A Few Challenge Problems from Robotics

Russ Tedrake

Follow along at https://slides.com/russtedrake/rl-2020-bc/live
or view later at https://slides.com/russtedrake/rl-2020-bc/

How broad is the umbrella of RL?
Sequential decision making, but then
Black-box / Derivative-free?
Learning + Control
My goals for today
- How well is control working in robotics today?
- A few core questions/challenges
- What role can simulation play?
- Why/when does gradient-based policy search work?
- Parameterizations/algorithms from control.
- RL in the rare-event regime.
- Challenge problem instances
- Raibert's hopper, planar gripper, plates, onions, shoe laces.
How well is control working in robotics?
Feels like an opportunity for RL?
Is the task difficult because we don't have a model?
What role can simulation play?
for spreading peanut butter, buttoning my shirt, etc.
As more people started applying RL to robots, we saw a distinct shift from "model-free" RL to "model-based" RL.
(most striking at the 2018 Conference on Robot Learning)
Recent IFRR global panel on "data-driven vs physics-based models"
(caveat: I didn't choose the panel name)
Core technology: Deep learning perception module that learns "dense correspondences"
Learn a deep dynamic model of "keypoint" dynamics.
Online: use model-predictive control (MPC)
What is a (dynamic) model?
System
State-space
Auto-regressive (eg. ARMAX)
input
output
state
noise/disturbances
parameters
Lagrangian mechanics,
Recurrent neural networks (e.g. LSTM), ...
Feed-forward networks
(e.g. \(y_n\)= image)
What is a (dynamic) model?
System
State-space
Auto-regressive (eg. ARMAX)
input
output
Models come in many forms
input
cost-to-go
Q-functions are models, too. They try to predict only one output (the cost-to-go).
As you know, people are using Q-functions in practice on non-Markovian state representations.
\[ Q^{\pi}(n, x_n,u_n, \theta) \]
Model "class" vs model "instance"
- \(f\) and \(g\) describe the model class.
- with \(\theta\) describes a model instance.
"Deep models vs Physics-based models?" is about model class:
Should we prefer writing \(f\) and \(g\) using physics or deep networks?
Maybe not so different from
- should we use ReLU or \(\tanh\)?
- should we use LSTMs or Transformers?
Galileo, Kepler, Newton, Hooke, Coulomb, ...
were data scientists.
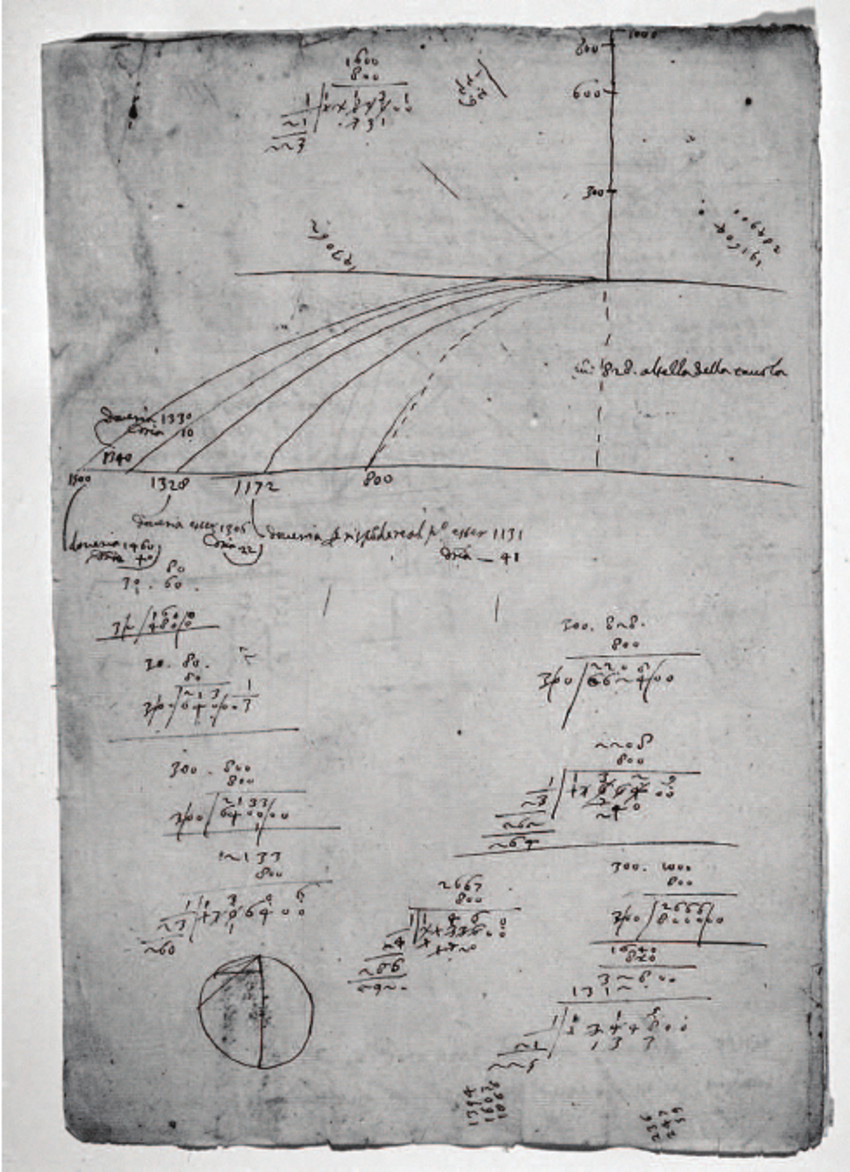
They fit very simple models to very noisy data.
