Deep Perception
(for manipulation)
Part 1

MIT 6.4210/2
Robotic Manipulation
Fall 2022, Lecture 11

Follow live at https://slides.com/d/4hDt7rQ/live
(or later at https://slides.com/russtedrake/fall22-lec11)
Limitations of using geometry only
- No understanding of what an object is.
- "Double picks"
- Might pick up a heavy object from one corner
- Partial views
- Depth returns don't work for transparent objects
- ...
- some tasks require object recognition! "pick the mustard bottles"

A sample annotated image from the COCO dataset
What object categories/labels are in COCO?
Fine tuning
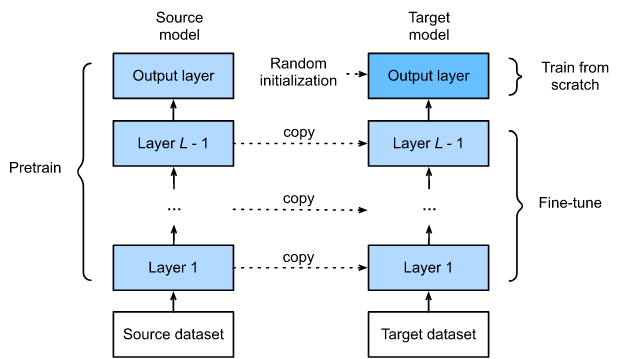
source: https://d2l.ai/chapter_computer-vision/fine-tuning.html

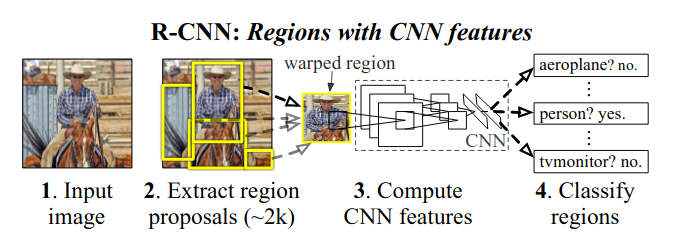
R-CNN (Regions with CNN features)

source: https://towardsdatascience.com/understanding-regions-with-cnn-features-r-cnn-ec69c15f8ea7
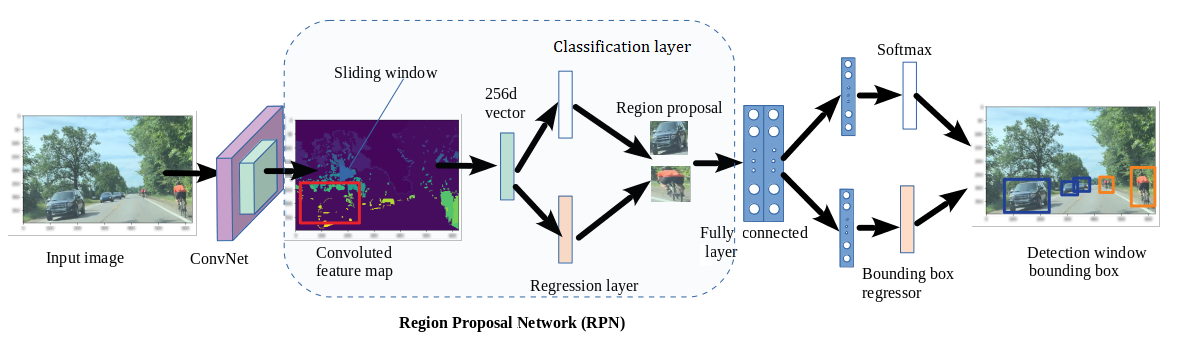
Faster R-CNN adds a "region proposal network"
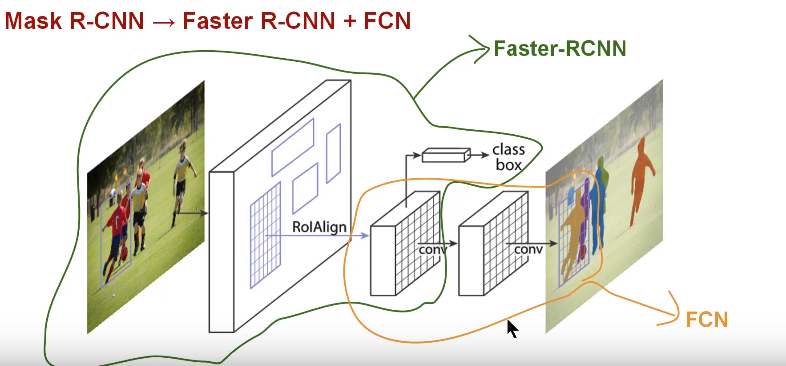
source: https://www.analyticsvidhya.com/blog/2018/07/building-mask-r-cnn-model-detecting-damage-cars-python/
Pick up the mustard bottles...
