Aprendizaje reforzado y epidemiología: una invitación a las aplicaciones de los procesos Markovianos de decisión en Ciencia de Datos
“1er Congreso Multidisciplinario de la Facultad de Ciencias en Física y Matemáticas”
Yofre H. Garcia
Saúl Diaz-Infante Velasco
Jesús Adolfo Minjárez Sosa
sauldiazinfante@gmail.com
02 de octubre de 2024
“1er Congreso Multidisciplinario de la Facultad de Ciencias en Física y Matemáticas”
Yofre H. Garcia
Saúl Diaz-Infante Velasco
Jesús Adolfo Minjárez Sosa
sauldiazinfante@gmail.com
02 de octubre de 2024

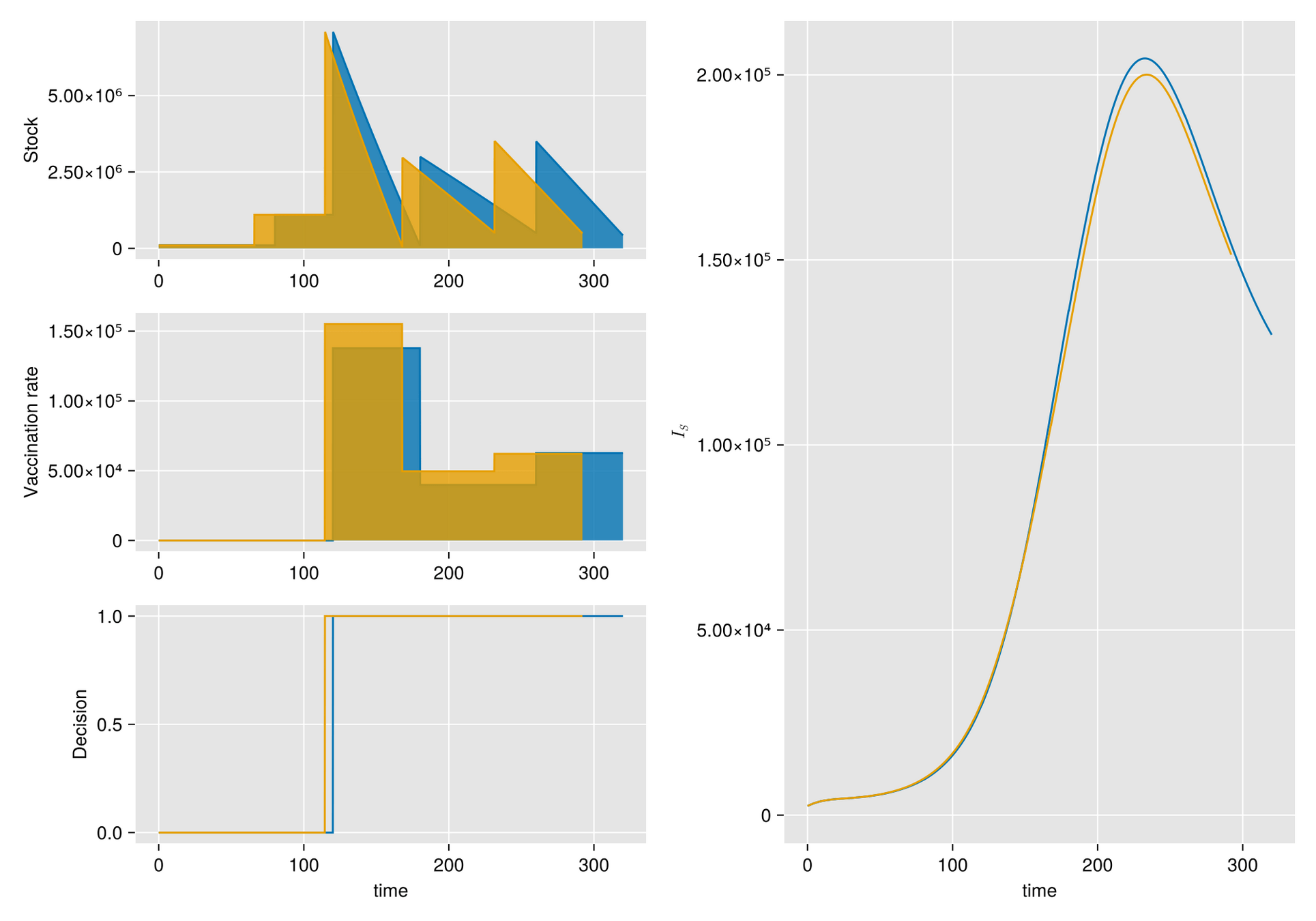
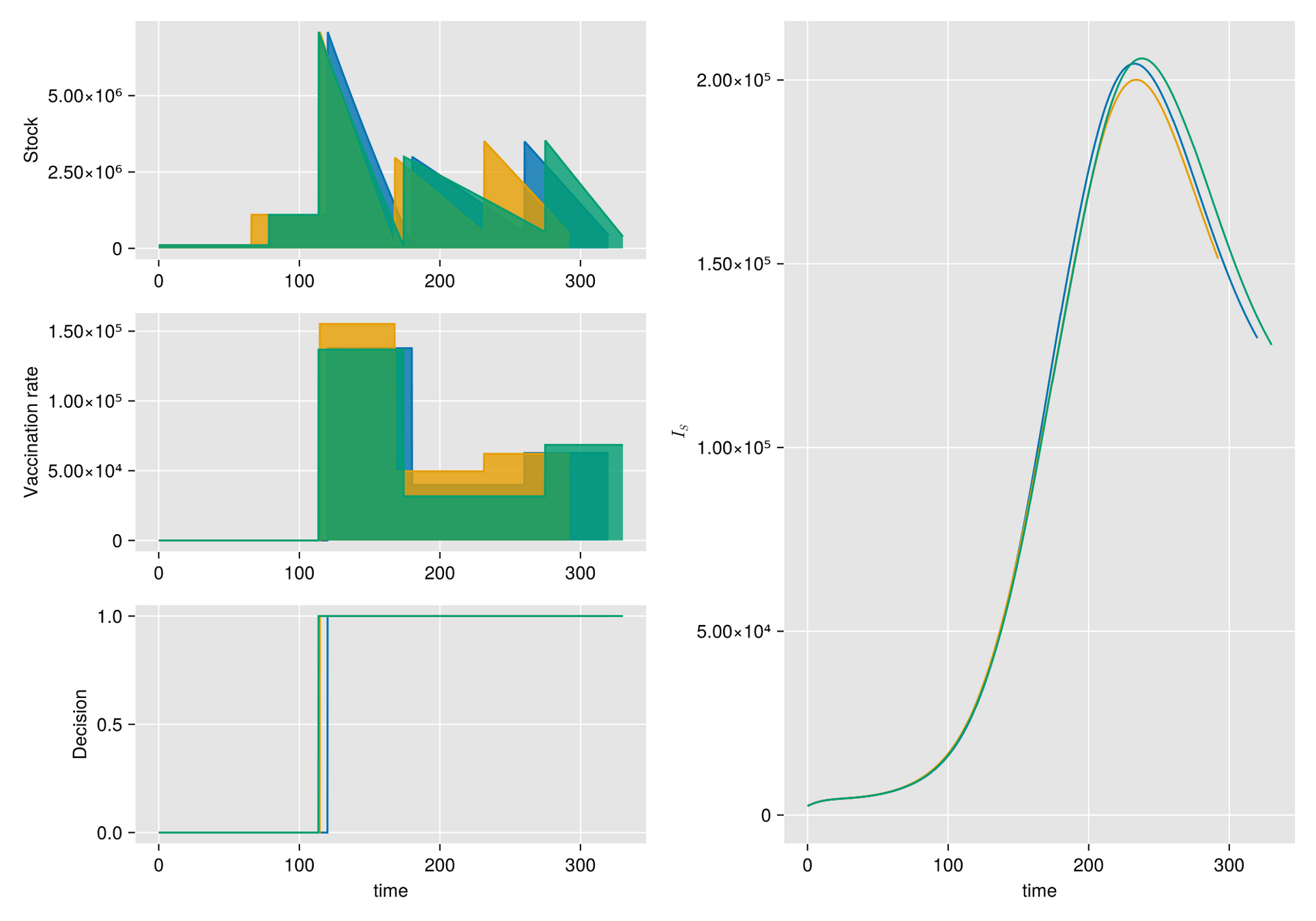
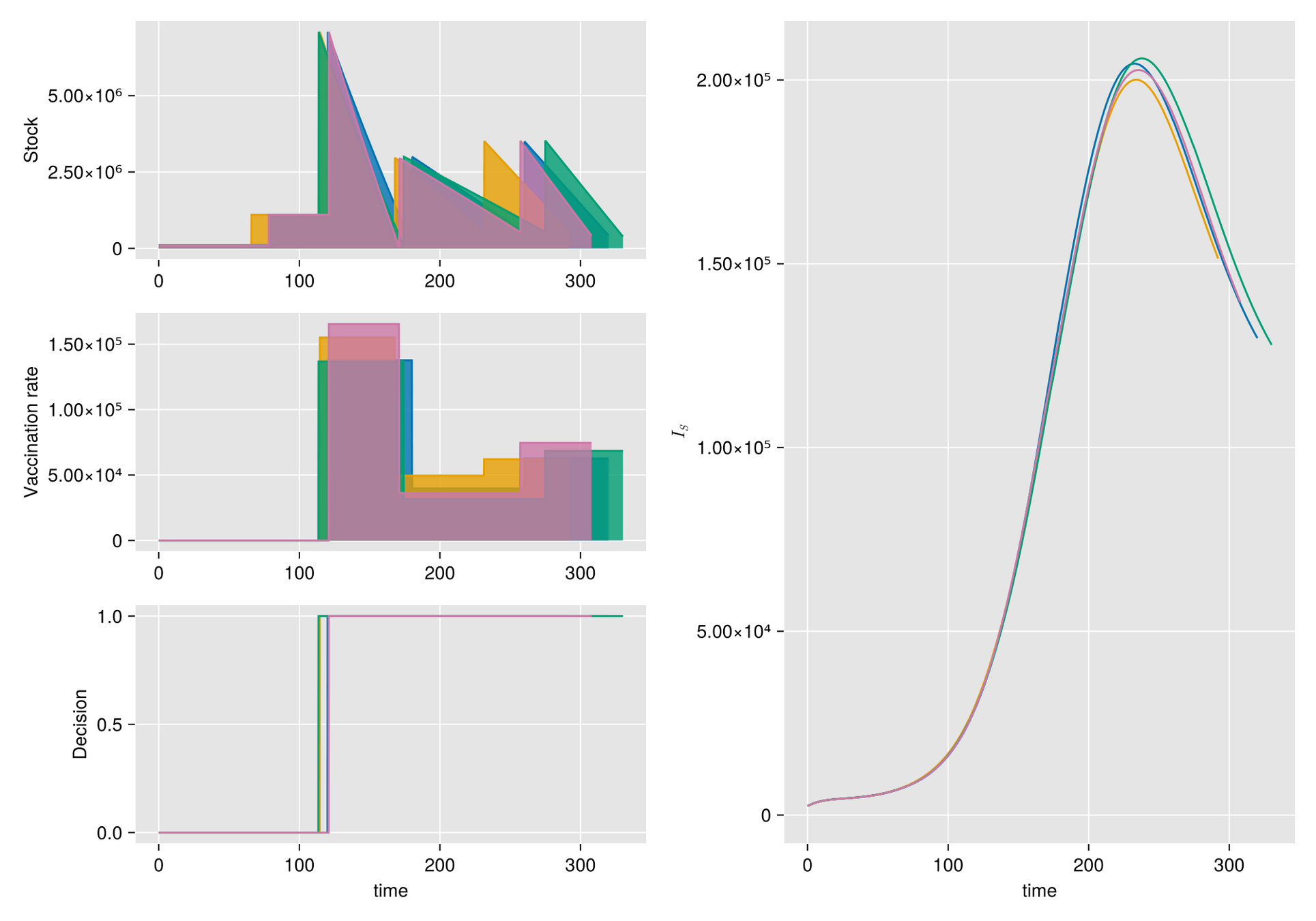
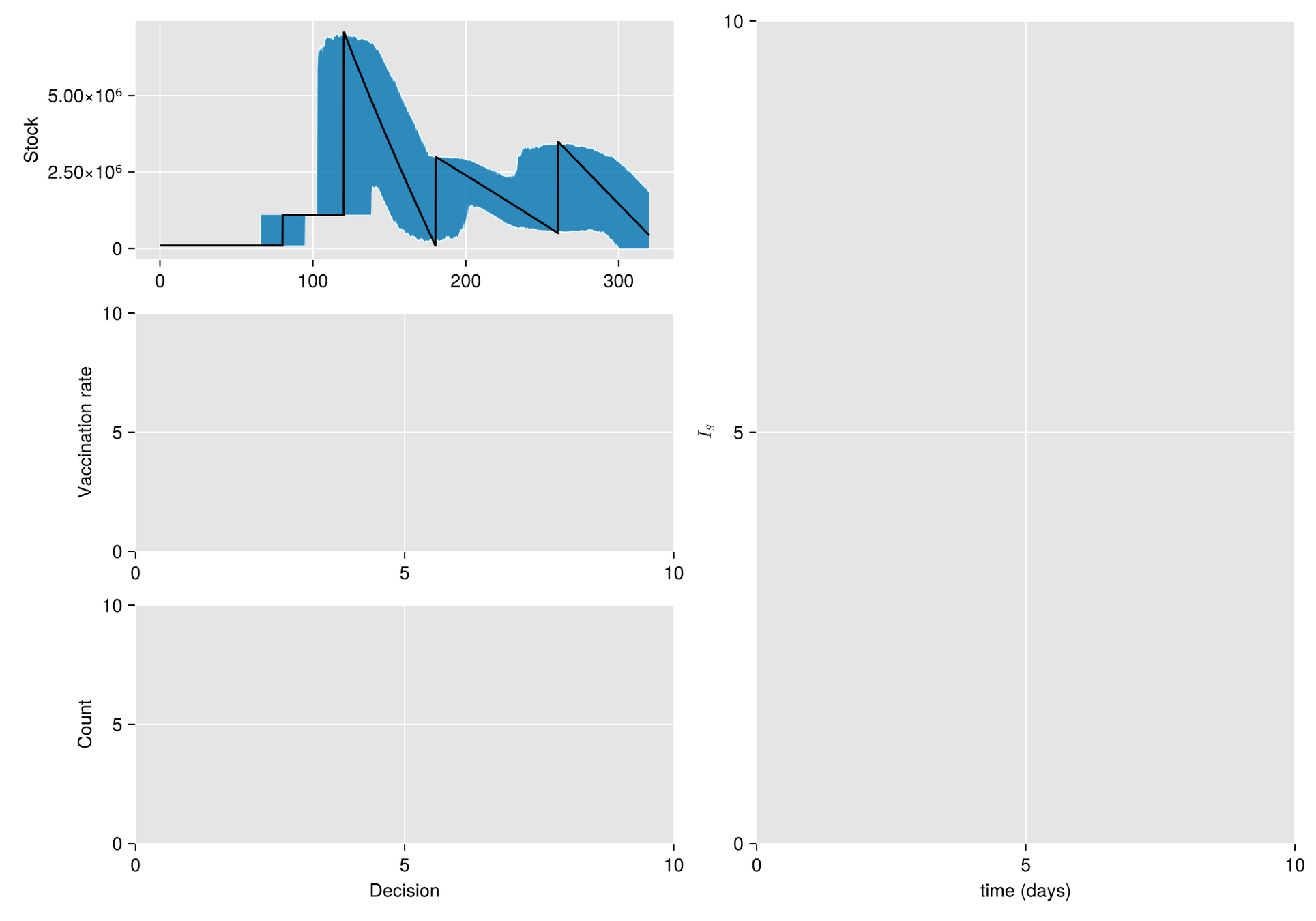
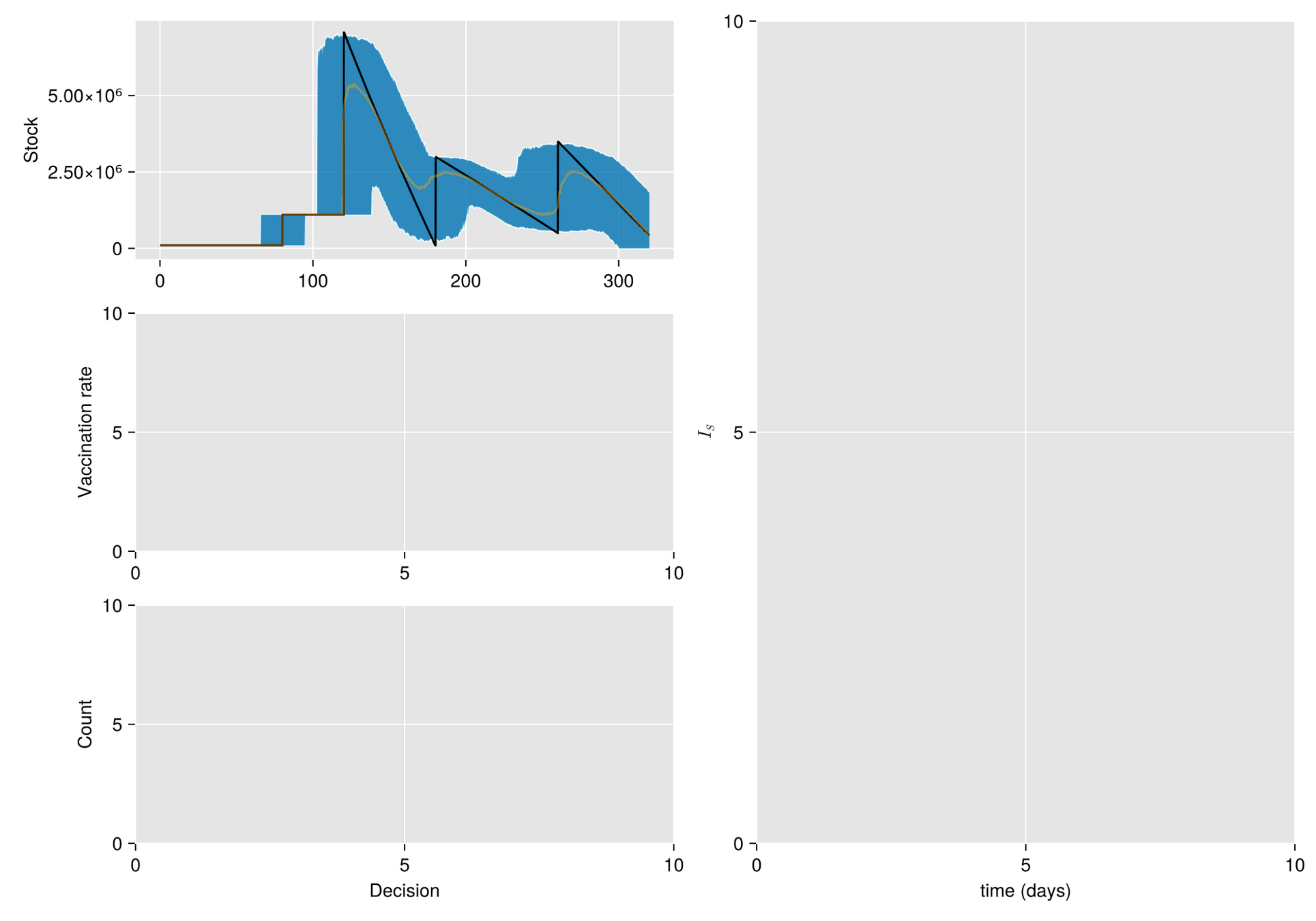
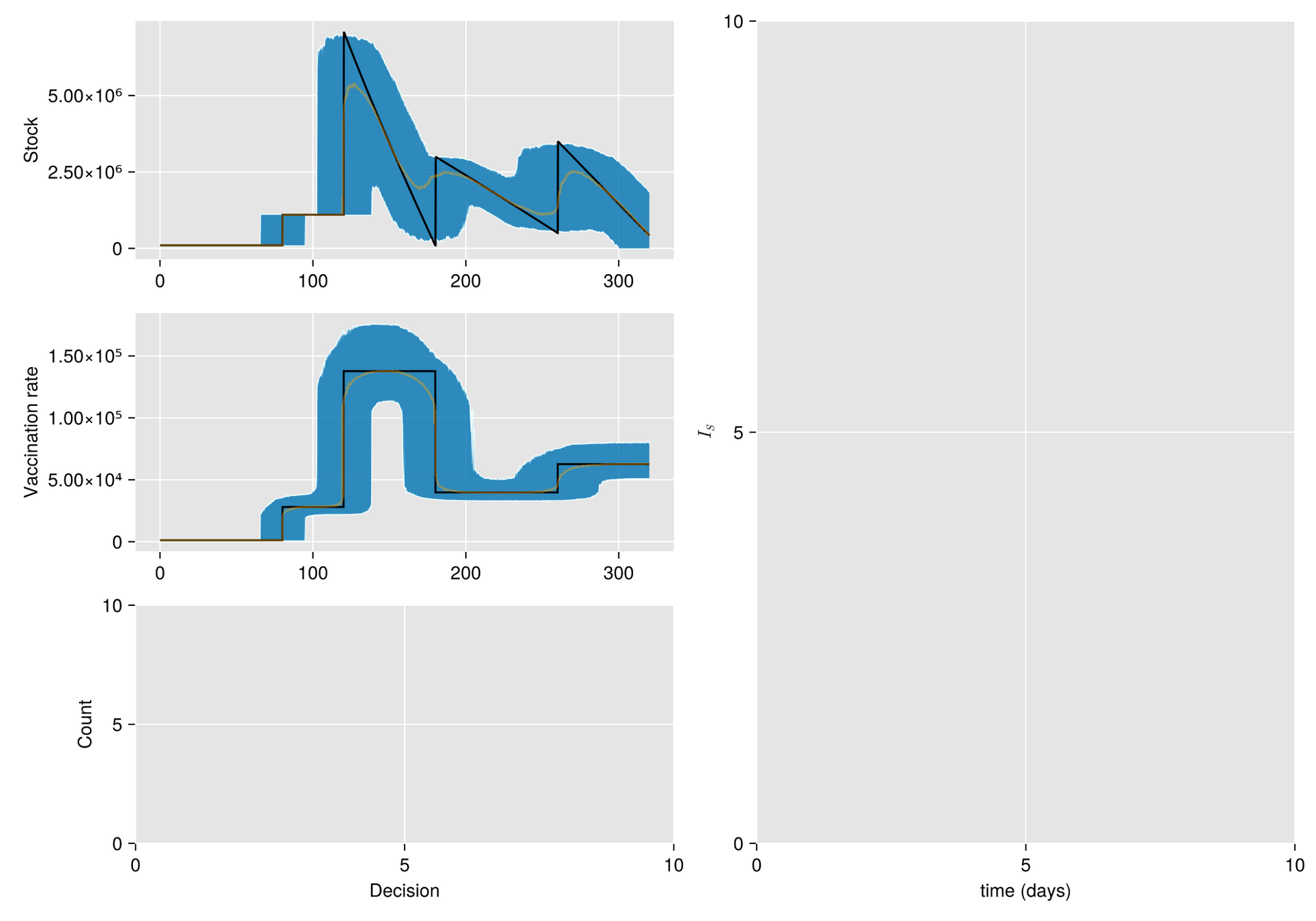
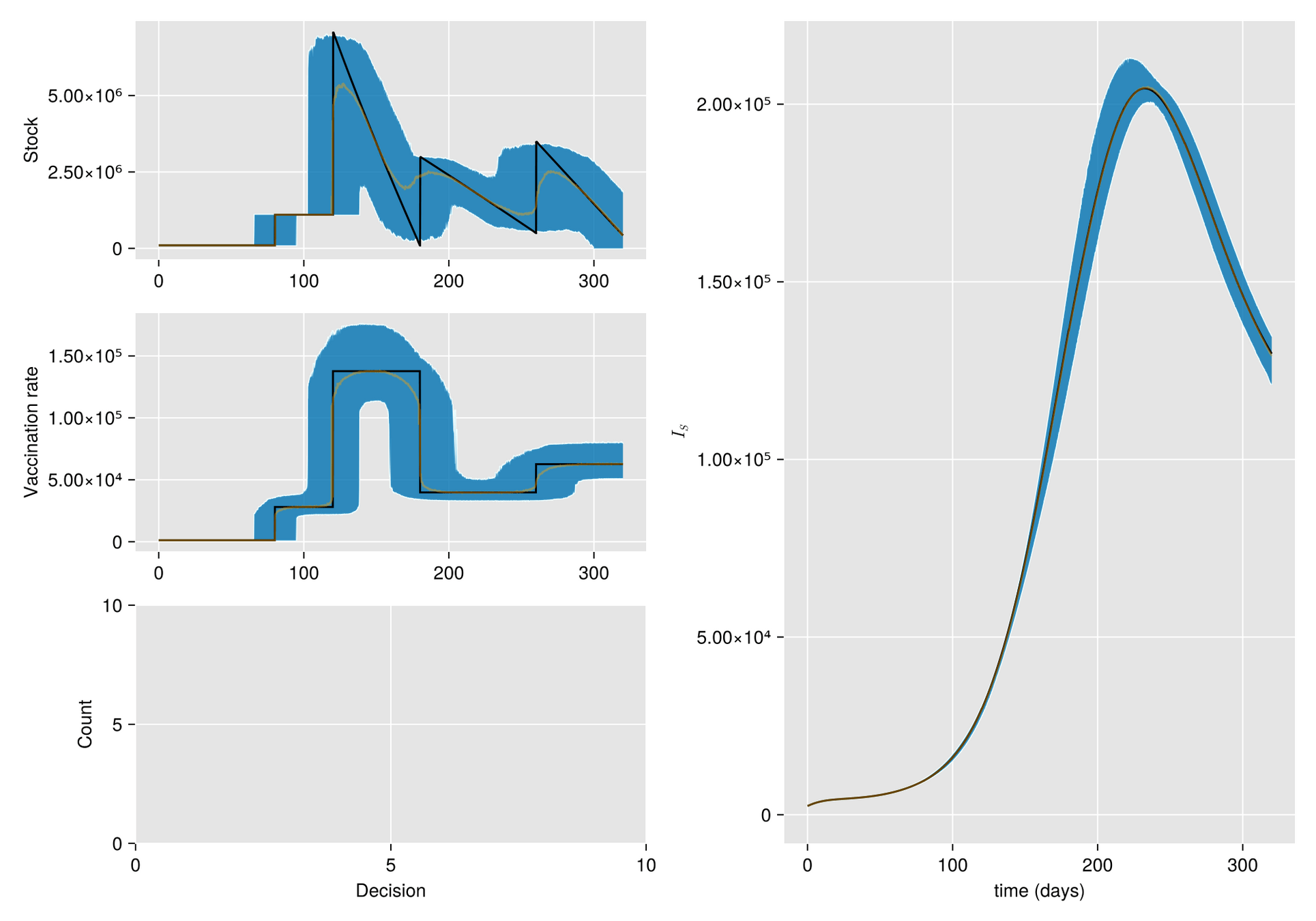