Gave us a rich class of parametric models that we could fit to new data.
What if Newton had deep learning...?
Galileo's notes on projectile motion
Aside: "Differentiable Physics"
Our physics models are (and have always been) differentiable.
You don't need neural networks. Just the chain rule.
What makes a model class useful?
"All models are wrong, but some are useful" -- George Box
Use case: Simulation
e.g., for
- generating synthetic training data
- Monte-Carlo policy evaluation
- offline policy optimization
What makes a model class useful?
- Reasonable: \( y_{sim}(u) \in \{ y_{real}(u) \} \)
- Coverage: \( \forall y_{real}(u), \exists y_{sim}(u) \)
- Accuracy: \( p(y_{real} | u) \approx p(y_{sim} | u) \)
- Corollary: Reliable system identification (data \( \Rightarrow \theta \))
- Generalizable, efficient, repeatable, interpretable/debuggable, ...

Use case: Online Decision Making (Planning/Control)
What makes a model class useful?
- Reasonable, Accurate, Generalizable, ...
- Efficient / compact
- Observable
- Task-relevant
State-space models tend to be more efficient/compact, but require state estimation.
- Ex: chopping onions.
- Lagrangian state not observable.
- Task relevant?
- Doesn't imply "no mechanics"
vs.
Auto-regressive
State-space
Occam's razor and predicting what won't happen
Perhaps the biggest philosophical difference between traditional physics models and "universal approximators".
- \( f,g\) are not arbitrary. Mechanics gives us constraints:
- Conservation of mass
- Conservation of energy
- Maximum dissipation
- ...
- Arguably these constraints give our models their structure
- Control affine
- Inertial matrix is positive definite
- Inverse dynamics have "branch-induced sparsity"
- Without structure, maybe we can only ever do stochastic gradient descent...?
The failings of our physics-based models are mostly due to the unreasonable burden of estimating the "Lagrangian state" and parameters.
For e.g. onions, laundry, peanut butter, ...
The failings of our deep models are mostly due to our inability to due efficient/reliable planning, control design and analysis.
I want the next Newton to come around and to work on onions, laundry, peanut butter...
Why/when does gradient-based policy search work?
OpenAI - Learning Dexterity
"PPO has become the default reinforcement learning algorithm at OpenAI because of its ease of use and good performance."
https://openai.com/blog/openai-baselines-ppo/


But there are also cases where it will not work...
A simple counter-example from static output feedback:
http://underactuated.mit.edu/policy_search.html
The set of stabilizing \(k\) is a disconnected set.
|
k |
Maximum real closed-loop eigenvalue |
|---|---|
| 0.9 | -0.035 |
| 1.5 | 0.032 |
| 2.1 | -0.009 |
What characterizes the good cases?
- Maybe it is over-parameterization of deep policies?
- Is there a comparable story to interpolating solutions in high-dimensional policy space?
- Maybe it is the distribution over tasks?
- Control has traditionally studied algorithms that must work for all A,B,C. Maybe the world never gives us the hard ones?
- Optimizing simultaneously over diverse tasks might be easier than optimizing over one task.
Lessons from Control
(for instance: better controller parameterizations)
- Just because you can search over \(u = -Kx\) directly, does not mean that you should!
- Slow convergence
- Set of stabilizing \(K\) is nontrivial
- If model is known, searching \(Q\) and \(R\) is better.

