Synthetic populations and agent-based transport simulation
Replicability and application cases in France
Sebastian Hörl
20 April 2026
Master Smart Mobility

Télecom SudParis
The street in 1900
http://www.loc.gov/pictures/item/2016800172/
The street today
https://commons.wikimedia.org/wiki/File:Atlanta_75.85.jpg
The street of tomorrow?
Julius Bär / Farner
Macroscopic transport modeling
Classic four-step models
- Travel demand generated in (large) zones
- Focus on large flows between these zones
- For the morning or evening commute
- For limited user groups
- Question: Where to add capacity?
Macroscopic transport modeling
Classic four-step models
- Travel demand generated in (large) zones
- Focus on large flows between these zones
- For the morning or evening commute
- For limited user groups
- Question: Where to add capacity?

Macroscopic transport modeling
Classic four-step models
- Travel demand generated in (large) zones
- Focus on large flows between these zones
- For the morning or evening commute
- For limited user groups
- Question: Where to add capacity?

Agent-based transport modeling







0:00 - 8:00
08:30 - 17:00
17:30 - 0:00
0:00 - 9:00
10:00 - 17:30
17:45 - 21:00
22:00 - 0:00


- Individual travellers with daily activities
- Moving from one activity to another
- Simulation of the entire day
- Highly detailed interaction between travellers and services
- Multitude of (design) questions can be answered
Agent-based transport modeling
How to set up agent-based transport simulations?
* with reproducible results
* in a replicable way
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
The classic four-step model
- Goal: Analyse how changes in demand, habits, offers, and infrastructure impact the use of the transport system
- Model in four steps that answer four questions:
- Where do travellers come from?
- Where do they go to?
- How do they perform these trips (transport modes)?
- How heavily are services and infrastructure utilized?
Trip generation
Trip distribution
Mode choice
Traffic assignment
The classic four-step model
Trip generation
Trip distribution
Mode choice
Traffic assignment
-
Question: Where do travellers come from?
-
Goal: Obtain a number of originating trips for a number of zones defined in the study area
- Number of generated trips may depend on the total population, the age distribution in a zone, the distribution of job types, ...
- Usually focus on the morning peak hour
- "How many people go to work at around 8pm?"
- Sometimes also evening peak, midday offpeak, evening off-peak
- Modelling task: Set up a model that yields the number of originating trips at a certain time given specific inputs per origin zone
The classic four-step model
Trip distribution
Mode choice
Traffic assignment
Trip generation
-
Question: Where do the generated travellers go to?
-
Goal: Obtain a matrix of movements between all zones (origins) to all other zones (destinations)
- Flows between two zones may be affected by
- how well the two zones are connected
- how attractive it is to go to another zone
- For instance, often, the amount and quality of employment in a zone determines if the zone is attractive for commuters
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
The classic four-step model
Trip generation
Trip distribution
Mode choice
Traffic assignment
-
Question: How do people go from one zone to another?
-
Goal: Understand how people decide which mode of transport (and which route) they choose to go from A to B
- Mode choice is heavily impacted by
- travel time
- monetary cost
- number of transfers (public transport)
- waiting time (public transport, on-demand transport)
- ...
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
The classic four-step model
Trip generation
Trip distribution
Mode choice
Traffic assignment
-
Question: How is the infrastructure impacted by travel decisions?
-
Goal: Find out how many cars make use of the road network or how many travellers the public transport services and how much time it takes to travel
- The last modelling step helps to understand if changes in generation, distribution or mode choice lead to saturation of the system
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
The classic four-step model
Trip generation
Trip distribution
Mode choice
Traffic assignment
- It is possible to run the model in an iterative way:
- Accessibility of a zone may impact how likely people are to live there (generation)
- Travel times between two zones may impact how likely people are to work in a specific area (distribution)
- Travel times between two zones may impact which modes of transport people use to move between them (mode choice)
- Accessibility of a zone may impact how likely people are to live there (generation)
- In such a setting, the model is run in a feedback loop until key indicators (travel times, flows, ...) stabilize, demand and supply go then into equilibrium
Step 1: Trip generation
- Modelling task: Set up a model that yields the number of originating trips at a certain time given specific inputs per origin zone
Trip generation
Trip distribution
Mode choice
Traffic assignment
Step 1: Trip generation
- Modelling task: Set up a model that yields the number of originating trips at a certain time given specific inputs per origin zone
Trip generation
Trip distribution
Mode choice
Traffic assignment
Characteristics of zone i
Step 1: Trip generation
- Modelling task: Set up a model that yields the number of originating trips at a certain time given specific inputs per origin zone
Trip generation
Trip distribution
Mode choice
Traffic assignment
Characteristics of zone i
Model
Step 1: Trip generation
- Modelling task: Set up a model that yields the number of originating trips at a certain time given specific inputs per origin zone
Trip generation
Trip distribution
Mode choice
Traffic assignment
Generated trips for zone i
Characteristics of zone i
Model
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
Population in zone i
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
Population in zone i
Growth factor
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
Population in zone i
Growth factor
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
- How do we estimate the parameter?
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
Population in zone i
Growth factor
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
- How do we estimate the parameter?
Reference value
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
Population in zone i
Growth factor
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
- How do we estimate the parameter?
Linear regression
Ordinary least squares
Step 1: Trip generation
Trip generation
Trip distribution
Mode choice
Traffic assignment
Population in zone i
Growth factor
- Example: Growth factor model
- More complex models (ML, DL, ...) exist
- First approach:
- How do we estimate the parameter?
Linear regression
Ordinary least squares
Step 1: Trip generation
- Let's test our model!
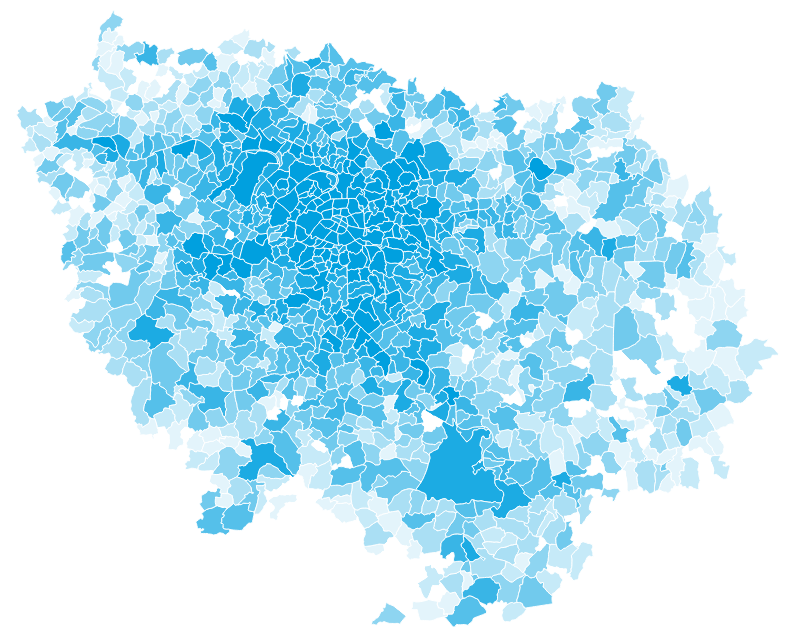
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092


Step 1: Trip generation
- Let's test our model!
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092
Step 1: Trip generation
- Let's test our model!
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092
Model results

Step 1: Trip generation
- Let's test our model!
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092
Difference

Step 1: Trip generation
- Let's test our model!
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092

Step 1: Trip generation
- Let's test our model!
Population in Île-de-France by municipality
Source: INSEE RP
Commuters in Île-de-France
Source: INSEE RP
Source: INSEE MOBPRO
12,262,544
5,420,092
Are we happy with this model?
Step 1: Trip generation
- Next try:

Source: INSEE
Population by socio-professional category in Île-de-France
CSP = Catégorie socio-professionelle
The socio-professional category is a common statistical tool in France to perform analyses based on different employment levels in France with eight categories
Step 1: Trip generation
- Next try:
Source: INSEE
Population by socio-professional category in Île-de-France
CSP = Catégorie socio-professionelle
The socio-professional category is a common statistical tool in France to perform analyses based on different employment levels in France with eight categories
Population by CSP
Step 1: Trip generation
- Next try:
Source: INSEE
Population by socio-professional category in Île-de-France
CSP = Catégorie socio-professionelle
The socio-professional category is a common statistical tool in France to perform analyses based on different employment levels in France with eight categories
Population by CSP
Growth factor by CSP
Step 1: Trip generation
- Let's test our model!
Intellectual professions
(CSP 3)
Workers (CSP 6)
Employees (CSP 5)



Step 1: Trip generation
- Let's test our model!
Diff. CSP Model
Commuters in Île-de-France
Source: INSEE MOBPRO
Diff. Simple model

Step 1: Trip generation
- Let's test our model!
Diff. CSP Model
Commuters in Île-de-France
Source: INSEE MOBPRO

Step 1: Trip generation
- We can now, for instance, apply the data on a smaller zoning system if we know the number of people in a certain CSP living there. Example: IRIS system.

Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
Origin characteristics
Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
Origin characteristics
Destination characteristics
Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
Origin characteristics
Destination characteristics
Model
Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
- Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
Origin characteristics
Destination characteristics
Model
Flow
Step 2: Trip distribution
Trip distribution
Mode choice
Traffic assignment
Trip generation
Origin characteristics
Destination characteristics
Model
Flow
-
Modelling task: Set up a model that takes into account characteristics of an origin zone, a destination zone, how well they are connected and which yields the expected flow between these zones.
- Flow models are mainly concerned with large flows, for instance, commuters going to work in the peak hour
Step 2: Trip distribution
- We can imagine F as a matrix where rows indicate the origins and columns the destinations
- Row sums are the outflows of the origin zones
- Column sums are the inflows of the destination zones

Trip distribution
Mode choice
Traffic assignment
Trip generation
Step 2: Trip distribution
- We can imagine F as a matrix where rows indicate the origins and columns the destinations
- Row sums are the outflows of the origin zones
- Column sums are the inflows of the destination zones
- Let's define
Outflow / Origins
Inflow / Destinations
Step 2: Trip distribution
- We can imagine F as a matrix where rows indicate the origins and columns the destinations
- Row sums are the outflows of the origin zones
- Column sums are the inflows of the destination zones
Outflow / Origins
Inflow / Destinations
- Let's define
- We may use a trip generation model to generate the row sums, and we may use a trip attraction model to generation the column sums
Step 2: Trip distribution
- Example: Zonal flows in Île-de-France
- 1,287 municipalities in total
- 1,656,369 combinations
- 123,787 combinations are available (7.4%)
Source: INSEE MOBPRO
Paris 13e
Alfortville
Melun



Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
Production term
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
Production term
Attraction term
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
Production term
Attraction term
Friction / Resistance term
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
Production term
Attraction term
Friction / Resistance term
- Production term: Weighs how much trips are produced by a zone
- Attraction term: Weighs how attractive a zone is for a trip to arrive
- Friction term: Quantifies how are it is to get from one zone to another (road, transit, natural obstacles, ...)
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
- The friction term is often estimated stand-alone and upfront
- Simple approach: Friction depends on the distance between two zones
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
- The friction term is often estimated stand-alone and upfront
- Simple approach: Friction depends on the distance between two zones
The probability of observing a commute between two municipalities in Île-de-France decreases exponentially with the distance between these municipalities

Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
- The friction term is often estimated stand-alone and upfront
- Simple approach: Friction depends on the distance between two zones
The probability of observing a commute between two municipalities in Île-de-France decreases exponentially with the distance between these municipalities
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
- The friction term is often estimated stand-alone and upfront
- Simple approach: Friction depends on the distance between two zones
- More complex friction terms are possible and are widely used
- Travel time
- Monetary cost
- Others
Step 2: Trip distribution
- Gravity model: The most commonly used model is the Gravity model with the following form:
- The use of the gravity model depends on which data is available. The single-constrained gravity model assumes that we have reference data for the outflow of certain zones.
- Combing the gravity model with
- Gives
- And
- This fixed expression for P can be inserted in the main model from above.
Step 2: Trip distribution
- Single-constrained gravity model
- Any choice for A will now by design of the model yield the correct origin flows
Step 2: Trip distribution
- Single-constrained gravity model
-
Any choice for A will now by design of the model yield the corrent origin flows
- Simple example: The attraction of a zone is dependent on the employees working in that zone
Step 2: Trip distribution
- Single-constrained gravity model
-
Any choice for A will now by design of the model yield the corrent origin flows
- Simple example: The attraction of a zone is dependent on the employees working in that zone
Emploiment in zone j
Step 2: Trip distribution
- Single-constrained gravity model
-
Any choice for A will now by design of the model yield the corrent origin flows
- Simple example: The attraction of a zone is dependent on the employees working in that zone
Emploiment in zone j
Model parameter
Step 2: Trip distribution
- Single-constrained gravity model
Emploiment in zone j
Model parameter
-
Any choice for A will now by design of the model yield the correct origin flows
- Simple example: The attraction of a zone is dependent on the employees working in that zone
- We use the friction model as defined before
Step 2: Trip distribution
- Single-constrained gravity model
- Given some reference flows on the territory, we may now fit the parameter
- Alternatively, we may have some of the destination flows as data to fit
(used in the following example)
Step 2: Trip distribution
- Example: Île-de-France

Step 2: Trip distribution
- Example: Île-de-France
Alfortville

Data
Model

Step 2: Trip distribution
- Sometimes, we may also know the destination flows
- The inflow constraint can be integrated analogously to the origins
- This leads to the double-constrained gravity model
- The values of A and P are fully determined by the observed origin and destination flows. By design, the model produces flow matrices F that have the correct row and column sums.
- The values of A and P are obtained by evaluating the two right-mode functions iteratively until the values stabilize.
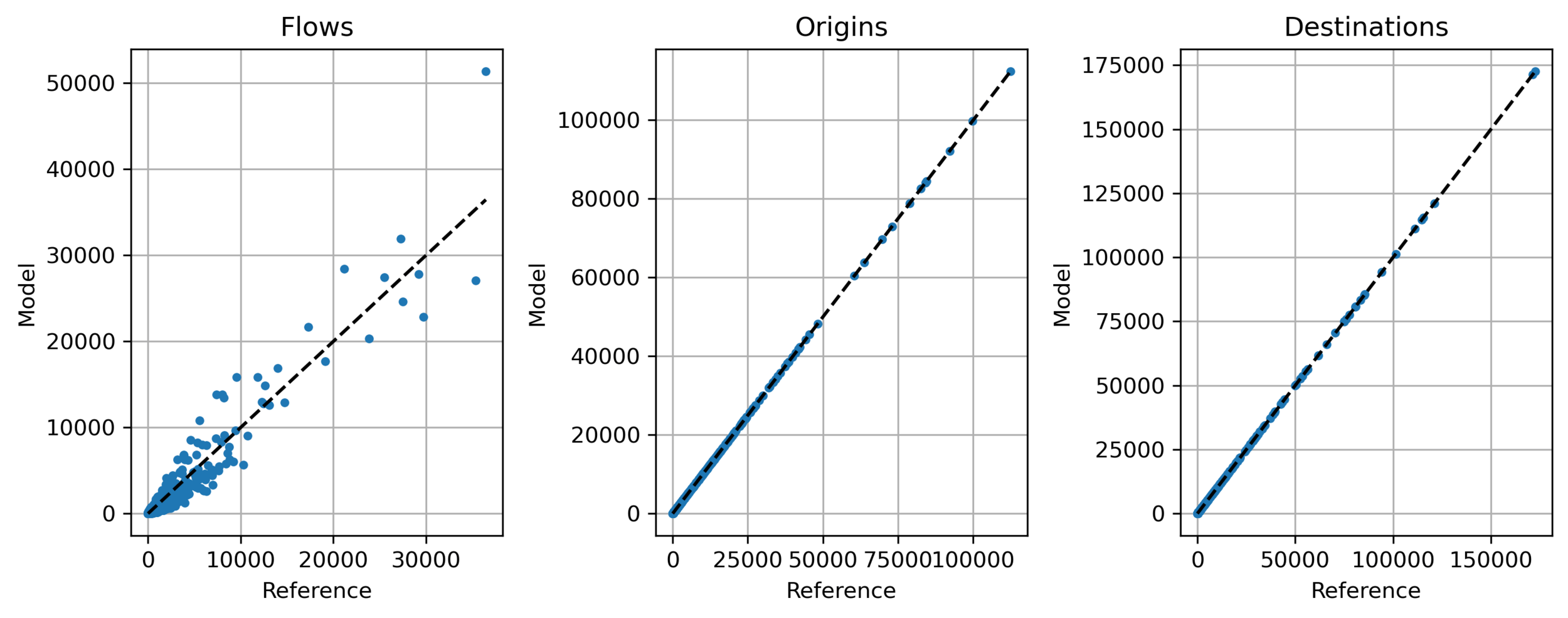
Step 2: Trip distribution
- Example: Île-de-France
Step 3: Mode choice
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
Step 3: Mode choice
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
Step 3: Mode choice
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
Characteristics of alternative k
Step 3: Mode choice
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
Characteristics of alternative k
Probability of choosing k
Step 3: Mode choice
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model, which, given a set of alternative ways of going from A to B with their characteristics, yield the probability of either alternative being chosen.
Characteristics of alternative k
Probability of choosing k
Model
Step 3: Mode choice


