

Lecture 6: Neural Networks II
Intro to Machine Learning

layer
linear combo
activations
layer
input
neuron
learnable weights
Engineers choose:
- activation \(f\) in each layer
- # of layers
- # of neurons in each layer
hidden
output
Recap
(aka, multi-layer perceptrons)
a (fully-connected, feed-forward) neural network
\(\dots\)
Forward pass: evaluate, given the current parameters
- the model outputs \(g^{(i)}\) =
- the loss incurred on the current data \(\mathcal{L}(g^{(i)}, y^{(i)})\)
- the training error \(J = \frac{1}{n} \sum_{i=1}^{n}\mathcal{L}(g^{(i)}, y^{(i)})\)
linear combination
loss function
(nonlinear) activation
Recap
\(f =\sigma(\cdot)\)
\(f(\cdot) \) identity function
Recap
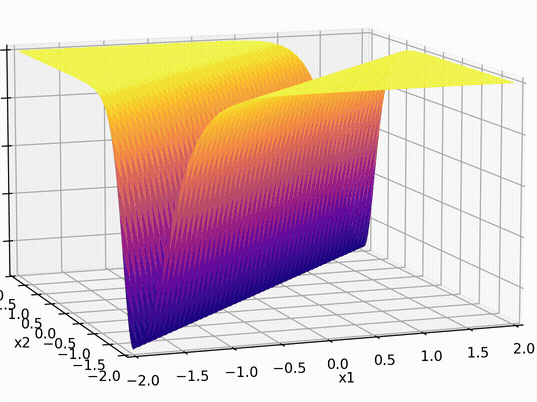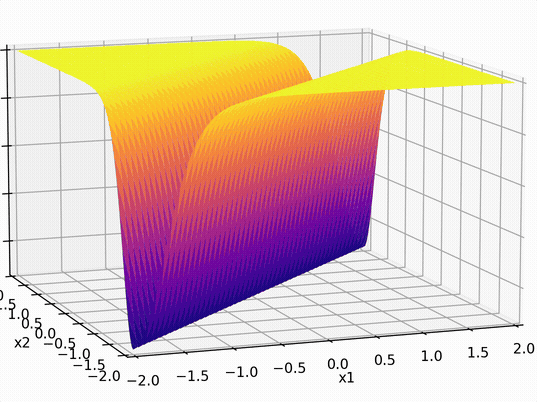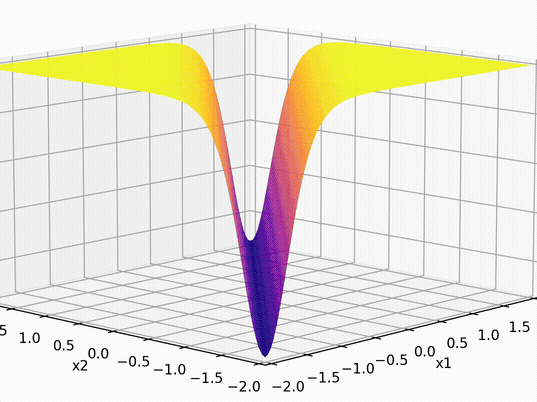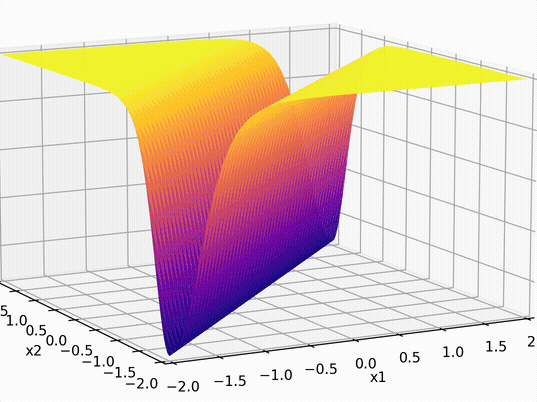
\(-3(\sigma_1 +\sigma_2)\)
(The demo won't embed in PDF. The direct link below gets to the demo.)
(The demo won't embed in PDF. The direct link below gets to the demo.)
