Towards
Markov Decision Processes and Best Responses in Epidemic Models
A framework based on stochastic optimal control and dynamic programming.
Gabriel Salcedo-Varela, David González-Sánchez,
Saúl Díaz-Infante Velasco,
saul.diazinfante@unison.mx,
November, 2023
Red Mexicana de Biología y Matemática


Data
- Modelling
Control
To fix ideas:
- TYLCV Disease
- is spread by the insect whitefly (Bemisia tabaci)
-
How to Manage TYLCV?




-
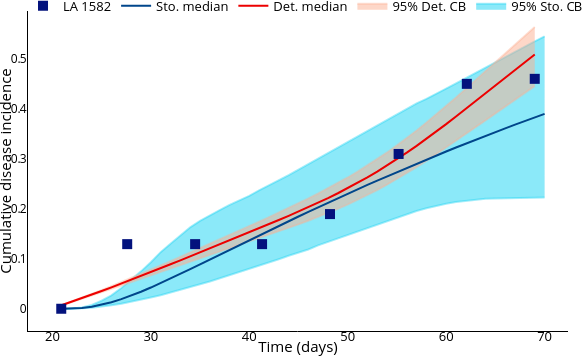
Replanting infected plants suffers random fluctuations due to is leading identification because a yellow plant is not necessarily infected.
- The protocol to manage infected plants suggests replanting neighbors. Then naturally, a farmer could randomly replant a healthy plant instead of a latent one.
- Thus strategies like fumigation with insecticide suffer random fluctuationsin their efficiency.
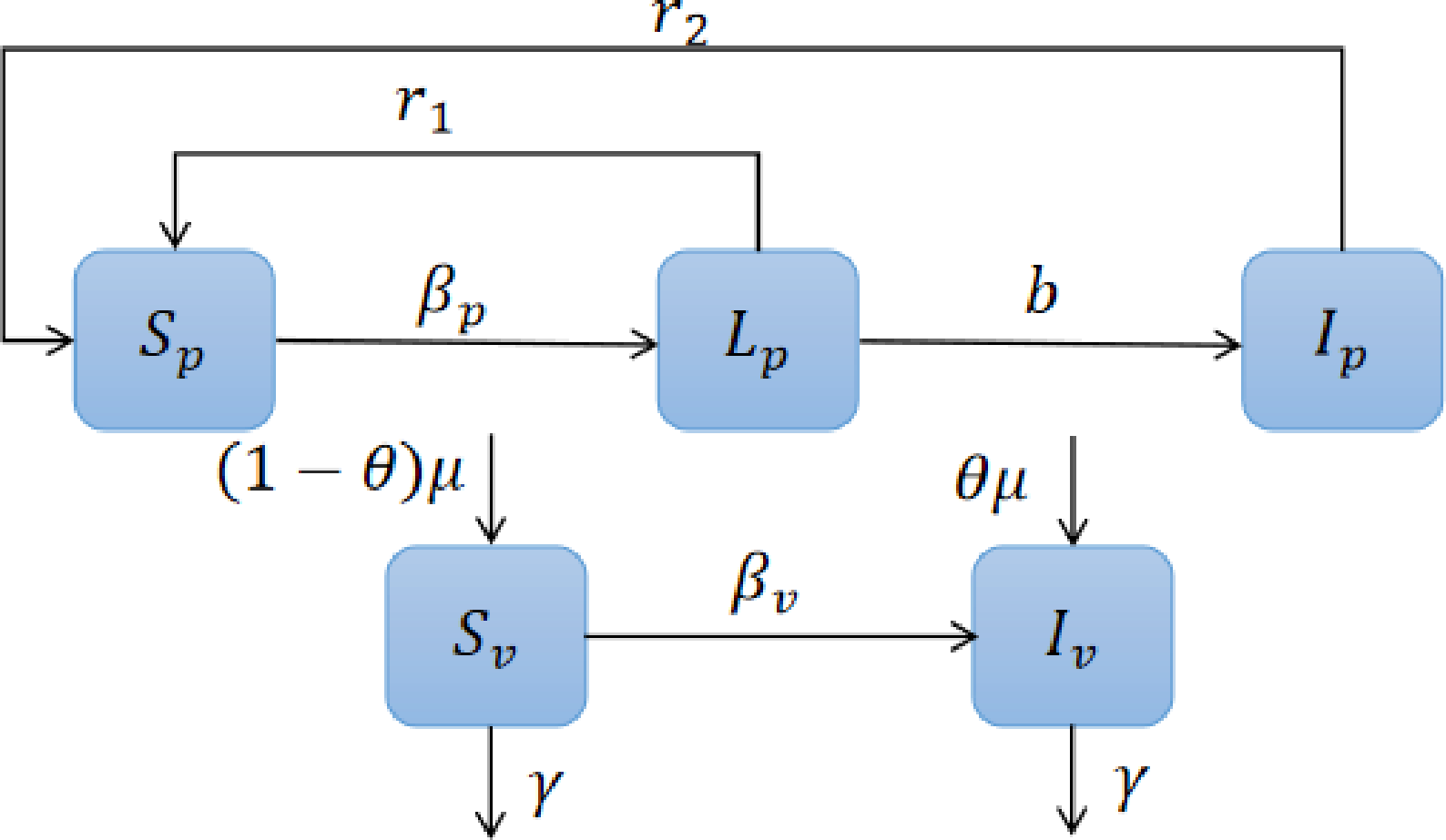