Step 3: Mode choice
Step 3: Mode choice


Step 3: Mode choice
Step 3: Mode choice
Step 3: Mode choice
Step 3: Mode choice


Step 3: Mode choice
Step 3: Mode choice
Step 3: Mode choice
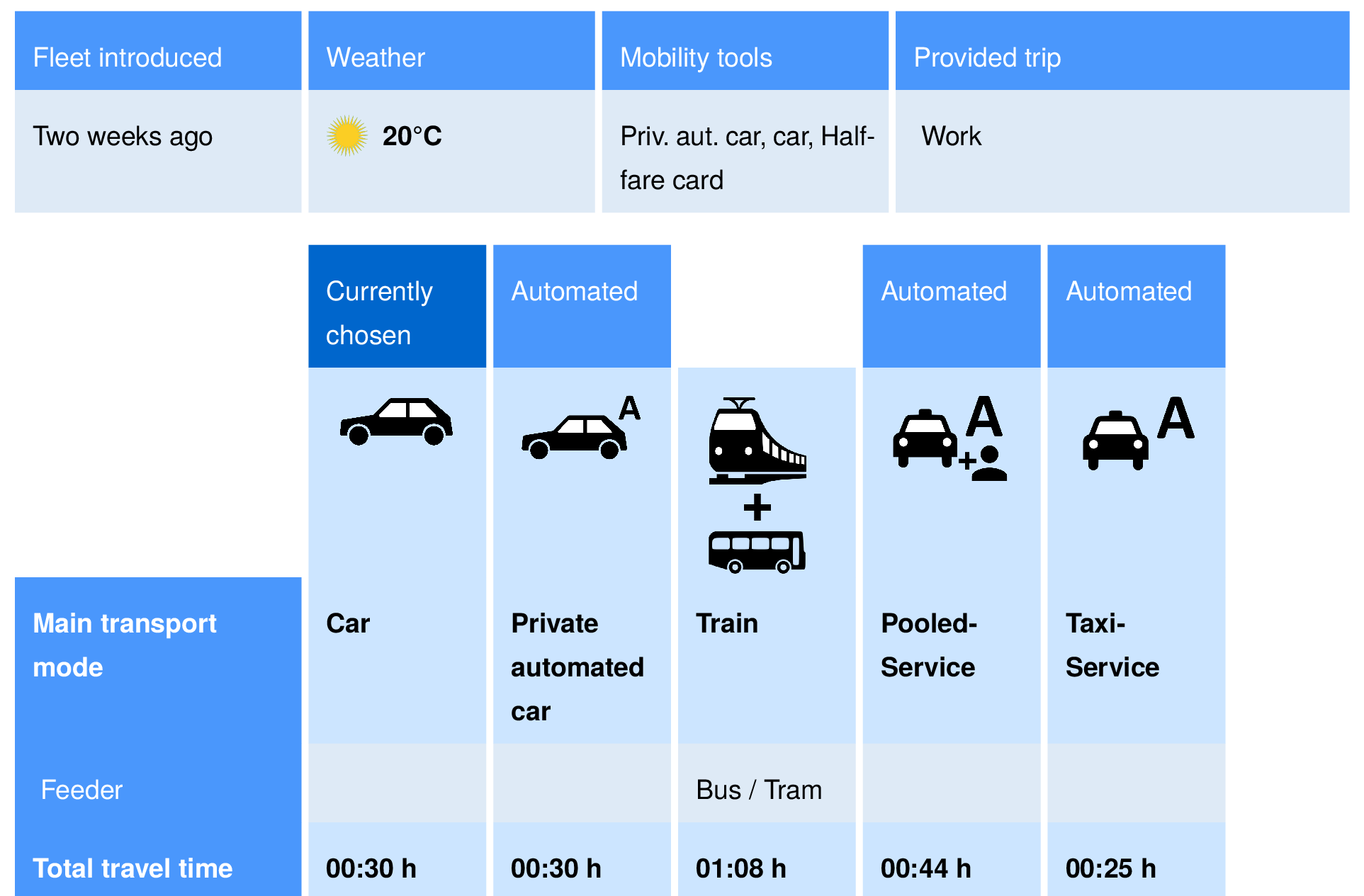
- Which option will I choose?
- Which option do people statistically choose?
Step 3: Mode choice
Source: Felix Becker, Institute for Transport Planning and Systems, ETH Zurich.
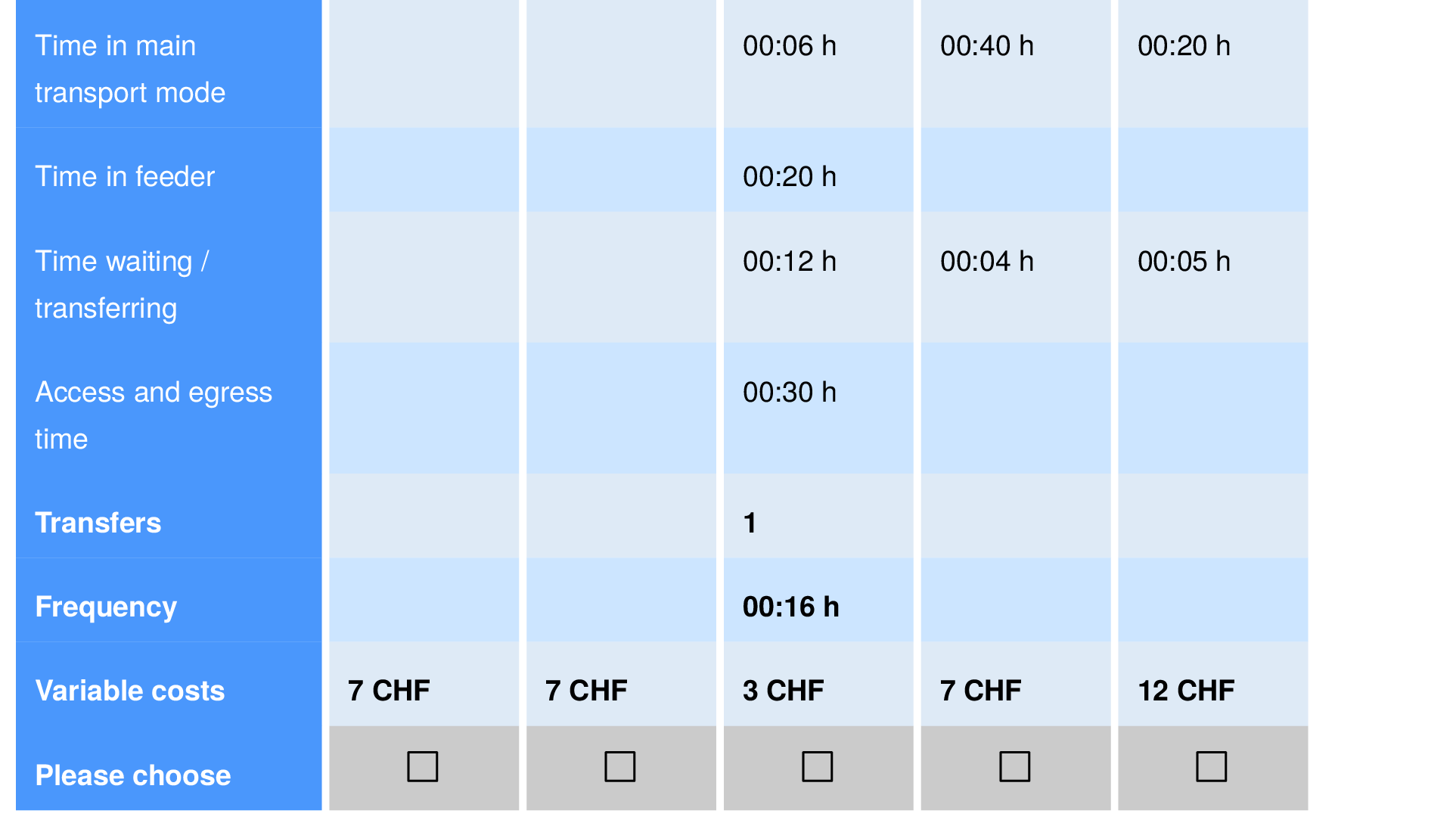
- A common source for choice models is survey data
Step 3: Mode choice
- A common source for choice models is survey data
- They are performed in a pivot design: Each person gets to view various combinations of values.
- Difficulty I: How to design the survey?
- How many questions are too many?
- How to cover the whole range of potential values?
- Difficulty II: Respondents
- How to ensure that the survey is representative?
- How to make sure the relevant user groups are covered?
- Difficulty III: Misbehaviour
- What if somebody always selects random options?
- What if somebody always selects the first option?
- What if answers are missing?
Step 3: Mode choice
- Alternative source to Stated Preference data (SP) is Revealed Preference data (RP)
- In Revealed Preference experiments, the actual choices of the persons are tracked
- What do we observe?
- SP: Hypothetic choices of the respondents
- RP: Actual choices of the respondents
- What is known?
- SP: Full knowledge about all choices
- RP: Only knowledge about the taken choice, all alternatives need to be reconstructed!
Step 3: Mode choice
- Alternative sources are data sets in which people have been asked about the trips they did during one day
- Alternatives to the chosen option need to be generated a posteriori
- Île-de-France
- Enquête Globale de Transport (EGT)
- (2010, on request); (2015 on yet published)
- Nantes, Lyon, Lille, ...
- Enquête Déplacements Grand Territoire (EDGT)
- Available for various years depending on city
- Sometimes publicly accessible as open data (Nantes, Lille)
- France
- Enquête Nationale Transports et Déplacements (ENTD)
- From 2008, available as open data
- Enquête Nationale Transports et Déplacements (ENTD)
Step 3: Mode choice
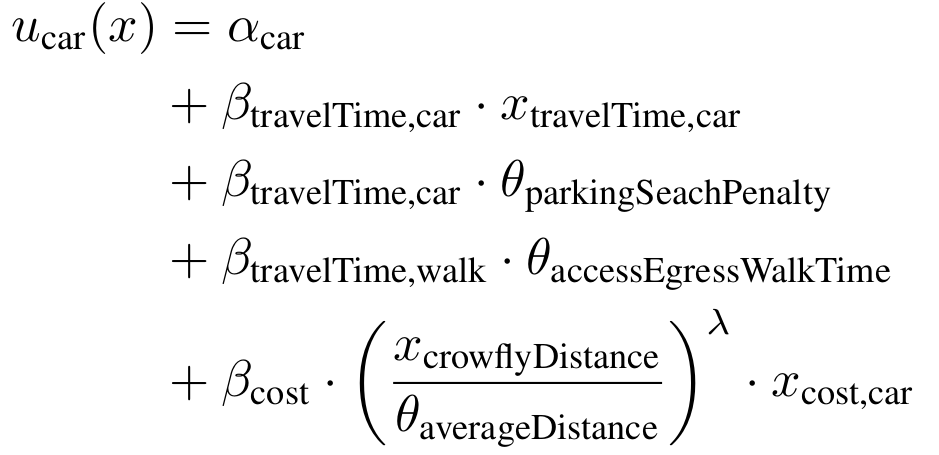
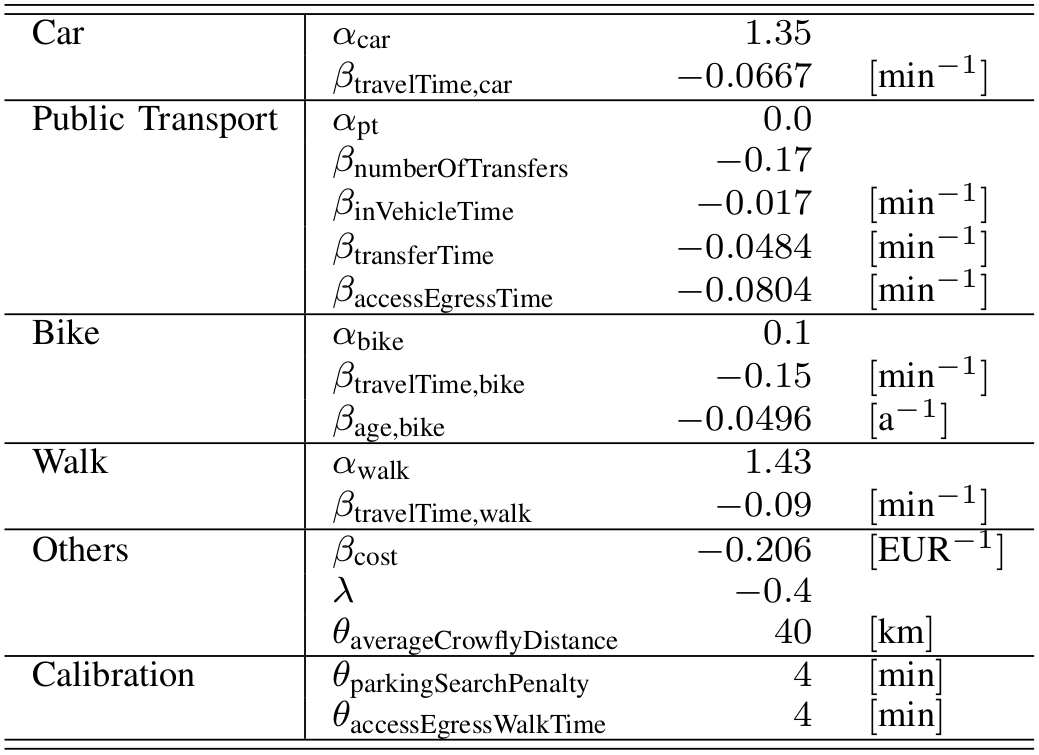
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
Value of variable q
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
Influence weight of variable q
Value of variable q
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
Influence weight of variable q
Value of variable q
Systematic utility of alternative k for decision-maker i
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
- In general, we have K alternatives, we have Q variables (or inputs, like travel time, monetary costs, number of transfers, ...), and N decision-makers (observations)
- Systematic utilities are also called generalized costs
Systematic utility of alternative k for decision-maker i
Influence weight of variable q
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
- A rational decision-maker (homo oeconomicus) would then choose the alternative that has the highest utility!
Systematic utility of alternative k for decision-maker i
Influence weight of variable q
Step 3: Mode choice
- A common mode choice model is the multinomial logit model
- The idea is that the utility of an alternative can be quantified:
- A rational decision-maker (homo oeconomicus) would then choose the alternative that has the highest utility!
Systematic utility of alternative k for decision-maker i
Influence weight of variable q
Chosen alternative
Step 3: Mode choice
-
Example: Choice between two public transport connections
Connection A
Connection B
Step 3: Mode choice
-
Example: Choice between two public transport connections
Connection A
Connection B
-0.6
-1.0
Step 3: Mode choice
-
Example: Choice between two public transport connections
Connection A
Connection B
-0.6
-1.0
-0.6 * 20 - 1.0 * 1 = -13
-0.6 * 30 - 1.0 * 0 = -19
Step 3: Mode choice
-
Example: Choice between two public transport connections
Connection A
Connection B
-0.6
-1.0
-0.6 * 20 - 1.0 * 1 = -13
-0.6 * 30 - 1.0 * 0 = -19
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Parameters we want to find
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Parameters we want to find
Characteristics of all alternatives
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Parameters we want to find
Characteristics of all alternatives
Systematic utility per alternative
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Parameters we want to find
Characteristics of all alternatives
Systematic utility per alternative
Actual choice taken by the person
Step 3: Mode choice
- In vector form, the utility maximization model can be written as:
- To find the correct parameters, would need:
- N observations of decisions taken
- Each observation states a chosen alternative
- Each observation states the respective choice characteristics
- The task is then:
Find
such that
!
Parameters we want to find
Characteristics of all alternatives
Systematic utility per alternative
Actual choice taken by the person
No exact solution can exist!
Step 3: Mode choice
-
Idea: No exact solution exists, because human decisions are partly random. What if we introduce randomness into our model?
- Based on our systematic utility, we introduce a random utility
- We have added an independent random error term over all alternatives for all decision-makers
- A straightforward choice would be to use a Normal distribution
- Mathematically, we still select the best alternative, but is this better?
- In any case, we call this a Random Utility Model (RUM)
with
Step 3: Mode choice
- Is it better? Yes, but we need a special case!
- A straightforward expression can be obtained if we use an Extreme Value Distribution like the Gumbel Distribution
- Then it has been shown that there is a correspondance between:
(Lots of math)
[Daniel McFadden in the 70s]
Step 3: Mode choice
- Is it better? Yes, but we need a special case!
- A straightforward expression can be obtained if we use an Extreme Value Distribution like the Gumbel Distribution
- Then it has been shown that there is a correspondance between:
(Lots of math)
[Daniel McFadden in the 70s]
Step 3: Mode choice
- With this finding, discrete choice modeling has been revolutionized in the 70s
- The expression on the right is now a closed-form expression of the probability of choosing alternative y
- The model is called the Multinomial Logit Model. It is the most commonly used approach for choice modelling today (with a large variety of extensions and versions).
- Why has it been so impactful? Because it allows us to estimate the model parameters that are hidden in the systematic utility v in the equation above.
Step 3: Mode choice
- With this finding, discrete choice modeling has been revolutionized in the 70s
- The expression on the right is now a closed-form expression of the probability of choosing alternative y
- The model is called the Multinomial Logit Model. It is the most commonly used approach for choice modelling today (with a large variety of extensions and versions).
- Why has it been so impactful? Because it allows us to estimate the model parameters that are hidden in the systematic utility v in the equation above.
Step 3: Mode choice
- Having a closed-form expression allows us to perform a Maximum Likelihood Estimation (MLE) of the model parameters. For that we set up the likelihood function of the model:
- It answers: How well does the model (with given parameters) explain the choices?
- The maximum likelihood estimate for the model parameters is then:
- It can be found using standard methods such as Gradient Descent or Newton-Raphson
Step 3: Mode choice

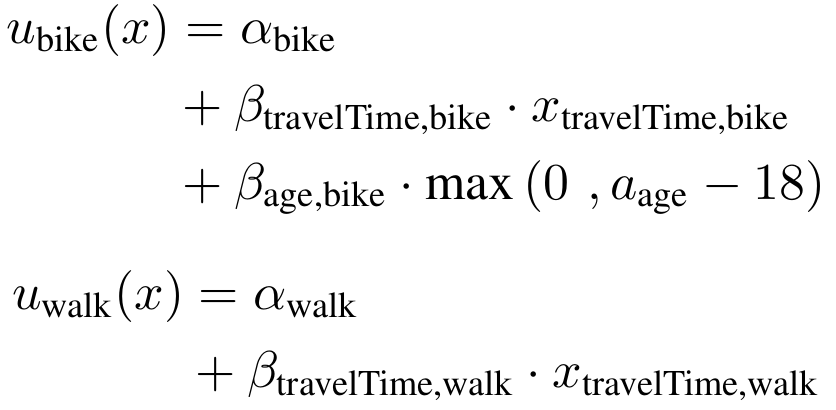
-
More elaborate example
Step 3: Mode choice
- Finally, how do we use the Multinomial Logit model to make a decision for a new choice situation?
-
Option 1: Direct sampling
- Calculate systematic utilities
- Calculate probabilities
- Sample one alternative
- Calculate systematic utilities
Step 3: Mode choice
- Finally, how do we use the Multinomial Logit model to make a decision for a new choice situation?
-
Option 2: Error sampling
- Calculate systematic utilities
- Sample error terms
- Select the maximum
- Calculate systematic utilities
Step 3: Mode choice
- There is a large field of discrete choice modelling with specific journals
- What happens if we replace the EV distribution by a Normal distribution?
- We get a Multinomial Probit model
- There is no analytical likelihood function any more, but simulation stays straight-forward
- Possibility to flexibly model the error term
- Correlations between choice alternatives
(if I like the red bus, I also like the blue bus)
- More complex formulations of the MNL exist
- Mainly to disentangle the above-mentioned correlation structure of errors
- Nested logit model (first I choose that I use the bus, then if I prefer red or blue)
-
Cross-nested logit model (an automated taxi is like a bus, but also a bit like a car)
- Multiplicative error terms ...
- Parameters (β) are not static but follow a distribution themselves ...
Step 4: Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
Trip generation
Trip distribution
Mode choice
Traffic assignment
Step 4: Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
Trip generation
Trip distribution
Mode choice
Traffic assignment
Movements from zone r to zone s
Step 4: Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
Trip generation
Trip distribution
Mode choice
Traffic assignment
Movements from zone r to zone s
Travel times on road a
Step 4: Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
Trip generation
Trip distribution
Mode choice
Traffic assignment
Movements from zone r to zone s
Travel times on road a
Vehicle flow on road a
Step 4: Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
Trip generation
Trip distribution
Mode choice
Traffic assignment
Step 4: Traffic assignment
Trip generation
Trip distribution
Mode choice
Traffic assignment
-
Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
- How to calculate travel times from one zone to another?
- We need a network to assign representative locations in each zone.
- We perform a shortest path calculation with individual travel times on each link.

Step 4: Traffic assignment
Trip generation
Trip distribution
Mode choice
Traffic assignment
- Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
The Dijkstra algorithm
- Explore the network step by step to find the quickest link sequence towards the destination


Step 4: Traffic assignment
Trip generation
Trip distribution
Mode choice
Traffic assignment
-
Modelling task: Set up a model that determines which roads and transit lines will be used by the travellers and yields the travel times
- The model is based on a rational decision maker: Individually, I will follow the route that minimizes my personal travel time.
- This is the game-theoretic Wardrop principle
- Travel times in the network are described through volume-delay functions:
Step 4: Traffic assignment
-
Example: Two routes and Wardrop equilibrium
- Travel demand from S to E:
- Travel time on Route A (normal road):
- Travel time on Route B (highway):
- Travel demand from S to E:
S
E
Route A
Route B
Step 4: Traffic assignment
-
Example: Two routes and Wardrop equilibrium
- Travel demand from S to E:
- Travel time on Route A (normal road):
- Travel time on Route B (highway):
- Travel demand from S to E:
S
E
Route A
Route B
How many cars use routes A and B and what is the travel time?
Step 4: Traffic assignment
S
E
Route A
Route B
-
Example: Two routes and Wardrop equilibrium
- Travel demand from S to E:
- Travel time on Route A (normal road):
- Travel time on Route B (highway):
- Flow must be distributed over the routes:
- Wardrop: If the travel time on Route A is quicker than Route B, I would not use Route A, but rather Route B!
- Travel demand from S to E:
Step 4: Traffic assignment
S
E
Route A
Route B
-
Example: Two routes and Wardrop equilibrium
- Travel demand from S to E:
- Travel time on Route A (normal road):
- Travel time on Route B (highway):
- Flow must be distributed over the routes:
- Wardrop: If the travel time on Route A is quicker than Route B, I would not use Route A, but rather Route B!
- Travel demand from S to E:
Step 4: Traffic assignment
S
E
Route A
Route B
-
Example: Two routes and Wardrop equilibrium
- Travel demand from S to E:
- Travel time on Route A (normal road):
- Travel time on Route B (highway):
- Flow must be distributed over the routes:
- Wardrop: If the travel time on Route A is quicker than Route B, I would not use Route A, but rather Route B!
- Travel demand from S to E:
How many cars use routes A and B and what is the travel time?
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
The flow on the route alternatives k between r and s must some to the overall zonal flow between r and s
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
The flow on the route alternatives k between r and s must some to the overall zonal flow between r and s
Does route k between r and s pass through link a?
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
The flow on the route alternatives k between r and s must some to the overall zonal flow between r and s
Does route k between r and s pass through link a?
The link flow of a is the sum of all route flows passing through
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
The flow on the route alternatives k between r and s must some to the overall zonal flow between r and s
Does route k between r and s pass through link a?
The link flow of a is the sum of all route flows passing through
All link flows must be non-negative
Step 4: Traffic assignment
- General case yields a complex optimization problem
There are k different routes to go from origin r to destination s and the route flow must be non-negative
The flow on the route alternatives k between r and s must some to the overall zonal flow between r and s
Does route k between r and s pass through link a?
The link flow of a is the sum of all route flows passing through
All link flows must be non-negative
The "first" vehicle on link a as low travel time, the "second" one a bit longer, and so on ...
Step 4: Traffic assignment
- General case yields a complex optimization problem
- The problem can not be solved analytically - it needs to be simulated!
- Various approaches with different complexity exist:
- Method of Successive Averages (MSA)
- Frank-Wolfe Assignment
- Biconjugate Frank-Wolfe Assignment
Step 4: Traffic assignment
Sketch for Method of Successive Averages (MSA)
- Find the quickest path for all (r,s) pairs under freeflow condtiions and note down the link flows
- Calculate the resulting travel times on all links
- Based on these travel times, recalculate the quickest paths for all (r,s) pairs and note down the updated link flows as
- Update the link flows for the next iteration as
- Continue at 2 until convergence
- The lambda parameter should be decreasing over iterations (to avoid oscillations)
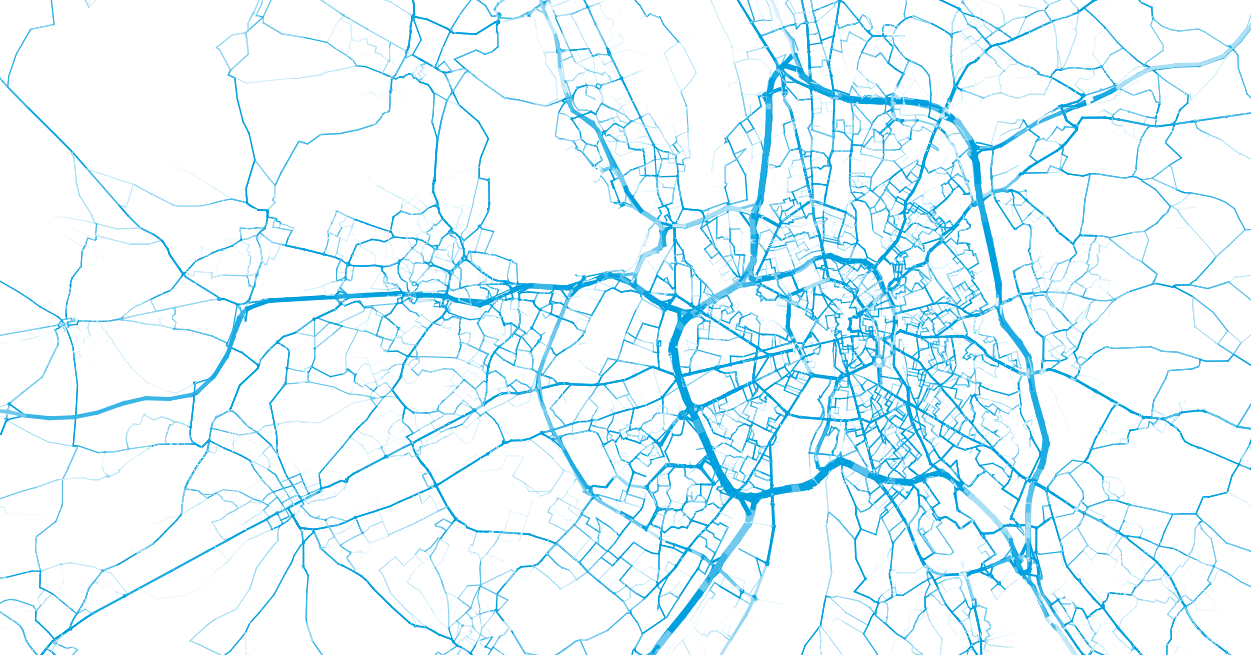
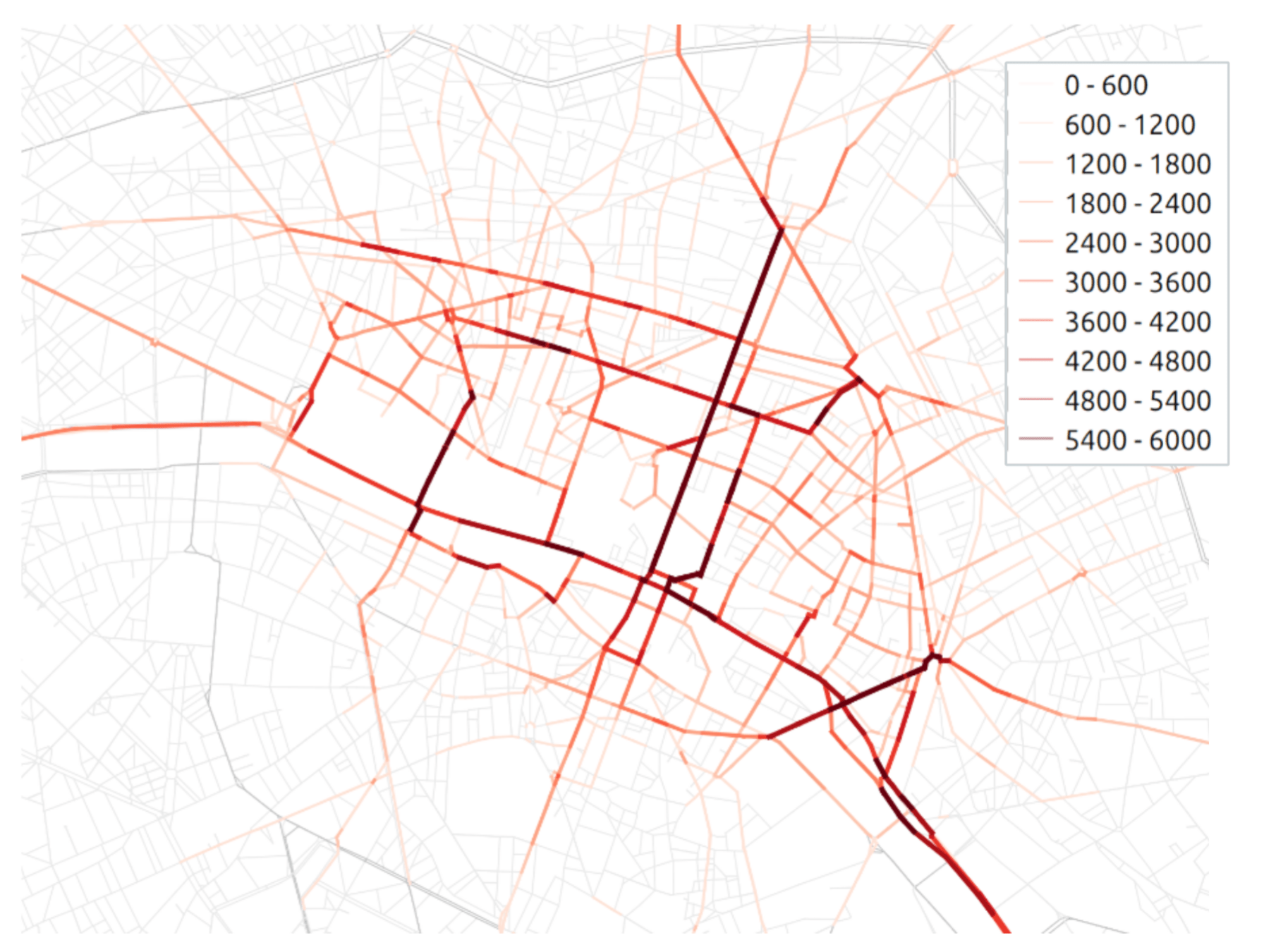
Step 4: Traffic assignment
The resulting link flows can be visualized:
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
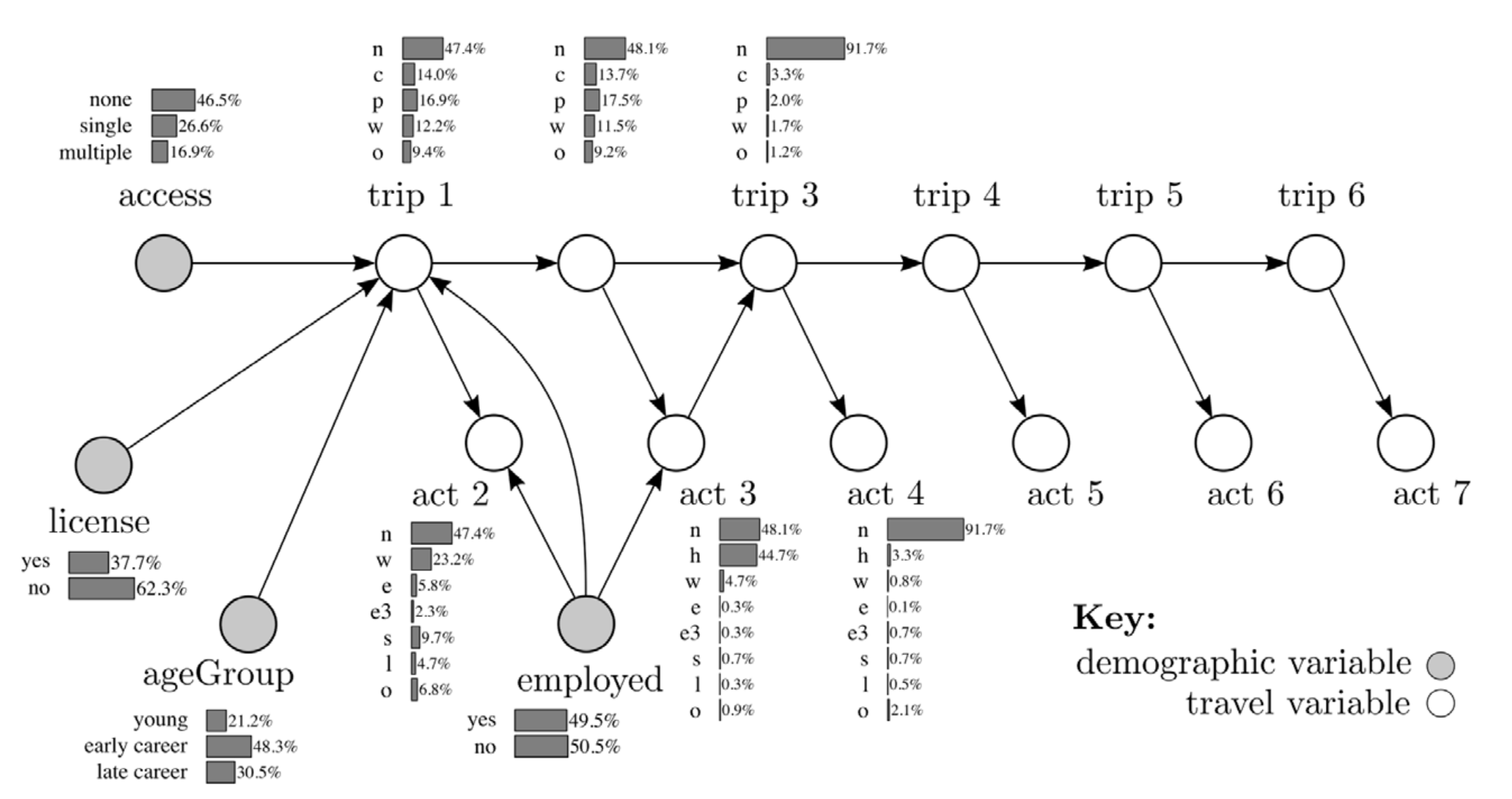
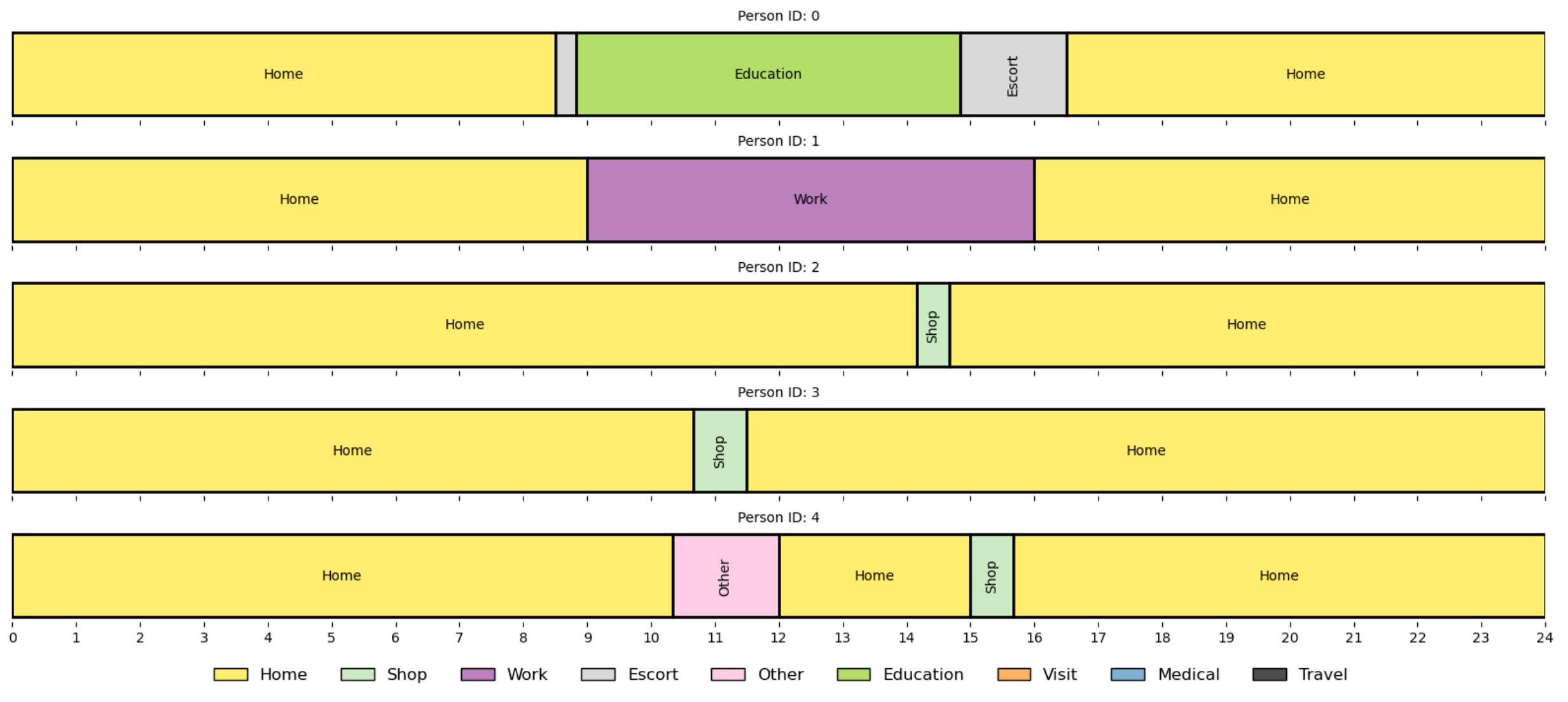
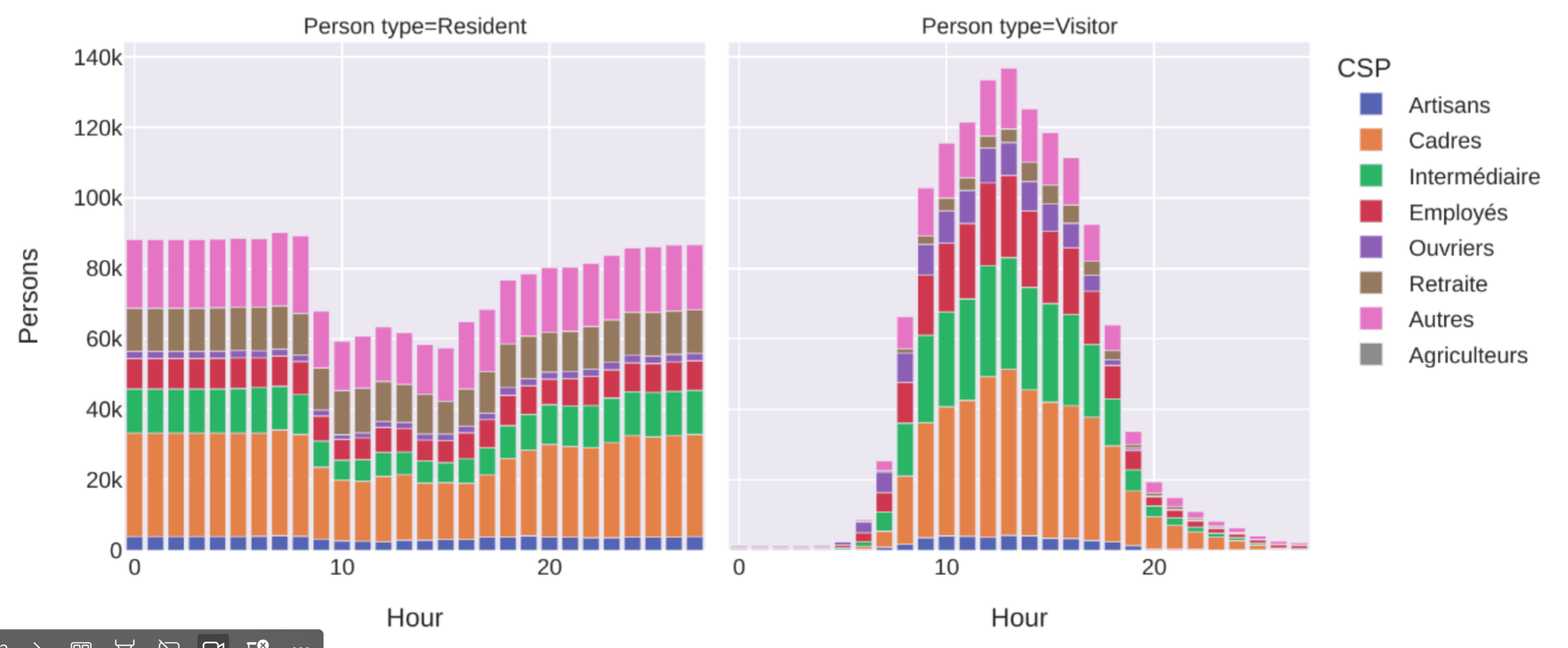
Synthetic populations: Introduction
Definition
- Representation digital version of the real population of a territory
- Persons (single-level) or households with persons (two-level) population
- Households and persons with individual attributes
- Persons with individual activity chains
0:00 - 8:00
08:30 - 17:00
0:00 - 9:00
10:00 - 17:30
17:45 - 21:00
22:00 - 0:00
17:30 - 0:00
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations

RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Data
Goals
- Generate individual households and persons
- Choose a distinct place of residence
French population census
| Household ID | Person ID | Zone | Age | Sex | ... | Weight |
|---|---|---|---|---|---|---|
| 512 | 1 | 75013 | 35 | f | ... | 3.2 |
| 512 | 2 | 75013 | 32 | m | ... | 3.2 |
| 516 | 1 | 75019 | 42 | m | ... | 4.1 |
| ... | ... | ... | ... | ... | ... |
Upsampling of persons using Truncate-Replicate-Sample (TRS)
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Data
Goals
- Generate individual households and persons
- Choose a distinct place of residence
Sampling by number of housing units per building
French bulding database
French address database
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Goal
- Choose work places and education locations
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
French work
commuting matrix
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Goal
- Choose work places and education locations
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
French work
commuting matrix
National enterprise
database
with facilities by number of employees
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Goal
- Choose work places and education locations
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
French education
commuting matrix
Permanent facility
database
with education facilities and attendants
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Goal
- Generate activity sequences (type, start and end time) for each person
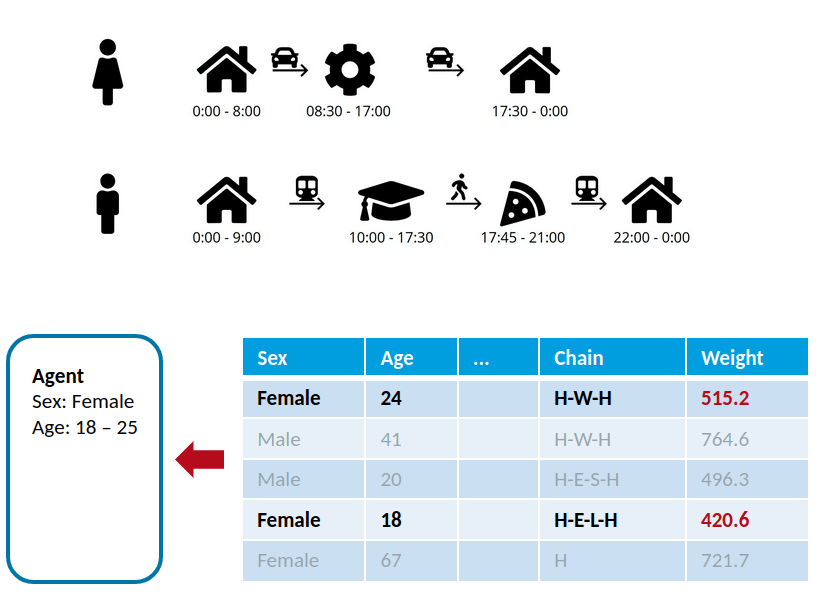
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Statistical Matching
National Household Travel Survey 2008
(Local Household Travel Surveys)
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Goals
- Choose locations of secondary (shopping, leisure, ...) activities
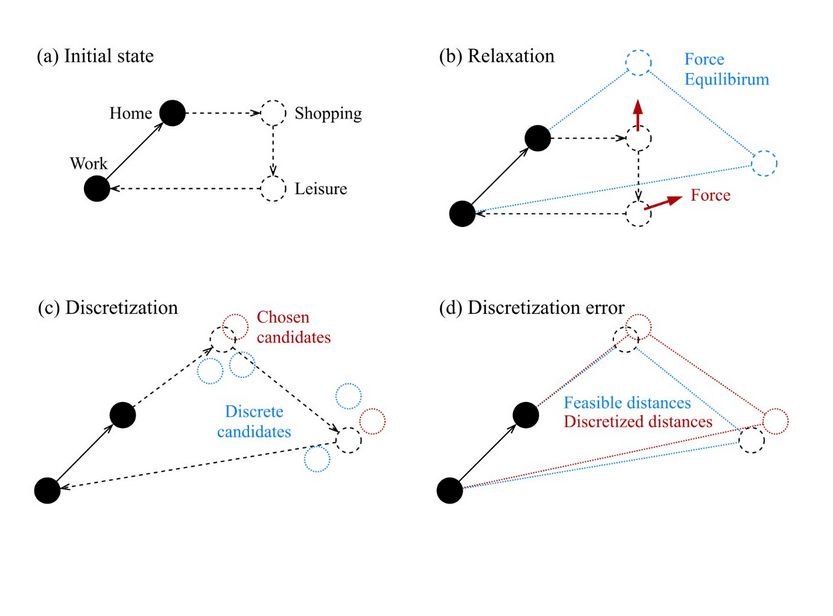
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Hörl, S., Axhausen, K.W., 2021. Relaxation–discretization algorithm for spatially constrained secondary location assignment. Transportmetrica A: Transport Science 1–20.
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Output
- Three main tables: households, persons, activities
- Supplementary tables: commutes, trips, ...
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
| household_id | income | number_of_cars | ... |
|---|---|---|---|
| 1024 | 85,000 | 2 | ... |
| household_id | person_id | age | sex | employed | ... |
|---|---|---|---|---|---|
| 1024 | 1 | 34 | f | true | ... |
| 1024 | 2 | 36 | m | true | ... |
| household_id | person_id | activity_id | start_time | end_time | type | location | ... |
|---|---|---|---|---|---|---|---|
| 1024 | 1 | 1 | 00:00 | 08:00 | home | (x, y) | ... |
| 1024 | 1 | 2 | 09:00 | 18:00 | work | (x, y) | ... |
| 1024 | 1 | 3 | 19:00 | 24:00 | home | (x, y) | ... |
Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Output
- Three main tables: households, persons, activities
- Supplementary tables: commutes, trips, ...
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
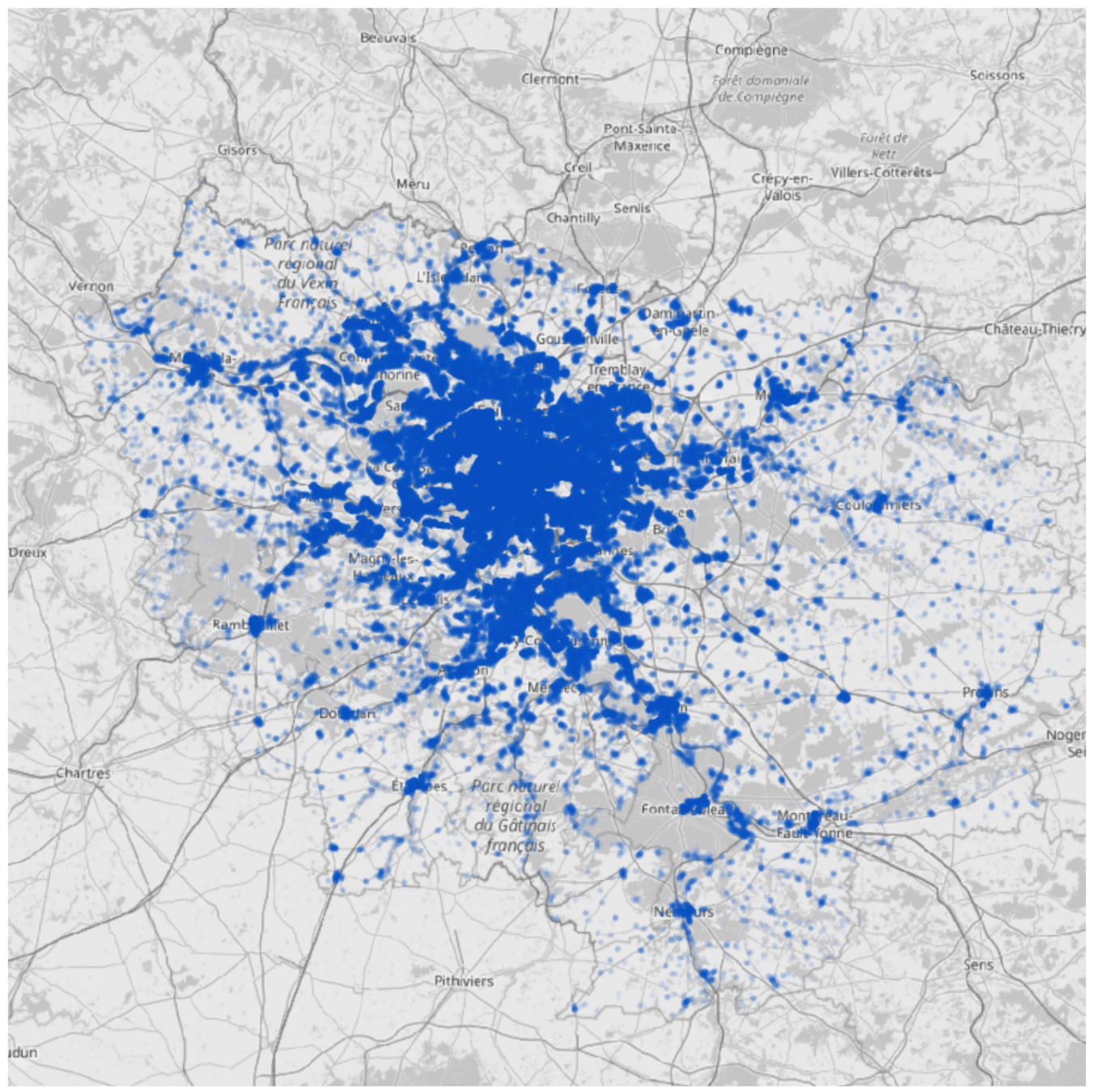
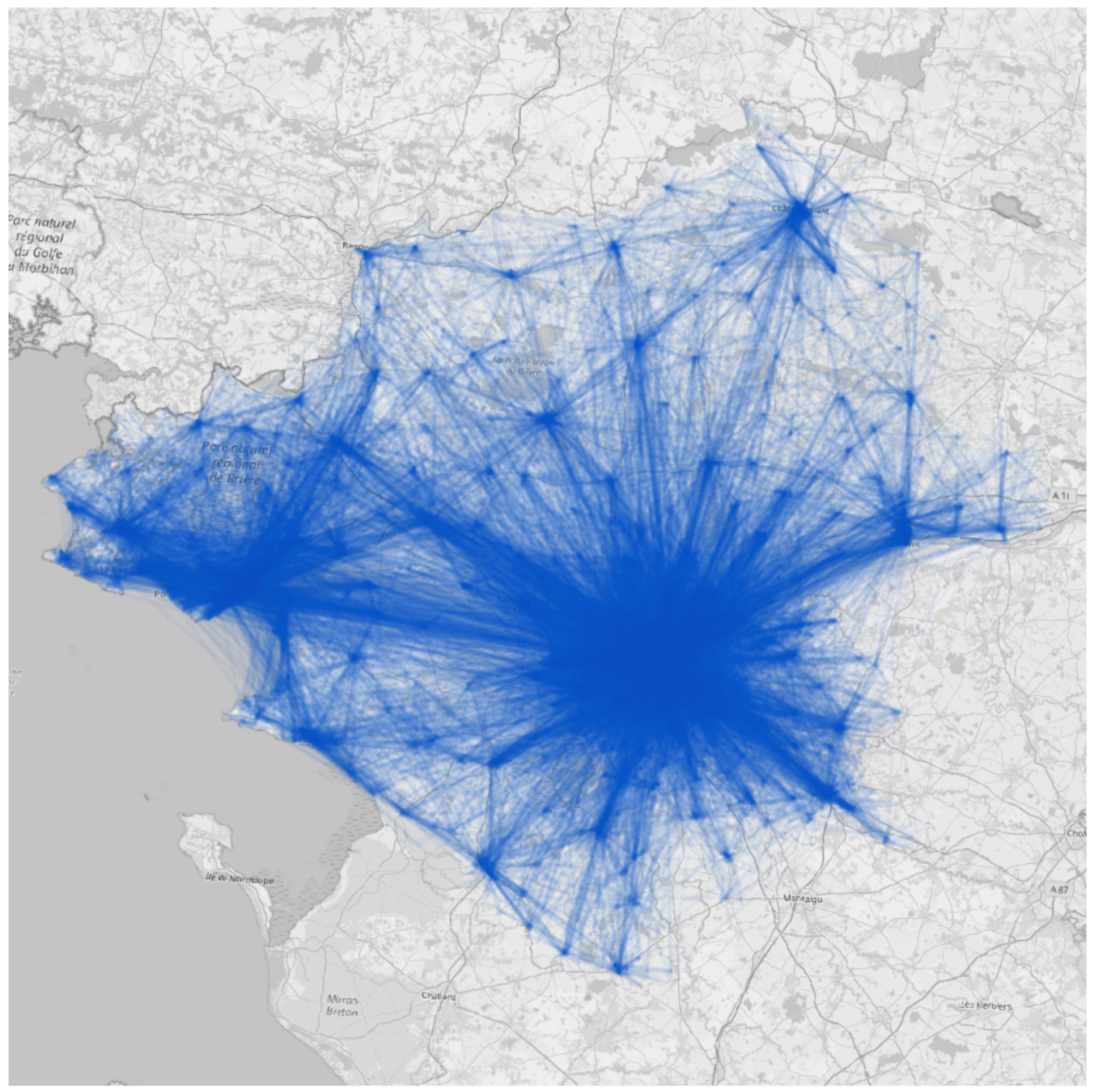
Place of residence
Commuting trips
Hourly work activities

Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Validation
- Comparison with census data, HTS data, ...

