Supervised Policy Learning for Real Robots
Diffusion Policy Deeper Dive




Nur Muhammad
"Mahi" Shafiullah
New York University
Siyuan Feng
Toyota Research
Institute
Lerrel Pinto
New York University
Russ Tedrake
MIT, Toyota Research Institute

"Diffusion" models

great tutorial: https://chenyang.co/diffusion.html
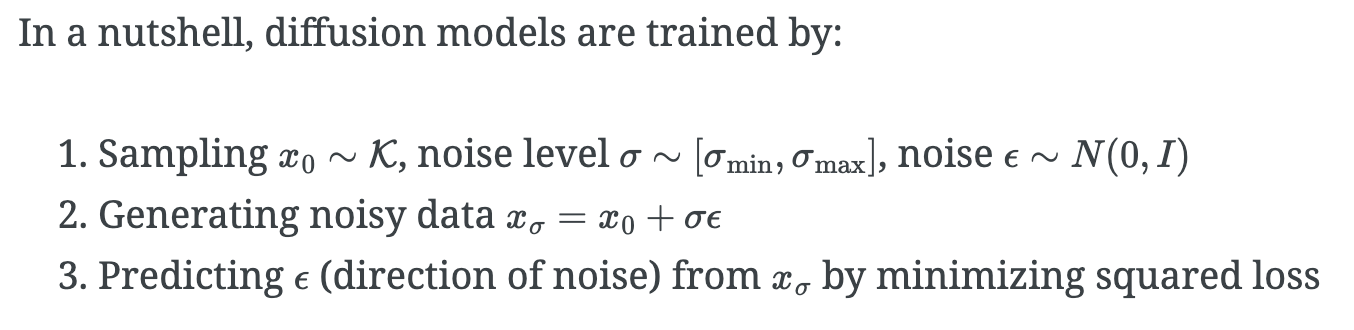
"Diffusion" models
another nice reference:
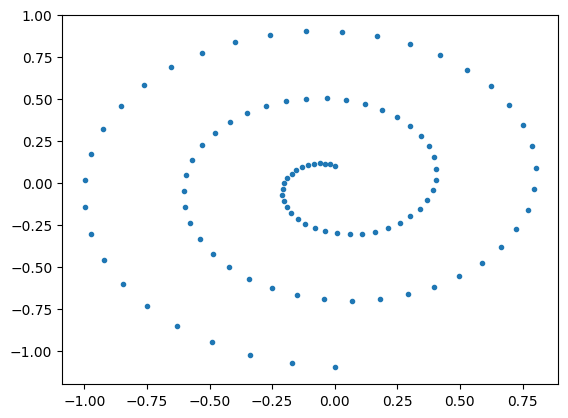
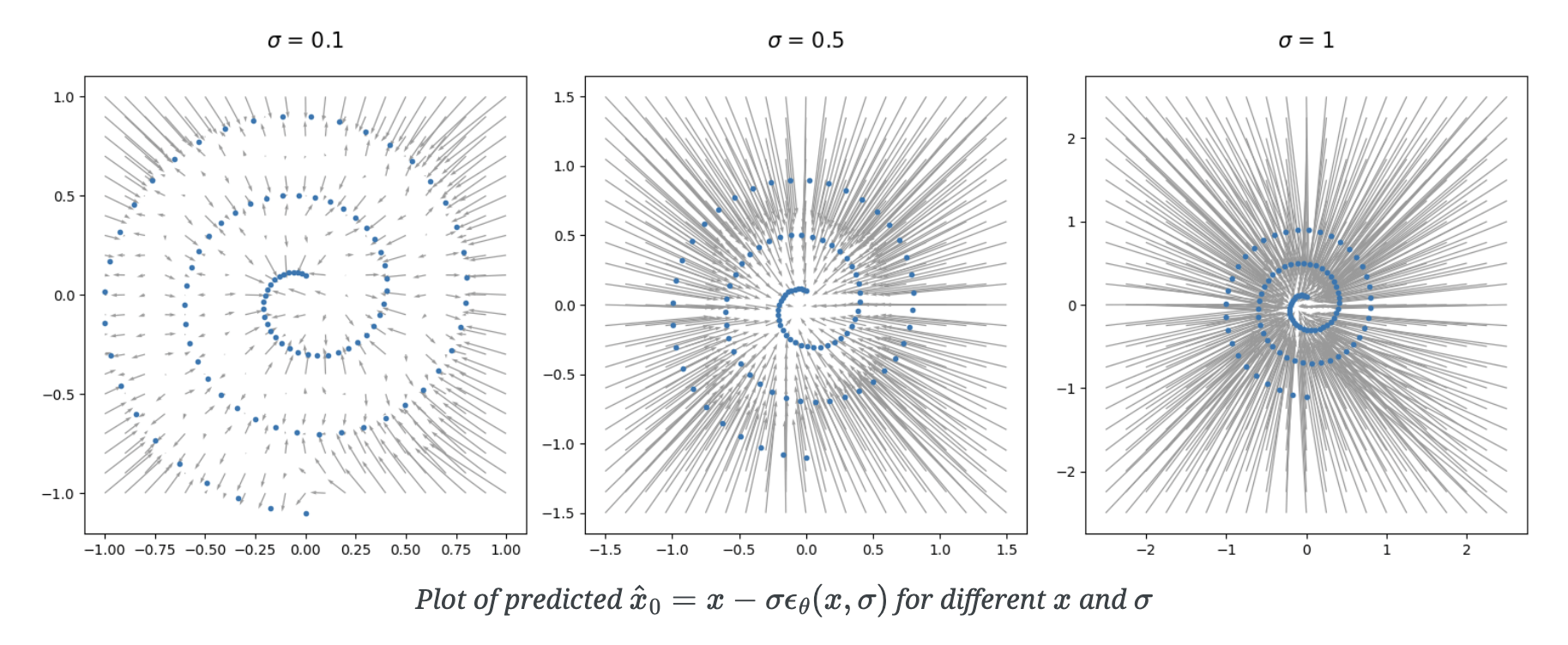
"Diffusion" models: deterministic interpretation
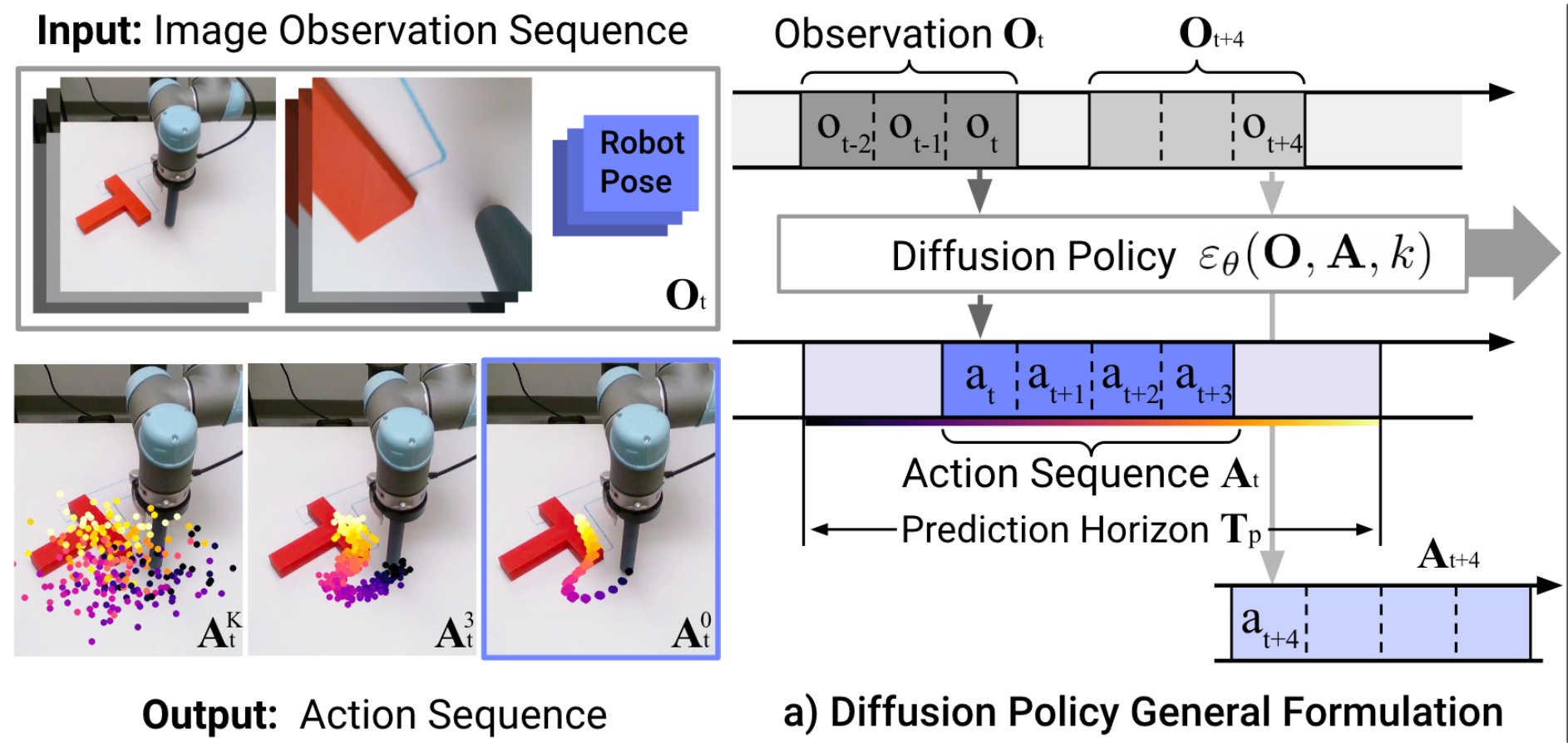
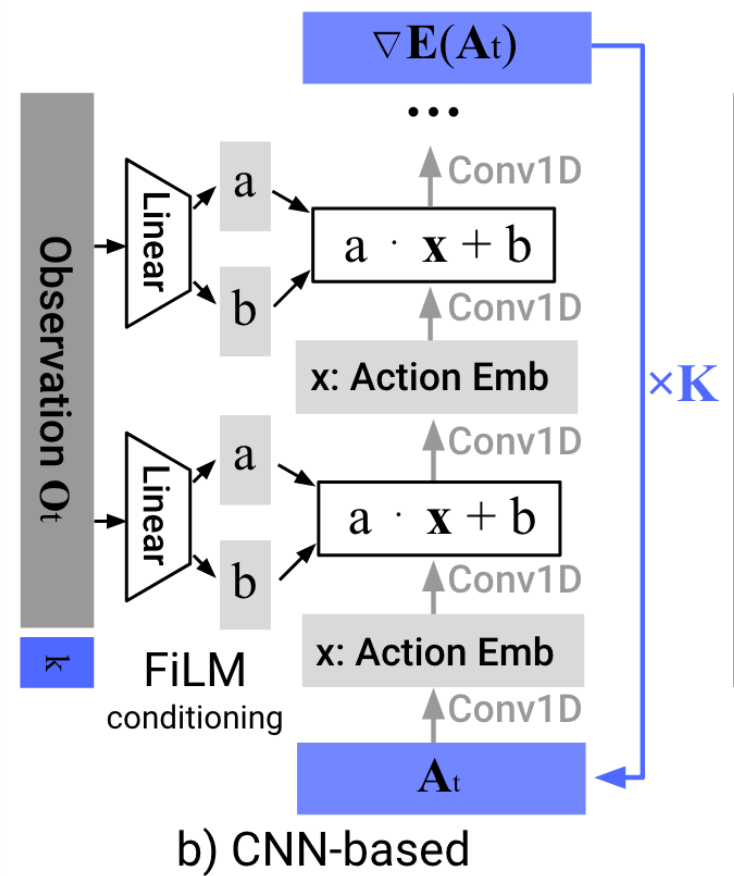
Image backbone: ResNet-18 (pretrained on ImageNet)
Total: 110M-150M Parameters
Training Time: 3-6 GPU Days ($150-$300)
Signs that things are working well...
- Often reactive (e.g. responds robustly to perturbations)
- Long-horizon tasks (multiple seconds, multiple steps)
- Discrete/branching logic.
