


Domain Shift 1
Covariate & Label Shift
Face ID: A Success Story
Apple's Face ID. Trained on over a billion images.
Works in the dark.
Works with glasses.
Works with hats.
Ship it!
Then 2020 Happened
COVID-19 → everyone wears masks
Your phone keeps asking for your passcode.
Again. And again. And again.
Millions of frustrated users worldwide.
Face ID Meets Masks
Training
Deployment
Face ID didn't get worse. The input to the model changed.
Apple had to ship iOS 15.4 with "Face ID with a Mask" to fix this.
This is Domain Shift
Also called: distribution shift, dataset shift
Wait... Is This Just Overfitting?
Let's look at a trained neural network on MNIST digits
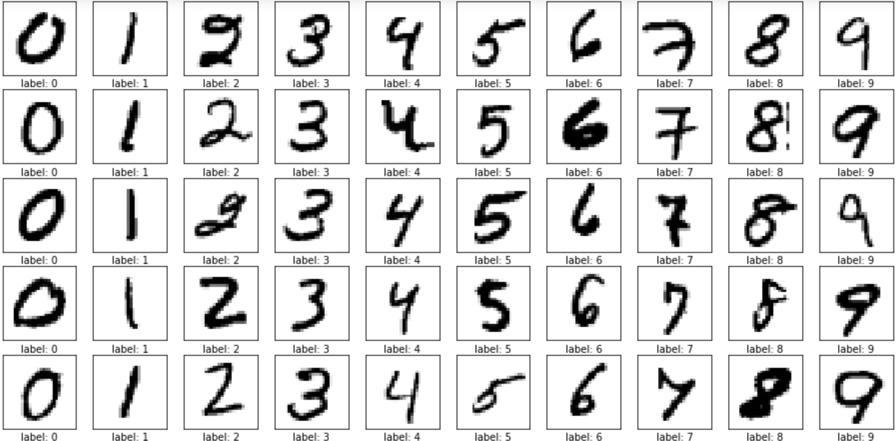
Training samples
Accuracy: 97%

Test samples
Accuracy: 81%
Looks like overfitting... or is it?
What the MNIST Network Learned
Activation maps at each layer, what each filter responds to for a digit "4":

Layer 1 (32 filters): strokes, edges, digit still recognizable

Layer 2 (64 filters): stroke fragments, spatial patterns
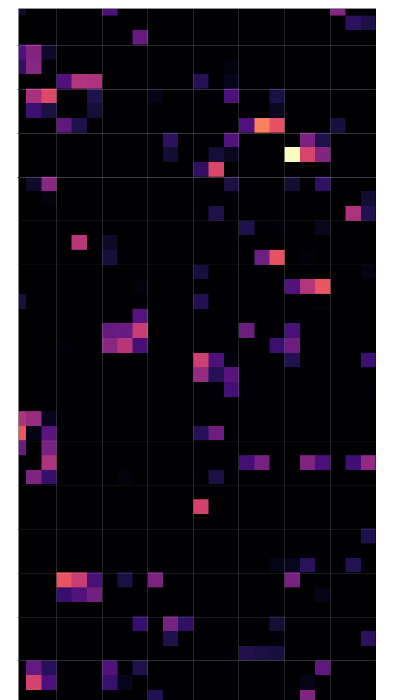
Layer 3 (128 filters): abstract, sparse codes
The network builds hierarchical features: not memorizing individual digits.
Training ≠ Deployment
Training: upright, centered
Test: rotated and shifted
The distribution changed, not the model complexity
This is domain shift, not overfitting
Domain Shift
| Overfitting | Domain Shift | |
|---|---|---|
| Symptom | Training ✓, testing ✗ | |
| Analogy | Studies only past exams, tested on same course | Masters C01, tested on C011 exam |
| Root cause | Model memorizes noise | \(P_{\text{source}}(x,y) \neq P_{\text{target}}(x,y)\) |
| Fixes | Regularization, dropout, simpler model | Different, that's today & next lecture |
Source domain = training | Target domain = deployment
The Joint Breaks Three Ways
Covariate Shift
\(P(x)\) moves; the labeling rule holds
Label Shift
\(P(y)\) moves; each class still looks the same
Concept Shift
The rule itself changes (next lecture)
Today we diagnose and fix the first two. Concept shift, where the rule itself moves, comes next time.
Pattern 1: Covariate Shift
The inputs change, but the rules don't
Covariate Shift: Wildlife Monitoring

Training: one location, one season
Deployment: new locations, new times
Same Deer, Different Pixels
A deer in a different place, at a different time, is still a deer.
Same ears. Same legs. Same antlers.
Didn't change
The relationship between "deer features" and "deer"
Changed
The background: location, lighting, vegetation
The rules are the same, only the inputs look different.
Covariate Shift: Definition
\(P(x)\) changes, inputs look different
\(P(y|x)\) stays the same, rules unchanged
The deer detector's knowledge is still valid, a deer is still a deer.
It just needs adjusting for different-looking inputs.
The most common type of domain shift.