ADPRL, 2012
- Youla parameterization (disturbance-based feedback)
- LMI formulations
- Result in convex formulations only for linear systems, but the benefits are likely more general.
ADPRL, 2012
For LQG, \(H_\infty\), etc., we know convex parameterizations.
Youla parameters (time-domain, no-noise)
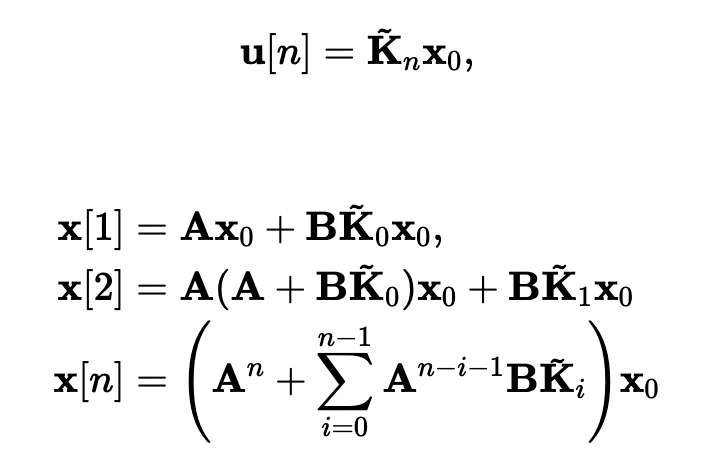
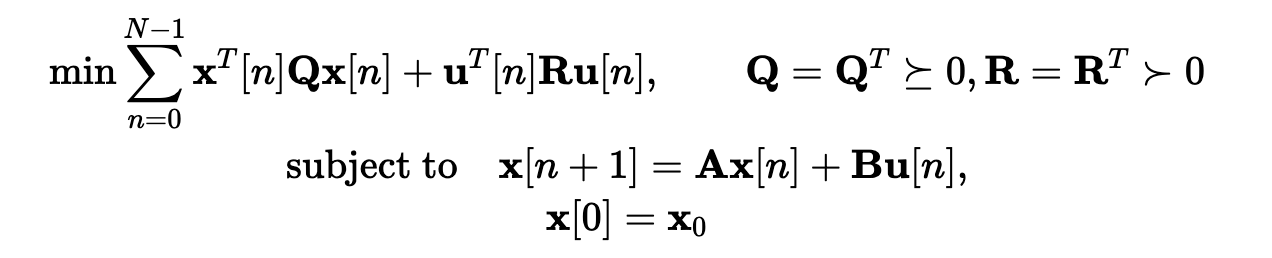
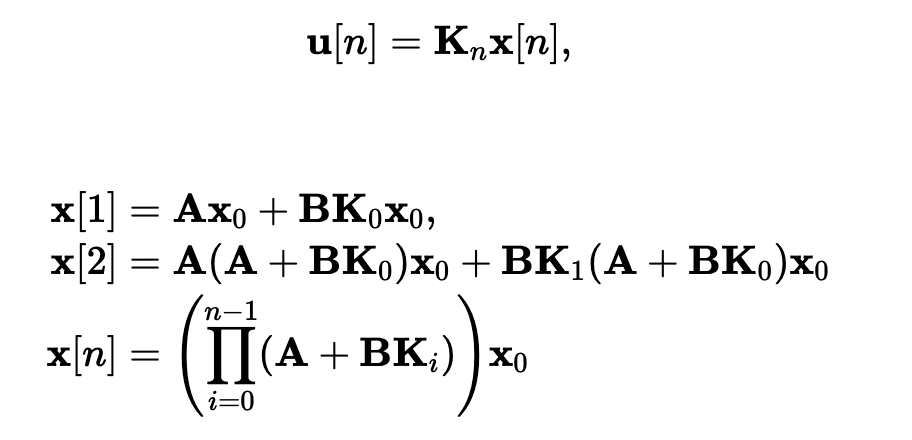
http://underactuated.csail.mit.edu/lqr.html
Control parameterizations from the "robot whisperers"
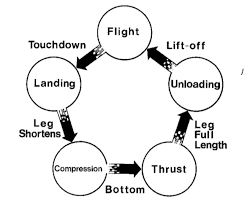