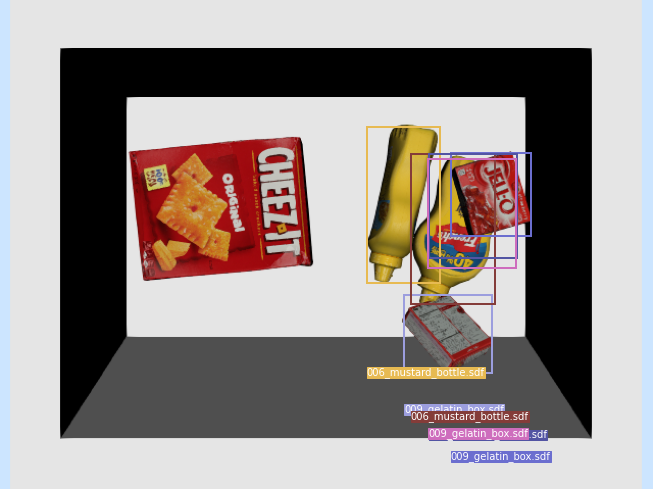

- Segmentation + ICP => model-based grasp selection
- Segmentation => antipodal grasp selection
6D Object Pose Estimation Challenge
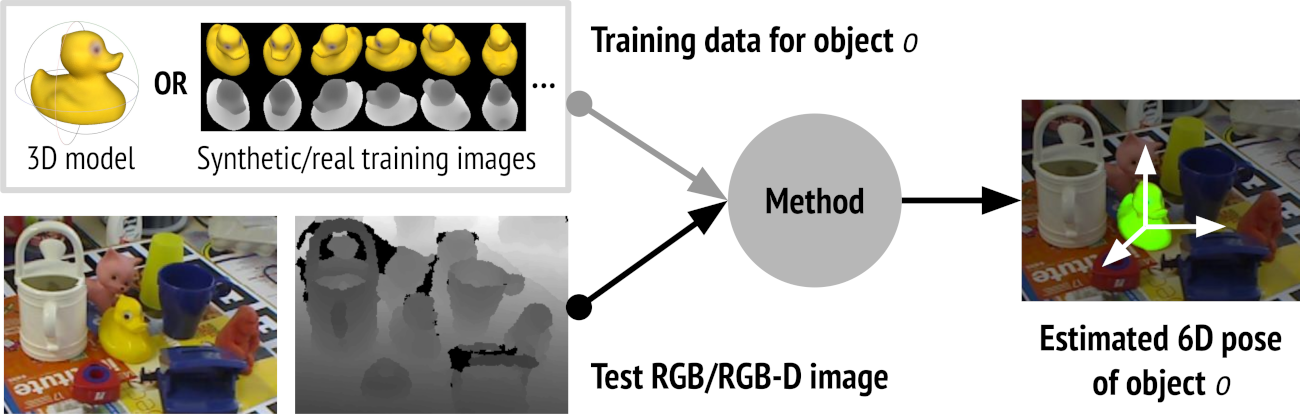
- Until 2019, geometric pose estimation was still winning*.
