Learning Enabled Control
Goals and Motivation
- Learning theory in dynamic settings
- Getting robots (or other ML systems) to work
Framework
- Collect and learn from data: models and uncertainty quantification (learning theory, statistics)
- Use learned model for control (robust synthesis)
Interplay between these steps: online learning, exploration, adaptivity
Outline
- Review analysis of LQR + extensions
- Perception-based control
Linear Quadratic Regulator
minimize \(\lim_{T\to\infty} \frac{1}{T} \sum_{t=0}^\infty \mathbb{E} [x_t^\top Q x_t + u_t^\top R u_t] \)
such that \(x_{t+1} = A_\star x_t + B_\star u_t + w_t\)
Classic optimal control problem
Static state feedback solution, \(u_t = K_\star x_t\) arises from DARE(\(A_\star,B_\star,Q,R\))
1. Learning Dynamics
Dynamics learned by least squares:
\(\widehat A, \widehat B = \arg\min \sum_{k=0}^T \|x_{k+1} - Ax_k - Bu_k\|^2\)
\( = \arg\min \|X-Z[A~B]^\top \|_F^2\)
\(= [A_\star~B_\star]^\top + (Z^\top Z)^{-1} Z^\top W\)
\(z_k = \begin{bmatrix} x_k\\u_k\end{bmatrix}\)
Simplifying error bound relies on non-asymptotic statistics
\(\|[\widehat A-A_\star~~\widehat B-B_\star]\|_2 \leq \frac{\|Z^\top W\|_2}{\lambda_{\min}(Z^\top Z)}\)
2. Robust Control
The robust control problem:
minimize \(\max_{A,B} ~\lim_{T\to\infty} \frac{1}{T} \sum_{t=0}^\infty \mathbb{E} [x_t^\top Q x_t + u_t^\top R u_t] \)
such that \(x_{t+1} = A x_t + B u_t + w_t\)
and \(\|A-\widehat A\|_2\leq\varepsilon_A,~ \|B-\widehat B\|_2\leq\varepsilon_B\)
