
Lecture 4: Generative Models - Scaling (up)
Shen Shen
April 9, 2025
2:30pm, Room 32-144
Modeling with Machine Learning for Computer Science
Outline
- Scaling matters
- Training/post training phase
- Inference phase
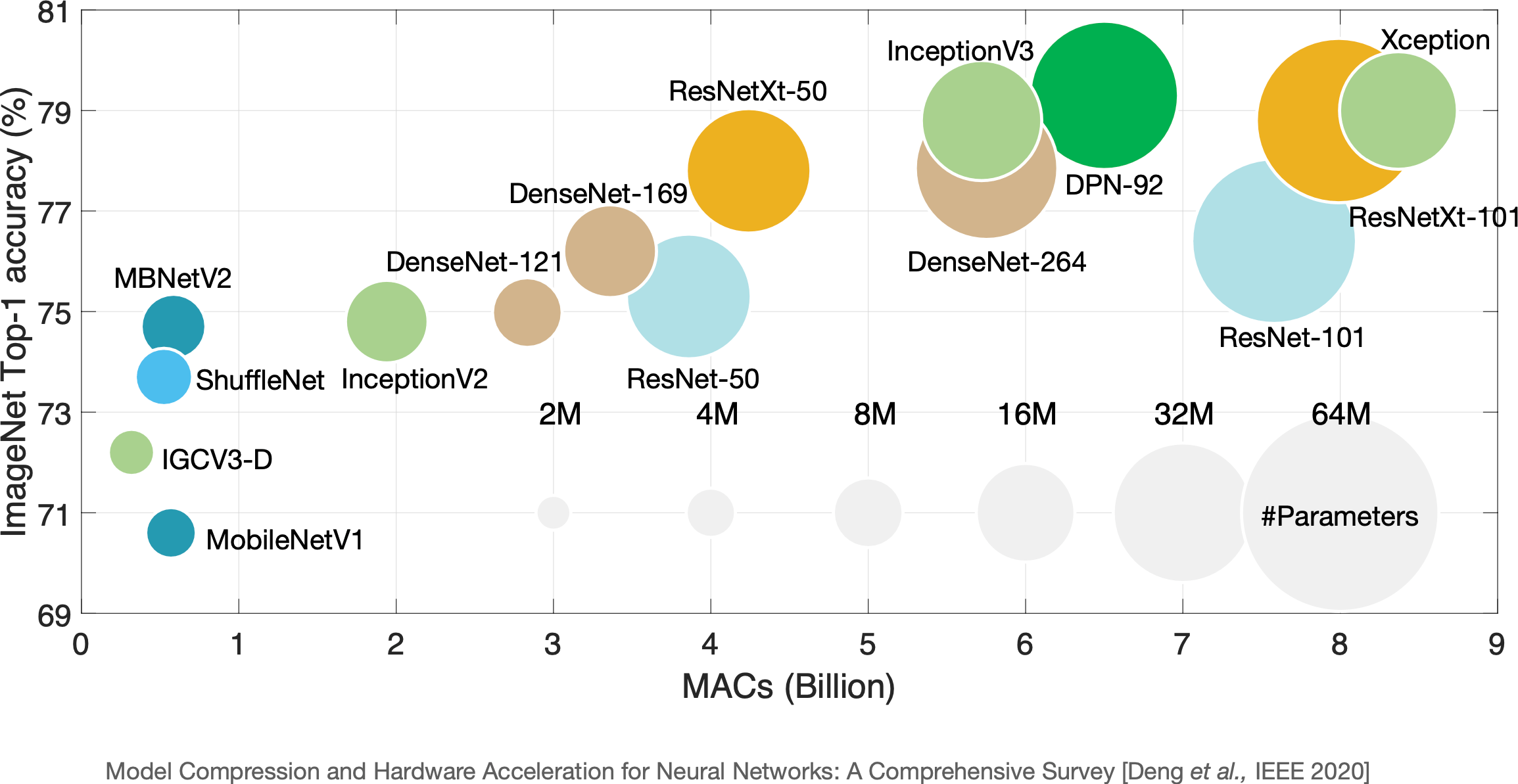
Deep learning, big models
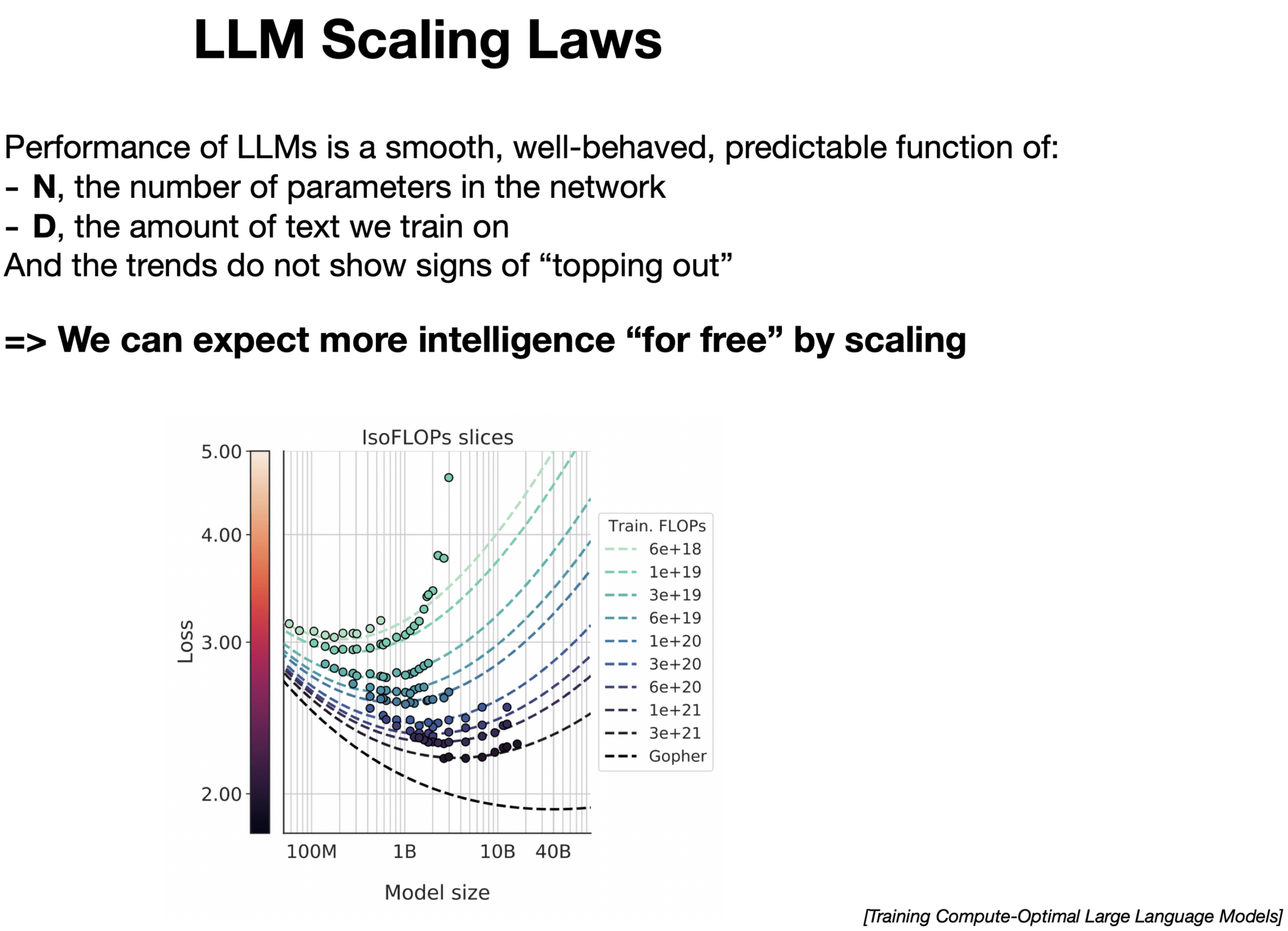
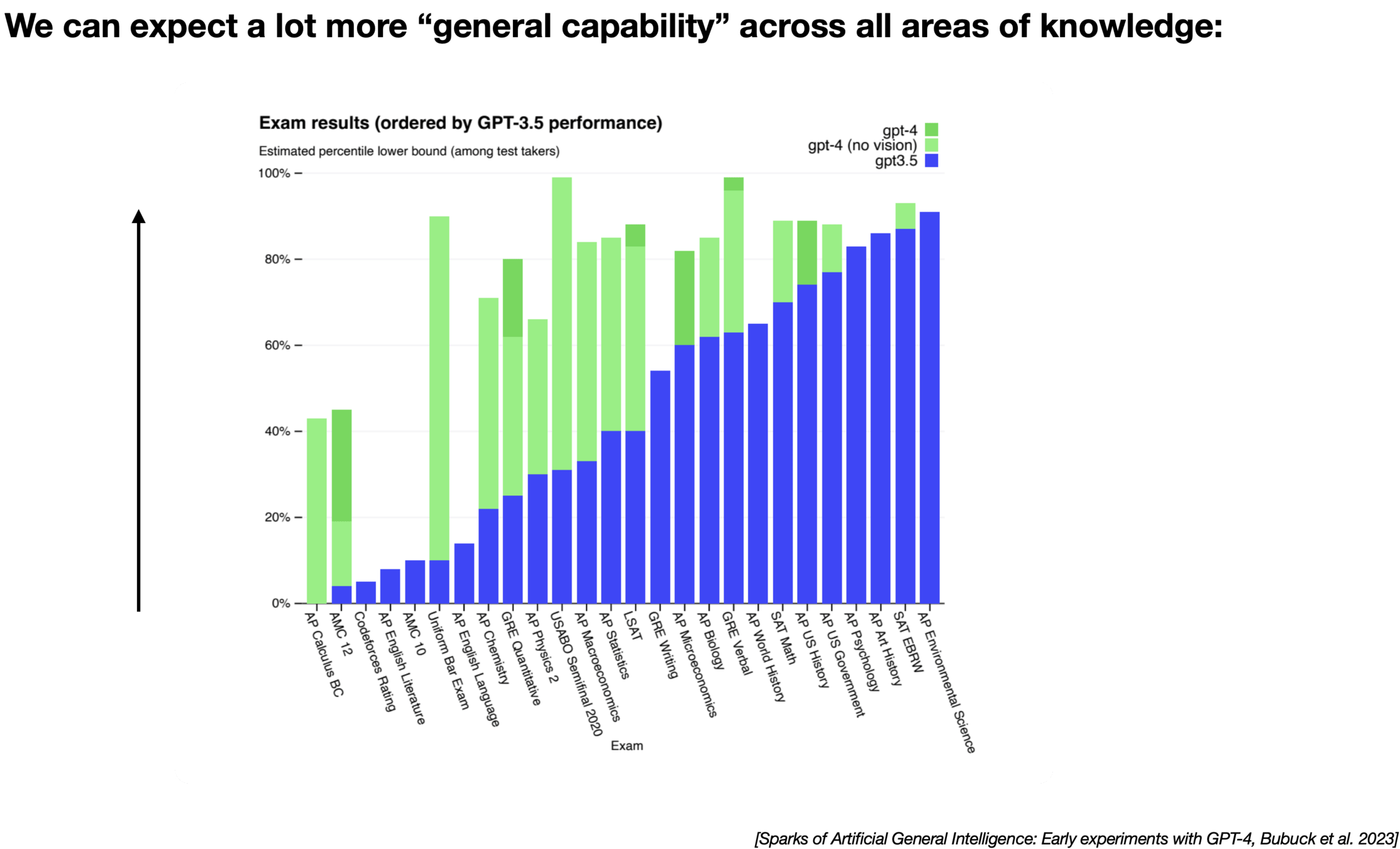
It seems
It seems
(deep) double descent
at odds with the classical statistical learning result
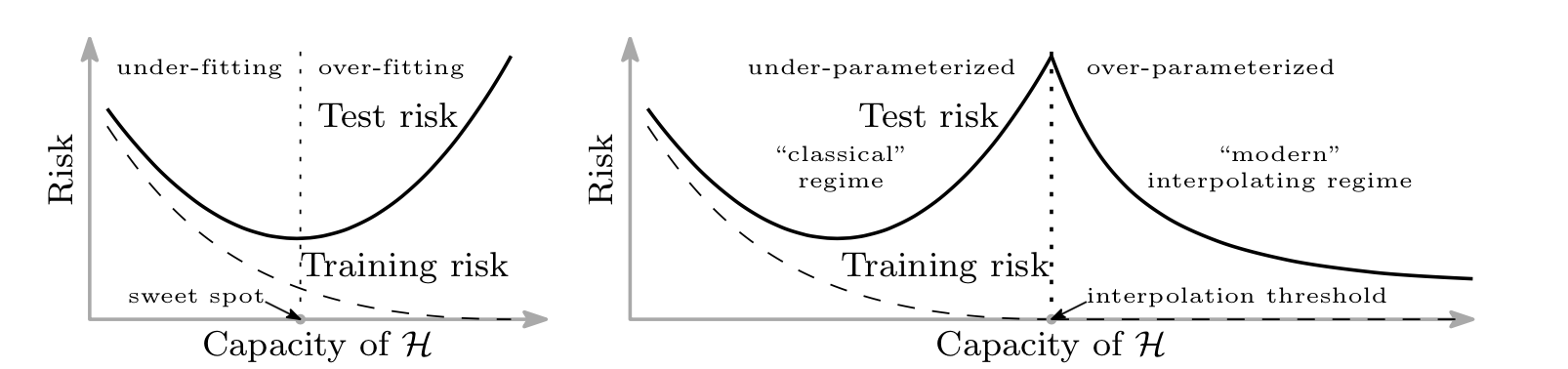
https://arxiv.org/pdf/1812.11118.pdf

slides credit: Andrej Karpathy

slides adapted from 6.5940
Network Augmentation for Tiny Deep Learning [Cai et al., ICLR 2022]
Neural network must be tiny to run efficiently on tiny edge devices.
How to train tiny model with the help of large model?
Pruning
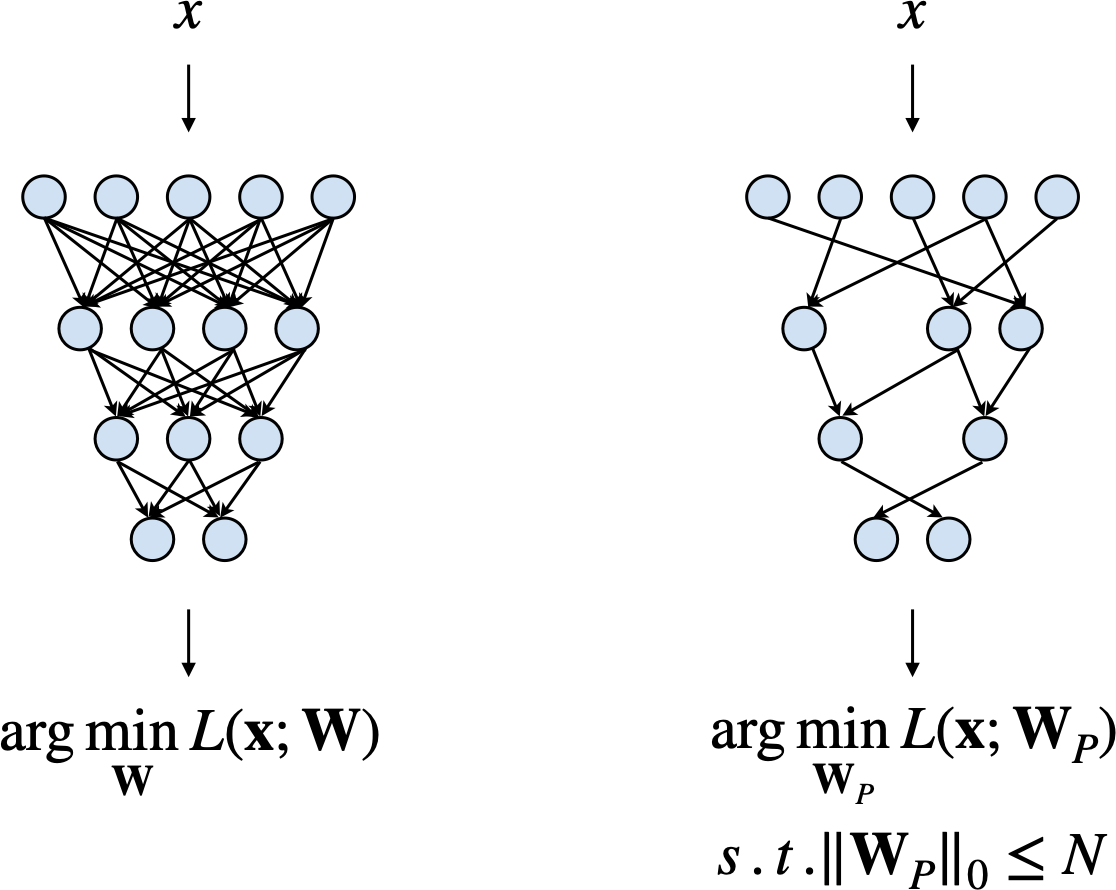
\(\begin{gathered}\arg \min _{\mathbf{W}_P} L\left(\mathbf{x} ; \mathbf{W}_P\right) \\ \text { subject to } \\ \left\|\mathbf{W}_p\right\|_0<N\end{gathered}\)
- \(L\) represents the objective function for neural network training;
- \(\mathbf{x}\) is input, \(\mathbf{W}\) is original weights, \(\mathbf{W}_P\) is pruned weights;
- \(\left\|\mathbf{W}_p\right\|_0\) calculates the \#nonzeros in \(W_P\), and \(N\) is the target \#nonzeros.