- In 2020, CosyPose: mask-rcnn + deep pose estimation + geometric pose refinement was best.
* - partly due to low render quality?
Self-supervised pretraining
Example: SimCLR
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html

Example: SimCLR
https://ai.googleblog.com/2020/04/advancing-self-supervised-and-semi.html

"Contrastive visual representation learning"
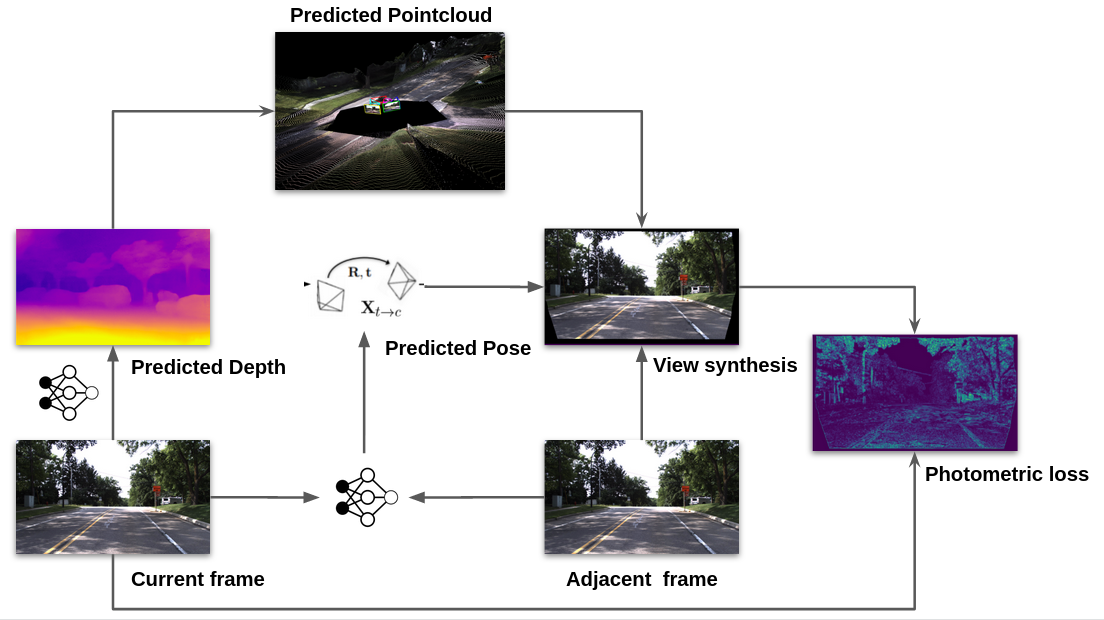
Example: Monocular Depth Estimation
from TRI Medium Blog Post
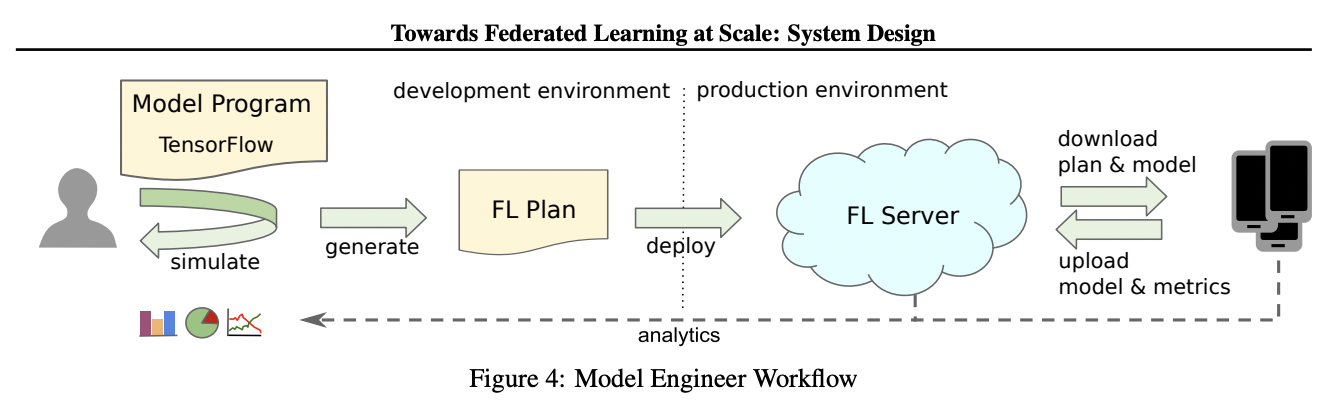
Decentralized self-supervised learning
Goal: Testing in simulation matches testing in reality. Continual learning / improvement.
