Stochastic Dynamics and Filtering
ML in Feedback Sys #8
Fall 2025, Prof Sarah Dean
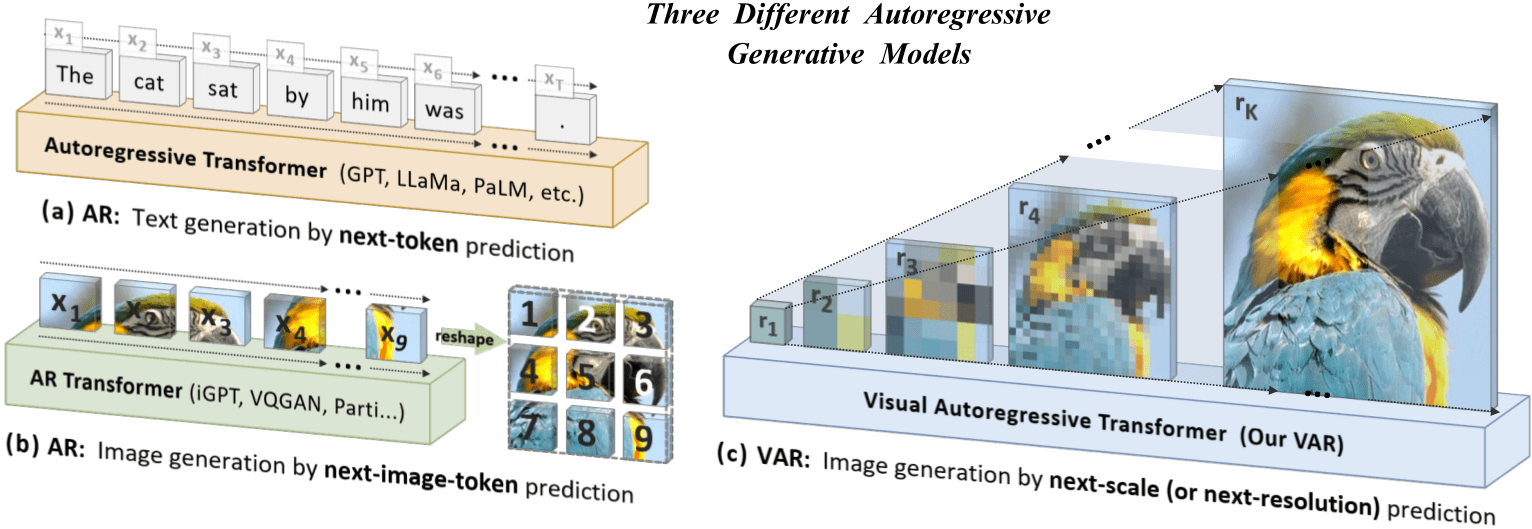
Linear auto-regression
"What we do"
- Train a model of the form (via least squares) $$\hat y_{t+1} = \hat\Theta^\top \hat{\bar y}_{t:t-L+1} = \sum_{\ell=0}^{L-1} \hat \Theta_{\ell+1}^\top \hat y_{t-\ell} $$
"Why we do it"
-
Last lecture: AR of length \(L\) is equivalent to deterministic LDS with state dimension \(L\)
-
This lecture: AR of length \(L=O(\log(1/\epsilon))\) can \(\epsilon\) approximate optimal prediction for stochastic LDS
$$ s_{t+1} = F s_t + w_t,\quad y_t = Hs_t + v_t$$
Kalman filter
"What we do"
- Given dynamics matrices \(F\in\mathbb R^{d_s\times d_s}\) and \(H\in\mathbb R^{d_y\times d_s}\), noise covariance matrices \(\Sigma_w\) and \(\Sigma_v\), streaming observations \(y_t\)
- Representing a stochastic, partially observed linear dynamical system $$ s_{t+1} = F s_t + w_t,\quad y_t = Hs_t + v_t$$
- Using observations at time \(t\), \(y_{0:t}\) we $$\hat s_{t\mid t}\quad\text{and} \quad \hat y_{t\mid t} = H\hat s_{t\mid t}$$
- More generally, we can write \(\hat s_{k\mid t}\) our guess of \(s_k\) given observations up to time \(t\)

Kalman filter
"What we do"
- Given dynamics matrices \(F\in\mathbb R^{d_s\times d_s}\) and \(H\in\mathbb R^{d_y\times d_s}\), noise covariance matrices \(\Sigma_w\) and \(\Sigma_v\), streaming observations \(y_t\)
- Initialize \(\hat s_{-1|-1} = 0\) and \(P_{-1|-1} = 0\)
- For \(t=0,1,...\)
- Extrapolate state \(\hat s_{t\mid t-1} =F\hat s_{t-1\mid t-1} \)
- Extrapolate Info matrix \(P_{t\mid t-1} = FP_{t-1\mid t-1} F^\top + \Sigma_w\)
- Compute gain \(L_{t} = P_{t\mid t-1}H^\top ( HP_{t\mid t-1} H^\top+\Sigma_v)^{-1}\)
- Update state \(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-H\hat s_{t\mid t-1})\)
- Update Info matrix \(P_{t\mid t} = (I - L_{t}H)P_{t\mid t-1}\)
Kalman filter
"Why we do it"
-
Fact 1: if \(w_k\) and \(v_k\) are Gaussian random variables, then the Kalman filter computes the posterior distribution of the latent state $$P(s_t | y_0,...,y_t) =\mathcal N(\hat s_{t|t}, P_{t|t})$$
-