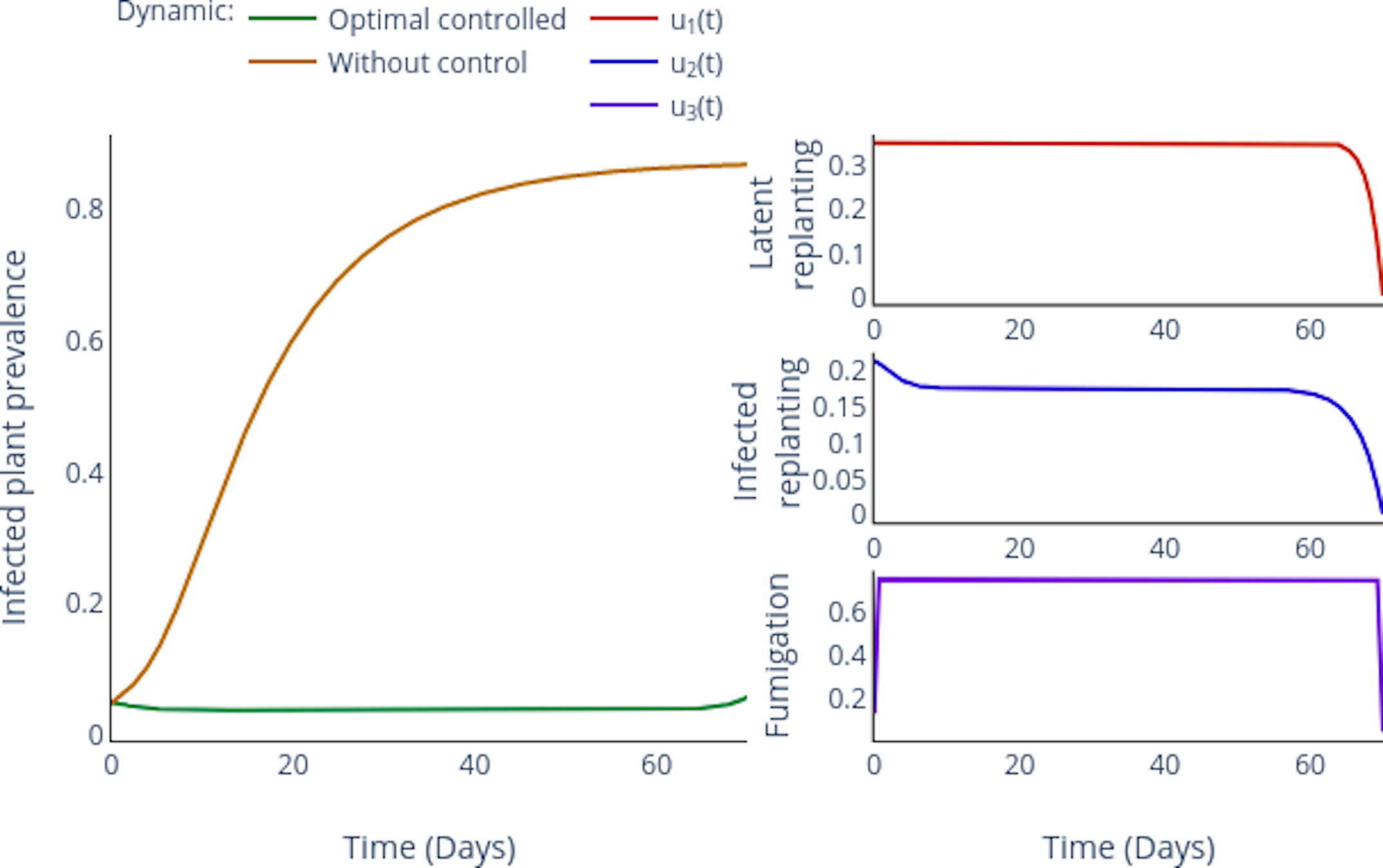
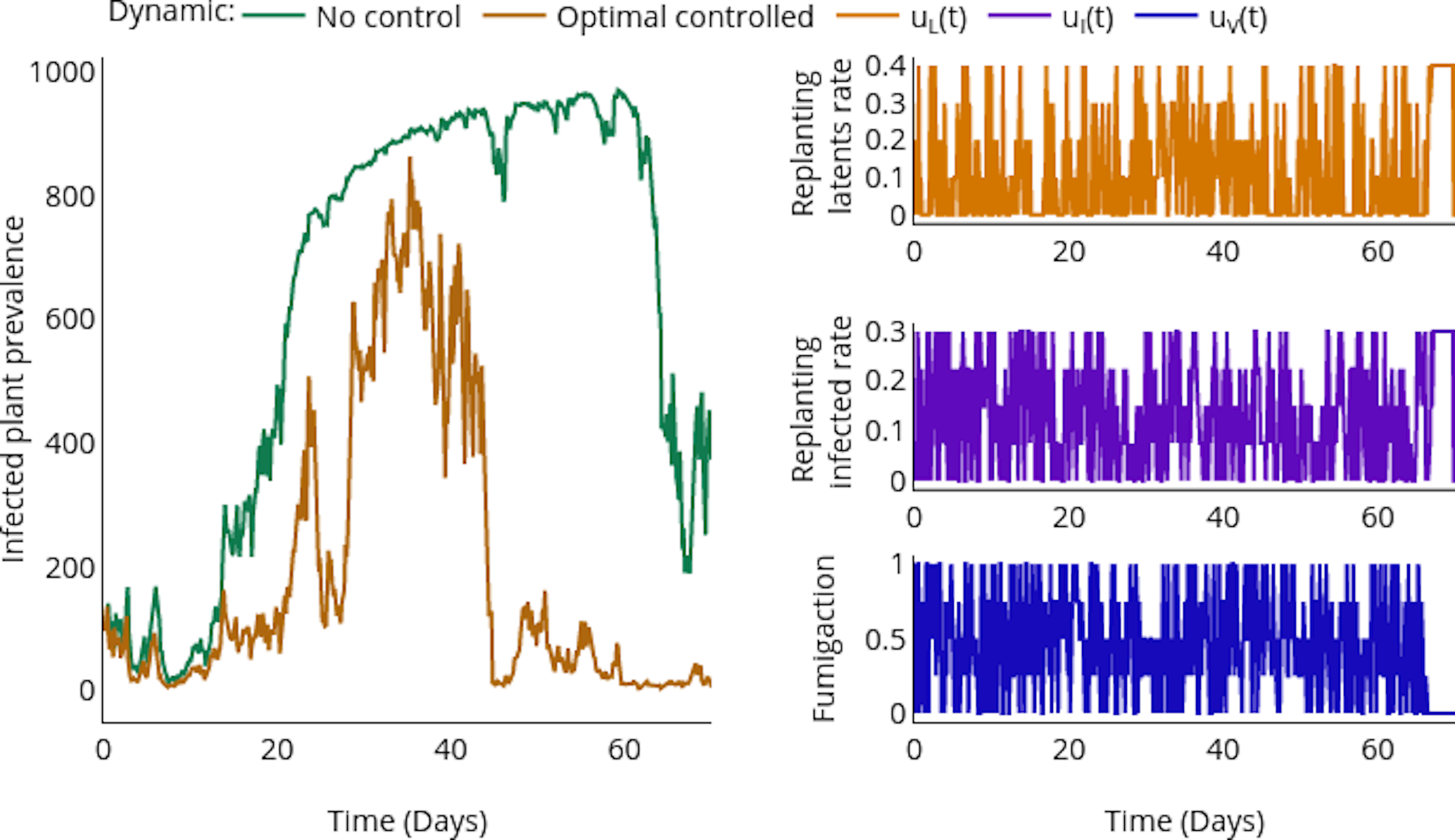
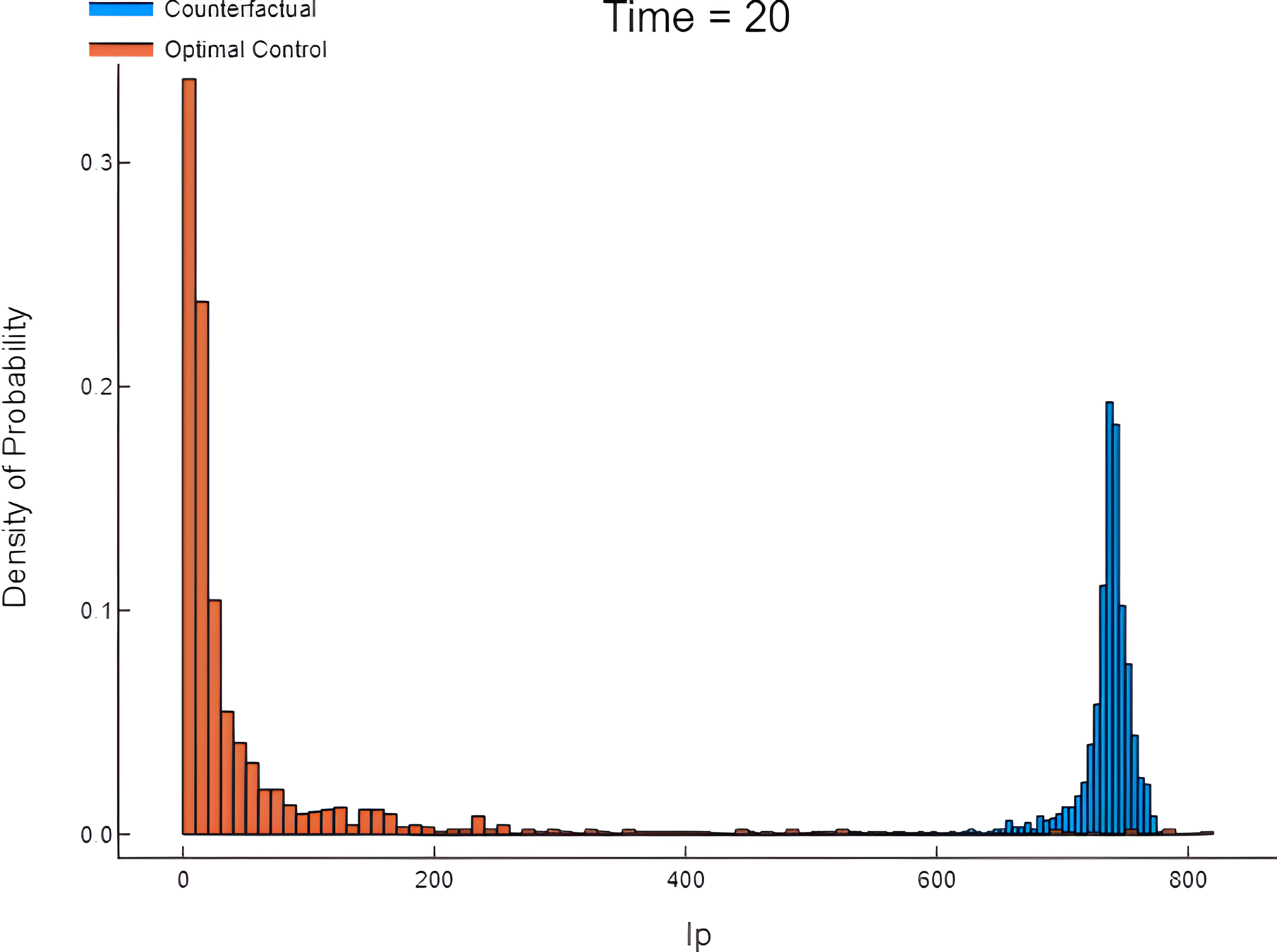
Controls
- Replanting
- Fumigation
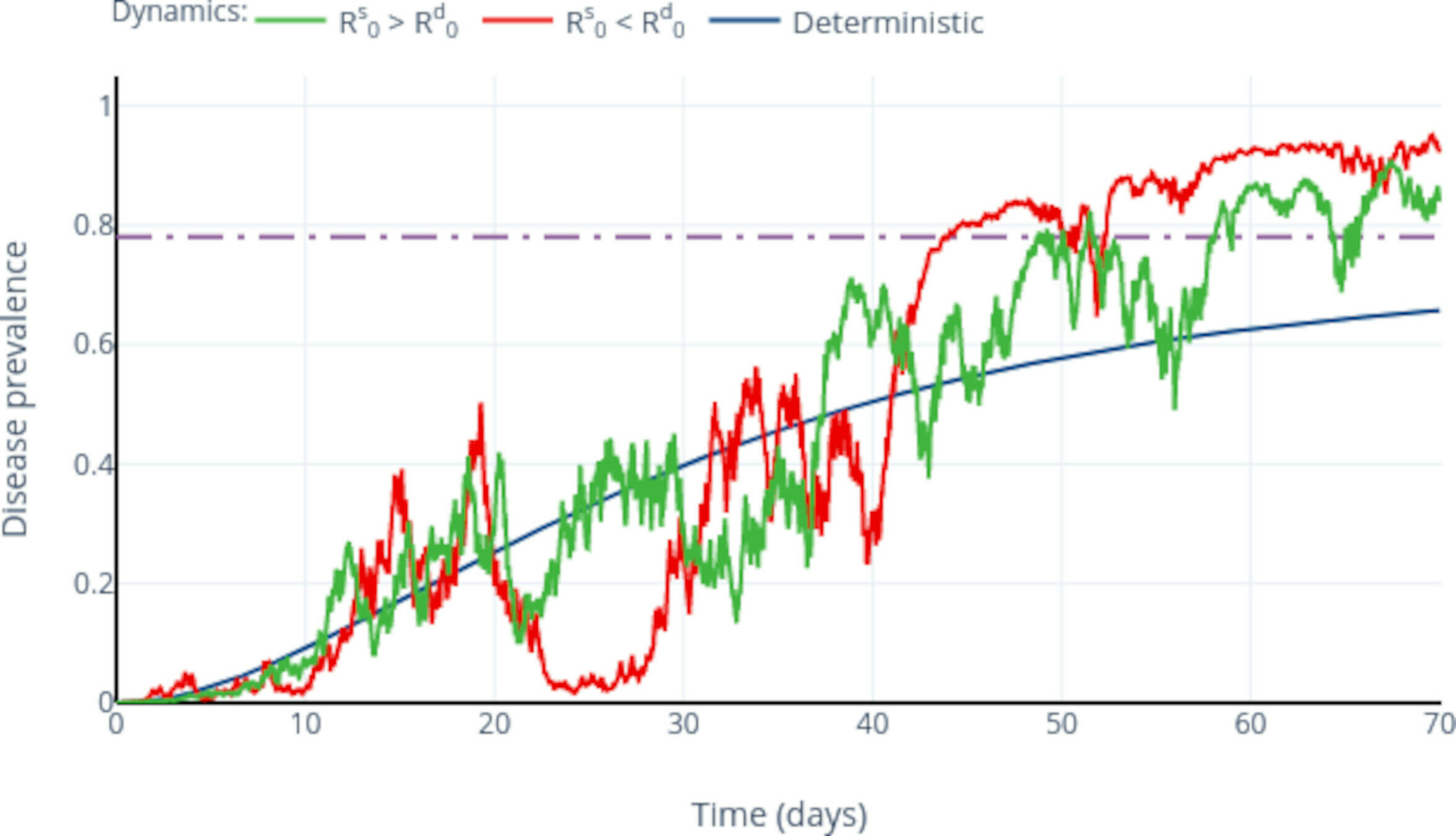
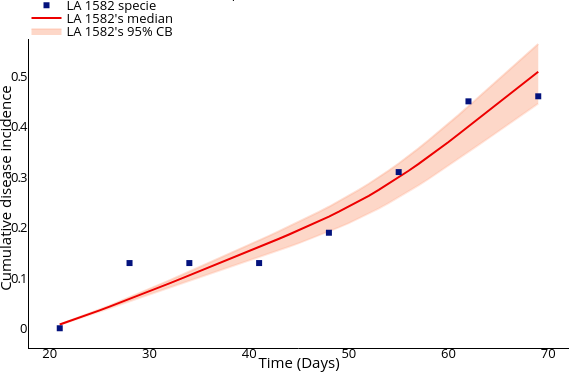
Enhancing parameter calibration through noise
const { data: unknownAssetsBalances } = useQueriesData(
unknownAssetsIds.map((id) => ({
...queries.assets.balances.addressToken(addressHash, id),
enabled: unknownAssetsIds.length > 0
