FAIR Research Software
Why FAIR?
Findable
Accessible
Interoperable
Reusable
"Data available
upon request"
"Data available
upon reasonable request"
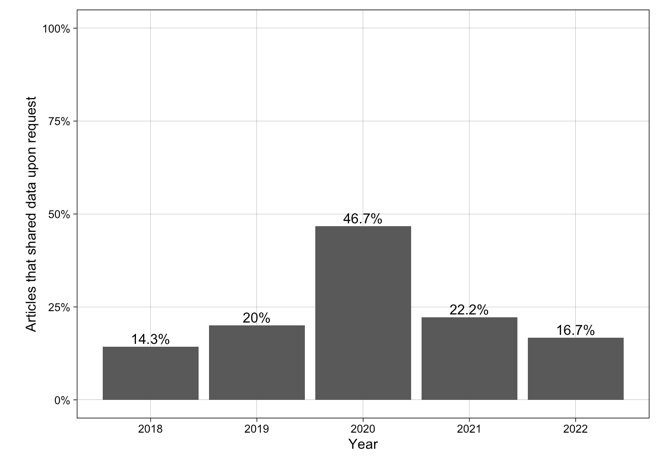
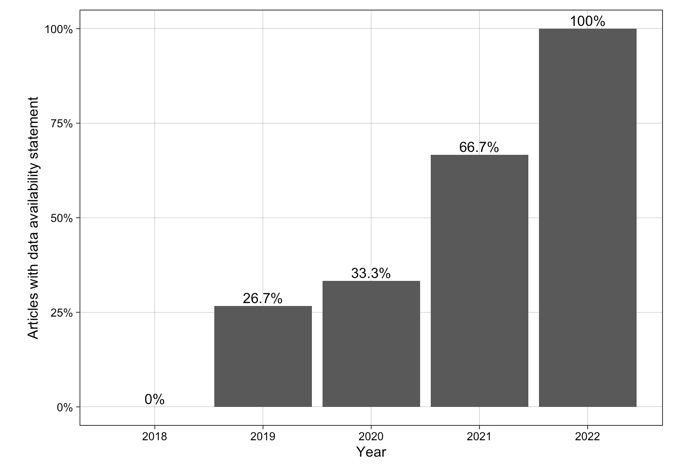
Hussey, 2023
Web Plot Digitiser, 2024
Data Unavailability
- No structures to enable it
- No documentation
- Effort/reward is just not worth it
- Complex ownership
- 'Protecting' future papers/avoiding scoops
- Commercialisation
- Quality is shaky
- Churn
Data Quality
- Highly bespoke formats
- Not machine-readable
- No incentives for quality
- No training on what good data looks like
- No standards to follow
Problems
- Replication crisis
- Reliability
- Duplicated effort
s/Data/Code/g
Letter to the Editor: Comment on Editorial on Software Distribution in Science, John Figueras


Defining
FAIR4RS
Good enough practises in scientific computing, Wilson 2017
https://doi.org/10.1371/journal.pcbi.1005510
Findable: (Meta)data should be easy to find for both humans and computers
Accessible: Once the user finds the required data, they need to know how they can be accessed, including authentication and authorisation
Interoperable: (Meta)data needs to be interoperable with applications or workflows for analysis, storage, and processing
Reusable: (Meta)data should be well-described so it can be replicated and/or combined in different settings
Findable: Software and its metadata are easily human- and machine-findable
Accessible: Software and its metadata can be accessed via standard protocols
Interoperable: Software must exchange (meta)data using APIs described by standards
Reusable: Software can be run, and can be understood, modified and extended
Findable
Un-Findable
- Software lives on a researcher's computer
- Software is 'available upon request'
- Old versions are almost certainly not available
- Software either has:
- No name (
analyse_pt1234.py) - A name that is a backronym or 'fancy'-sounding word
- No name (
- The only way to know it exists is to read the paper
Findable
- Has a globally unique persistent identifier
- Components with different levels of granularity have their own identifiers
- Different versions have their own identifiers
- Described by rich metadata
- Metadata identifies the software it describes
- Metadata is FAIR, searchable, and indexable
Software, and its associated metadata, is easy for both humans and machines to find
Findable
- Hosted on GitHub/Lab/domain-specific stable repo / has a DOI from Zenodo
Has a globally unique persistent identifier- Components with different levels of granularity have their own identifiers (?)
