MLflow for ML Lifecycle Management
Automatic animations between code
Dr. Srijith Rajamohan
MLflow for ML Experiment Management
Post-discovery experimentation
Discovery
Deployment

MLflow for ML Experiment Management
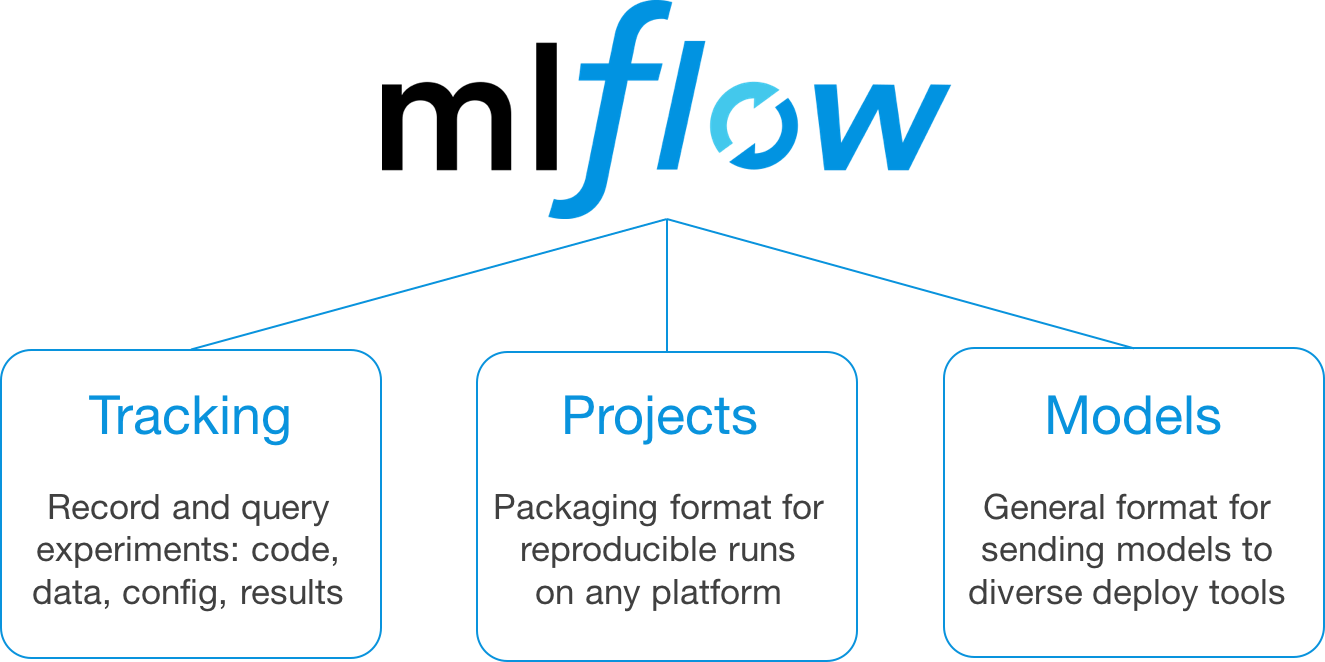
MLflow for ML Experiment Management
Model Registry
MLflow Tracking
- Organized into experiments, and runs within experiments
- Experiment runs save metrics, parameters, artifacts (output files, images etc.)
- Models can be saved and version controlled
- Models can also be saved in the Model registry
- Enables discovery and reuse across an organization
- Track model stages, i.e. staging -> production
- Use directly for inference
- ML code can be saved in MLProjects for reproducibility
MLflow
MLflow Storage
- Storage consists of two components
-
Backend store - Store experiment and run parameters, metrics, tags and other metadata
- File store
- Path can be ./path_to_store or file:/path_to_store
- Database store
- mysql, sqlite, postgresql etc.
- File store
-
Artifact store - Store by-products of a model run such as images, files etc.
- Stored in:
- Local file system
- S3,Azure blob storage, GCP, FTP, NFS, HDFS etc.
- Stored in:
-
Backend store - Store experiment and run parameters, metrics, tags and other metadata
- High-level and concise API
- Starting and managing MLflow runs, for e.g.
- Log parameters
- Log metrics
- Save models
- Emphasizes productivity
- E.g. autolog() enables autologging for supported libraries
The Fluent API
import mlflow
mlflow.start_run()
mlflow.log_param("my", "param")
mlflow.log_metric("score", 100)
mlflow.end_run()
with mlflow.start_run() as run:
mlflow.log_param("my", "param")
mlflow.log_metric("score", 100)- Low-level API
- CRUD interface that translates directly to the REST API
- Access run and experiment attributes such as metrics, parameters etc.
Tracking API
from mlflow.tracking import MlflowClient
# Create an experiment with a name that is unique and case sensitive.
client = MlflowClient()
experiment_id = client.create_experiment("Social NLP Experiments")
client.set_experiment_tag(experiment_id, "nlp.framework", "Spark NLP")
# Fetch experiment metadata information
experiment = client.get_experiment(experiment_id)
print("Name: {}".format(experiment.name))
print("Experiment_id: {}".format(experiment.experiment_id))
print("Artifact Location: {}".format(experiment.artifact_location))
print("Tags: {}".format(experiment.tags))
print("Lifecycle_stage: {}".format(experiment.lifecycle_stage))Fluent API
- Use this framework to:
- Minimize boilerplate code
- Manage a single run
Which one should I use?