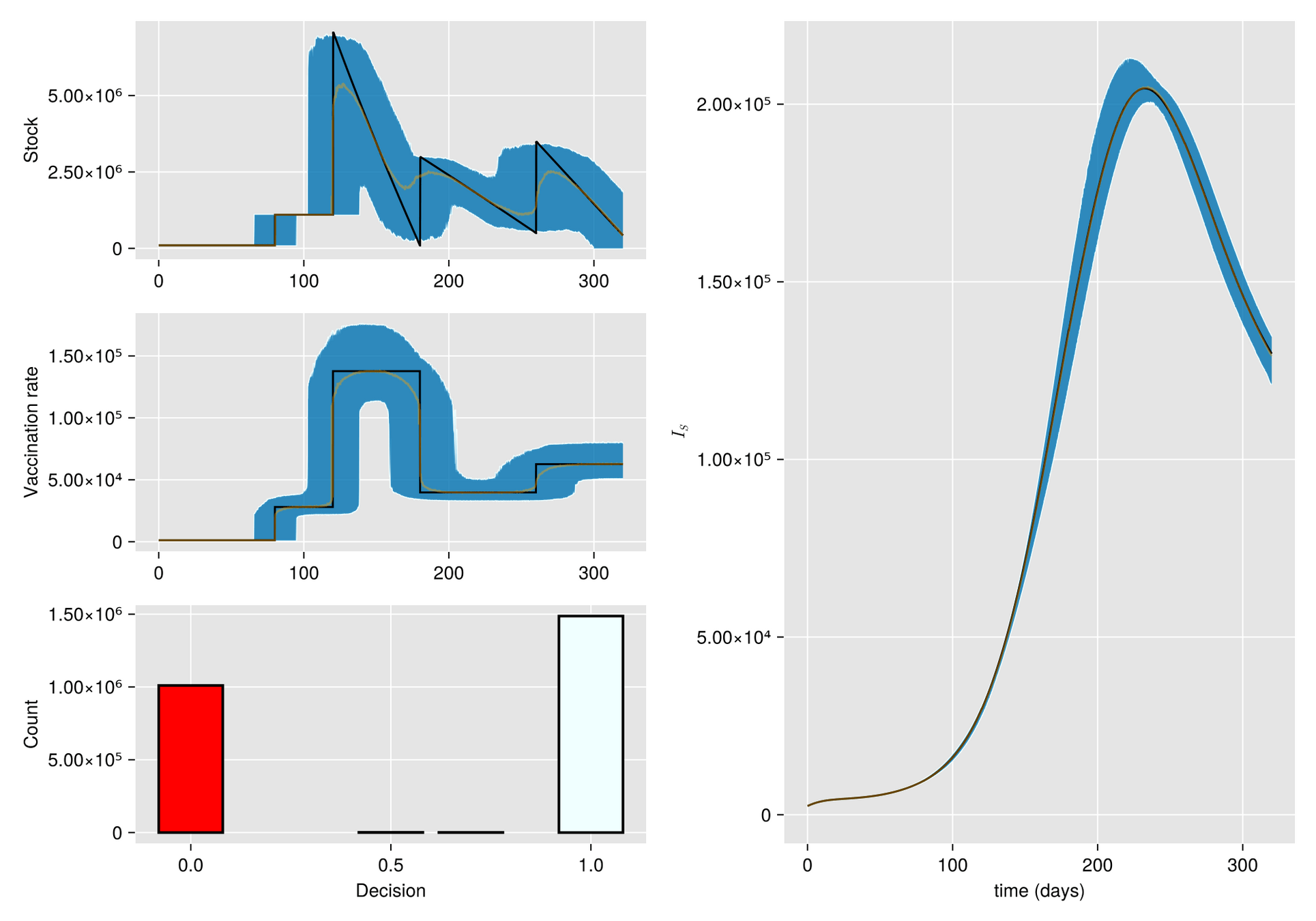
Argumento. Cuando hay escasez de vacunas, a veces la mejor respuesta es abstenerse de vacunarse, al menos por un tiempo.

Hipótesis. Bajo estas condiciones, el manejo de inventarios sufre importantes fluctuaciones aleatorias
Objetivo. Optimizar el manejo del inventario de vacunas y su efecto en una campaña de vacunación

El 13 de octubre de 2020, el gobierno Mexicano anunció un plan de entrega de vacunas por parte de Pfizer-BioNTech y otras empresas como parte de la campaña de vacunación contra el COVID-19.
