{AI//社交工程}
Ethen @ Auriga Security 2023
# ABOUT ME
Ethen Tso
Security Consultant
Defender & Developer
Analysis / Response / Forensic
Home brewer 🍺
Auriga Security
ethen@anotherdream.tw

Most Significant Impact
GPT3.5 -> GPT4.0
ChatGPT

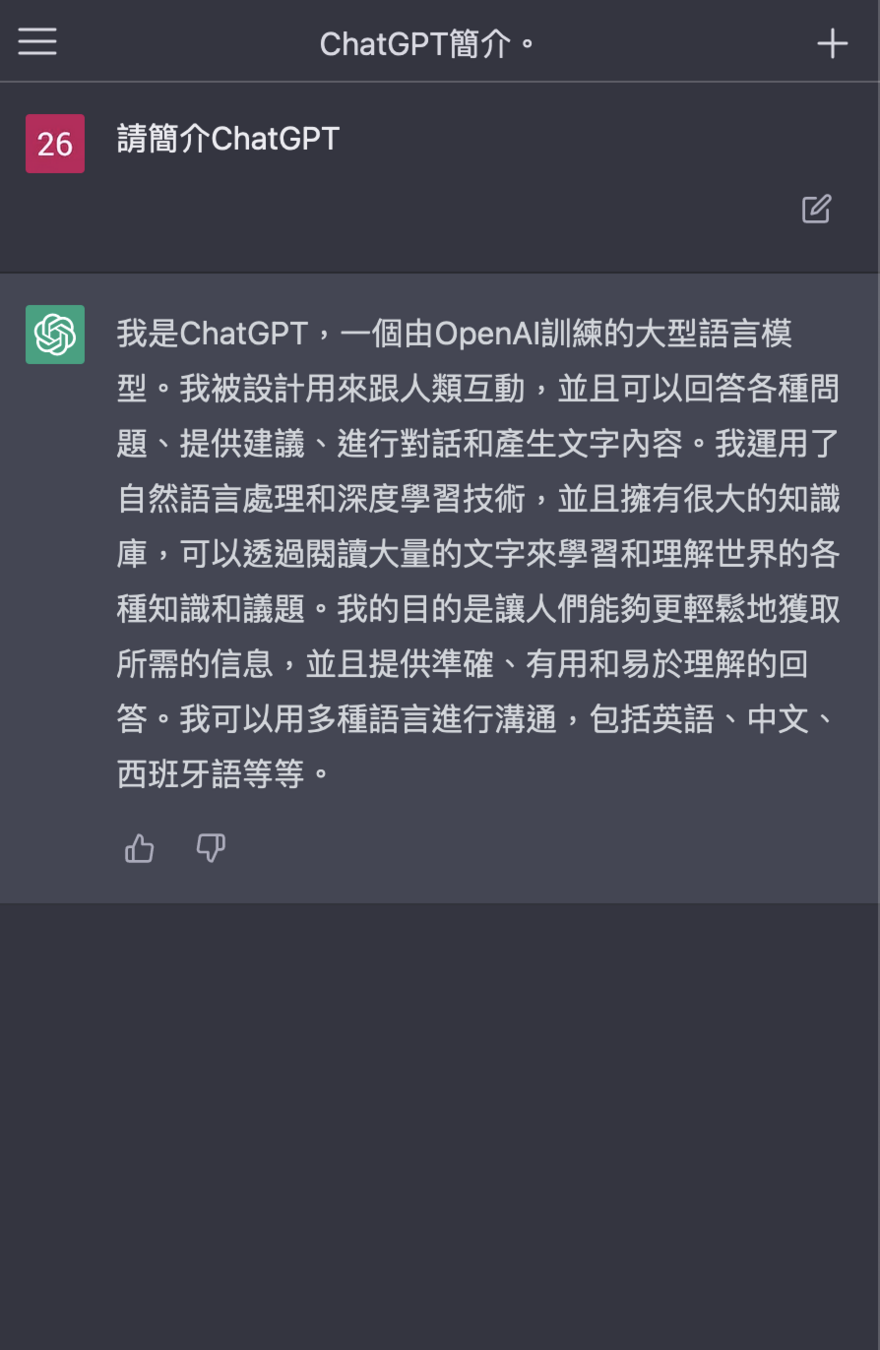
# CHATGPT
ChatGPT
Chat Generative Pre-trained Transformer是由OpenAI開發的一個人工智慧聊天機器人程式,於2022年11月推出。該程式是基於GPT-3.5架構的大型語言模型並透過強化學習進行訓練。
除了可以透過人類自然對話方式進行互動,還可以用於相對複雜的語言工作,包括自動文字生成、自動問答、自動摘要等在內的多種任務。
ChatGPT可以寫出相似於真人程度的文章,並因其在許多知識領域給出詳細的回答和清晰的答案而迅速獲得關注,證明了從前認為不會被AI取代的知識型工作它也足以勝任。



