Computation, Constructivism, and Curriculum Design
Shayan Doroudi
Carnegie Mellon University
Thesis Proposal
Automated Content Selection
Prior Work:
- Ed Tech: Mostly rely on domain expertise and hand-designed rules.
- Machine Learning: Use black box reinforcement learning algorithms.
My Approach:
Combine aspects of both for greater impact.
Thesis Statement
I focus on scalable automated content selection, using methods that combine machine learning, human computation, and principles from the learning sciences
- Creating more robust content selection policies by considering model mismatch.
- Using students to create content in a cost-effective way.
- Using machine learning to curate content.
- Using learning science principles to constrain the search for good content selection policies.
Thesis Statement
- Model Robustness (Completed)
- Content Creation (Ongoing Work)
- Content Curation (Ongoing Work)
- Learning Sciences + Content Selection (Early Stages)
I focus on scalable automated content selection, using methods that combine machine learning, human computation, and principles from the learning sciences
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
Two Common Approaches
Cognitive Mastery Learning
Overconstrained
Reinforcement Learning (RL)
Underconstrained
Mastery Learning
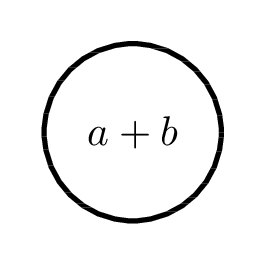


Bayesian Knowledge Tracing (BKT)
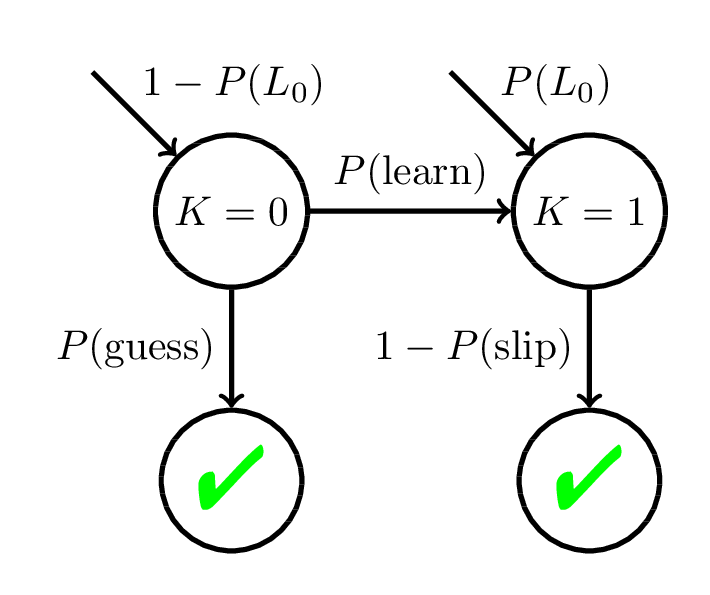
Corbett and Anderson, 1994
Mastery Learning
Cognitive Mastery Learning
Heuristic Mastery Learning
Corbett and Anderson, 1994
Kelly, Wang, Thompson, and Heffernan, 2015
Mastery Learning:
Empirical Evidence?
- Mastery learning is commonly used in successful educational technology such as intelligent tutoring systems, but...
- Mastery learning may not be the reason for the success of these systems (Sales and Pane, 2017).
- Using a simple heuristic to do mastery learning may be just as good or better than using a model + AI (Pelánek and Řihák, 2017; Kelly, Wang, Thompson, and Heffernan, 2015).
Reinforcement Learning
Use student response data to find the optimal adaptive content selection policy.
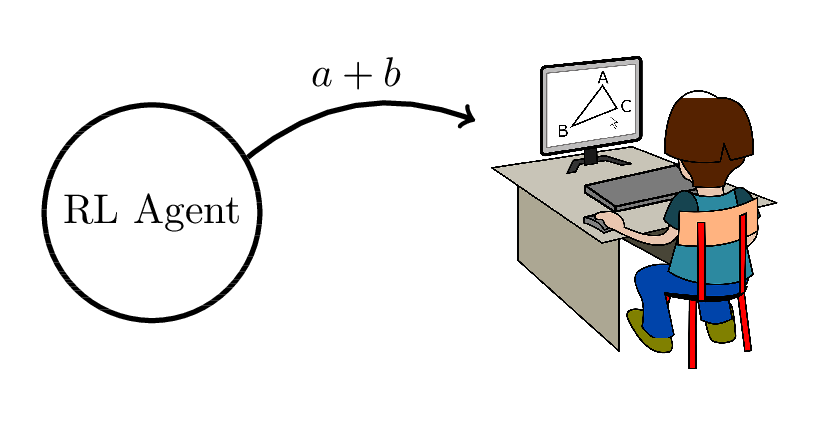
Reinforcement Learning
Use student response data to find the optimal adaptive content selection policy.
