Large Behavior Models for Dexterous Manipulation
Russ Tedrake
VP, Robotics Research (and MIT prof)





Goal: Foundation Models for Manipulation
TRI has a special role to play
- Expertise across robotics, ML, and software
- Resources to train large models and do rigorous evaluation
- Resources to build large high-quality datasets
- Ability to advance robot hardware
- Our charter is basic research ("invent and prove")
- Strong tradition of open source
+ Amazing university partners

"Dexterous Manipulation" Team
(founded in 2016)
For the next challenge:
Good control when we don't have useful models?

For the next challenge:
Good control when we don't have useful models?
- Rules out:
- (Multibody) Simulation
- Simulation-based reinforcement learning (RL)
- State estimation / model-based control
- My top choices:
- Learn a dynamics model
- Behavior cloning (imitation learning)
Levine*, Finn*, Darrel, Abbeel, JMLR 2016
Key advance: visuomotor policies
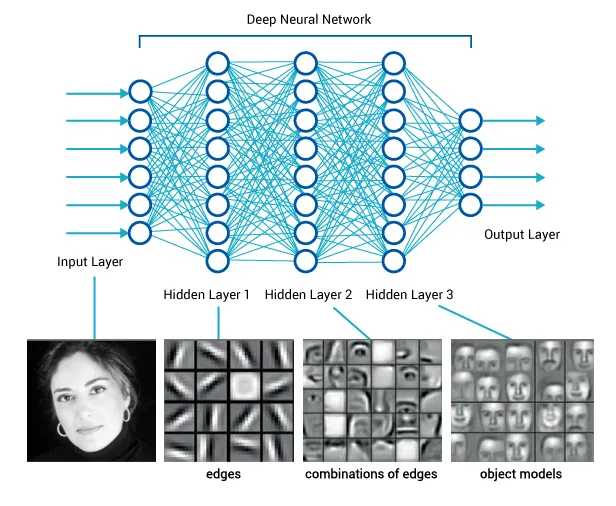
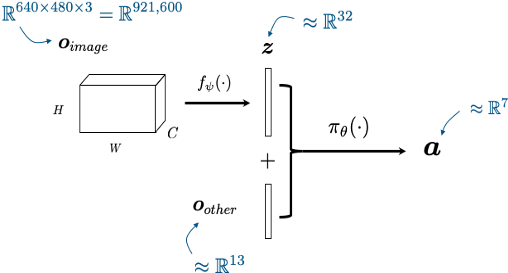
perception network
(often pre-trained)
policy network
other robot sensors
learned state representation
actions
x history
I was forced to reflect on my core beliefs...
- The value of using RGB (at control rates) as a sensor is undeniable. I must not ignore this going forward.
- I don't love imitation learning (decision making \(\gg\) mimcry), but it's an awfully clever way to explore the space of policy representations
- Don't need a model
- Don't need an explicit state representation
- (Not even to specify the objective!)
We've been exploring, and found something good in...

