_Yearly_2021],
[PG_Yearly_2022])
GOPartitioning
Partitioned Table
CREATE TABLE [dbo].[Votes_Partitioned](
[Id] [INT] NOT NULL,
[PostId] [INT] NOT NULL,
[UserId] [INT] NULL,
[BountyAmount] [INT] NULL,
[VoteTypeId] [INT] NOT NULL,
[CreationDate] DATE NOT NULL,
CONSTRAINT [PK_Votes_Partitioned] PRIMARY KEY CLUSTERED
(
[Id] ASC,
[CreationDate] ASC
) WITH (DATA_COMPRESSION = PAGE)
ON [PS_Yearly]([CreationDate])) ON [PS_Yearly]([CreationDate])
GOPartitioning
Insert Example
INSERT INTO
dbo.Votes_Partitioned WITH (TABLOCK)
(Id, PostId, UserId, BountyAmount, VoteTypeId, CreationDate)
SELECT
Id,
PostId,
UserId,
BountyAmount,
VoteTypeId,
CreationDate
FROM
dbo.Votes;
--9 minutes 11 seconds --231,441,846Partitioning
Non-Clustered Index
--19 seconds
CREATE NONCLUSTERED INDEX [IX_Votes_Partitioned_UserId_BountyAmount_VoteTypeId_CreationDate]
ON [dbo].[Votes_Partitioned]
(
UserId,
BountyAmount,
VoteTypeId,
CreationDate
)
WHERE BountyAmount IS NOT NULL
WITH (SORT_IN_TEMPDB = ON, DATA_COMPRESSION = PAGE) ON [PS_Yearly]([CreationDate])
GOPartitioning
Rows Per Filegroup
SELECT
p.partition_number,
ps.name AS PartitionScheme,
pf.name AS PartitionFunction,
prv.value AS BoundaryValue,
SUM(p.rows) AS RowCounts
FROM
sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id AND i.index_id IN (0, 1) -- Heap or clustered index
INNER JOIN sys.partitions p
ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN sys.partition_schemes ps
ON i.data_space_id = ps.data_space_id