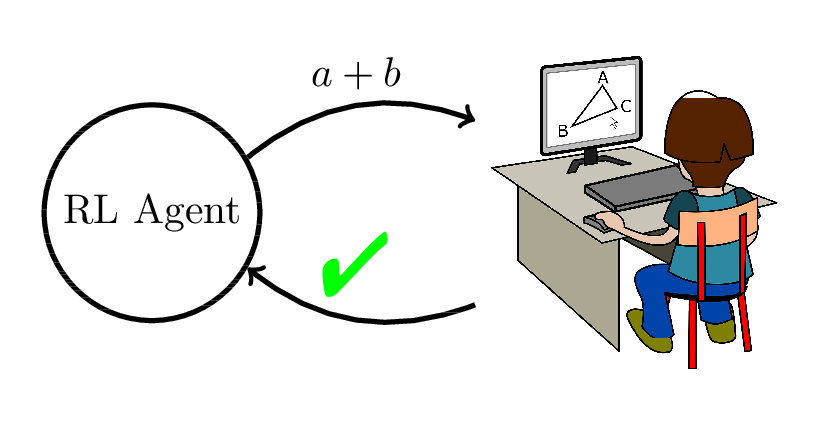
Reinforcement Learning
Use student response data to find the optimal adaptive content selection policy.
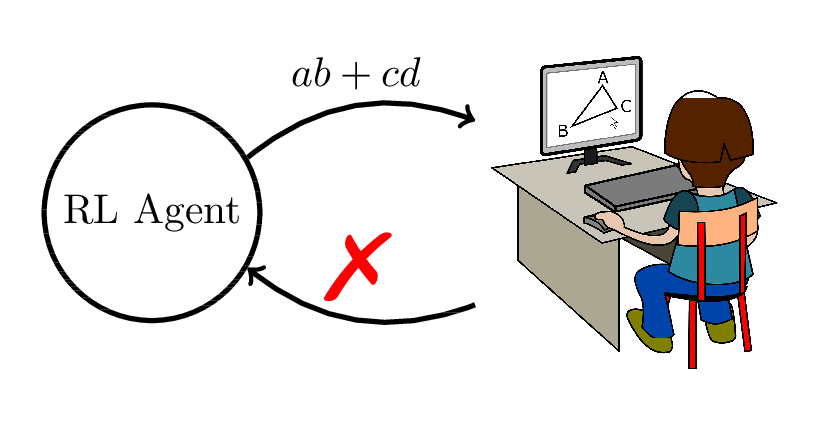
Reinforcement Learning
Use student response data to find the optimal adaptive content selection policy.
Reinforcement Learning
Use student response data to find the optimal adaptive content selection policy.
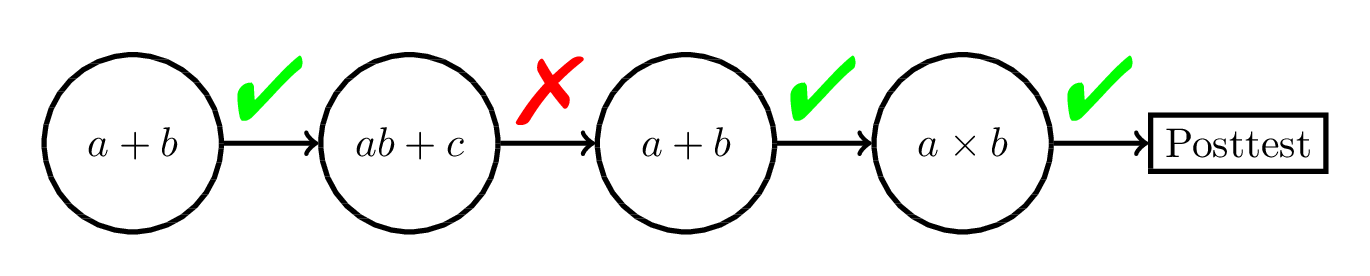
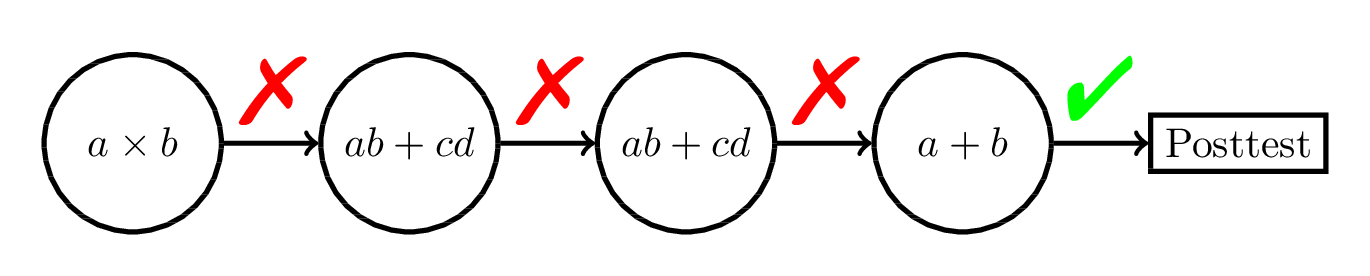
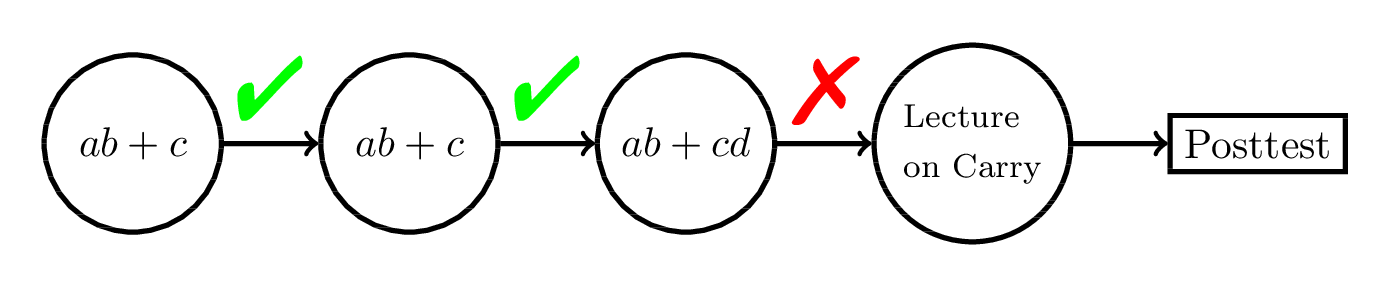
RL-Based Approaches:
Empirical Evidence?
- We ran two experiments comparing 6 different content selection policies in a fractions ITS