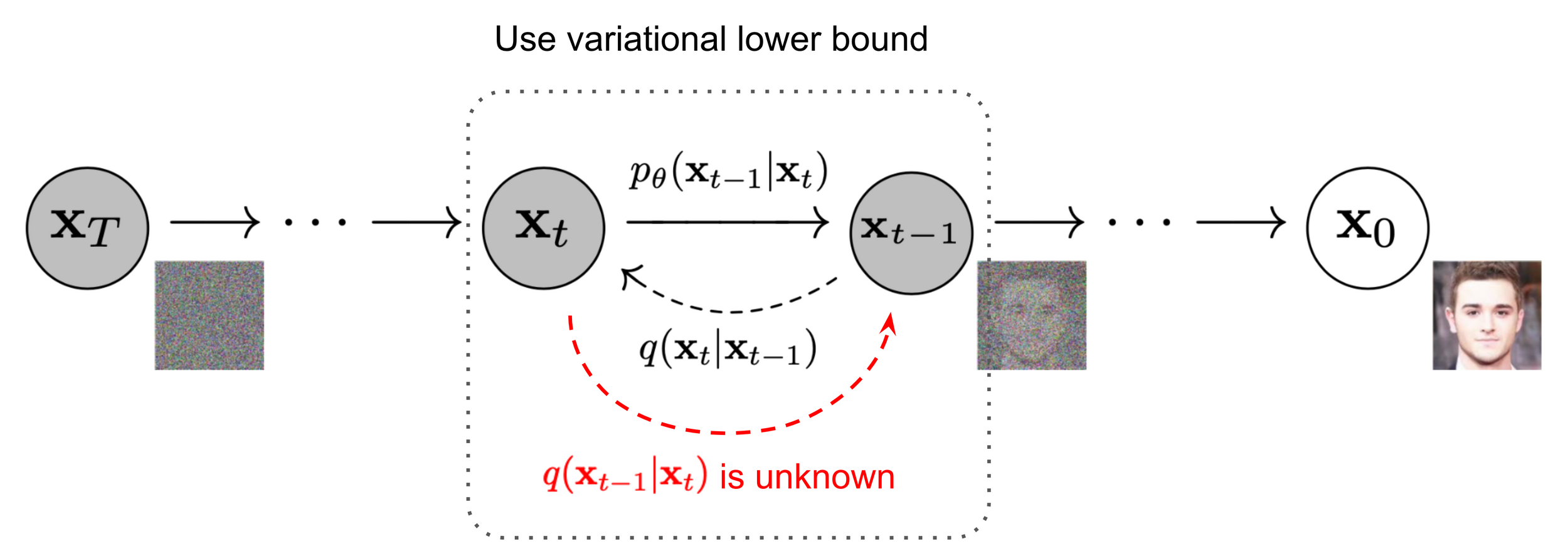
Diffusion models (e.g. for image generation)
Image source: Ho et al. 2020
great tutorial: https://chenyang.co/diffusion.html
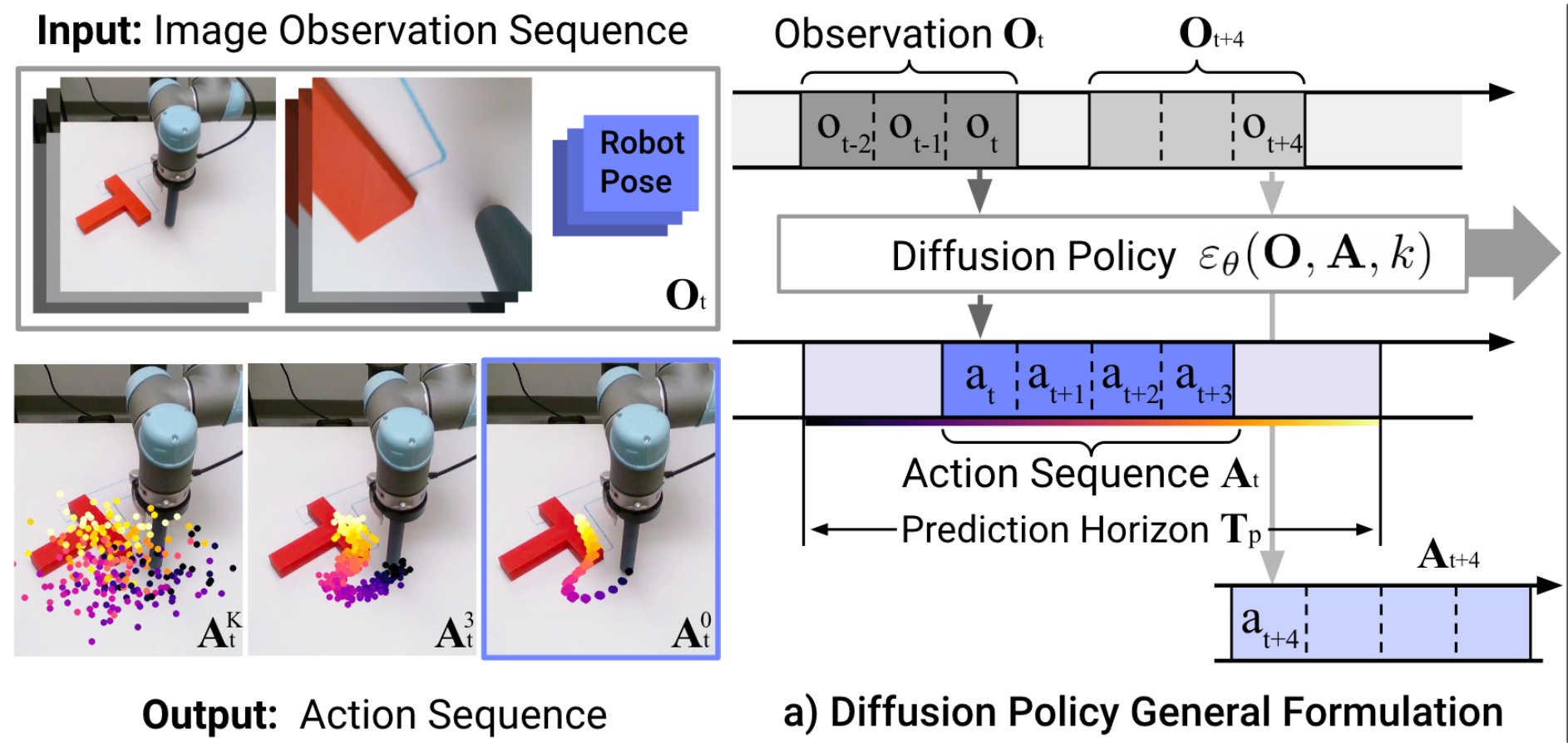
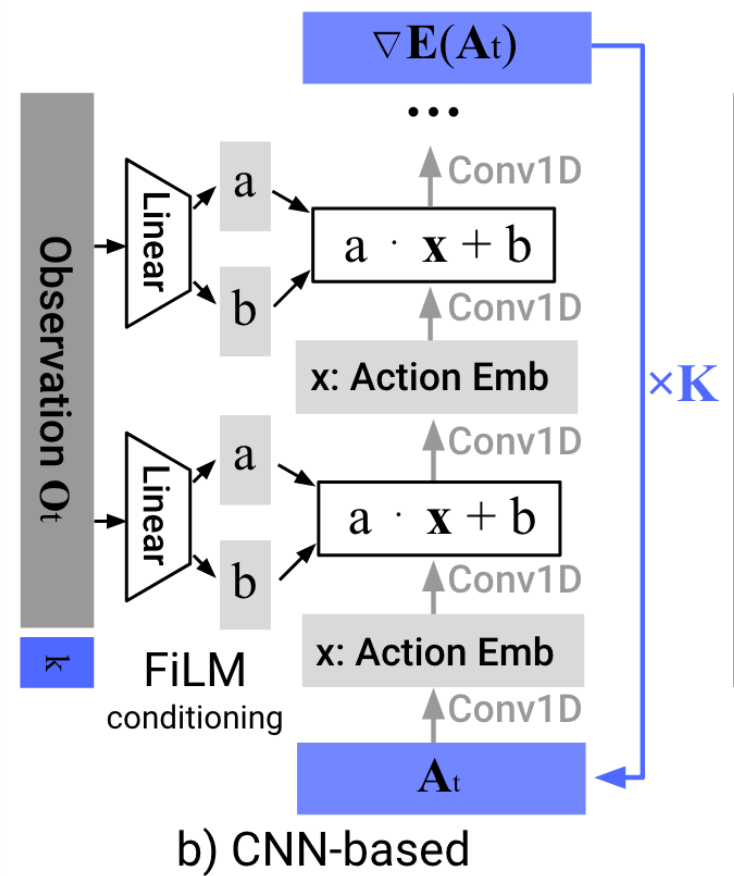
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
(Often) Reactive
Discrete/branching logic
Long horizon
Limited "Generalization"
(when training a single skill)
a few new skills...
Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50-100)
- Multi-modal (non-expert) demonstrations