Discrete/branching logic
Long horizon
Limited "Generalization"
(when training a single skill)
a few more recent skills...
(we've now trained many hundreds)
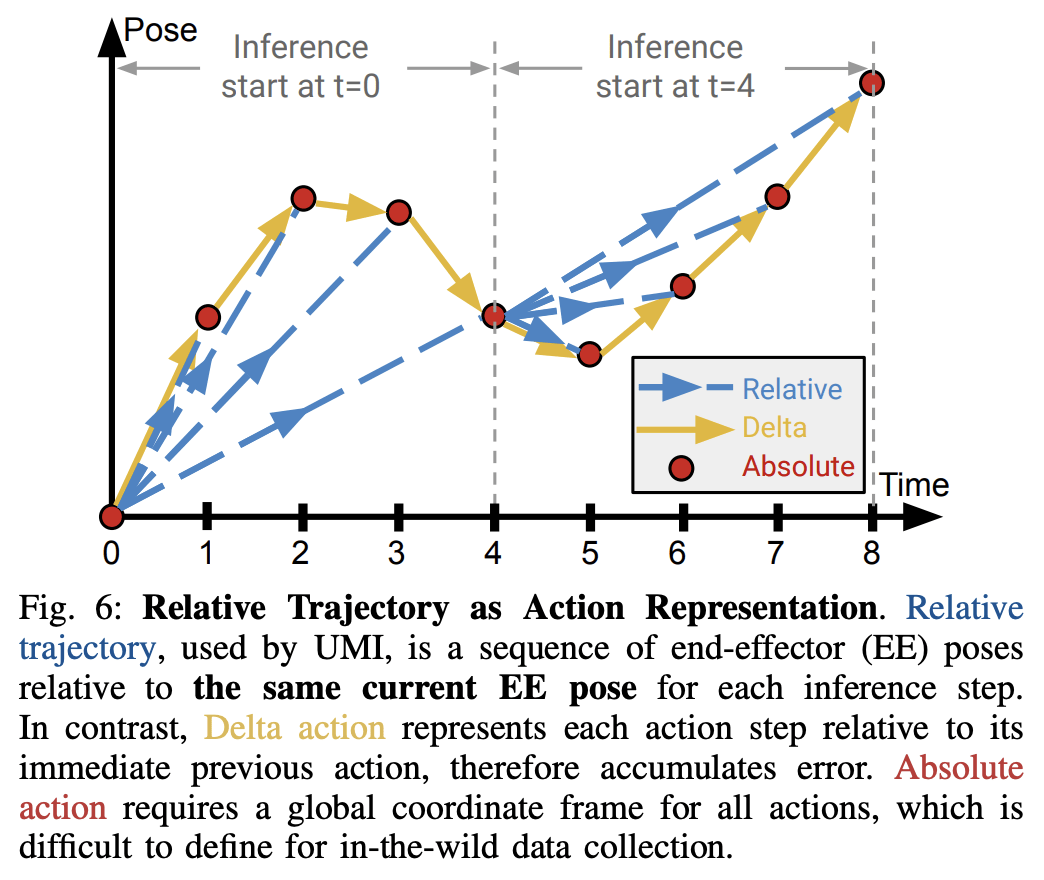
We've switched to relative action parameterizations
interestingly, seems even more important in sim.