Fact 2: the Kalman filter solves the following weighted least squares problem online $$\min_{{s_0, ..., s_t}} ~~~\sum_{k=0}^t \|\Sigma_v^{-1/2}(H{s_k}-y_k)\|_2^2+ \|\Sigma_w^{-1/2}(F{s_k-s_{k+1}})\|_2^2+ \|{s_0}\|_2^2 $$
-
Fact 3: A linear autoregressive model of length \(L=O(\log(1/\epsilon))\) can \(\epsilon\) approximate the Kalman filter's estimates
$$ s_{t+1} = F s_t + w_t,\quad y_t = Hs_t + v_t$$
Stochastic linear systems
- Consider linear state space models with process noise and measurement noise $$s_{t+1} = Fs_t+ w_t,\quad y_t = Hs_t+v_t$$
- Equivalent linear output model $$ y_t = \Phi(t+1)s_0+ \sum_{k=1}^t \Phi(k) w_{t-k}+v_t$$
- Suppose means \(\mu_w,\mu_v\) and covariances, \(\Sigma_w, \Sigma_v\), then:
-
\(\mathbb E[y_t] = \sum_{k=0}^{t}HF^{k}\mu_w + \mu_v\)
-
\(\mathrm{Cov}[y_t] = \sum_{k=0}^{t}HF^{k}\Sigma_w(F^{k})^\top H^\top + \Sigma_v\)
-
-
For Gaussian noise, mean and covariance characterizes the entire (prior) distribution on outputs (similar expression for states)
-
Converges to a steady state distribution as \(t\to\infty\) if \(F\) is stable
\(\displaystyle y_{t} = HF^t s_0+ \sum_{k=1}^{t}HF^{k-1}w_{t-k}+v_t\)
-
Fact 1: if \(w_k\) and \(v_k\) are Gaussian random variables, then the Kalman filter computes the posterior distribution of the latent state $$P(s_t | y_0,...,y_t) =\mathcal N(\hat s_{t|t}, P_{t|t})$$
-
Consider a single KF update
-
At time \(t\) we have \(P(s_t|y_{t-1},...) = \mathcal N(\hat s_{t\mid t-1} ,P_{t\mid t-1} )\) given by the Extrapolate step
- The measurement likelihood \(P(y_t|s_t) =\mathcal N(Hs_t, \Sigma_v)\)
- Bayes rule \(P(s_t|y_t, ...)\propto P(y_t|s_t)P(s_t|y_{t-1},...)\) is equivalent to the Update step
-
-
As a result, the state estimated by the Kalman filter is statistically optimal as it is both the Minimum Variance Unbiased Estimator and the Maximum Likelihood Estimator
Posterior distribution
Recall the least square optimization $$ \min_{\textcolor{yellow}{\theta}} \sum_{k=0}^t (y_t - \textcolor{yellow}{\theta^\top} x_t )^2 $$
Optimal least squares filtering
\(y_0 = \textcolor{yellow}{\theta^\top} x_0 + \textcolor{yellow}{v_0}\)
\(\vdots\)
\(y_t = \textcolor{yellow}{\theta^\top} x_t + \textcolor{yellow}{v_t}\)
$$ \min_{\textcolor{yellow}{\theta, v_k}} \sum_{k=0}^t \textcolor{yellow}{v_k}^2 $$
s.t.