Why the Joint Changes: \(P(x)\) Shifts
\(P(x, y) = P(y|x) \cdot P(x)\)
| \(P(\text{deer} | \text{infrared image})\) | \(P(\text{infrared image})\) | \(P(\text{infrared, deer})\) | |
|---|---|---|---|
| Training | 20% | 5% | 1% |
| Deployment | 20% | 90% | 18% |
Same conditional × different input frequency = different joint → \(P_{\text{source}} \neq P_{\text{target}}\)
Sim-to-Real
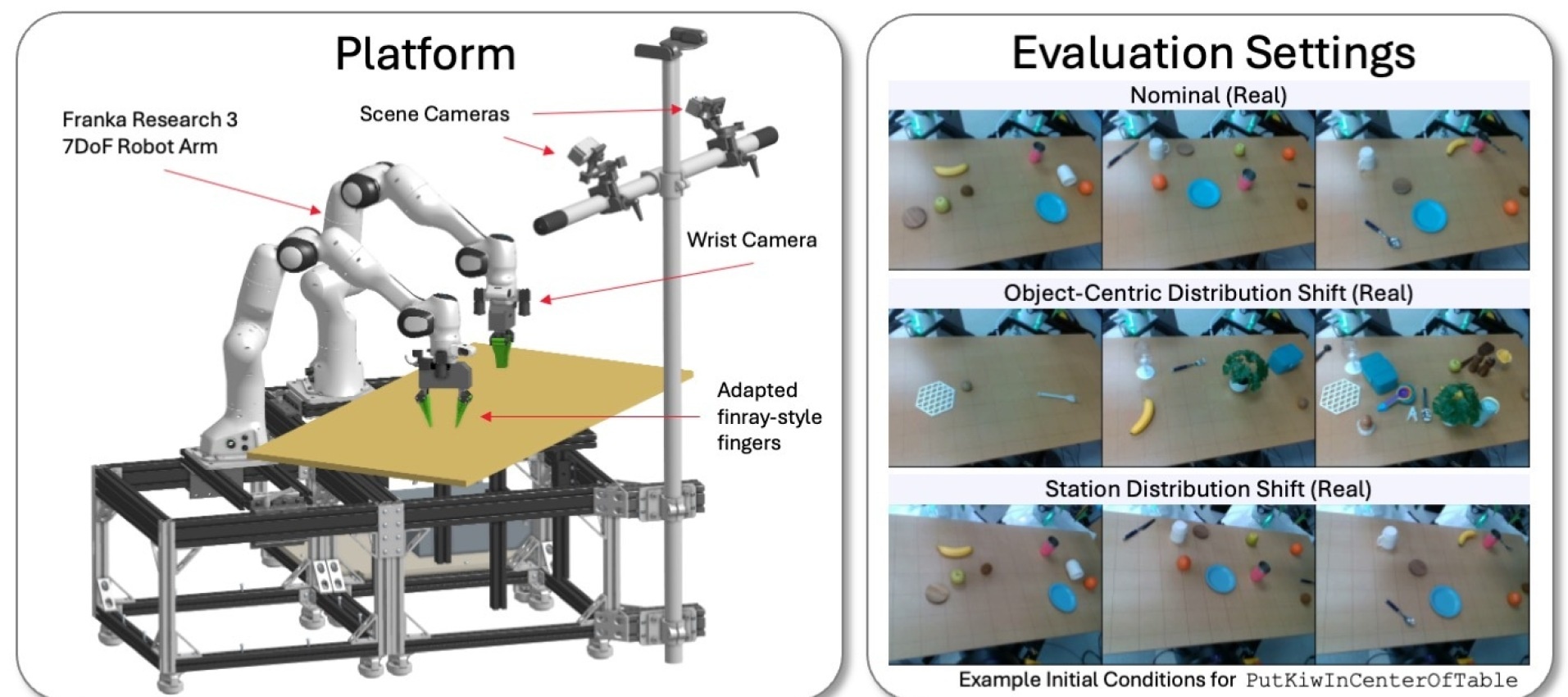
Robot platform and distribution shift settings: same task, different object and station configurations
Tedrake et al. (2025)
The Sim-to-Real Gap

Top: real world | Middle & bottom: simulation counterparts
Maddukuri et al. (2025)
Covariate Shift: You've Seen It
| Example | \(x\) | \(P(x)\) shifted | \(P(y|x)\) same |
|---|---|---|---|
| Face ID + masks | face scan | masked faces everywhere | your identity didn't change |
| MNIST rotation | digit image | rotated pixels | a 3 is still a 3 |
| Sim-to-real robotics | camera image | sim vs real textures | same grasping task |
| Wildlife monitoring | trail camera | day vs infrared night | a deer is still a deer |
Same rules, different-looking inputs → covariate shift.
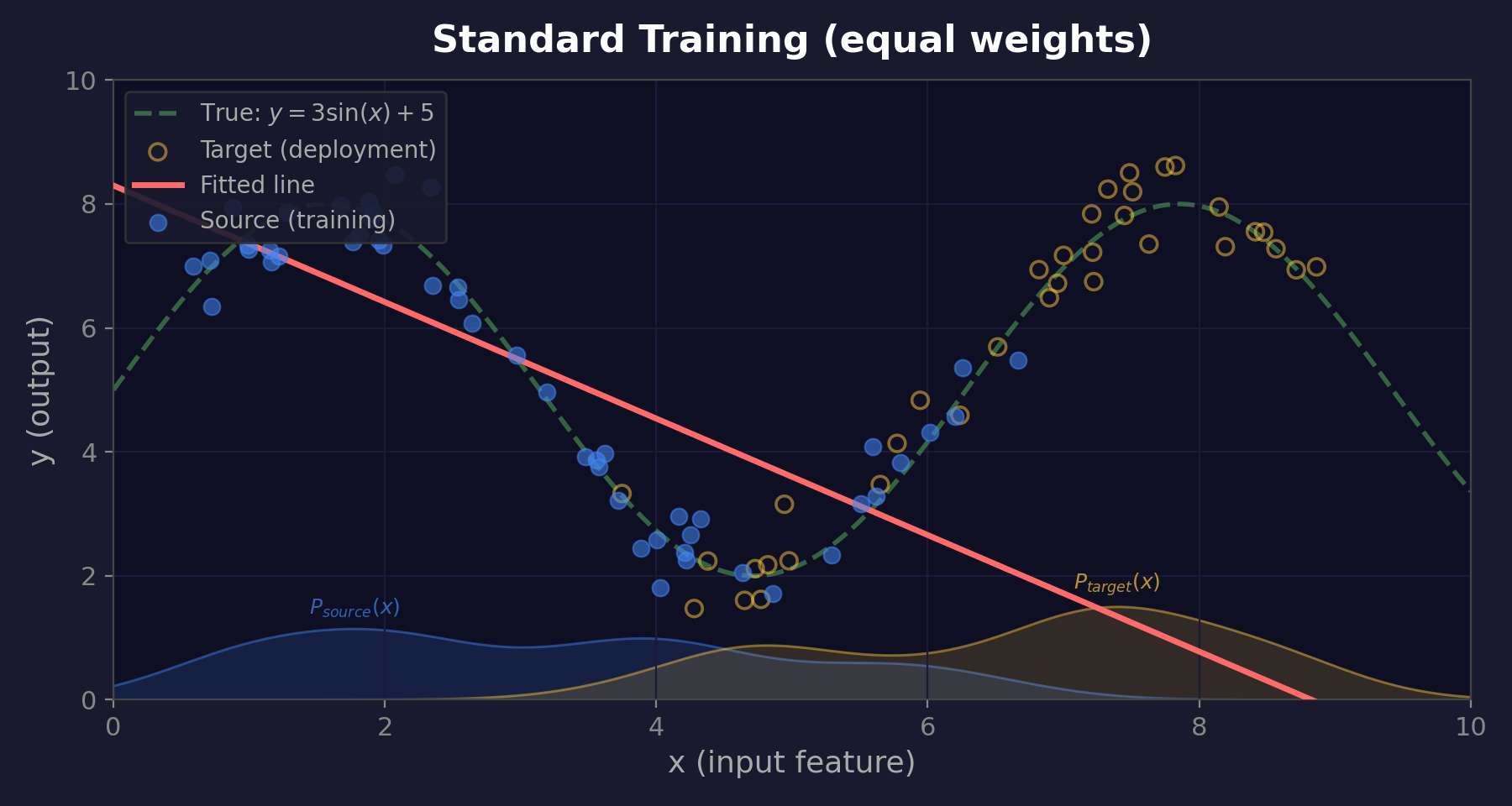