INNER JOIN sys.partition_functions pf
ON ps.function_id = pf.function_id
LEFT OUTER JOIN sys.partition_range_values prv
ON pf.function_id = prv.function_id AND p.partition_number = prv.boundary_id + 1
WHERE
t.name = 'Votes_Partitioned' AND SCHEMA_NAME(t.schema_id) = 'dbo'
AND pf.name = 'PF_Yearly'
GROUP BY
p.partition_number, ps.name, pf.name, prv.value
ORDER BY
p.partition_number;Partitioning
Rows Per Filegroup
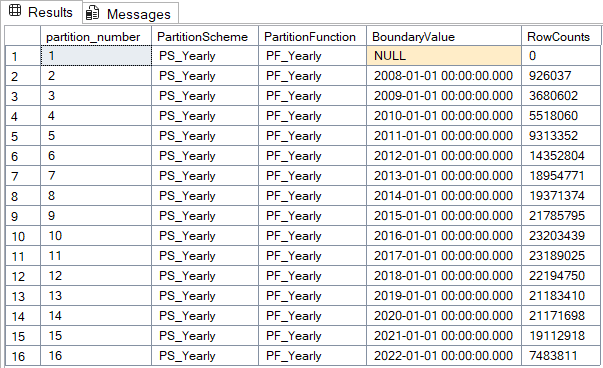
Partitioning
Execution Plans

Partitioning
Execution Plans
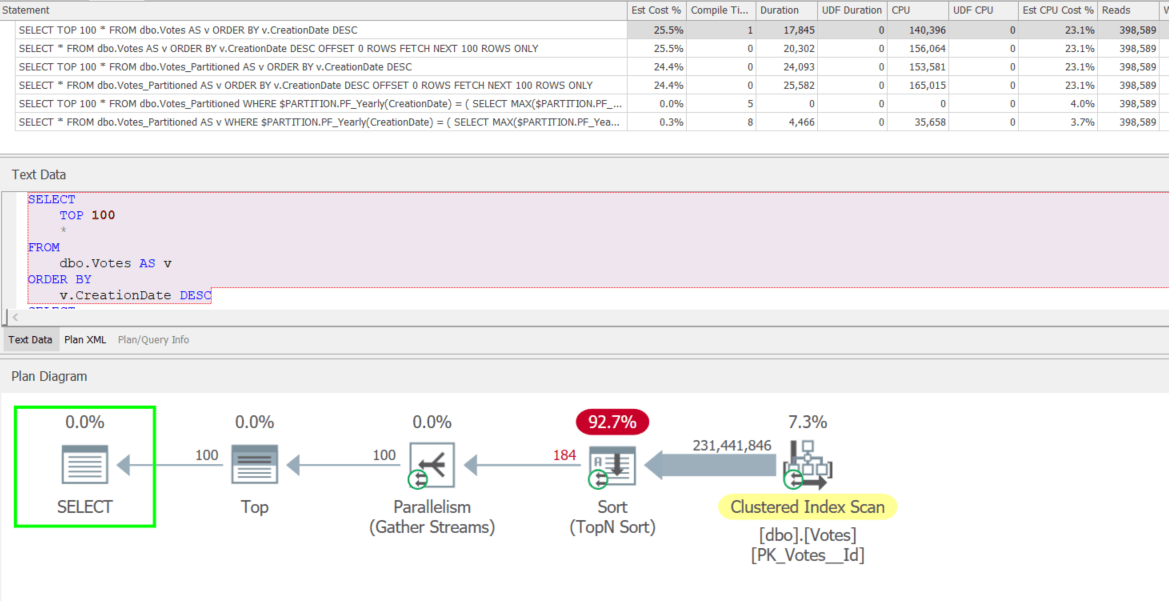
Partitioning
Execution Plans
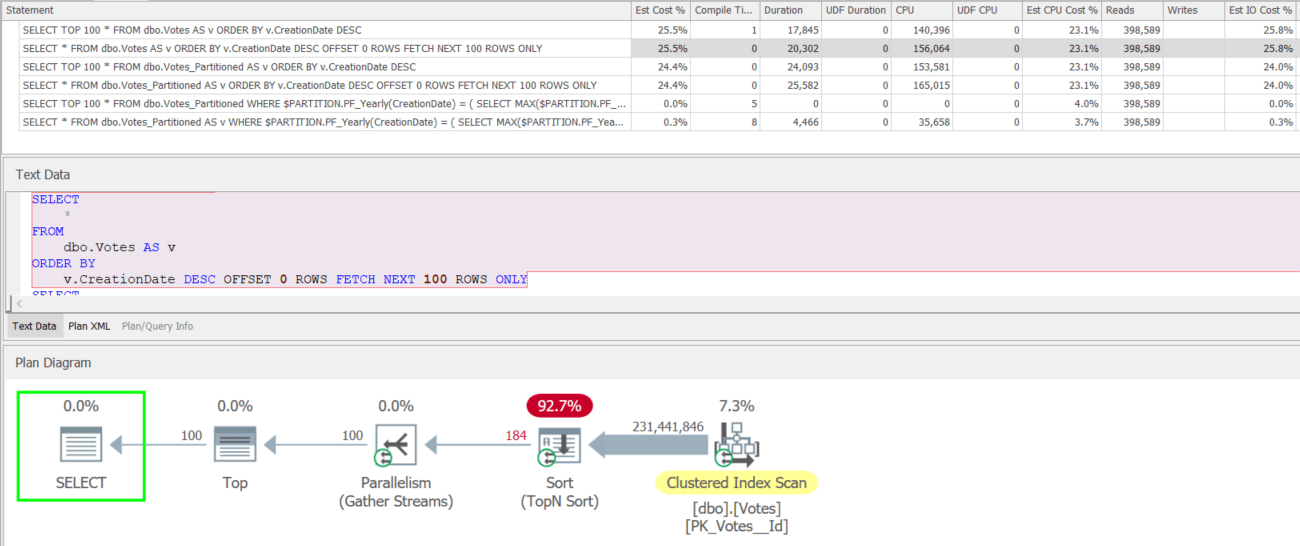
Partitioning
Execution Plans
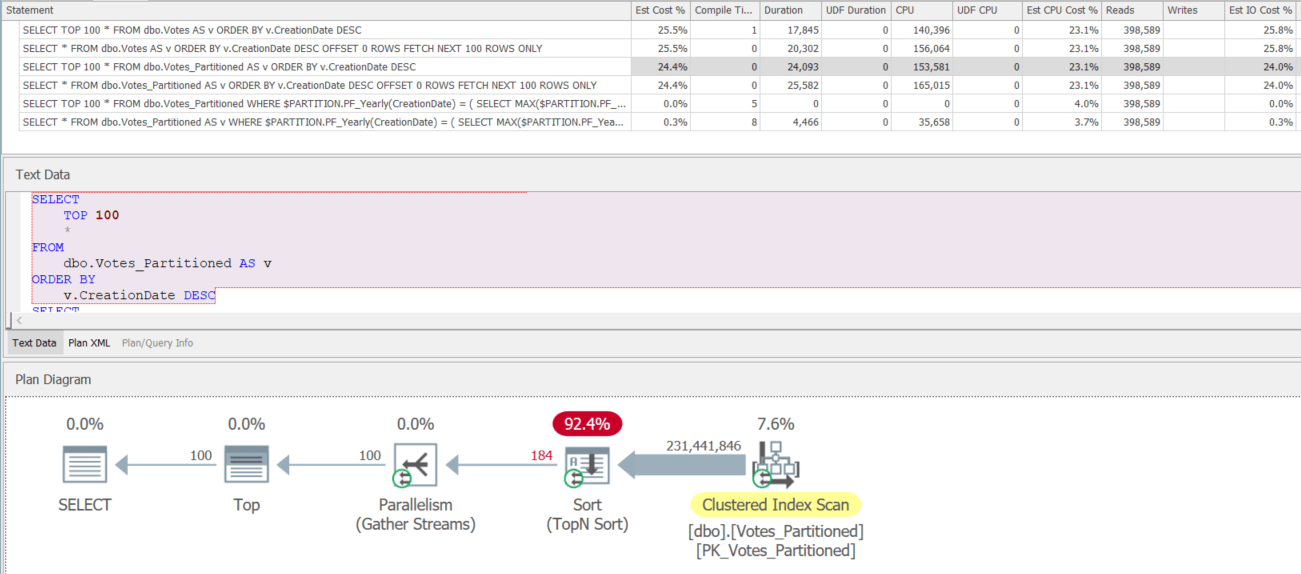
Partitioning
Execution Plans
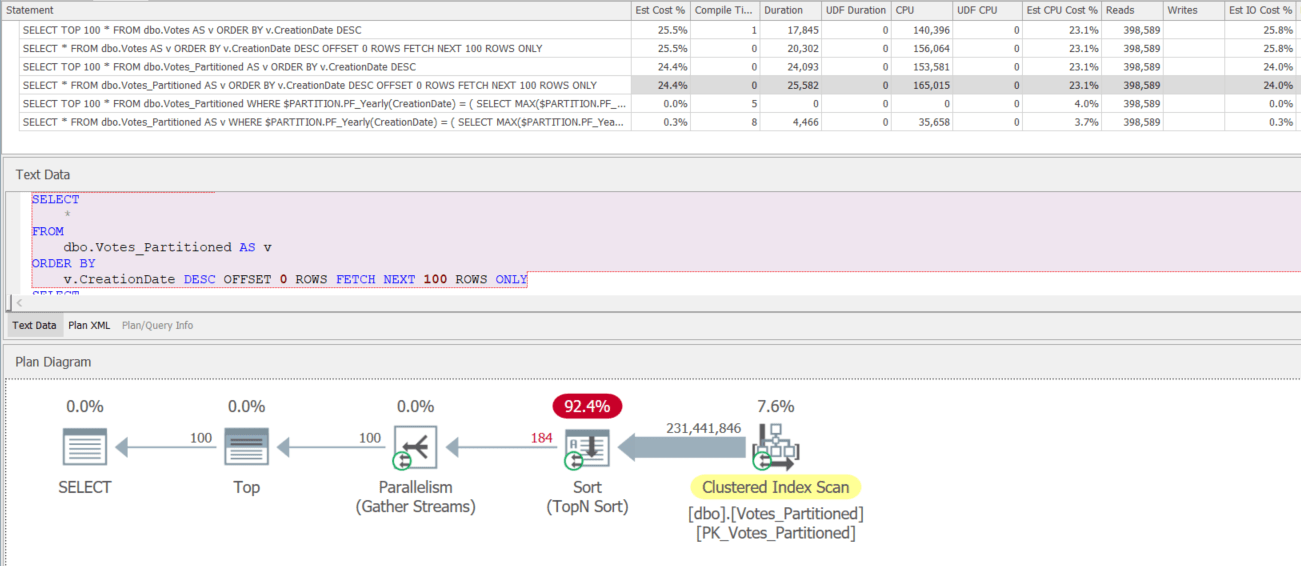
Partitioning
Execution Plans

Partitioning
Execution Plans
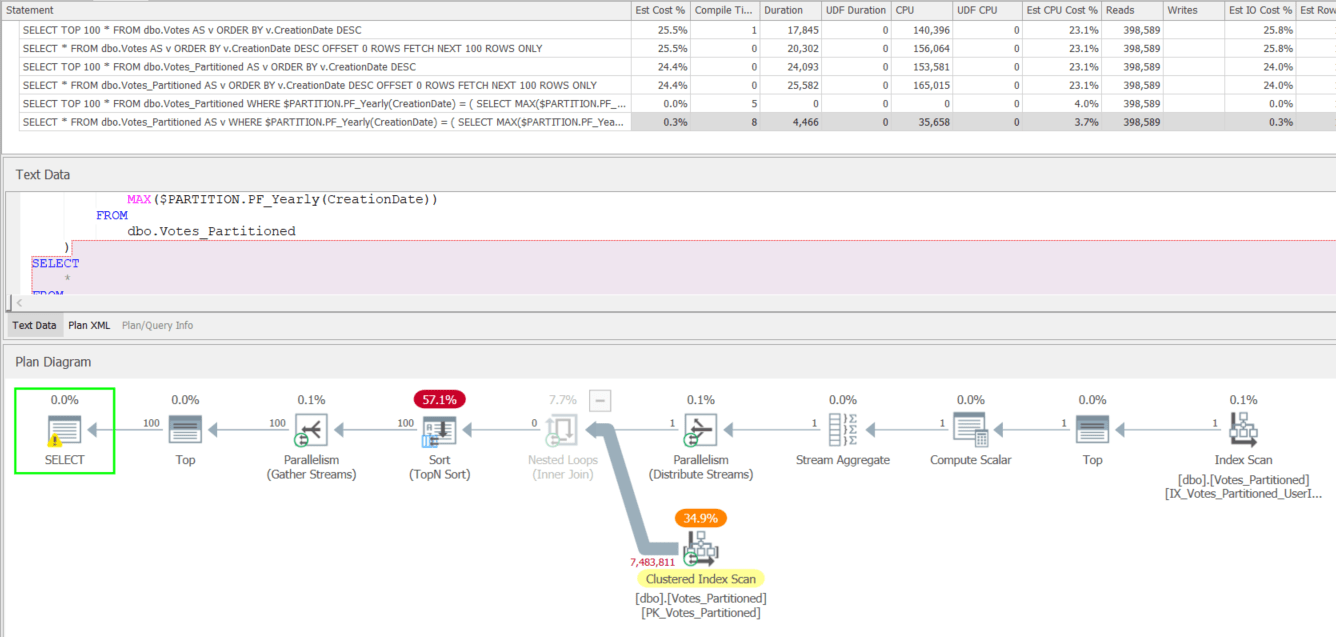
Partitioning
$PARTITION function
SELECT
TOP 100
COUNT(v.PostId) AS Posts,
COUNT(v.UserId) AS Users,
SUM(v.BountyAmount) AS BountyAmount,
v.VoteTypeId,
YEAR(v.CreationDate) AS YearValue
FROM
dbo.Votes_Partitioned AS v
WHERE
v.BountyAmount IS NOT NULL
AND $PARTITION.PF_Yearly(CreationDate) =
(
SELECT
MAX($PARTITION.PF_Yearly(CreationDate))
FROM
dbo.Votes_Partitioned
)
GROUP BY
v.VoteTypeId,
YEAR(v.CreationDate)
ORDER BY
5 DESC;Partitioning
$PARTITION function
SELECT
COUNT(v.PostId) AS Posts,
COUNT(v.UserId) AS Users,
SUM(v.BountyAmount) AS BountyAmount,
v.VoteTypeId,
