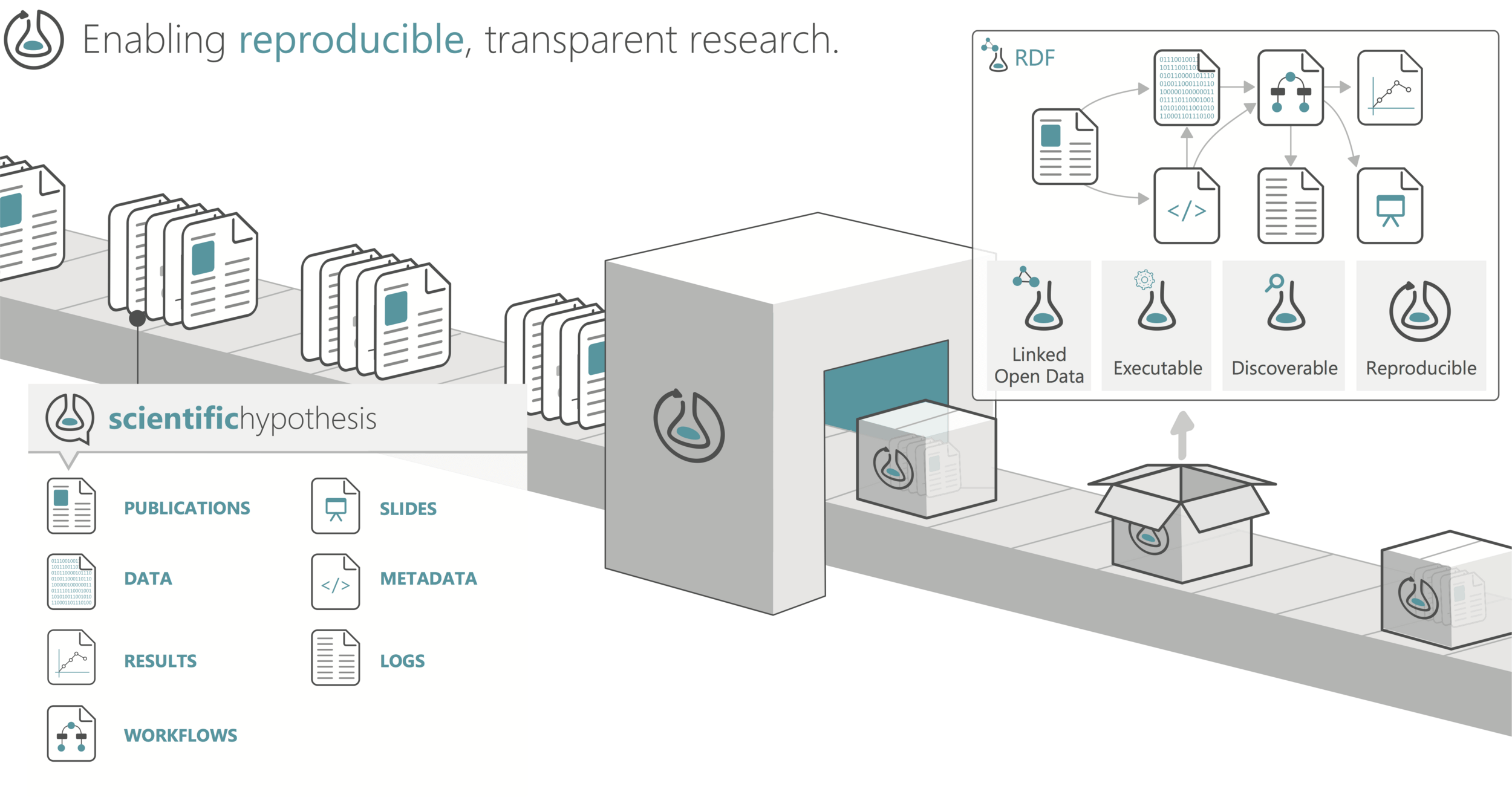
Reproducibility
and FAIR principles
DATA71011 Understanding Data and their Environment
Stian Soiland-Reyes, Meznah Aloqalaa


This work is licensed under a
Creative Commons Attribution 4.0 International License.