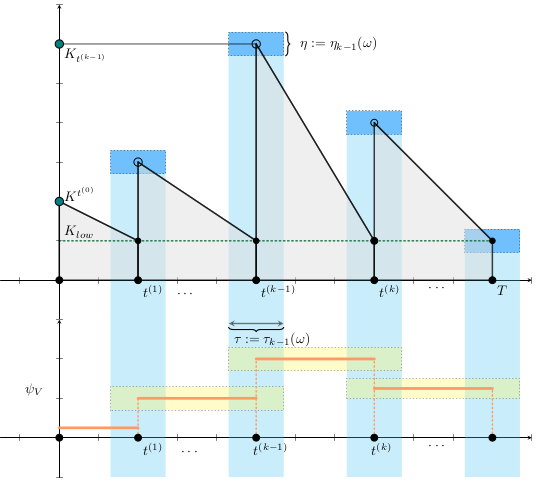
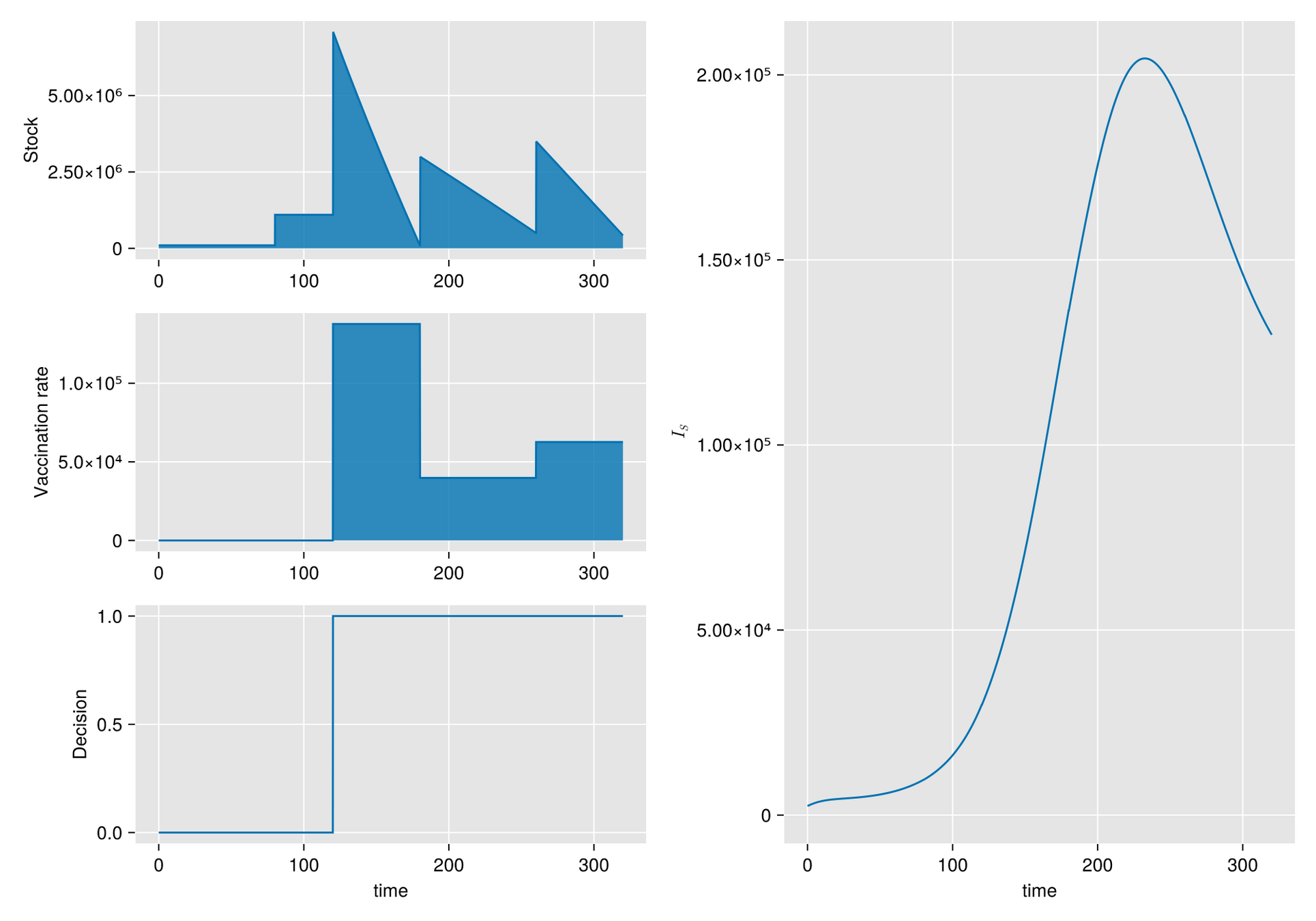
Métodos. Dado un calendario de envíos de vacunas, describimos la gestión de stock con protocolo de respaldo y cuantificamos las fluctuaciones aleatorias debido a un programa bajo alta incertidumbre.
Luego, incorporamos esta dinámica en un sistema de EDO que describe la enfermedad y evaluamos su respuesta.
1
Discovery of requirements for a project.
2
Research into the project space, competitors and the market.
3
Creating a Plan that sets the requirements for the design and build phases.
5
Review and Iterate on the designs with testing of ideas, client feedback and prototypes.
4
Design a number of iterations that capture the plans and requirements.
6
Build the project to an MVP to test and evaluate. Iterate using these learnings.
Text
Text
Control no lineal: HJB y DP
Dado
Agente
Objetivo:
Diseño
para seguir
t. q. optimizar costo