- Uses VC / has versioned DOIs from Zenodo
Different versions have their own identifiers
- Has commit messages, documentation
Described by rich metadata - Includes the repo / DOI in the documentation and
citation.cfffile
Metadata identifies the software it describes - Has a
citation.cff/codemeta.jsonfile / on a software registry
Metadata is FAIR, searchable, and indexable
Aside on Metadata
Checklist vs Process
Accessible
In-Accessible
- Software is 'available upon request' by email
- ...to which corresponding author may not
- Software is hosted on a website hand-written by a postdoc who left 5 years ago and is full of dead links
Accessible
- Software is retrievable by its identifier using a standardised communications protocol
- The protocol is open, free, and univerally implementable
- The protocol allows for authentication where necessary
- Metadata is accessible even when the software is no longer available
Software, and its metadata, is retrievable via standardised protocols
Accessible
- Hosted on GitHub/Lab/domain-specific stable repo / has a DOI from Zenodo
Software is retrievable by its identifier using a standardised communications protocol- The protocol is open, free, and univerally implementable
- The protocol allows for authentication where necessary
-
See above
Metadata is accessible even when the software is no longer available
- Open-source unless barred by medical confidentiality, collaboration agreements with industry or realistic, imminent commercialisation
Interoperable
Non-Interoperable
- Software reads/writes entirely bespoke data files
- Or just writes casually-formatted text to
stdout
- Or just writes casually-formatted text to
- Has owns implementations of common functionality
- These are not designed as APIs and/or have horrible internal state dependency that makes them impossible to treat as one
- Precisely what it does is not documented
- Chaining together tools involves shell scripts full of indecipherable regex
- Those shells scripts are not documented
Interoperable
- Software reads, writes and exchanges data in a way that meets domain-relevant community standards
- Software includes qualified references to other objects
Software interoperates with other software by exchanging data and/or metadata, and/or through interaction via applicationprogramming interfaces (APIs), described through standards.
Interoperable
- Search for domain-specific standard formats and use them if they exist. If they don't, use something structured and standardised - YAML? JSON? Parquet? HDF5?
Software reads, writes and exchanges data in a way that meets domain-relevant community standards- Document the input and output formats, units e.t.c.
- Ideally include metadata within those outputs
- Reference and link to the libraries and formats you use
Software includes qualified references to other objects
Reuseable
Non-Reusable
- No instructions/instructions passed down as oral tradition within community
- No license or ownership, so no clear way to use it as the base for future work
- Incredibly fragile and only does the one thing the paper it was written for is about
- Can only be run on the authors machine because of complex, undocumented dependencies
- Esoteric/unique behaviour
Reusable
- Software is described with a plurality of accurate and relevant attributes
- Software is given a clear and accessible license
- Software is associated with a detailed provenance
- Software includes qualified references to other software
- Software meets domain-relevant community standards
Software is both usable (can be executed) and reusable (can be understood, modified, built upon, or incorporated into other
software)
Reusable
- Document how to install and use the software, the API & code itself. Also, make sure the functionality matches the papers
Software is described with a plurality of accurate and relevant attributes- Add a
license.md
Software is given a clear and accessible license - Add a citation.cff file, and have a version-controlled history of development
Software is associated with a detailed provenance
- Add a
- List dependencies, standardised if possible (e.g.
requirements.txt)
Software includes qualified references to other software - Make sure it behaves in a way that's comprehensible - don't redefine terms or behaviour
Software meets domain-relevant community standards