圖像辨識的神經網路
陳信嘉
文字識別
數字圖像處理與識別
物體識別
圖像識別發展的三個階段
ImageNet Challenge
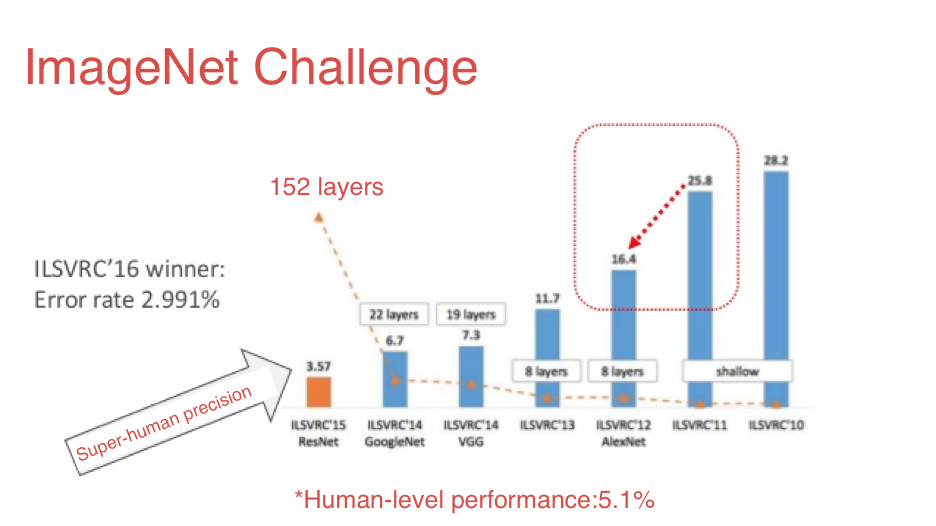
CNN 在圖像辨識競賽中超越人類表現
ImageNet Challenge 是電腦視覺的競賽,需要對影像進行 1000 個類別的預測,在 CNN 出現後首次有超越人類準確率的模型
Source: http://img.mp.itc.cn
2016 年 ILSVRC 的影象識別錯誤率已經達到約 2.9%,遠遠超越人類(5.1%)
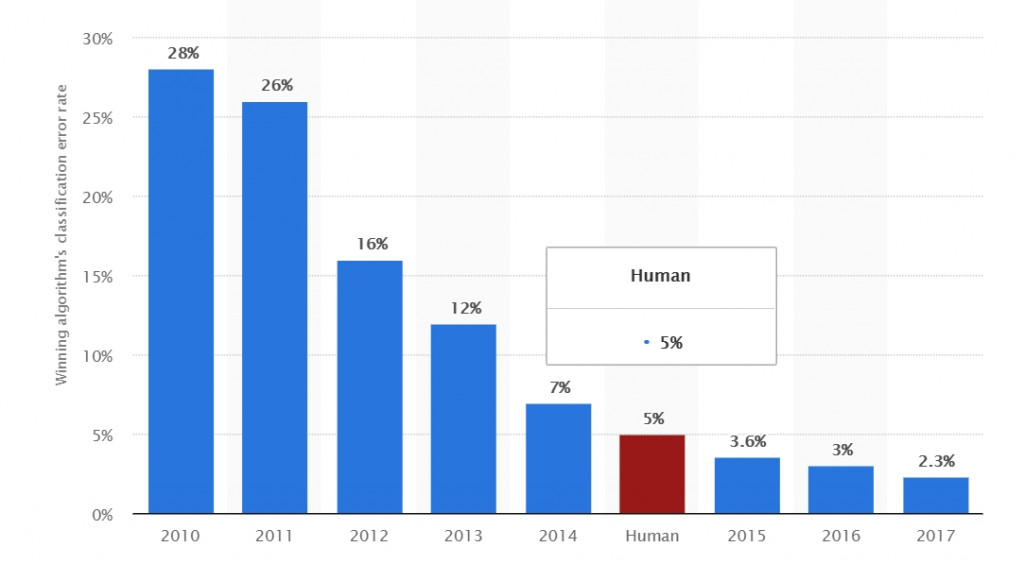
視覺辨識錯誤率
ImageNet Challenge
ImageNet 每年舉辦的競賽(ILSVRC)這幾年產生了不少的CNN冠軍,歷屆比賽的模型演進非常精彩,簡單敘述如下:
- 2012 年冠軍 AlexNet 錯誤率比前一年減少超過10%,且首度引用 Dropout 層。
- 2014 年亞軍 VGGNet 承襲 AlexNet 思路,建立更多層的模型,達到 16 及19 個隱藏層。
- 2014 年圖像分類冠軍 GoogNet & Inception 同時使用多種不同大小的 Kernel,讓系統決定最佳的 Kernel。Inception 引入 Batch Normalization 等觀念,參見 Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift。
- 2015 年冠軍 ResNets 發現 20 層以上的模型前面幾層會發生優化退化 (degradation) 的狀況,因而提出以『殘差』(Residual) 解決問題,參見Deep Residual Learning for Image Recognition。
ImageNet Challenge
ImageNet 大規模視覺識別挑戰賽 (ILSVRC) 評估用於大規模對象檢測和圖像分類的算法。一個高層次的動機是讓研究人員能夠比較更廣泛對象的檢測進展——利用相當昂貴的標記工作。另一個動機是衡量計算機視覺在用於檢索和註釋的大規模圖像索引方面的進展。
WebVision
WebVision