The MIT Leg Lab Hopping Robots

http://www.ai.mit.edu/projects/leglab/robots/robots.html
RL in the rare-event regime (for robotics)
Motivation

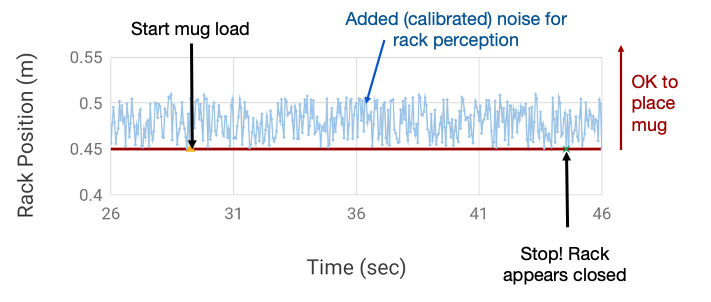
Finding subtle bugs



Estimating failure probability
for black-box, very high-dimensional, complex simulators
- adaptive multi-level splitting
- Hamiltonian MC
- parametric warping distributions via normalizing flows
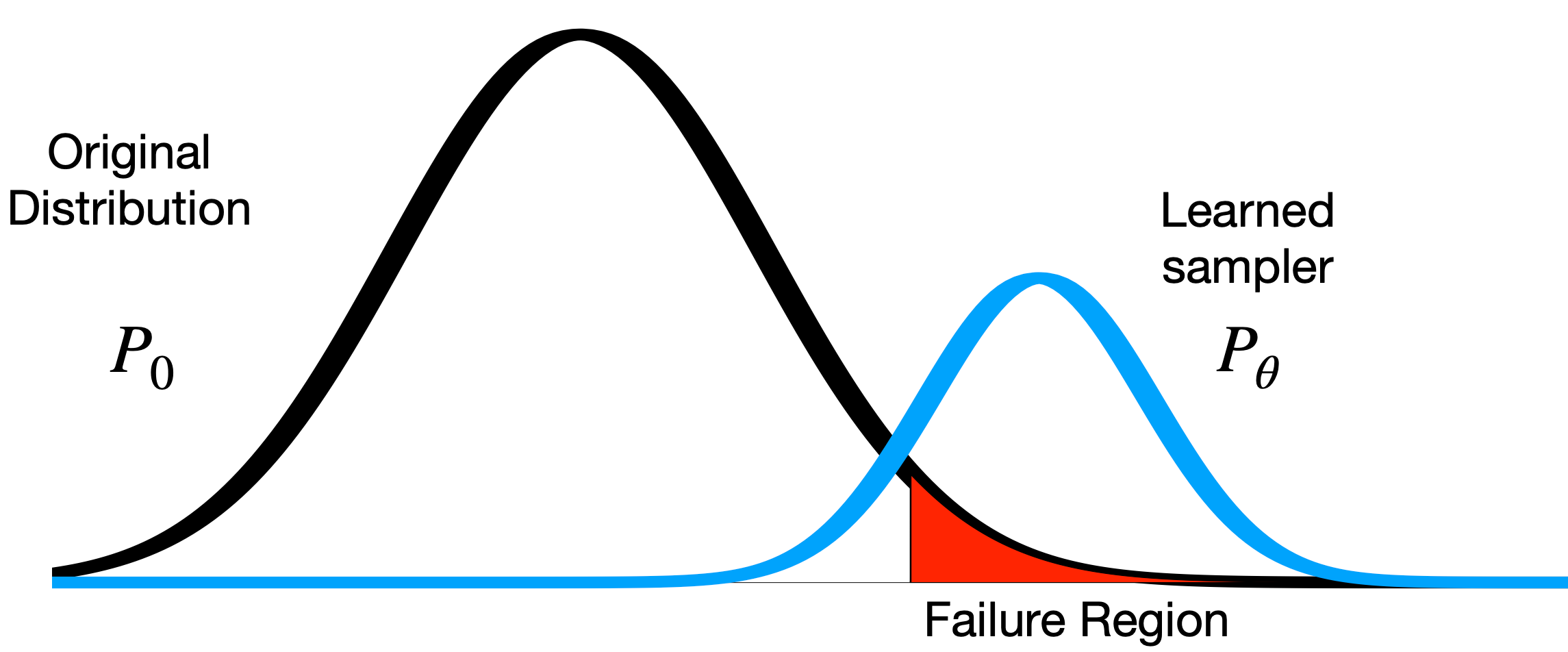
Failure probability vs "falsification"
Falsification algorithms are not designed for coverage.