(Doroudi, Aleven, and Brunskill, 2017).- No significant difference between any of the conditions!
- I don't think we're the only ones!
- Through extensive literature review, I will attempt to show that RL-based approaches to sequencing have not been very successful.
- In what cases is it successful?
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
Statistical Models of Student Learning
≠
How Students Learn
Recall: Bayesian Knowledge Tracing (BKT)
Corbett and Anderson, 1994
Model Mismatch & Mastery Learning
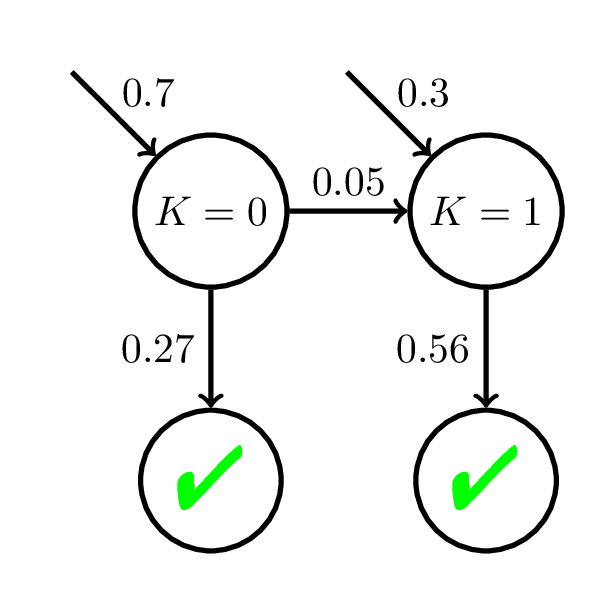
Perceived Mastery State
Actual Mastery State
We may give fewer practice opportunities to students than they actually need to reach mastery.