Challenge: Distribution shift / non-iid data

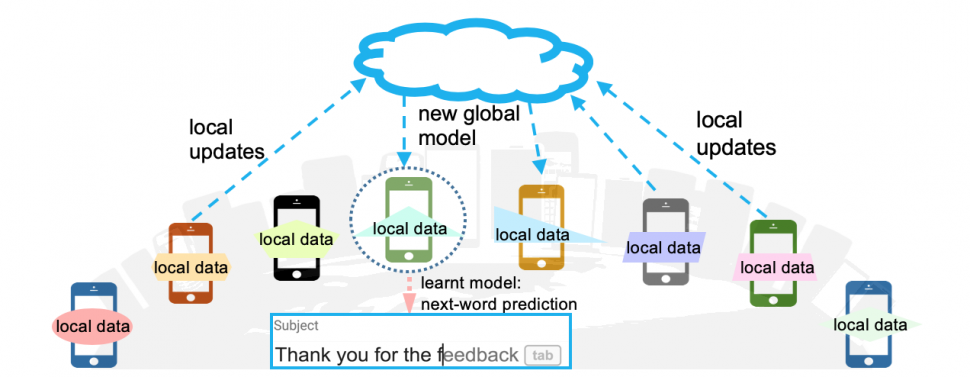
Federated Learning
Why Federated Learning?

Why not aggregate all data in the cloud and train a centralized model?
- Too much data, fleet can induct over 2M/day (bandwidth limits and costs)
- It is not clear that we should pool all of the data? (Generalization vs specialization). More data can hurt!
Distribution shifts in Amazon Robotics (AR) Dataset
- Lighting conditions
- Density (e.g. time of year/holidays)
- Upstream material handling systems
- Altitude
- Hardware configuration
- End of arm tooling (EoAT) type
- Arm type
- Sensor types
- Conveyors and walls
Distribution shifts in AR Data
Site A
Site B




Distribution shifts in AR Data
Site C
Site D
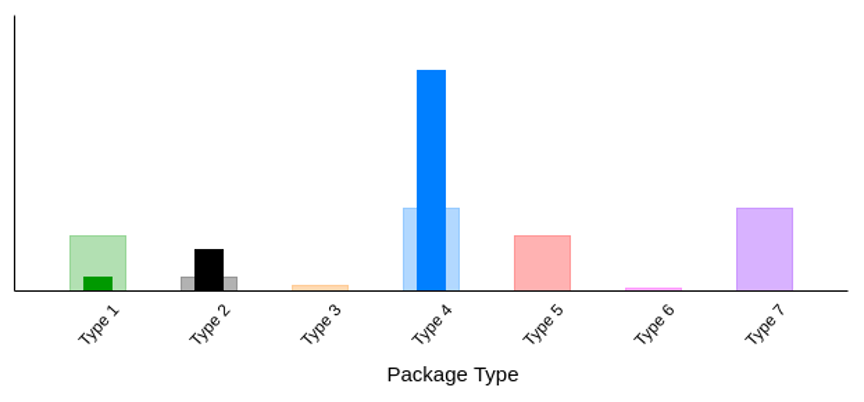
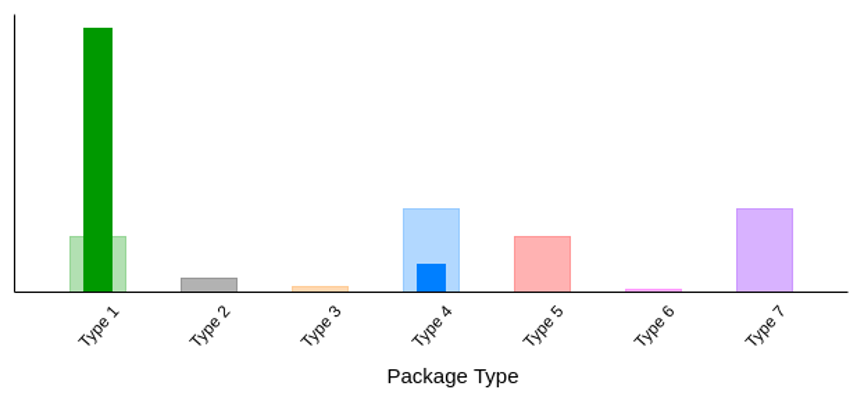




Distribution shifts in AR Data
Average number of segments per induct