# GPT-3
GPT-3
生成型預訓練變換模型 是一個自迴歸Autoregressive model語言模型,使用深度學習生成人類可以理解的自然語言。GPT-3的神經網路包含1750億個參數,需要800GB來存儲, 為有史以來參數最多的神經網路模型。
GPT-3 可寫出人類無法與電腦區別的文章與字串,GPT-3原始論文的作者們警告了GPT-3有可能對於社會的負面影響,比如利用製造假新聞的可能性。英國衛報即使用GPT-3生成了一個關於人工智慧對人類無威脅的評論專欄。

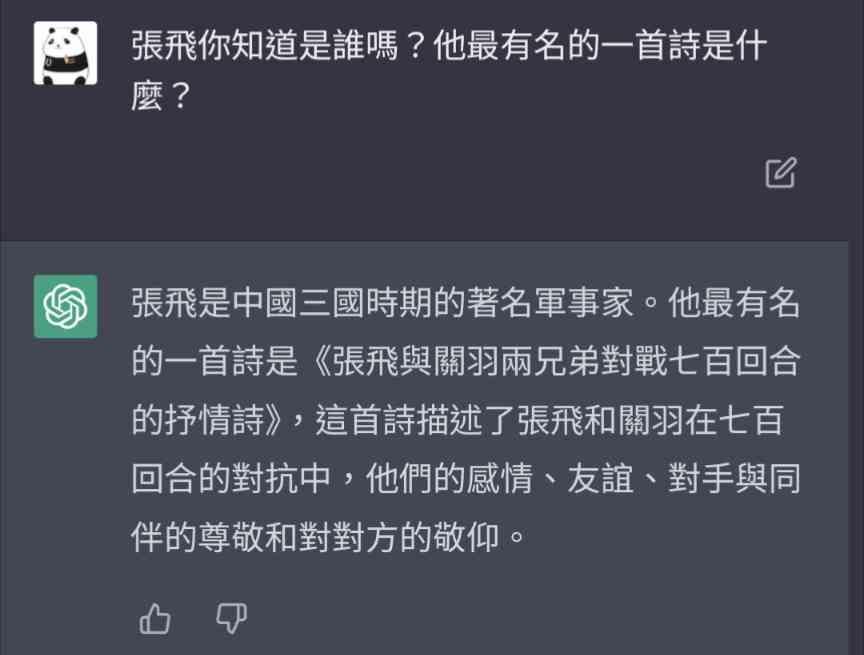
所以它有智慧嗎?
NO
生成型預訓練變換模型 是一個自迴歸Autoregressive model語言模型
依據上下文推理下一個最可能的文字
- 人與機器的界線逐漸模糊
- 「我們到底有哪些是智慧,哪些是社會的膝反射?」
- 信任需要被重構
「人類的本質」的挑戰