YEAR(v.CreationDate) AS YearValue
FROM
dbo.Votes_Partitioned AS v
WHERE
v.BountyAmount IS NOT NULL
AND $PARTITION.PF_Yearly(CreationDate) =
(
SELECT
MAX($PARTITION.PF_Yearly(CreationDate))
FROM
dbo.Votes_Partitioned
)
GROUP BY
v.VoteTypeId,
YEAR(v.CreationDate)
ORDER BY
5 DESC
OFFSET 0 ROWS FETCH NEXT 100 ROWS ONLY;Partitioning
Backups - No Compression
--38 minutes 39 seconds
BACKUP DATABASE [StackOverflow]
TO
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.bak'
WITH
NOFORMAT,
NOINIT,
NAME = N'StackOverflow-Full Database Backup',
SKIP,
NOREWIND,
NOUNLOAD,
STATS = 10,
CHECKSUM;
GO
DECLARE @backupSetId AS INT;
SELECT
@backupSetId = position
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
AND backup_set_id =
(
SELECT
MAX(backup_set_id)
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
);
IF @backupSetId IS NULL
BEGIN
RAISERROR(N'Verify failed. Backup information for database ''StackOverflow'' not found.', 16, 1);
END;
RESTORE VERIFYONLY
FROM
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.bak'
WITH
FILE = @backupSetId,
NOUNLOAD,
NOREWIND;
GO
Partitioning
Backups - No Compression
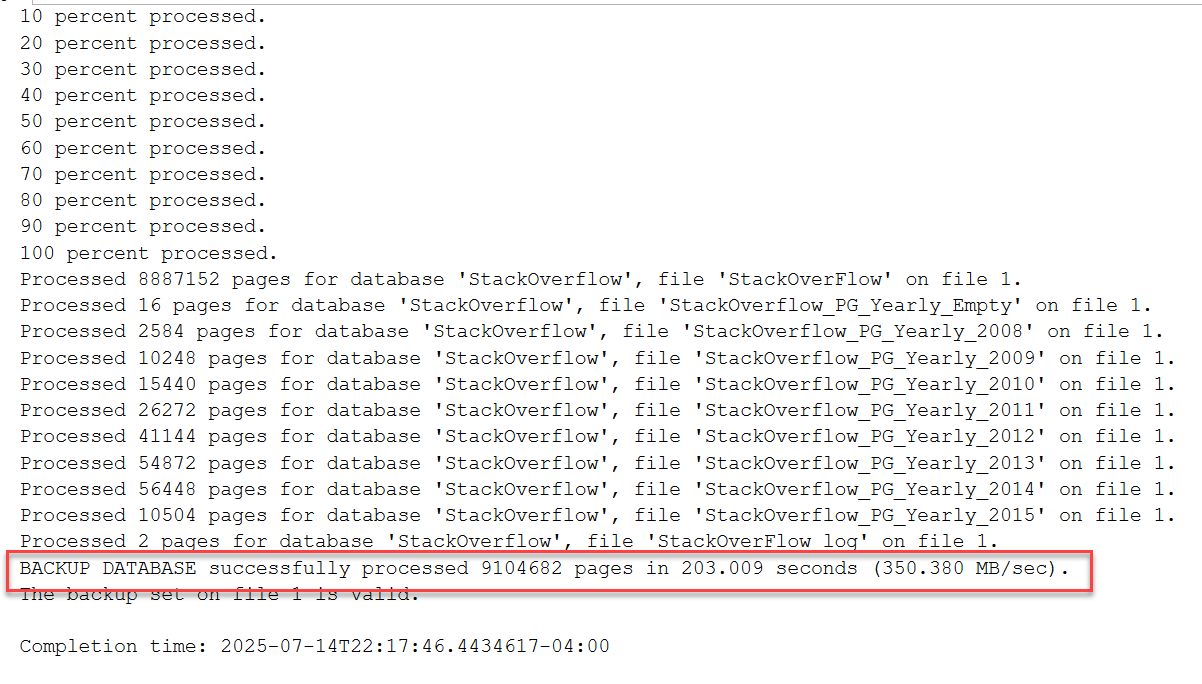
Partitioning
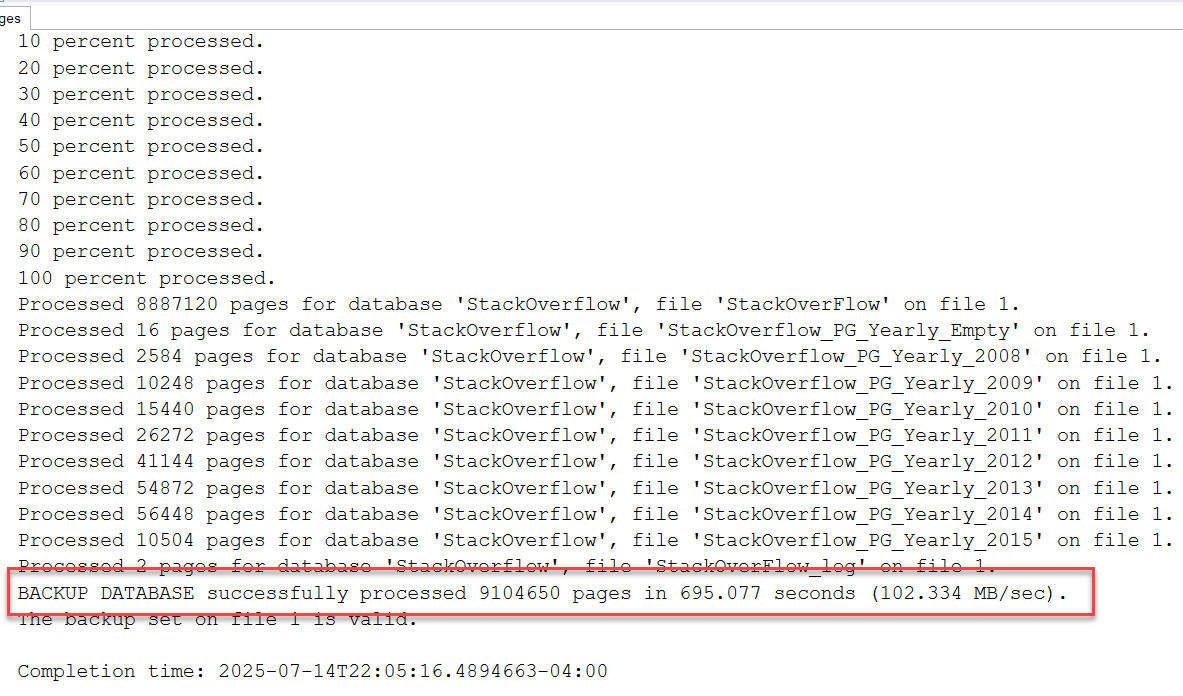
Backups - With Compression
--37 minute 20 seconds
BACKUP DATABASE [StackOverflow]
TO
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.Compression.bak'
WITH
NOFORMAT,
NOINIT,
NAME = N'StackOverflow-Full Database Backup',
SKIP,
NOREWIND,