Generally, by solving this:
Pruning
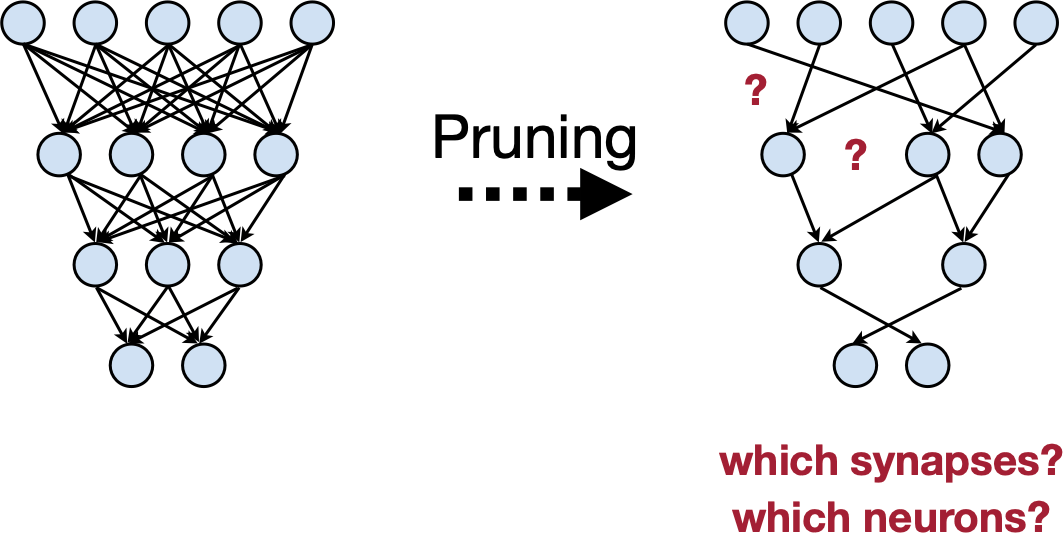
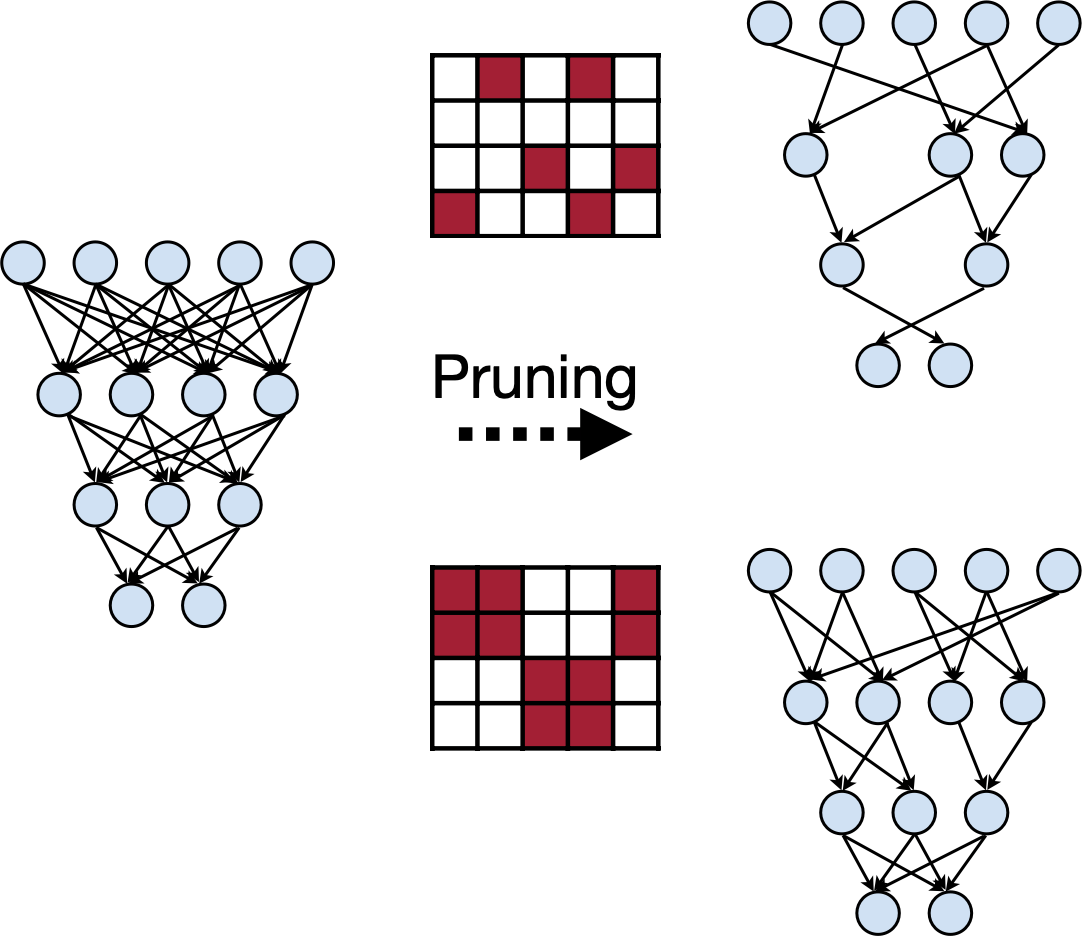
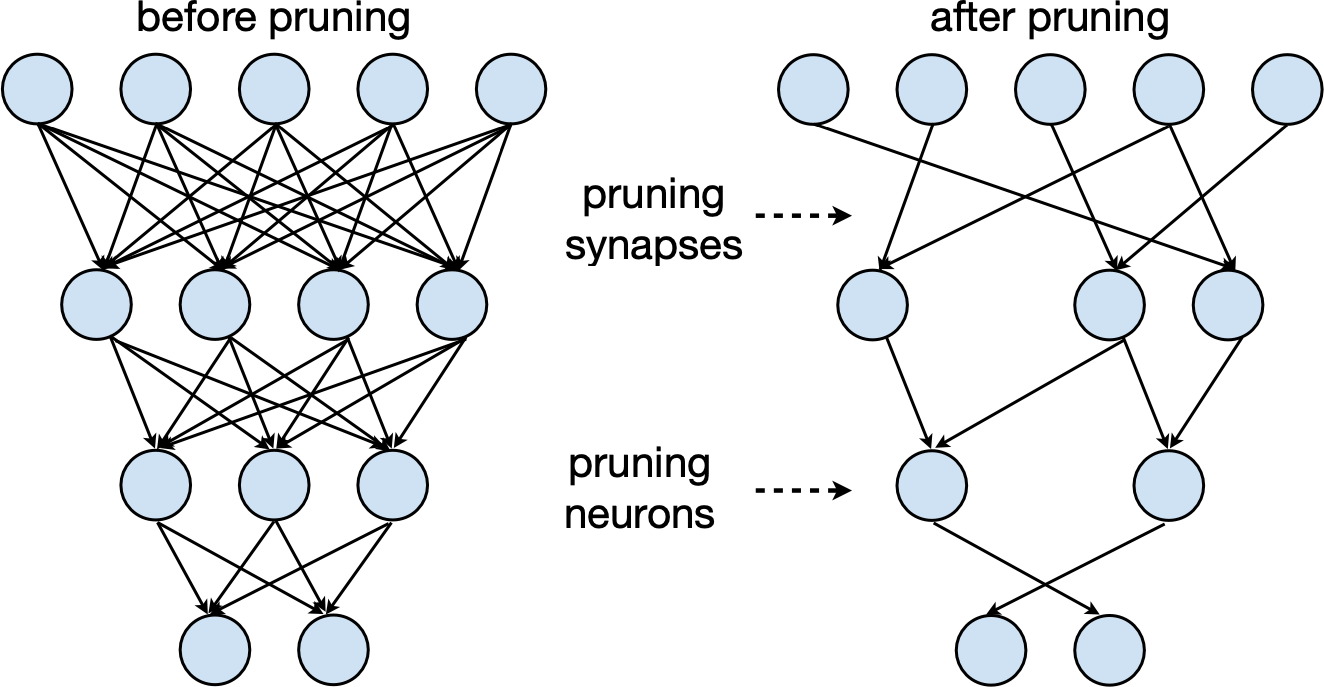


Pruning Happens in Human Brain
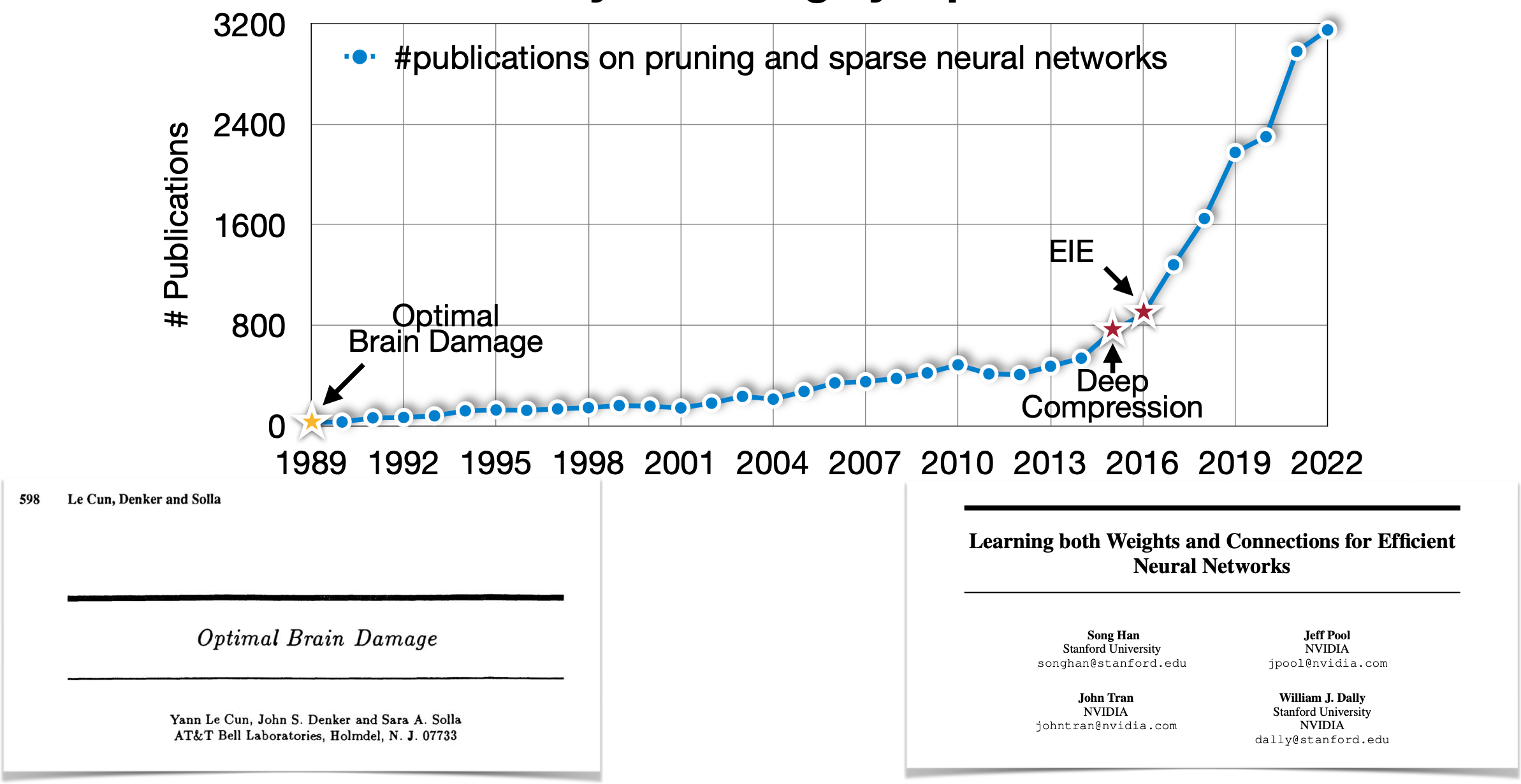
Souce: https://github.com/mit-han-lab/pruning-sparsity-publications
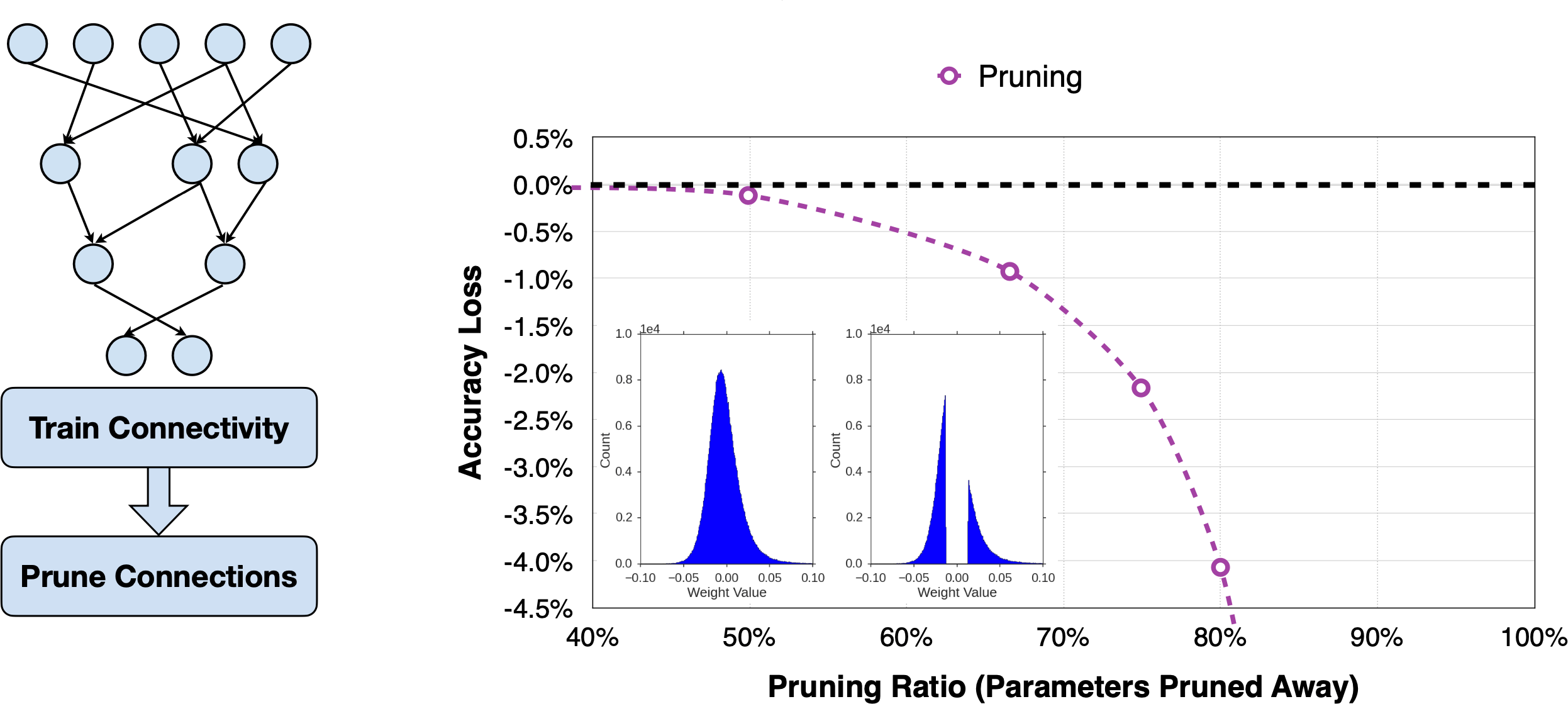
Learning Both Weights and Connections for Efficient Neural Network [Han et al., NeurIPS 2015]
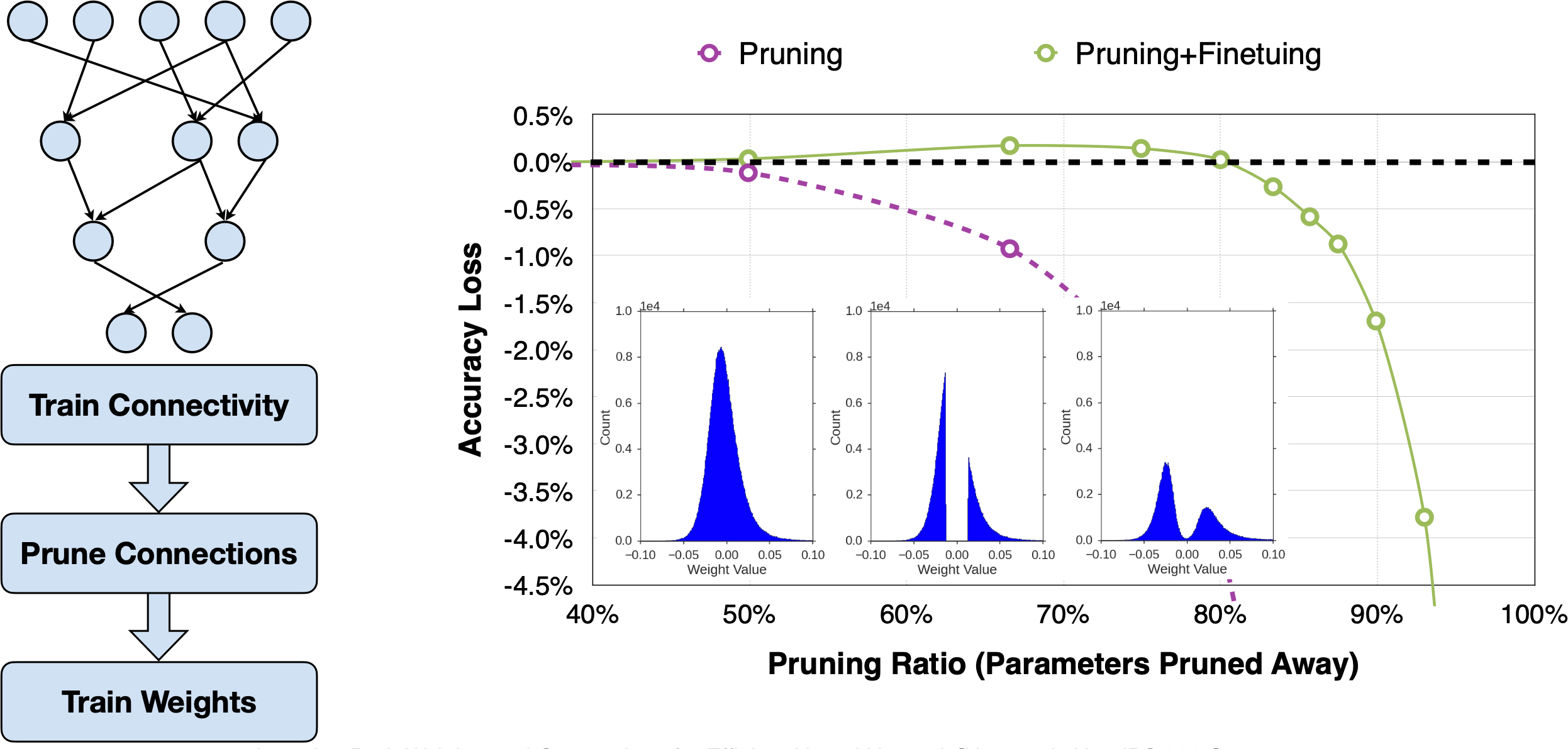
Learning Both Weights and Connections for Efficient Neural Network [Han et al., NeurIPS 2015]
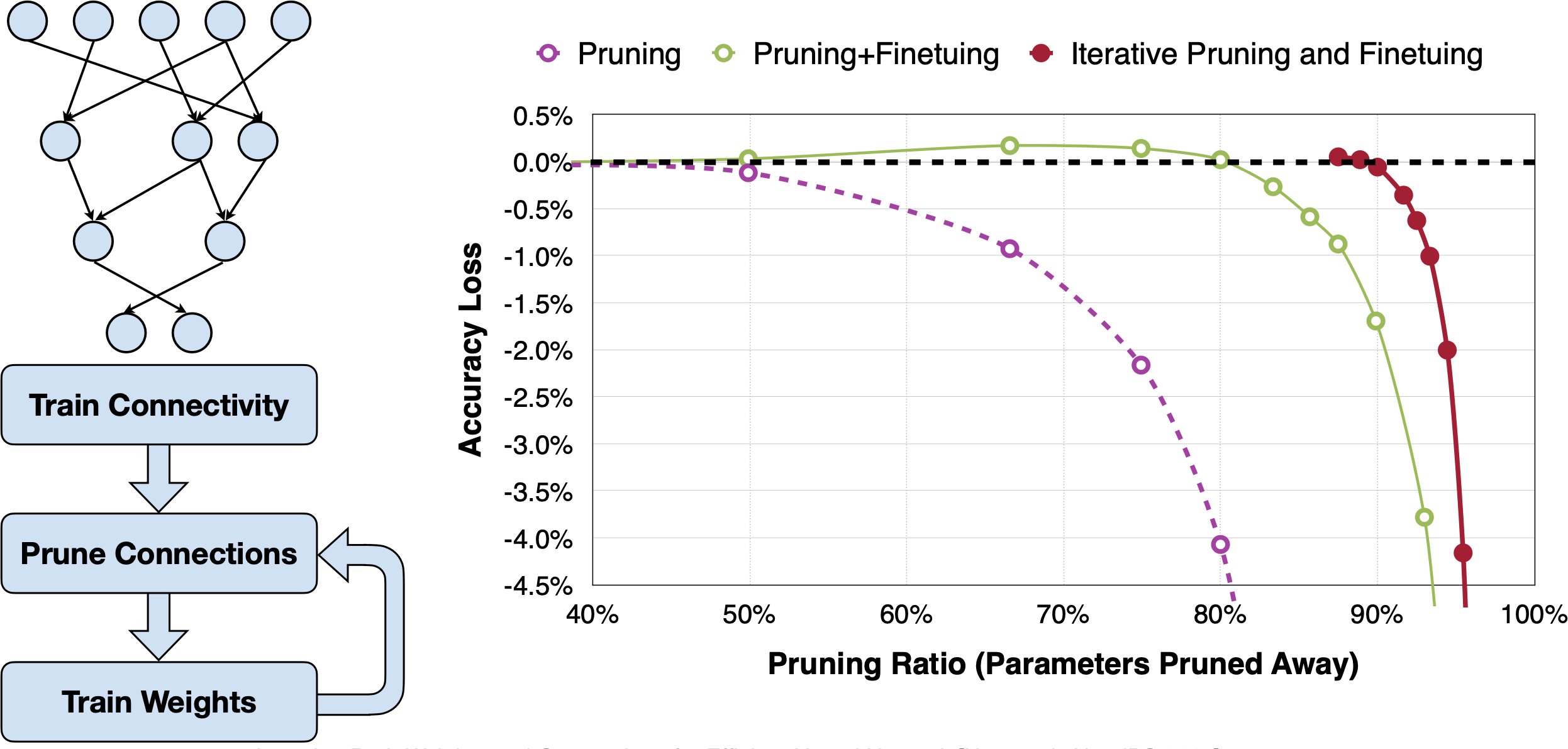
Learning Both Weights and Connections for Efficient Neural Network [Han et al., NeurIPS 2015]
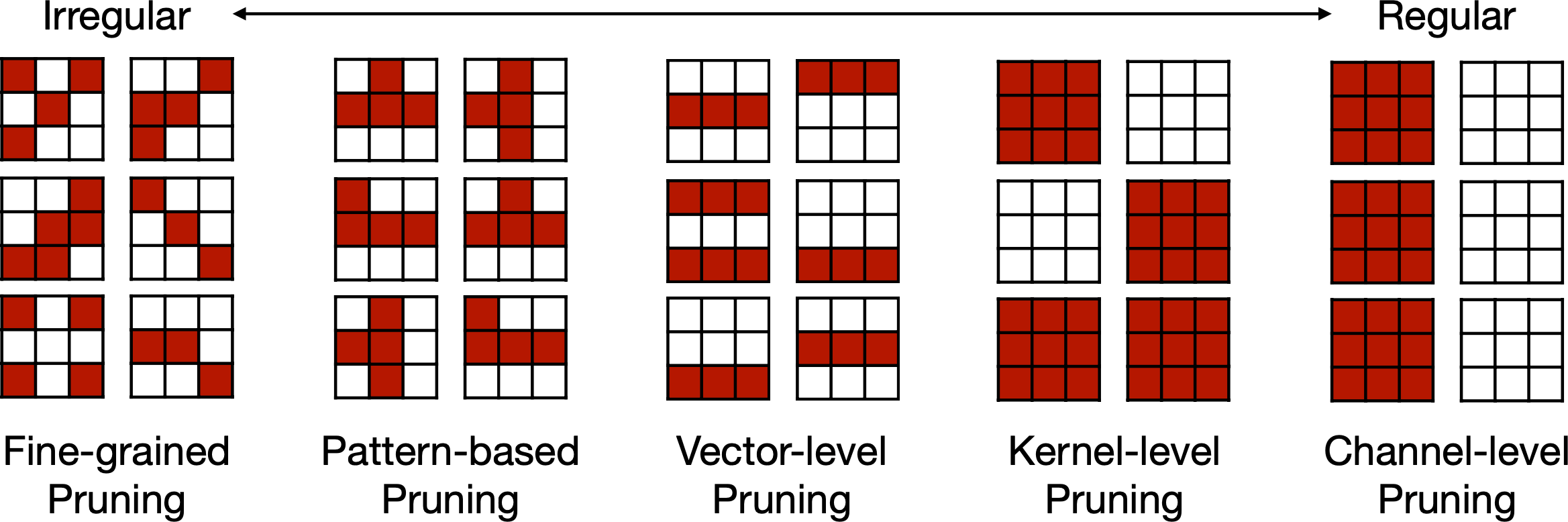
Exploring the granularity of sparsity in convolutional neural networks [Mao et al., CVPR-W]
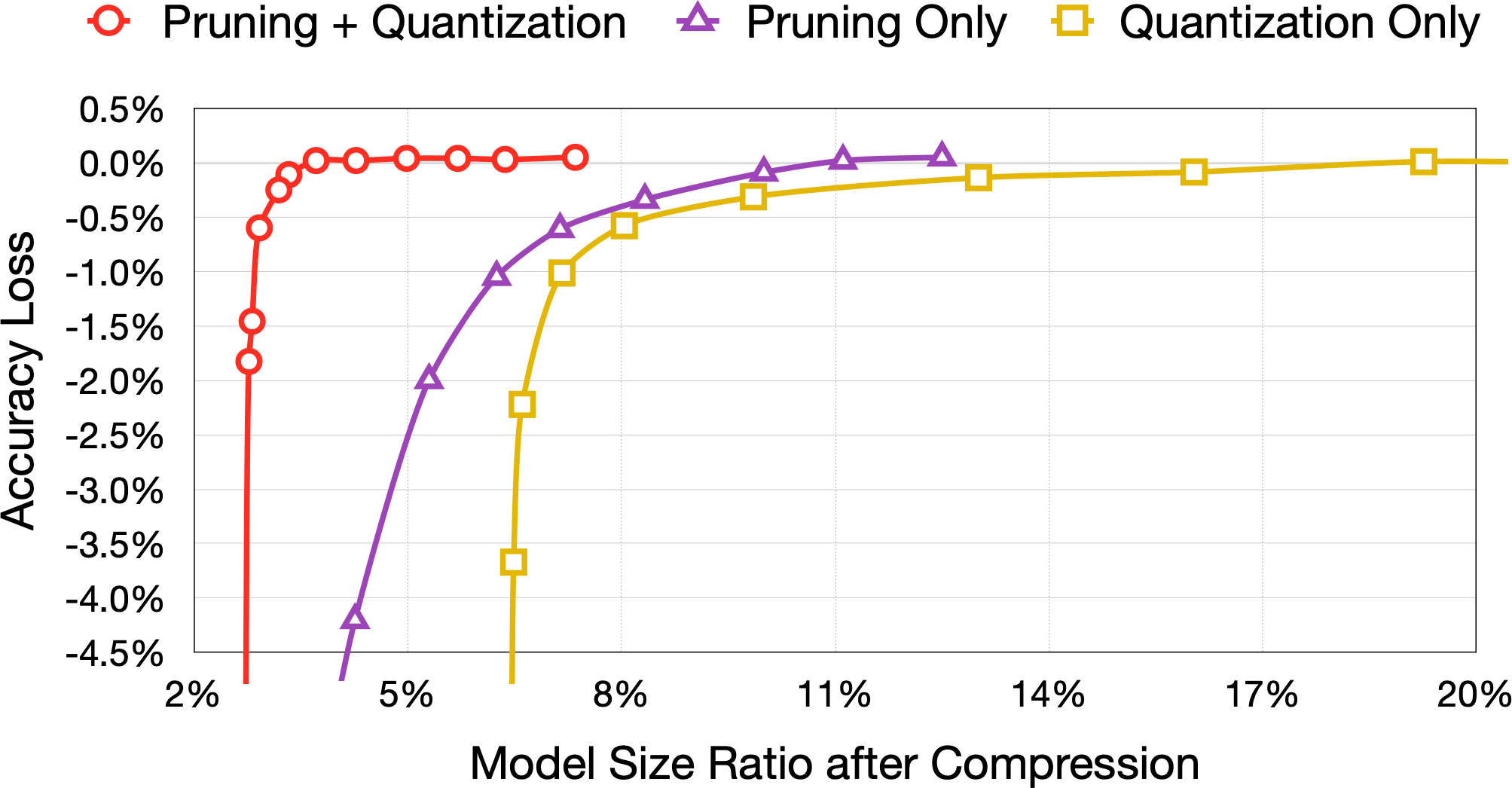
Quantization
Quantization is the process of constraining an input from a continuous or otherwise large set of values to a discrete set.