Tracking API
- Use this framework to:
- Get access to all runs
- Have access to the full functionality of MLflow
Tracking Server
mlflow server \
--backend-store-uri sqlite:///mlflow.db \
--default-artifact-root PATH_TO_WORKING_FOLDER/artifacts \
--host 0.0.0.0
--port 5000Set up a tracking server to use
- The sqlite backend so that it can log models
- The default artifact to store artifacts locally
- Provide full path for the artifact store
- Provide the host address and optionally the port
MLflow Demo
Tracking UI
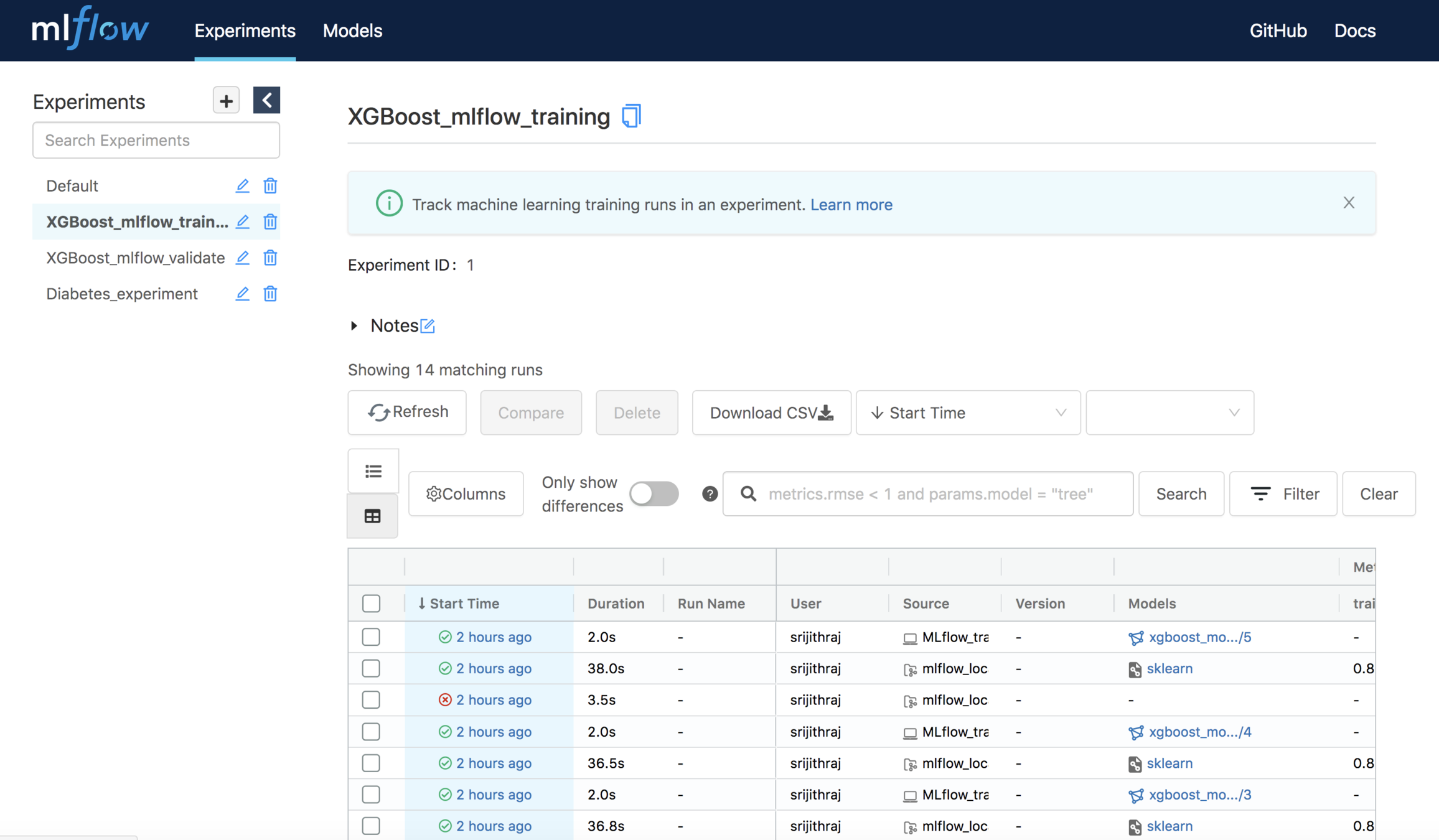
Tracking UI
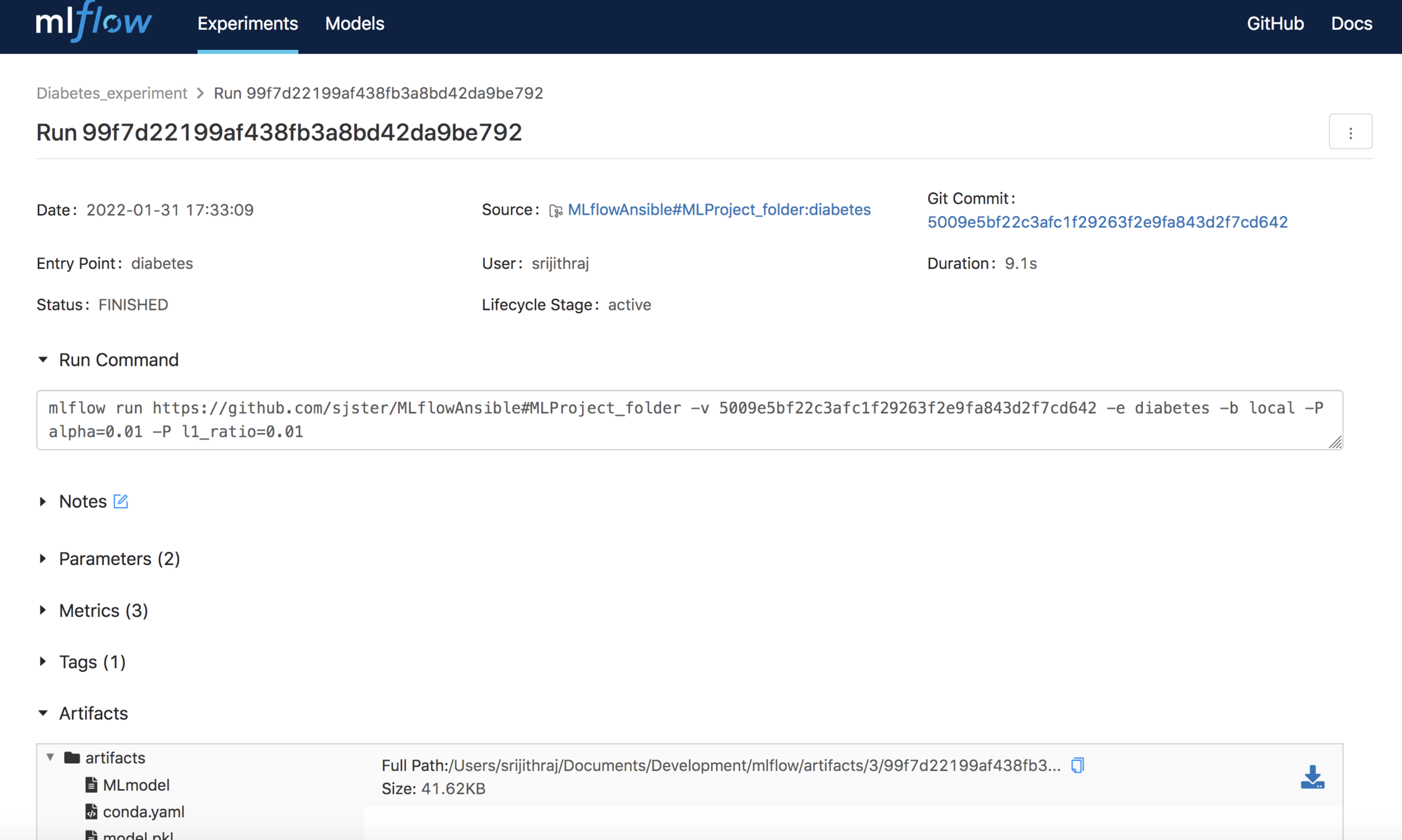
Tracking UI
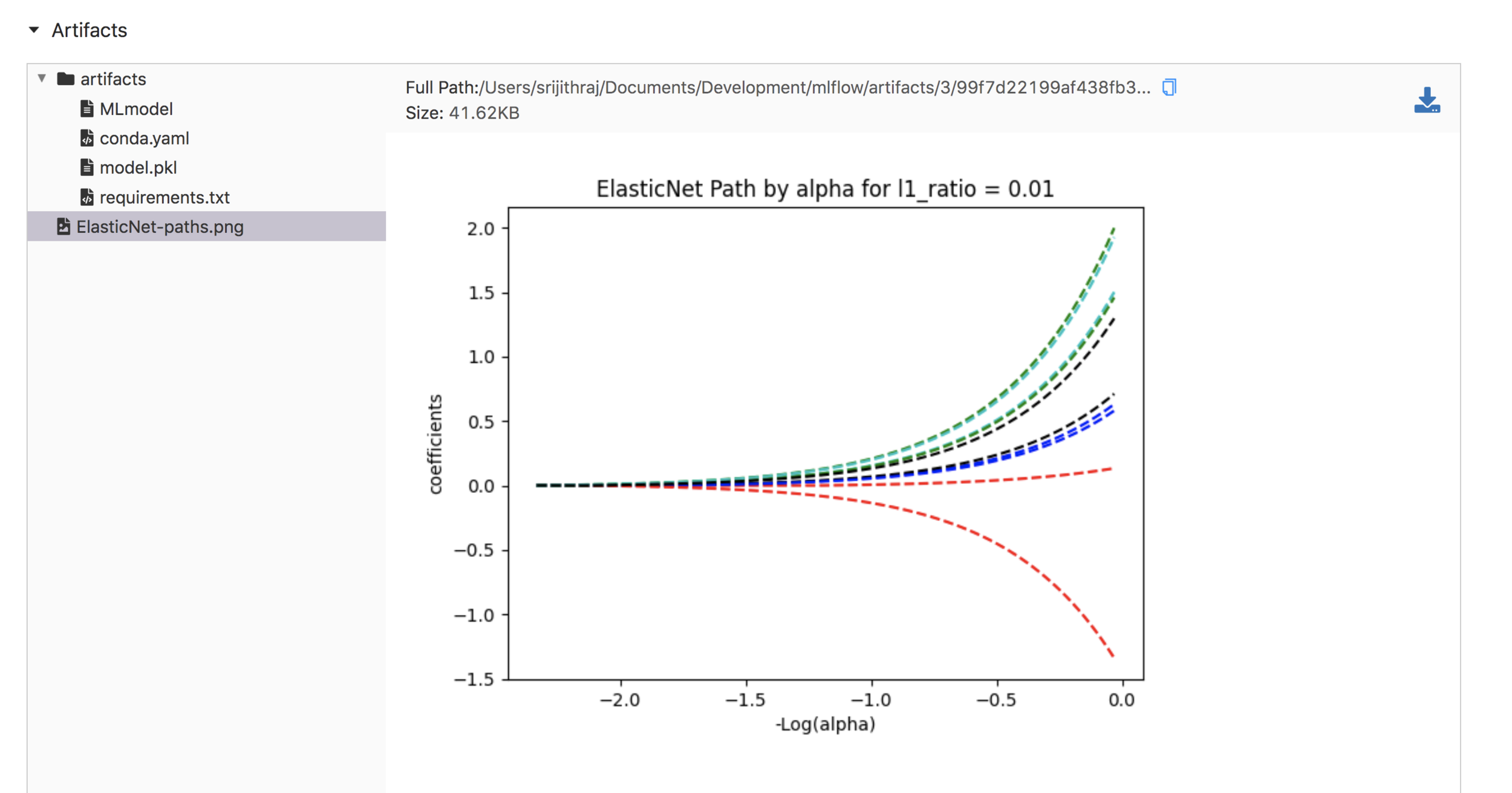
MLProject
- Enable reproducible research
- Format for packaging ML code (not models) that can reside in
- Local directories
- Git repositories
- MLProjects can be deployed and run
- Locally on a system
- Remotely on
- Amazon Sagemaker
- Databricks cluster
- Kubernetes (experimental)
