Scalability & Delivery
COMP63301 Data Engineering Concepts
Stian Soiland-Reyes


This work is licensed under a
Creative Commons Attribution 4.0 International License.
Intended Learning Outcomes
- Understand scaling challenges of batch-based data processing
- Explain how cloud computing is used in data processing
- Describe fundamentals of streaming data processing
- Recognise how streaming may impact data reliability and concurrency
- Relate choice of processing architecture to transformation queries and serving

Scaling beyond
batch jobs
Data generation
🛒📲
Ingestion
🧺
👩🏻💻🛠️
Transformation
Serving
🍲🥘🍛
Analytics
👨🏻💻📈📊
Traditional data
processing use batch computing and relational databases
- Centralised approach lends itself to a monolithic architecture
- Reduced technology choice simplifies maintenance and debugging
- Databases are well understood, any SQL tooling can be plugged in
- Batch jobs with transactions are reliable
- Re-executable when requirements change
Database
⛃
Database
Database
⛃
Database
⛃
"Stakeholders"
👩🏻🦰👱🏻♀️👨🏻💼
👧🏽👦🏻👧🏾
Consumers and users
🧑🏾💼💰🤵🏼♂️
Data generation
🛒📲
Ingestion
🧺
👩🏻💻🛠️
Transformation
Serving
🍲🥘🍛
Analytics
👨🏻💻📈📊
Traditional data
processing use batch computing and relational databases
- Monoliths react slowly to change
⟶ release cycles, separate test systems - Danger of single point of failure
⟶ redundant systems, monitoring - Challenging to scale
⟶ bigger machines! (Vertical scaling) - Processing can be slow
.. just wait till next batch job!
Database
⛃
Database
Database
⛃
Database
⛃
"Stakeholders"
👩🏻🦰👱🏻♀️👨🏻💼
👧🏽👦🏻👧🏾
Consumers and users
🧑🏾💼💰🤵🏼♂️
Data generation
🛒📲
Ingestion
🧺
Serving
🍲🥘🍛
Analytics
👨🏻💻📈📊
“Embarrassingly
parallel”
Database
⛃
Database
Database
⛃
👩🏻🦰👱🏻♀️👨🏻💼
👧🏽👦🏻👧🏾
🧑🏾💼💰🤵🏼♂️
👩🏻💻🛠️
Transformation
Serving
🍲🥘🍛
More production lines
Can we scale up by processing each "file" separately and in parallel?
Database
⛃
Database
⛃
Database
⛃
Database
⛃
How did we ever manage before cloud? Case: Scaling Web servers in 2002


/home/a
/web

www.ntnu.no
webmail.ntnu.no
SAN
Storage Area Network


/home/b
Infrastructure as a Service


vm5241
16 GB
vm5719
16 GB
vm6532
32 GB
host8121
machine images
machine images
machine images
www.example.com
Public IP
15.197.159.59
IaAS APIs
dataset
results
dataset
dataset
dataset
dataset
dataset
Horizontal scaling
Splitting tasks for cloud computing, 2002 style!
ingest1.example.com
ingest2
transform1
transform2
transform3
transform4
aggregate1
aggregate2
aggregate3
serve1
db.example.com
- Use redundancy support where available
- Estimate how many tasks fit in a virtual machine
- Set up and manage cloud nodes
- Assign tasks to cloud nodes
Below is a clear, structured overview of the most typical cloud services across AWS, Azure, Google Cloud (GCP), and other major cloud providers. They are grouped into common cloud service categories, with the closest equivalents placed side-by-side for easy comparison.