Sites
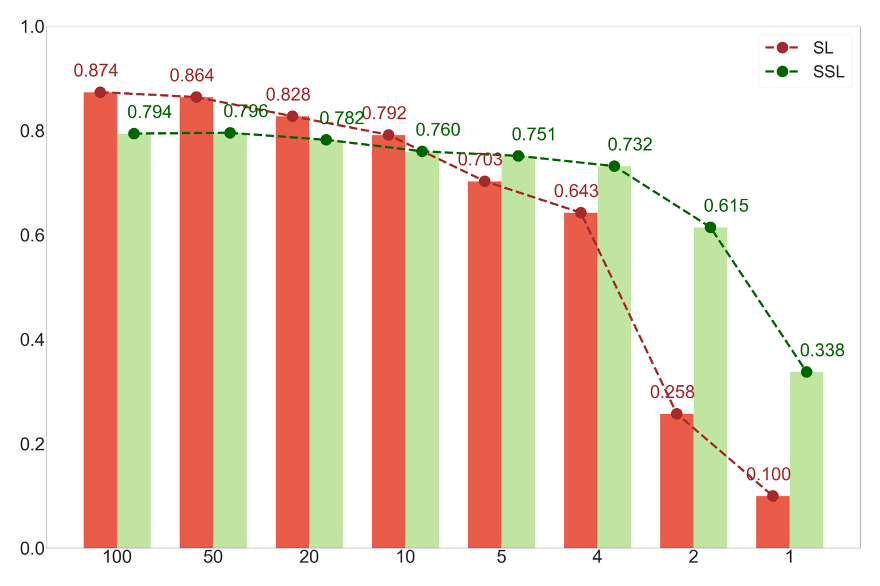
Key finding
Distributed training on the primary objective (e.g. classification / segmentation) is subject to over-fitting and shows limited robustness to distribution shift.
Distributed training on a surrogate self-supervised objective (e.g. SimCLR, SimSiam) reduces overfitting and shows superior generalization across distributions.
- Bonus: it requires less human-annotated labels.
We will compare two algorithms
Data: We created distribution shift datasets grouped by clustering labels, images, or features.
Algorithm 1: Supervised Learning (SL): Trains classification or segmentation objective directly.
Algorithm 2: Self-Supervised Learning (SSL): Train common visual representation, then only "fine-tune" a small "head" on the supervised data.
FedAvg algorithm (McMahon et al, 2017)
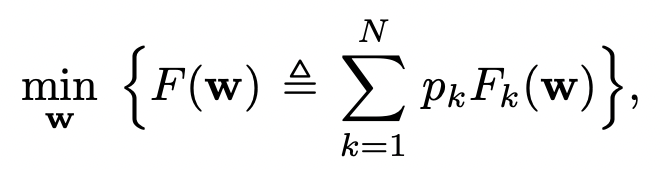
\(N\) robots.