Any method for solving yields upper bounds on stability and realized performance, but we also want suboptimality compared with \(K_\star\)
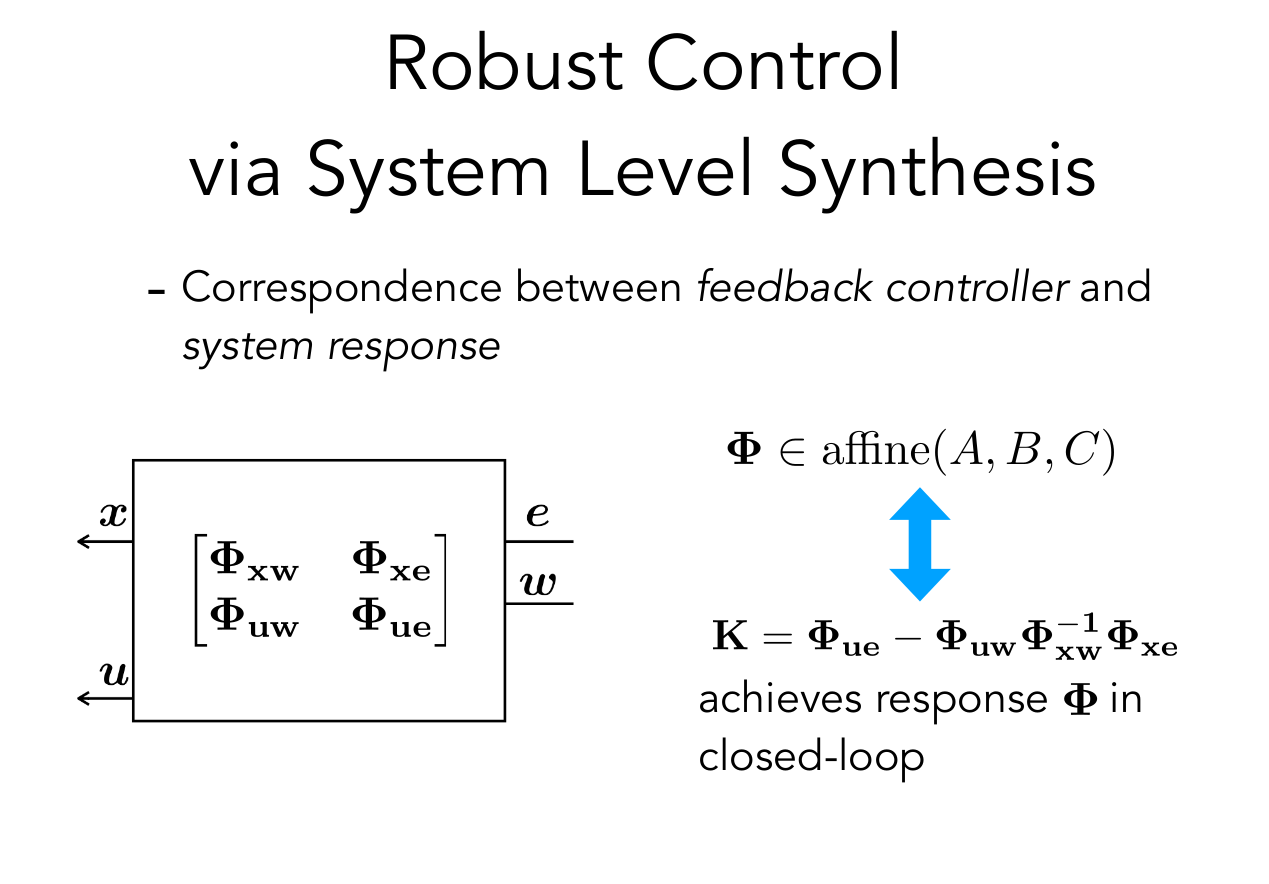
2. Robust Control via SLS
We can map planned trajectories to realized trajectories under mismatches in dynamics
\(\begin{bmatrix} \widehat{\mathbf x}\\ \widehat{\mathbf u}\end{bmatrix} = \mathbf{\widehat{\Phi} w} \)
\(\begin{bmatrix} {\mathbf x}\\ {\mathbf u}\end{bmatrix} = \mathbf{\widehat{\Phi}}(I - \mathbf{\widehat \Delta})^{-1}\mathbf w \)
\(\bf x\)
\(\bf u\)
\(\bf w\)
\(\mathbf{\Phi}\)
plant \((A,B)\)
controller \(\mathbf{K}\)
\(\bf x\)
\(\bf u\)
\(\bf w\)
LQR with SLS
robust cost
nominal achievable subspace
\( \underset{\mathbf{\Phi},\gamma}{\min}\) \(\frac{1}{1-\gamma}\)\(\text{cost}(\mathbf{\Phi})\)
\(\text{s.t.}~\begin{bmatrix}zI- \widehat A&- \widehat B\end{bmatrix} \mathbf\Phi = I\)
\(\|[{\varepsilon_A\atop ~} ~{~\atop \varepsilon_B}]\mathbf \Phi\|_{H_\infty}\leq\gamma\)
sensitivity constraints
quadratic cost
achievable subspace
minimize \(\mathbb{E}[\)cost\((x_0,u_0,x_1...)]\)
s.t. \(x_{t+1} = Ax_t + Bu_t + w_t\)
minimize cost(\(\mathbf{\Phi}\))
s.t. \(\begin{bmatrix}zI- A&- B\end{bmatrix} \mathbf\Phi = I\)
Robust LQR with SLS
LQR with System Level Synthesis
quadratic cost
achievable subspace
minimize \(\mathbb{E}[\)cost\((x_0,u_0,x_1...)]\)
s.t. \(x_{t+1} = Ax_t + Bu_t + w_t\)
minimize cost(\(\mathbf{\Phi}\))
s.t. \(\begin{bmatrix}zI- A&- B\end{bmatrix} \mathbf\Phi = I\)