Doroudi and Brunskill, EDM 2017, Best Paper Nominee
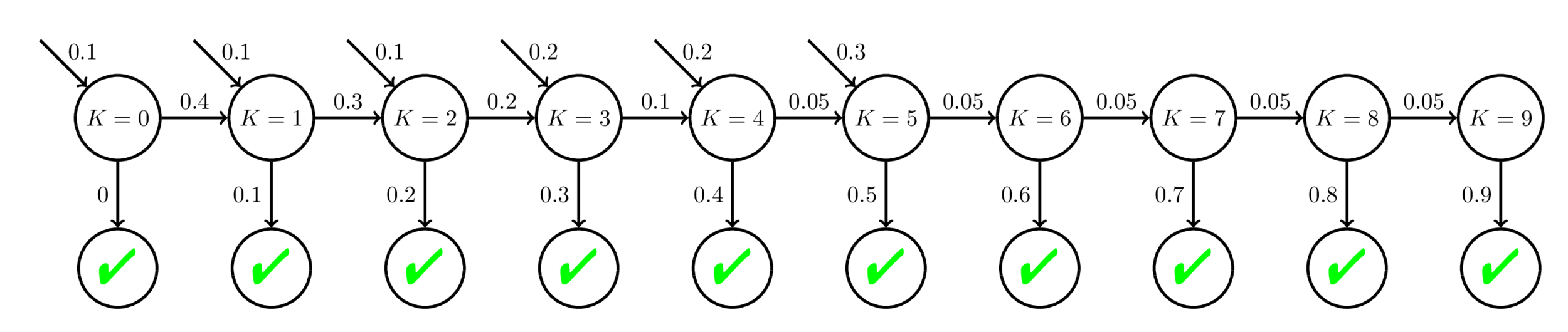
Model mismatch can help us better understand limitations of student models.
Model Mismatch & RL
| Baseline | Adaptive Policy | |
|---|---|---|
| Simulated Results | 5.9 ± 0.9 | 9.1 ± 0.8 |
Doroudi, Aleven, and Brunskill, L@S 2017
Model Mismatch & RL
| Baseline | Adaptive Policy | |
|---|---|---|
| Simulated Results | 5.9 ± 0.9 | 9.1 ± 0.8 |
| Experimental Results | 5.5 ± 2.6 | 4.9 ± 1.8 |
Doroudi, Aleven, and Brunskill, L@S 2017
Single Model Simulation
- Used by Chi, VanLehn, Littman, and Jordan (2011) and Rowe, Mott, and Lester (2014) in educational settings.
- Rowe, Mott, and Lester (2014): New content selection policy estimated to be much better than random policy.
- But in experiment, no significant difference found (Rowe and Lester, 2015).
Importance Sampling
- Estimator that gives unbiased and consistent estimates for a policy!
- Can have very high variance when policy is different from prior data.
- Example: Worked example or problem-solving?
- 20 sequential decisions ⇒ need over \(2^{20}\) students
- 50 sequential decisions ⇒ need over \(2^{50}\) students!
- Importance sampling can prefer the worse of two policies more often than not (Doroudi, Thomas, and Brunskill, 2017).
Doroudi, Thomas, and Brunskill, UAI 2017, Best Paper
Robust Evaluation Matrix
| Policy 1 | Policy 2 | Policy 3 | |
|---|---|---|---|
| Student Model 1 | |||
| Student Model 2 | |||
| Student Model 3 |
\(V_{SM_1,P_1}\)
\(V_{SM_2,P_1}\)
\(V_{SM_3,P_1}\)
\(V_{SM_1,P_2}\)
\(V_{SM_2,P_2}\)
\(V_{SM_3,P_2}\)
\(V_{SM_1,P_3}\)
\(V_{SM_2,P_3}\)
\(V_{SM_3,P_3}\)
Robust Evaluation Matrix
Baseline |
Adaptive Policy |
|
|---|---|---|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
|
|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
|
|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
|
Deep Knowledge Tracing |
9.9 ± 1.5 |
8.6 ± 2.1 |
Doroudi, Aleven, and Brunskill, L@S 2017
Robust Evaluation Matrix
|
Baseline |
Adaptive Policy |
Awesome Policy |
|
|---|---|---|---|
|
G-SCOPE Model |
5.9 ± 0.9 |
9.1 ± 0.8 |
16 |
|
Bayesian Knowledge Tracing |
6.5 ± 0.8 |
7.0 ± 1.0 |
16 |
|
Deep Knowledge Tracing |
9.9 ± 1.5 |
8.6 ± 2.1 |
16 |
Doroudi, Aleven, and Brunskill, L@S 2017
In the absence of good models, robustness can improve black box reinforcement learning.