Outline
-
Backward pass (to learn parameters/weights)
- Backpropagation (gradient descent & the chain rule)
- Recursive reuse of computation
- Practical gradient issues and remedies
stochastic gradient descent to learn a linear regressor
- Randomly pick a data point \((x^{(i)}, y^{(i)})\)
- Evaluate the gradient \(\nabla_{w} \mathcal{L}(g^{(i)},y^{(i)})\)
- Update the weights \(w \leftarrow w - \eta \nabla_w \mathcal{L}(g^{(i)},y^{(i)})\)

for simplicity, say training data set is just\((x,y)\) and squared loss
example on the blackboard
Slightly more interesting:
example on the blackboard
Slightly more interesting:
example on the blackboard
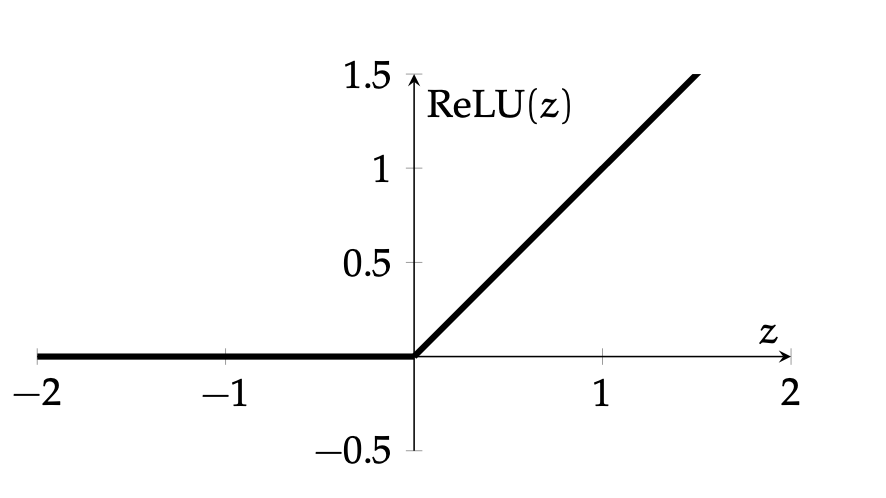
Outline
-
Backward pass (to learn parameters/weights)
- Backpropagation (gradient descent & the chain rule)
- Recursive reuse of computation
- Practical gradient issues and remedies
- Randomly pick a data point \((x^{(i)}, y^{(i)})\)
- Evaluate the gradient \(\nabla_{W^2} \mathcal{L}(g^{(i)},y^{(i)})\)
- Update the weights \(W^2 \leftarrow W^2 - \eta \nabla_{W^2} \mathcal{L}(g^{(i)},y^{(i)})\)
\(\dots\)
\(\nabla_{W^2} \mathcal{L}(g^{(i)},y^{(i)})\)
Backward pass: run SGD to update all parameters
e.g. to update \(W^2\)
\(\dots\)
how to find
?
\(\dots\)
how to find
?
Previously, we found
\(\dots\)
how to find
Now
backpropagation: reuse of computation
\(\dots\)
\(\dots\)
backpropagation: reuse of computation
Training a neural network: the full loop
Initialize all weights \(W^1, W^2, \dots, W^L\) randomly
Repeat until stopping criterion:
- Forward pass: for each data point, compute \(Z^1, A^1, Z^2, A^2, \dots, g^{(i)}\)
- Evaluate loss: for each data point, compute \(\mathcal{L}(g, y)\)
-
Backward pass: pick a data point, compute \(\nabla_{W^\ell} \mathcal{L}(g^{(i)}, y^{(i)})\) for all \(\ell = L, L{-}1, \dots, 1\) via the chain rule
(reuse intermediate results → backpropagation) - Update: \(W^\ell \leftarrow W^\ell - \eta\, \nabla_{W^\ell} \mathcal{L}\) for all \(\ell\)
In practice, we use mini-batches rather than a single point.