Equivalent to minimizing the squared residuals of a linear model
\(\hat\theta = \left(\sum_{k=0}^tx_kx_k^\top\right)^{-1}\sum_{k=0}^t x_k y_k\)
We can also understand the KF as solving a specific (familiar) optimization problem
Recall the least square optimization $$ \min_{\textcolor{yellow}{\theta}} \sum_{k=0}^t (y_t - \textcolor{yellow}{\theta^\top} x_t )^2 $$
Optimal least squares filtering
Equivalent to minimizing the squared residuals of a linear model
We can also understand the KF as solving a specific (familiar) optimization problem
$$ \min_{\textcolor{yellow}{\theta, v_k}} \sum_{k=0}^t \textcolor{yellow}{v_k}^2 $$
s.t.
\(\hat\theta = \left(X^\top X\right)^{-1}X^\top Y\)
$$\underbrace{\begin{bmatrix} y_0 \\ \vdots \\ y_t \end{bmatrix} }_Y= \underbrace{ \begin{bmatrix} x_0^\top\\ \vdots \\ x_t^\top \end{bmatrix} }_{X}\textcolor{yellow}{\theta} + \textcolor{yellow}{\begin{bmatrix} v_0\\ \vdots \\ v_t\end{bmatrix}}$$
At time \(t\), due to our observations, measurement model, and dynamics model:
Estimation via least squares
- \(y_0=H \)\(s_0\) \( + \) \(v_0\)
- \(s_1 \) \(= F\)\(s_0\) \( + \) \(w_0\)
- \(y_1=H \)\(s_1\) \( + \) \(v_1\)
- \(s_t \) \(= F\)\(s_{t-1}\) \( + \) \(w_{t-1}\)
- \(y_t=H\)\(s_t\) \( + \) \(v_t\)
\(\vdots\)
Our least-square estimation problem is*
$$\min_{\textcolor{yellow}{s}} ~~~\sum_{k=0}^t \|H\textcolor{yellow}{s_k}-y_k\|_2^2+ \|F\textcolor{yellow}{s_k-s_{k+1}}\|_2^2+ \|\textcolor{yellow}{s_0}\|_2^2 $$
*for simplicity for the rest of lecture, let \(\Sigma_w=I\) and \(\Sigma_v=I\)
- \(y_0=H \)\(s_0\) \( + \) \(v_0\)
- \(0= F\)\(s_0-s_1\) \( + \) \(w_0\)
- \(y_1=H \)\(s_1\) \( + \) \(v_1\)
- \(0= F\)\(s_{t-1}-s_t\) \( + \) \(w_{t-1}\)
- \(y_t=H \)\(s_t\) \( + \) \(v_t\)
\(\vdots\)
At time \(t\), due to our observations, measurement model, and dynamics model:
Estimation via least squares
$$\begin{bmatrix} y_0 \\ 0 \\ y_1 \\ \vdots \\ 0 \\ y_t \end{bmatrix} = \begin{bmatrix} H\\ F-I \\ &H\\ & F-I \\ &&\ddots \\ &&&H \end{bmatrix} \textcolor{yellow}{\begin{bmatrix}s_0\\ s_1 \\ \vdots \\ s_t \end{bmatrix}} + \textcolor{yellow}{\begin{bmatrix} v_0\\ w_0\\ v_1 \\ \vdots \\ w_{t-1} \\ v_t\end{bmatrix}}$$