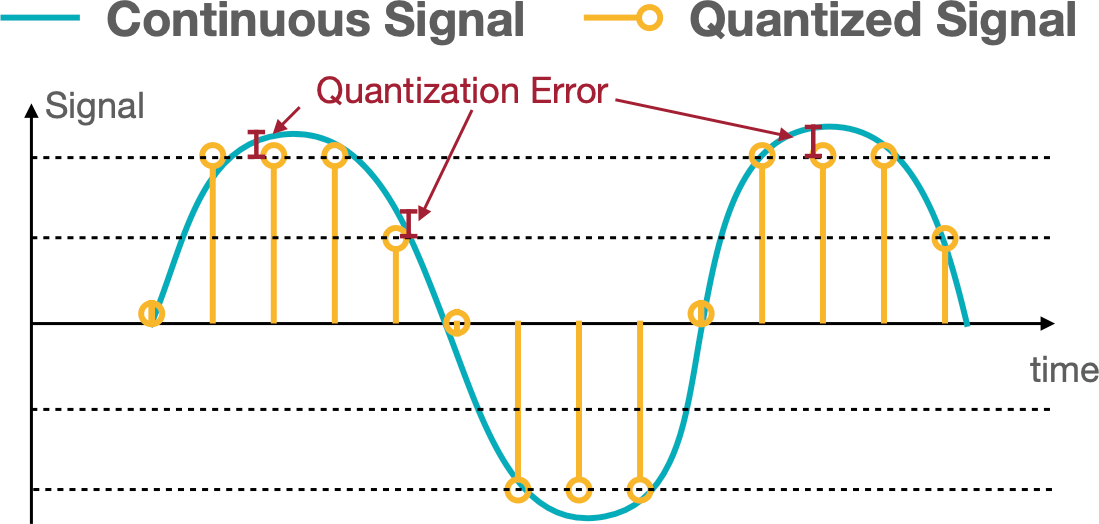
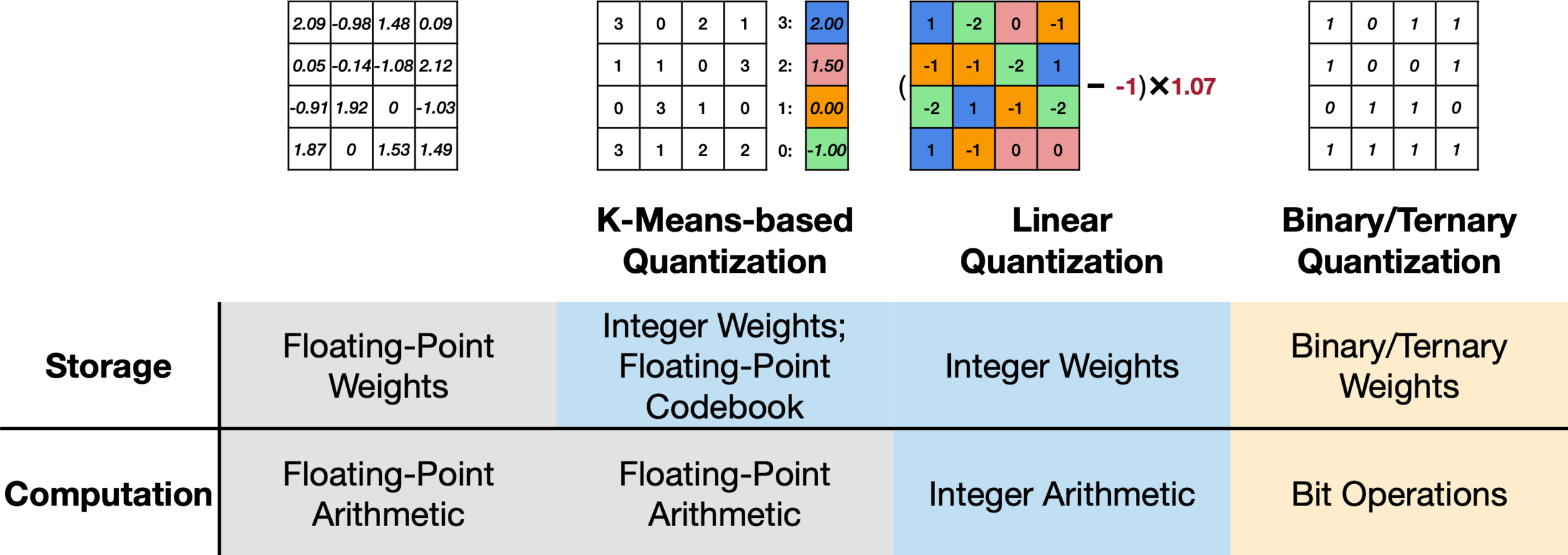
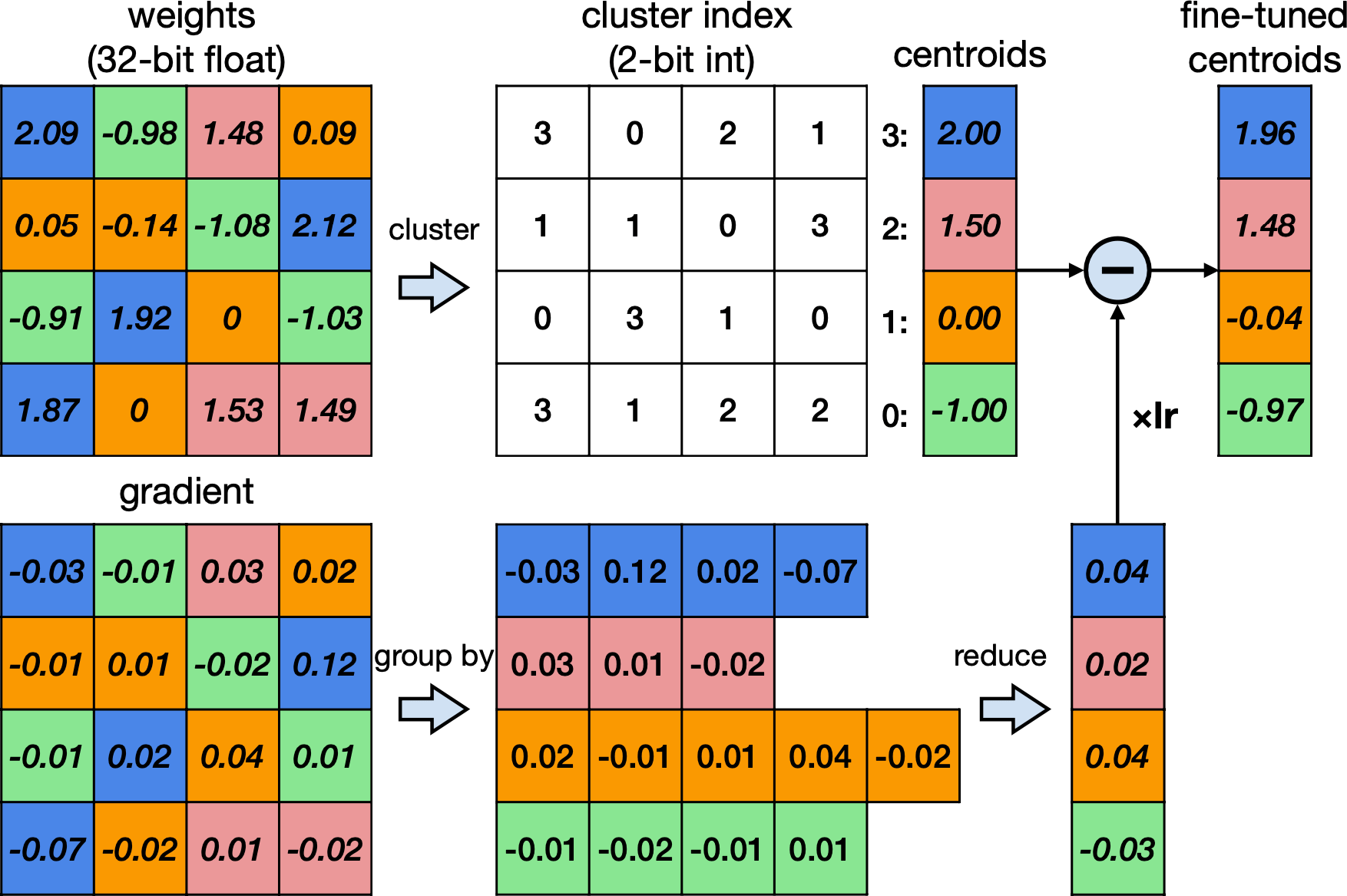
K-means based quantization
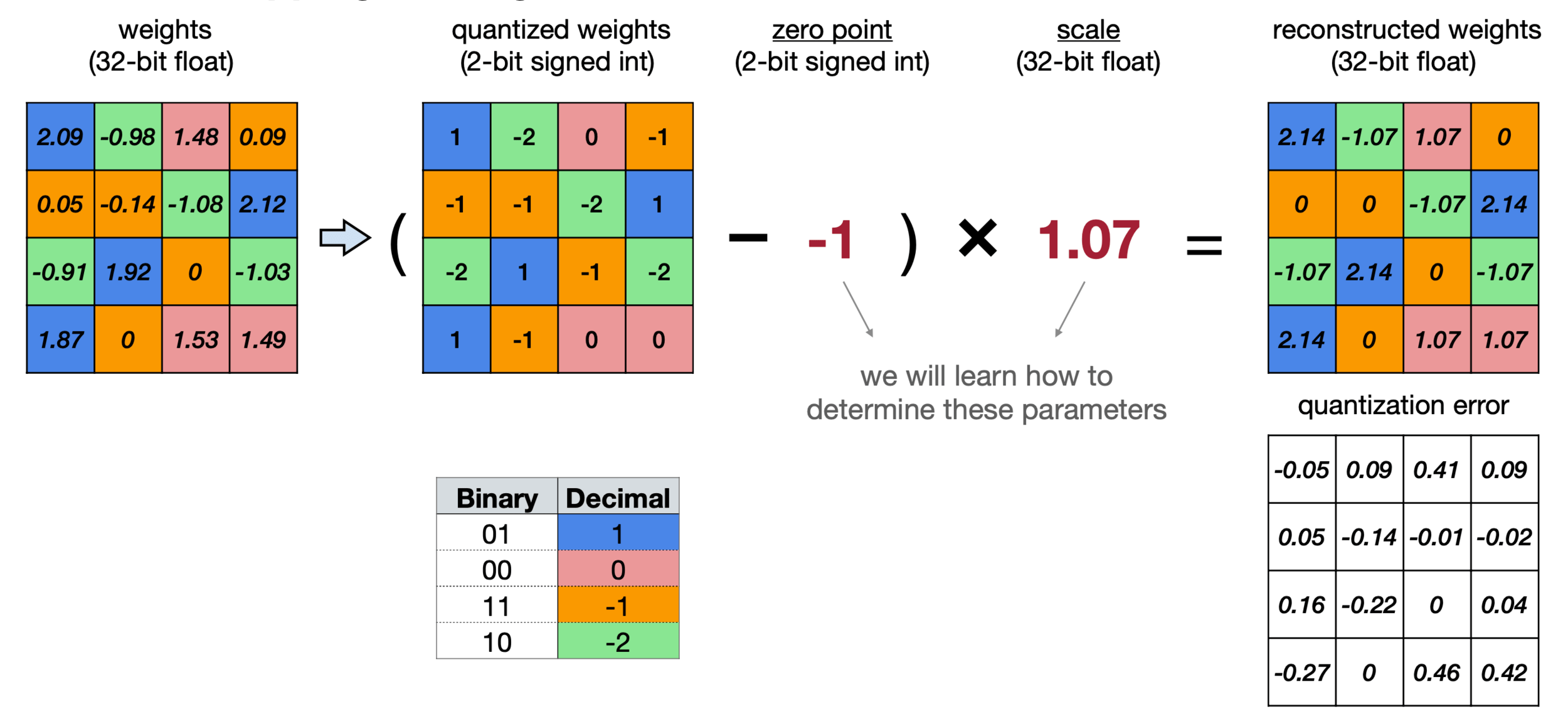
Linear Quantization
An affine mapping of integers to real numbers
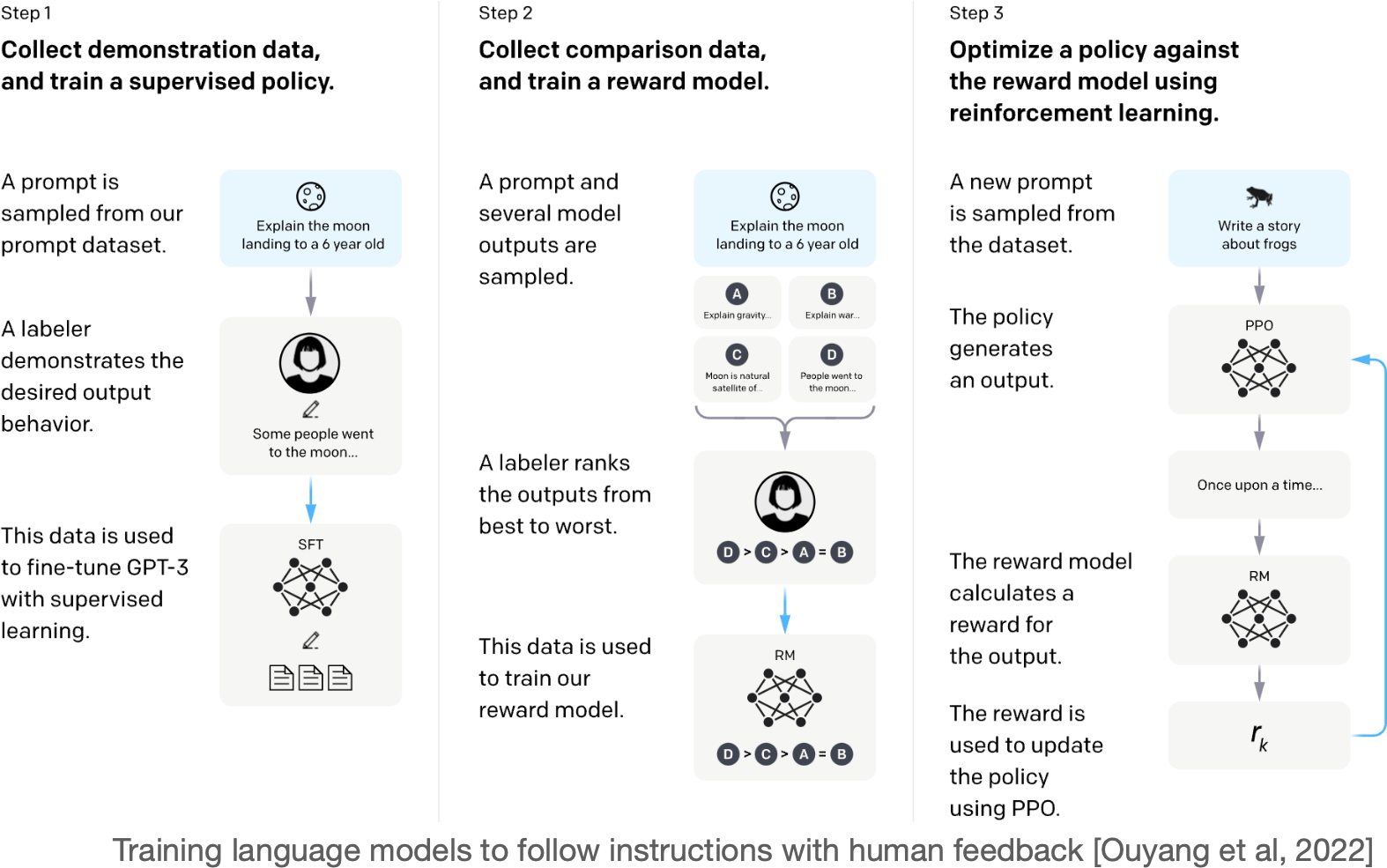
Fine-tuning: supervised fine-tuning (SFT)
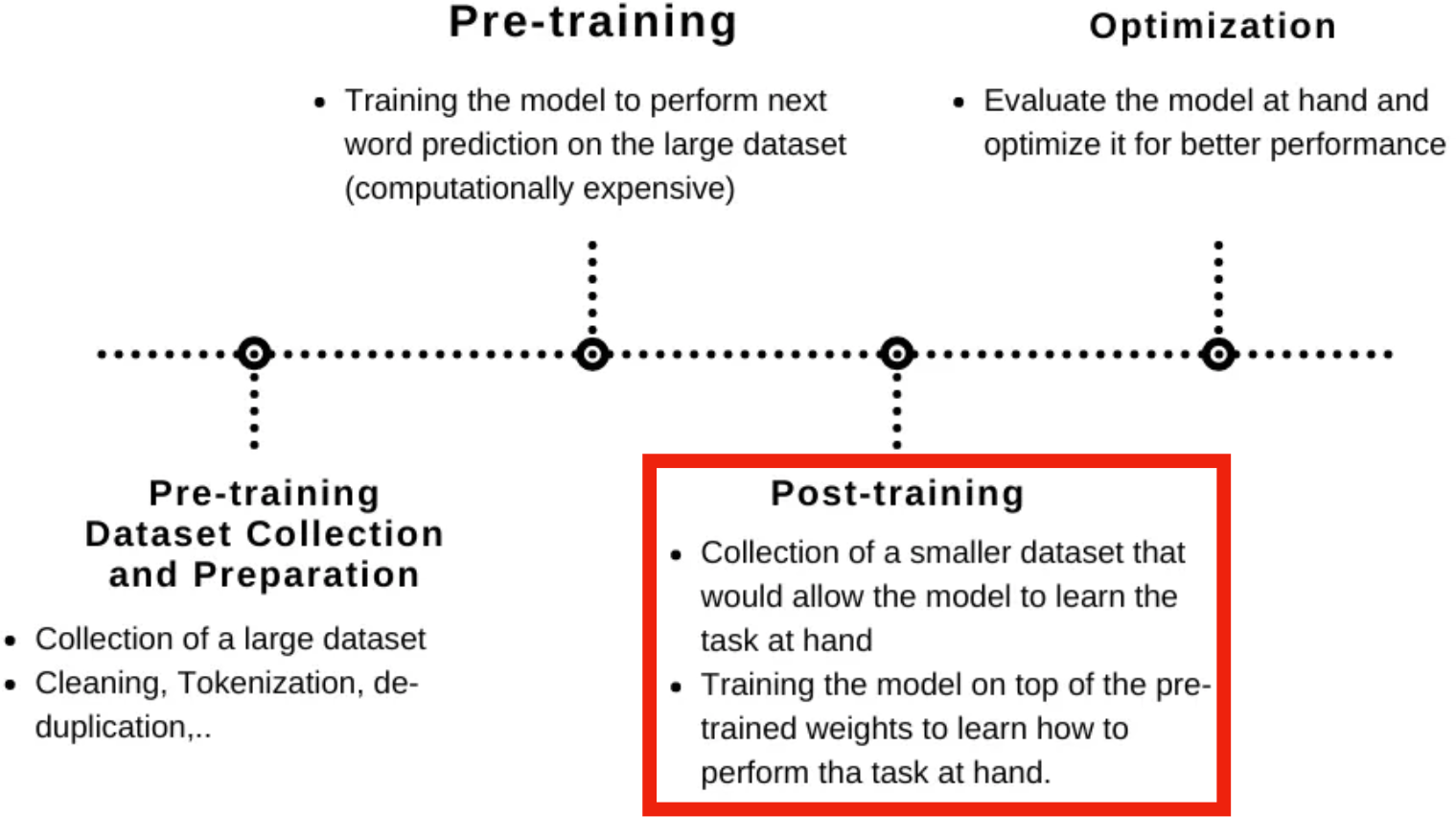
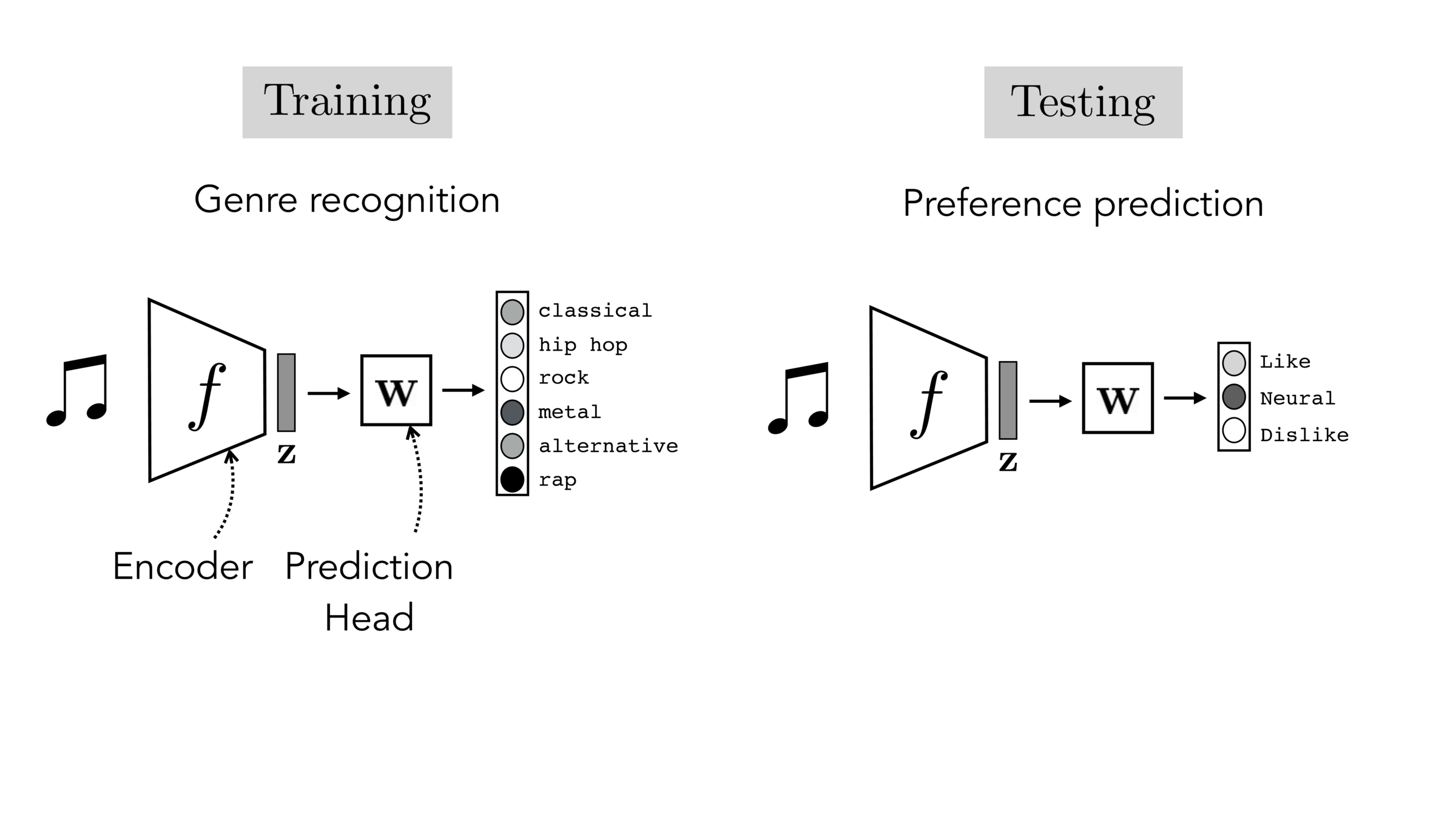
Often, what we will be “tested” on is not what we were trained on.
[images credit: visionbook.mit.edu]