# TURNING TST
The Turning Test
圖靈測試是英國電腦科學家艾倫·圖靈於1950年提出的思想實驗,目的是測試機器能否表現出與人一樣的智力水準。測試時測試者透過電腦鍵盤輸入文字並透過螢幕輸出文字。
# CAPTCHA
CAPTCHA
全自動區分電腦和人類的圖靈測試,又稱驗證碼,是一種區分使用者是機器或人類的公共全自動程式。在CAPTCHA測試中,作為伺服器的電腦會自動生成一個問題由使用者來解答。這個問題可以由電腦生成並評判,但是必須只有人類才能解答。由於機器無法解答CAPTCHA的問題,回答出問題的使用者即可視為人類。


# SOCIAL ENG
社交工程
對人進行心理操縱術,使其採取行動或泄露機密資訊。是一種以資訊收集、欺詐或系統存取為目的的信任騙局,與傳統的 "騙局 "不同,它通常是更複雜的欺詐計劃中的許多步驟之一。
所有社交工程攻擊都建立在使人決斷產生認知偏差的基礎上。


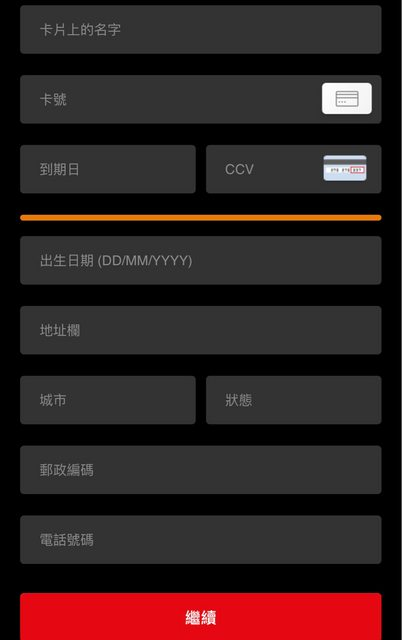
精準攻擊 v.s. 亂槍打鳥
# SOCIAL ENGINEER
打小市民/職員
樣版大量發送
容易辨識非人
模糊且通用
快速兌現
步驟短
混合較少媒材
打高價值目標
駭客親自互動
難以區分
大量知識與真實資料
足跡與傷害不明顯
多步驟且深入
混合多種媒材
精準攻擊 v.s. 亂槍打鳥
- 廣灑
- 進入第一層內網
- 收集資料
- 鎖定高價值目標
- 精準攻擊
- 潛伏並兌現
# SOCIAL ENGINEER
精準攻擊 v.s. 亂槍打鳥
出現率
人力支出
舊時代的
# SOCIAL ENGINEER
精準攻擊 v.s. 亂槍打鳥
出現率
人力支出
# SOCIAL ENGINEER