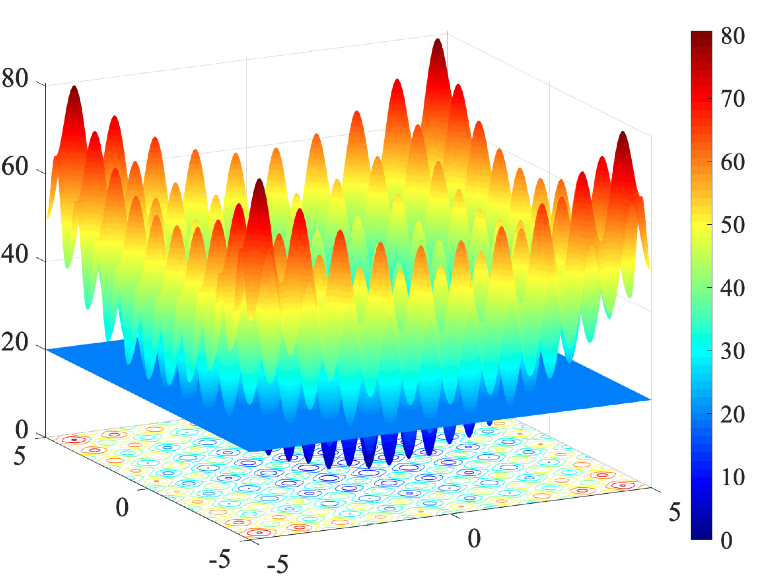
find \(x < 20\)
vs
estimate \(p(x<20)\)
The risk-based framework
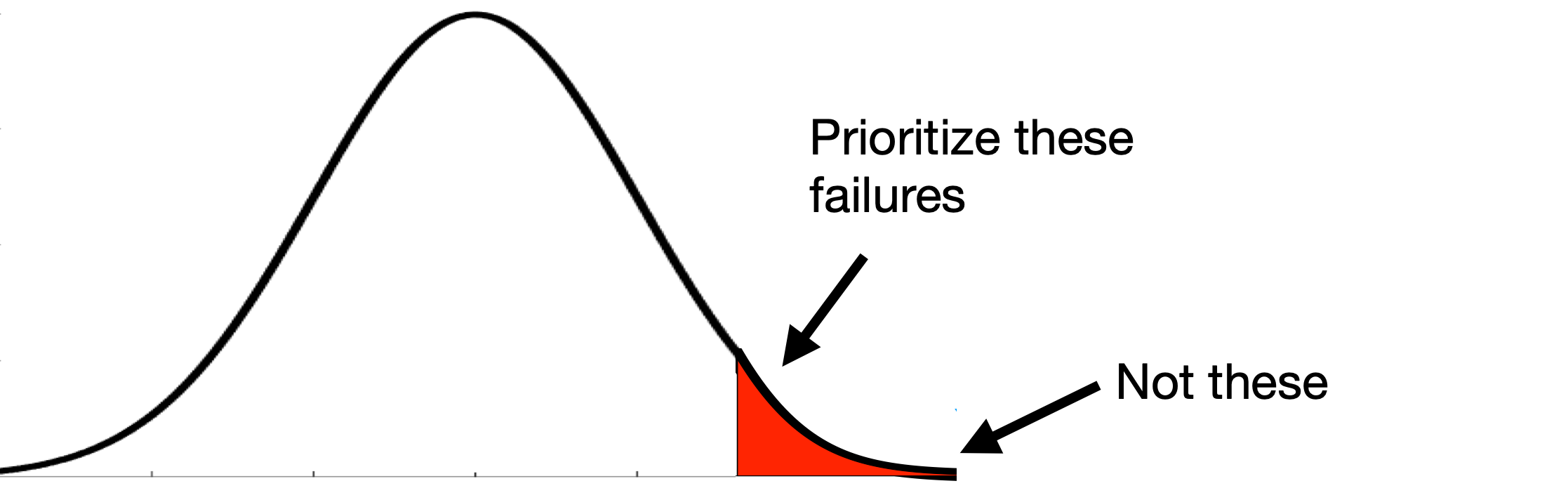
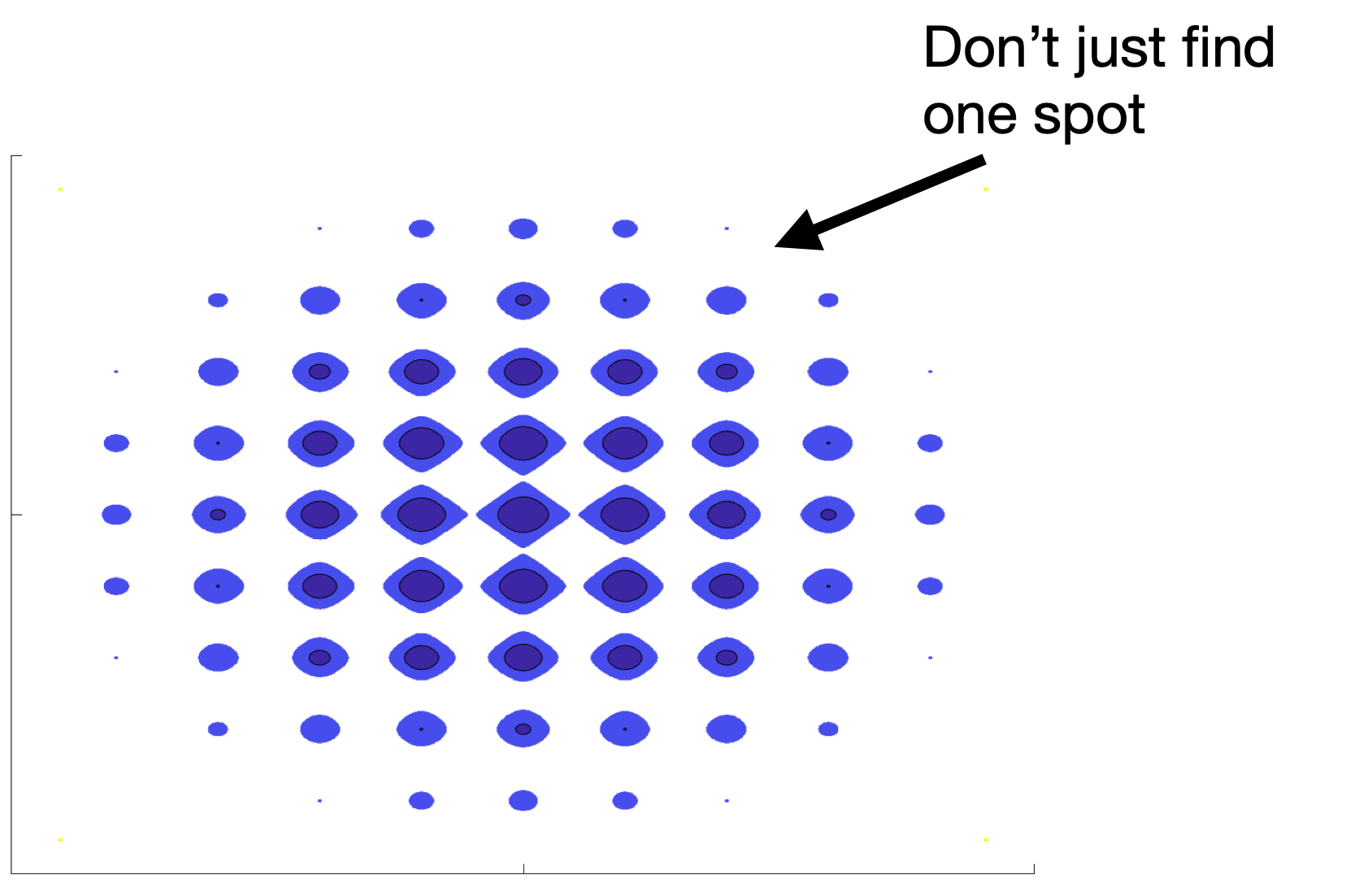
The risk-based framework
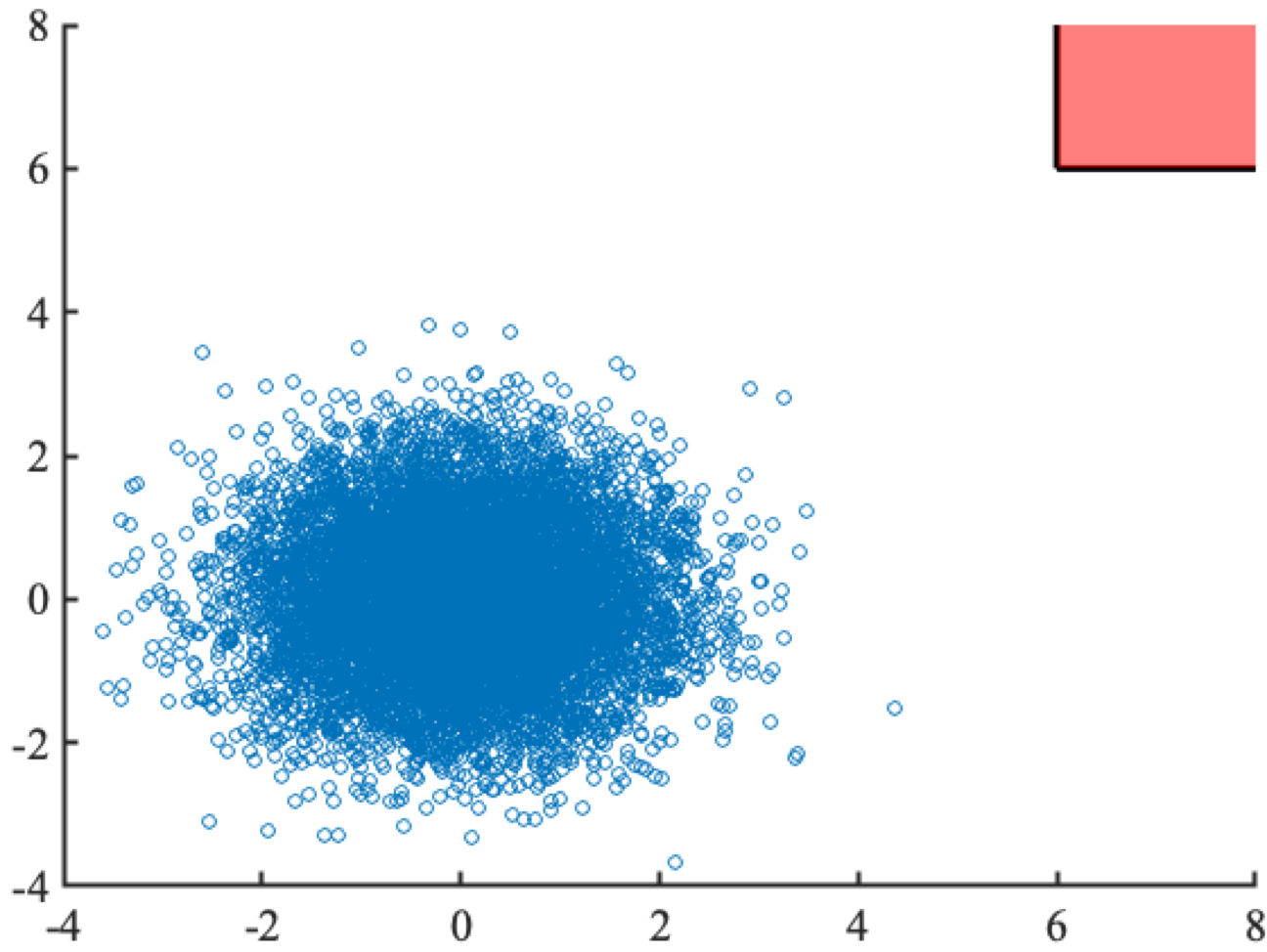
Region of interest
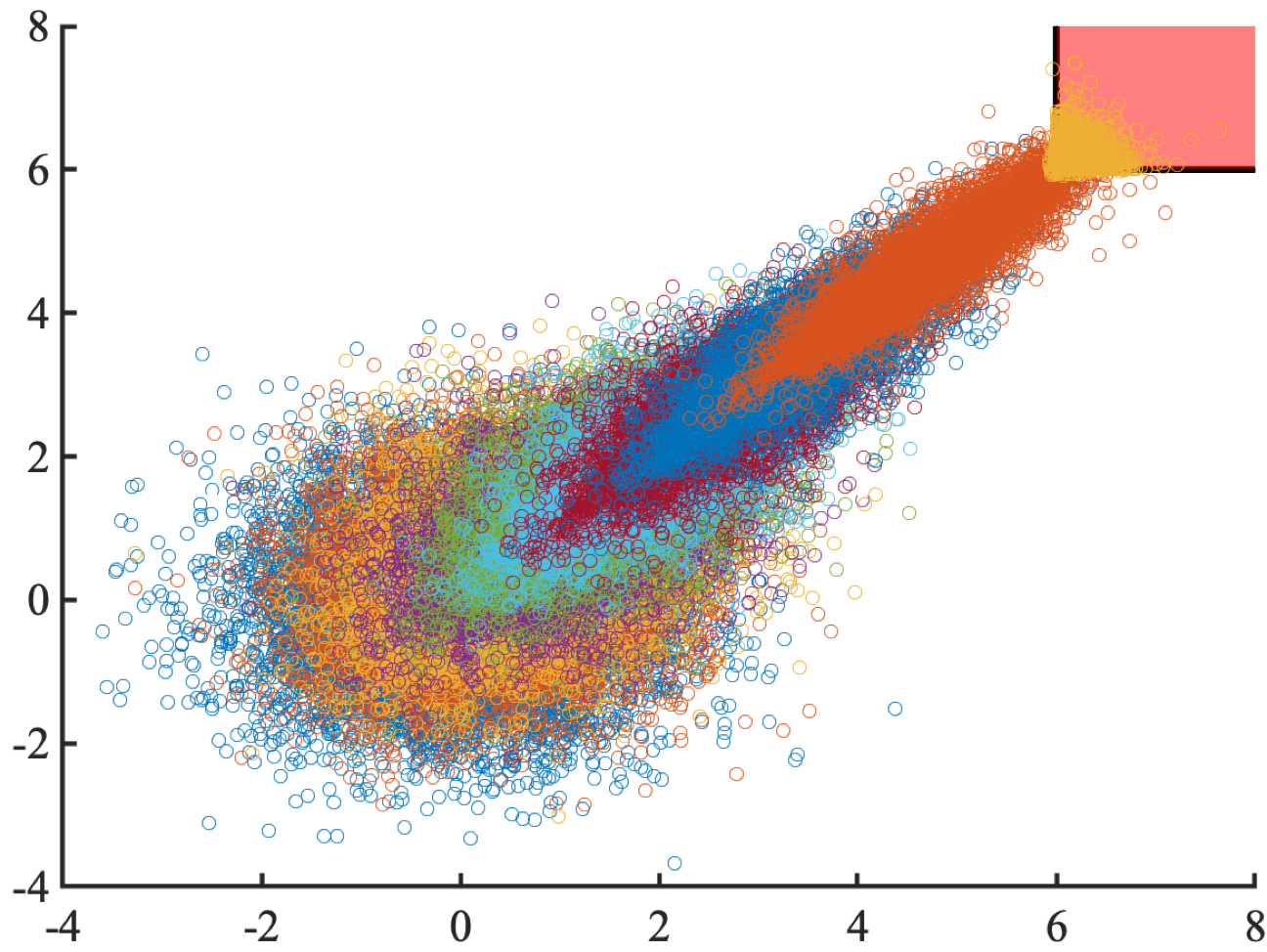
a smooth ladder of samplers

Finds surprisingly rare and diverse failures of the full comma.ai openpilot in the Carla simulator.
The primary authors have now created a startup:
RL in the rare-event regime
Invites super interesting questions for RL / control.