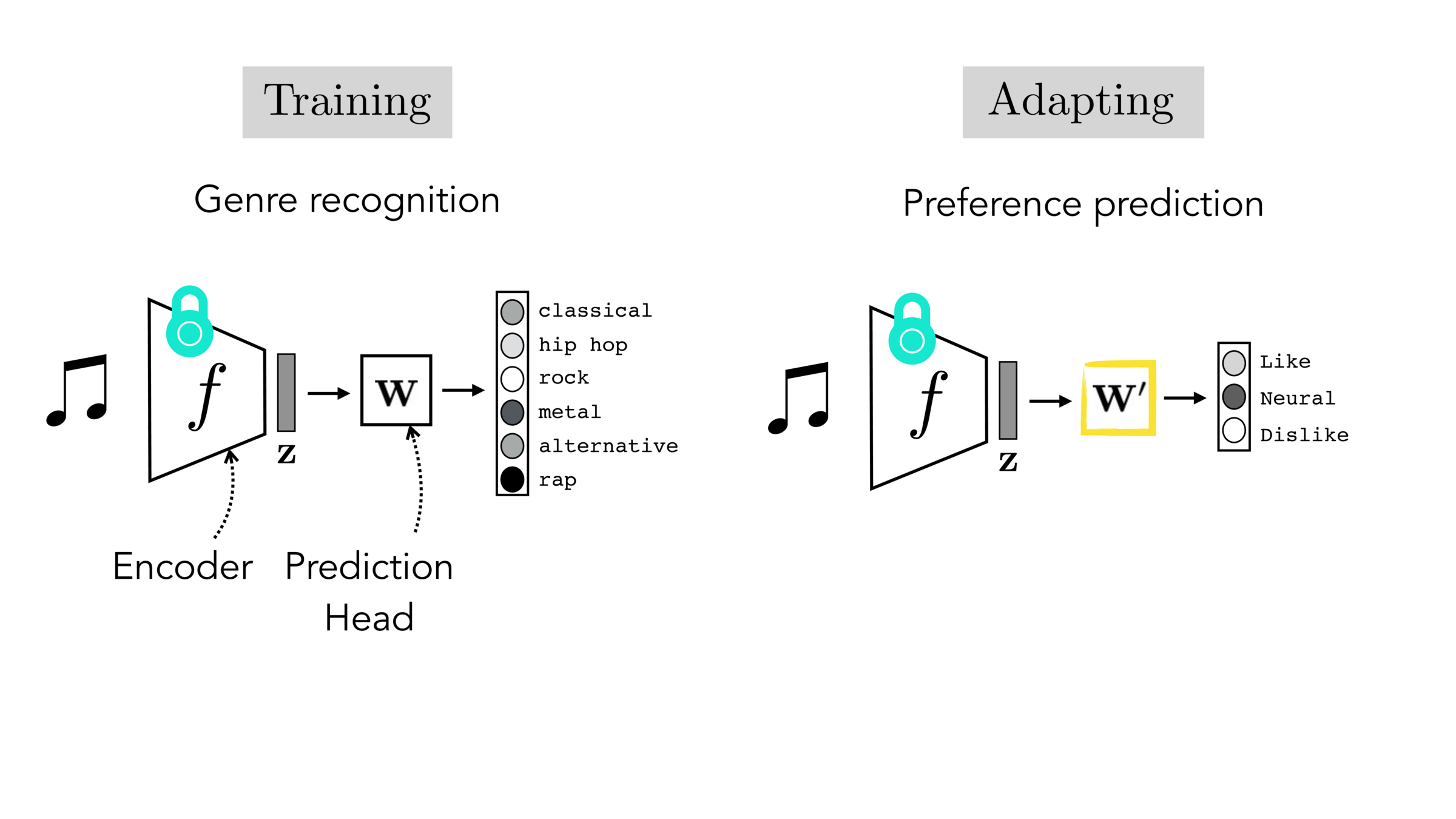
Final-layer adaptation: freeze \(f\), train a new final layer to new target data
[images credit: visionbook.mit.edu]
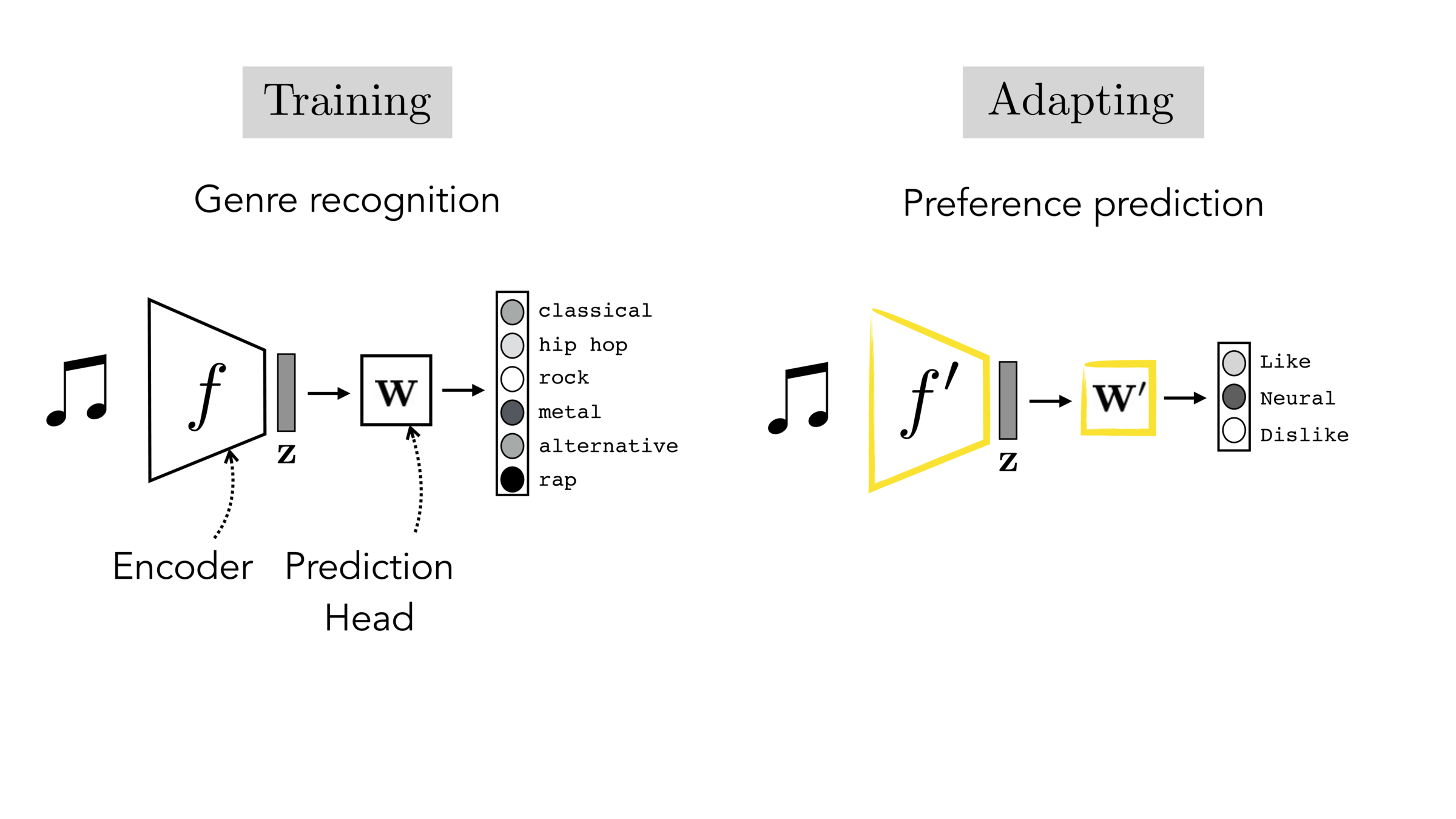
Finetuning: initialize \(f’\) as \(f\), then continue training for \(f'\) as well, on new target data
[images credit: visionbook.mit.edu]
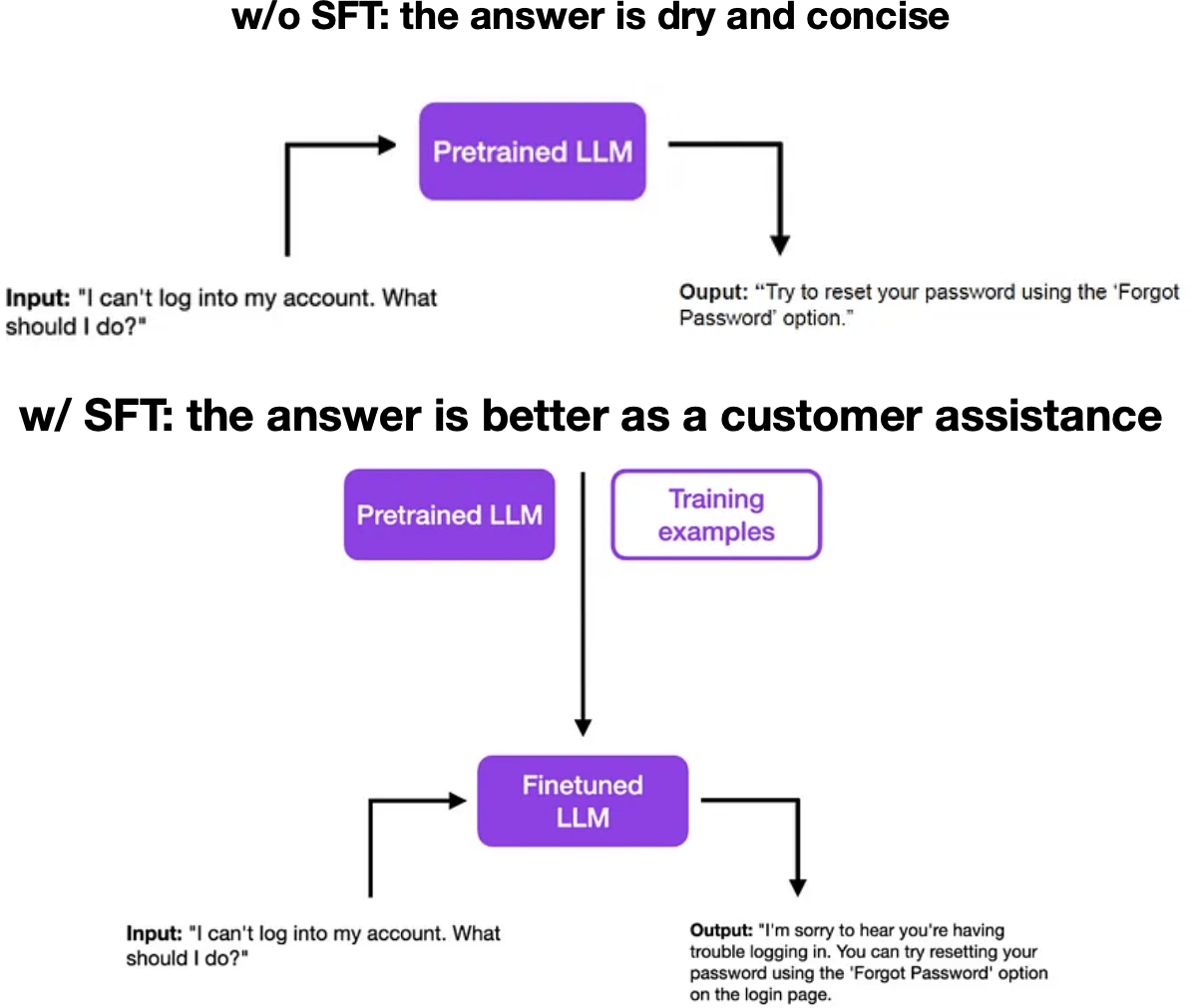
Fine-tuning: supervised fine-tuning (SFT)
Fine-tuning: supervised fine-tuning (SFT)

Fine-tuning: Reinforcement Learning from Human Feedback (RLHF)
BitFit: Fine-tune only the bias terms.