}))
)
let tokensWithBalanceAndMetadata = flatMap(tokenBalances, (t) => {
const metadata = find(fungibleTokens, { id: t.id })
return metadata ? [{ ...t, ...metadata, balance: BigInt(t.balance), lockedBalance: BigInt(t.lockedBalance) }] : []
})
tokensWithBalanceAndMetadata = sortBy(tokensWithBalanceAndMetadata, [
(t) => !t.verified,
(t) => !t.name,
(t) => t.name.toLowerCase(),
'id'
])
OPC:
Value Function
HJB
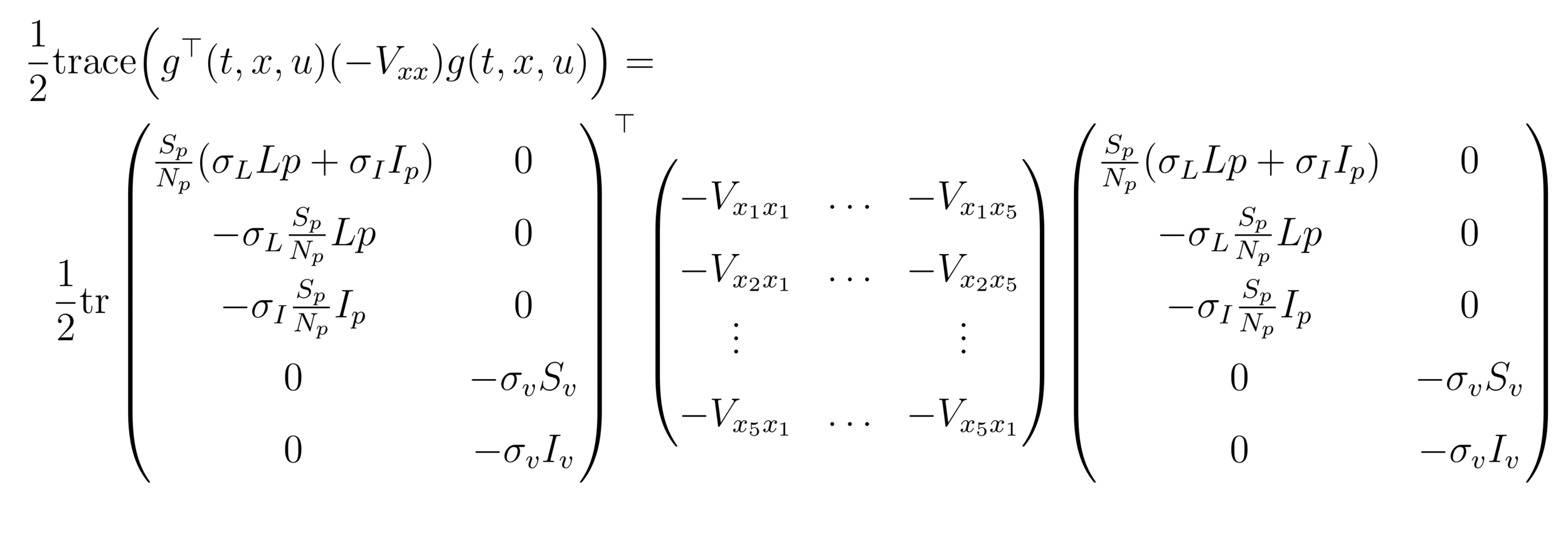
