Network—feature dependencies using graph convolutional auto-encoders
Sébastien Lerique, Jacobo Levy-Abitbol, Márton Karsai & Éric Fleury
Questions
network—feature dependencies

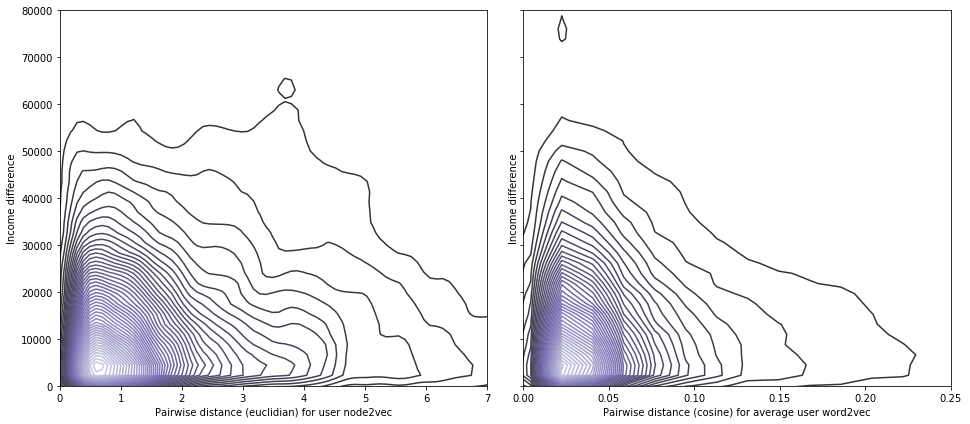
In Twitter (courtesy of Jacobo)
Problem reduction
-
2-way: how much do network structure and feature structure correlate
-
3-way: how well does feature set 1 + network structure predict feature set 2
(and how much does network structure help in predicting) -
Combined: how much can we compress network + features (down to what dimension)



network—feature dependencies
network—feature independence
Use deep learning to explore these
A framework
Graph convolutional neural networks + Auto-encoders
How is this framework useful
Reformulate our questions
Status update
Where are we at & what's next
Neural networks

x
y
green
red

\(H^{(l+1)} = \sigma(H^{(l)}W^{(l)})\)
\(H^{(0)} = X\)
\(H^{(L)} = Z\)
Inspired by colah's blog
Graph-convolutional neural networks




\(H^{(l+1)} = \sigma(H^{(l)}W^{(l)})\)
\(H^{(0)} = X\)
\(H^{(L)} = Z\)
\(H^{(l+1)} = \sigma(\color{DarkRed}{\tilde{D}^{-\frac{1}{2}}\tilde{A}\tilde{D}^{-\frac{1}{2}}}H^{(l)}W^{(l)})\)
\(H^{(0)} = X\)
\(H^{(L)} = Z\)
\(\color{DarkGreen}{\tilde{A} = A + I}\)
\(\color{DarkGreen}{\tilde{D}_{ii} = \sum_j \tilde{A}_{ij}}\)
Kipf & Welling (2017)
Semi-supervised GCN netflix
Four well-marked communities of size 10, small noise
Five well-marked communities of size 20, moderate noise
Overlapping communities of size 12, small noise
Two feature communities in a near-clique, small noise
Auto-encoders

From blog.keras.io
- Usually trained to reconstruct their input
- A bottleneck forces a compression → creates embeddings
- Lets us apply any architecture as encoder
- Lets us emphasize aspects of the input to reconstruct
high dimension
high dimension
low dimension
Example — auto-encoding MNIST digits

MNIST Examples by CC-BY-SA 4.0)
60,000 training images
28x28 pixels
784 dims
784 dims
2D

From blog.keras.io
GCN + Auto-encoders = 🎉💖🎉
node features
embedding
GCN
node features
adjacency matrix
Socio-economic status
Language style
Topics
Socio-economic status
Language style
Topics


Compressed & combined representation of nodes + network
How is this useful
a.k.a., questions we can (will be able to) ask
2-way: how much do network structure and feature structure correlate
Combined: how much can we compress network + features
(down to what dimension)
3-way: how well does feature set 1 + network structure predict feature set 2
(and how much does network structure help in predicting)
Force a 2D embedding with one axis for each type of information
AE input = feature set 1
AE output = feature set 2
with / without convolutions
Plot the embedding dimension vs. reconstruction accuracy
Status update
✔ Graph convolutions exploration
✔ Variational AE basic implementation
✔ Feature + Adjacency reconstruction
✔ Adjacency reconstruction normalisation
✔ Sensitivity analysis
✔ Mini-batch training
✔ Smarter mini-batch sampling
👷 Exploring small real data sets BlogCatalog, Flickr, YouTube
👷 2nd sensitivity analysis for mini-batching on real datasets
👷 Refining target questions
👷 Choosing language features
👷 Scaling up to Twitter
Mini-batching — sampling


node2vec, Grover & Leskovec (2016)
walk back \(\propto \frac{1}{p}\)
walk out \(\propto \frac{1}{q}\)
walk in triangle \(\propto 1\)
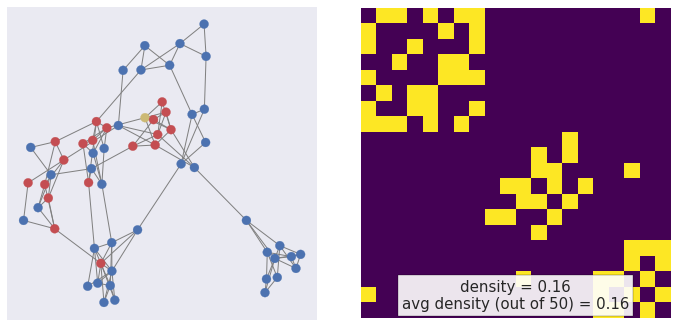
Non-biased
p=1, q=1
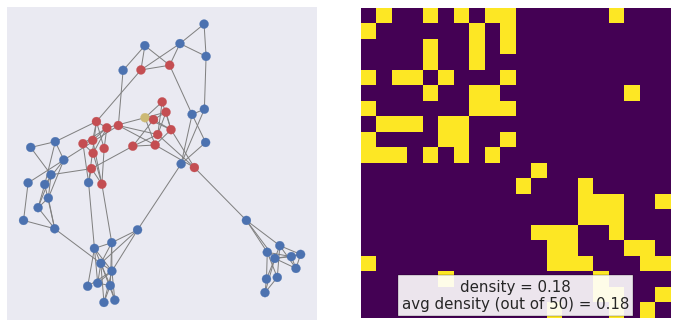
Triangles
p=100, q=100

Walk out
p=1, q=.01
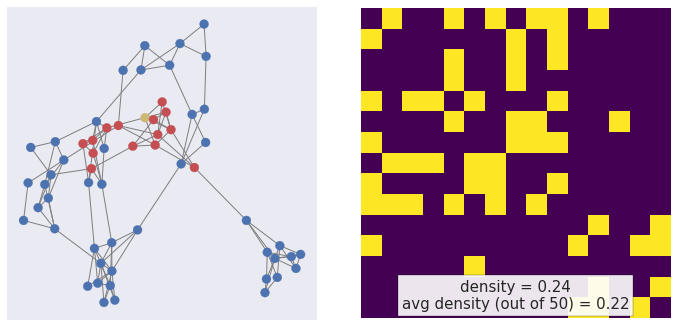
Walk back
p=.01, q=1
Thank you!
Jacobo, Márton, Éric