🌩️ 1. Compute Services
| Virtual Machines (IaaS) | EC2 | Virtual Machines | Compute Engine | Oracle OCI Compute, IBM Cloud Virtual Servers |
| Autoscaling | Auto Scaling | VM Scale Sets | Instance Groups | All major providers have autoscaling variants |
| Serverless Functions | Lambda | Azure Functions | Cloud Functions | Cloudflare Workers, IBM Cloud Functions |
| Container Orchestration (Managed Kubernetes) | EKS | AKS | GKE | IBM Cloud Kubernetes Service, Oracle OKE |
| Container Execution / Serverless Containers | Fargate | Container Apps | Cloud Run | Cloudflare Workers, DigitalOcean App Platform |
| Bare Metal | EC2 Bare Metal | Azure BareMetal | Bare Metal Solution | IBM Bare Metal Servers, OCI Bare Metal |
📦 2. Storage Services
| Object Storage | S3 | Blob Storage | Cloud Storage | DigitalOcean Spaces, Backblaze B2 |
| Block Storage | EBS | Managed Disks | Persistent Disks | OCI Block Storage |
| File Storage (NFS/SMB) | EFS, FSx | Azure Files | Filestore | IBM File Storage |
| Archival Storage | Glacier | Archive Storage | Coldline/Archive | Backblaze B2, Wasabi |
🗄️ 3. Database Services
| Managed Relational DBs | RDS (MySQL, PostgreSQL, etc.) | Azure SQL, PostgreSQL/MySQL Flexible Server | Cloud SQL | Oracle Autonomous DB, IBM Db2 |
| Cloud-Native Distributed SQL | Aurora | Azure Cosmos DB (multi-model) | Spanner | CockroachCloud |
| NoSQL Key-Value / Document | DynamoDB | Cosmos DB | Firestore, Cloud Bigtable | MongoDB Atlas |
| Data Warehousing | Redshift | Azure Synapse Analytics | BigQuery | Snowflake (cloud-agnostic) |
| In-Memory Caches | ElastiCache | Azure Cache for Redis | Memorystore | Redis Enterprise Cloud |
🔌 4. Networking Services
| Virtual Networks | VPC | Virtual Network | VPC | OCI Virtual Cloud Network |
| Load Balancers | ALB, NLB, CLB | Azure Load Balancer, App Gateway | Cloud Load Balancing | F5 Cloud, HAProxy Cloud |
| CDN | CloudFront | Azure CDN | Cloud CDN | Cloudflare, Akamai |
| DNS | Route 53 | Azure DNS | Cloud DNS | Cloudflare DNS |
| VPN / Direct Connect | Site-to-Site VPN, Direct Connect | VPN Gateway, ExpressRoute | Cloud VPN, Interconnect | Oracle FastConnect |
🧠 5. AI & Machine Learning
| ML Platforms | SageMaker | Azure Machine Learning | Vertex AI | IBM Watson Studio |
| Generative AI APIs | Bedrock | Azure OpenAI | Gemini | Anthropic, OpenAI APIs |
| Vision / Speech APIs | Rekognition, Polly | Cognitive Services | Cloud Vision, Speech-to-Text | Clarifai |
| Conversational AI | Lex | Bot Service | Dialogflow | Rasa (cloud-hosted) |
🛠️ 6. Developer / Application Services
| CI/CD | CodePipeline, CodeBuild | Azure DevOps, GitHub Actions (Microsoft) | Cloud Build | GitLab CI, CircleCI |
| API Gateways | API Gateway | API Management | API Gateway | Kong Cloud, Apigee |
| Event Bus / Messaging | EventBridge, SNS, SQS | Event Grid, Service Bus | Pub/Sub | RabbitMQ Cloud, Kafka Confluent Cloud |
🔐 7. Security & Identity
| Identity & Access | IAM | Azure AD / Entra ID | Cloud IAM | Okta |
| Secrets Management | Secrets Manager | Key Vault | Secret Manager | HashiCorp Vault |
| Key Management | KMS | Key Vault | Cloud KMS | Thales CipherTrust |
📊 8. Monitoring, Logging & Observability
| Metrics & Monitoring | CloudWatch | Azure Monitor | Cloud Monitoring | Datadog, New Relic |
| Logging | CloudWatch Logs | Azure Log Analytics | Cloud Logging | Splunk, ELK Stack |
| Trace & APM | X-Ray | Application Insights | Cloud Trace | Datadog APM |
🏗️ 9. DevOps & Infrastructure Management
| Infrastructure as Code | CloudFormation | ARM/Bicep | Deployment Manager | Terraform (all clouds) |
| Config Management | Systems Manager | Automation | Config Connector | Puppet, Ansible, Chef |
| Container Registry | ECR | ACR | Artifact Registry | Docker Hub, GitHub Container Registry |
💼 10. Enterprise & Business Applications
| Directory Services | Directory Service | Active Directory Domain Services | Managed AD | IBM Cloud Directory |
| ERP / SaaS Platforms | — | Dynamics 365 | — | Salesforce, SAP Cloud |
Can you list and categorise the most typical cloud services used from AWS, Azure, GCP, and other cloud computing providers?