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
Content Creation
Let students construct their own understandings.
Share those constructions with future students to help them co-construct their understandings.
Building on recent literature on learnersourcing (Kim et al., 2015).
Advantages:
Can create content in a more cost-effective way.
Both content creators and content consumers can learn from this content.
Students can engage with content in new, authentic ways.
Domains
-
Complex Crowdsourcing Tasks (Web Search)

-
Introduction to Mathematical Thinking MOOC
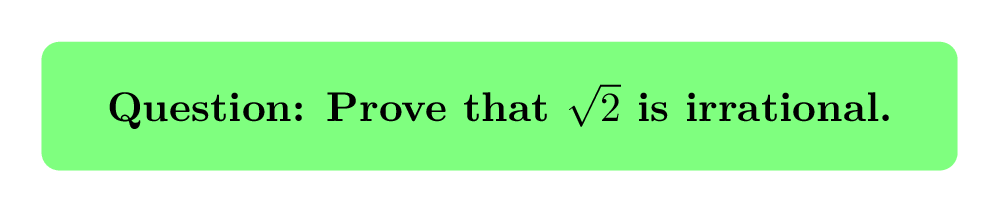
Web Search Task
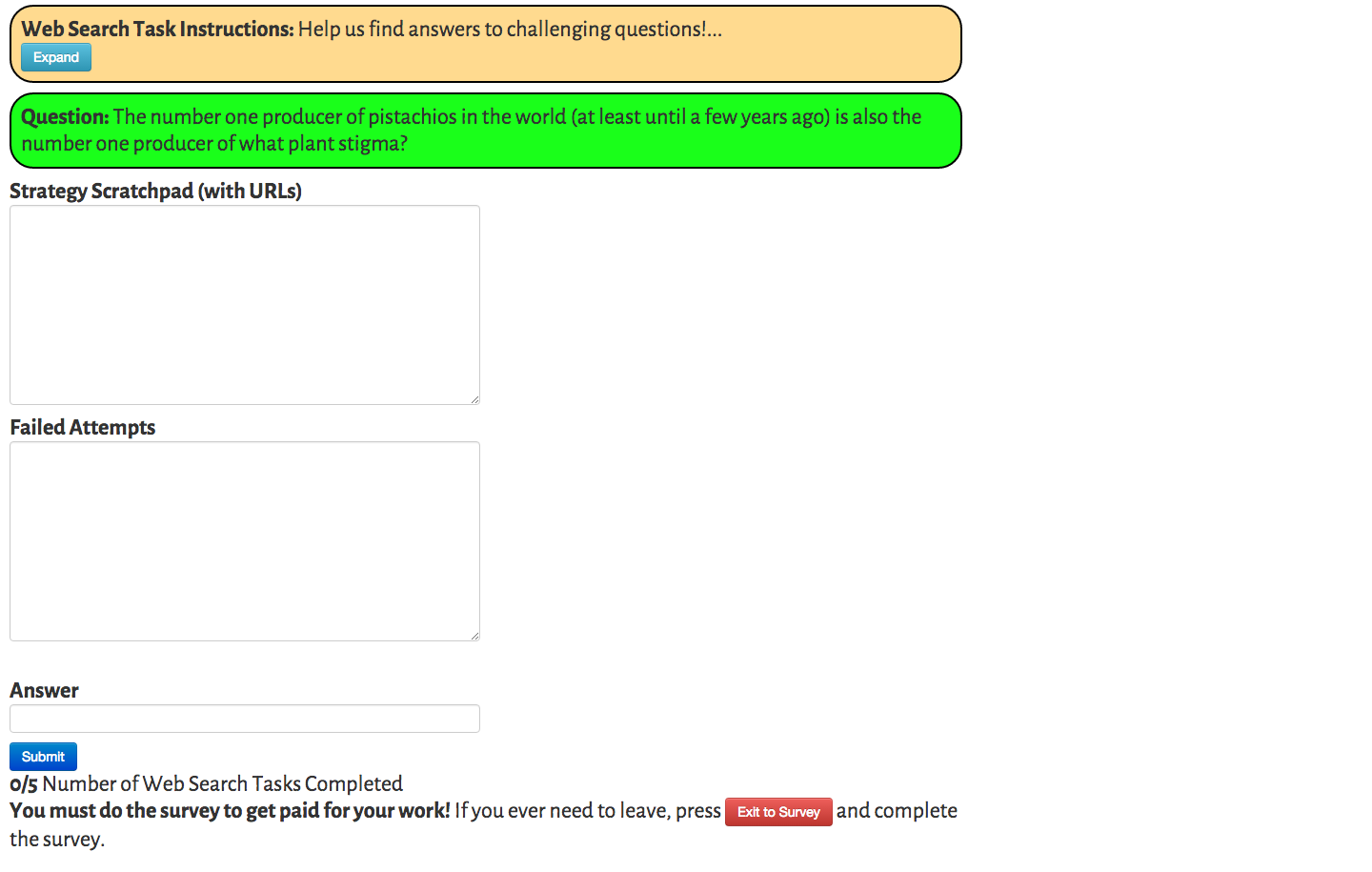
Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
Learner-Generated Content

Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
Expert Solutions ≠ Peer Solutions

Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016

Validating Peer Solutions
Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
Validating Peer Solutions
# Workers |
Accuracy |
|
|---|---|---|
Control |
150 |
0.50 ± 0.27 |
Reviewing Expert Examples |
140 |
0.61 ± 0.26 |
Validating Peer Solutions |
107 |
0.56 ± 0.26 |
Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
Experiment I
Validating Peer Solutions
Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
* Workers see one short (<800 char) and one long (>800 char) solution
Experiment II
# Workers |
Accuracy |
|
|---|---|---|
Reviewing Expert Examples |
102 |
0.59 ± 0.26 |
Validating Peer Solutions |
95 |
0.58 ± 0.23 |
Validating Filtered Solutions* |
88 |
0.60 ± 0.25 |