MLflow Projects
MLflow Projects
$ (mlflow_demos) mlflow_project % ls
MLProject MLflow_training.py conda.yamlMLflow project structure is shown below
- MLProject file (YAML file) that indicates how to run the project
- ML code
-
Environment file
- Conda environment
- Docker
Call 'mlflow run' one level above this folder
MLProject file
name: My Project
conda_env: conda.yaml
# Can have a docker_env instead of a conda_env, e.g.
# docker_env:
# image: mlflow-docker-example
entry_points:
main:
parameters:
data_file: { type: string, default: "../data/WA_Fn-UseC_-Telco-Customer-Churn.csv" }
command: "python MLflow_training.py {data_file}"YAML file that contains the environment filename, entry point, commands (along with parameters)
MLflow Projects - Parameters
$ mlflow run mlflow_project - You can also leave out the parameters
- This will use the default parameters in the MLProject file
-
The data type can be
- string
- float
- path
- uri
Note that I used string instead of path as the data type in the example, so that I can use relative paths
MLflow Projects - Running a project
$ mlflow run mlflow_project -P data_file=../data/WA_Fn-UseC_-Telco-Customer-Churn.csv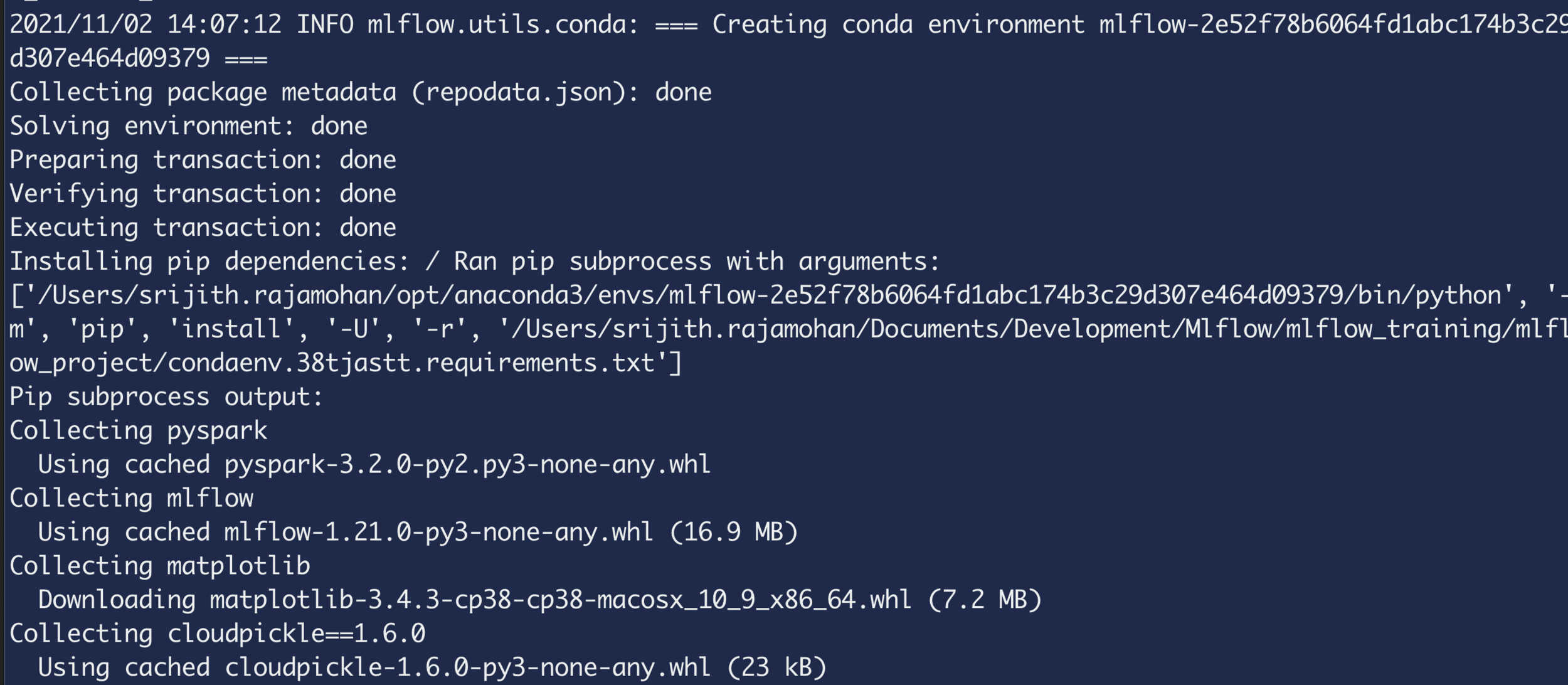
MLflow Projects - Running a project
$ mlflow run mlflow_project -P data_file=data/WA_Fn-UseC_-Telco-Customer-Churn.csv
MLflow Projects from Git
$ mlflow run https://github.com/sjster/MLflowAnsible#MLProject_folder