dataset
results
dataset
dataset
dataset
dataset
dataset
scalability
Handle parallelization:
- execute for tens to thousands of datasets
- efficiently use any computing platform
automation
Workflow systems can scale batch executions

vm5241
16 GB
vm6532
32 GB
Scheduling containerized jobs to virtualized worker nodes via cloud batch APIs




Queued jobs
Dependent jobs
Container images
https://www.ibm.com/history/time-sharing

IBM VM/CMS 1972
Scheduling batch jobs to virtual machines via mainframe APIs
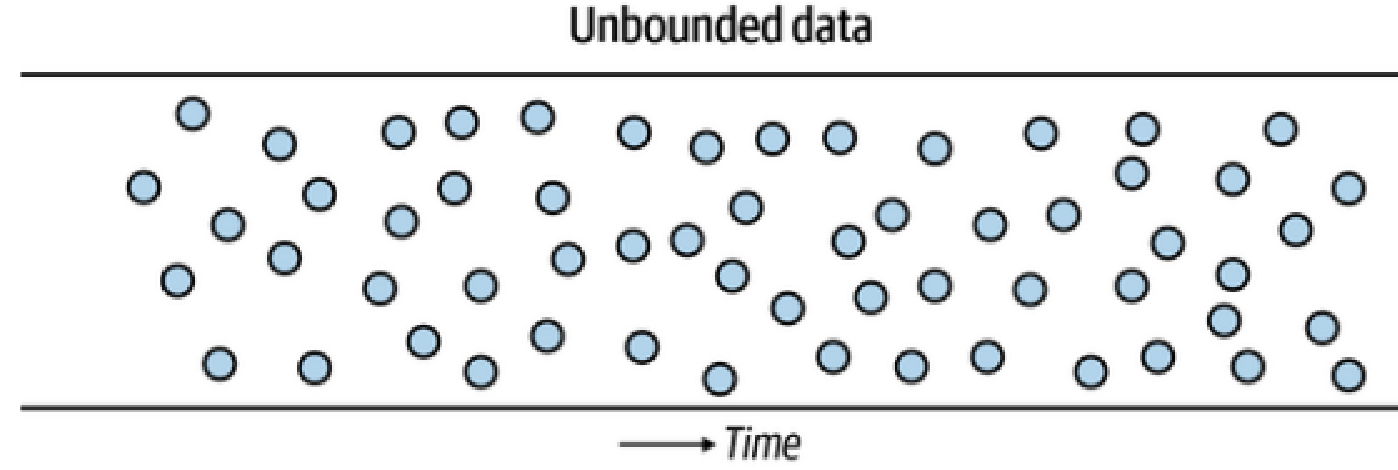
Bounded and unbounded data
Adopted from Figure 7.3, Fundamentals of Data Engineering
Data sources are mostly unbounded, new items arrive semi-continuously to be ingested into a computer system
What kind of data items?
Sale transaction, temperature measurement, login attempt, ad view, parcel tracking, ...