Validating Peer Solutions
Experiment II
# Workers |
Accuracy |
|
|---|---|---|
Reviewing Expert Examples |
102 |
0.59 ± 0.26 |
Validating Peer Solutions |
95 |
0.58 ± 0.23 |
Validating Filtered Solutions* |
88 |
0.60 ± 0.25 |
|
Extra Filtered Solutions** |
34 |
0.74 ± 0.17 |
* Workers see one short (<800 char) and one long (>800 char) solution
** Post Hoc analysis of workers who saw one medium (500-800 char)
and one extra long (>1000 char) solution
Doroudi, Kamar, Brunskill, and Horvitz, CHI 2016
Evaluating Peer Solutions
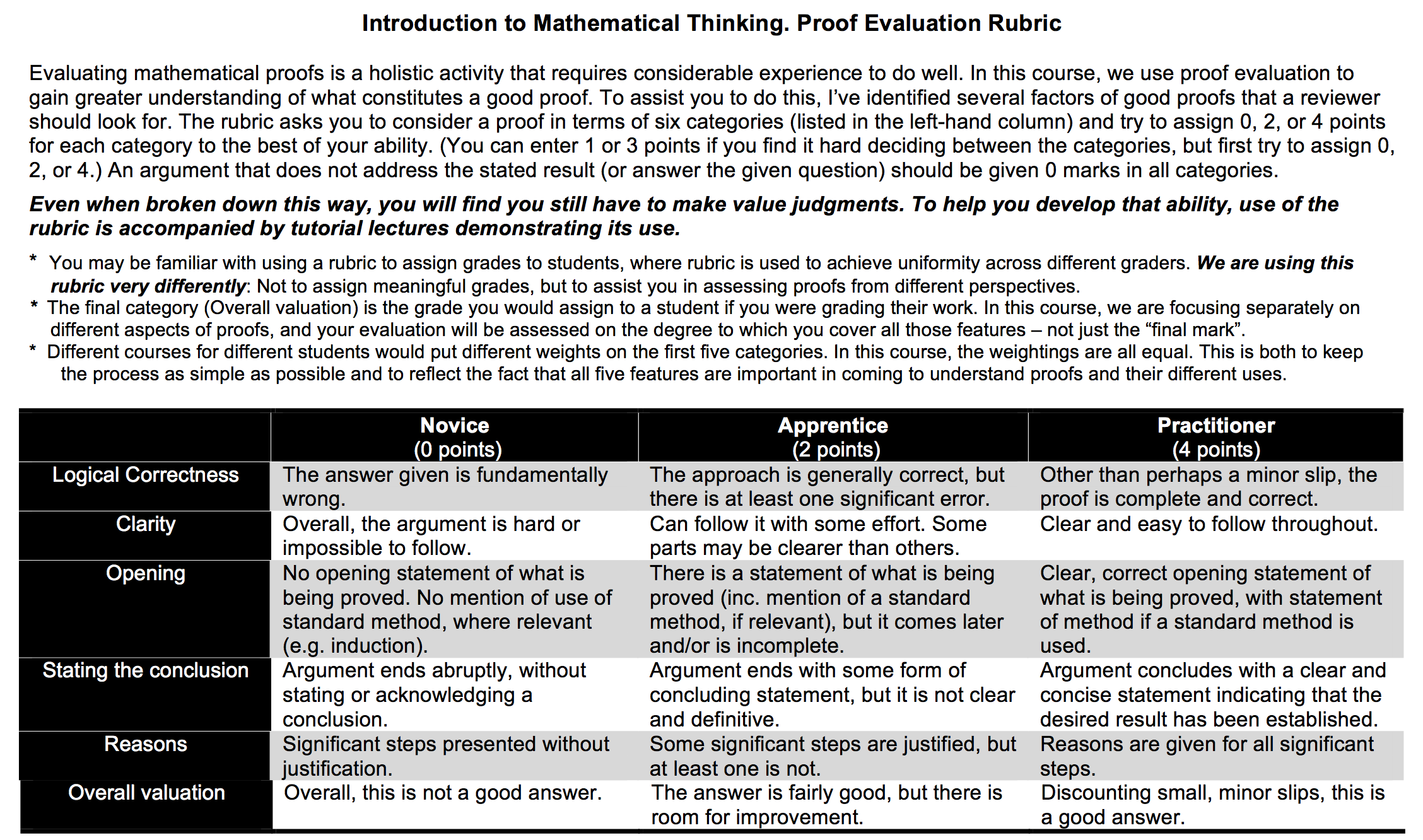
Keith Devlin, Introduction to Mathematical Thinking
Proposed Work



Evaluate the following proofs
Read the following proofs and then construct your own
Proposed Work
Logically correct
Logically correct
Good reasons
Clear
Good opening
Good conclusion
Peer-generated content is not only cost-effective, but also beneficial.
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
Prior Work

Williams, Kim, Rafferty, Maldonado, Gajos, Lasecki, and Heffernan, 2016
Prior Work
Williams, Kim, Rafferty, Maldonado, Gajos, Lasecki, and Heffernan, 2016
Proposed Work






Proposed Work
\(p_j\) is the probability of answering a question correctly after seeing peer solution \(j\).
-
\(\mathcal{F}\) is the set of features. Could include:
Solution length
Number of symbols/urls
Bag of words representation
Score on rubric items
Machine learning can be combined with human computation to improve content over time.
Outline
Limitations of Existing Approaches to
Adaptive Content Selection
Model Robustness
Content Creation