- Convinced me that empirical risk estimation might actually to scale to high dimensional data.
- Plausible formulation of "safety" in difficult domains.
- Do the parameterized warping distributions enable more efficient importance-sampling RL?
Some specific robotics problem instances

Distributional Robustness
We have parameterized simulations to study distributional robust / distribution shift.
- Parameterized environments (lighting conditions, etc)
- Carefully parameterized procedural mugs!
- ...
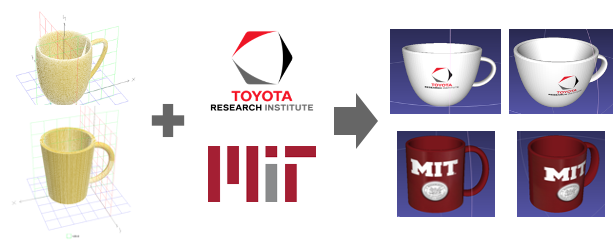


Releasing all of these as a part of my fall manipulation class at MIT (which is open and online).
Comparison w/ computer vision
- We can simulate (render) almost anything.
- I don't worry about accuracy, because we must be robust to model errors. Sim2Real for perception.
- What is difficult is to capture the distributions of relevant simulation parameters (images).
- It may be that empirical distributions are best.
- Does that imply we should use black box optimization?
Inverse "Rendering" is difficult
If my robot is in the world, and experiences a scenario -- it's hard to put that back into simulation.
How well is RL working for robotic control?
Information theoretic MPPI driving an AutoRally platform aggressively at the Georgia Tech Autonomous Racing Facility.
OpenAI dexterous hand
Summary
- How well is control working in robotics today?
- A few core quesitons/challenges
- What role can simulation play?
- Why/when does gradient-based policy search work?
- Parameterizations/algorithms from control.
- RL in the rare-event regime.
- Challenge problem instances
- Plates, planar gripper, Raibert's hopper, onions, shoe laces...
Click here
(on this slide)
Then here
(in the colab window)
or from Ch.1 at http://manipulation.mit.edu