At time \(t\), due to our observations, measurement model, and dynamics model:
Estimation via least squares
The least squares estimator minimizes the squared residual
$$\text{s.t.}~~~\begin{bmatrix} y_0 \\ 0 \\ y_1 \\ \vdots \\ 0 \\ y_t \end{bmatrix} = \underbrace{\begin{bmatrix} H\\ F&-I \\ &H \\ & F&-I \\ &&\ddots \\ &&&H\end{bmatrix}}_{A} \textcolor{yellow}{\begin{bmatrix}s_0\\ s_1 \\ \vdots \\ s_t \end{bmatrix}} + \textcolor{yellow}{\begin{bmatrix} v_0\\ w_0\\ v_1 \\ \vdots \\ w_{t-1} \\ v_t\end{bmatrix}}$$
$$\min_{\textcolor{yellow}{s,v,w}} ~~~\sum_{k=0}^{t-1} \textcolor{yellow}{\|w_k\|_2^2 + \|v_k\|^2 + \|v_t\|^2+\|s_0\|_2^2} $$
This is equivalent to the optimization problem $$\min_{\textcolor{yellow}{s}} ~~~\sum_{k=0}^t \|H\textcolor{yellow}{s_k}-y_k\|_2^2+ \|F\textcolor{yellow}{s_k-s_{k+1}}\|_2^2+ \|\textcolor{yellow}{s_0}\|_2^2 $$
Estimation via least squares
The least squares estimator minimizes the squared residual
$$\text{s.t.}~~~\begin{bmatrix} y_0 \\ 0 \\ y_1 \\ \vdots \\ 0 \\ y_t \end{bmatrix} = \underbrace{\begin{bmatrix} H\\ F&-I \\ &H \\ & F&-I \\ &&\ddots \\ &&&H\end{bmatrix}}_{A} \textcolor{yellow}{\begin{bmatrix}s_0\\ s_1 \\ \vdots \\ s_t \end{bmatrix}} + \textcolor{yellow}{\begin{bmatrix} v_0\\ w_0\\ v_1 \\ \vdots \\ w_{t-1} \\ v_t\end{bmatrix}}$$
$$\min_{\textcolor{yellow}{s,v,w}} ~~~\sum_{k=0}^{t-1} \textcolor{yellow}{\|w_k\|_2^2 + \|v_k\|^2 + \|v_t\|^2+\|s_0\|_2^2} $$
Estimation via least squares
$$ \begin{bmatrix}\hat s_{0\mid t}\\ \hat s_{1\mid t} \\ \vdots \\ \hat s_{t\mid t} \end{bmatrix} = (A^\top A)^{-1} A^\top \begin{bmatrix} y_0 \\ 0 \\ y_1 \\ \vdots \\ 0 \\ y_t \end{bmatrix}$$
Fact 2: the Kalman filter efficiently solves the above least squares problem online, i.e. \(\hat s_{t|t}\) exactly coincides with the solution above
(see extra slides below)
Online estimation
$$ \begin{bmatrix}\hat s_{0\mid t}\\ \hat s_{1\mid t} \\ \vdots \\ \hat s_{t\mid t} \end{bmatrix} = (A^\top A)^{-1} A^\top \begin{bmatrix} y_0 \\ 0 \\ y_1 \\ \vdots \\ 0 \\ y_t \end{bmatrix}$$
$$\begin{bmatrix}\hat s_{0\mid t}\\ \hat s_{1\mid t} \\ \vdots \\ \hat s_{t\mid t} \end{bmatrix} =\begin{bmatrix}H^\top H + F^\top F & -F^\top \\ -F& H^\top H+F^\top F + I & -F^\top \\ & -F & \ddots & \\ &&& H^\top H+I\end{bmatrix}^{-1}\begin{bmatrix}H^\top y_0 \\ \vdots \\ H^\top y_t \end{bmatrix} $$