Para fijar ideas: Un modelo de población de crecimiento exponencial.
Objetivo:
Diseño
para dirigir
t. q. optimizar costo
Control no lineal: HJB and DP
Principio de opt. de Bellman
Problema de Control
t.q-
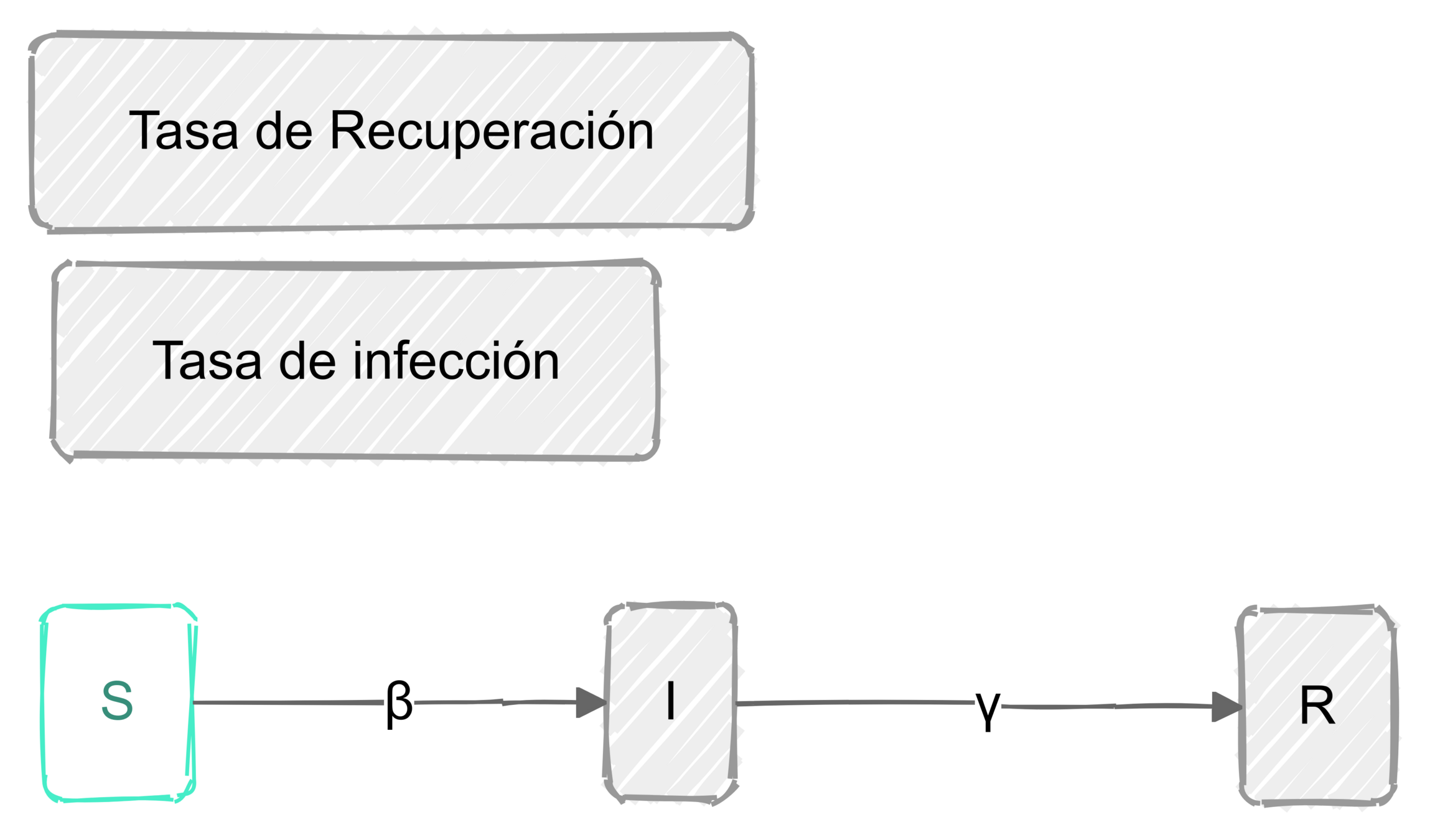


El esfuerzo invertido en prevenir o mitigar una epidemia mediante la vacunación es proporcional a la tasa de vacunación
Supongamos al inicio del brote:
Entoces estimaos el número de vacunas con
Luego, para una campaña de vacunación, sean:

Entoces estimaos el número de vacunas con
Luego, para una campaña de vacunación, sean:
La población total de Tuxtla Gutiérrez en 2020 fue de 604,147.
Entonces para vacunar el 70% de esta población en un año:
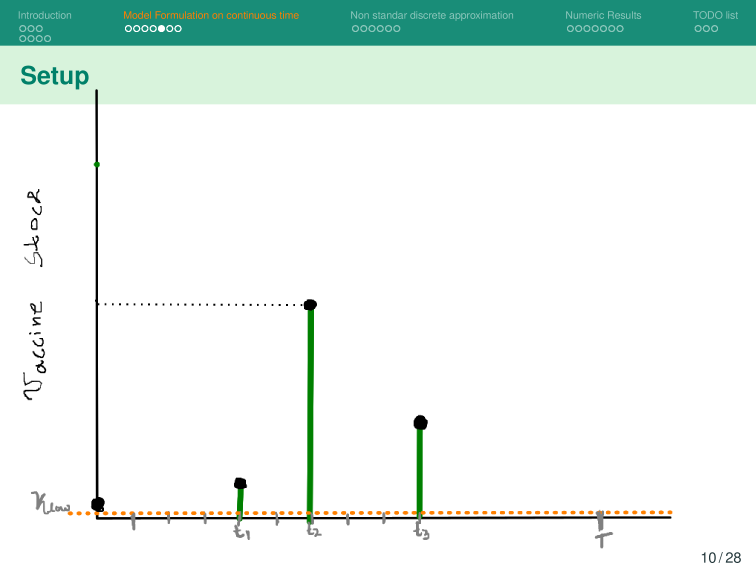
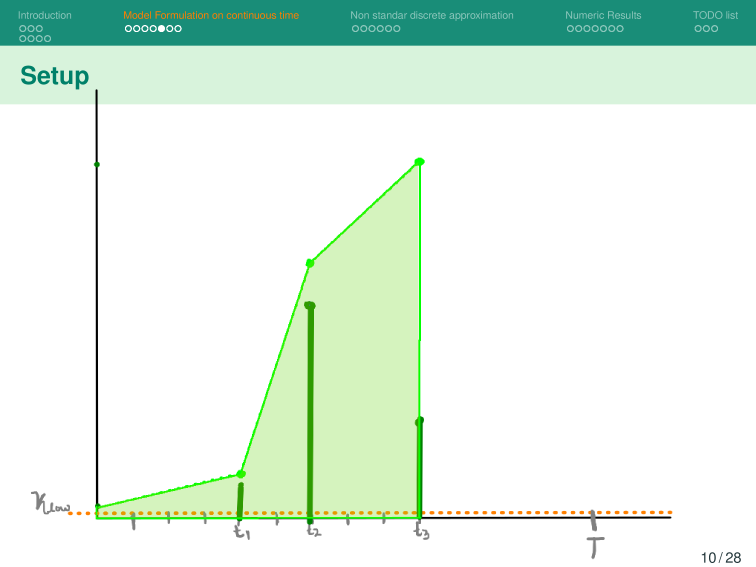
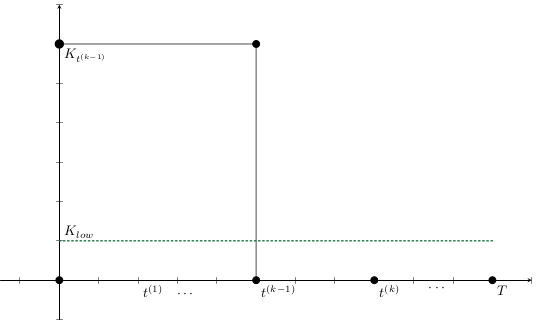
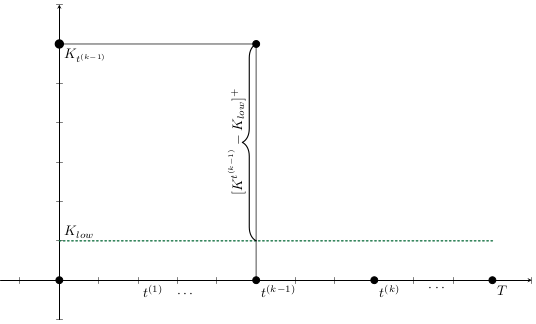
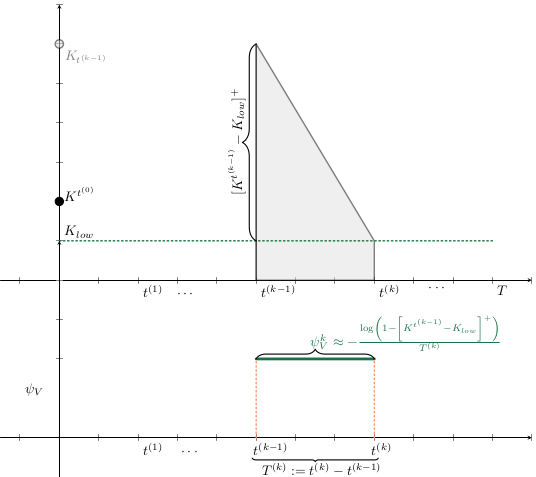
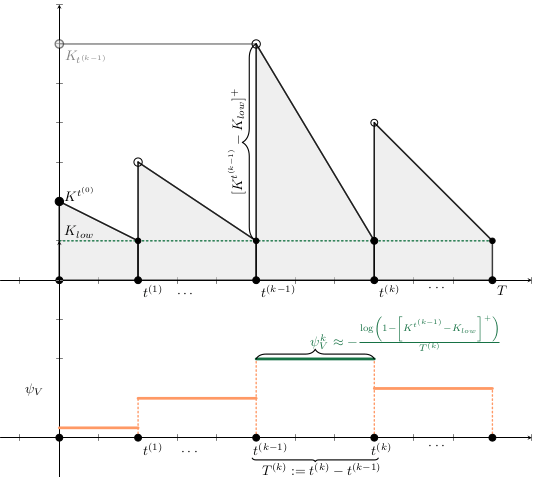
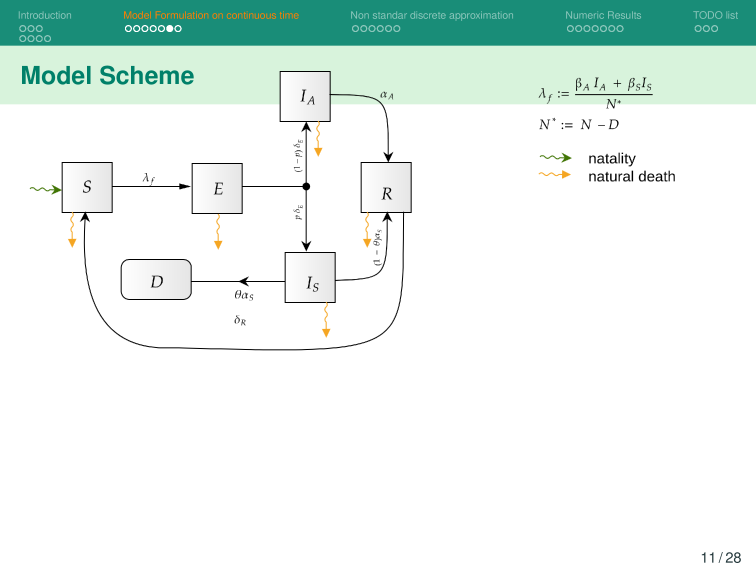