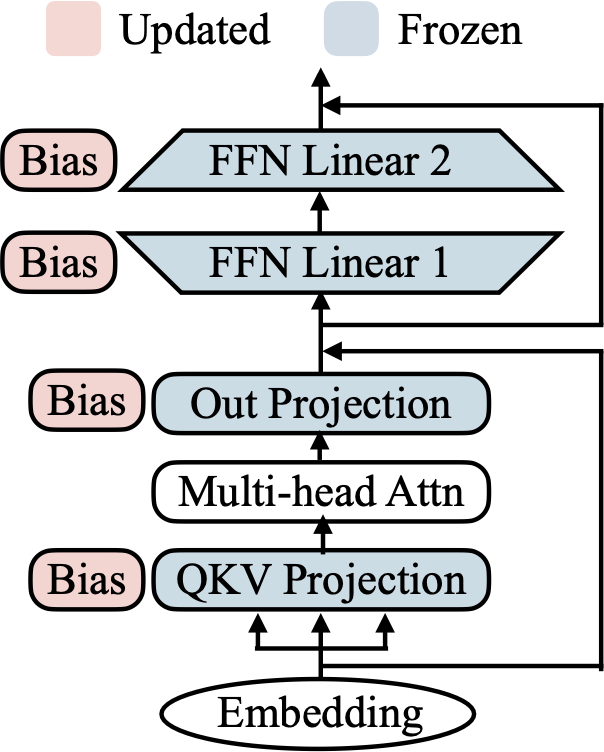
- A sparse fine-tuning method where only the bias of the model (or a subset of the bias) are being updated.
- BERT-base has 110M parameters, but only 0.1M biases (>1000x less).
- From small-to-medium datasets, BitFit is competitive with (and sometimes better than) full-fine-tuning.
- For larger data, the method shows inferior performance than full.
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models [Zeken et al, ACL 2021]
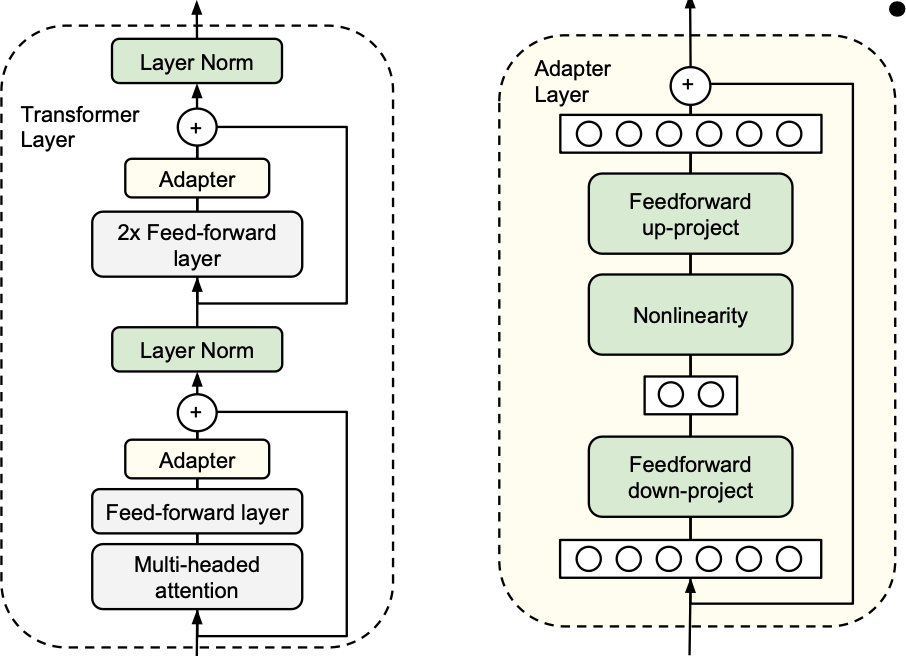
Adapter: Inserting learnable layers inside transformer architectures
- Add only a few trainable parameters per task, and new tasks can be added without revisiting previous ones.
- Adapters attain near state-of-the-art performance, whilst adding only a few parameters per task.
Parameter-Efficient Transfer Learning for NLP [Houlsby et al, ICML 2019]
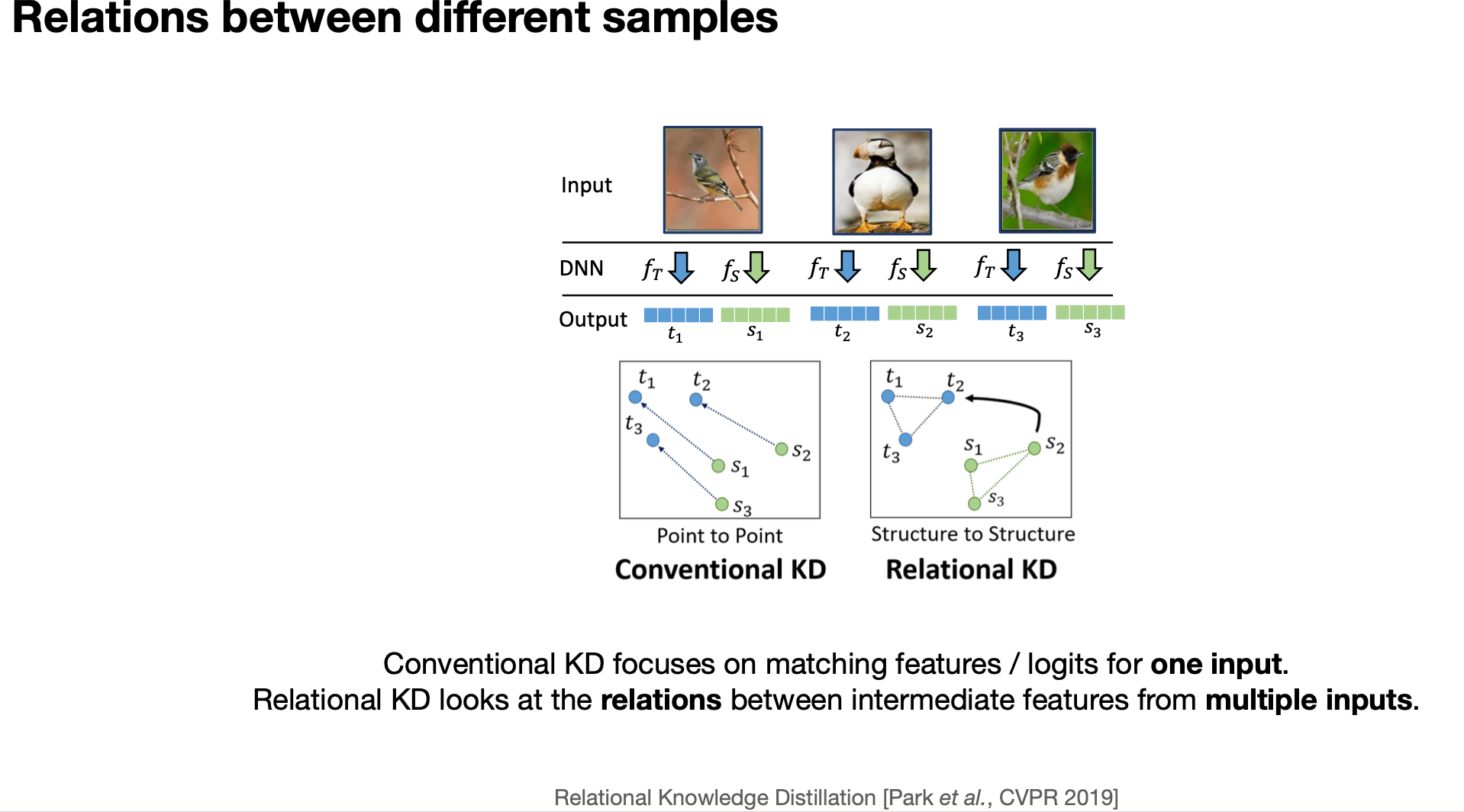
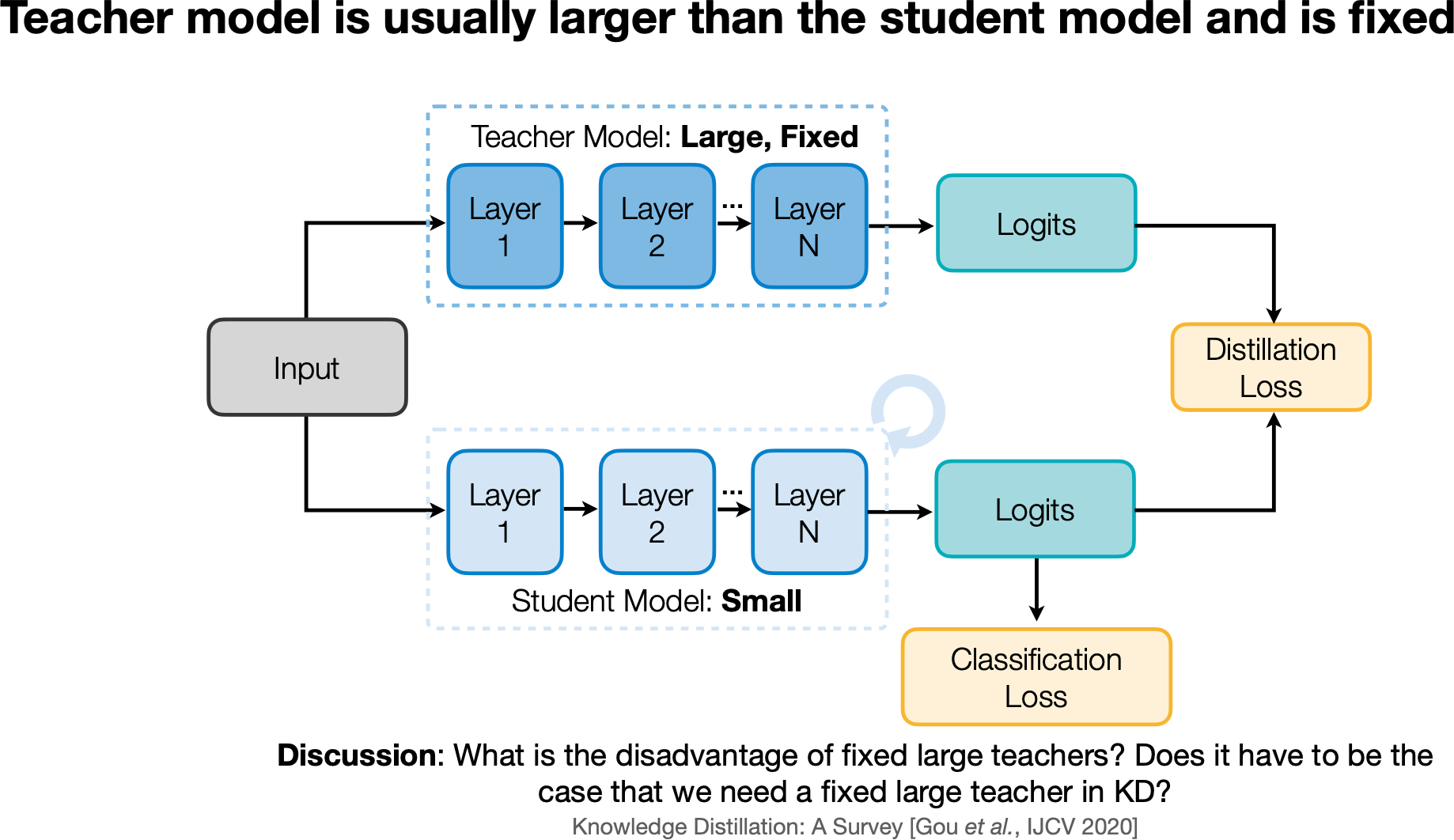
Knowledge Distillation
Distilling the Knowledge in a Neural Network [Hinton et al., NeurIPS Workshops 2014]
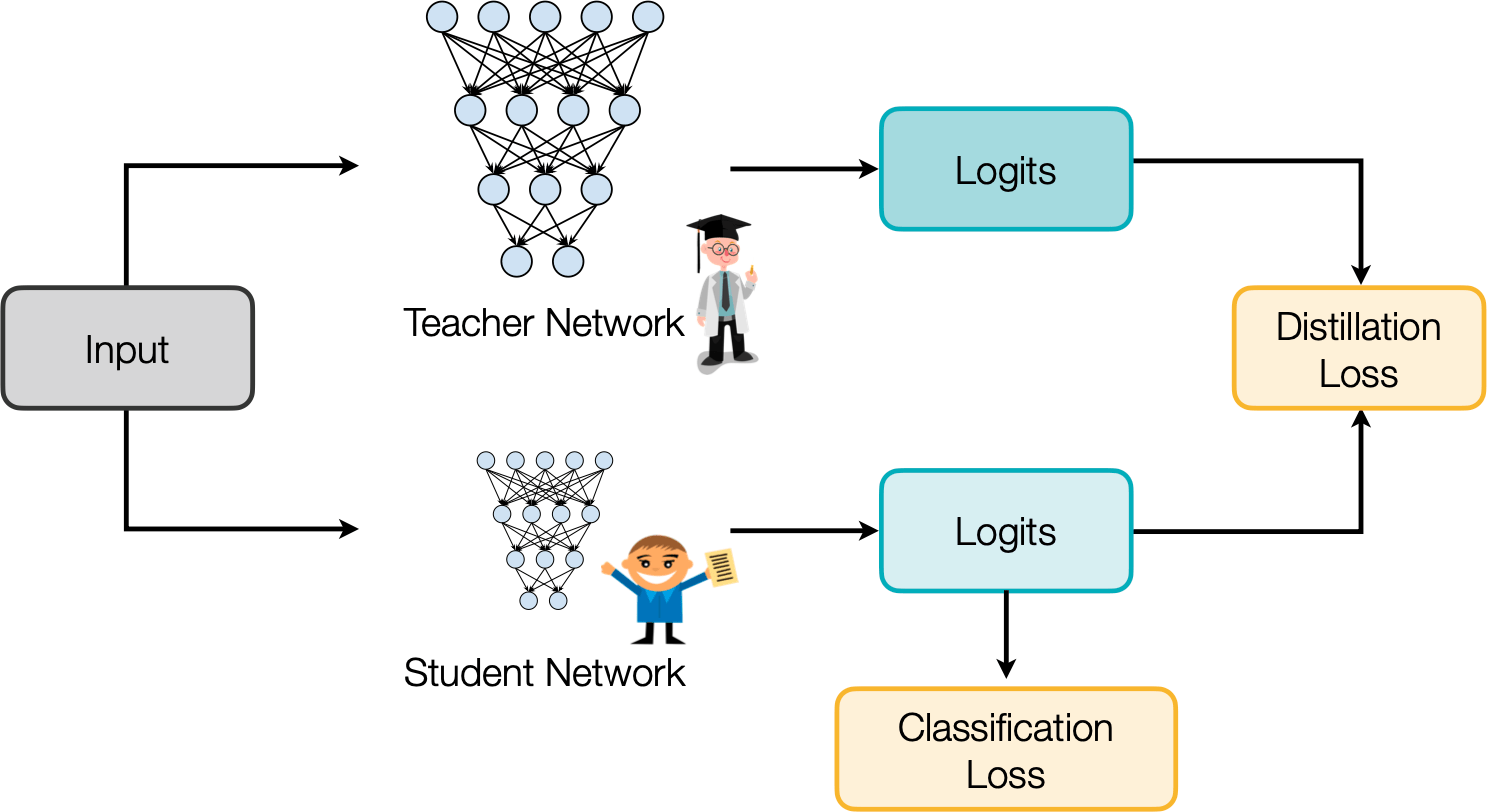
Matching prediction probabilities between teacher and student
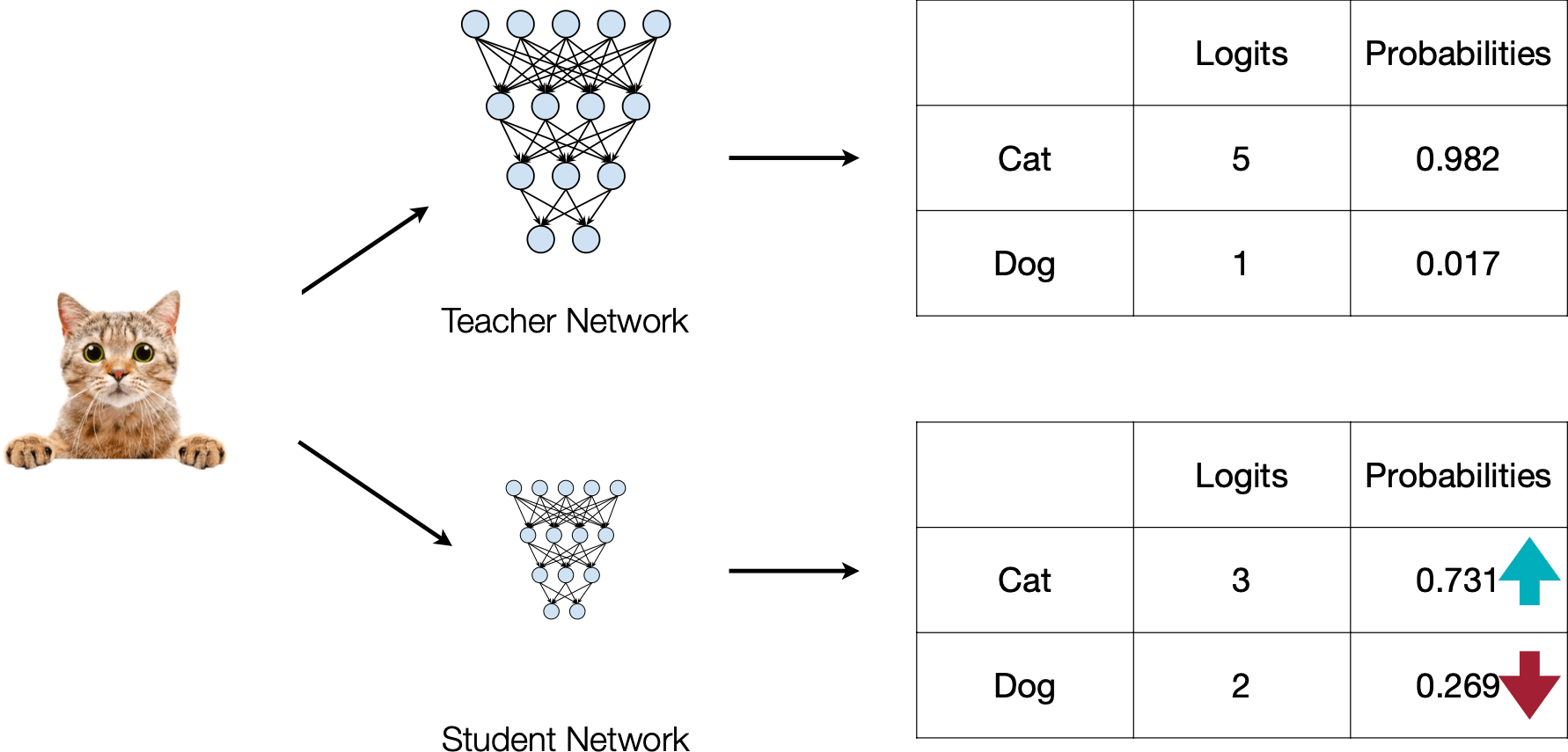
What to match?