Synthetic populations: Pipeline
Pipeline
- Households and persons
- Primary activity locations
- Activity chains
- Secondary activity locations
Data
Validation
- Comparison with census data, HTS data, ...
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Synthetic populations: Pipeline
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Open data
Open source
+
=
Replicable research in agent-based transport simulation

Synthetic populations: Pipeline
RP
BAN
BD-TOPO
MOBPRO
MOBETUD
SIRENE
BPE
ENTD
Open data
Open source
+
=
Synthetic populations: Community







Lille
Paris
Strasbourg
Lyon
Toulouse
Bordeaux
Nantes
Rennes

Contributors
Users




Synthetic populations: Adaptations
Screenshot Sao Paolo
Copy & paste of the code base
Difficulty of maintenance
São Paulo
Almost same open data available as in France
California
Substantial modifiations required
Switzerland
Not based on open data
(for now)

Paper published in
Regional Studies, Regional Science (2020)

Paper presented at the Annual Meeting of the Transportation Research Board (2021)
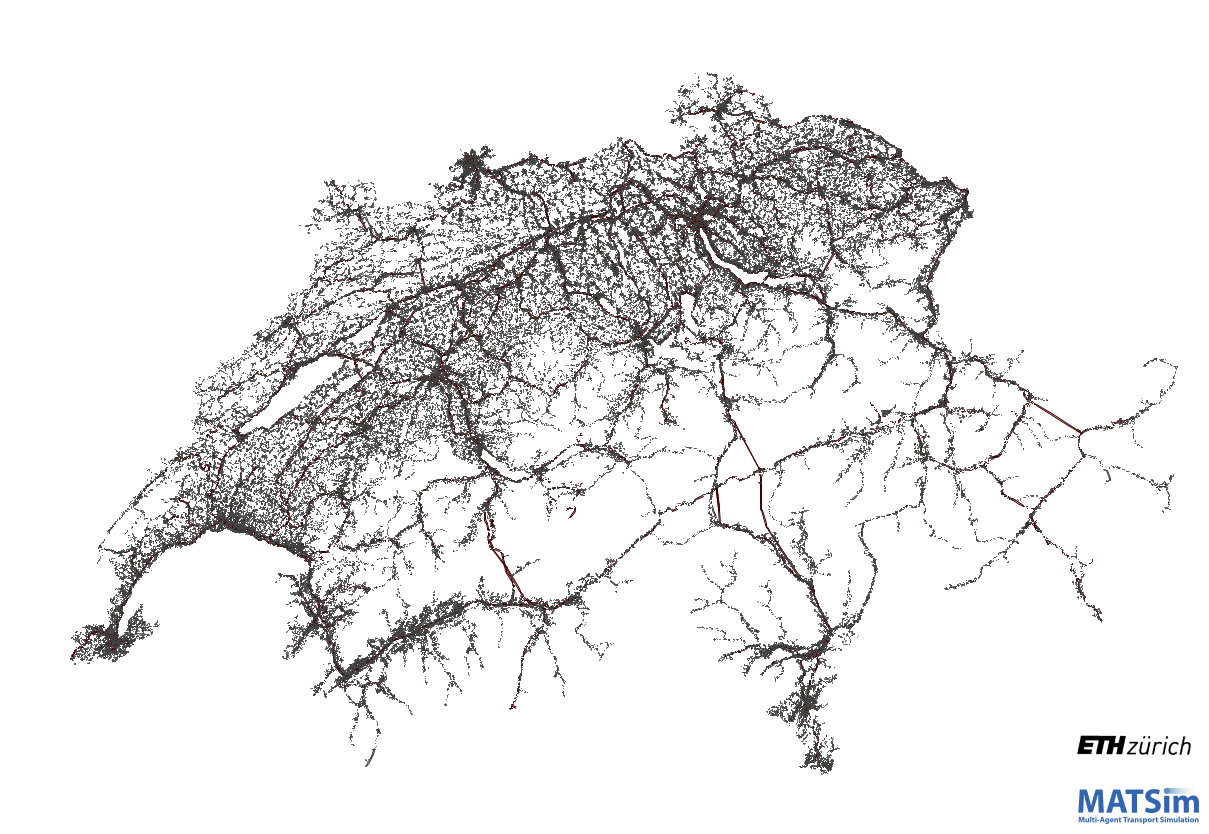
Work in progress at ETH Zurich
Synthetic populations: Adaptations
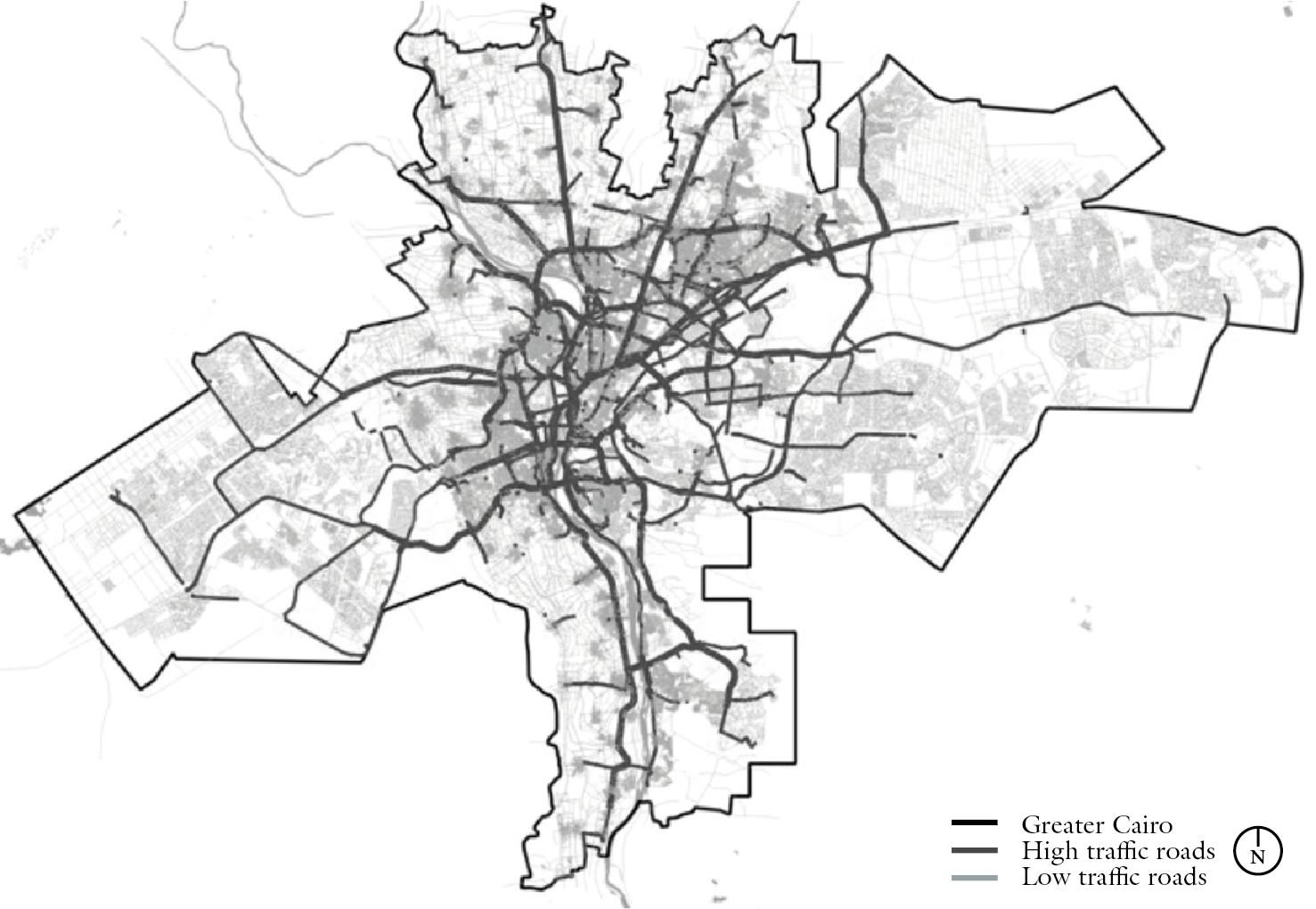
Cairo: Extreme case, very few data available and not in the right format
Idea: Use data to generate "fake" input to the French pipeline and reuse the code!
Gall, T., Vallet, F., Reyes Madrigal, L.M., Hörl, S., Abdin, A., Chouaki, T., Puchinger, J., 2023. Sustainable Urban Mobility Futures, Sustainable Urban Futures. Springer Nature Switzerland, Cham.
Synthetic populations: Adaptations
Cairo: Extreme case, very few data available and not in the right format
Idea: Use data to generate "fake" input to the French pipeline and reuse the code!
Bavaria: Set up a robust and replicable pipeline with data replacement
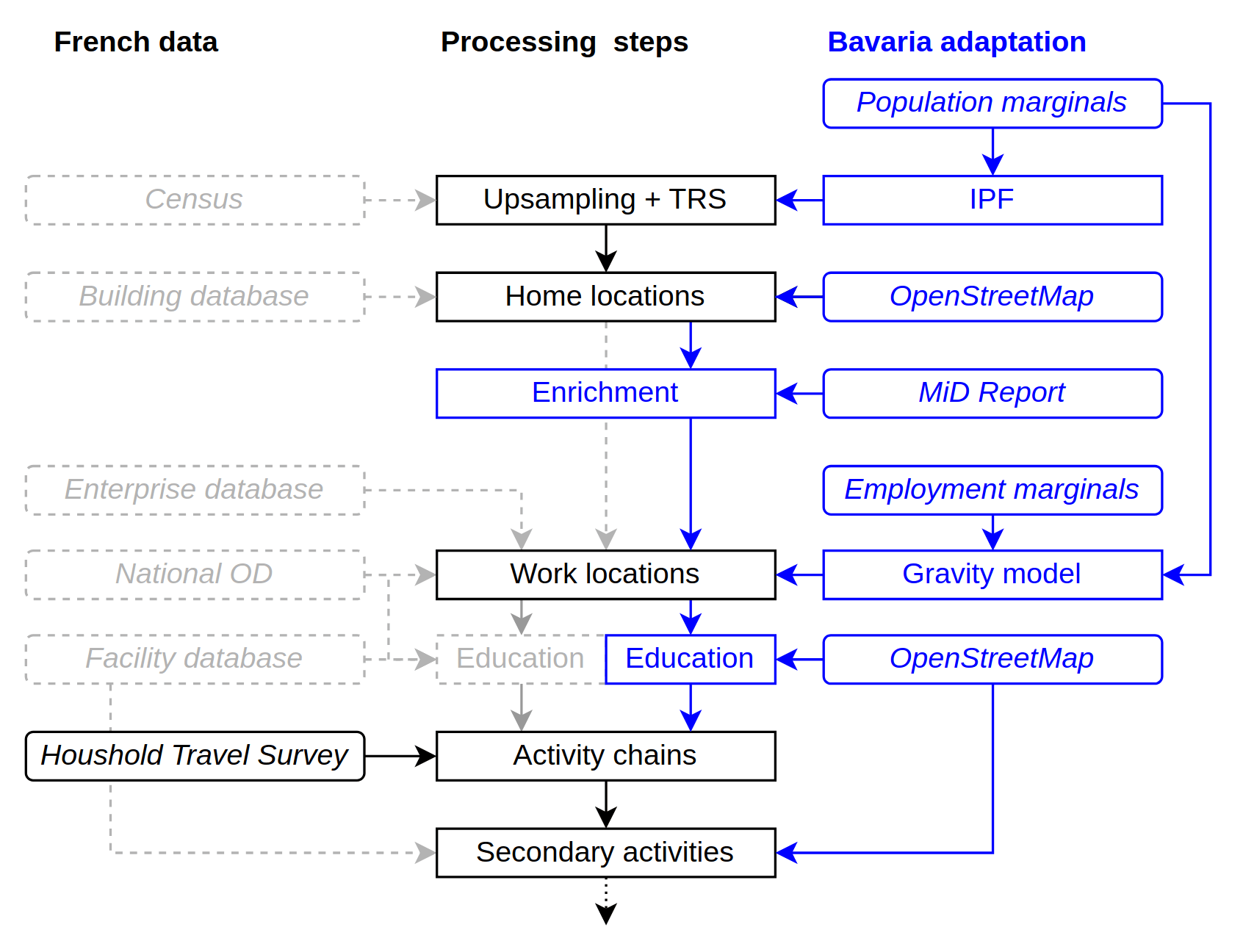
Hörl, S., Burianne, A., Natterer, E., Engelhardt, R., Müller, J. (2025) Towards a replicable synthetic population and agent-based transport model for Bavaria, paper presented at the 23rd International Conference on Practical applications of Agents and Multi-Agent Systems (PAAMS 2025), June 2025, Lille, France.
As part of the national project MINGA
Synthetic populations: Adaptations
Cairo: Extreme case, very few data available and not in the right format
Idea: Use data to generate "fake" input to the French pipeline and reuse the code!
Bavaria: Set up a robust and replicable pipeline with data replacement

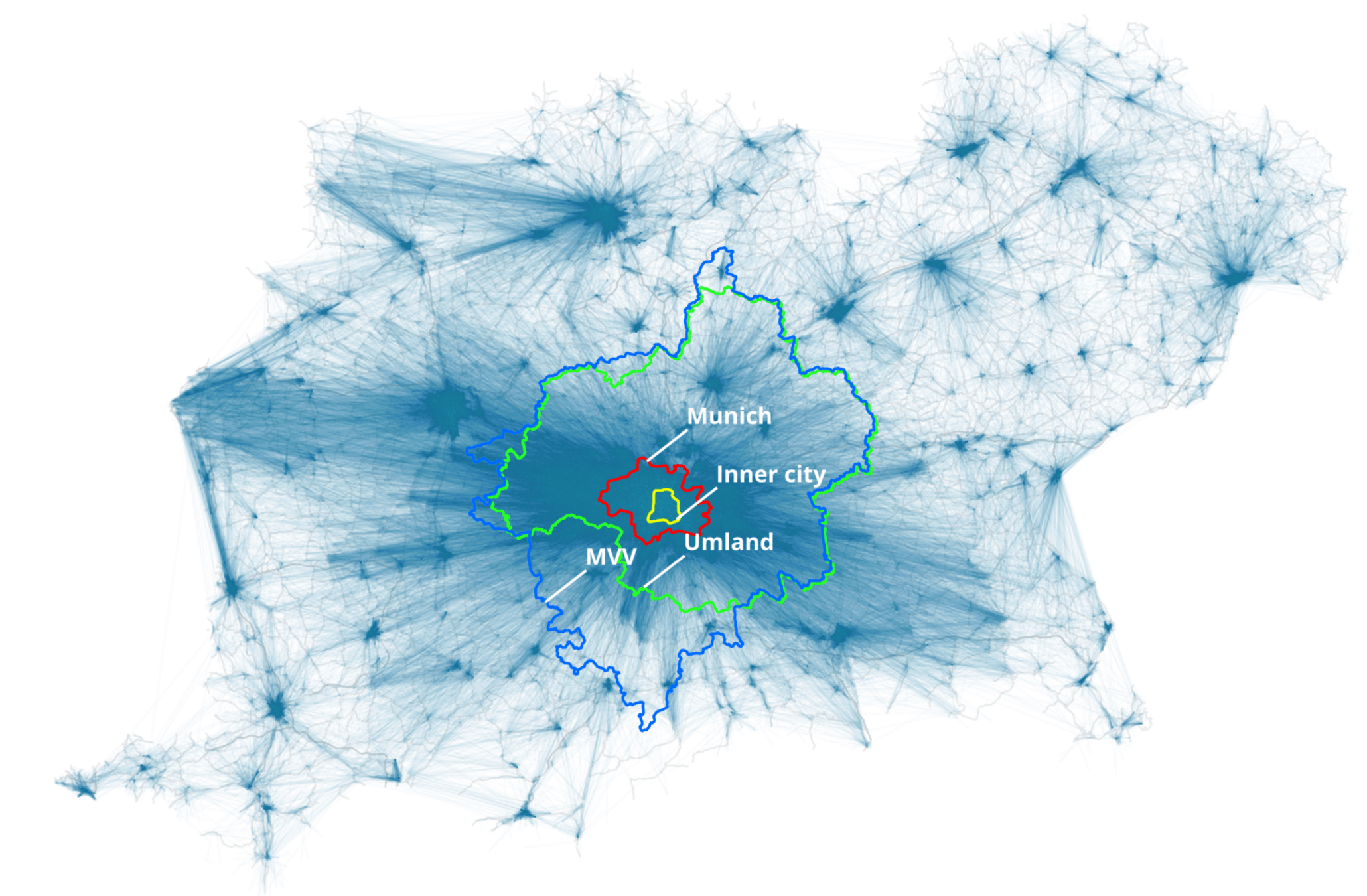
As part of the national project MINGA
Hörl, S., Burianne, A., Natterer, E., Engelhardt, R., Müller, J. (2025) Towards a replicable synthetic population and agent-based transport model for Bavaria, paper presented at the 23rd International Conference on Practical applications of Agents and Multi-Agent Systems (PAAMS 2025), June 2025, Lille, France.
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
- Iterative Proportional Fitting
| Age | Count |
|---|---|
| 0 - 14 | ... |
| 14 - 18 | ... |
| 18-24 | ... |
| ... | ... |
| CSP | Count |
|---|---|
| 1 | ... |
| 2 | ... |
| 3 | ... |
| ... | ... |
| Cars | Count |
|---|---|
| 1 | ... |
| 2 | ... |
| 3+ | ... |
| Age | CSP | Cars | Count |
|---|---|---|---|
| 0 - 14 | 1 | 1 | ? |
| 14 - 18 | 1 | 1 | ? |
| 18-24 | 1 | 2 | ? |
| ... | ... | ... | ... |
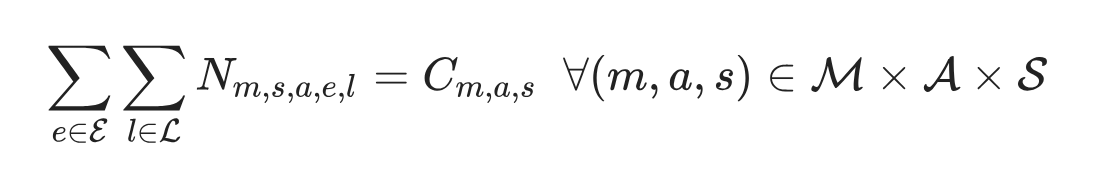
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
- Iterative Proportional Fitting
- Bayesian networks
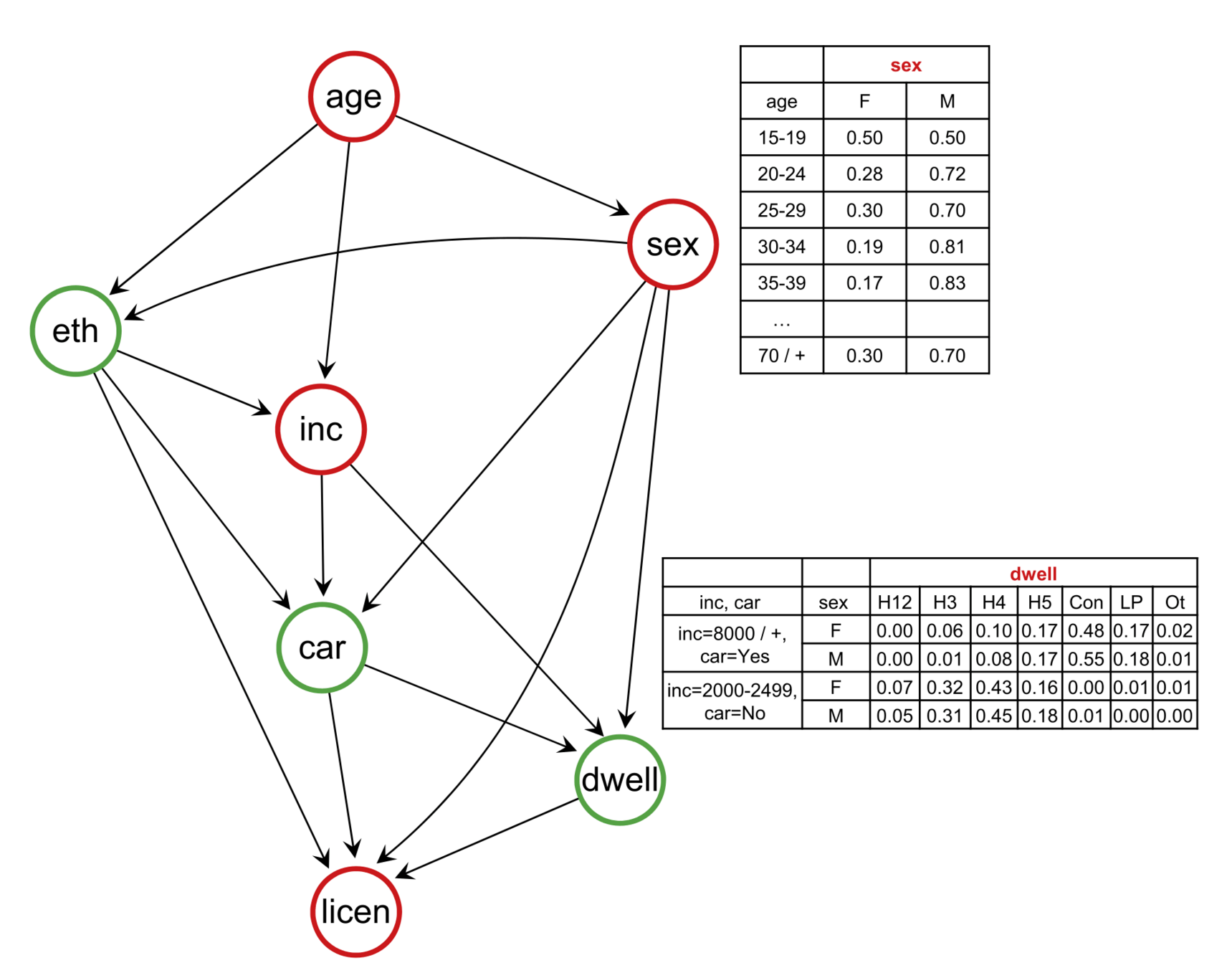
Sun, L., & Erath, A. (2015). A Bayesian network approach for population synthesis. Transportation Research Part C: Emerging Technologies, 61, 49–62. https://doi.org/10.1016/j.trc.2015.10.010
- Network learning
- Distribution learning
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
- Iterative Proportional Fitting
- Bayesian networks
- Variational Auto-Encoders (VAEs)
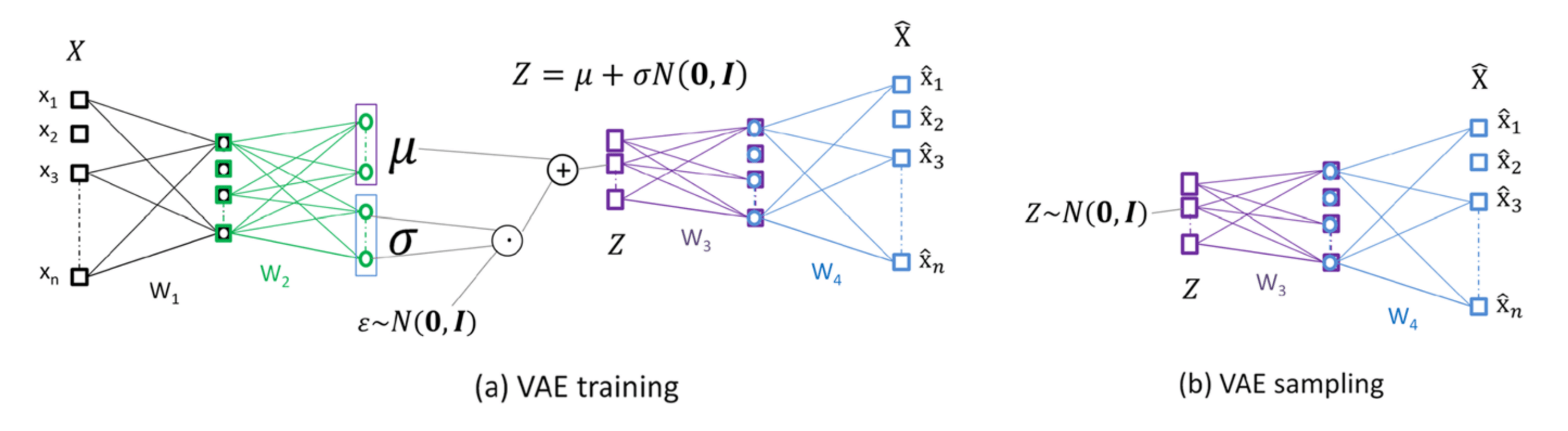
Sané, A. R., Vandanjon, P.-O., Belaroussi, R., & Hankach, P. (2024). A comprehensive investigation of variational auto-encoders for population synthesis. Journal of Computational Social Science, 8(1), 13. https://doi.org/10.1007/s42001-024-00332-0
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
- Iterative Proportional Fitting
- Bayesian networks
- Variational Auto-Encoders (VAEs)
- Generative Adversarial Networks (GANs)
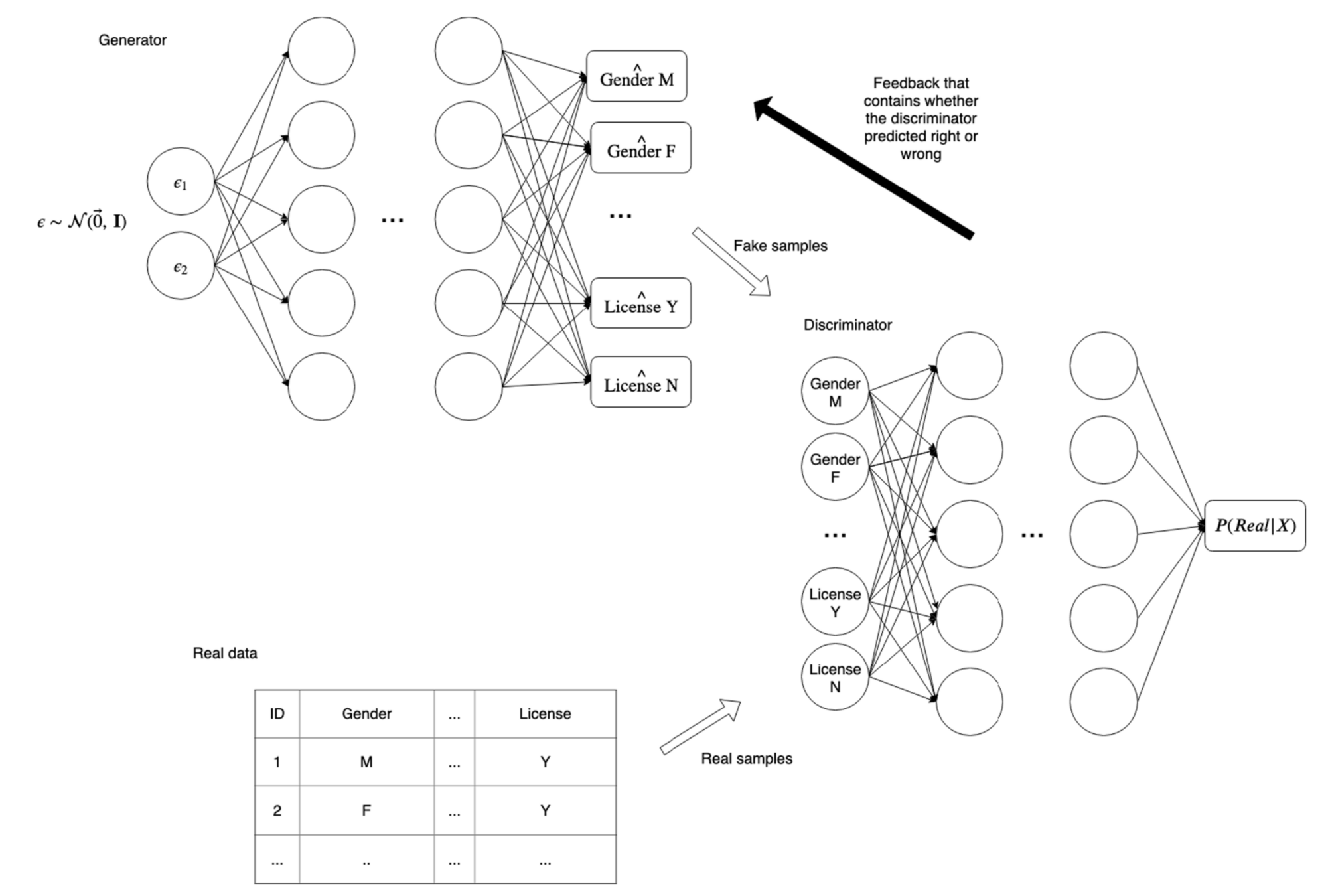
Garrido, S., Borysov, S. S., Pereira, F. C., & Rich, J. (2020). Prediction of rare feature combinations in population synthesis: Application of deep generative modelling. Transportation Research Part C: Emerging Technologies, 120, 102787. https://doi.org/10.1016/j.trc.2020.102787
Synthetic populations: Advanced methods
Synthetic households and persons can be generated using
- Iterative Proportional Fitting
- Bayesian networks
- Variational Auto-Encoders (VAEs)
- Generative Adversarial Networks (GANs)
- ...
Synthetic populations: Advanced methods
Activity chains can be generated using
Synthetic populations: Advanced methods
Activity chains can be generated using
- Bayesian networks
Joubert, J. W., & de Waal, A. (2020). Activity-based travel demand generation using Bayesian networks. Transportation Research Part C: Emerging Technologies, 120, 102804. https://doi.org/10.1016/j.trc.2020.102804
Synthetic populations: Advanced methods
Activity chains can be generated using
- Bayesian networks
- VAEs / GANs (current research)
Shone, F., & Hillel, T. (2024, June 20). Activity Sequence Modelling with Deep Generative Models [Proceedings paper]. hEART. hEART 2024: 12th Symposium of the European Association for Research in Transportation. In: hEART 2024: 12th Symposium of the European Association for Research in Transportation, Proceedings. hEART: Espoo, Finland. (2024). https://transp-or.epfl.ch/heart/2024.php
Synthetic populations: Advanced methods
Activity chains can be generated using
- Bayesian networks
- VAEs / GANs (current research)
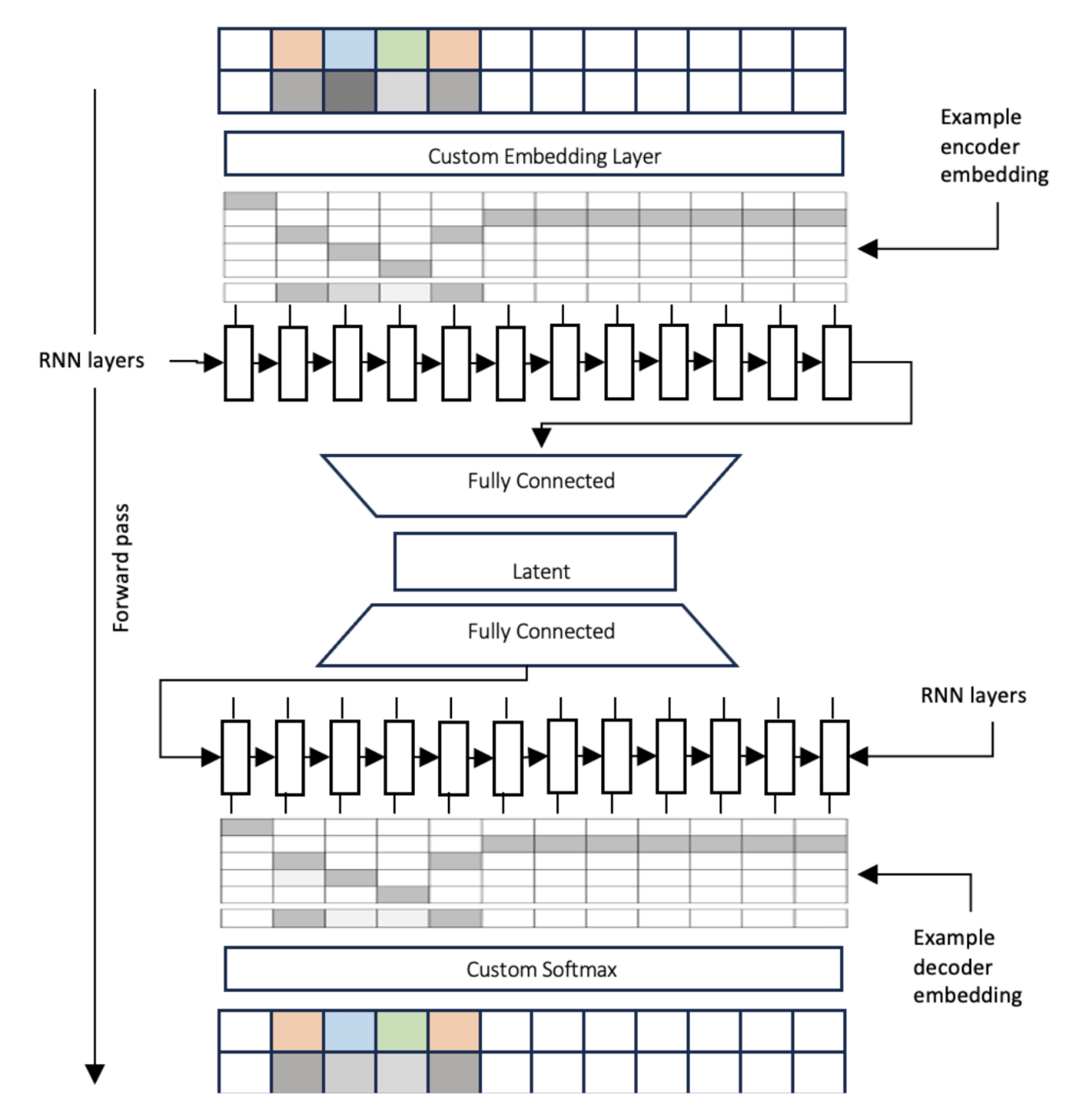
Shone, F., & Hillel, T. (2024, June 20). Activity Sequence Modelling with Deep Generative Models [Proceedings paper]. hEART. hEART 2024: 12th Symposium of the European Association for Research in Transportation. In: hEART 2024: 12th Symposium of the European Association for Research in Transportation, Proceedings. hEART: Espoo, Finland. (2024). https://transp-or.epfl.ch/heart/2024.php
Synthetic populations: Advanced methods
Activity chains can be generated using
- Bayesian networks
- VAEs / GANs (current research)
- ...
Synthetic populations
- Reproducibility
- Low in transport modelling / simulation, especially with agent-based models
- Can increase acceptance, uptake and more widespread use of these models
- Increasingly available open data sources make reproducibility possible, but processes aren't standardized or not easily accessible as open source
- Our goal: Have pipeline from raw data to a calibrated large-scale agent-based transport simulation that is nearly 100% replicable with reproducible results.

Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Agent-based simulation: Introduction
GTFS
OpenStreetMap
Synthetic demand
+
Driving car
Metro / Train
Work activity starts
Agent-based simulation: Introduction
Synthetic demand
Agent-based simulation: Introduction
Mobility simulation
Synthetic demand
Daily mobility plans
Agent-based simulation: Introduction
Decision-making
Mobility simulation
Synthetic demand

Experienced travel times, crowding, ...
Daily mobility plans
Agent-based simulation: Introduction
Decision-making
Mobility simulation
Synthetic demand
Experienced travel times, crowding, ...
Daily mobility plans
Agent-based simulation: Introduction
Decision-making
Mobility simulation
Synthetic demand
Experienced travel times, crowding, ...
Daily mobility plans
Update
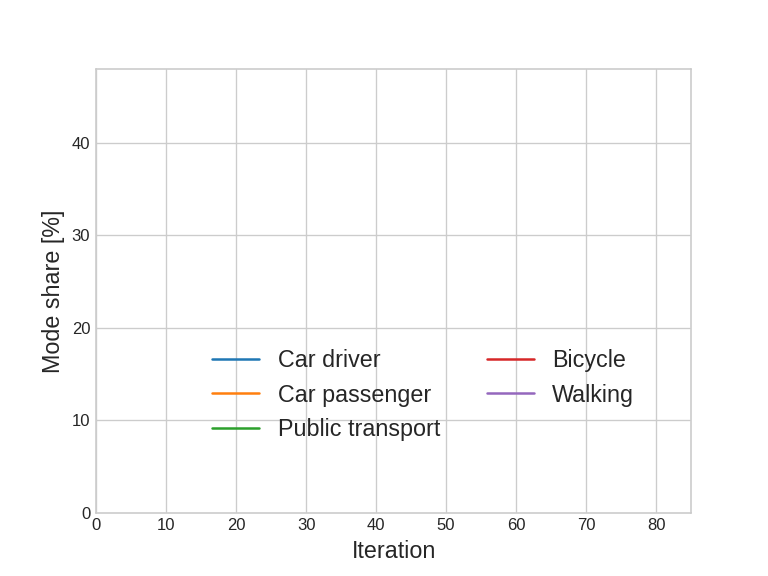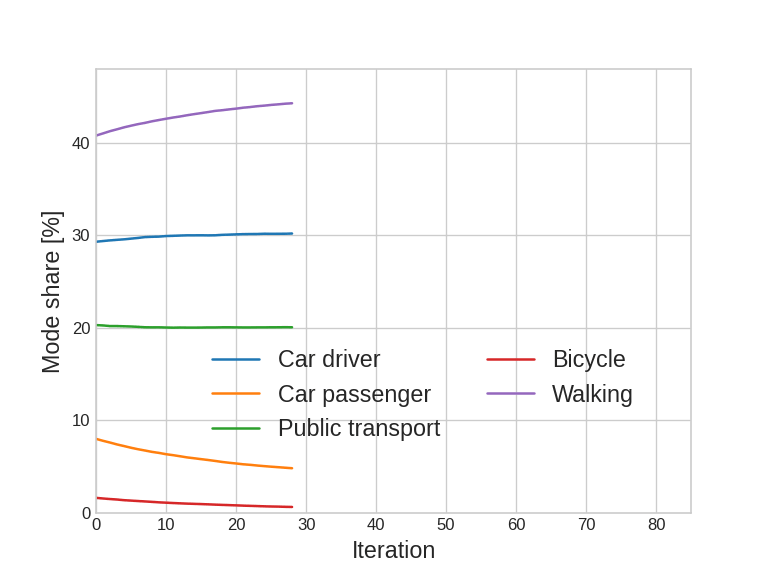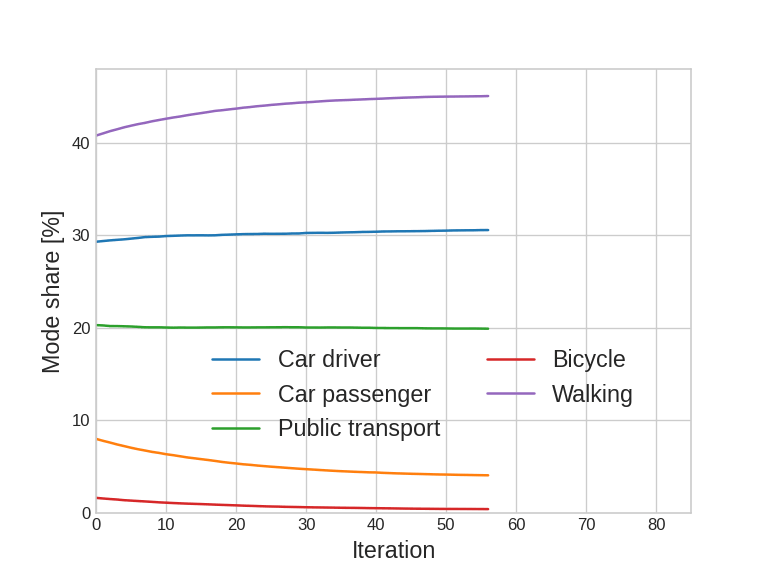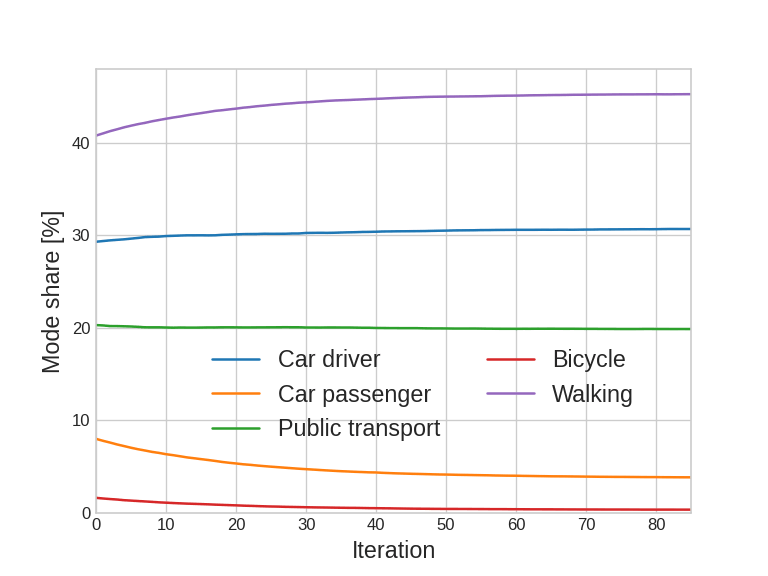
Agent-based simulation: Introduction
Decision-making
Mobility simulation
Synthetic demand

- Maintained by TU Berlin, ETH Zurich, (IRT SystemX)
- 50+ research users world-wide, SBB, Volkswagen, ...
- Contributor since ~2016
Mode shares
Traffic patterns
Emissions
Noise
Agent-based simulation: IDM
- Traffic simulations can be microscopic
- Each agent is simulated in detail
- Cars have a location
- Velocity and acceleration
- They move according to what they perceive around them
Agent-based simulation: IDM
- Traffic simulations can be microscopic
- Each agent is simulated in detail
- Cars have a location
- Velocity and acceleration
- They move according to what they perceive around them
- A commonly used model is the Intelligent Driver Model

Agent-based simulation: IDM
- Traffic simulations can be microscopic
- Each agent is simulated in detail
- Cars have a location
- Velocity and acceleration
- They move according to what they perceive around them
- A commonly used model is the Intelligent Driver Model
is your current speed, and is the speed limit
Agent-based simulation: IDM
- Traffic simulations can be microscopic
- Each agent is simulated in detail
- Cars have a location
- Velocity and acceleration
- They move according to what they perceive around them
- A commonly used model is the Intelligent Driver Model
is your current distance to the leading car , and is the desired distance
Agent-based simulation: IDM
- Check out the following website for a car-following model in action

Agent-based simulation: IDM
- Microscopic models
- Represent traffic in high detail
- Are highly realistic
- Can be calibrated directly on driver behavior (drone videos, ...)
- But
- Are computational heavy!
- Need to be simulated on a sub-second basis
- With many cars (12M agents in Île-de-France, this becomes infeasible!)
Agent-based simulation: IDM
- Other option: Mesoscopic models
- Agents interact with a network that consists of vertices and edges (nodes and links)
- Link-based mobility simulation
- Each link consists of a queue and a buffer
- Vehicles enter the queue and wait until they are allowed to pass through the link (flow capacity) into the buffer
- Vehicles wait inside the buffer until there is space (storage capacity) on the next link of their route
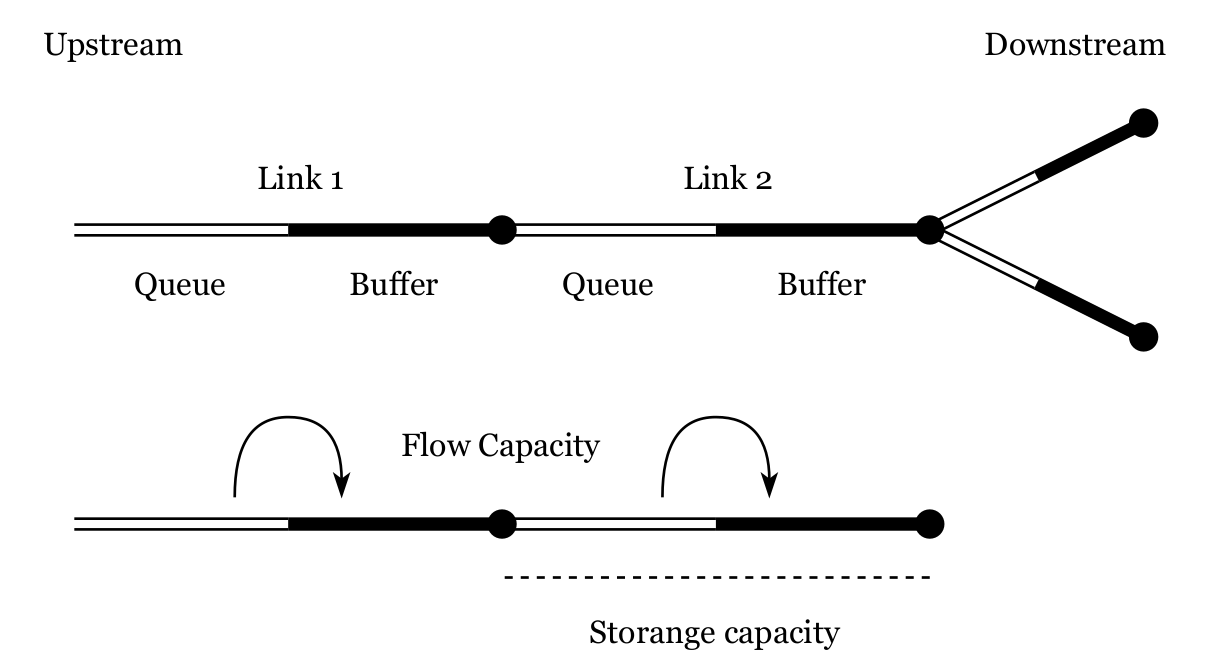
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Overview
An overview of transport modeling methodologies towards synthetic populations and agent-based models.
- The classic four-step model
- Synthetic populations
- Agent-based simulation
- Use cases
Automated taxi
Pickup
Dropoff
Use cases: On-demand mobility
- An operator centrally controls a fleet of vehicles
- Each vehicle is represented as an agent that receives instructions in each time step
-
Customer agents sent requests to be transported
- Objectives: maximize operator revenue, minimize empty distance, ...
Automated taxi
Pickup
Dropoff
Use cases: On-demand mobility
- An operator centrally controls a fleet of vehicles
- Each vehicle is represented as an agent that receives instructions in each time step
-
Customer agents sent requests to be transported
- Objectives: maximize operator revenue, minimize empty distance, ...
R1
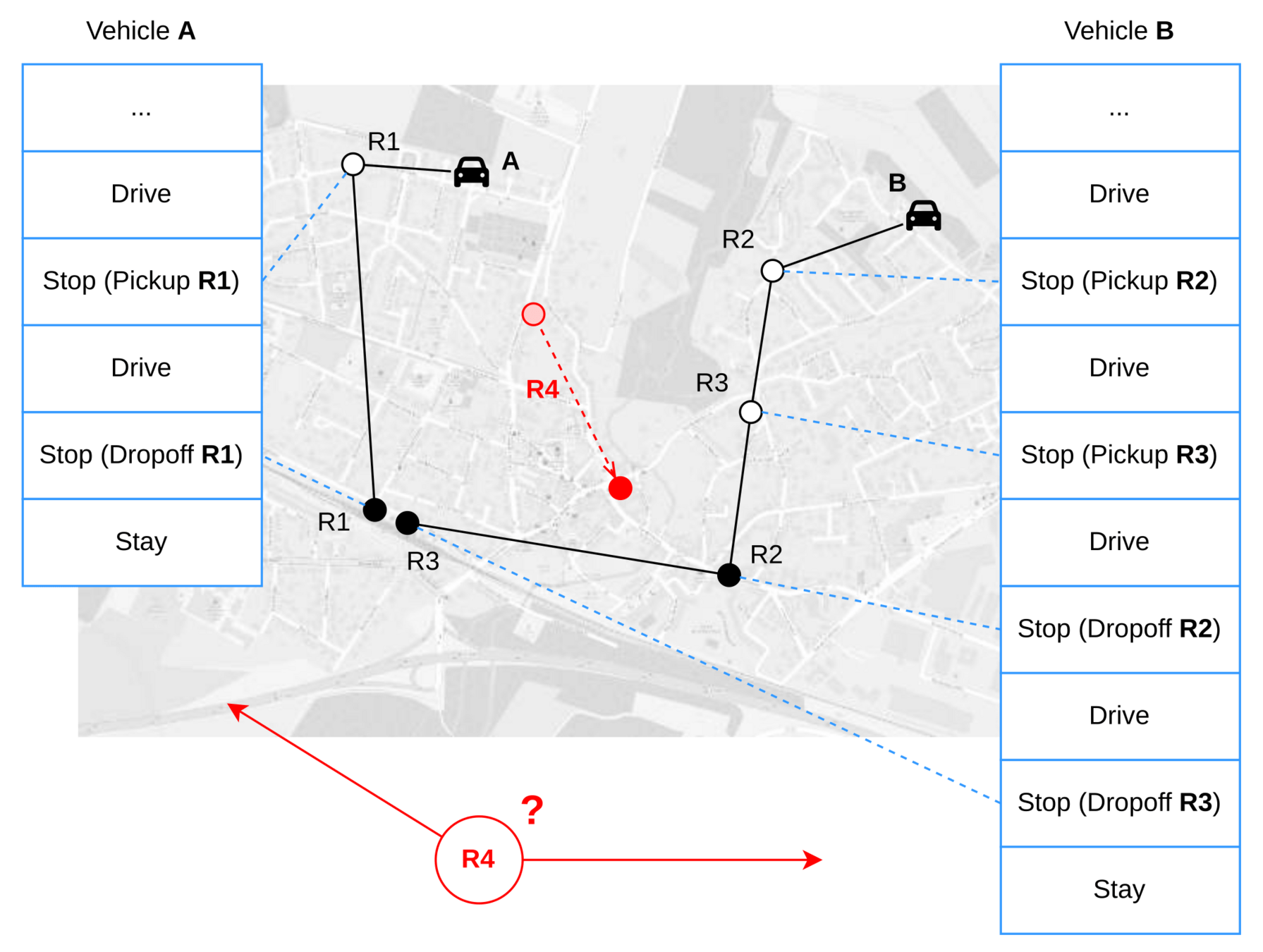
Use cases: On-demand mobility
- Different dispatching strategies provide different outcomes in terms of empty distance, revenue, and wait times
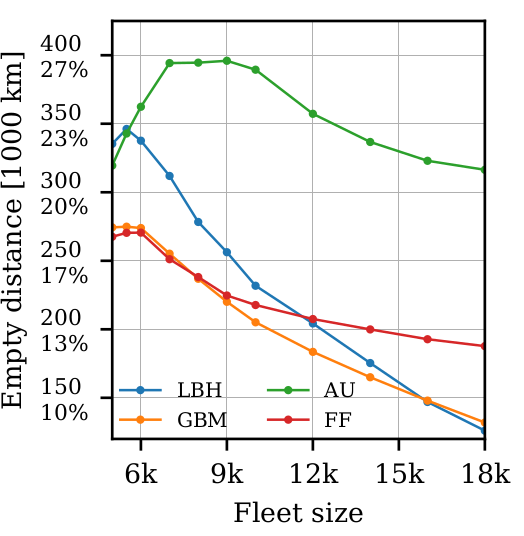
Use cases: On-demand mobility
Cost model
Discrete choice model
Mobility simulation
Estimation
Fare per trip and km
Wait time
Outcomes
Passenger distance, empty distance
- The problem becomes even more interesting when customer agents have the choice to use the service or not (dynamic demand)
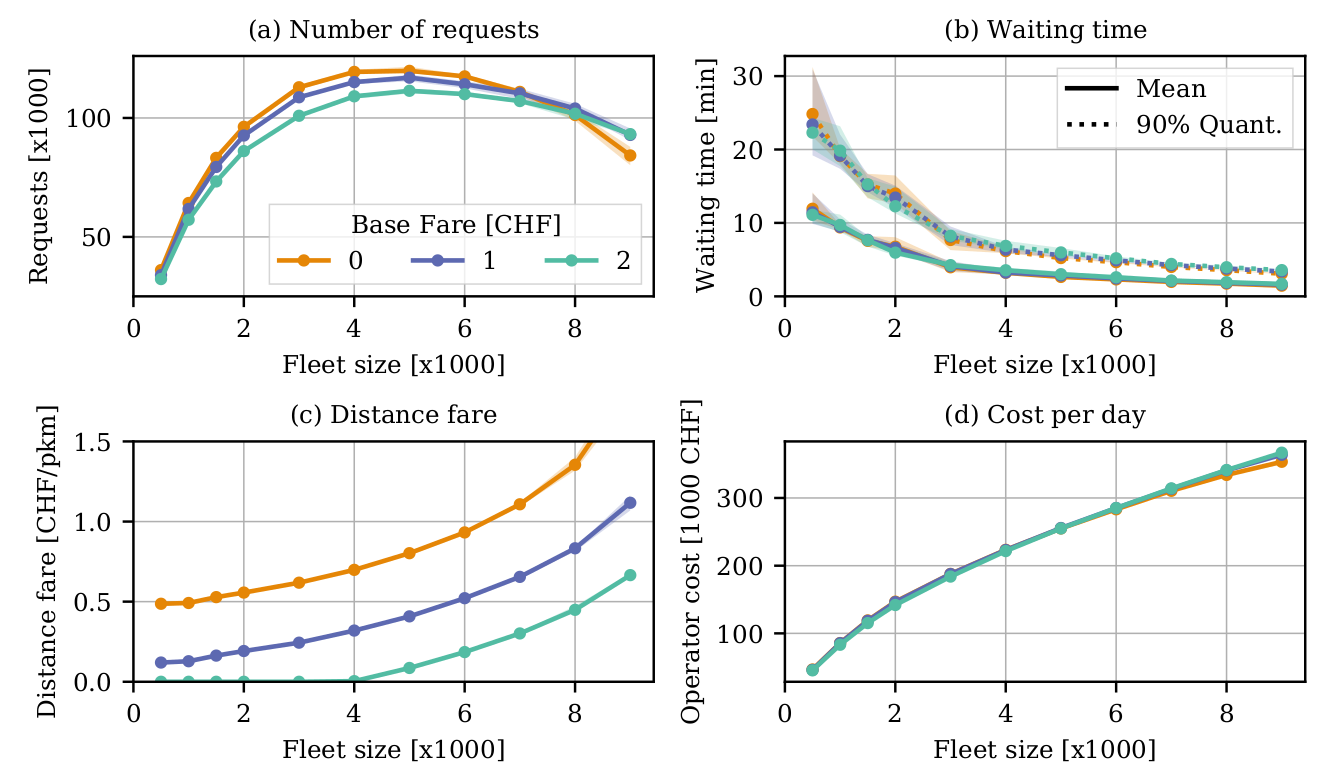
Use cases: On-demand mobility
- Provides an understanding of a mobility service that doesn't exist today
- Shows pathways for policy and regulation
Hörl, S., Becker, F., & Axhausen, K. W. (2021). Simulation of price, customer behaviour and system impact for a cost-covering automated taxi system in Zurich. Transportation Research Part C: Emerging Technologies, 123, 102974.
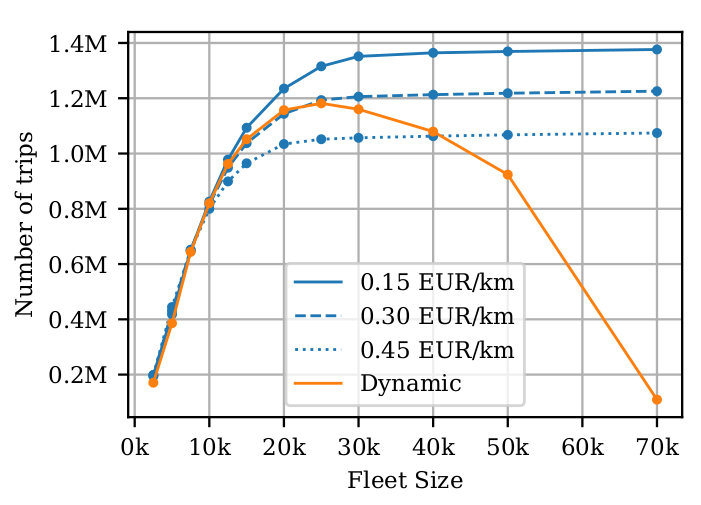
Use cases: On-demand mobility
Hörl, S., Balac, M., & Axhausen, K. W. (2019). Dynamic demand estimation for an AMoD system in Paris. IEEE Intelligent Vehicles Symposium (IV 2019), 260–266.
On-demand mobility: Intermodality
- How to combine on-demand mobility systems with public transport?
- How to take into account rejection rates in discrete choice models?
- Various other publications ...
Chouaki, T., Hörl, S., Puchinger, J., 2023. Towards Reproducible Simulations of the Grand Paris Express and On-Demand Feeder Services, in: 102nd Annual Meeting of the Transportation Research Board (TRB 2023). Washington D.C, United States.
Chouaki, T., Hörl, S., Puchinger, J., 2023. Control-based integration of rejection rates into endogenous demand ride-pooling simulations, in: 8th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS 2023). IEEE, Nice, France, pp. 1–6.
- How to combine on-demand mobility systems with public transport?
- How to take into account rejection rates in discrete choice models?
- Various other publications ...
Chouaki, T., Hörl, S., Puchinger, J., 2023. Towards Reproducible Simulations of the Grand Paris Express and On-Demand Feeder Services, in: 102nd Annual Meeting of the Transportation Research Board (TRB 2023). Washington D.C, United States.
Chouaki, T., Hörl, S., Puchinger, J., 2023. Control-based integration of rejection rates into endogenous demand ride-pooling simulations, in: 8th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS 2023). IEEE, Nice, France, pp. 1–6.
On-demand mobility: Intermodality
- How to combine on-demand mobility systems with public transport?
- How to take into account rejection rates in discrete choice models?
- Various other publications ...
Chouaki, T., Hörl, S., Puchinger, J., 2023. Towards Reproducible Simulations of the Grand Paris Express and On-Demand Feeder Services, in: 102nd Annual Meeting of the Transportation Research Board (TRB 2023). Washington D.C, United States.
Chouaki, T., Hörl, S., Puchinger, J., 2023. Control-based integration of rejection rates into endogenous demand ride-pooling simulations, in: 8th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS 2023). IEEE, Nice, France, pp. 1–6.