Learns a distribution (score function) over actions
e.g. to deal with "multi-modal demonstrations"
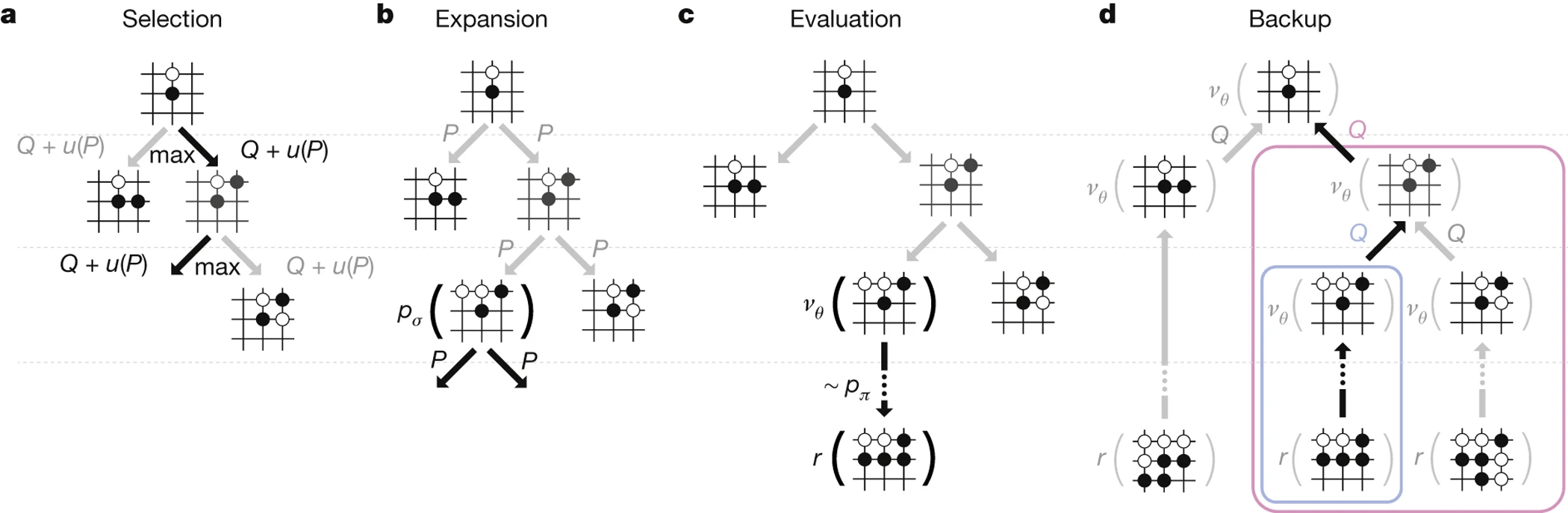
Learning categorial distributions already worked well (e.g. AlphaGo)
Diffusion helped extend this to high-dimensional continuous trajectories
Why (Denoising) Diffusion Models?
- High capacity + great performance
- Small number of demonstrations (typically ~50)
- Multi-modal (non-expert) demonstrations
- Training stability and consistency
- no hyper-parameter tuning
- Generates high-dimension continuous outputs
- vs categorical distributions (e.g. RT-1, RT-2)
- CVAE in "action-chunking transformers" (ACT)
- Solid mathematical foundations (score functions)
- Reduces nicely to the simple cases (e.g. LQG / Youla)
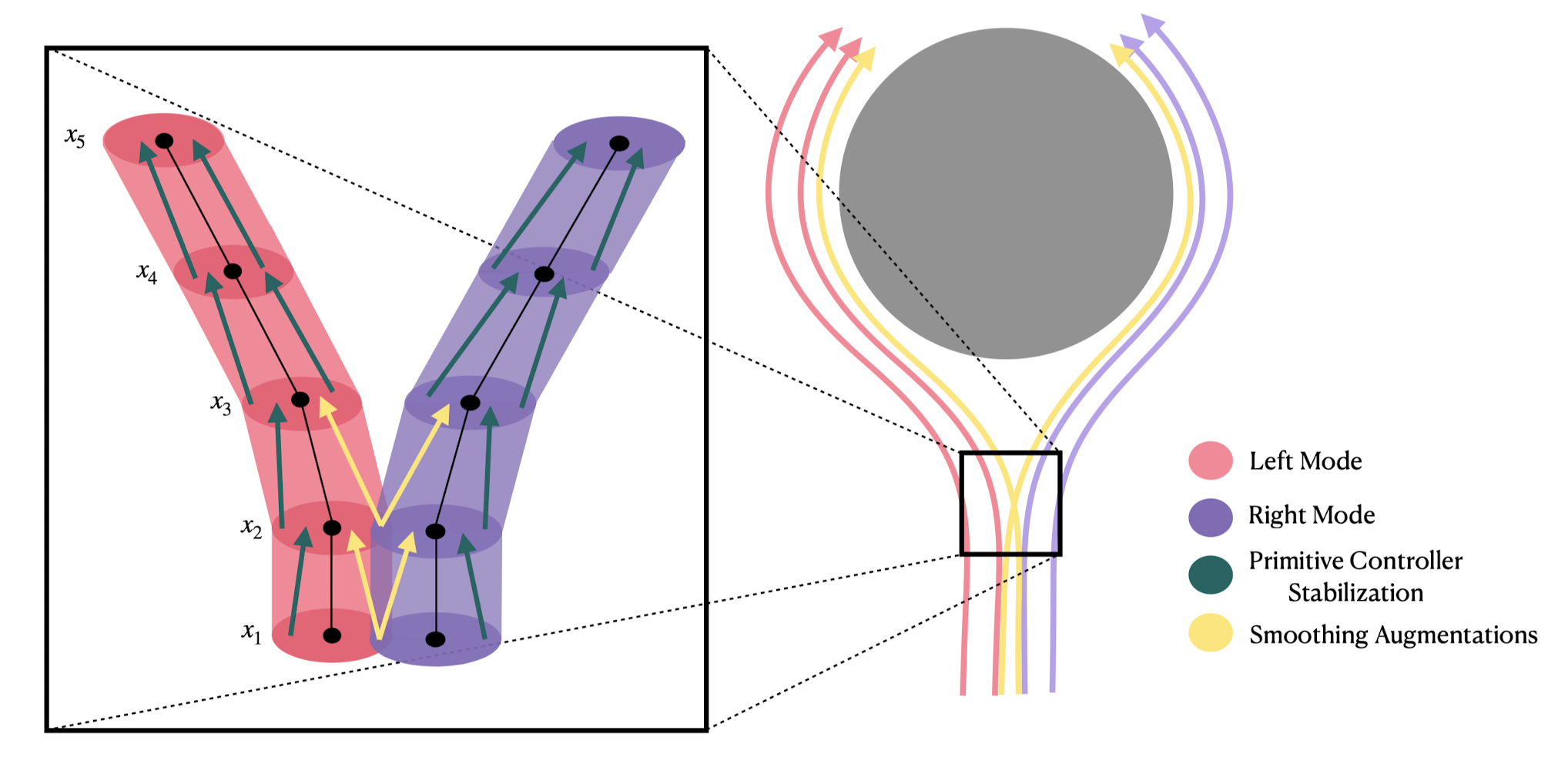
Denoising LQR ( )
Standard LQR:
Optimal actor:
Training loss:
stationary distribution of optimal policy
Optimal denoiser:
(deterministic) DDIM sampler:
Straight-forward extension to LQG:
Diffusion Policy learns (truncated) unrolled Kalman filter.
converges to LQR solution
Denoising LQR ( )
Diffusion Policy for Dexterous HANDs?