NOUNLOAD,
COMPRESSION,
STATS = 10,
CHECKSUM;
GO
DECLARE @backupSetId AS INT;
SELECT
@backupSetId = position
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
AND backup_set_id =
(
SELECT
MAX(backup_set_id)
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
);
IF @backupSetId IS NULL
BEGIN
RAISERROR(N'Verify failed. Backup information for database ''StackOverflow'' not found.', 16, 1);
END;
RESTORE VERIFYONLY
FROM
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.Compression.bak'
WITH
FILE = @backupSetId,
NOUNLOAD,
NOREWIND;
GO
Partitioning
Backups - With Compression
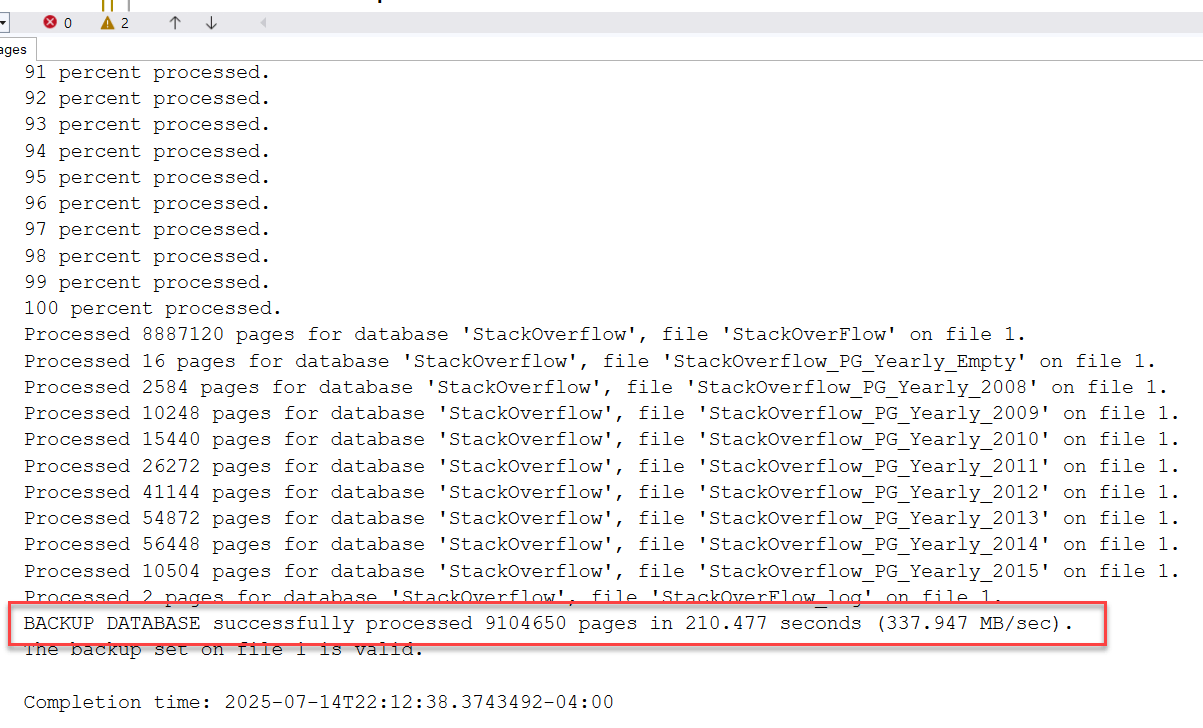
Partitioning
Backups - With ZSTD Compression
--1 hour 6 minutes 19 seconds
--It went to 149GB and then down to 105GB
BACKUP DATABASE [StackOverflow]
TO
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.ZSTD.bak'
WITH
NOFORMAT,
NOINIT,
NAME = N'StackOverflow-Full Database Backup',
SKIP,
NOREWIND,
NOUNLOAD,
COMPRESSION (ALGORITHM = ZSTD, LEVEL = HIGH),
STATS = 10,
CHECKSUM;
GO
DECLARE @backupSetId AS INT;
SELECT
@backupSetId = position
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
AND backup_set_id =
(
SELECT
MAX(backup_set_id)
FROM
msdb..backupset
WHERE
database_name = N'StackOverflow'
);
IF @backupSetId IS NULL
BEGIN
RAISERROR(N'Verify failed. Backup information for database ''StackOverflow'' not found.', 16, 1);
END;
RESTORE VERIFYONLY
FROM
DISK = N'C:\Files\DatabaseBackups\2025\StackOverflow2025.ZSTD.bak'