1. Output logits
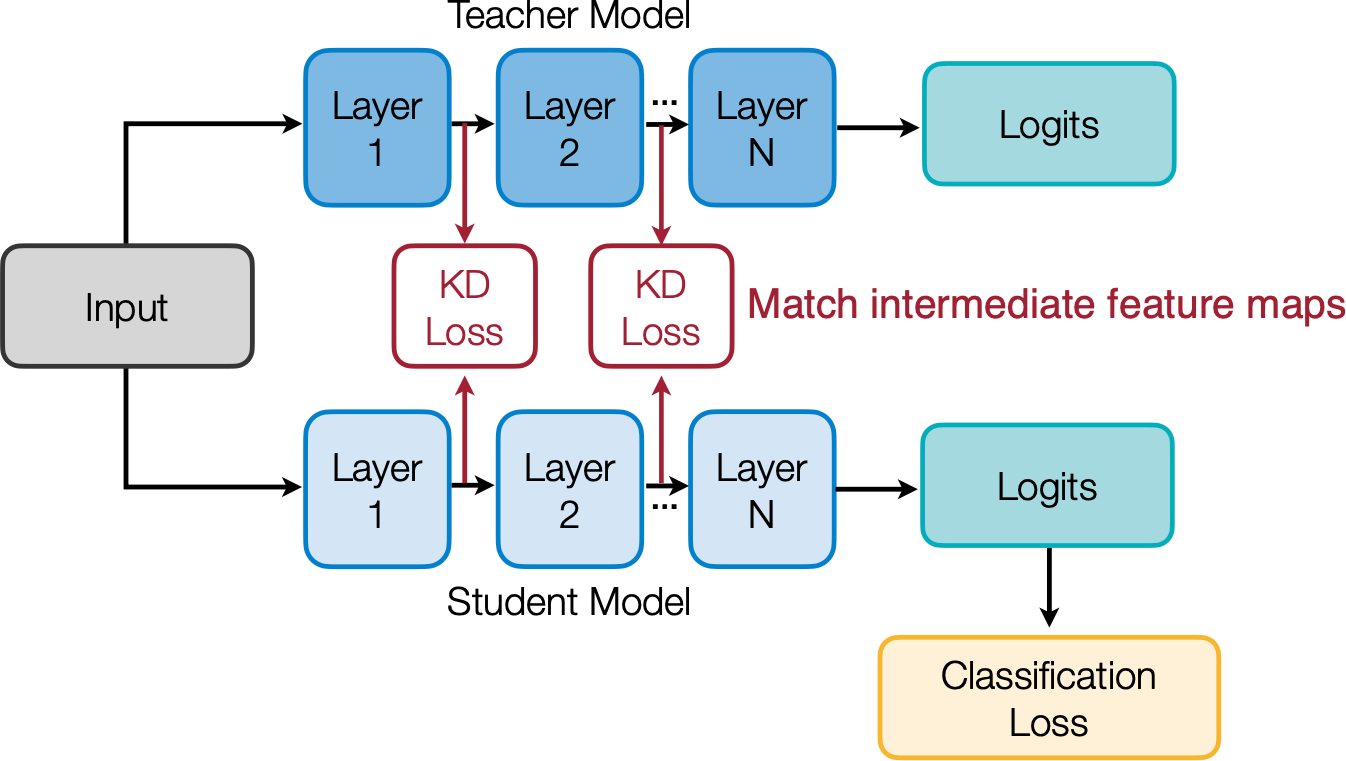
2. Intermediate weights
3. Intermediate features
4. Gradients
5. Sparsity patterns
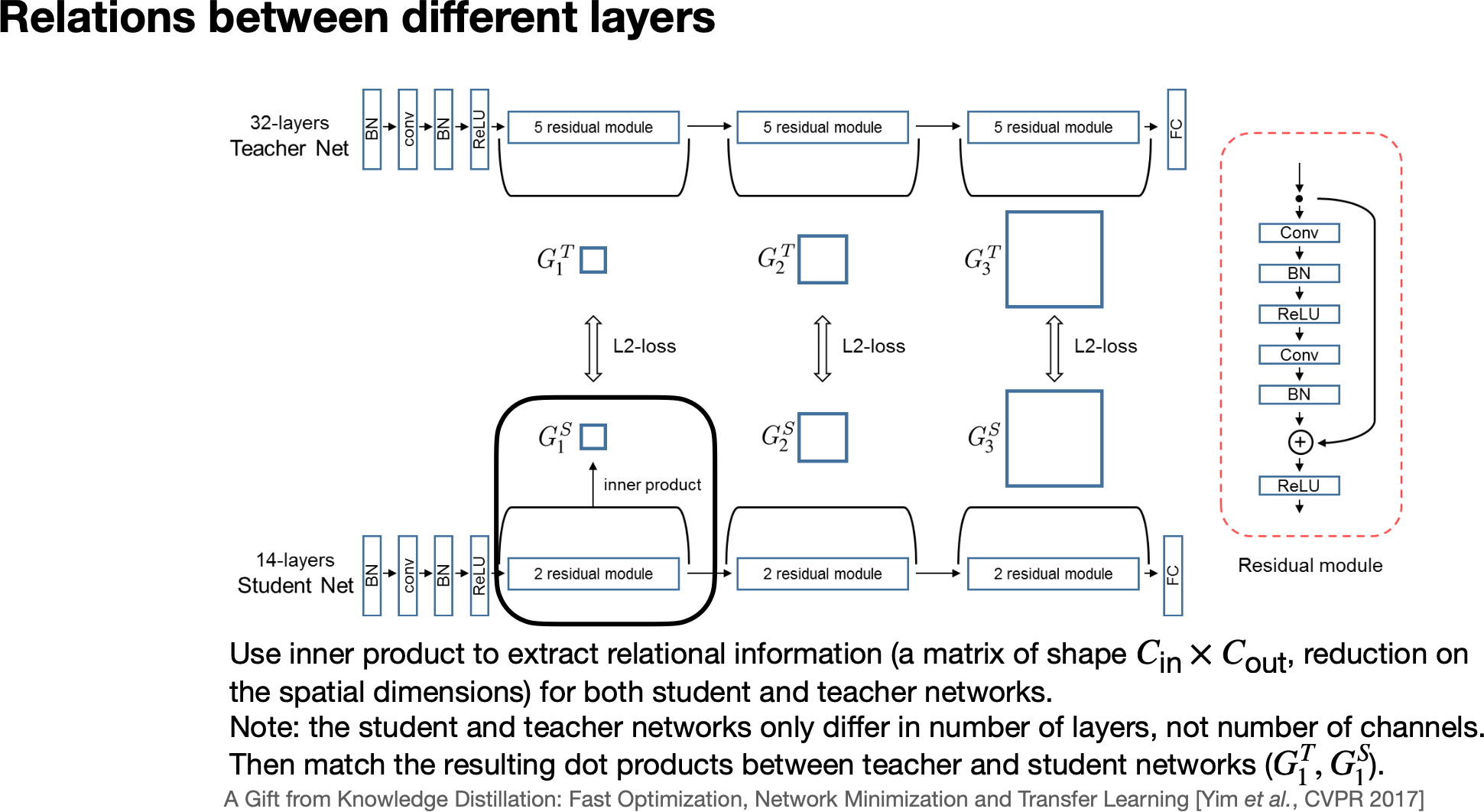
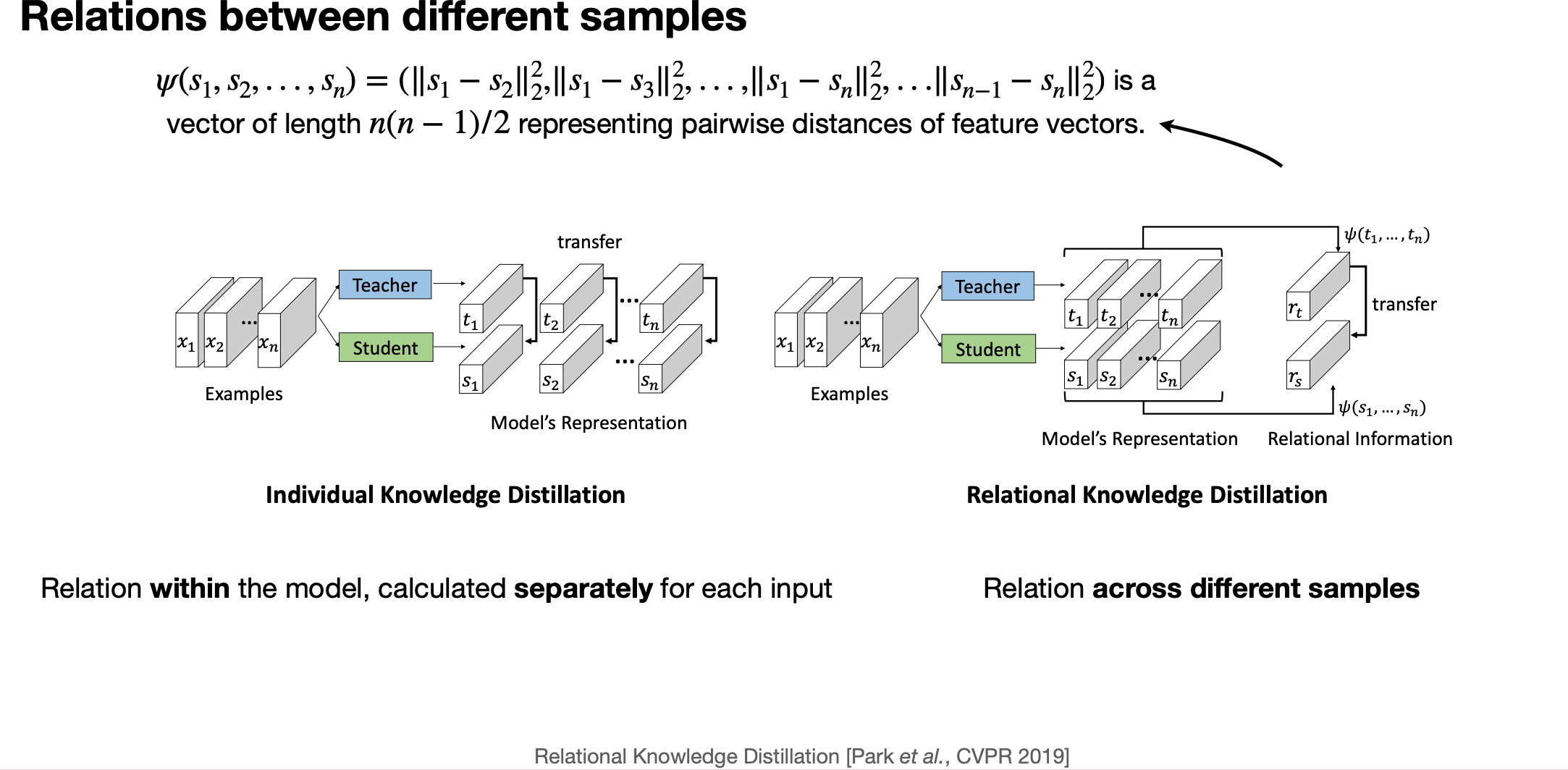
6. Relational information
Minimizing maximum mean discrepancy between feature maps
Intuition: teacher and student networks should have similar feature distributions, not just output probability distributions.

matching gradeints
not the transformer attention
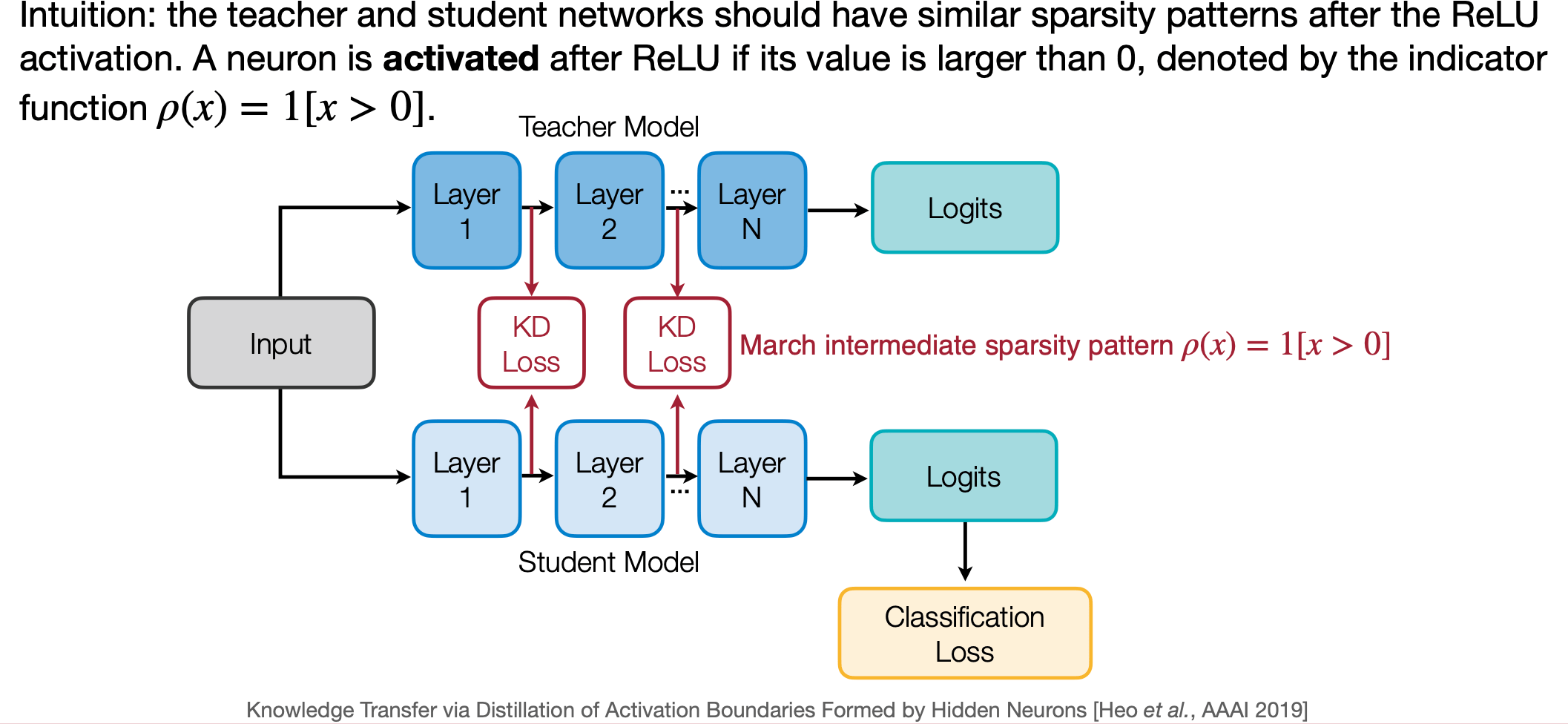
Intuition: the teacher and student networks should have similar sparsity patterns after the ReLU activation. A neuron is activated after ReLU if its value is larger than 0 , denoted by the indicator function \(\rho(x)=1[x>0]\).
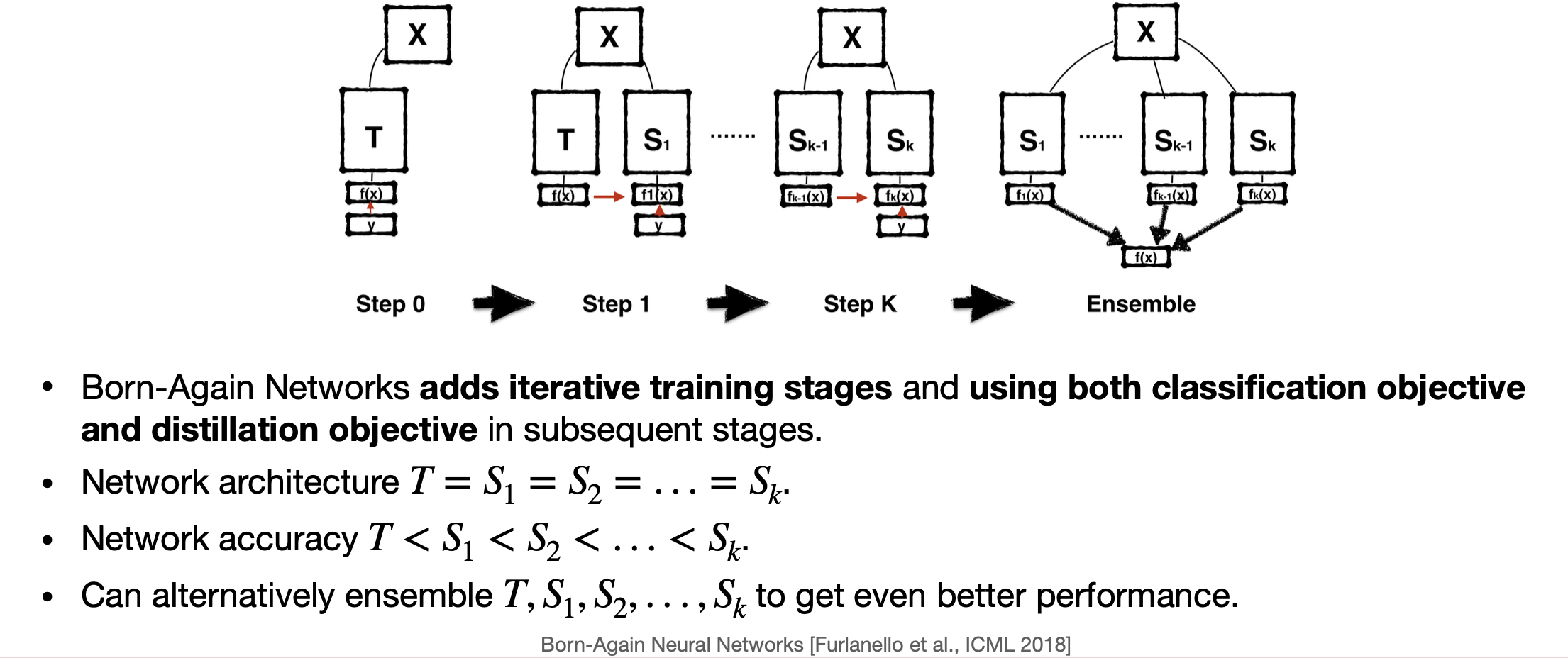
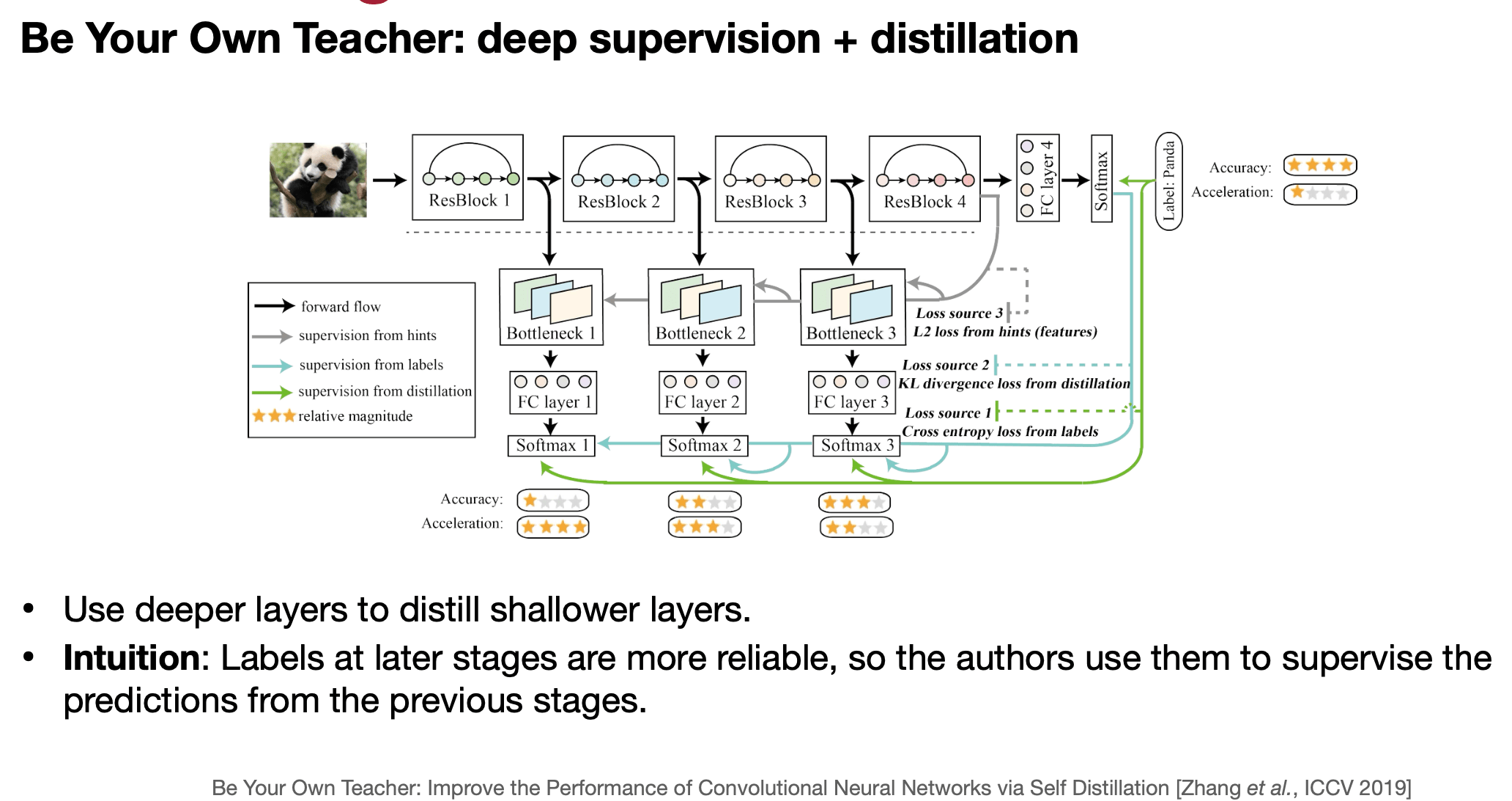
Self-distillation with Born-again NNs
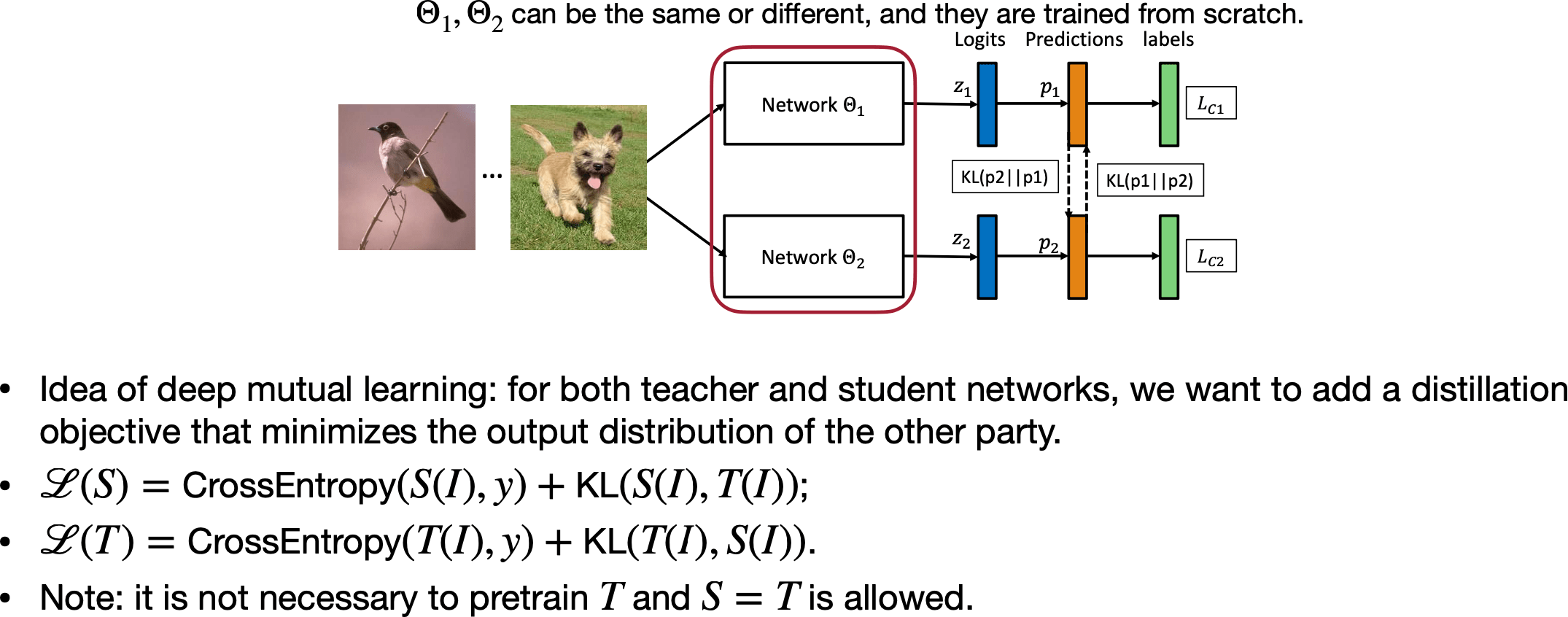
Deep Mutual learning
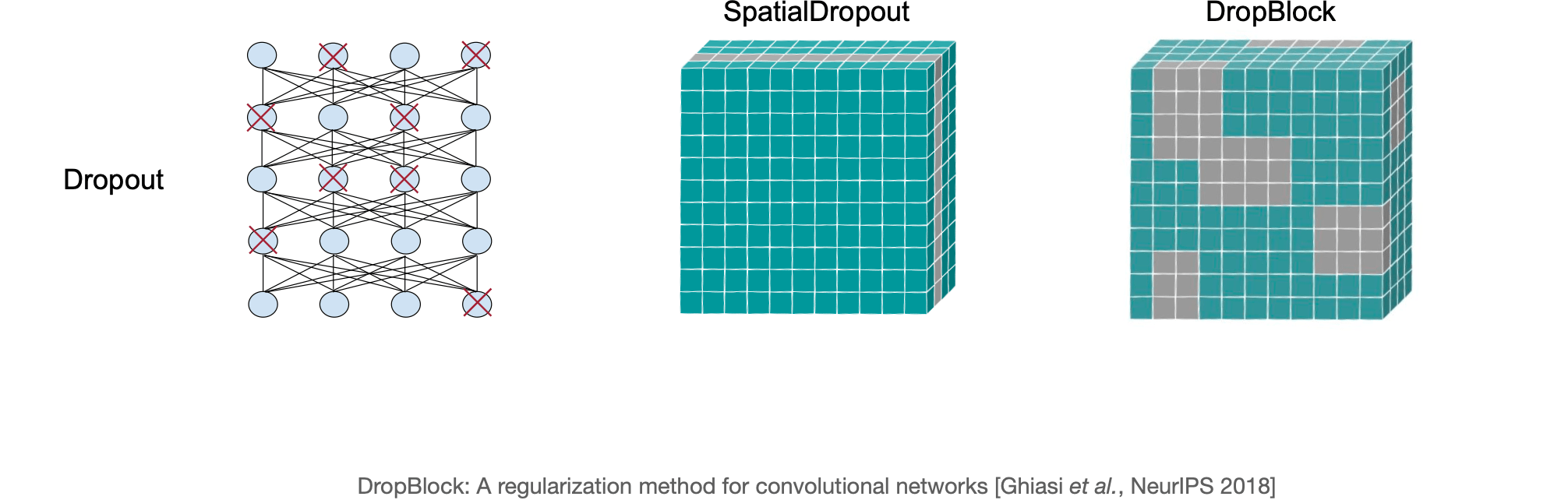
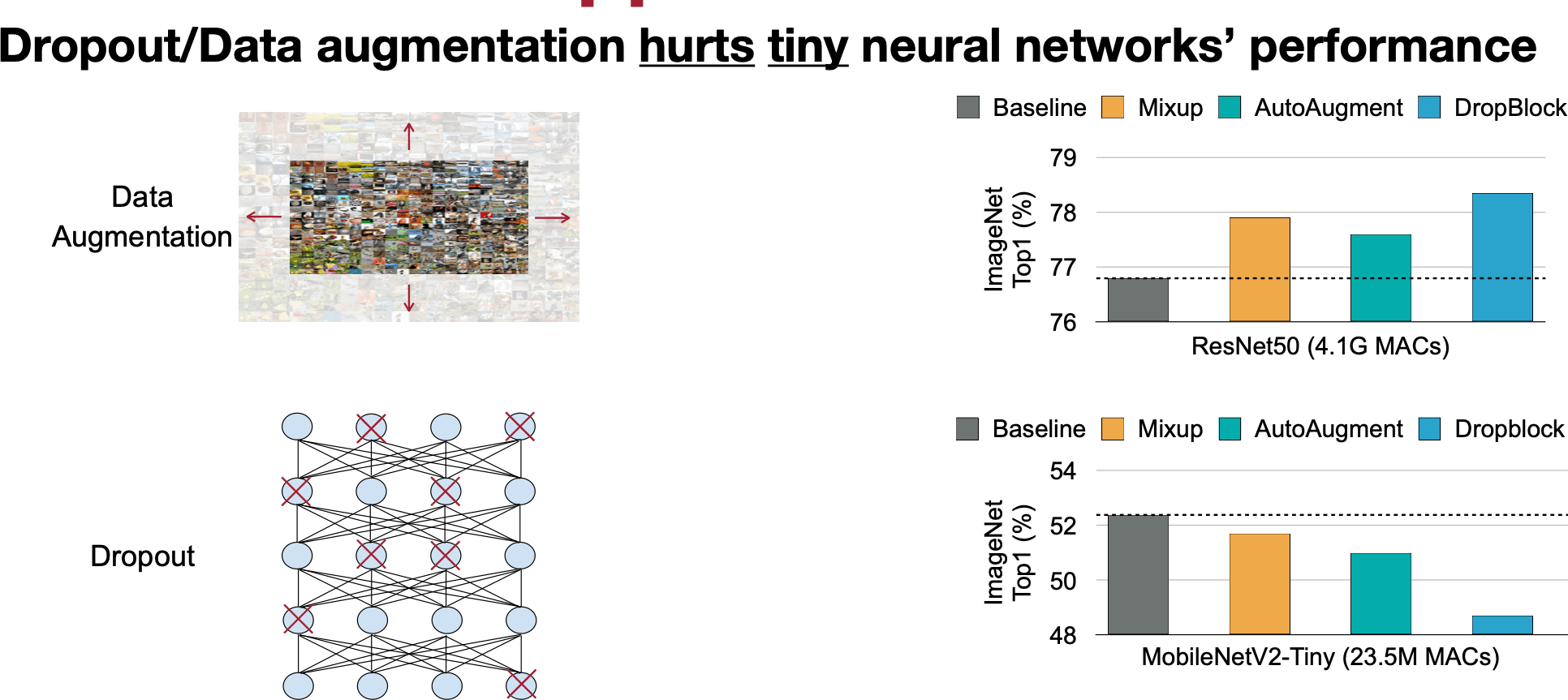
Data Augmentation

AutoAugment: Learning Augmentation Policies from Data [Cubuk et al., CVPR 2019]
Prompt tuning
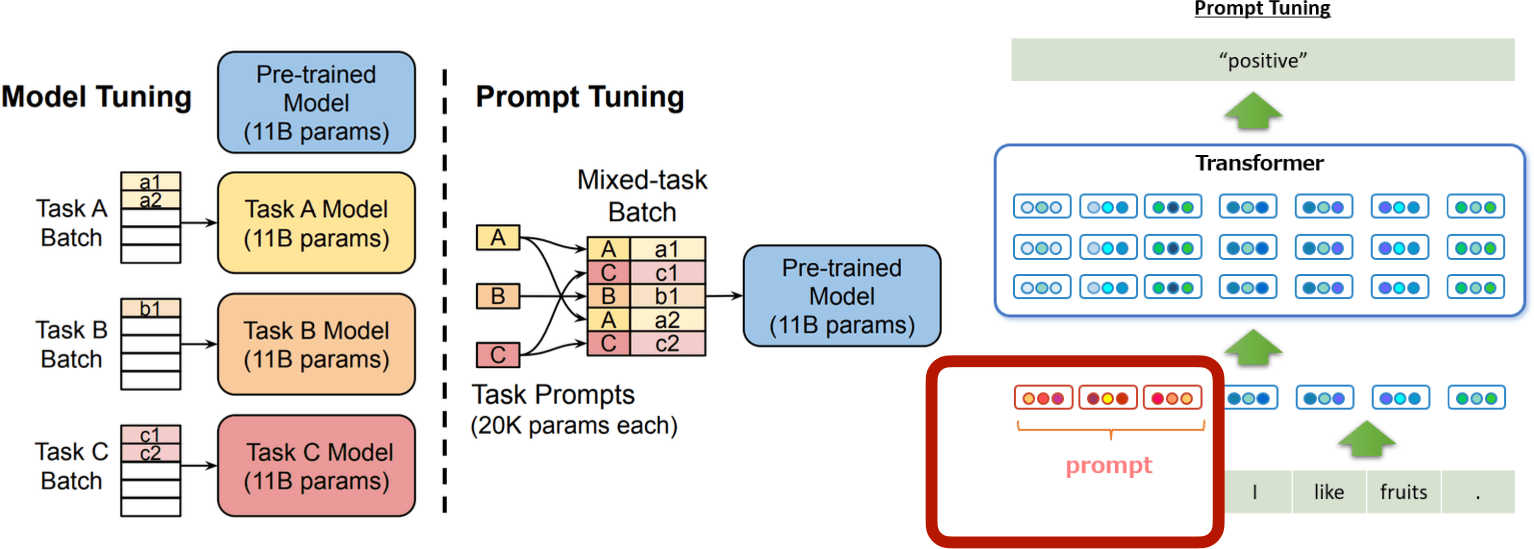
[The Power of Scale for Parameter-Efficient Prompt Tuning [Lester, ACL 2021]]
- Prompt engineering can help LLM work on different downstream applications