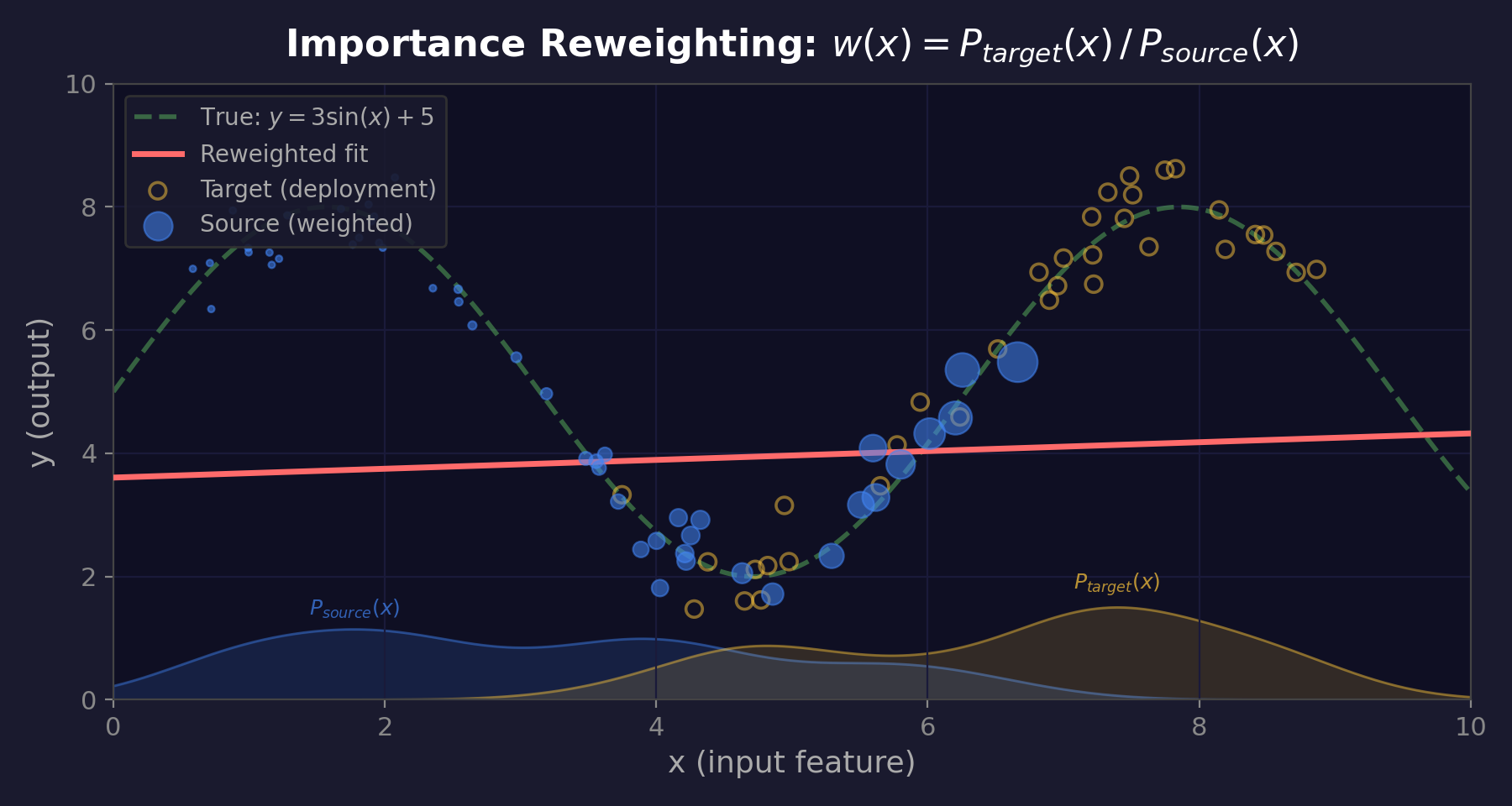
Fixing Covariate Shift
Weight each training example by: \(w(x) = \frac{P_{\text{target}}(x)}{P_{\text{source}}(x)}\)
Common in target → boost | Rare in target → reduce
Data Augmentation
Expand \(P_{\text{source}}(x)\) so it already covers likely \(P_{\text{target}}(x)\)
A transformation \(T\) is valid iff: \(y(T(x)) = y(x)\) for all \(x\)

Not every transformation is safe:
- Flip "b" → "d" (OCR)
- Rotate "6" → "9"
- Crop out tumor (medical imaging)
[image credit: visionbook.mit.edu]
Transfer Learning: Reuse the Representation
A broader claim than covariate shift: a representation learned on one domain is useful in another, even when the inputs look very different.
Standard practice in vision: start from a pre-trained ImageNet model. Edges, textures, and brightness transfer across tasks.
Early layers learn universal low-level features; later layers are task-specific, so those are the ones we adapt.
- Feature extraction: freeze the encoder, train a new head. Safe when target data is small.
- Fine-tuning: keep training everywhere. More powerful with larger target data, but risks catastrophic forgetting.