e.g.,
Outline
-
Backward pass (to learn parameters/weights)
- Backpropagation (gradient descent & the chain rule)
- Recursive reuse of computation
- Practical gradient issues and remedies
example on the blackboard
More neurons, more layers
example on the blackboard
if \(z^2 > 0\) and \(z_1^1 < 0\), some weights (grayed-out ones) won't get updated
👻 dead ReLU
example on the blackboard
if \(z^2 < 0\), no weights get updated
👻 dead ReLU
Residual (skip) connection:
example on the blackboard
Now, \(g= z^2 + \text{ReLU}(z^2)\)
even if \(z^2 < 0\), with skip connection, weights in earlier layers can still get updated
Vanishing and Exploding Gradients
Backpropagation computes gradients via the chain rule — a product of many factors:
e.g. \(\displaystyle \quad \frac{\partial \mathcal{L}}{\partial W^1} \;=\; \frac{\partial Z^1}{\partial W^1} \cdot \underbrace{\frac{\partial A^1}{\partial Z^1} \cdot \frac{\partial Z^2}{\partial A^1} \cdots \frac{\partial A^{L-1}}{\partial Z^{L-1}} \cdot \frac{\partial Z^L}{\partial A^{L-1}}}_{{L-1}\text{ layers of multiplicative factors}} \cdot \frac{\partial g}{\partial Z^L} \cdot \frac{\partial \mathcal{L}}{\partial g}\)
If each factor is small, their product shrinks very quickly with depth, little learning.
If factors are large (magnitude\(> 1\)), gradients explode, also problematic.
Many practical remedies: residual connection, gradient clipping
Gradient clipping: If \(\|\nabla\| > \tau\), rescale: \(\nabla \leftarrow \tau \frac{\nabla}{\|\nabla\|}\). Preserves gradient direction, caps its magnitude
Summary
-
Multi-layer perceptrons automatically learn good features and transformations from data.
-
Training loop: forward pass \(\rightarrow\) loss \(\rightarrow\) backward pass \(\rightarrow\) weight update, repeat.
-
Backpropagation reuses intermediate computations to efficiently evaluate all gradients via the chain rule.
-
Dead ReLU neurons (pre-activation always negative) get zero gradient and stop learning; careful initialization helps.
-
Vanishing/exploding gradients arise from multiplying many small (or large) factors across layers.
Reference: weight initialization
- If all weights start at 0, every neuron computes the same thing → no learning
- If weights are too large, activations saturate or explode
- If weights are too small, signals shrink to zero across layers
Goal: keep the variance of activations roughly constant across layers.
-
Xavier initialization (for sigmoid/tanh): \(W^\ell_{ij} \sim \mathcal{N}\!\left(0,\; \frac{1}{n_{\ell-1}}\right)\)
where \(n_{\ell-1}\) = number of inputs (fan-in) to the layer -
He initialization (for ReLU): \(W^\ell_{ij} \sim \mathcal{N}\!\left(0,\; \frac{2}{n_{\ell-1}}\right)\)
factor of 2 compensates for ReLU zeroing out half the inputs
Numerical example: backprop with two hidden neurons
1 input, 2 hidden neurons (ReLU), 1 output, squared loss
\(x = 1,\; y = 3,\; w_1^1 = 2,\; w_2^1 = -1,\; w_1^2 = 1,\; w_2^2 = 2\)
Forward:
\(z_1^1 = 2 \cdot 1 = 2 \;\Rightarrow\; a_1^1 = \text{ReLU}(2) = 2\)
\(z_2^1 = -1 \cdot 1 = -1 \;\Rightarrow\; a_2^1 = \text{ReLU}(-1) = \color{red}{0}\)
\(g = 1 \cdot 2 + 2 \cdot 0 = 2\)
Loss: \(\mathcal{L} = (2 - 3)^2 = 1\)
Backward: \(\;\frac{\partial \mathcal{L}}{\partial g} = 2(2 - 3) = -2\)
\(\frac{\partial \mathcal{L}}{\partial w_1^2} = -2 \cdot a_1^1 = -2 \cdot 2 = -4\)
\(\frac{\partial \mathcal{L}}{\partial w_2^2} = -2 \cdot a_2^1 = -2 \cdot \color{red}{0} = \color{red}{0}\)
\(\frac{\partial \mathcal{L}}{\partial w_1^1} = -2 \cdot w_1^2 \cdot \mathbb{1}[z_1^1 > 0] \cdot x = -2\)
\(\frac{\partial \mathcal{L}}{\partial w_2^1} = -2 \cdot w_2^2 \cdot \underbrace{\mathbb{1}[z_2^1 > 0]}_{\color{red}{= 0}} \cdot x = \color{red}{0}\)
Neuron 2 is "dead" (\(z_2^1 < 0\)) — none of its weights get updated. This foreshadows the vanishing gradient problem.