Enabling technologies
Haptic Teleop Interface
Excellent system identification / robot control
Visuotactile sensing

with TRI's Soft Bubble Gripper
Open source:
But there are definitely limits to the single-task models
Scaling Up
LLMs \(\Rightarrow\) VLMs \(\Rightarrow\) LBMs
large language models
visually-conditioned language models
large behavior models
\(\sim\) VLA (vision-language-action)
\(\sim\) EFM (embodied foundation model)
Q: Is predicting actions fundamentally different?
Why actions (for dexterous manipulation) could be different:
- Actions are continuous (language tokens are discrete)
- Have to obey physics, deal with stochasticity
- Feedback / stability
- ...
should we expect similar generalization / scaling-laws?
Success in (single-task) behavior cloning suggests that these are not blockers
Prediction actions is different
- We don't have internet scale action data (yet)
- We still need rigorous/scalable "Eval"
Prediction actions is different
- We don't have internet scale action data (yet)
- We need rigorous/scalable "Eval"
The Robot Data Diet

Big data
Big transfer
Small data
No transfer
robot teleop

(the "transfer learning bet")
Open-X
simulation rollouts


novel devices
Action prediction as representation learning
In both ACT and Diffusion Policy, predicting sequences of actions seems very important
Thought experiment:
To predict future actions, must learn
dynamics model
task-relevant
demonstrator policy
dynamics
Cumulative Number of Skills Collected Over Time
The (bimanual, dexterous) TRI CAM dataset