WITH
FILE = @backupSetId,
NOUNLOAD,
NOREWIND;
GOPartitioning
Backups - With ZSTD Compression
Partitioning
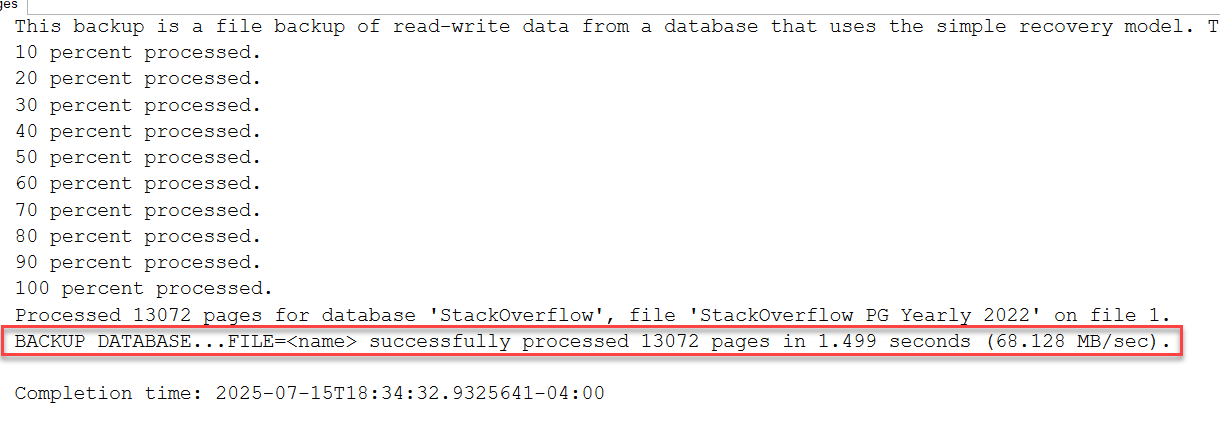
Backup Filegroup
DECLARE @FileGroupName NVARCHAR(128), @SQL NVARCHAR(MAX);
-- Get the latest filegroup name
SELECT TOP 1 @FileGroupName = name FROM sys.filegroups ORDER BY data_space_id DESC;
--Create Backup command
SET @SQL = '
BACKUP DATABASE StackOverflow
FILEGROUP = ''' + @FileGroupName + '''
TO DISK = ''C:\Files\DatabaseBackups\2025\StackOverflow_' + @FileGroupName + '.bak''
WITH NOFORMAT,
NOINIT,
NAME = N''StackOverflow-' + @FileGroupName + ' Database Backup'',
SKIP,
NOREWIND,
NOUNLOAD,
COMPRESSION (ALGORITHM = ZSTD, LEVEL = HIGH),
STATS = 10,
CHECKSUM;';
-- Execute the backup
EXEC sp_executesql @SQL;Partitioning
Backup Filegroup
Partitioning
Statistics
SELECT
name,
is_incremental,
object_id
FROM
sys.stats
WHERE
object_id = OBJECT_ID('dbo.Votes_Partitioned');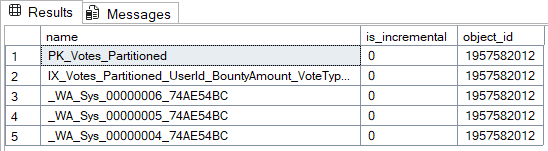
Partitioning
Statistics
CREATE STATISTICS Votes_Partitioned_LatestPartition
ON dbo.Votes_Partitioned
(
CreationDate
)
WITH
FULLSCAN,
INCREMENTAL = ON;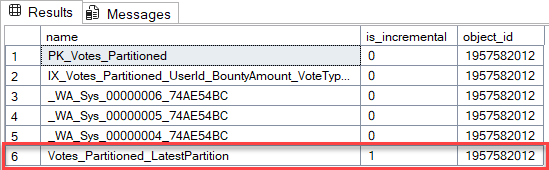
Partitioning
Statistics
DECLARE @MaxPartition INT, @SQLQuery NVARCHAR(MAX);
SELECT
@MaxPartition = MAX(p.partition_number)
FROM
sys.partitions p
JOIN
sys.tables t ON p.object_id = t.object_id
WHERE
t.name = 'Votes_Partitioned';
SET @SQLQuery = 'UPDATE STATISTICS dbo.Votes_Partitioned Votes_Partitioned_LatestPartition