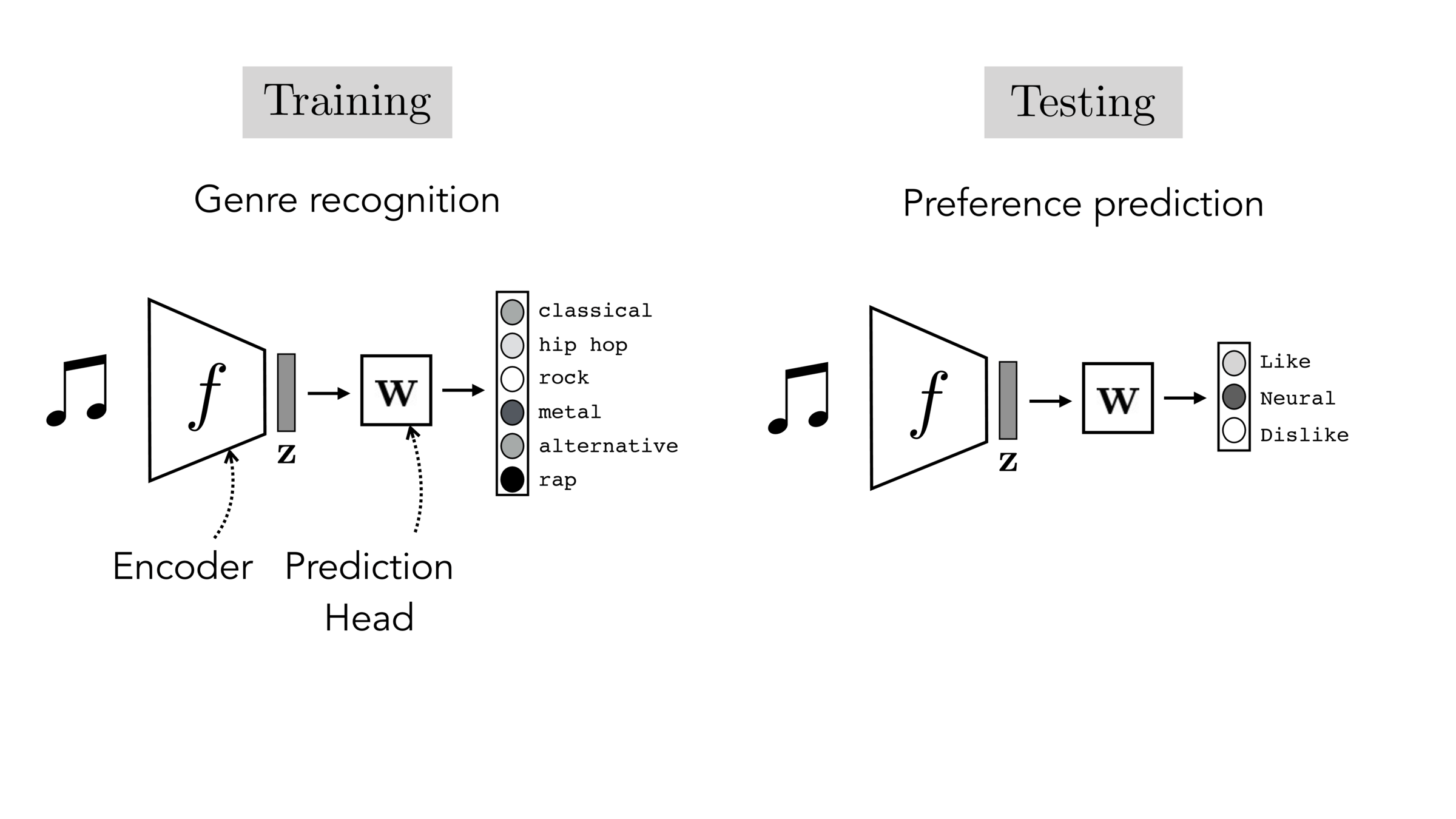
Often, what we will be "tested" on is not what we were trained on.
[images credit: visionbook.mit.edu]
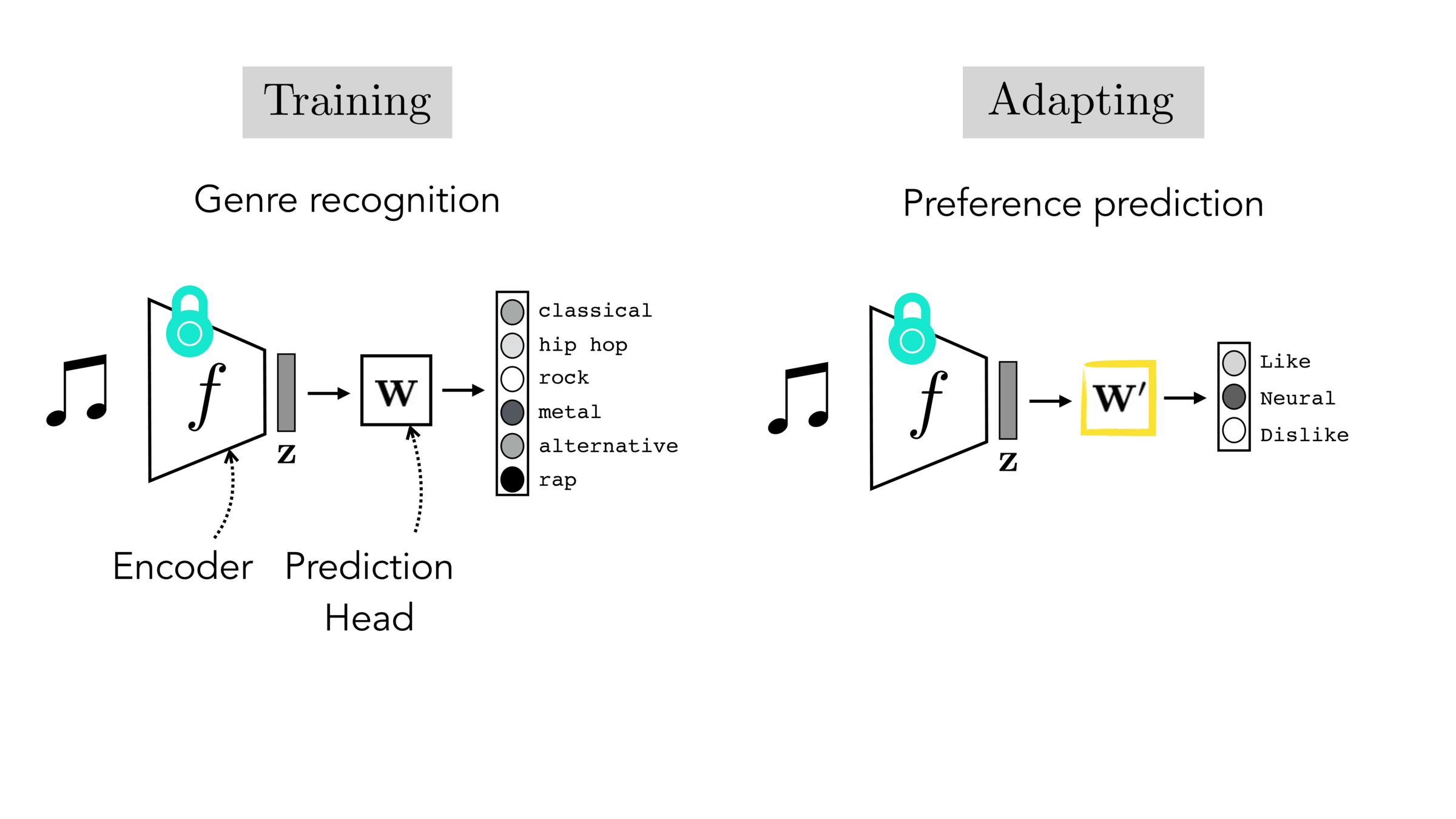
Feature extraction: Freeze \(f\), train only a new final layer on target data
[images credit: visionbook.mit.edu]
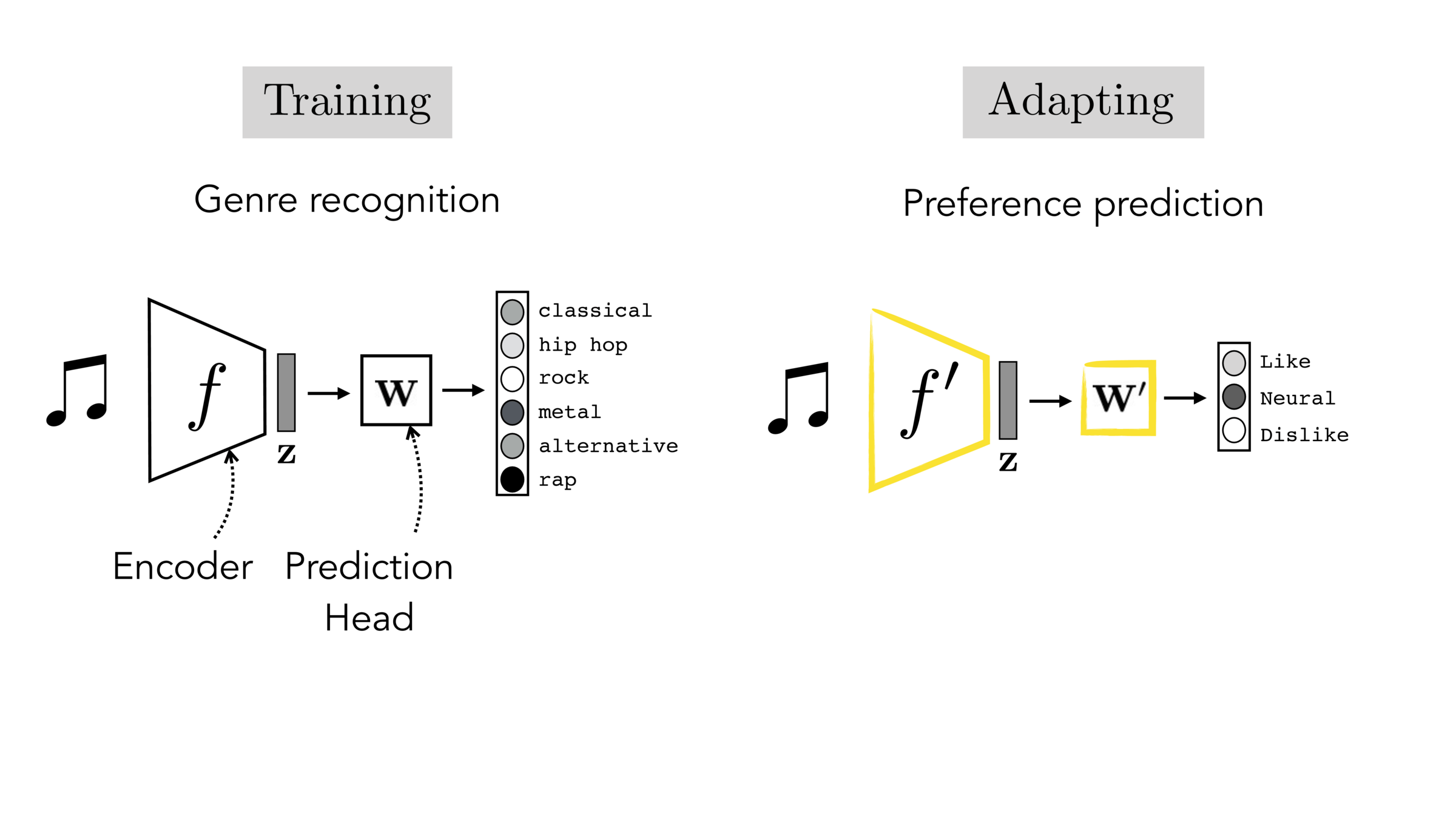