Instead of reasoning about a controller \(\mathbf{K}\),
we reason about the interconnection \(\mathbf\Phi\) directly
\(\bf x\)
\(\bf u\)
\(\bf w\)
\(\mathbf{\Phi}\)
plant \((A,B)\)
controller \(\mathbf{K}\)
\(\bf x\)
\(\bf u\)
\(\bf w\)
As long as \(T\) is large enough, then w.p. \(1-\delta\),
subopt. of \(\widehat{\mathbf K}\lesssim \frac{\sigma_w C_u}{\sigma_u} \sqrt{\frac{(n+d)\log(1/\delta)}{T}} \|\)CL\((A_\star,B_\star, K_*)\|_{H_\infty} \)
LQR Sample Complexity
Extensions
- Online robust control: decaying excitation over time
- Constrained LQR: polytopic constraints
- Online CE control: no need for robustness
Perception-Based Control
Difficulty making use of complex sensing modalities

Example: cameras on drones
Traditional Approach
- Physics-based state estimation with EKF or UKF
- Careful control design and tuning
End-To-End Approach
- Deep networks map images to actions
Optimal Control Perspective
minimize \(\mathrm{cost}(\mathbf x, \mathbf u)\)
such that \(x_{k+1} = f(x_k, u_k, w_k),~~z_k = g(x_k,\nu_k),~~u_k = \gamma_k(z_{0:k})\)
Traditional State Estimation:
minimize \(\mathrm{cost}(\widehat{\mathbf x}, \mathbf u)\)
such that \(\widehat x_{k+1} = f(\widehat x_k, u_k, w_k), \\ u_k = \gamma(\widehat x_k)\)
End-to-end:
minimize \(\mathrm{cost}\)
such that \(u_k = \gamma_k(z_{0:k})\)
Our Approach: Use perception map
minimize \(\mathrm{cost}(\mathbf x, \mathbf u)\)
such that \(x_{k+1} = f(x_k, u_k, w_k),~~z_k = g(x_k,\nu_k),\)