WITH
RESAMPLE ON PARTITIONS (' + CAST(@MaxPartition AS VARCHAR(7)) + ');'
EXEC sp_executesql @SQLQueryPartitioning
Indexes
DECLARE @MaxPartition INT;
SELECT
@MaxPartition = MAX(p.partition_number)
FROM
sys.partitions p
JOIN
sys.tables t ON p.object_id = t.object_id
WHERE
t.name = 'Votes_Partitioned';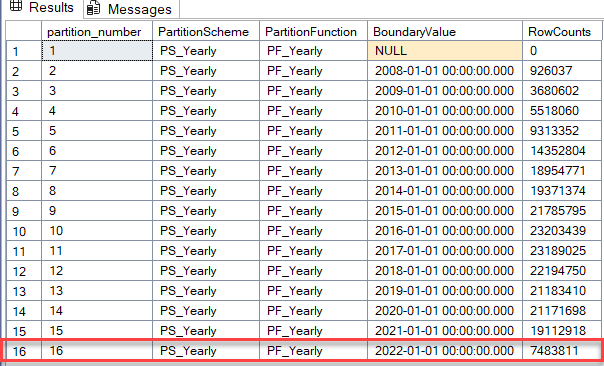
ALTER INDEX ALL ON dbo.Votes_Partitioned REBUILD PARTITION = @MaxPartition; Partitioning
Switching Partitions
SELECT
p.partition_number,
ps.name AS PartitionScheme,
pf.name AS PartitionFunction,
prv.value AS BoundaryValue,
SUM(p.rows) AS RowCounts
FROM
sys.tables t
INNER JOIN sys.indexes i
ON t.object_id = i.object_id AND i.index_id IN (0, 1) -- Heap or clustered index
INNER JOIN sys.partitions p
ON i.object_id = p.object_id AND i.index_id = p.index_id
INNER JOIN sys.partition_schemes ps
ON i.data_space_id = ps.data_space_id
INNER JOIN sys.partition_functions pf
ON ps.function_id = pf.function_id
LEFT OUTER JOIN sys.partition_range_values prv
ON pf.function_id = prv.function_id AND p.partition_number = prv.boundary_id + 1
WHERE
t.name = 'Votes_Partitioned' AND SCHEMA_NAME(t.schema_id) = 'dbo'
AND pf.name = 'PF_Yearly'
GROUP BY
p.partition_number, ps.name, pf.name, prv.value
ORDER BY
p.partition_number;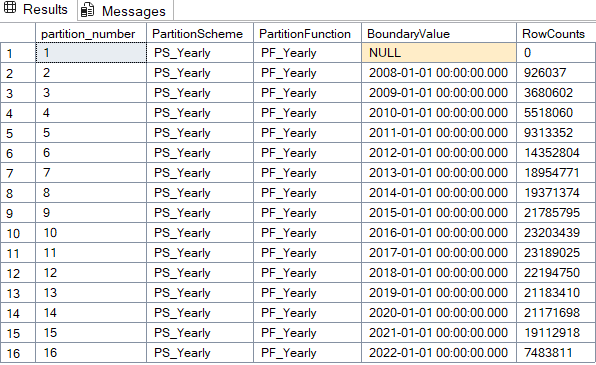
Partitioning
Switching Partitions
CREATE TABLE [dbo].[Votes_History](
[Id] [int] NOT NULL,
[PostId] [int] NOT NULL,