Irregularity: Data will arrive depending on external factors, e.g. when customers chose to visit the store
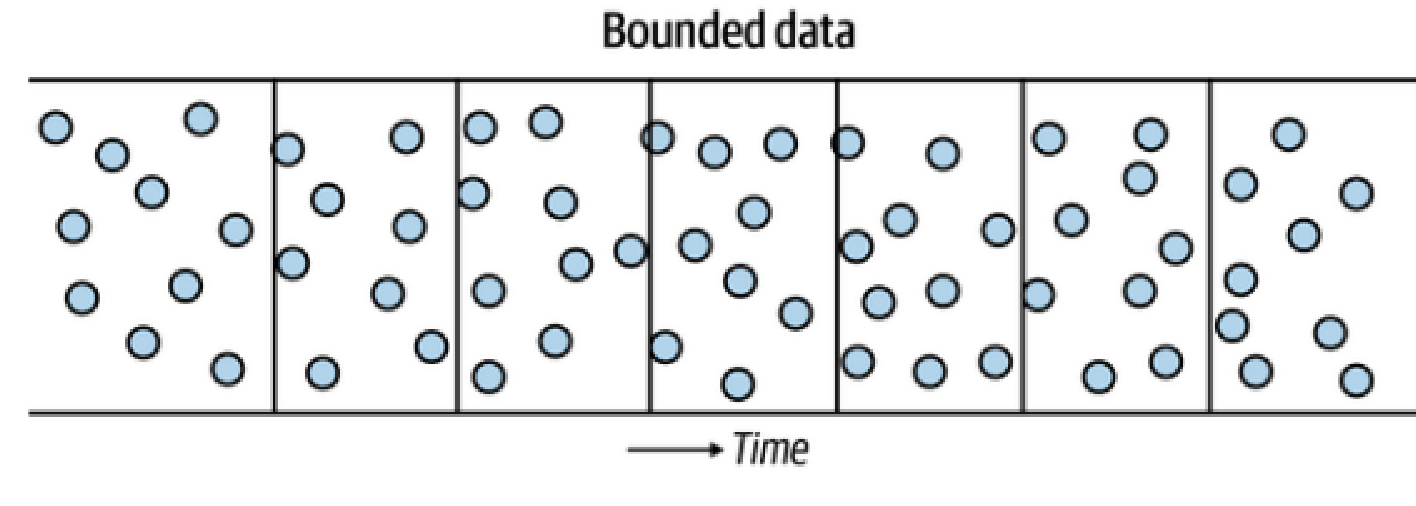
Adopted from Figure 7.3, Fundamentals of Data Engineering
Forming Bounded data allows processing in manageable chunks (batch processing)
by frequency: Weekly, daily, hourly, every 5 minutes
by volume: 100, 1000, 10k, 100k items
by size: kilobytes, megabytes, gigabytes
Streaming
Smaller batches, fresh produce
Streaming data reduces latency
Processing in micro-batches (e.g. 10 items) or real-time (e.g. 1 item) means data is integrated immediately for impacting business action
Cloud computing is needed to scale for varying data volumes (e.g. more processing nodes during "rush hour")

Message queues

Adopted from Figure 5.9, Fundamentals of Data Engineering
Asynchronous sending of messages
Publish–Subscribe model
Messages are buffered in queue, until processed by subscriber
Queue system can be distributed to have handle many concurrent producers and subscribers
Events &
topics
Adopted from Figure 5.10, Fundamentals of Data Engineering
Topic-based queues with multiple subscribers
Can dispatch to many sides e.g. analytics, operations

{
"Type": "Web Order",
"Key": "Order #12345",
"Value": "SKU 123, purchase price of $100",
"Timestamp": "2023-01-02 06:01:00"
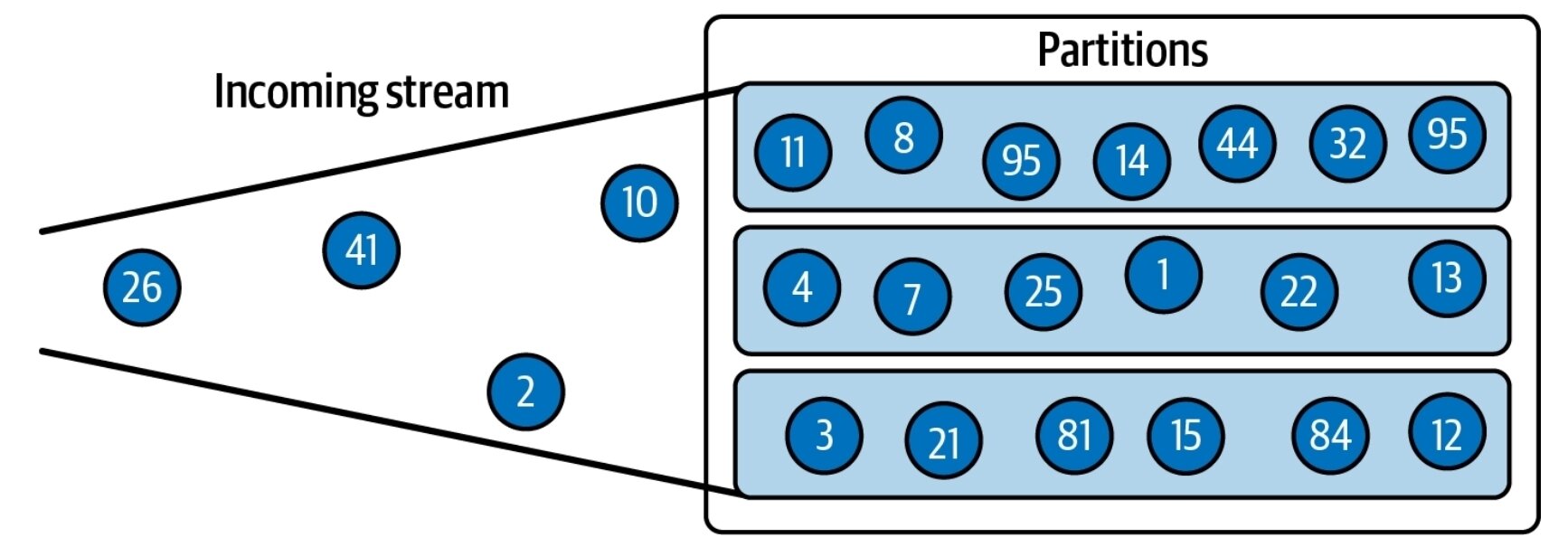
}Stream partitions
Adopted from Figure 5.11, Fundamentals of Data Engineering
Streams can be partitioned by the partition key of each event
e.g. using hashing or modulo: 11 mod 3 = 2