The DROID dataset
w/ Chelsea Finn and Sergey Levine
Standard training recipe
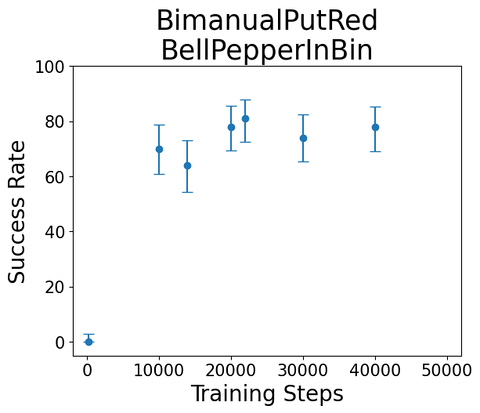
Some fairly typical training curves
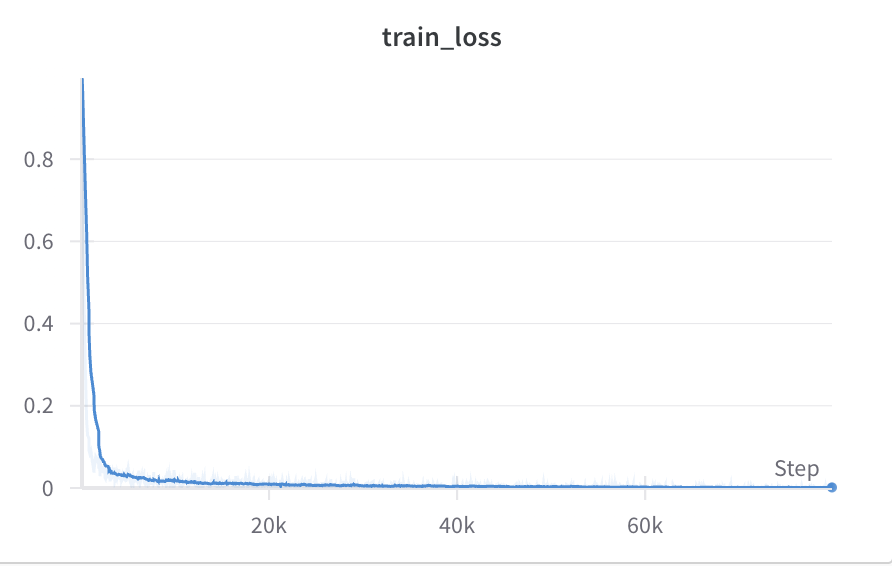
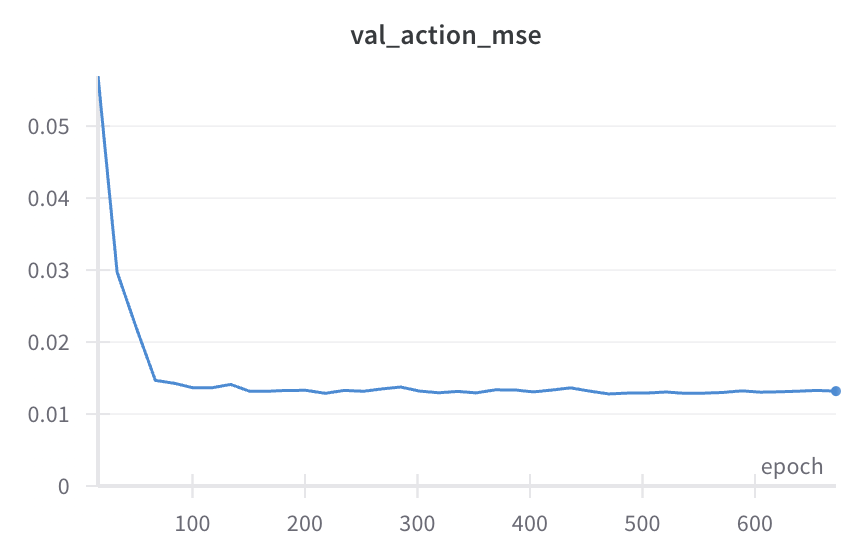
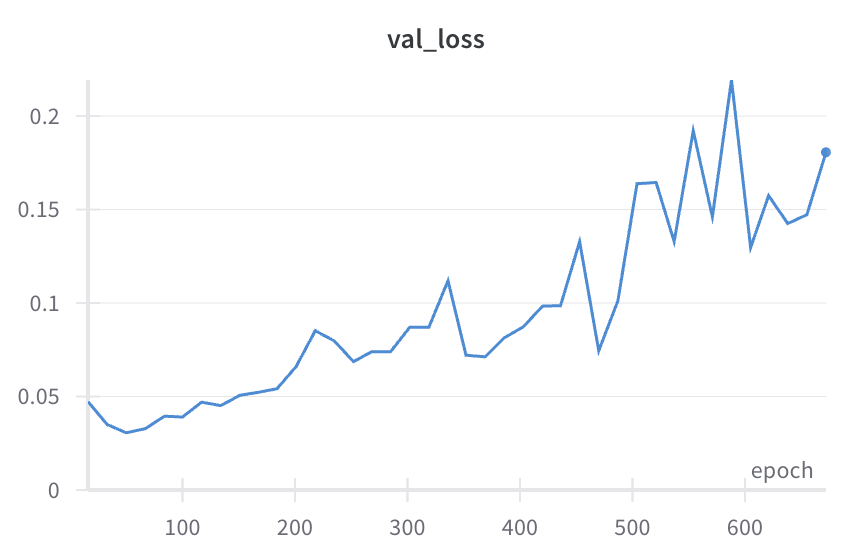
Our standard training recipe (hardware eval)
- Run a fixed number of training steps (80k)
- Take the last checkpoint
- occasionally (hardware) eval the last few checkpoints.