Block tri-diagonal matrix inverse
$$\begin{bmatrix}\hat s_{0\mid t}\\ \hat s_{1\mid t} \\ \vdots \\ \hat s_{t\mid t} \end{bmatrix} =\begin{bmatrix}D_1 & -F^\top \\ -F &D_2 & -F^\top \\ & -F & \ddots & \\ &&&D_3\end{bmatrix}^{-1}\begin{bmatrix}H^\top y_0 \\ \vdots \\ H^\top y_t \end{bmatrix} $$
Online estimation
$$\textcolor{yellow}{\begin{bmatrix}\hat s_{0\mid t+1}\\ \hat s_{1\mid t+1} \\ \vdots \\ \hat s_{t\mid t+1} \\ \hat s_{t+1\mid t+1} \end{bmatrix}} =\begin{bmatrix}D_1 & -F^\top \\ -F& D_2 & -F^\top \\ & -F & \ddots & \\ &&& D_3+\textcolor{yellow}{F^\top F} & \textcolor{yellow}{-F^\top}\\ &&& \textcolor{yellow}{-F} &\textcolor{yellow}{ H^\top H + I}\end{bmatrix}^{-1}\begin{bmatrix}H^\top y_0 \\ \vdots \\ H^\top y_t \\ \textcolor{yellow}{H^\top y_{t+1}}\end{bmatrix} $$
Block tri-diagonal matrix inverse
Possible to write \(\hat s_{t+1\mid t+1}\) as a linear combination of \(\hat s_{t\mid t}\) and \(y_{t+1}\)
1. Classic least squares regression
- assume fixed \(s_t = s\)
- least squares solution to measurement model equations $$\begin{bmatrix} y_0\\\vdots\\y_t\end{bmatrix} = \begin{bmatrix} s\\\vdots\\s\end{bmatrix} + \begin{bmatrix} v_0\\\vdots\\v_t\end{bmatrix}$$
- what is \(\hat s_{\mid 0}\), \(\hat s_{\mid 1}\), and \(\hat s_{\mid 2}\)?
- predict average $$\hat s_{\mid t} = \frac{1}{t+1}\sum_{t=0}^t y_t$$
Example: effect of modelling drift
Suppose we take noisy measurements of heart rate \(y_t = s_t + v_t\)
2. Least squares filtering
- allow for drift \(s_{t+1} = s_{t} + w_t\)
- least squares solution to measurement model and drift model equations
- what is \(\hat s_{k\mid 0}\), \(\hat s_{k\mid 1}\), and \(\hat s_{k\mid 2}\)?
Example: effect of modelling drift
Suppose we take noisy measurements of heart rate \(y_t = s_t + v_t\)
$$ y_0 = s_0 + v_0$$
\(\hat s_{0\mid 0} = y_0\)
2. Least squares filtering
- allow for drift \(s_{t+1} = s_{t} + w_t\)
- least squares solution to measurement model and drift model equations
- what is \(\hat s_{k\mid 0}\), \(\hat s_{k\mid 1}\), and \(\hat s_{k\mid 2}\)?