-P data_file=data/WA_Fn-UseC_-Telco-Customer-Churn.csvMLflow Projects - Additional entrypoints
name: My Project
conda_env: conda.yaml
entry_points:
main:
parameters:
data_file: { type: string, default: "../data/WA_Fn-UseC_-Telco-Customer-Churn.csv" }
command: "python MLflow_training.py {data_file}"
validate:
parameters:
X_val: { type: string, default: "../data/X_val.csv" }
y_val: { type: string, default: "../data/y_val.csv" }
command: "python MLflow_validate.py {X_val} {y_val}"mlflow run mlflow_project -e validate -P X_val=../data/X_val.csv -P y_val=../data/y_val.csvTracking Server - Run a Project
To run the MLproject with this tracking server, append the MLFLOW_TRACKING_URI before calling 'mlflow run'
MLFLOW_TRACKING_URI=http://0.0.0.0:5000 mlflow run mlflow_project \
--experiment-name="XGBoost_mlflow_validate" \
-e validate -P X_val=../data/X_val.csv -P y_val=../data/y_val.csvMLflow Models
- MLflows models are a way for packaging models for reuse
- Real-time inference using REST APIs
- Batch inference with Apache Spark/other supported frameworks
- Models are saved in different flavors
- Supported frameworks ->
- Python flavor to run the model as a Python function
- Scikit-learn flavor can load the model as a Pipeline object
- Supported frameworks ->
MLflow Models

Model Directory
mlflow_training % ls mlflow_project/my_local_model/
MLmodel conda.yaml model.pkl requirements.txt
mlflow_training % cat mlflow_project/my_local_model/MLmodel
flavors:
python_function:
env: conda.yaml