Fine-tuning: Initialize \(f' = f\), then continue training everything on target data
[images credit: visionbook.mit.edu]
Transfer Learning in Practice
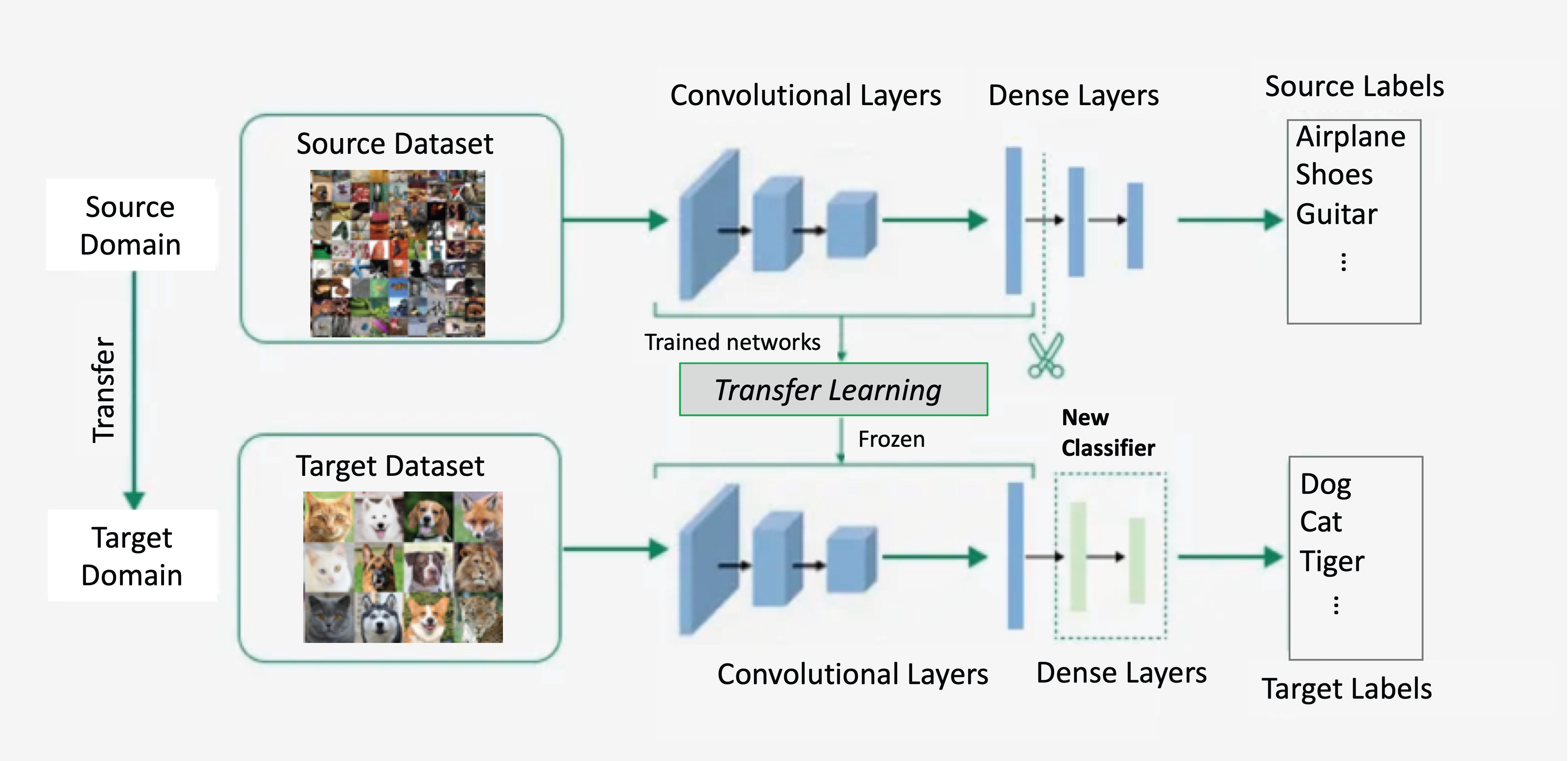
Even when source and target domains look very different, low-level edges and textures transfer surprisingly well.