CAM data collect


The DROID dataset
w/ Chelsea Finn and Sergey Levine
The Robot Data Diet
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
w/ Shuran Song
The Robot Data Diet
Big data
Big transfer
Small data
No transfer
robot teleop
(the "transfer learning bet")
Open-X
simulation rollouts
novel devices
Prismatic VLMs
w/ Dorsa Sadigh
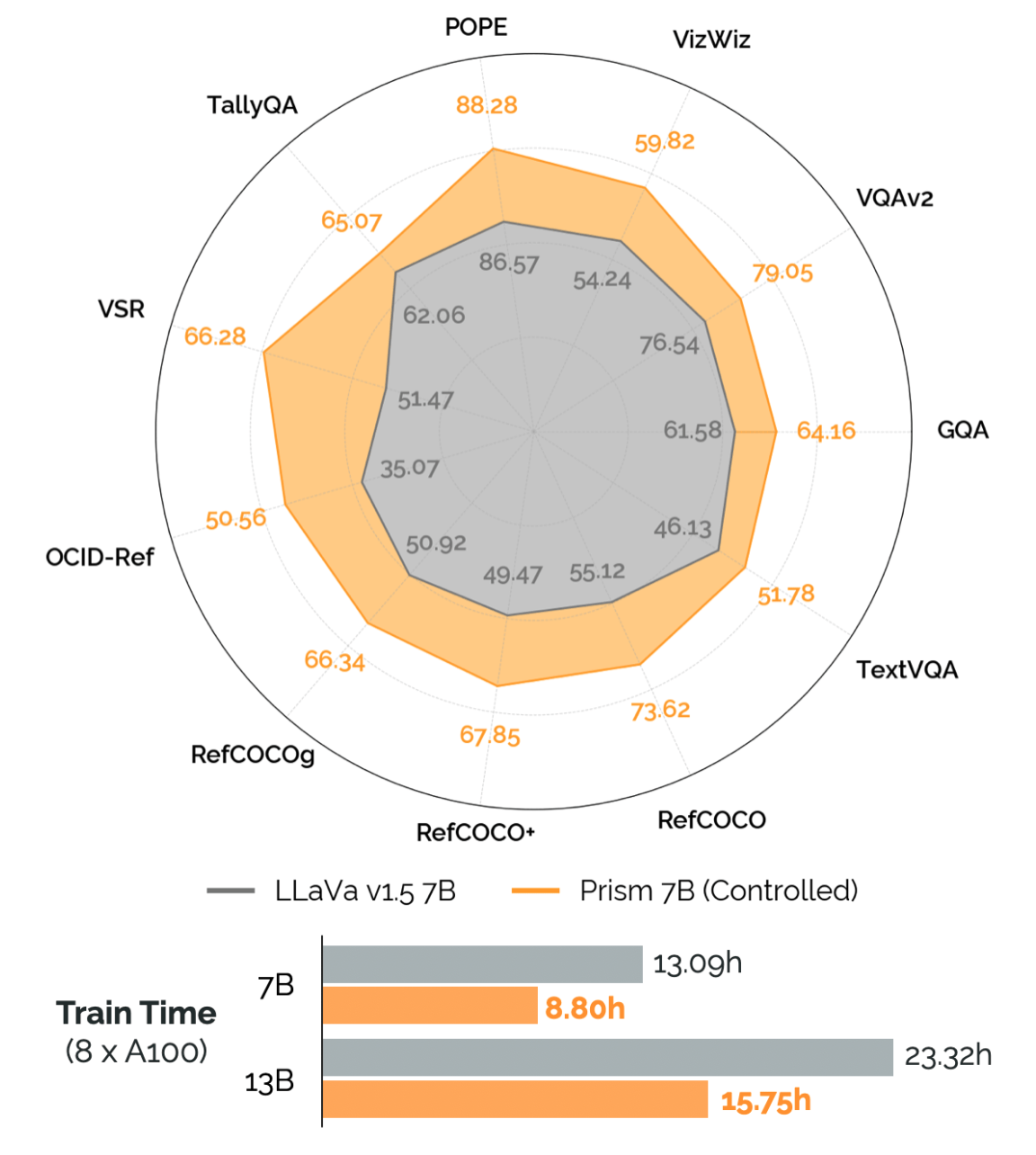
Fine-grained evaluation suite across a number of different visual reasoning tasks
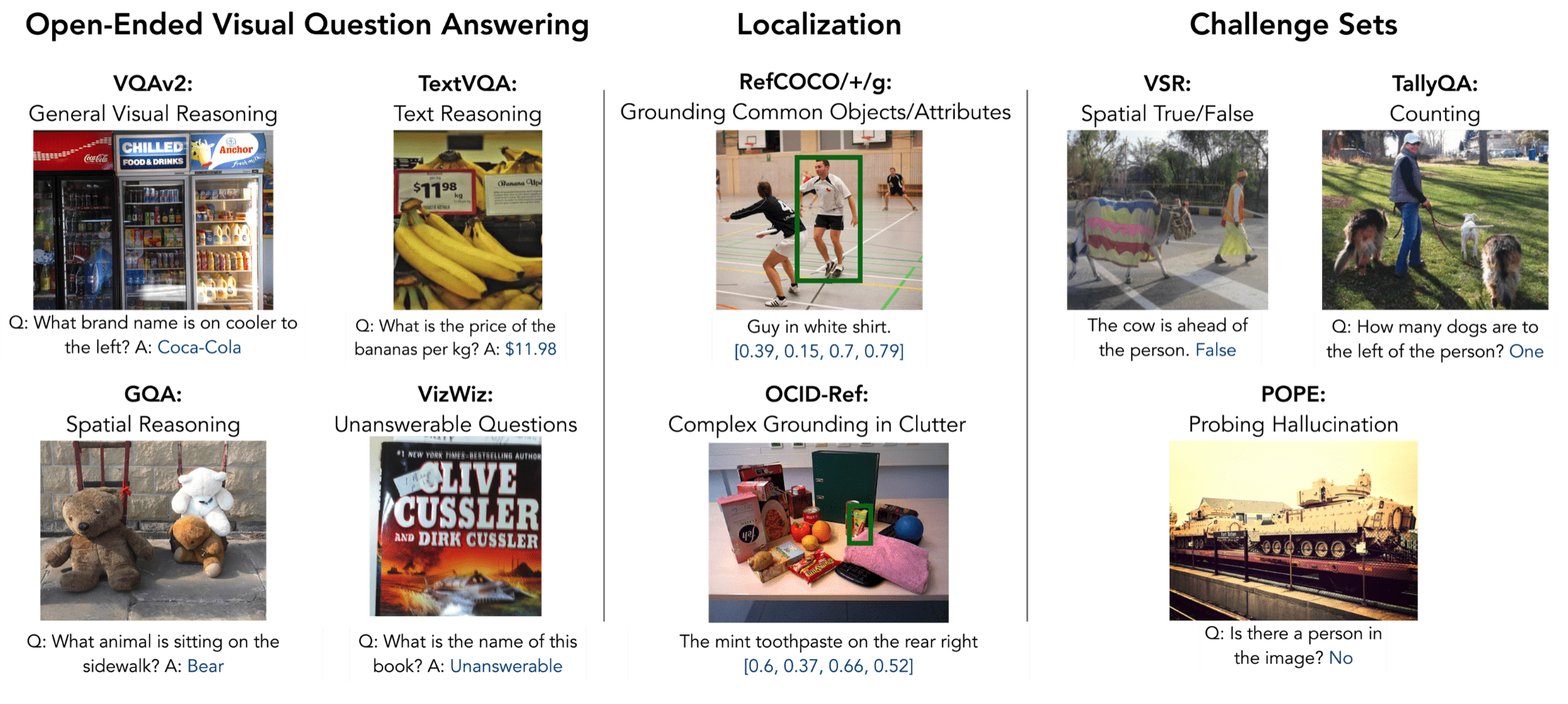
Prismatic VLMS \(\Rightarrow\) Open-VLA
Video Diffusion