loader_module: mlflow.sklearn
model_path: model.pkl
python_version: 3.8.10
sklearn:
pickled_model: model.pkl
serialization_format: cloudpickle
sklearn_version: 0.24.1
utc_time_created: '2021-11-02 19:48:30.135900'Save and Load Models
mlflow.sklearn.save_model(model, "my_local_model")
my_model_reload = mlflow.sklearn.load_model('my_local_model')
mlflow.sklearn.eval_and_log_metrics(my_model_reload, X_val, y_val, prefix="val_")
Out[27]: {'val_precision_score': 0.7968969091728362,
'val_recall_score': 0.805170239596469,
'val_f1_score': 0.799325453841428,
'val_accuracy_score': 0.805170239596469,
'val_log_loss': 0.406791751504339,
'val_roc_auc_score': 0.8524996656137788,
'val_score': 0.805170239596469}Logged Models
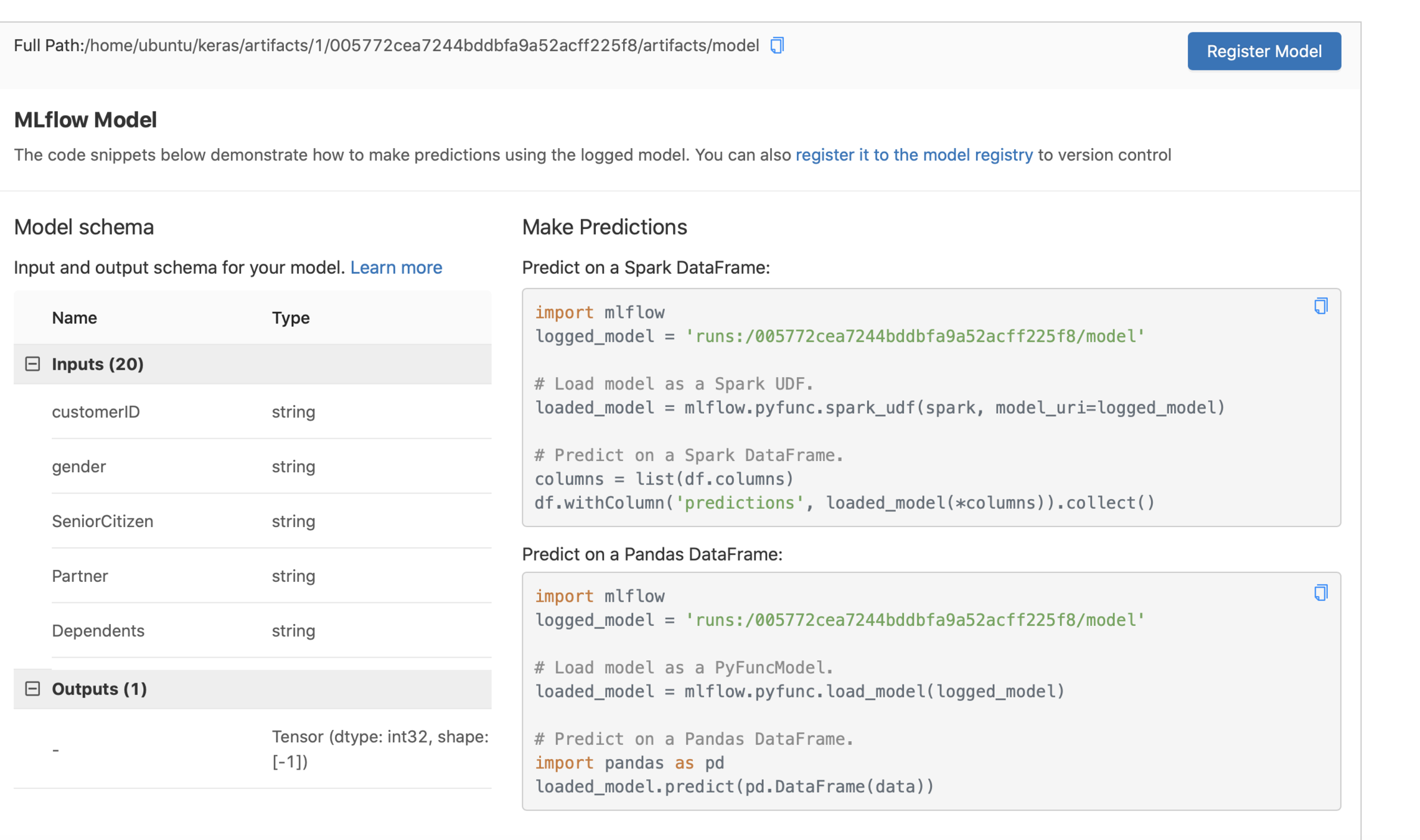
Using a Logged Model
logged_model = 'runs:/314035cfab2245d5ad266b84751dff8a/model'
model_loaded = mlflow.sklearn.load_model(logged_model)
mlflow.sklearn.eval_and_log_metrics(model_loaded, X_val, y_val, prefix="val_")
Out[27]: {'val_precision_score': 0.7968969091728362,
'val_recall_score': 0.805170239596469,
'val_f1_score': 0.799325453841428,
'val_accuracy_score': 0.805170239596469,
'val_log_loss': 0.406791751504339,
'val_roc_auc_score': 0.8524996656137788,
'val_score': 0.805170239596469}- Load the logged model from a run
- Note that we use mlflow.sklearn.load_model instead of mlflow.pyfunc.load_model
Text
Saved vs. Logged Models
- Saved models
- Download/copy/share the model folder