On-demand mobility: Intermodality
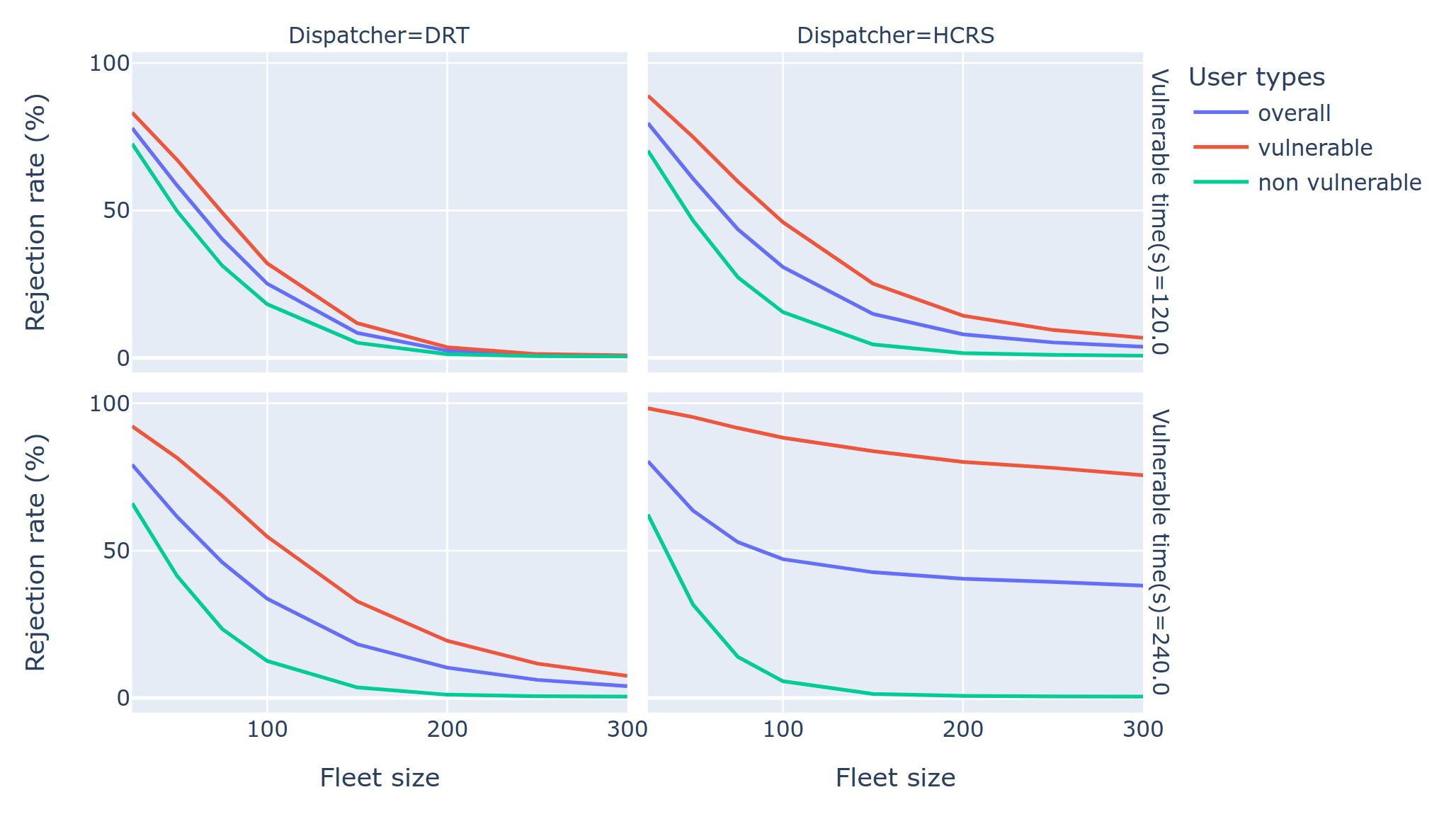
On-demand mobility: Algorithmic fairness
Do dispatching algorithms discriminate against certain user groups?
- Standard algorithms aim at minimizing wait times, travel times and maximizing revenue
- Do standard algorithms reject mobility-impaired person with longer interactions or larger groups more frequently than others?
-
Yes, they do!
- Can we mitigate the problem?
- Opens a whole new section of research in fleet management
Chouaki, T., Hörl, S., 2024. Comparative assessment of fairness in on-demand fleet management algorithms, in: The 12th Symposium of the European Association for Research in Transportation (hEART). Espoo, Finland.
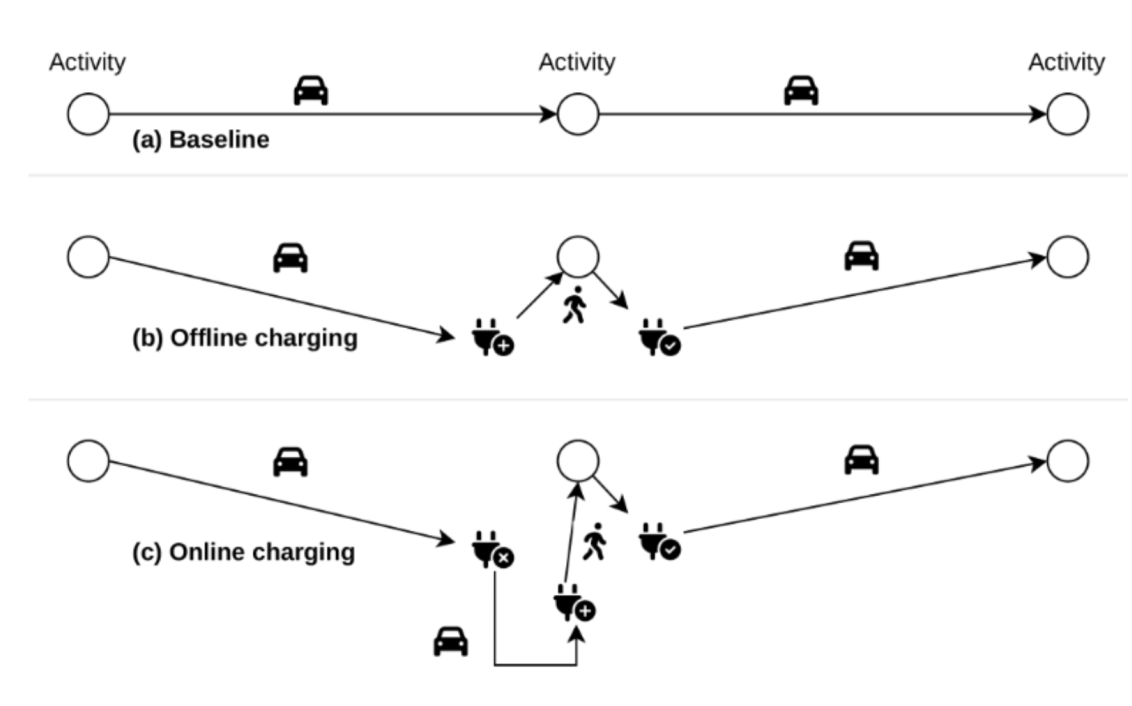
Infrastructure: Charging behaviour
How do people choose between public, home and work chargers for their electric cars?
- Very few data available (surveys and use)
-
Idea
- Assign electric vehicles to the population, then force them to charge (to avoid zero SoC)
- What is their ideal charging configuration, given the provided infrastructure?
- Collective charging strategy selection process (home, work, public) through maximization of scores
- Negative scores for zero SoC, falling below a minimum SoC during the day or at the end, monetary costs, ...

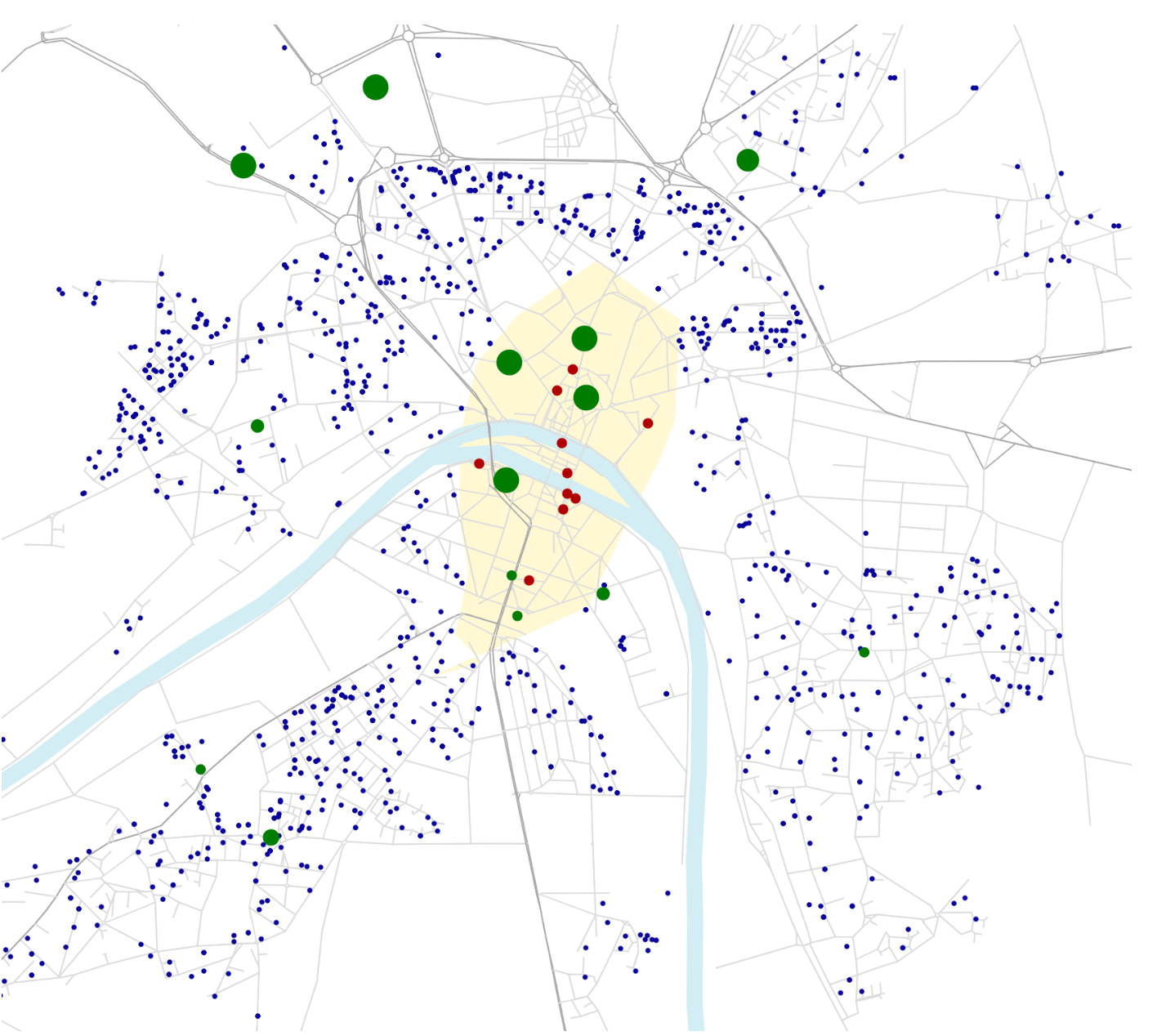
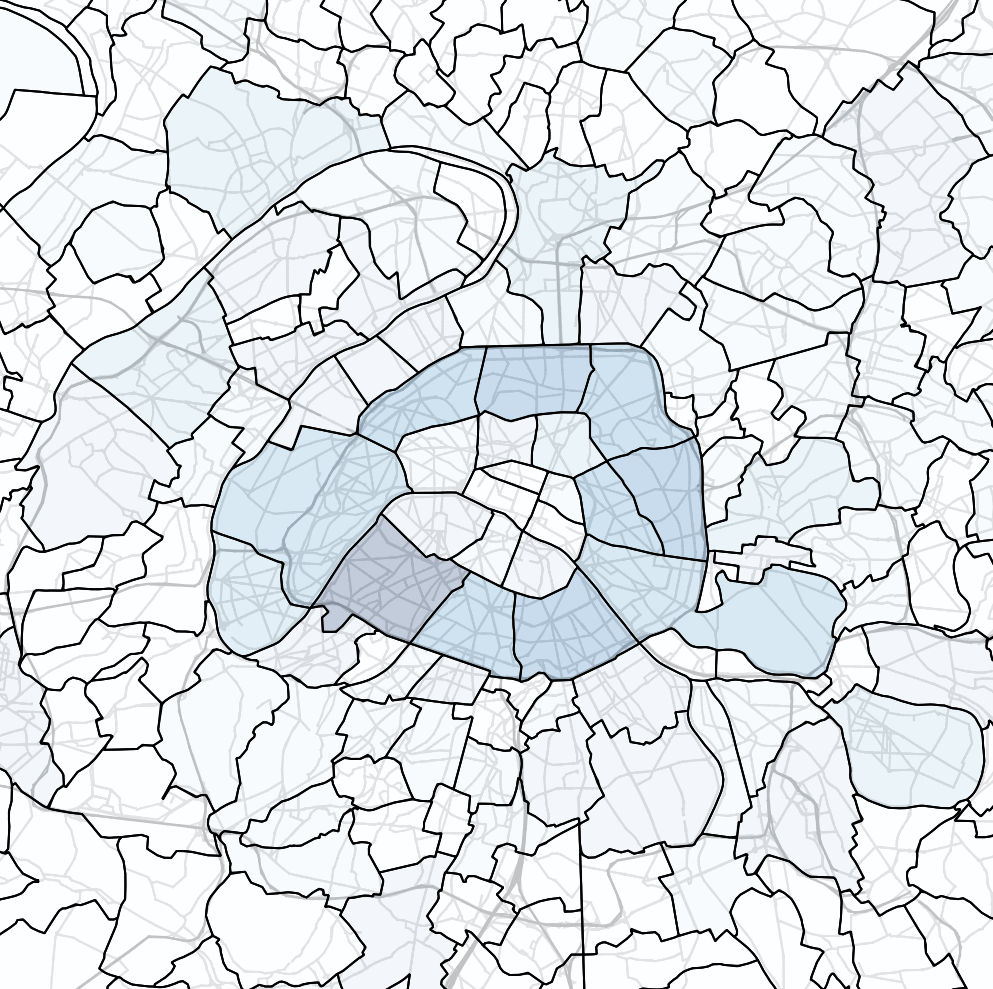
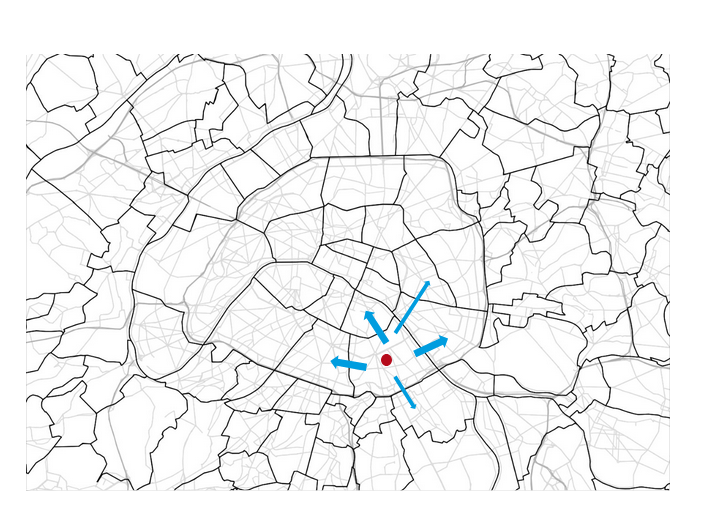
Transport policy: Limited traffic zones