\(u_k = \gamma_k(y_{0:k}),~~y_k=p(z_k)\approx Cx_k\)
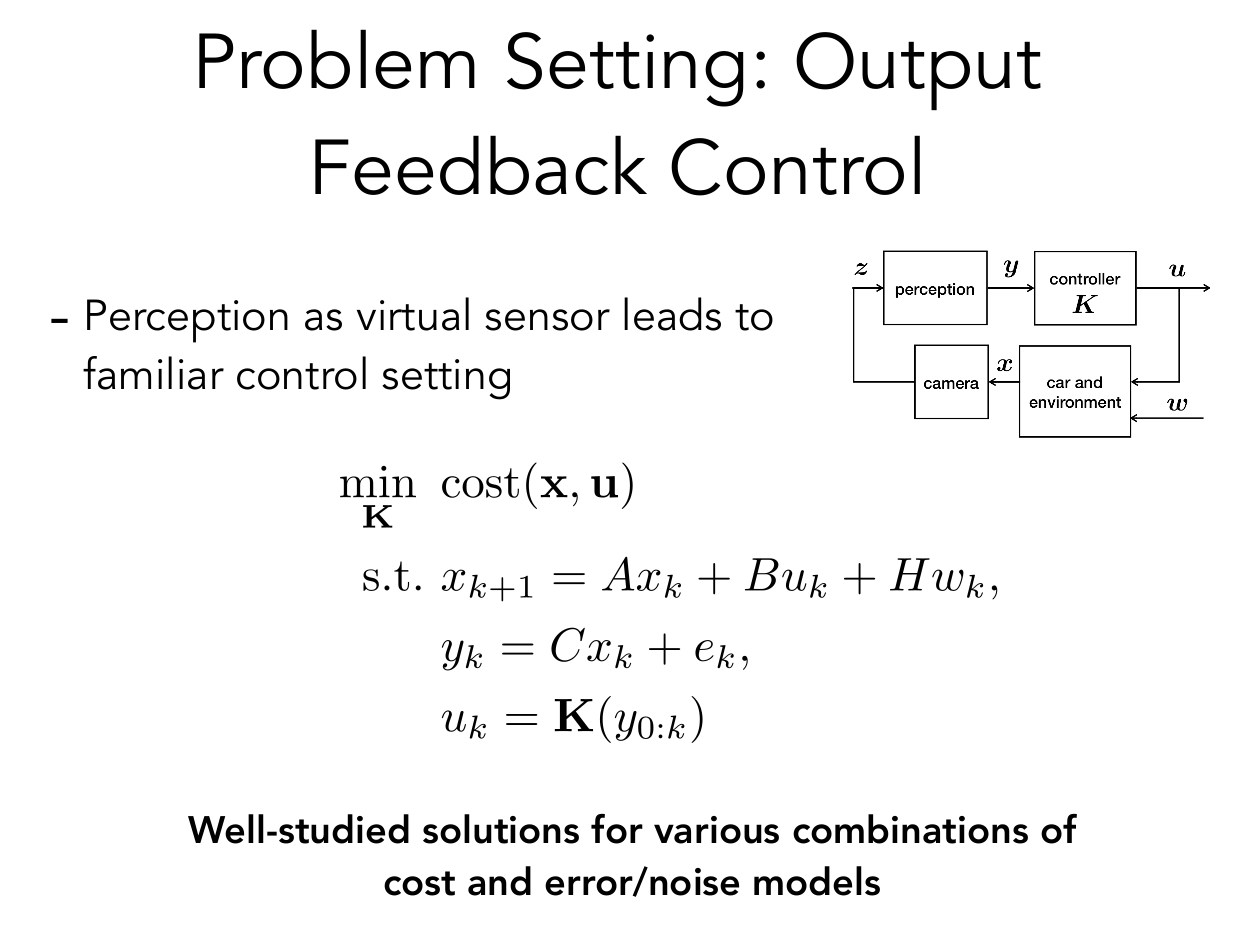
Problem Setting
- Linear dynamics: \(x_{k+1} = Ax_k + B u_k + Hw_k\)
- State-dependent observations: \(z_k \approx q(x_k) \)
- Perception map acts as virtual sensor, \(y_k = p(z_k) = C x_k + e_k\)
1. Learning Perception Map
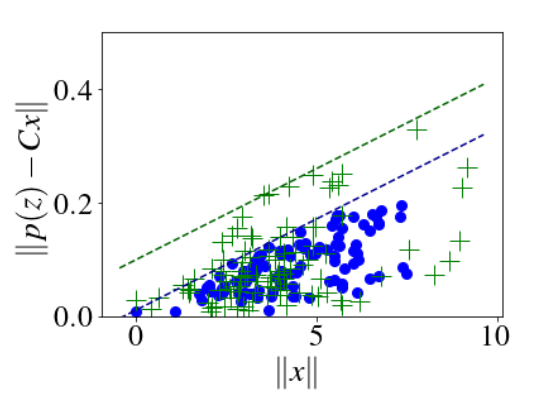
We need to fit some \(p\) and then guarantee something useful about errors \(e=Cx-p(z)\).
Robust regression:
minimize \(\varepsilon_e + \lambda R(p)\)
such that \(\|p(z_k) - x_k\|\leq \varepsilon_e\)
1. Learning Perception Map
More generally, the errors might be better characterized as
\(p(z_k) - Cx_k = \Delta(x_k) + n_k = \Delta_{C,k} x_k + n_k\)
where \(\Delta_C\) and \(n\) are norm bounded.
Regressing error profile:
minimize \(M\varepsilon_C +\varepsilon_n\)
such that \(\|p(z_k) - x_k\|\leq \varepsilon_C\|x_k\| + \varepsilon_n\)
2. Output Feedback Control
If we know that \(\|p(z_k) - Cx_k\|= \|e_k\|\leq \varepsilon_e\), we can apply our favorite robust control cost

The SLS problem looks like:
minimize \( \Big \| \begin{bmatrix}Q^{1/2} &\\&R^{1/2}\end{bmatrix} \mathbf{\Phi} \begin{bmatrix}\sigma_w H \\ \varepsilon_e I\end{bmatrix} \Big \| \)
such that \(\mathbf{\Phi} \in \mathrm{affine}(A,B,C)\)
2. Robust Output Feedback Control
Instead: \(p(z_k) - x_k=\Delta_{C,k}x_k + n_k\) for \( \|\Delta_C\| \leq \varepsilon_C\) and \(\|n\| \leq \varepsilon_n\)
Adapt the previous approach to handle uncertainty in the sensing matrix.