[UserId] [int] NULL,
[BountyAmount] [int] NULL,
[VoteTypeId] [int] NOT NULL,
[CreationDate] [date] NOT NULL,
CONSTRAINT [PK_Votes_History] PRIMARY KEY CLUSTERED
(
[Id] ASC, [CreationDate] ASC
)WITH (DATA_COMPRESSION = PAGE) ON [PG_Yearly_2008]
) ON [PG_Yearly_2008]
GO
CREATE NONCLUSTERED INDEX [IX_Votes_Partitioned_UserId_BountyAmount_VoteTypeId_CreationDate] ON [dbo].[Votes_History]
(
[UserId] ASC, [BountyAmount] ASC, [VoteTypeId] ASC, [CreationDate] ASC
)
WHERE ([BountyAmount] IS NOT NULL)
WITH (DATA_COMPRESSION = PAGE) ON [PG_Yearly_2008]
GO
ALTER TABLE dbo.Votes_History ADD CONSTRAINT CK_Votes_History_Range
CHECK (CreationDate >= '2008-01-01' AND CreationDate < '2009-01-01');Partitioning
Switching Partitions
DECLARE @PartitionNumber INT = 2;
ALTER TABLE dbo.Votes_Partitioned SWITCH PARTITION @PartitionNumber TO dbo.Votes_History;SELECT MIN(CreationDate) AS MinDate, MAX(CreationDate) AS MaxDate FROM dbo.Votes_History;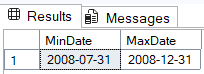
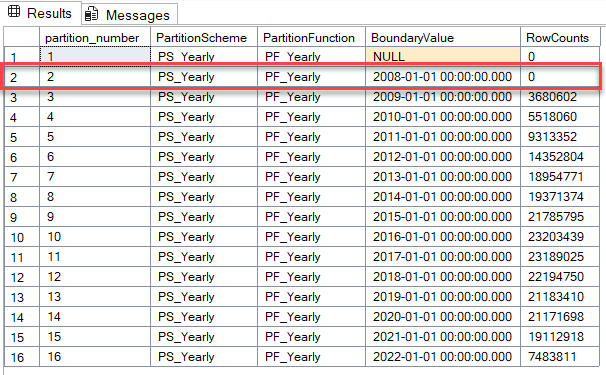

Partitioning
Switching Back
ALTER TABLE dbo.Votes_History SWITCH TO dbo.Votes_Partitioned PARTITION 2;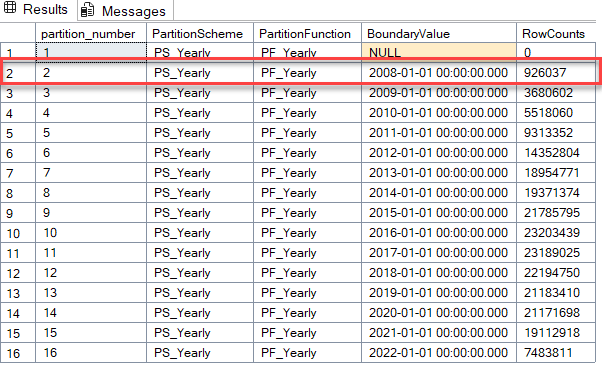
Partitioning
Best Practices
- Stripe each partition across many disks. This is especially relevant when using spinning disks.
- When possible, use a server with enough main memory to fit frequently accessed partitions, or all partitions in memory, to reduce I/O cost.