Example: effect of modelling drift
Suppose we take noisy measurements of heart rate \(y_t = s_t + v_t\)
2. Least squares filtering
- allow for drift \(s_{t+1} = s_{t} + w_t\)
- least squares solution to measurement model and drift model equations
- what is \(\hat s_{k\mid 0}\), \(\hat s_{k\mid 1}\), and \(\hat s_{k\mid 2}\)?
$$ \begin{bmatrix} y_0\\ 0 \\ y_1\end{bmatrix} = \begin{bmatrix} 1 \\ 1 & -1 \\ & 1 \end{bmatrix} \begin{bmatrix}s_0\\s_1\end{bmatrix} + \begin{bmatrix} v_0 \\ w_0 \\ v_1\end{bmatrix}$$
$$ \begin{bmatrix} 2 & -1 \\ -1 & 2\end{bmatrix}^{-1} \begin{bmatrix} 1 & 1\\ & -1 & 1 \end{bmatrix} \begin{bmatrix} y_0\\ 0 \\ y_1\end{bmatrix} $$
\(\hat s_{0\mid 1} = \frac{2y_0+y_1}{3}\)
\(\hat s_{1\mid 1} = \frac{y_0+2y_1}{3}\)
Example: effect of modelling drift
Suppose we take noisy measurements of heart rate \(y_t = s_t + v_t\)
2. Least squares filtering
- allow for drift \(s_{t+1} = s_{t} + w_t\)
- least squares solution to measurement model and drift model equations
- what is \(\hat s_{k\mid 0}\), \(\hat s_{k\mid 1}\), and \(\hat s_{k\mid 2}\)?
$$ \begin{bmatrix} y_0\\ 0 \\ y_1\\ 0 \\ y_2 \end{bmatrix} = \begin{bmatrix} 1 \\ 1 & -1 \\ & 1\\ & 1 & -1 \\ && 1 \end{bmatrix} \begin{bmatrix}s_0\\s_1\\ s_2\end{bmatrix} + \begin{bmatrix} v_0 \\ w_0 \\ v_1\\w_1\\v_2\end{bmatrix}$$
\(\hat s_{0\mid 2} = \frac{5y_0+2y_1+1y_2}{8}\)
\(\hat s_{1\mid 2} = \frac{2y_0+4y_1+2y_2}{8}\)
\(\hat s_{2\mid 2} = \frac{y_0+2y_1+5y_2}{8}\)
Example: effect of modelling drift
Suppose we take noisy measurements of heart rate \(y_t = s_t + v_t\)
1. Classic least squares regression
- assume fixed \(s_t = s\)
- least squares solution to measurement model equation
- predict average $$\hat s_{\mid t} = \frac{1}{t+1}\sum_{t=0}^t y_t$$
2. Least squares filtering
- allow for drift \(s_{t+1} = s_{t} + w_t\)
- least squares solution to measurement model and drift model equations
- predict average weighted by proximity in time
- \(\hat s_{k\mid t}\) more heavily weights \(y_k\)
\(y_t\)
\(s_{t+1} = Fs_t + w_t\)
\(y_t = Hs_t + v_t\)
Kalman Filter
\(\hat s_t\)
\(F-L_tHF\)
\(\hat s\)
\(L_t\)
Kalman filter as a state space model

\(F\)
\(s\)
\(w_t\)
\(v_t\)
\(H\)
\(\hat s_{t+1} = F\hat s_t + L_t(y_{t+1} -HF\hat s_t)\)
\(\hat y_t = H\hat s_t\)
-
The Kalman filter in state space $$ \hat s_{t+1} = \underbrace{(F-L_tHF)}_{F_{L,t}}\hat s_t + L_ty_{t+1},\quad \hat y_t = H\hat s_t$$
-
"Unrolling" to get equivalent linear output model $$\hat y_{t} = H\Big(\prod_{k=0}^{t-1} F_{L,k}\Big) \hat s_{0}+ \sum_{k=1}^{t}H \Big(\prod_{\ell=0}^{k-1} F_{L,\ell}\Big) L_{t-1}y_{t-k+1}$$
-
The prediction \(\hat y_t\) is a linear combination of all past observations \(y_k\)
-