The robust SLS problem looks like:
minimize \( \Big \| \begin{bmatrix}Q^{1/2} &\\&R^{1/2}\end{bmatrix} \begin{bmatrix}\mathbf{\Phi_{xw}} & \mathbf{\Phi_{xn}} \\ \mathbf{\Phi_{uw}} & \mathbf{\Phi_{un}} \end{bmatrix} \begin{bmatrix}\sigma_w H \\ \varepsilon_n I\end{bmatrix} \Big \|\)
\(+ \frac{\varepsilon_C(\gamma\varepsilon_w + \tau\varepsilon_n)}{1-\tau\varepsilon_C}\Big \| \begin{bmatrix}Q^{1/2} \\R^{1/2}\end{bmatrix} \begin{bmatrix} \mathbf{\Phi_{xn}} \\ \mathbf{\Phi_{un}} \end{bmatrix} \Big \| \)
such that \(\mathbf{\Phi} \in \mathrm{affine}(A,B,C)\), \(\|\mathbf{\Phi_{xw}}H\|\leq \gamma\), \(\|\mathbf{\Phi_{xn}}\|\leq \tau\)
Main Result
We can synthesize a controller \(\mathbf \Phi\) with performance
cost\((\mathbf \Phi)\leq \Big \| \begin{bmatrix}Q^{1/2} &\\&R^{1/2}\end{bmatrix} \mathbf{\Phi} \begin{bmatrix}\sigma_w H \\ (\widehat\varepsilon_e + \varepsilon_\mathrm{gen}) I\end{bmatrix} \Big \| \)
where \(\varepsilon_\mathrm{gen} \) depends on smoothness and robustness of the perception map, bounded closed-loop response to errors \(\mathbf\Phi_{xe}\), and the planned trajectory's distance to training points
Generalization
If we learn some perception map \(p\) and error bound \(\widehat \varepsilon_e\) on training data, what can we say about the performance of \(p\) during operation?

Traditional generalization
Non-parametric guarantees from learning theory on risk \(\mathcal R\)
\( \mathcal R(p) = \mathcal R_N(p) +\mathcal R(p)- \mathcal R_N(p) \leq \mathcal R_N(p) +\varepsilon_\mathrm{gen} \)
e.g. for classic ERM, \( \mathbb{E}_{\mathcal D}[\ell(p;x,z)] \leq \mathbb{E}_{\mathcal D_N}[\ell(p;x,z)] + \mathcal{O}(\sqrt{\frac{1}{N}})\)
This usual statistical generalization argument relies on \(\mathcal D_N\) being drawn from \(\mathcal D\).
Distribution shift
Our setting looks more like
\( \mathbb{E}_{\mathcal D}[\ell(p;x,z)] = \mathbb{E}_{\mathcal D_N'}[\ell(p;x,z)] \)
\(+(\mathbb{E}_{\mathcal D_N}[\ell(p;x,z)]- \mathbb{E}_{\mathcal D_N'}[\ell(p;x,z)] )\)
\(+ (\mathbb{E}_{\mathcal D}[\ell(p;x,z)] - \mathbb{E}_{\mathcal D_N}[\ell(p;x,z)] ) \)
\(\leq \mathbb{E}_{\mathcal D_N'}[\ell(p;x,z)] +\varepsilon_\mathrm{shift}\rho(\mathcal{D,D'})+ \varepsilon_N\)
But our training and closed-loop distributions will be different, especially since \(\mathcal D\) depends on the errors \(\mathbf e\) themselves,
\(\mathbf x = \mathbf{\Phi_w w + \Phi_e e}\)
Generalization Argument
High level generalization argument
- Closeness implies generalization: if \(\rho(\mathcal D,\mathcal D')\) bounded, then \( \mathcal R(p) \) bounded.
- Generalization implies closeness: if \(\mathcal R(p)\) bounded, then \(\rho(\mathcal D,\mathcal D') \) bounded
But our training and closed-loop distributions will be different, especially since \(\mathcal D\) depends on the errors \(\mathbf e\) themselves,
\(\mathbf x = \mathbf{\Phi_w w + \Phi_e e}\)
Generalization Argument
- Closeness implies generalization (statistical, structural):
if \(\rho(\mathcal D,\mathcal D')\leq r\), then \( \mathcal R(p) \leq \mathcal R_N(p) +\varepsilon_N +\varepsilon_\mathrm{shift}\rho(\mathcal D,\mathcal D') \) - Generalization implies closeness (control, planning):
\(\rho(\mathcal D,\mathcal D') \leq \rho_0 +\varepsilon_\mathrm{rob}\mathcal R(p)\)
From this, we can bound \(\mathcal R(p) \) and \(\rho(\mathcal{D,D'}) \) as long as \(\varepsilon_\mathrm{shift}\varepsilon_\mathrm{rob}\leq 1\)
\(\implies\) guarantees on performance and stability.