What is the impact of the Limited Traffic Zone in the center of Paris?
- Rule: Non-residents that are not performing an activity in the center of Paris are not allowed to go through the center zone
- We can analyze which persons (agents) are affected by that policy
- We can measure the impact of the policy on the surrounding traffic
- High level estimation of traffic and emission impact
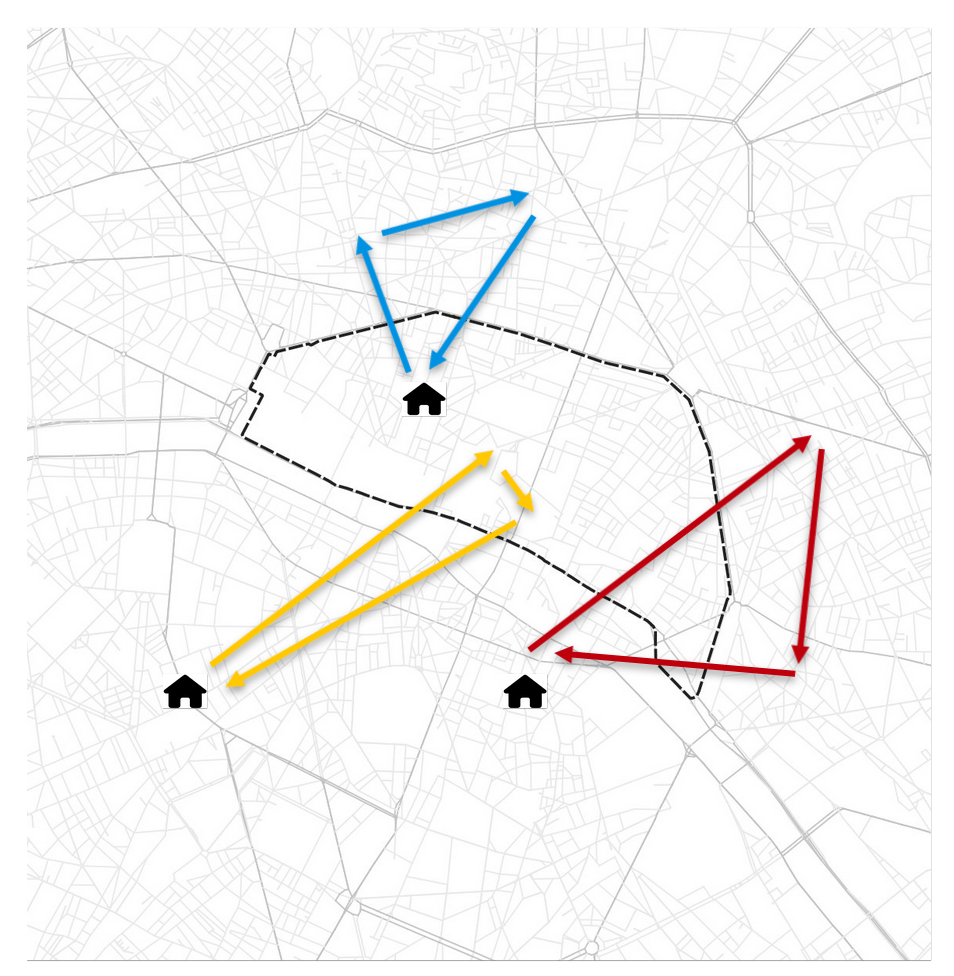
Residents
Transit
Visitors
Transport policy: Limited traffic zones
What is the impact of the Limited Traffic Zone in the center of Paris?
- Rule: Non-residents that are not performing an activity in the center of Paris are not allowed to go through the center zone
- We can analyze which persons (agents) are affected by that policy
- We can measure the impact of the policy on the surrounding traffic
- High level estimation of traffic and emission impact
Transport policy: Limited traffic zones
What is the impact of the Limited Traffic Zone in the center of Paris?
- Rule: Non-residents that are not performing an activity in the center of Paris are not allowed to go through the center zone
- We can analyze which persons (agents) are affected by that policy
- We can measure the impact of the policy on the surrounding traffic
- High level estimation of traffic and emission impact
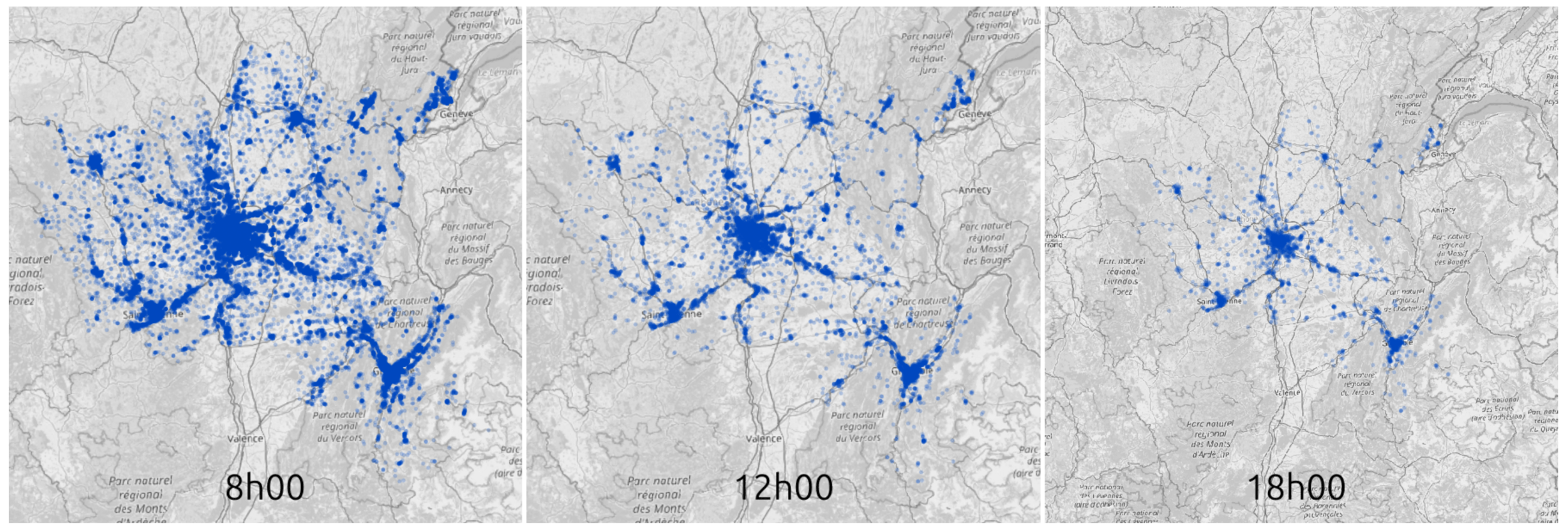
Overall flow related to the ZTL
Transport policy: Limited traffic zones
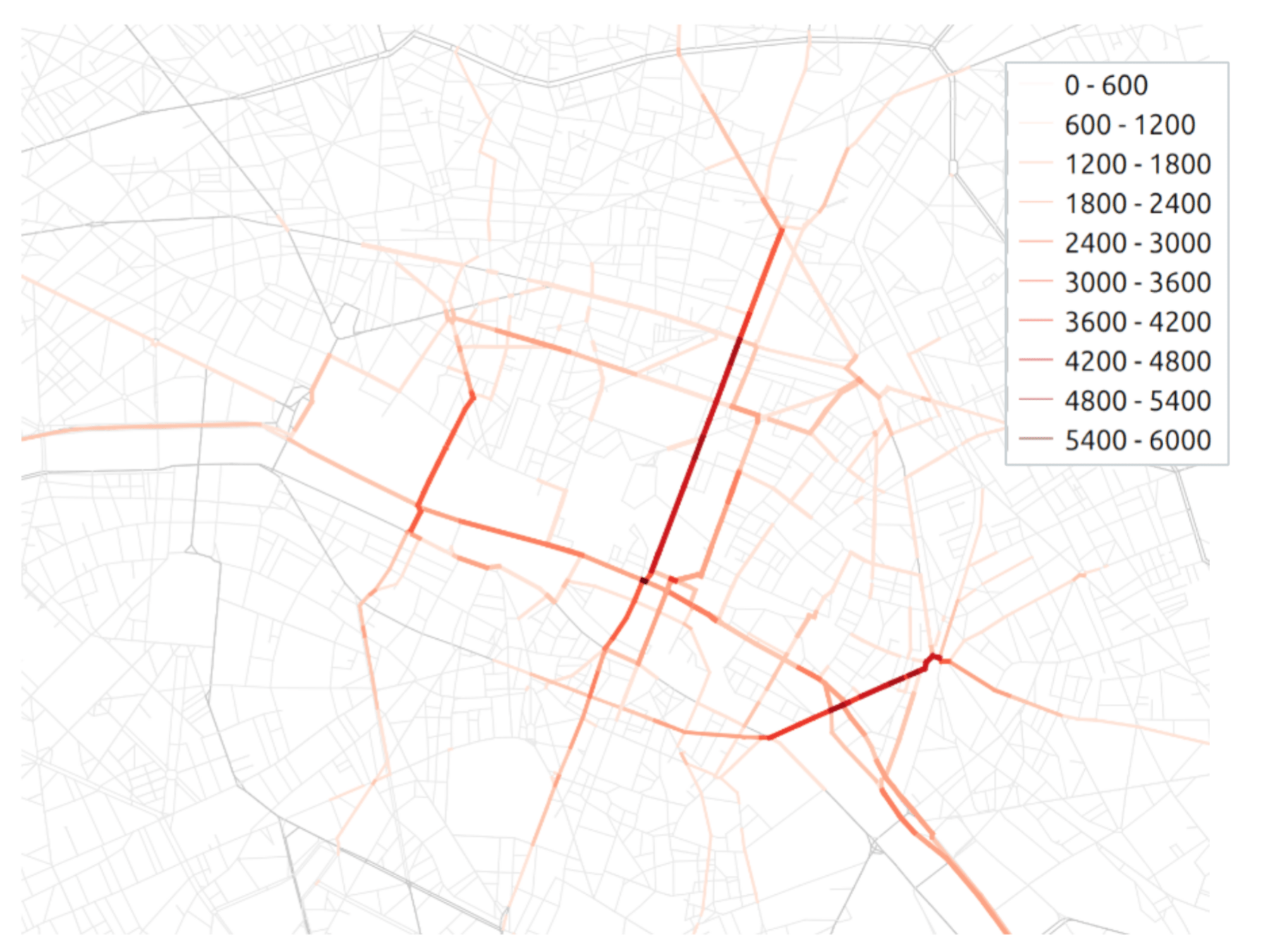
Transit flow related to the ZTL
What is the impact of the Limited Traffic Zone in the center of Paris?
- Rule: Non-residents that are not performing an activity in the center of Paris are not allowed to go through the center zone
- We can analyze which persons (agents) are affected by that policy
- We can measure the impact of the policy on the surrounding traffic
- High level estimation of traffic and emission impact
Transport policy: Limited traffic zones
Transit flow related to the ZTL
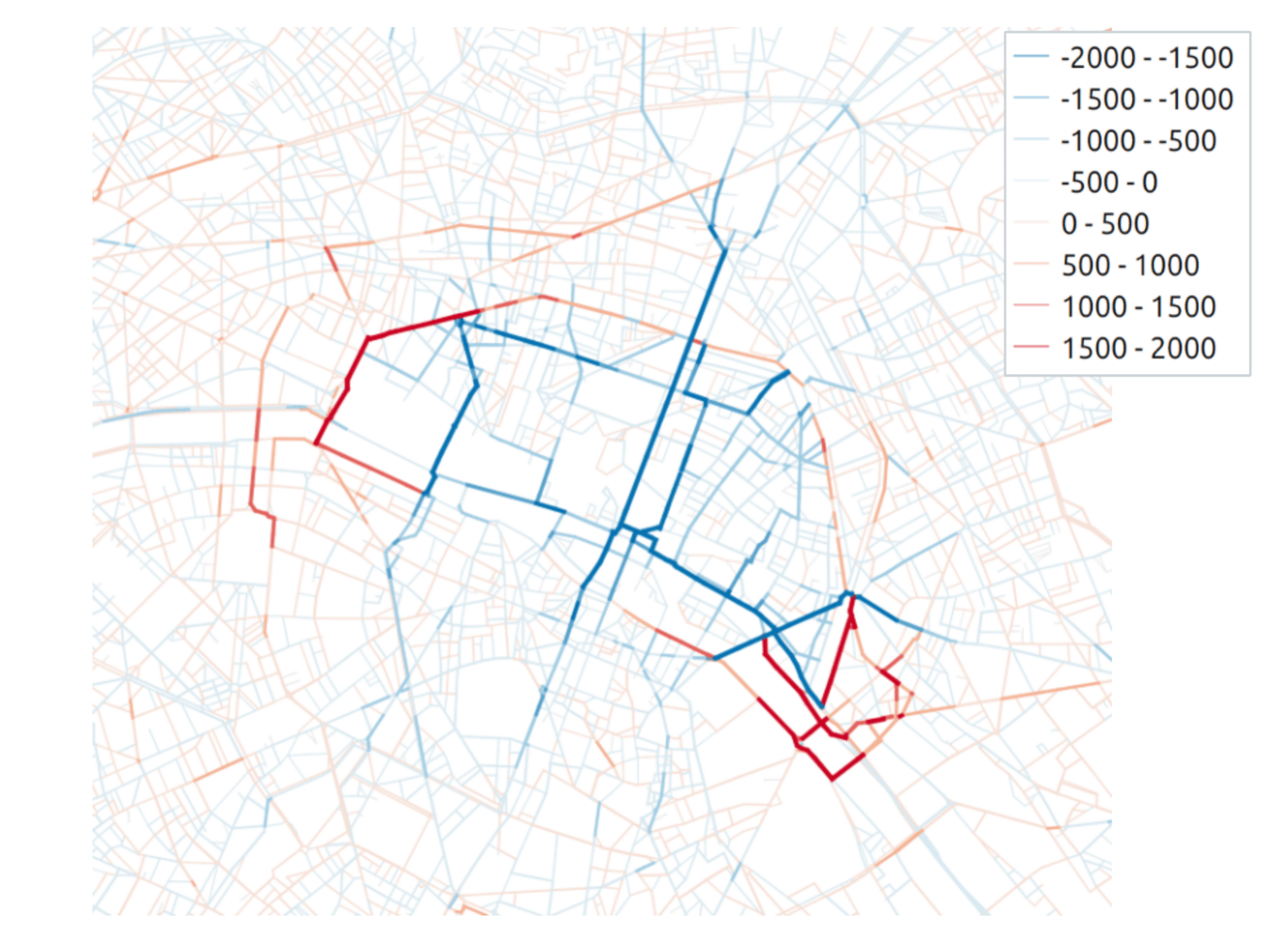
Difference after introduction of ZTL
What is the impact of the Limited Traffic Zone in the center of Paris?
- Rule: Non-residents that are not performing an activity in the center of Paris are not allowed to go through the center zone
- We can analyze which persons (agents) are affected by that policy
- We can measure the impact of the policy on the surrounding traffic
- High level estimation of traffic and emission impact
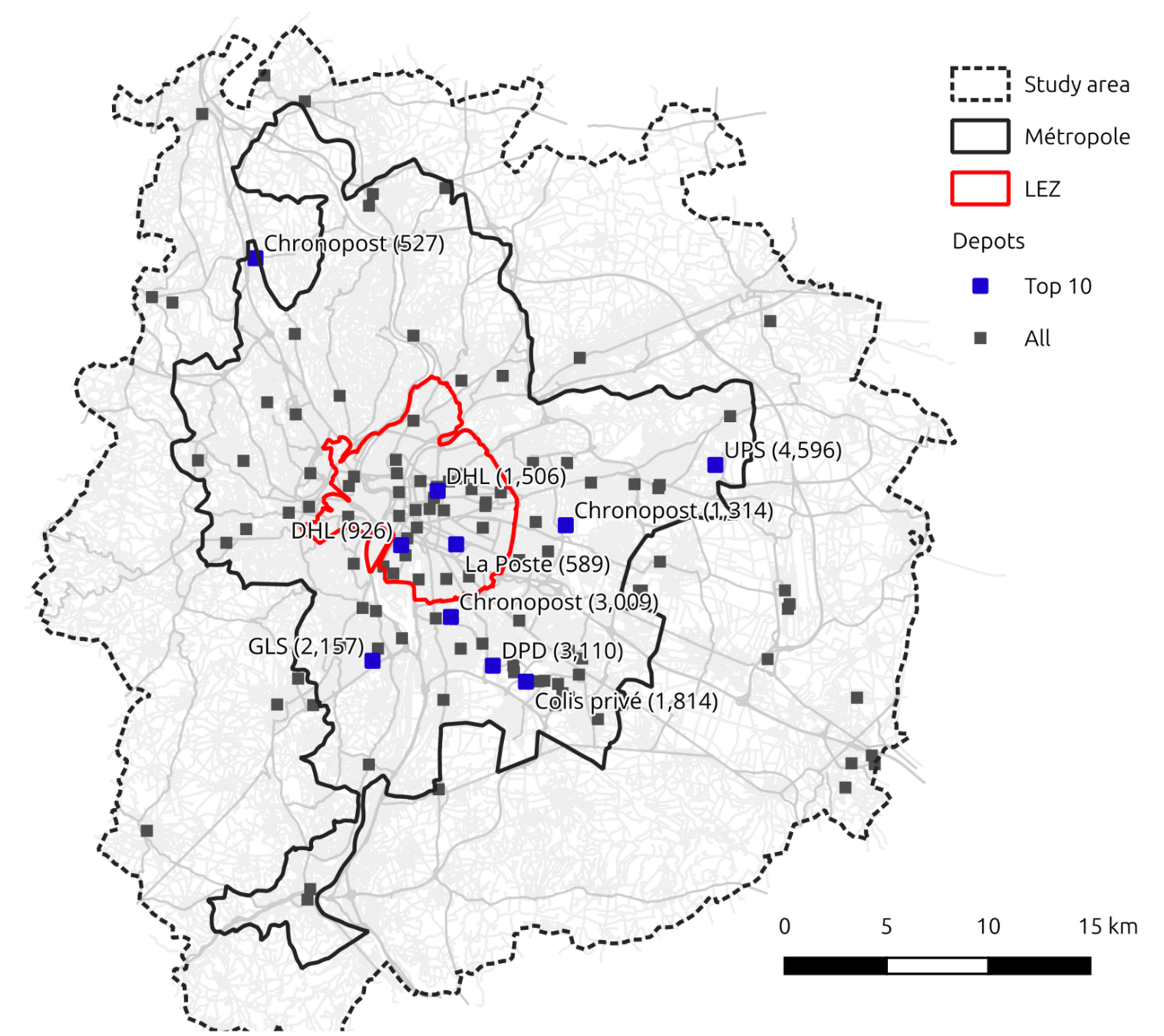
Transport policy: Parcel deliveries
A detailed study of environmental policies on parcel deliveries
- Obtaining a daily synthetic parcel demand based on a synthetic population for Lyon and statistics (Gardrat)
- Identifying all logistics centers in the area
- Cost structures (vehicles, drivers, operational) for ICVs and BEVs (small, medium, large)
- Definition of one Heterogeneous Fleet VRP per logistics center, sensitive to cost inputs
- Testing of CO2 tax, ICV tax, qualitative policies