HJB (Dynamic Programming)- Course of dimensionality
HJB(Neuro-Dynamic Programming)

Abstract dynamic programming.
Athena Scientific, Belmont, MA, 2013. viii+248 pp.
ISBN:978-1-886529-42-7
ISBN:1-886529-42-6

Rollout, policy iteration, and distributed reinforcement learning.
Revised and updated second printing
Athena Sci. Optim. Comput. Ser.
Athena Scientific, Belmont, MA, [2020], ©2020. xiii+483 pp.
ISBN:978-1-886529-07-6
Reinforcement learning and optimal control
Athena Sci. Optim. Comput. Ser.
Athena Scientific, Belmont, MA, 2019, xiv+373 pp.
ISBN: 978-1-886529-39-7

Gracias
1.Salcedo-Varela, G. & Diaz-Infante, S. Threshold behaviour of a stochastic vector plant model for Tomato Yellow Curl Leaves disease: a study based on mathematical analysis and simulation. Int J Comput Math 1–0 (2022) doi:10.1080/00207160.2022.2152680.
2. Salcedo‐Varela, G. A., Peñuñuri, F., González‐Sánchez, D. & Díaz‐Infante, S. Synchronizing lockdown and vaccination policies for COVID‐19: An optimal control approach based on piecewise constant strategies. Optim. Control Appl. Methods (2023) doi:10.1002/oca.3032.
3.Diaz-Infante, S., Gonzalez-Sanchez, D. & Salcedo-Varela, G. Handbook of Visual, Experimental and Computational Mathematics, Bridges through Data. 1–19 (2023) doi:10.1007/978-3-030-93954-0_37-1.
https://slides.com/sauldiazinfantevelasco/slides_red_mex_bio_mat