- Reusability and portability
- Logged models
- Use this when you want to reuse a model from a previous run
Register a Model in the Model Registry
- In addition to being logged, the model can be registered to the model registry
- Enables discoverability and reusability
mlflow.sklearn.log_model(lr,
artifact_path="artifacts",
registered_model_name="lr")# Get this id from the UI
result=mlflow.register_model('runs:/314035cfab2245d5ad266b84751dff8a/model', "XGBoost_sr")Can also register the model from a run
Registered Models
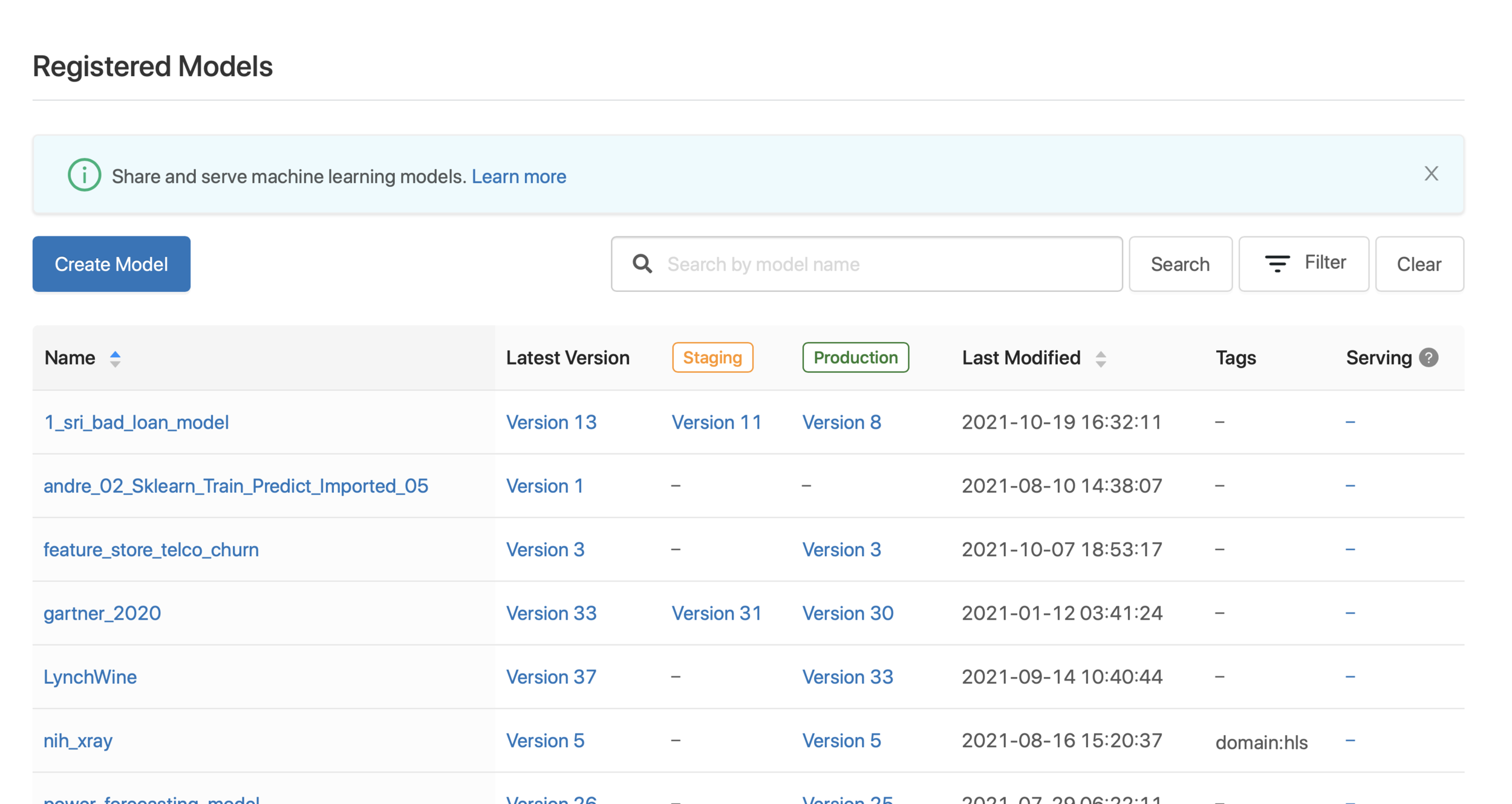
Inspecting the Registered Model
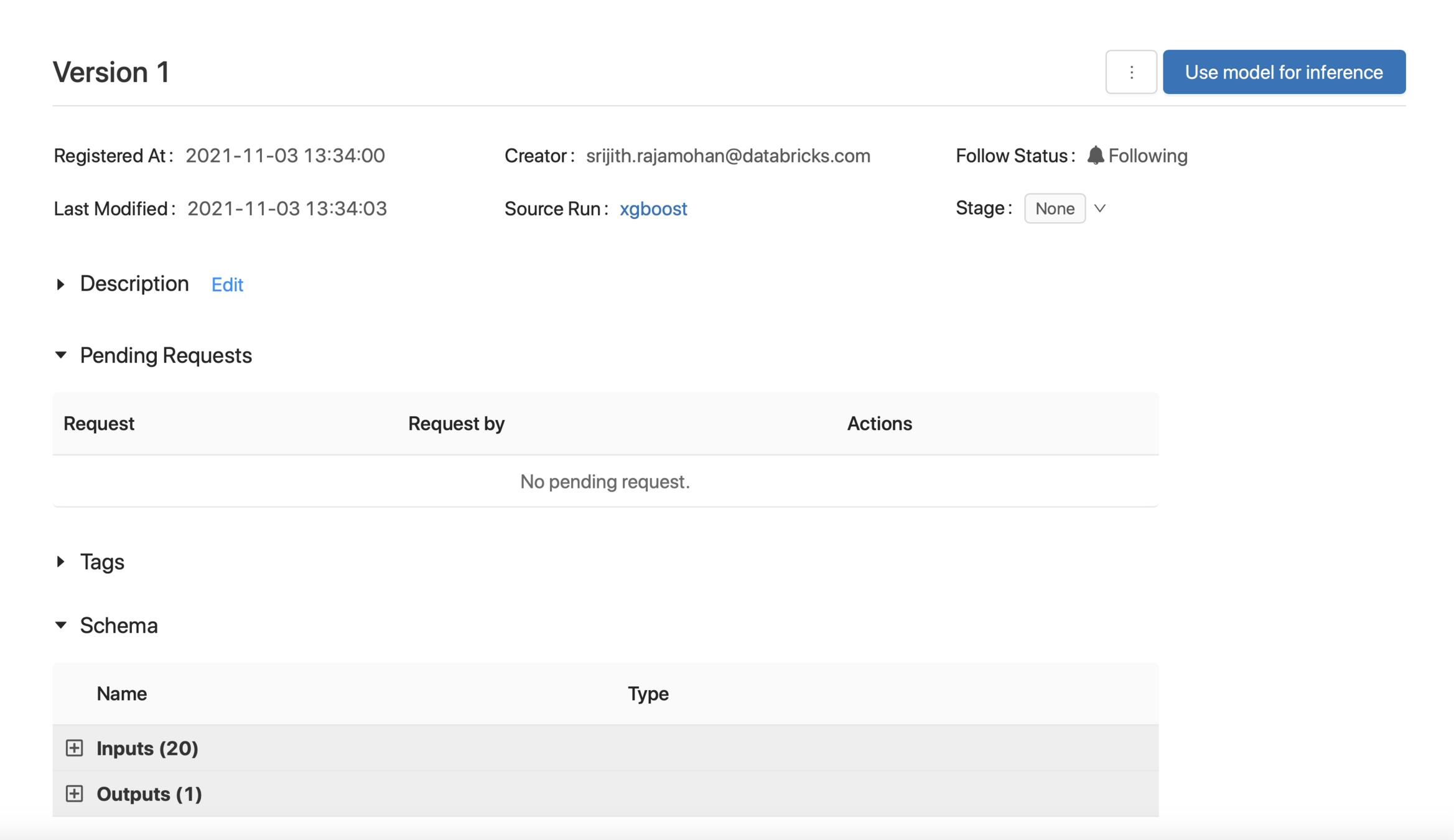
Stage the model
Use the Registered Model
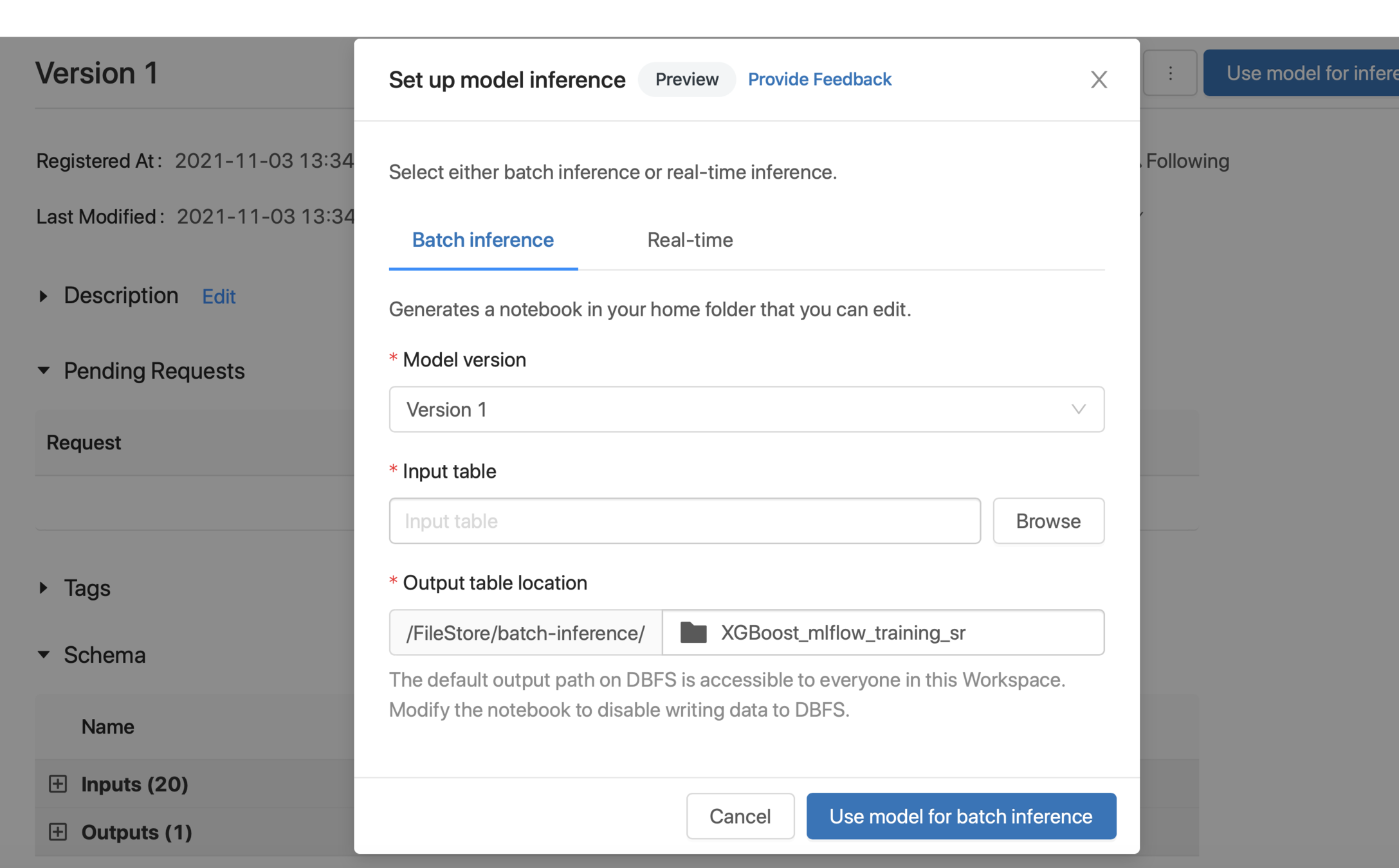
Use the Registered Model
# Get this id from the UI
result=mlflow.register_model('runs:/314035cfab2245d5ad266b84751dff8a/model', "XGBoost_sr")
model_loaded_from_registry = mlflow.sklearn.load_model(
model_uri=f"models:/XGBoost_sr/1"
)
mlflow.sklearn.eval_and_log_metrics(model_loaded_from_registry, X_val, y_val, prefix="val_")
Out[31]: {'val_precision_score': 0.7968969091728362,
'val_recall_score': 0.805170239596469,
'val_f1_score': 0.799325453841428,
'val_accuracy_score': 0.805170239596469,
'val_log_loss': 0.406791751504339,
'val_roc_auc_score': 0.8524996656137788,
'val_score': 0.805170239596469}Serve the Model
mlflow models serve -m my_local_model
2021/11/03 17:09:03 INFO mlflow.models.cli: Selected backend for flavor 'python_function'