\(p_k\) is weight for robot \(k\)
\(\ell(x)\) is the loss function
\(n_k\) training samples at \(k\)
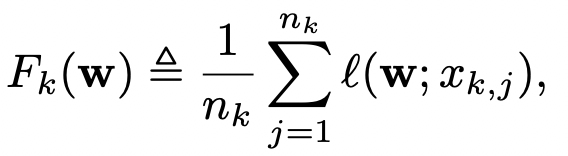
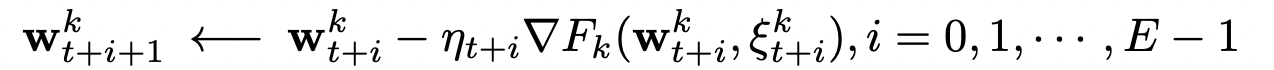
distributed client update: (\(E\) steps with random samples \(\xi\))
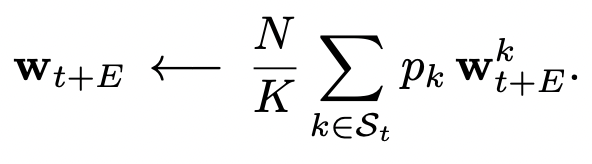
server update: (after responses from \(K\) clients)
E (number of decentralized steps)
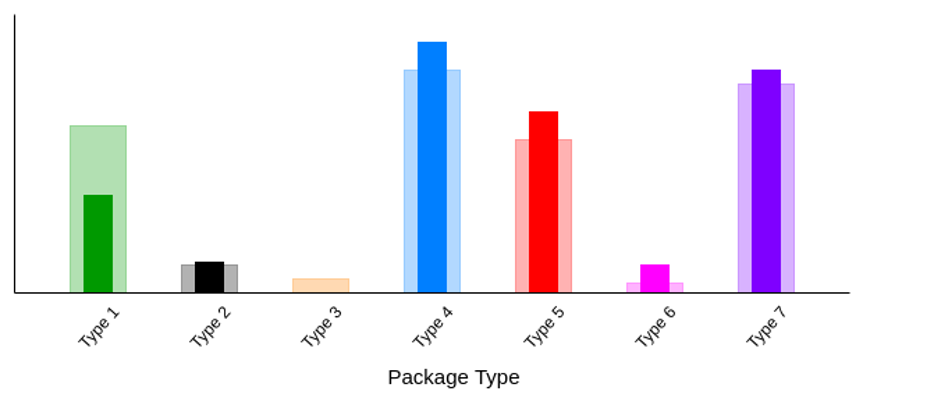
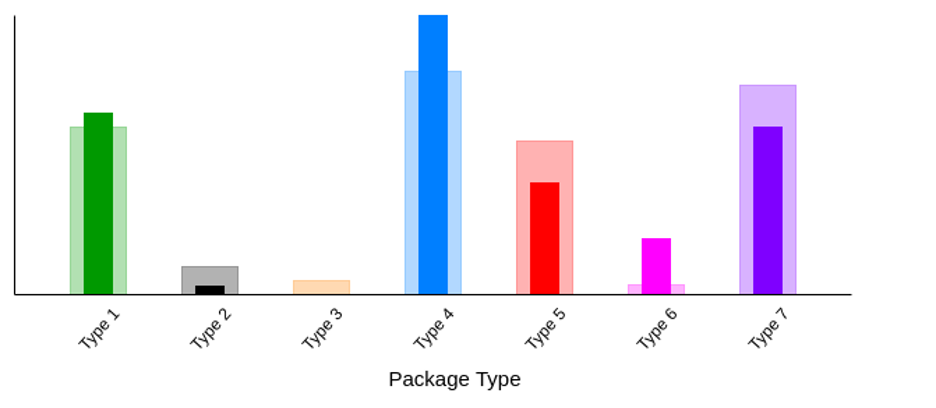
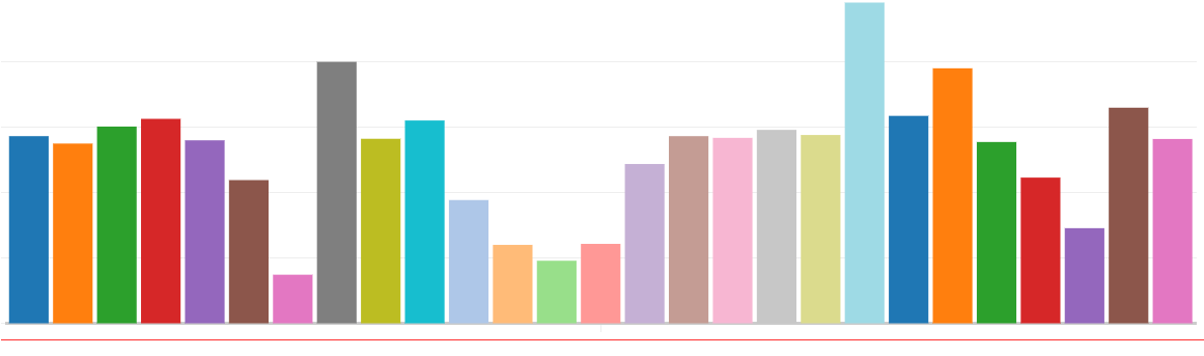
Classification on CIFAR distribution shift dataset
5
10
25
50
100
125
250
500