but now that we have sim eval that we trust...
Getting good data (at scale)
TRI's "CAM" data collect

Compared to many datasets, these are long-horizon (often 30 seconds - 1.5 minutes)
Often sequential/multistep
Getting good data ("batch dagger")
- Provide data that helps with robustness ("art, not magic")
- Passive: arrangement, background, view, ...
- Active: interactions, recovery, ...
- Initial data collect: ~100 demonstrations:
- "If you fail... keep going!"
- "Think about some likely failure cases, and demonstrate the recovery"
- Train the policy, test the rollouts
- if we see obvious failures, collect more demonstrations showing recovery.
- Almost never more than 200 total demonstrations
Q: So how many demonstrations do I need to get to 99.99% success rate (\(\Rightarrow\) a useful product)?
My Answer: That's not the question I want to answer.
I want "common sense robustness" (from multitask), then will re-examine.
Things I want to understand better
Things that I'd like to understand better
- Why does val loss go up?
- even val action mse goes up a little
- We're denoising past actions. Why?
- Condition on previous actions (analogy to LQG)
- Transformer-based denoiser never worked as well as expected
- Faster inference
- ...
- then flow matching, equivariance, ...
lbm_eval gives us the tool we needed
Enabling technologies

Haptic Teleop Interface
Excellent system identification / robot control
Visuotactile sensing

with TRI's Soft Bubble Gripper
Open source:
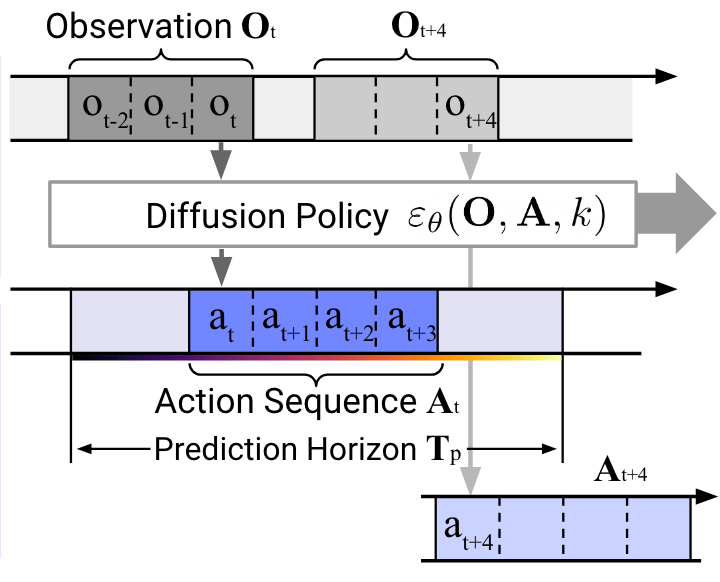
Predicting past actions (why?)
----------------------------------------------------------------------------------------------
(legend: o = n_obs_steps, h = horizon, a = n_action_steps)
|timestep | n-o+1 | n-o+2 | ..... | n | ..... | n+a-1 | n+a | ..... |n-o+1+h|
|observation is used | YES | YES | YES | NO | NO | NO | NO | NO | NO |
|action is generated | YES | YES | YES | YES | YES | YES | YES | YES | YES |
|action is used | NO | NO | NO | YES | YES | YES | NO | NO | NO |
----------------------------------------------------------------------------------------------(that's almost what our code does, too)
nicely documented in lerobot
but it's never really been tested for o > 2