Pattern 2: Label Shift
Semester
40%
30%
15%
15%
P(y) changed
Summer
10%
25%
30%
35%
👩💻, studying or fun? Same image, different odds.
Label Shift: Cold Diagnosis
Same cold detection model, different patient populations:
Children's Hospital
Kids get 6–8 colds per year
MGH (adult general hospital)
Adults get 2–3 colds per year
\(P(x|y)\) same, a cold looks the same in kids and adults
\(P(y)\) changed, prevalence is very different
Also called: prior probability shift, target shift
Why the Joint Changes: \(P(y)\) Shifts
\(P(x, y) = P(x|y) \cdot P(y)\)
| \(P(\text{runny nose} | \text{cold})\) | \(P(\text{cold})\) | \(P(\text{runny nose, cold})\) | |
|---|---|---|---|
| Children's | 80% | 40% | 32% |
| MGH | 80% | 10% | 8% |
Same conditional × different prior = different joint → \(P_{\text{source}} \neq P_{\text{target}}\)
Label Shift as Bayes' Rule
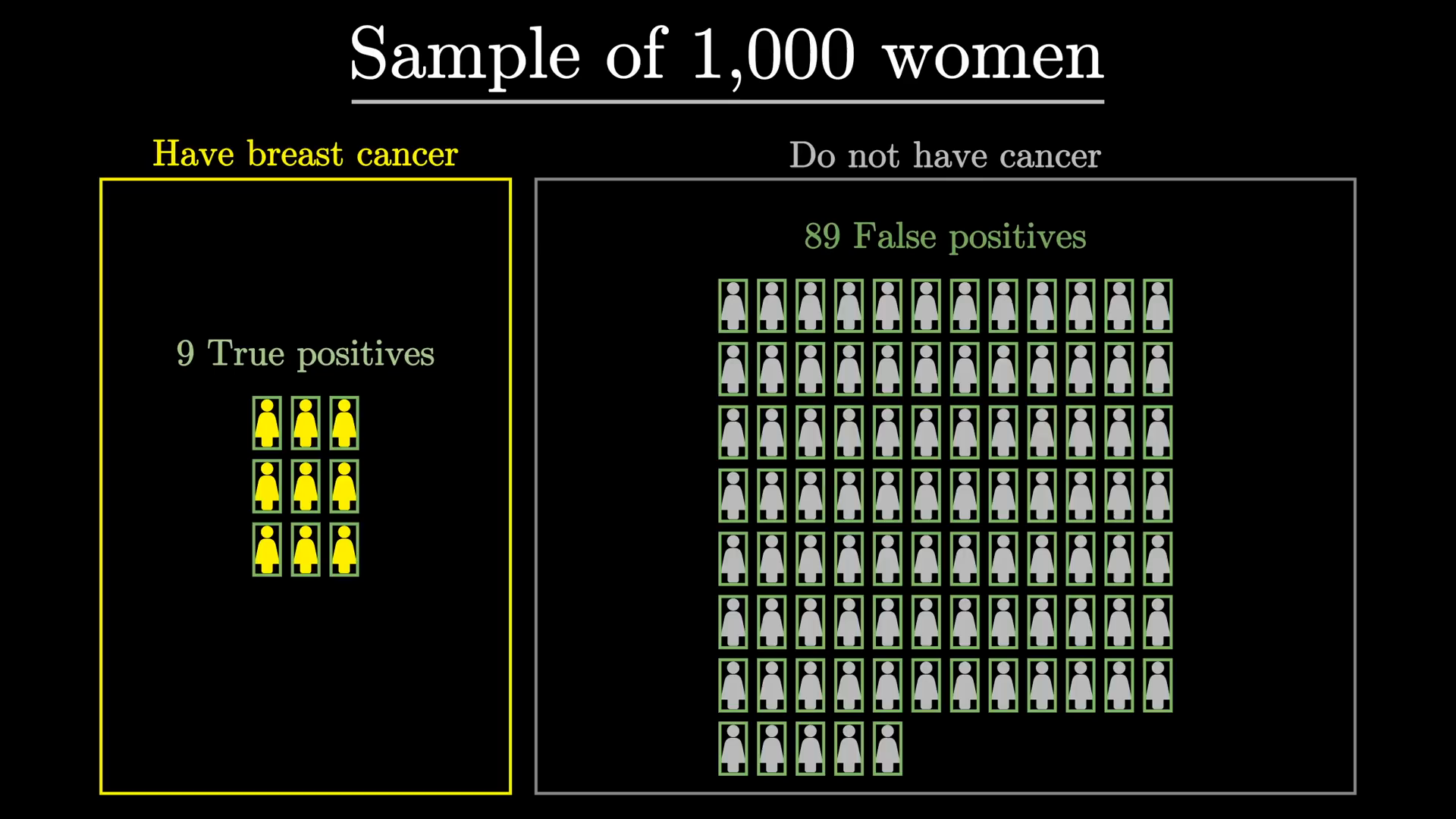
3Blue1Brown, The medical test paradox
Sensitivity = 90%, specificity = 91%. You test positive.
| \(P(\text{disease})\) | \(P(\text{disease} | +)\) | |
|---|---|---|
| 10% prevalence | 10% | ~50% |
| 1% prevalence | 1% | ~9% |
10% case: \(\frac{0.9 \cdot 0.10}{0.9 \cdot 0.10 + 0.09 \cdot 0.90} = \frac{0.09}{0.171} \approx 0.53 \approx 50\%\)
1% case: \(\frac{0.9 \cdot 0.01}{0.9 \cdot 0.01 + 0.09 \cdot 0.99} \approx 0.09\)
Same test, same \(P(x|y)\), the prior \(P(y)\) changes everything.