Content Curation
Learning Sciences + Content Selection
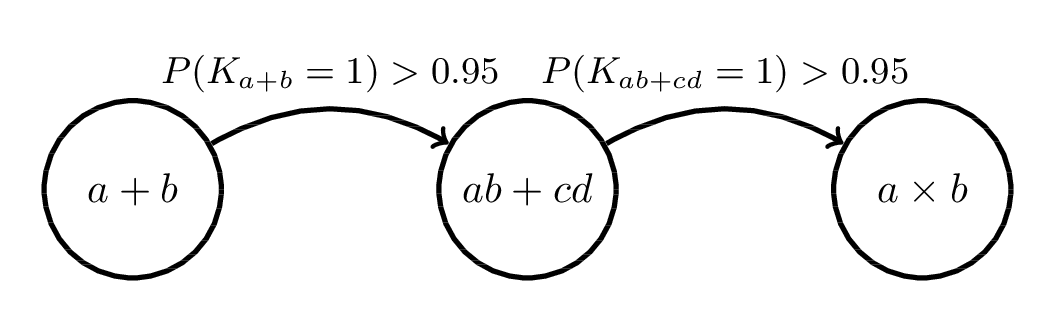
Sequencing with Expert Examples


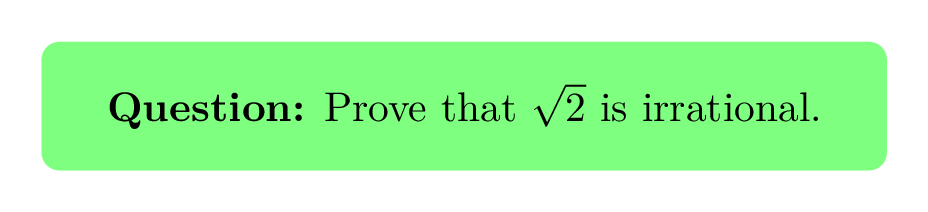
Shown to be a good sequence according to cognitive load theory (Kalyuga, 2003; Kalyuga and Sweller, 2005)
Review the following example
Fill in the missing steps
Answer the following question
Adapt instruction based on cognitive efficiency
(Kalyuga and Sweller, 2005; Najar, Mitrovic, and McLaren, 2016; Salden, Aleven, Schwonke, and Renkl 2010)
If CE > T1
If CE > T2
Review the following example
Answer the following question
Fill in the missing steps
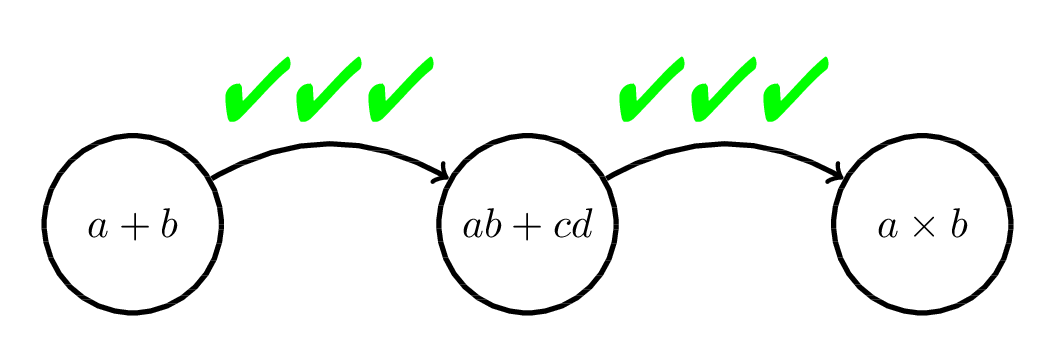
Sequencing with Expert Examples
Proposed Work
Based on cognitive load theory, hypothesize that this would be a good sequence

Review the following example
Answer the following question
Evaluate the following proof
Proposed Work
Use reinforcement learning to learn the appropriate transition points
Review the following example
Answer the following question
Evaluate the following proof
If CE > T1
If CE > T2
If CE < T3
If CE < T4
Can use cognitive load theory to restrict the set of potential adaptive content selection policies.
Timeline
-
By January 2018:
Complete content curation experiments for web search tasks and submit to IJCAI.
-
By March 2018:
Complete review of RL approaches to adaptive content selection and submit paper to JEDM.
Complete experiment testing different learnersourcing activities on MOOC and submit as Work-in-Progress to L@S.
-
By May 2018:
Complete initial activity sequencing experiment on MOOC.