E.g., "Please tell me the sentiment of the following text: "
- We can train a continuous prompt that is prepended to inputs for each task
- We can mix different learned prompts in a single batch
- Comparable accuracy as fine-tuning as the model gets larger.
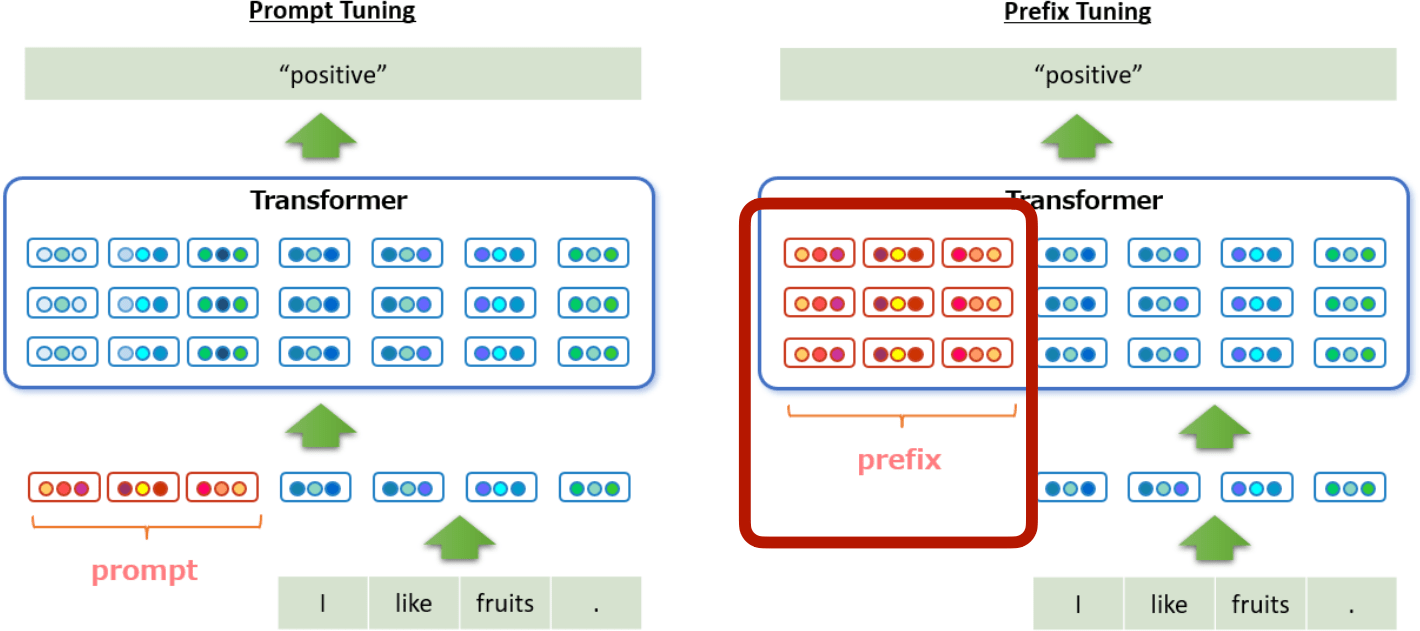
Prefix tuning
https://www.ogis-ri.co.jp/otc/hiroba/technical/similar-document-search/part28.html
Prefix-Tuning: Optimizing Continuous Prompts for Generation [Li et al, ACL 2021]
Prepend prefixes for each input.
Prompt-Tuning only adds learnable prompts to the first layer.
Prefix-Tuning adds tunable prompts to each layer.
Disadvantage of Prompt or Prefix tuning
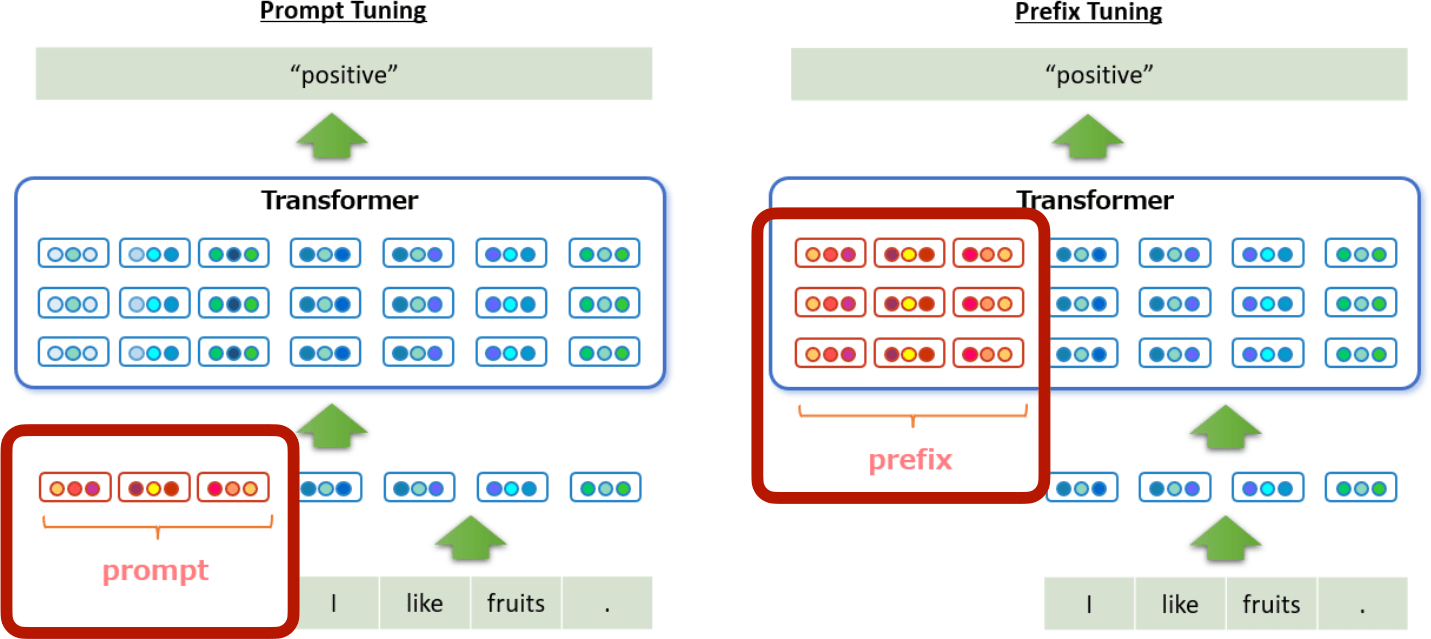
Both methods increase input length
- Lead to longer inference latency.
- Take up available input length and limit the real usable sequence.
LoRA
LoRA: Low-Rank Adaptation of Large Language Models [Hu et al, ICLR 2022]
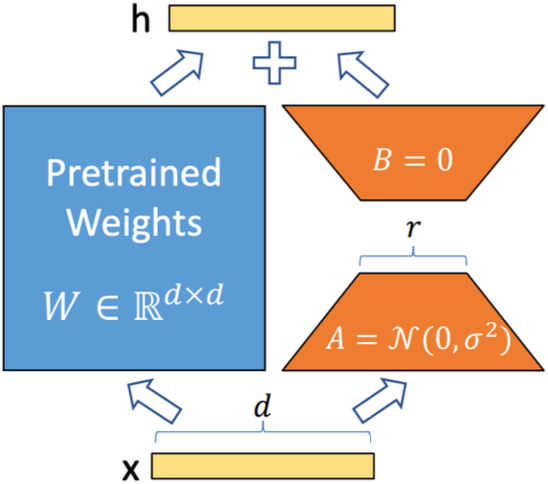
- Inject trainable rank decomposition matrices into each layer (as a parallel branch).
- The LoRA module have two parts:
- A: projects \(d\) dim to low-rank \(r\) dim, initialized with gaussian distribution.
- B: projects low-rank \(r\) dim back to \(d\) dim, initialized 0 s.
- \(r\) is the hyperparamter, easy to sweep.
- The output is
\(h=x @ W+x @ A @ B=x @(W+A @ B)=x @ W^{\prime}\)
Thus no extra inference latency!