That's label shift.
\[ P(D|+) = \frac{P(+|D)P(D)}{P(+|D)P(D) + P(+|\neg D)P(\neg D)} \]
Fixing Label Shift
Adjust predictions: \(P_{\text{target}}(y|x) \propto P_{\text{source}}(y|x) \cdot \frac{P_{\text{target}}(y)}{P_{\text{source}}(y)}\)
Common in target → boost | Rare in target → reduce
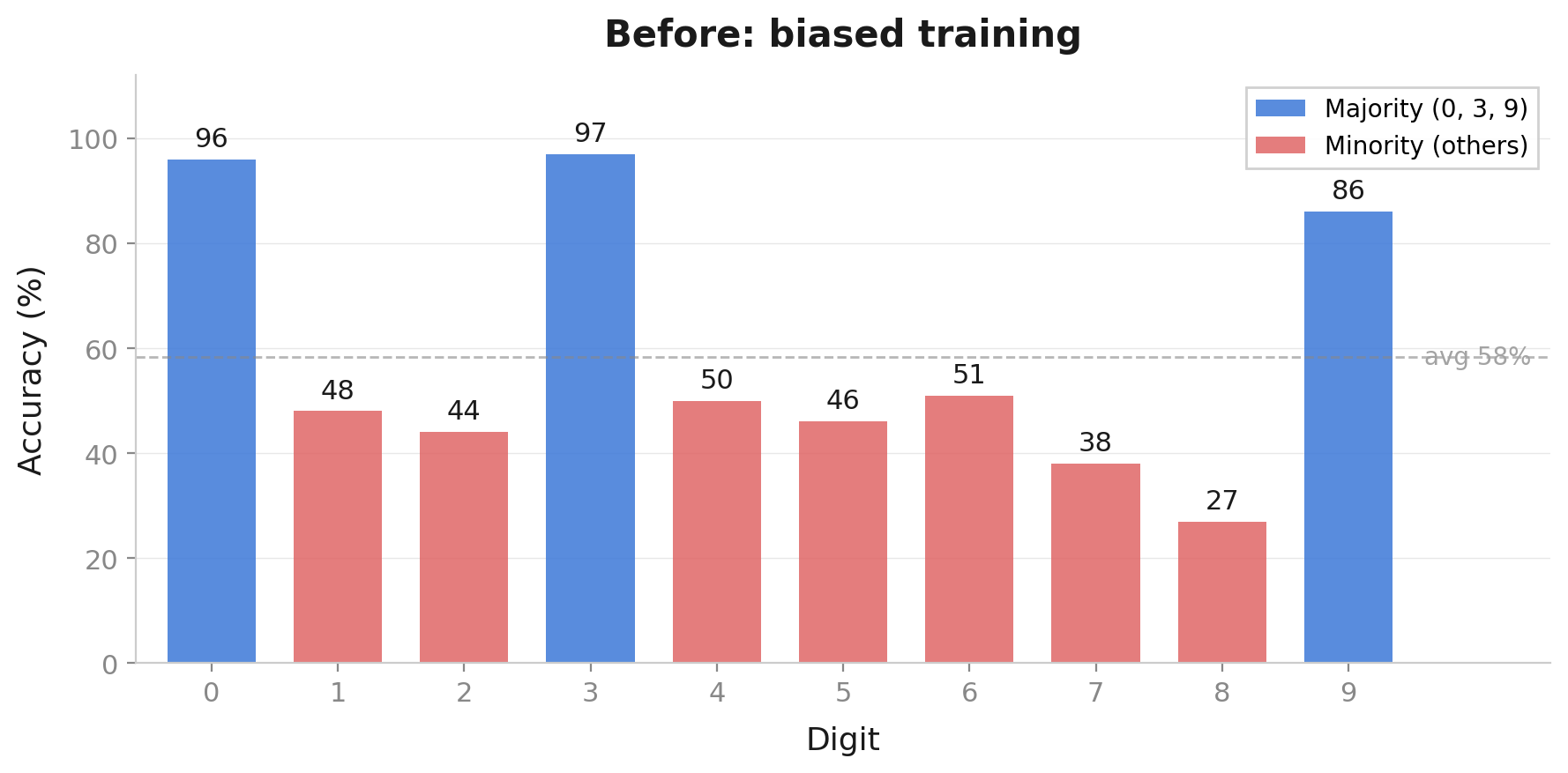
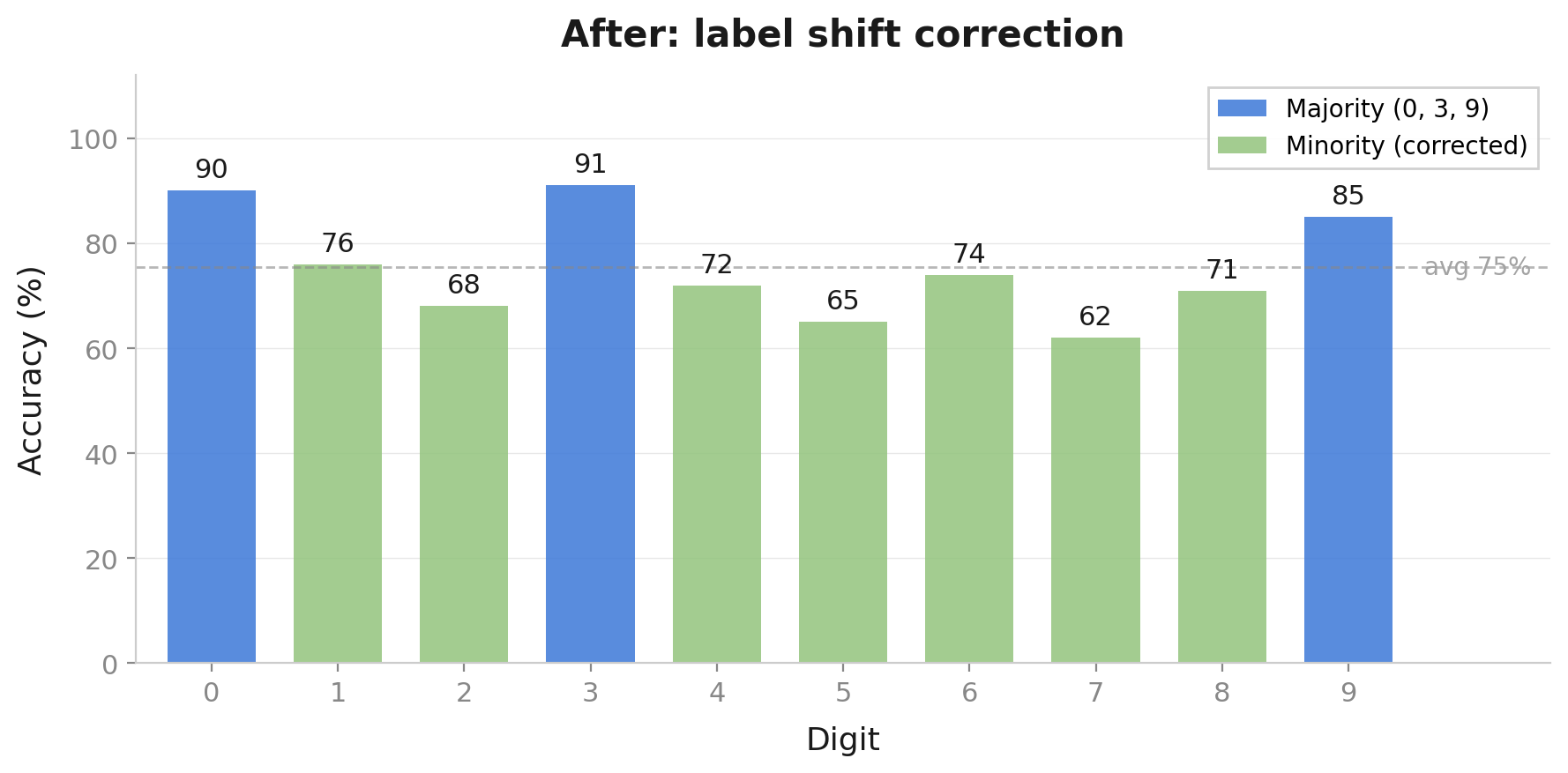
MNIST example demo
Threshold Adjustment: Move the Boundary
Even cheaper than recalibrating probabilities: just shift the decision threshold itself.