- If the data you query won't fit in memory, compress the tables and indexes. This will reduce I/O cost.
- Use a server with fast processors and as many processor cores as you can afford, to take advantage of parallel query processing capability.
- Ensure the server has sufficient I/O controller bandwidth.
- Create a clustered index on every large partitioned table to take advantage of B-tree scanning optimizations.
Partitioning
Resources
- Partitioned Tables & Indexes - https://learn.microsoft.com/en-us/sql/relational-databases/partitions/partitioned-tables-and-indexes?view=sql-server-ver17
- Query Processing Architecture - https://learn.microsoft.com/en-us/sql/relational-databases/query-processing-architecture-guide?view=sql-server-ver17#query-processing-enhancements-on-partitioned-tables-and-indexes
- Best Practices - https://learn.microsoft.com/en-us/sql/relational-databases/query-processing-architecture-guide?view=sql-server-ver17#best-practices
- $PARTITION function - https://learn.microsoft.com/en-us/sql/t-sql/functions/partition-transact-sql?view=sql-server-ver17
- Data Load Performance Guide - https://learn.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd425070(v=sql.100)
- Statistics - https://learn.microsoft.com/en-us/sql/t-sql/statements/update-statistics-transact-sql?view=sql-server-ver17
Questions

Thank you!
Jeff Taylor



Thank you for attending my session today.
If you have any additional questions, please don't hesitate to reach out.