Transport policy: Parcel deliveries
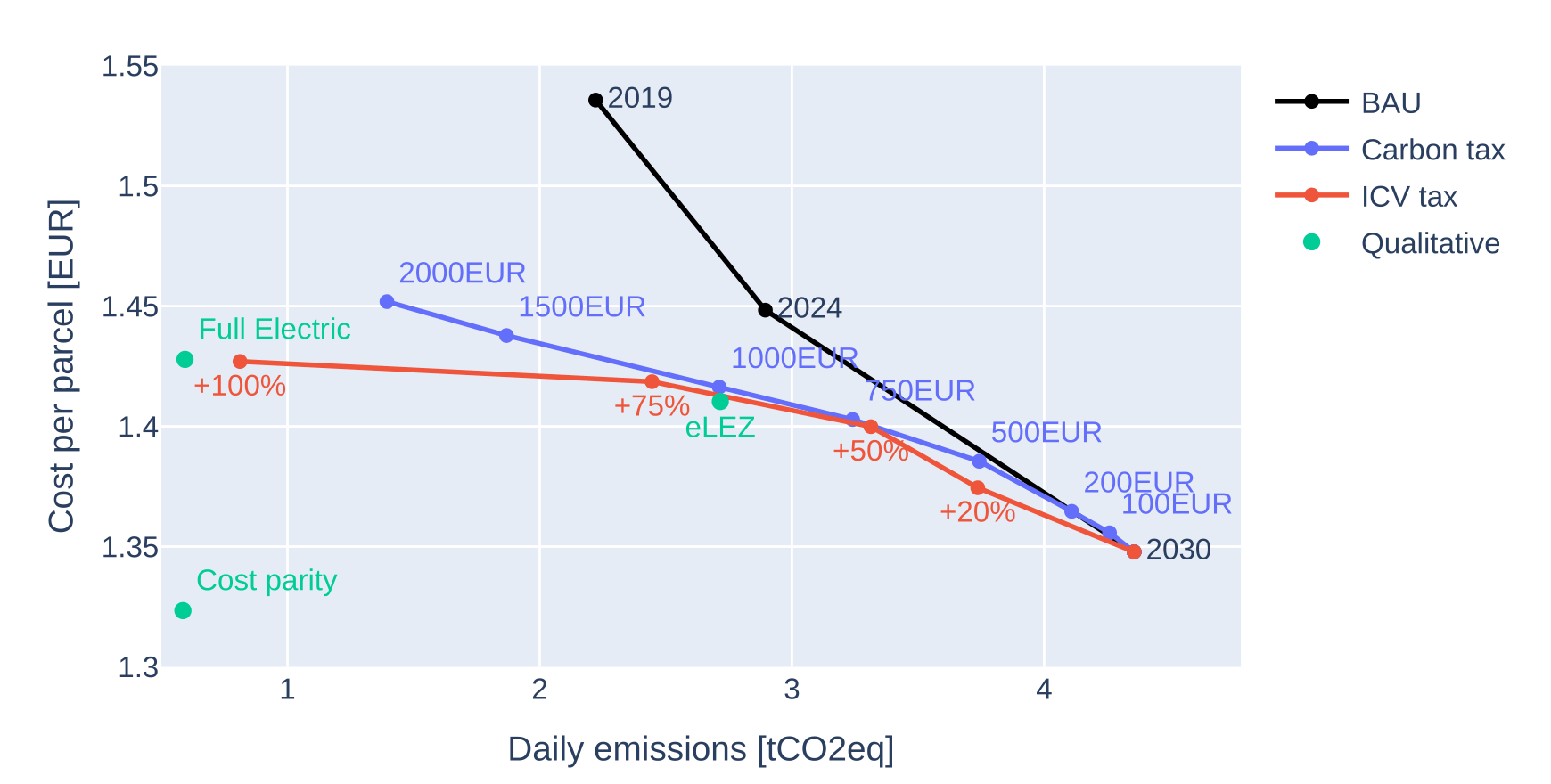
A detailed study of environmental policies on parcel deliveries
- Obtaining a daily synthetic parcel demand based on a synthetic population for Lyon and statistics (Gardrat)
- Identifying all logistics centers in the area
- Cost structures (vehicles, drivers, operational) for ICVs and BEVs (small, medium, large)
- Definition of one Heterogeneous Fleet VRP per logistics center, sensitive to cost inputs
- Testing of CO2 tax, ICV tax, qualitative policies
Hörl, S., Briand, Y., & Puchinger, J. (2025). Decarbonization policies for last-mile parcels: A replicable open-data case study for Lyon. Transportation Research Part D: Transport and Environment, 146, 104893.
Use cases: Community
Lille
Paris
Strasbourg
Lyon
Toulouse
Bordeaux
Nantes
Rennes
Contributors
Users
Paris
Bordeaux
Nantes
Impacts of noise on the population
- Connection with the open-source NoiseModeling framework
- Estimation of per-agent noise impact over an entire day
Le Bescond, V., Can, A., Aumond, P., & Gastineau, P. (2021). Open-source modeling chain for the dynamic assessment of road traffic noise exposure. Transportation Research Part D: Transport and Environment, 94, 102793.
Hankach, P., Le Bescond, V., Gastineau, P., Vandanjon, P.-O., Can, A., & Aumond, P. (2024). Individual-level activity-based modeling and indicators for assessing construction sites noise exposure in urban areas. Sustainable Cities and Society, 101, 105188.
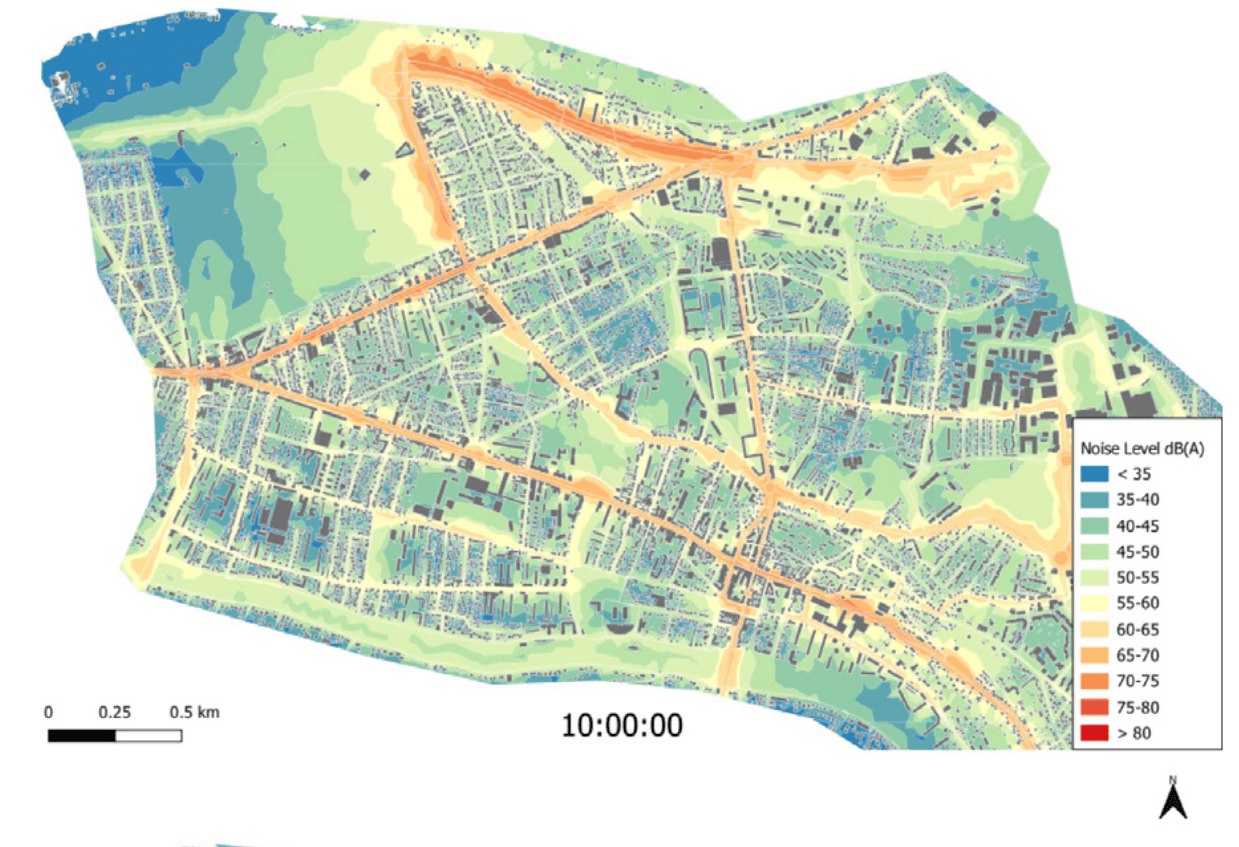
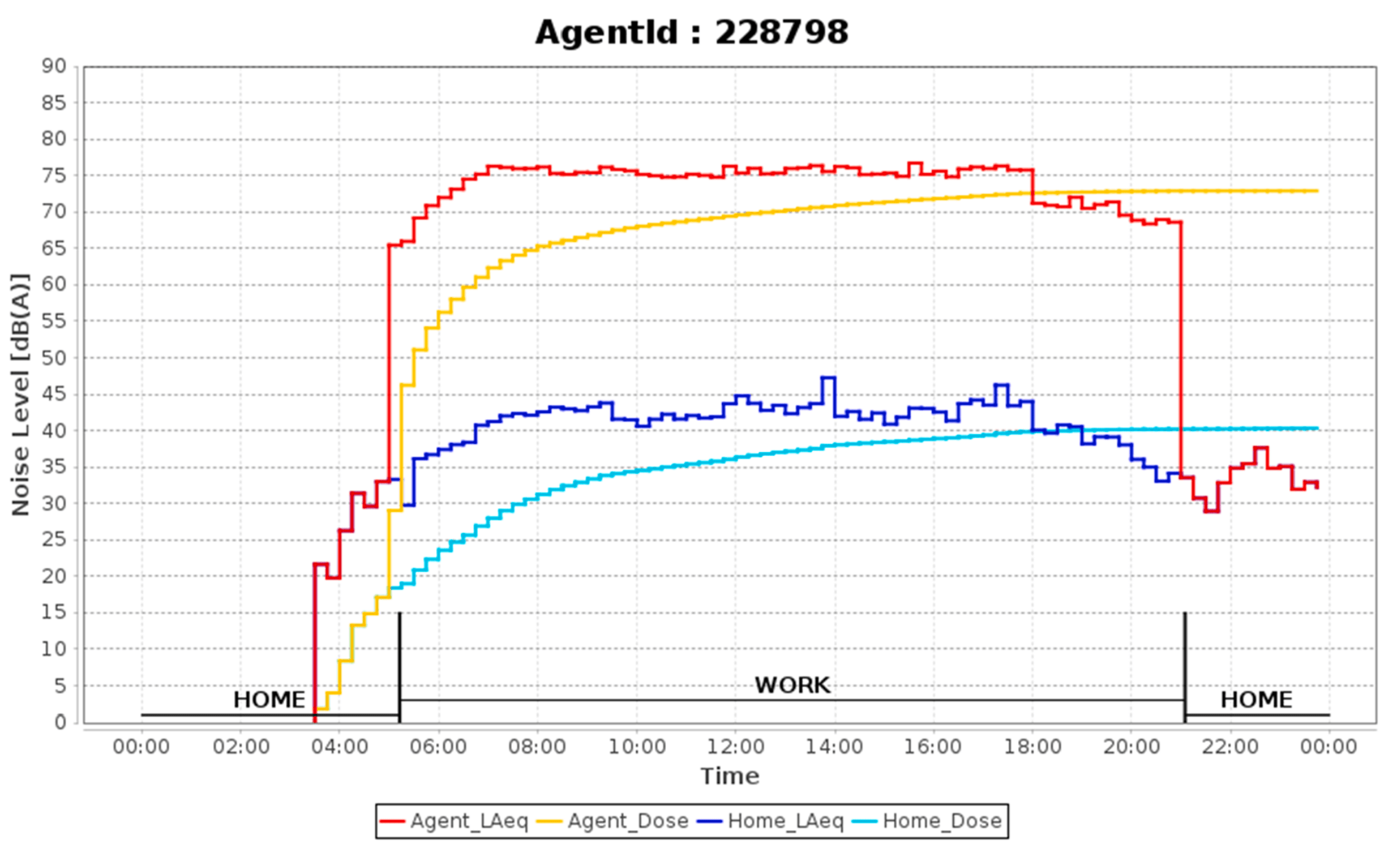
Use cases: Community
Lyon
Access to green spaces and quiet areas
- Individual-based geographic analysis of green space access per person
- Recommendations on urban development
Luquezi, L. G., Le Bescond, V., Aumond, P., Gastineau, P., & Can, A. (2025). Assessing accessibility to quiet and green areas at the city scale using an agent-based transport model. Landscape and Urban Planning, 263, 105452.
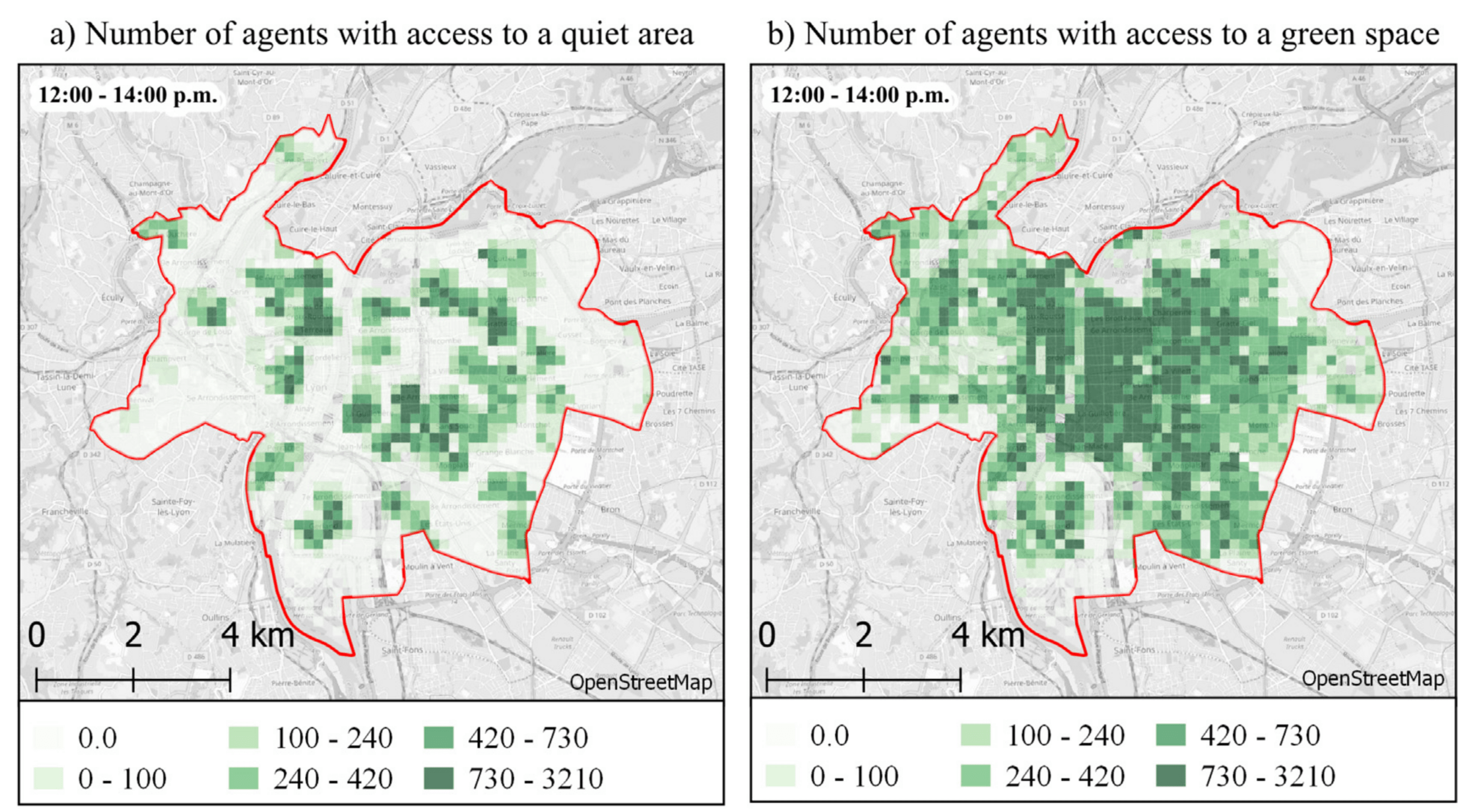
Use cases: Community
Lille
Mobility pricing and park + ride
- Implementation of a city tax to be paid when entering the city by car
- Development of additional park & ride infrastructure
Diallo, A. O., Lozenguez, G., Doniec, A., & Mandiau, R. (2023). Agent-Based Approach for (Peri-)Urban Inter-Modality Policies: Application to Real Data from the Lille Metropolis. Sensors, 23(5).
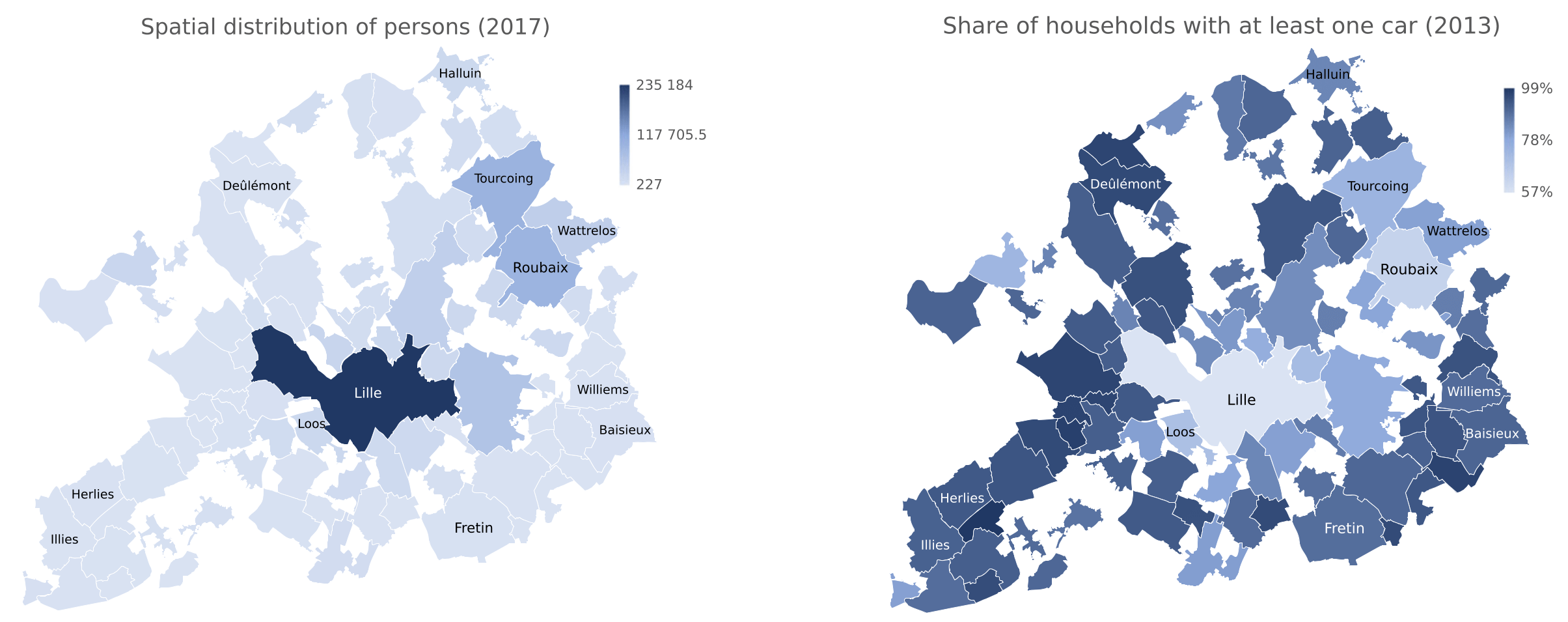
Diallo, A. O., Lozenguez, G., Doniec, A., & Mandiau, R. (2025). Utility-based agent model for intermodal behaviors: A case study for urban toll in Lille. Applied Intelligence, 55(4), 282.
Use cases: Community
Lille
Lyon
Toulouse
Rennes
Shared mobility services in Rennes
- Connection with shared mobility simulation package Starling
Manout, O., Diallo, A. O., & Gloriot, T. (2024). Implications of pricing and fleet size strategies on shared bikes and e-scooters: A case study from Lyon, France. Transportation.
Leblond, V., Desbureaux, L., & Bielecki, V. (2020). A new agent-based software for designing and optimizing emerging mobility services: Application to city of Rennes. European Transport Conference 2020, 17.
Dimensioning of shared bicycle supply in Lyon
- Agent-based simulations on pricing and fleet sizing
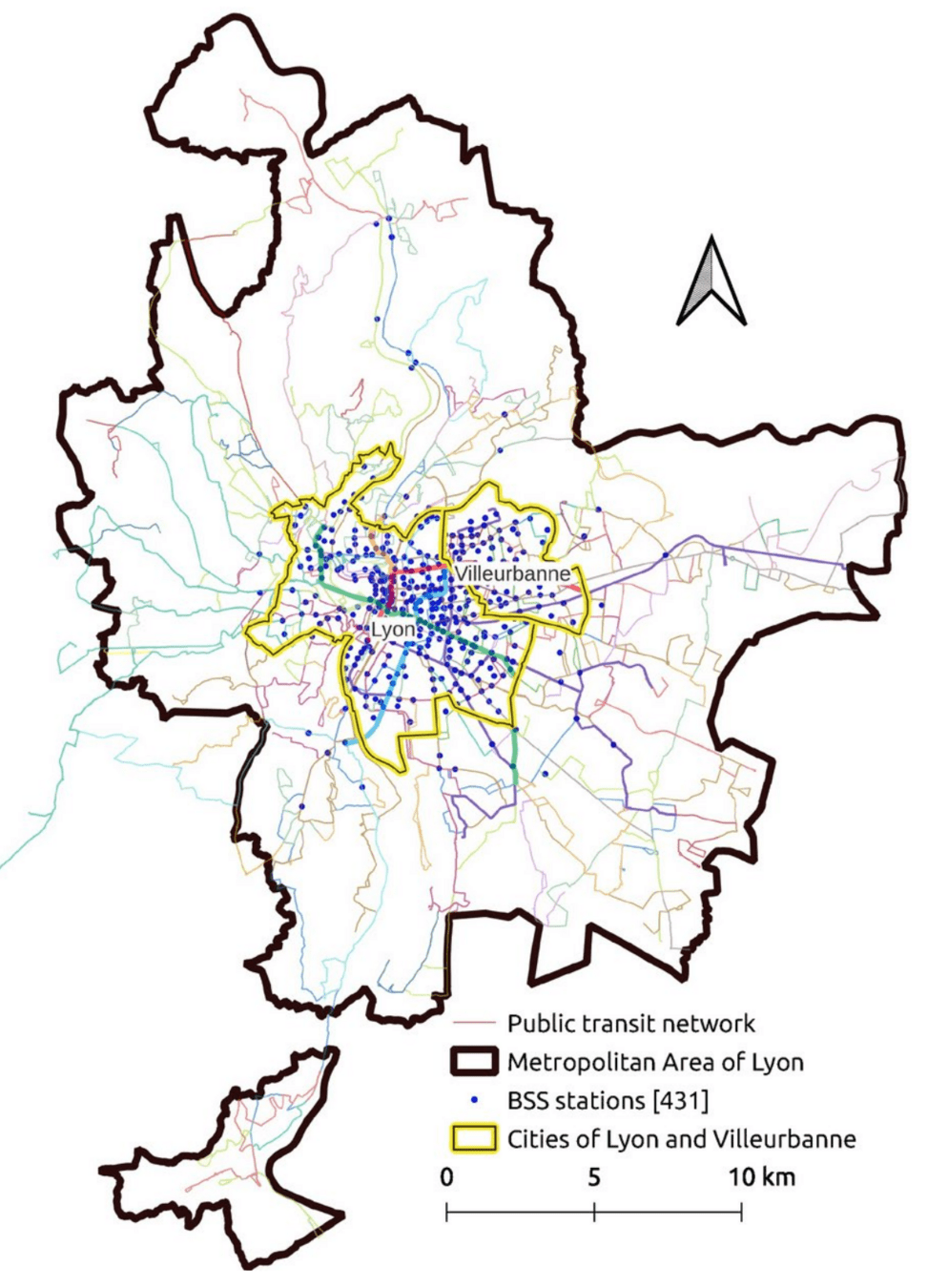
Use cases: Community
Communication: Interface development

TERRITORIA prize 2024
with Paris Saclay

- Ambition to provide project results through interactive interfaces
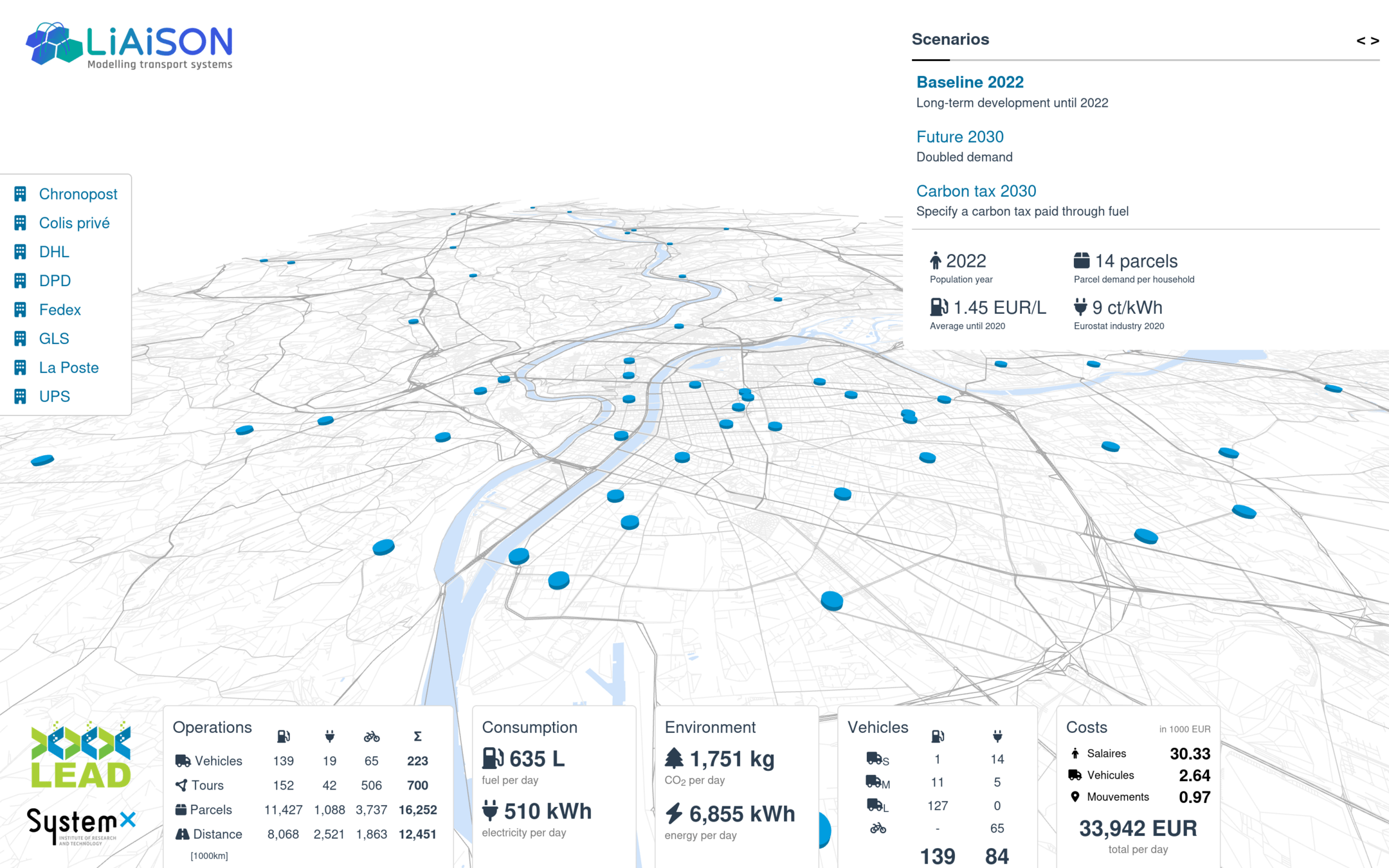
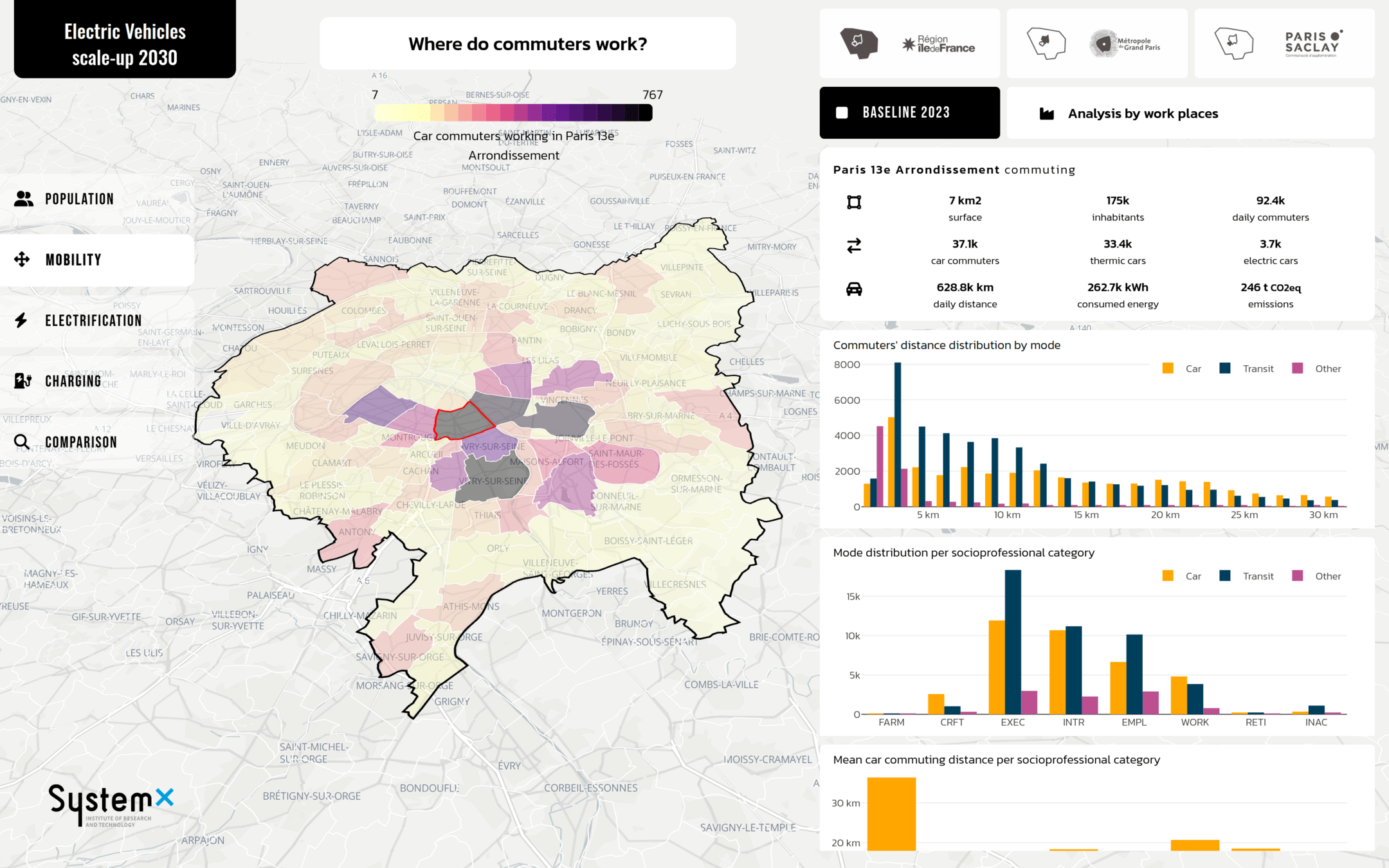
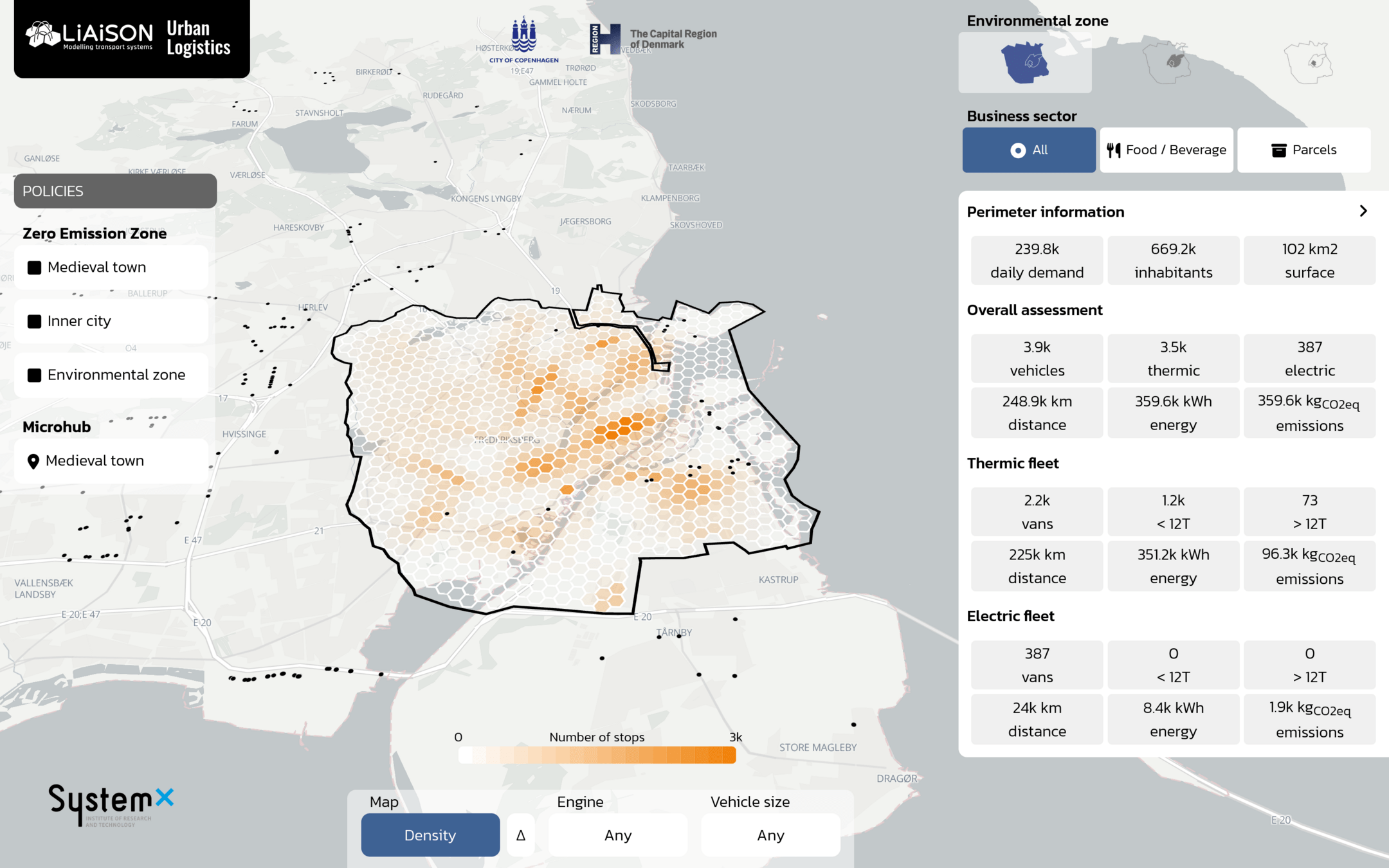
Thank you!
sebastian.horl@irt-systemx.fr
Icons throughout the presentation: https://fontawesome.com
Website
Contact