https://civitai.com/models/119229?modelVersionId=169740
Prompt engineering:

Few-shot prompting
Finetuned Language Models Are Zero-Shot Learners [Wei et al, ICLR 2020]
Emergent Abilities of Large Language Models [ Wei et al, TMLR 2022]
- By providing few examples, the LLMs can perform a new task even it is not trained on it.
- This is also called in-context learning where we provide demonstrations in the prompt to steer the model to better performance.
Prompt engineering:
Chain-of-thought prompting
Finetuned Language Models Are Zero-Shot Learners [Wei et al, ICLR 2020]
Emergent Abilities of Large Language Models [ Wei et al, TMLR 2022]
- aims to enable complex reasoning capabilities through intermediate reasoning steps
- Such prompting can be generalized to few-shot scenarios by simplify adding the magic phrase "Let's think step by step"

Prompt engineering:
Progressively adding new prompts
Model: SDXL-1.0



Experiments were conducted on GPT-3.
They are fixed with RAG now!
LLMs cannot remember all "facts" in their parameters


LLMs cannot be easily retrained to give up-to-date answers
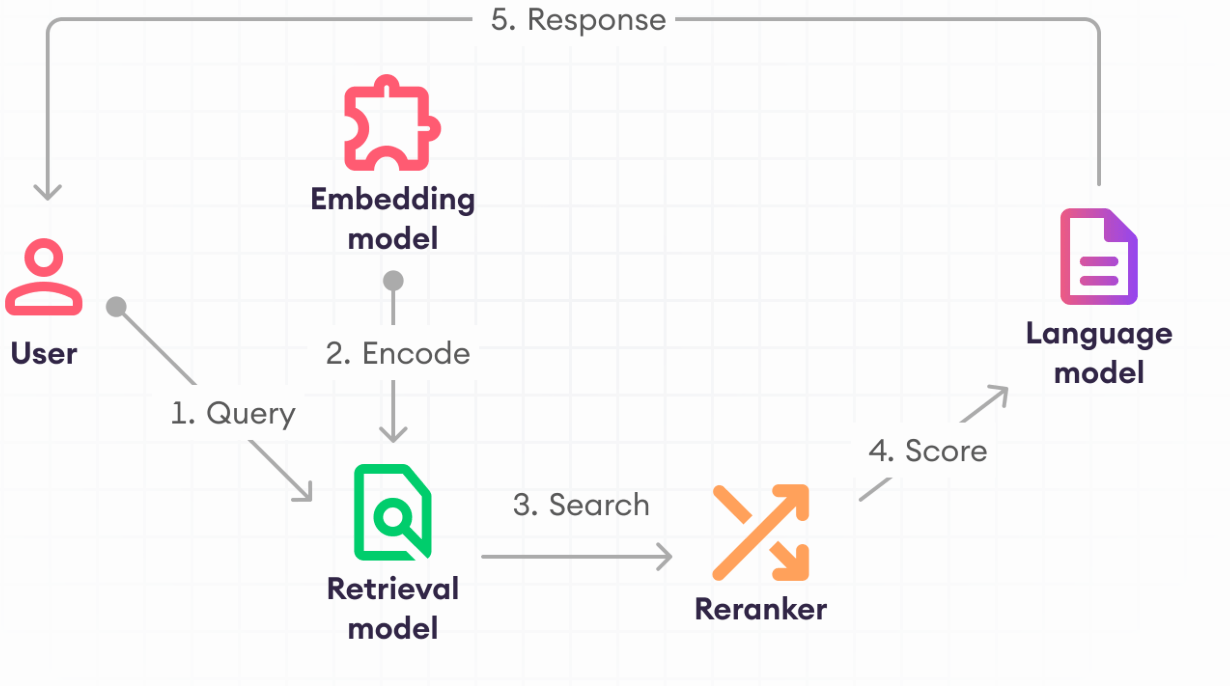
Retrieval Augmented Generation (RAG)
Image: https://ai.stanford.edu/blog/retrieval-based-NLP/
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks [Lewis et al, NeurIPS 2020]
Retrieval-based Language Models and Applications [Asai et al, ACL 2023 Tutorial]
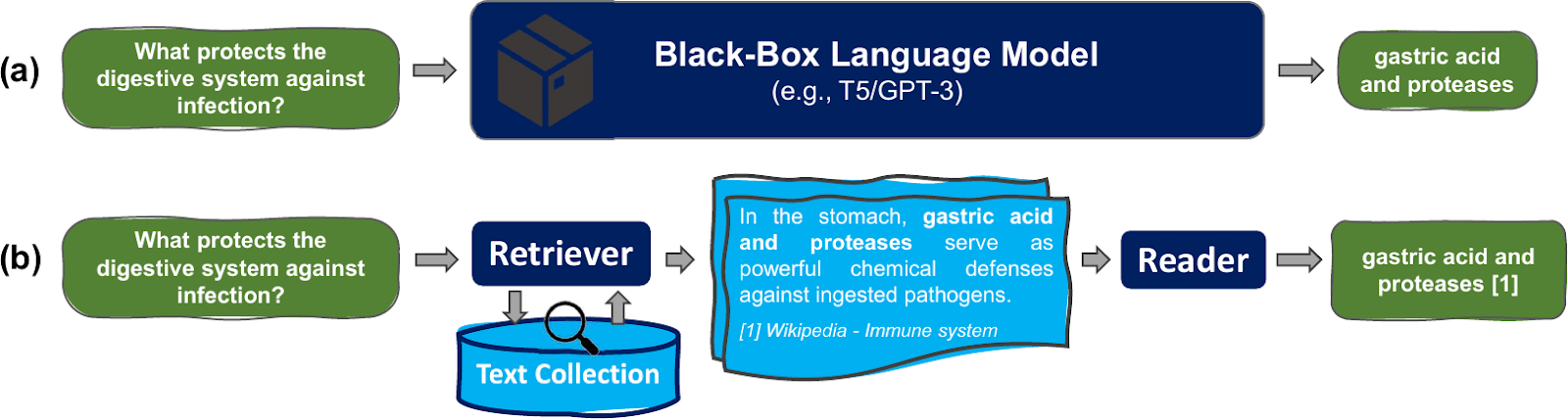
- Accurate information
- Recourse efficiency
- Knowledge efficiency
Image:https://www.superannotate.com/blog/rag-explained
Draft model / Speculative decoding
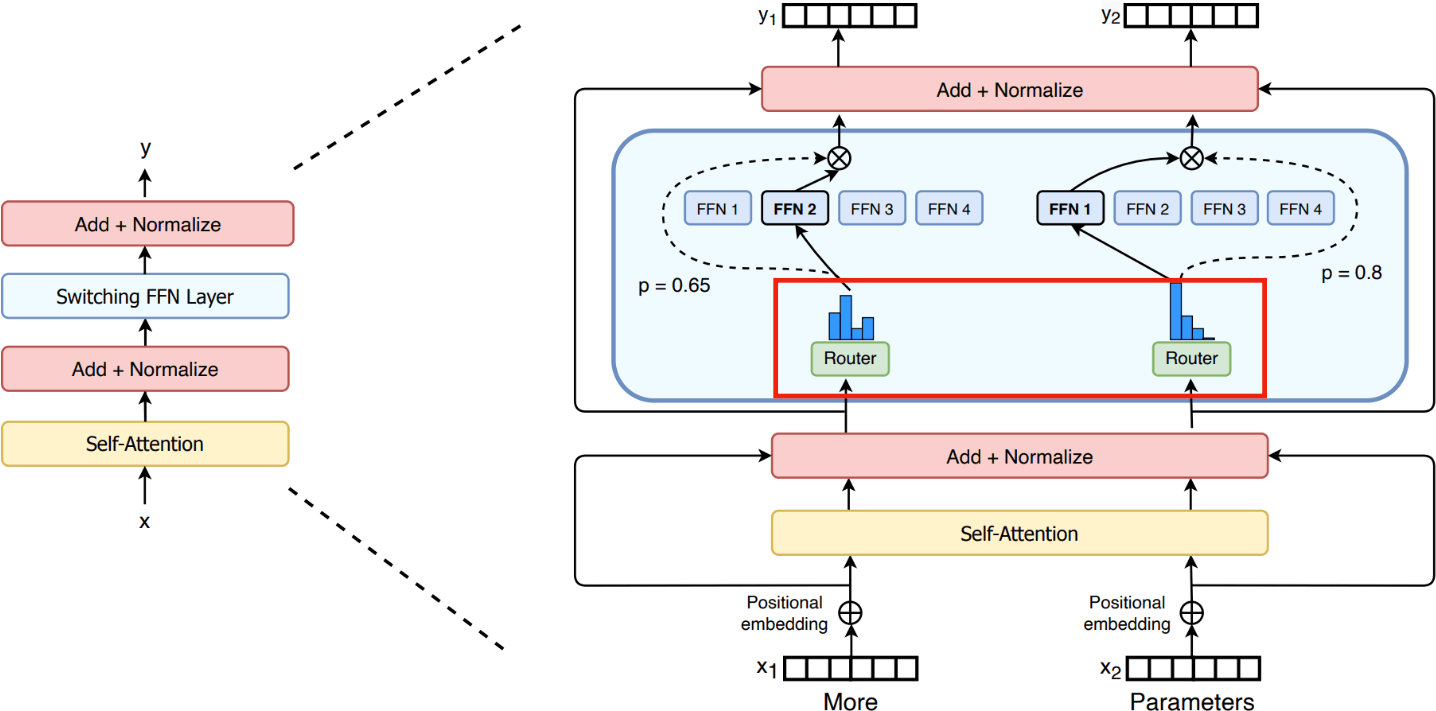
Mixture of experts (MoE)
- MoE allows us to sparsely use part of the parameters for each token during inference
- It can increase the total amount of parameters without increasing inference costs per token
- A router will distribute the workload among different experts
Mixture of experts (MoE)
- MoE allows us to use only part of the parameters for each token during inference
- It can increase the total amount of parameters without increasing inference costs per token
- A router will distribute the workload among different experts
- More experts -> larger total model size -> lower loss/better perplexity
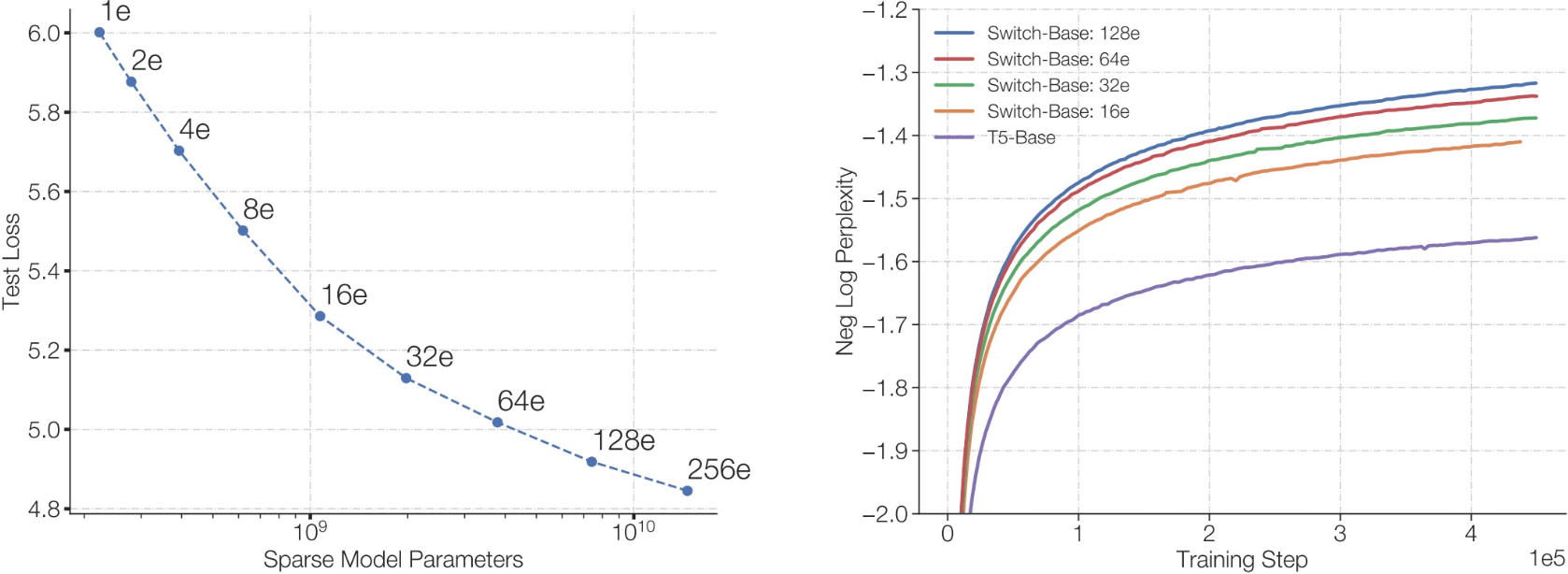
Foundation models scaling up
Improved designs after the initial transformer paper
• Most designs from the initial Transformer paper have been widely used by the community
• Nonetheless, people proposed various alternative designs. For example:
• Encoder-decoder (T5), encoder-only (BERT), decoder-only (GPT)
• Absolute positional encoding -> Relative positional encoding
• KV cache optimizations:
• Multi-Head Attention (MHA) -> Multi-Query Attention (MQA) -> Grouped-Query Attention (GQA)
• FFN -> GLU (gated linear unit)
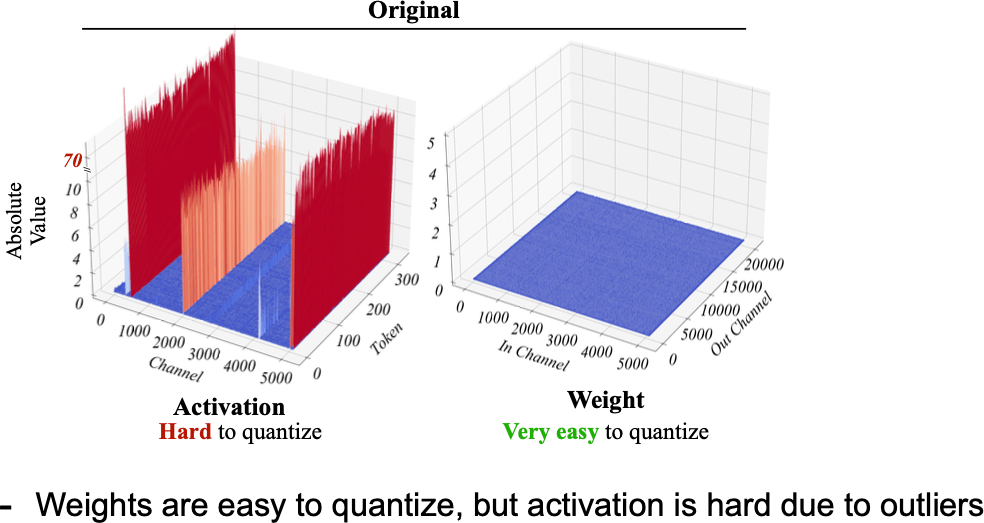
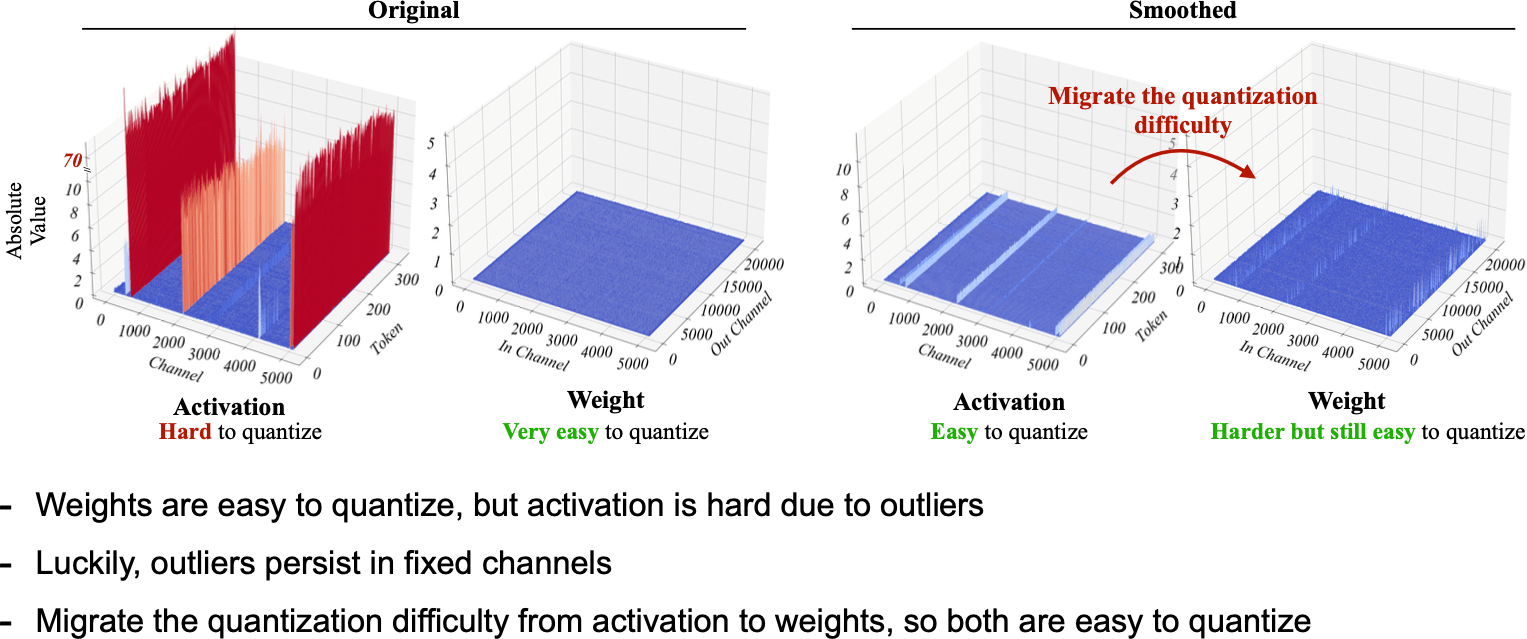
Activation Smoothing
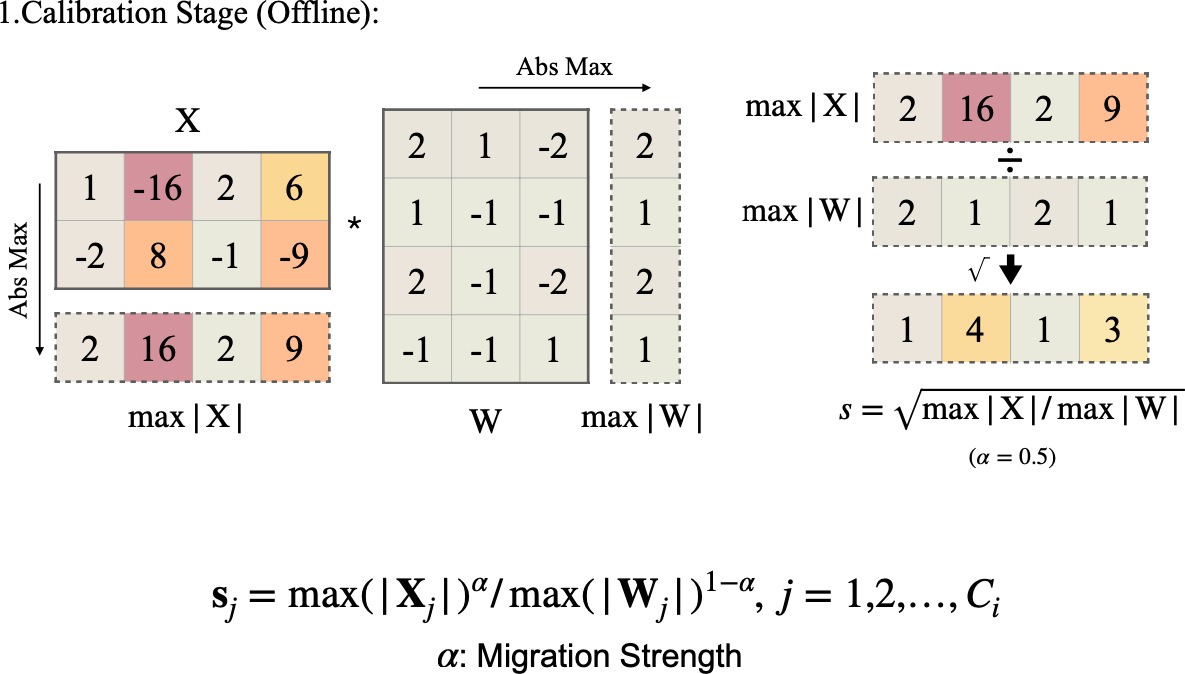
Thanks!
We'd love to hear your thoughts.