w/ Carl Vondrick
This is just Phase 1
Enough to make robots useful (~ GPT-2?)
\(\Rightarrow\) get more robots out in the world
\(\Rightarrow\) establish the data flywheel
Then we get into large-scale distributed (fleet) learning...
The AlphaGo Playbook

- Step 1: Behavior Cloning
- from human expert games
- Step 2: Self-play
- Policy network
- Value network
- Monte Carlo tree search (MCTS)
Scaling Monte-Carlo Tree Search


"Graphs of Convex Sets" (GCS)

Prediction actions is different
- We don't have internet scale action data (yet)
- We need rigorous/scalable "Eval"

Eval with real robots (it's hard!)
Example: we asked the robot to make a salad...

Eval with real robots
Rigorous hardware eval (Blind, randomized testing, etc)
But in hardware, you can never run the same experiment twice...
Simulation Eval / Benchmark


"Hydroelastic contact" as implemented in Drake
"Hydroelastic contact" as implemented in Drake

Material Point Method
w/ Chenfanfu Jiang
Partnership with Amazon Robotics and NVidia

NVIDIA is starting to support Drake (and MuJoCo):
- Drake OpenUSD parser
- RTX rendering
- potentially make Drake available in IsaacSym/Omniverse
Wrap-up
A foundation model for manipulation, because...
- start the data flywheel for general purpose robots
- unlock the new science of visuomotor "intelligence" (with aspects that can only be studied at scale)
Some (not all!) of these basic research questions require scale
There is so much we don't yet understand... many open algorithmic challenges


Dexterous Manipulation at TRI
https://www.tri.global/careers
We are hiring! (a little)
tri.global/careers