Claim: the first \(t-L\) terms can be upper bounded by a function scaling as \(C\rho^L\) for some \(\rho<1\) and \(C\geq 0\) (next assignment)
-
Fact 3: A linear autoregressive model of length \(L\geq \log(C/\epsilon) / \log(1/\rho)\) can \(\epsilon\)-approximate the Kalman filter's state estimates
AR models can approx. KF
Summary
$$ x_{t+1} = F x_t + w_t,\quad y_t = Hx_t + v_t$$
-
Fact 1: the Kalman filter is statistically optimal if noise is Gaussian
-
Fact 2: the Kalman filter provides an online solution to a least-squares optimization problem
-
Fact 3: A linear autoregressive model of length \(L=O(\log(1/\epsilon))\) can \(\epsilon\) approximate the Kalman filter's estimates
-
\(\implies\) AR is approximately optimal for LDS
Recap
- Stochastic linear dynamical systems
- Kalman filter and least-squares state estimation
Next time: discrete state and observation space
Announcements
- Third assignment due tonight
- Useful posts on Edstem about formatting PRs for submission
- Fourth assignment released this afternoon
Extensions
- Time-varying dynamics/measurements \(F_t, H_t\)
- Initialize \(P_{0\mid0} \) and \(\hat s_{0\mid 0}\)
- For \(t= 1, 2...\):
- Extrapolate
- State \(\hat s_{t\mid t-1} =\)\(F_t\)\(\hat s_{t-1\mid t-1} \)
- Info matrix
\(P_{t\mid t-1} = \)\(F_t\)\(P_{t-1\mid t-1}\)\( F_t^\top\)\( + I\)
- Compute gain
\(L_{t} = P_{t\mid t-1}\)\(H_t^\top\)\( ( \)\(H_t\)\(P_{t\mid t-1} \)\(H_t^\top\)\(+I)^{-1}\) - Update
- State
\(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-\)\(H_t\)\(\hat s_{t\mid t-1})\) - Info matrix
\(P_{t\mid t} = (I - L_{t}\)\(H_t\)\()P_{t\mid t-1}\)
- State
- Extrapolate
Extensions
- Initialize \(P_{0\mid0} \) and \(\hat s_{0\mid 0}\)
- For \(t= 1, 2...\):
- Extrapolate
- State \(\hat s_{t\mid t-1} =\)\(F_t\)\(\hat s_{t-1\mid t-1} \)
- Info matrix
\(P_{t\mid t-1} = \)\(F_t\)\(P_{t-1\mid t-1}\)\( F_t^\top\)\( + \Sigma_{w,t}\)
- Compute gain
\(L_{t} = P_{t\mid t-1}\)\(H_t^\top\)\( ( \)\(H_t\)\(P_{t\mid t-1} \)\(H_t^\top\)\(+\)\(\Sigma_{v,t}\)\()^{-1}\) - Update
- State
\(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-\)\(H_t\)\(\hat s_{t\mid t-1})\) - Info matrix
\(P_{t\mid t} = (I - L_{t}\)\(H_t\)\()P_{t\mid t-1}\)
- State
- Extrapolate
- Time-varying dynamics/measurements \(F_t, H_t\)
- Weighted least-squares models characteristics of noise
\(\displaystyle \min_{{s,v,w}} ~~~\sum_{k=0}^{t-1} \|\)\(\Sigma_{w,k}^{-1/2}\)\(w_k\|_2^2 + \|\)\(\Sigma_{v,k}^{-1/2}\)\(v_k\|^2+\|\)\(\Sigma_{s}^{-1/2}\)\(s_0\|_2^2 \)
$$\text{s.t.}~~~\bar{y}_{0:t} = F \bar s_{0:t}+ \bar w_{0:t} + \bar v_{0:t}$$
Extensions
- Initialize \(P_{0\mid0} \) and \(\hat s_{0\mid 0}\)
- For \(t= 1, 2...\):
- Extrapolate
- State \(\hat s_{t\mid t-1} =\)\(F_t\)\(\hat s_{t-1\mid t-1} \)