Simple way to divide the work across compute nodes
Map-reduce
Many data items (e.g. streaming)
Splitting into partitions
λ(
)=
λ(
)=
λ(
)=
λ(
)=
def λ(order):
return (order.amount *
order.item.price)Mapping
Shuffling
Reducing
Σ(
)=
Σ(
)=
def Σ(a,b):
return a+bΣ(
)=
Σ(
)=
Result
The map-reduce computational model splits work across distributed (cloud) nodes, each running the same algorithm for mapping across the data items, shuffled to reducing nodes that then combine (e.g. sum) to the final result.
Reliability challenges
Batch reliability
Scheduled batches may be delayed/missed by concurrent system load or connectivity issues (Don't run everything at 00:00!)
A batch may take too long to process, and block/conflict other batch jobs.
Errors may cause the rest of the batch to fail, but use of transactions can keep the databases in clean state
Batches are clearly defined and logged, and can be rerun if anything fails.
Streaming reliability
Streaming can dynamically scale (e.g. add more nodes) for increased compute loads.
Events are processed in near real-time, but may arrive out of order.
Queues are ephemeral, events may be lost if errors occur (e.g. cloud node unavailable)
Errors isolated to individual events or microbatches, but not as easily rolled back.
Harder to rerun (but Kappa architecture use a longer retention period to allow replay)
Streaming architecture choices
Impact from architecture choice
- Kappa architecture serves all data as if it was streamed, any relational databases are treated like a streaming source, some of their relational nature is lost.