Modelo Base
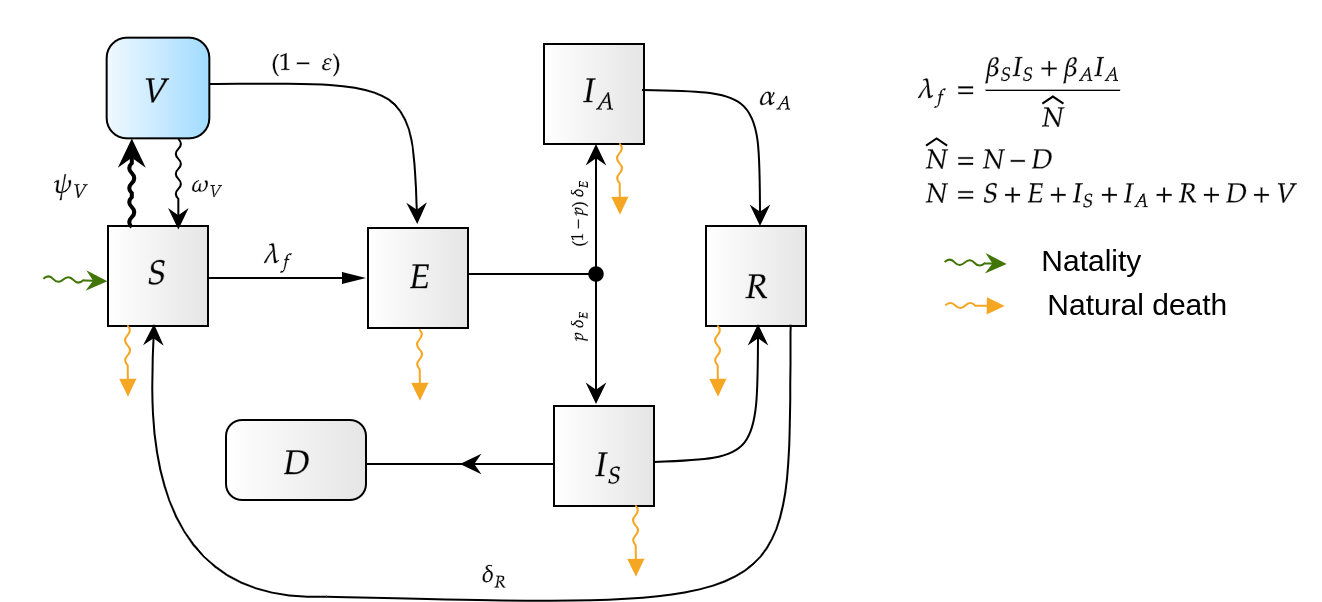





Control no lineal: HJB y DP
Dado
Agente
Objetivo:
Diseño
para seguir
t. q. optimizar costo


Agente
acción
estado
recompensa
Retorno descontado
Retorno total
Recompensa de dopamina
Agente
Control determinista
HJB (Dynamic Programming)- Maldición de la dimension
HJB(Neuro-Dynamic Programming)

Abstract dynamic programming.
Athena Scientific, Belmont, MA, 2013. viii+248 pp.
ISBN:978-1-886529-42-7
ISBN:1-886529-42-6

Rollout, policy iteration, and distributed reinforcement learning.
Revised and updated second printing
Athena Sci. Optim. Comput. Ser.
Athena Scientific, Belmont, MA, [2020], ©2020. xiii+483 pp.
ISBN:978-1-886529-07-6
Reinforcement learning and optimal control
Athena Sci. Optim. Comput. Ser.
Athena Scientific, Belmont, MA, 2019, xiv+373 pp.
ISBN: 978-1-886529-39-7

https://slides.com/sauldiazinfantevelasco/congreso_multisciplinario_fcfm-unach_2024
¡Gracias!