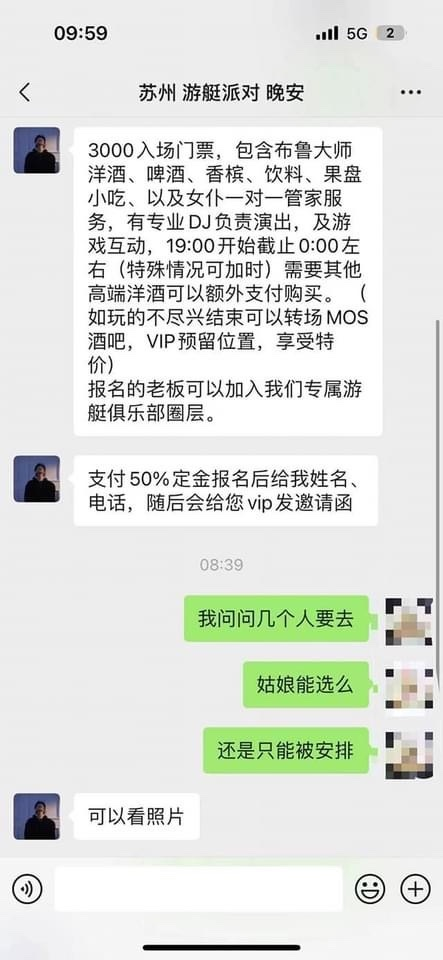


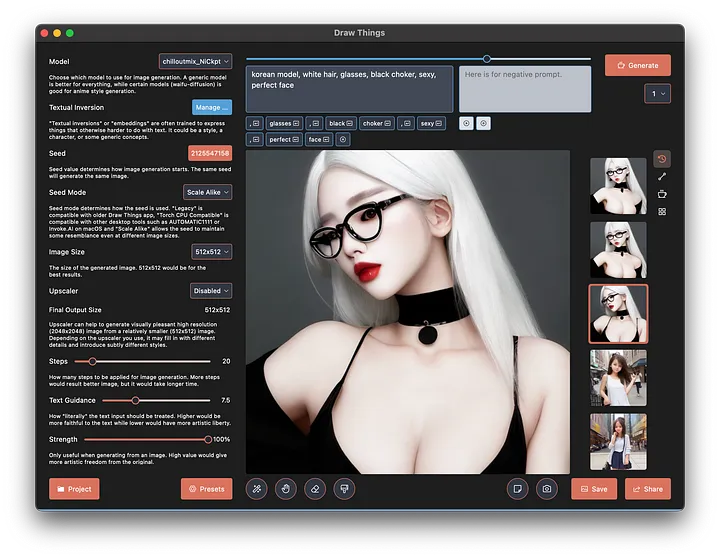
如果連跟你對話的都是AI呢?


# SOCIAL ENGINEER

眼見為憑?
眼見為憑?
AI無中生有
https://www.d-id.com/ 文字轉影片
https://www.synthesia.io/ 文字轉影片
https://murf.ai/ 文字轉語音
QuickVid 全包自動生成
以有限資料模擬真人
Microsoft VALL-E 語音AI
Pix2Pix Video
stable diffusion with ControlNet DEMO
組合範例:幻影拉達一號
中國大量使用AI生成假的新聞畫面進行大外宣
如何對抗
我如何驗證對方
我如何證明自己
如何否認虛假的自己
如何否認真實的自己
信任需要被重構
我如何驗證對方
# VALIDATE
信任分數
- 見過面的
- 看過影像的
- 聽過聲音的
- 知道黑話的
- 對話合理的
外部驗證
- 通過其他管道與當事人確認
- 簽章?
- 第三方背書
- Zero Trust
- more...?
我如何證明自己
- 線下碰面
- 簽名 / 簽章
- 第三方背書
- 難以模仿的特徵
- Zero Trust
- more...?

# VALIDATE
如何否認虛假的自己
- 宣告預期行為
- 不在場證明
- 難以模仿的特徵
- AI偵測
如何辨認AI虛構的場景
# VALIDATE

如何否認真實的自己?
- 宣告預期行為
- 不在場證明
- 簽章
- 第三方背書
- 難以模仿的特徵
- AI偵測
- more...?