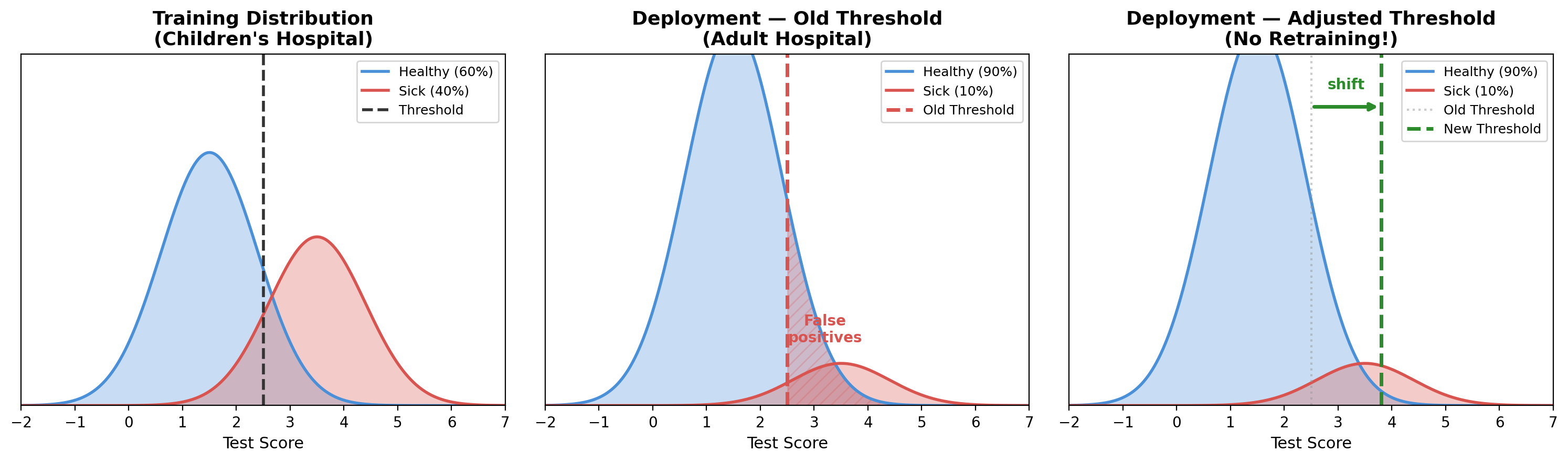
Children’s hospital 60/40 → adult hospital 90/10. Keep the old threshold and we flag many healthy adults; shift it right and stay conservative. No retraining, one knob.
Same Bayes idea: when priors move, the same evidence should lead to a different decision. How far to shift is a modeling choice (cross-validate on target data; monitoring helps next lecture).
Label-Shift Levers, by Cost
Inference time, no retraining
- Threshold adjustment: literally one number.
- Prior correction: multiply outputs by the new-to-old prior ratio, a few lines of code.
Retraining, reshape the per-class contribution
- Class-weighted loss or resampling: same lever, both encode that only \(P(y)\) moved.
Pick the cheapest lever that solves the problem. Match the intervention to the smallest piece of the system that actually moved.
Two Patterns, One Framework
Covariate Shift
\(P(x)\) changes
\(P(y|x)\) stays same
World looks different, works the same
e.g. deer detector, sim-to-real, Face ID
Fix: reweight, finetune, augment
Label Shift
\(P(y)\) changes
\(P(x|y)\) stays same
World works the same, mix is different
e.g. cold diagnosis, MNIST class bias
Fix: adjust priors, rebalance
Identifying which pattern → determines the fix.
The Diagnostic Framework
When we encounter a new deployment scenario, ask:
- Do the inputs look different? → Check for covariate shift
- Can a domain classifier separate source vs target? → measurable input shift
Probe: train \(d(x)\) to predict source vs target.
Near chance (~50%) → little detectable input shift; high accuracy → covariate shift signal.
- Are the class frequencies different? → Check for label shift
- Compare class distributions source vs target → class imbalance signals label shift
Probe: compare \(\hat{P}(y)\) across source and target.
Similar frequencies → no label shift; large gaps → label shift signal.
- Did the underlying rules change? → Might need to retrain
Which Type of Shift?
Spam filter: trained on Gmail, deployed on corporate email
→ Covariate: different writing style, same spam vs not-spam
Sentiment analysis: trained on restaurant reviews, deployed on electronics reviews
→ Covariate: different vocabulary, same positive/negative meaning
Disease screening: trained in flu season, deployed in summer
→ Label shift: same symptoms, way fewer sick patients
Satellite imagery: trained in France, deployed in India
→ Both!: different terrain (covariate) and different crop mix (label)
Satellite Imagery: Crop Classification

Large, regular fields → high accuracy

Tiny, irregular fields → much worse
Wang, Waldner & Lobell (2022)
Summary
Domain shift is not overfitting, the world changed, not your model's complexity.
Covariate shift (\(P(x)\) changes, \(P(y|x)\) same) is the most common pattern, fix with reweighting, finetuning, or augmentation.
Label shift (\(P(y)\) changes, \(P(x|y)\) same) requires adjusting class priors, not model architecture.
Diagnosis before treatment, identify what changed, then pick the matching fix.
Models are frozen snapshots of one distribution; the world keeps moving, so anticipate and adapt.
Reference: Shift Types
| Shift Type | What Changes? | What Stays Same? | Fix Strategy | Today's Examples |
|---|---|---|---|---|
| Covariate | \(P(x)\) | \(P(y|x)\) | Reweight, finetune, augment | Face ID, deer detector, sim-to-real |
| Label | \(P(y)\) | \(P(x|y)\) | Adjust priors, rebalance | Cold diagnosis, MNIST class bias |
| Concept (preview) | \(P(y|x)\) | Nothing guaranteed | Retrain, continual learning | Next lecture! |
Next Time: When the Rules Themselves Move
Every fix today worked because something stayed invariant: one piece of the joint survived the shift.
Concept shift: \(P(y\mid x)\) changes. The same input maps to a new correct label.
An MIT taste: “6.7” once meant the EECS-and-biology major. Now it mostly shows up as a meme.
Same string, completely different meaning.
No amount of input reweighting fixes that. Next time: concept shift, and keeping models alive in a moving world.