Classification success rate
Foundation models
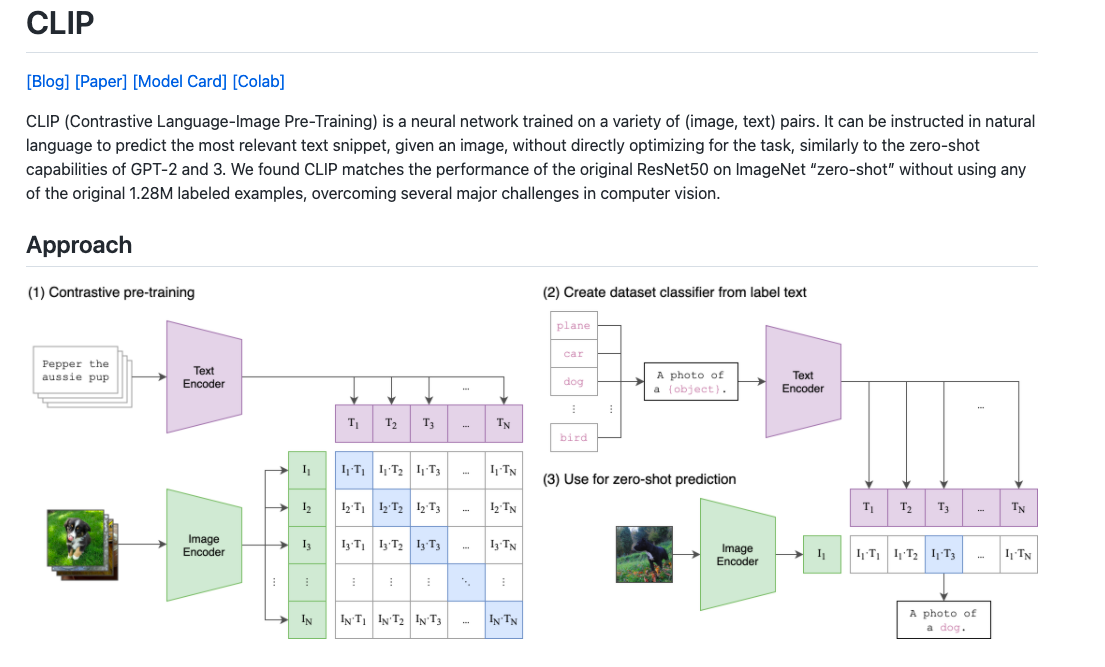
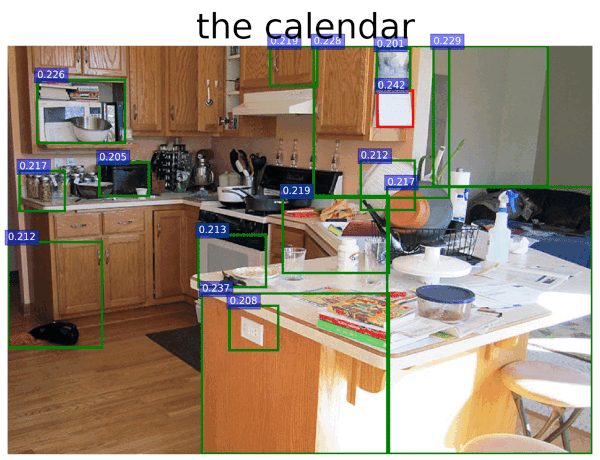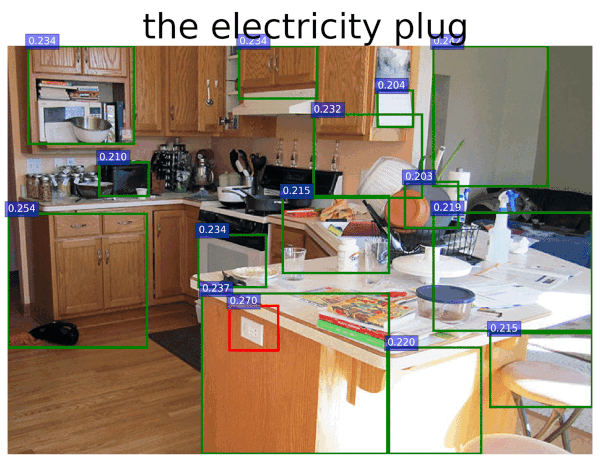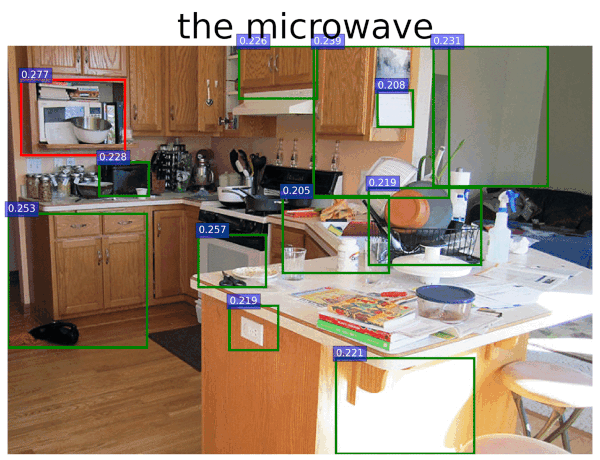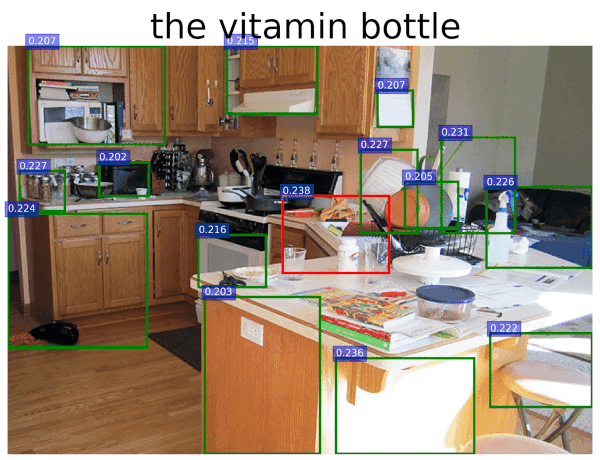
quick experiments using CLIP "out of the box" by Kevin Zakka