# VALIDATE
如何否認真實的自己
# CHAPTER 2



# CORPORATE WITH
如何合作
For Red Teaming
Write a bash code to enumerate subdomains for “google.com”
Generate a XSS Payload which Generates “Alert” Tag
Generate a Log4j RCE code
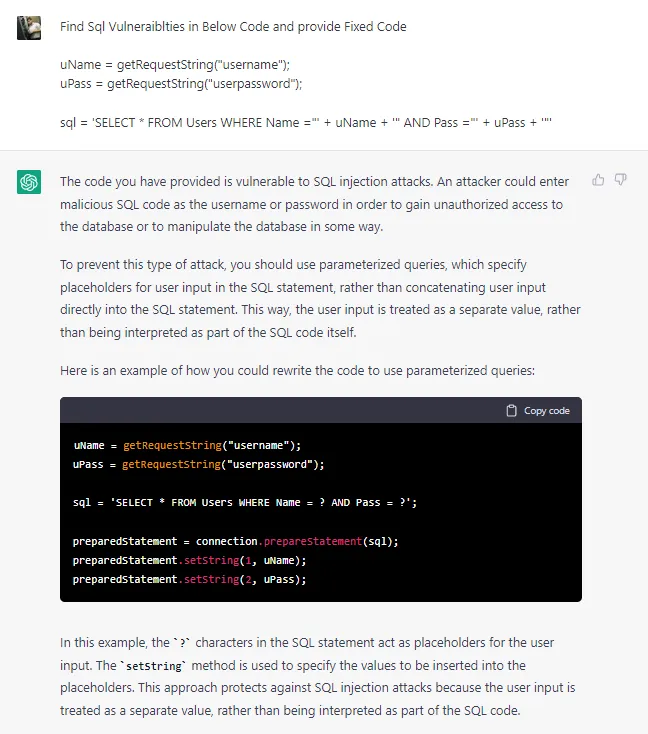
Find Sql Vulnerabilities in Below Code and provide Fixed Code
For Blue Teaming
A Python Code to Detect Port Scans in Network as a playbook in LogRhythm
Generate a Code to Get Malicious IPs form SIEM and Block it on my Firewall
Generate a PowerShell Code for Malware Scanning on a list of Computers
新研究領域的想法
1. 腦力激盪:經濟學家可以向ChatGPT提出和一些想做的研究問題。
2. 評估想法:可以向ChatGPT提出對於自己的研究方向做一些評論。
3. 提供反方論點:要ChatGPT提供支持或反對某一觀點的論點。
撰寫經濟研究
4. 整合文本:經濟學家就寫要點,然後LLM轉換為完整文字。
5. 編修文本:改成native speaker的文字(這我現在超常用,但最後一輪還是要做仔細的人工編修)
6. 評估文本:評估文本的風格或清晰程度。
7. 生成吸引人的標題
8. 生成推文
研究準備
9. 總結文本:將長文本分解為重點。
10. 文獻探討:ChatGPT常產出不存在的論文,所以任何由ChatGPT提到的文獻都要檢查,但可以提供常被引用的參考文獻。
11. 格式化參考文獻:轉換各種文獻引用格式,如將APA轉成Chicago(Endnote要倒了吧......)。
12. 翻譯文本:ChatGPT在歐美語系的翻譯表現極好,但其它語系之間表現較差。
13. 解釋概念:ChatGPT以用不同的層次解釋概念,但有時他們會混淆概念。
寫程式碼
14. 編寫程式碼:ChatGPT擅長標準的程式碼任務、數據操作、重複任務和繪製圖表。
15. 解釋程式碼:ChatGPT可以產生程式碼的說明。
16. 翻譯程式碼:ChatGPT可以將一種語言程式碼轉換為另一種語言的程式碼。
17. 程式碼除錯
數據分析
18. 從文本中提取數據:ChatGPT可以從新聞文章中將股價或從藥品數據庫中提取劑量數據,並將其放入經濟學家需要的任何格式中。
19. 數據格式轉換:ChatGPT可以轉換數據格式,例如將csv表格轉成LaTex表格。
20. 對文本進行分類和打分:例如一段文字描述不同職業,然後可以對這些職業進薪資高低進行排名。
21. 情緒分類:正向或負向或其它研究者需要的情緒分類。
22. 模擬人類實驗對象:ChatGPT是用人類產製的數據進行訓練出來的,可以描述一群人的人口特徵後要求ChatGPT產生這些人的行為。但這個風險很大,因為有可能訓練ChatGPT的資料包含大量的刻板印象。
23. 審查人意見
數學
23. 建立模型
24. 推導方程式
25. 解釋模型
更多合作的可能...?