Non-statistical assumptions
We take a robust and adversarial view,
training distribution \(\mathcal D'\) specified by points \(\{(x_d,z_d)\}\), "testing" distribution \(\mathcal D\) specified by trajectory \(\mathbf x, \mathbf z\)
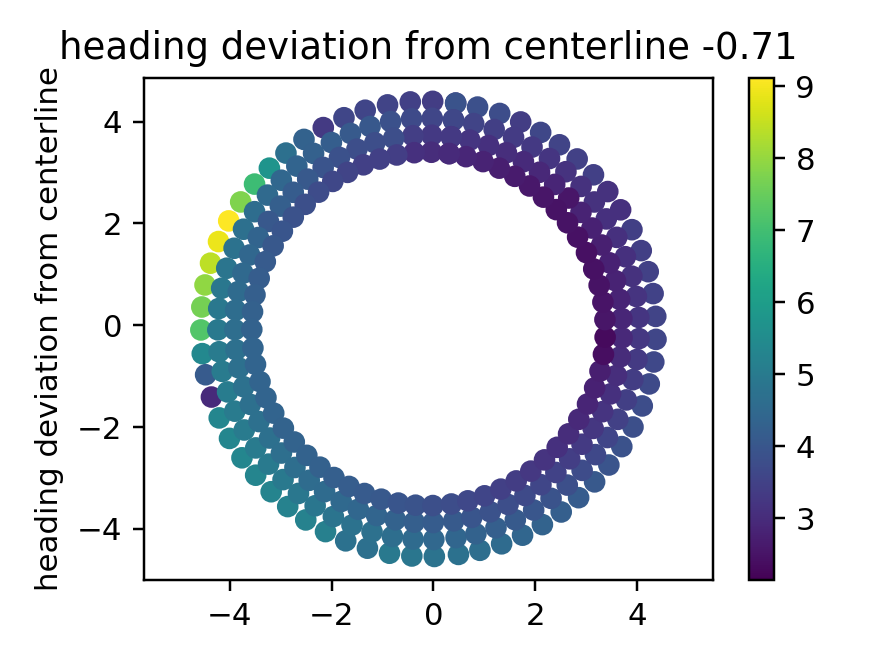
Then \(\mathcal{R}(p) = \|C\mathbf x - p(\mathbf z)\| \), \(\mathcal{R}_N(p) = \max_k \|Cx_k - p(z_k)\| \), and \(\rho(\mathcal{D,D'}) = \min_{\mathbf x_d}\|\mathbf{x-x_d}\|\)
In lieu of distributional assumptions, we assume smoothness.
- \(z_k = T_k(q(x_k),x_k)\) for nuisance transformations \(T_k\)
- e.g. sensor noise, lighting, scene changes
- \(\|p(z)-p(T(z,x))\|\leq \varepsilon_p\) for all \(T\) and \(z=q(x)\)
- \(p(q(x)) - Cx\) is locally \(L_e\) Lipschitz with a radius of \(r\)
- e.g. \(L_e \leq L_pL_q+\|C\|\)
Non-statistical generalization
- Determine set with bounded generalization error \(\varepsilon_\mathrm{gen}\)
- \(\min_{x_d}\|\mathbf{x-x_d}\|\leq \frac{\varepsilon_\mathrm{gen} - 2\varepsilon_p}{L_e} \leq r\)
- Design controller to remain within set:
- constraint \(\|\mathbf{ \Phi_{xw}w-x_d}\|+\|\mathbf{ \Phi_{xe}}\|(\hat \varepsilon_e + \varepsilon_\mathrm{gen}) \leq \frac{\varepsilon_\mathrm{gen} - 2\varepsilon_p}{L_e}\)
This is possible as long as \(L_e\|\mathbf{ \Phi_{xe}}\|\leq 1\)
Controller Design
Design controller to remain within set:
- constraint \(\|\mathbf{ \Phi_{xw}}H\mathbf{w-x_d}\|+\|\mathbf{ \Phi_{xe}}\|(\hat \varepsilon_e + \varepsilon_\mathrm{gen}) \leq \frac{\varepsilon_\mathrm{gen} - 2\varepsilon_p}{L_e}\)
For example, with reference tracking:
\(\|\)\(\mathbf{x_\mathrm{ref}}\)\(-\mathbf{x_d}\|+\|\mathbf{ \Phi_{xw}}H\|\varepsilon_\mathrm{ref}\)
Controller design balances responsiveness to references \(\|\mathbf{ \Phi_{xw}}H\|\) with sensor response \(\|\mathbf{ \Phi_{xe}}\|\)
Main Result
We can synthesize a controller \(\mathbf \Phi\) with performance
cost\((\mathbf \Phi)\leq \Big \| \begin{bmatrix}Q^{1/2} &\\&R^{1/2}\end{bmatrix} \mathbf{\Phi} \begin{bmatrix}\sigma_w H \\ (\widehat\varepsilon_e + \varepsilon_\mathrm{gen}) I\end{bmatrix} \Big \| \)
where \(\varepsilon_\mathrm{gen} \) depends on smoothness \(L_e\) and robustness \(\varepsilon_p\) of the perception map, bounded closed-loop response to errors \(\mathbf\Phi_{xe}\), and the planned trajectory's distance to training points \(\rho_0\).