Figure 3.4, 3.5 from Fundamentals of Data Engineering
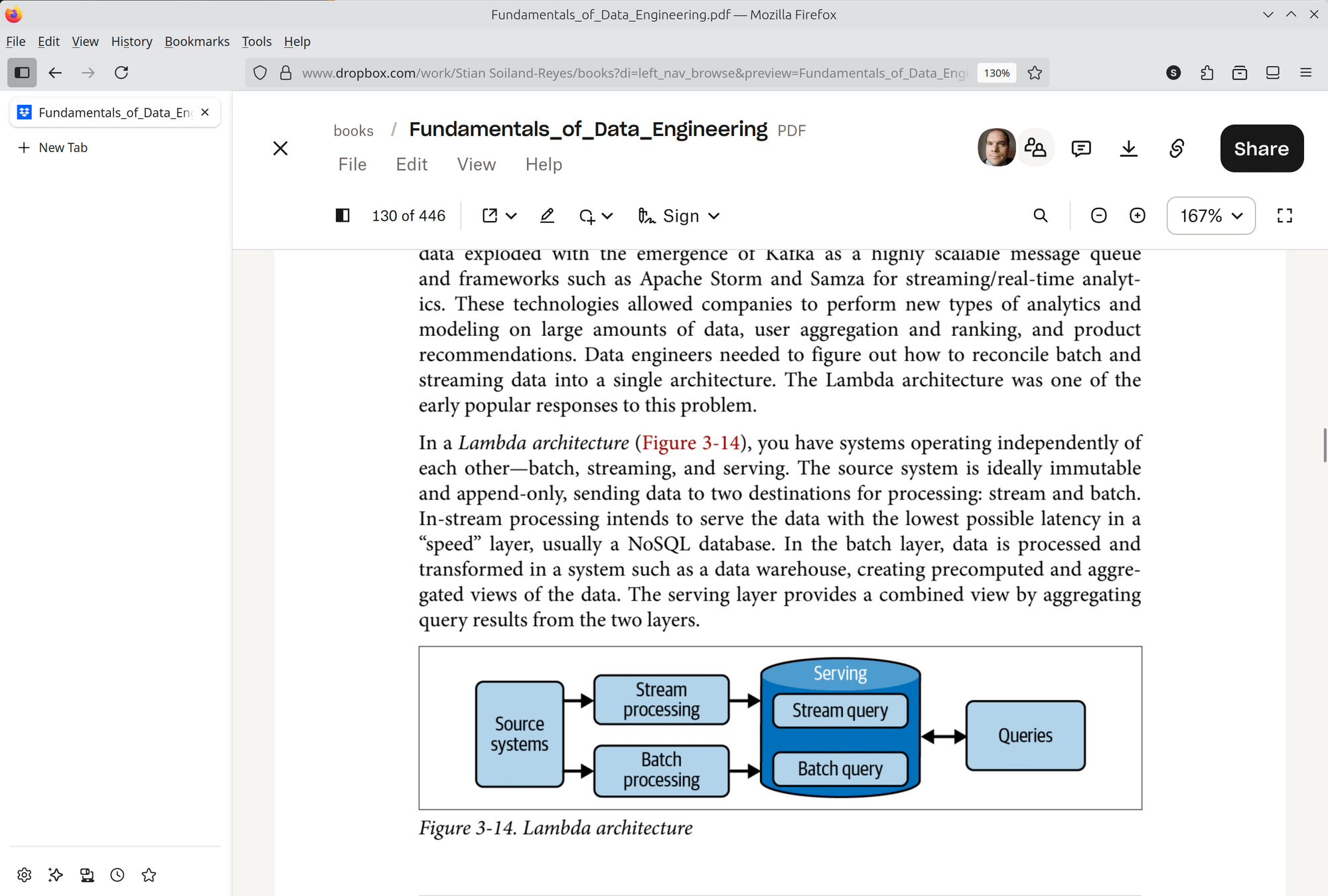
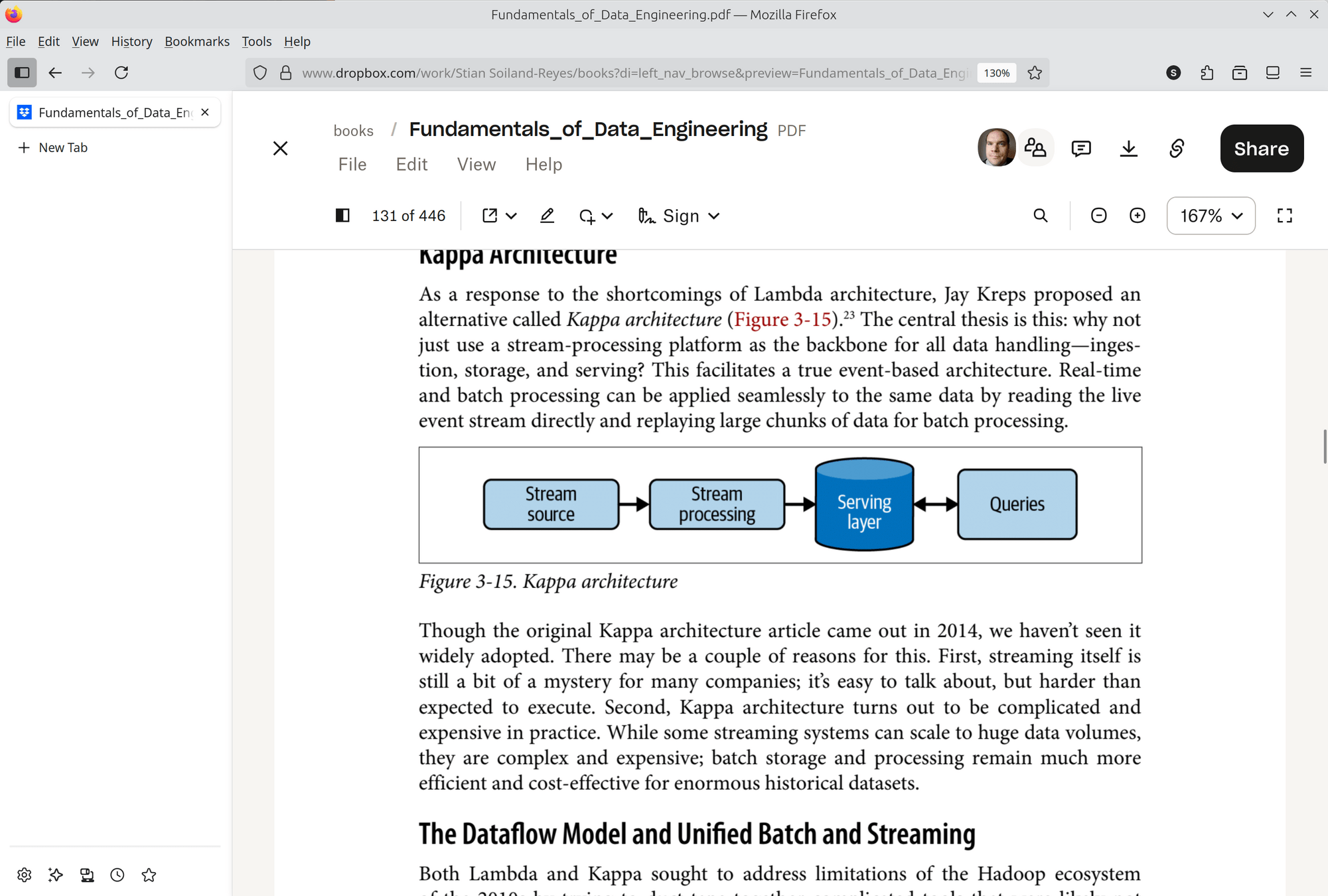
- Lambda architecture combines stream and batch processing, but with some code duplication (may lead to inconsistencies). Serving layer has two ways to query.
Architecture affects serving
Batch processing can stay close to relational database thinking
→ Online analytical processing (OLAP)
Stream processing may at first seem to complicate serving for end users
→Need to write Spark code rather than SQL queries
But.. streams can be queried with SQL. Streams can populate OLAPs. Streams can co-exist with batch.