- Info matrix
\(P_{t\mid t-1} = \)\(F_t\)\(P_{t-1\mid t-1}\)\( F_t^\top\)\( + \Sigma_{w,t}\)
- Compute gain
\(L_{t} = P_{t\mid t-1}\)\(H_t^\top\)\( ( \)\(H_t\)\(P_{t\mid t-1} \)\(H_t^\top\)\(+\)\(\Sigma_{v,t}\)\()^{-1}\) - Update
- State
\(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-\)\(H_t\)\(\hat s_{t\mid t-1})\) - Info matrix
\(P_{t\mid t} = (I - L_{t}\)\(H_t\)\()P_{t\mid t-1}\)
- State
- Extrapolate
- Time-varying dynamics/measurements \(F_t, H_t\)
- Weighted least-squares models characteristics of noise
- KF is the Minimum Variance Linear Unbiased Estimator
- if \(s_0, w_k, v_k\) stochastic and independent \(\forall k\)
- and \(\mathbb E[s_0] = \mathbb E[w_k] = \mathbb E[v_k] = 0\)
- and covariances \(\Sigma_s,\Sigma_{w,k},\Sigma_{v,k}\)
Extensions
- Initialize \(P_{0\mid0} \) and \(\hat s_{0\mid 0}\)
- For \(t= 1, 2...\):
- Extrapolate
- State \(\hat s_{t\mid t-1} =\)\(F_t\)\(\hat s_{t-1\mid t-1} \)
- Info matrix
\(P_{t\mid t-1} = \)\(F_t\)\(P_{t-1\mid t-1}\)\( F_t^\top\)\( + \Sigma_{w,t}\)
- Compute gain
\(L_{t} = P_{t\mid t-1}\)\(H_t^\top\)\( ( \)\(H_t\)\(P_{t\mid t-1} \)\(H_t^\top\)\(+\)\(\Sigma_{v,t}\)\()^{-1}\) - Update
- State
\(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-\)\(H_t\)\(\hat s_{t\mid t-1})\) - Info matrix
\(P_{t\mid t} = (I - L_{t}\)\(H_t\)\()P_{t\mid t-1}\)
- State
- Extrapolate
- Time-varying dynamics/measurements \(F_t, H_t\)
- Weighted least-squares models characteristics of noise
- KF is the Minimum Variance Linear Unbiased Estimator for stochastic/independent noise
- KF is the Minimum Variance Unbiased Estimator
- if \(s_0\sim N(0,\Sigma_s)\), \(w_k\sim N(0,\Sigma_{w,k})\), \(v_k\sim N(0,\Sigma_{v,k})\)
- in other words, KF exactly computes conditional expectation \(\hat s_{t\mid t} = \mathbb E[s_t\mid y_{0:t}]\)
- furthermore, \(P_{t\mid t}\) is the error covariance
Extensions
- Initialize \(P_{0\mid0} \) and \(\hat s_{0\mid 0}\)
- For \(t= 1, 2...\):
- Extrapolate
- State \(\hat s_{t\mid t-1} =\)\(F_t\)\(\hat s_{t-1\mid t-1} \)
- Info matrix
\(P_{t\mid t-1} = \)\(F_t\)\(P_{t-1\mid t-1}\)\( F_t^\top\)\( + \Sigma_{w,t}\)
- Compute gain
\(L_{t} = P_{t\mid t-1}\)\(H_t^\top\)\( ( \)\(H_t\)\(P_{t\mid t-1} \)\(H_t^\top\)\(+\)\(\Sigma_{v,t}\)\()^{-1}\) - Update
- State
\(\hat s_{t\mid t} = \hat s_{t\mid t-1}+ L_{t}(y_{t}-\)\(H_t\)\(\hat s_{t\mid t-1})\) - Info matrix
\(P_{t\mid t} = (I - L_{t}\)\(H_t\)\()P_{t\mid t-1}\)
- State
- Extrapolate
- Time-varying dynamics/measurements \(F_t, H_t\)
- Weighted least-squares models characteristics of noise
- KF is the Minimum Variance Linear Unbiased Estimator for stochastic/independent noise
- KF is the Minimum Variance Unbiased Estimator for Gaussian noise