-
By August 2018:
Complete adaptive sequencing experiment on MOOC.
Start writing dissertation.
-
By December 2018:
Replicate any interesting findings.
Complete dissertation.
Conclusion
-
I have proposed a number of methods for scalable automated adaptive content selection that combine machine learning, human computation, and principles from the learning sciences.
-
My work demonstrates how both:
-
Insights from computer science and statistics can inform the learning sciences.
-
Insights from the learning sciences can guide computational approaches.
-
Ed Tech
Machine Learning
My approach
Rule-Based AI
Statistical Machine Learning
Combine aspects of both
Adaptive Content Selection Approaches
AI
Approaches
Acknowledgements
The research reported here was supported, in whole or in part, by the Institute of Education Sciences, U.S. Department of Education, through Grants R305A130215 and R305B150008 to Carnegie Mellon University. The opinions expressed are those of the authors and do not represent views of the Institute or the U.S. Dept. of Education. Some of the research was also funded with the generous support of Microsoft Research
I am fortunate to have worked on (and continue to work on) much of the research presented here with a number of collaborators including Emma Brunskill, Vincent Aleven, Ken Holstein, Phil Thomas, Ece Kamar, Eric Horvitz, Minsuk Chang, Juho Kim, and Keith Devlin.
Special thanks to my thesis committee members,
Emma Brunskill, Vincent Aleven, Ken Koedinger, Chinmay Kulkarni, and Eric Horvitz
as well as Sharon Carver and David Klahr