2021/11/03 17:09:04 INFO mlflow.utils.conda: === Creating conda environment mlflow-a95404aa2487b42dc9f39755daafc1fe62e52876 ===
Collecting package metadata (repodata.json): ...working... done
Solving environment: ...working... done
...
...
2021/11/03 17:10:24 INFO mlflow.pyfunc.backend: === Running command 'source /databricks/conda/bin/../etc/profile.d/conda.sh && conda activate mlflow-a95404aa2487b42dc9f39755daafc1fe62e52876 1>&2 && gunicorn --timeout=60 -b 127.0.0.1:5000 -w 1 ${GUNICORN_CMD_ARGS} -- mlflow.pyfunc.scoring_server.wsgi:app'
[2021-11-03 17:10:24 +0000] [23870] [INFO] Starting gunicorn 20.1.0
[2021-11-03 17:10:24 +0000] [23870] [INFO] Listening at: http://127.0.0.1:5000 (23870)
[2021-11-03 17:10:24 +0000] [23870] [INFO] Using worker: sync
[2021-11-03 17:10:24 +0000] [23877] [INFO] Booting worker with pid: 23877
Serve the Model - Requests
curl http://127.0.0.1:5000/invocations -H 'Content-Type: application/json; format=pandas-records' -d '[
{"customerID": "8232-CTLKO", "gender": "Female", "SeniorCitizen": 0,
"Partner": "Yes",
"Dependents": "Yes",
"tenure": 66,
"PhoneService": "Yes",
"MultipleLines": "No",
"InternetService": "DSL",
"OnlineSecurity": "Yes",
"OnlineBackup": "No",
"DeviceProtection": "No",
"TechSupport": "No",
"StreamingTV": "Yes",
"StreamingMovies": "No",
"Contract": "Two year",
"PaperlessBilling": "Yes",
"PaymentMethod": "Electronic check",
"MonthlyCharges": 59.75,
"TotalCharges": 3996.8}
]'Thank you
Questions?