\(\varepsilon_\mathrm{gen} = \frac{2\varepsilon_p+L_e\rho_0}{1-L_e\|\mathbf{\Phi_{xe}}\|}\)
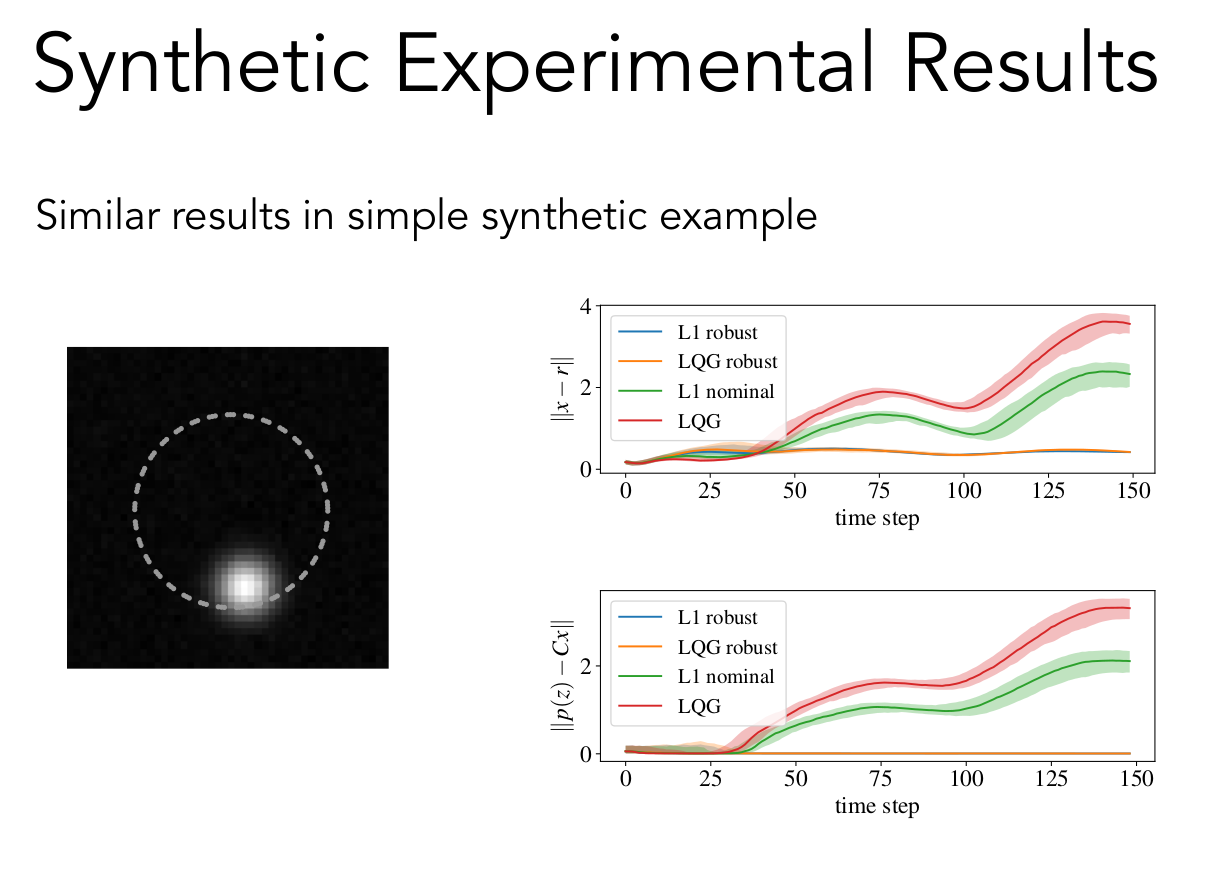
Synthetic setting