Intended Learning Outcomes
- Ability to recognise reproducibility challenges for computational analyses
- Skill of capturing computational environment using metadata
- Can explain the purpose of the FAIR Guiding Principles
- Can publish a dataset in a machine-actionable format (in lab)
The Turing Way Community. (2022): The Turing Way: A handbook for reproducible, ethical and collaborative research (1.0.2). Zenodo
https://doi.org/10.5281/zenodo.3233853.
Emma Karoune & Malvika Sharan (Alan Turing Institute):
Turing Way: Reproducibility, open science and collaboration in research
https://doi.org/10.5281/zenodo.4609987
Turing Way illustrations by Scriberia
https://doi.org/10.5281/zenodo.3332807

This work is licensed under a
Creative Commons Attribution 4.0 International License.






Motivation
Should policy makers trust the data science?
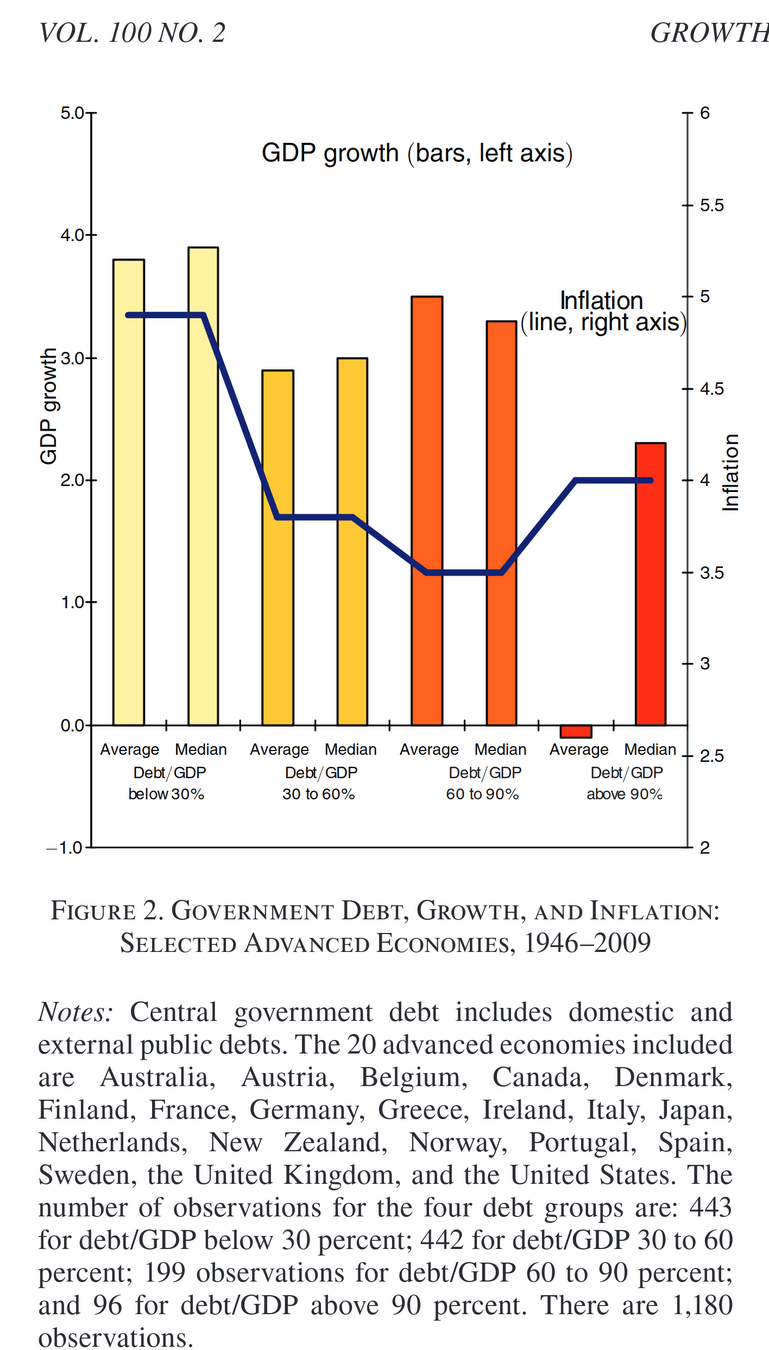
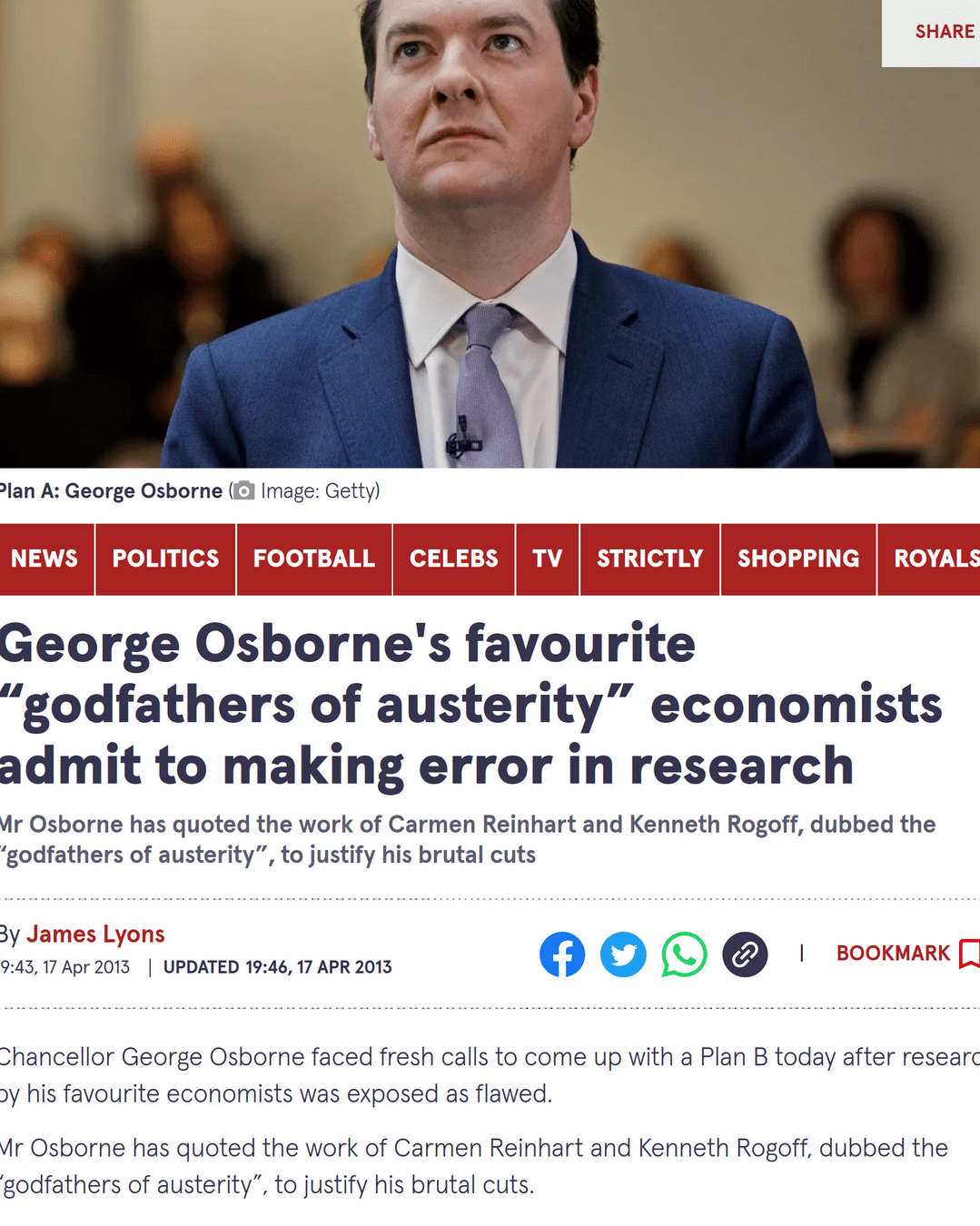
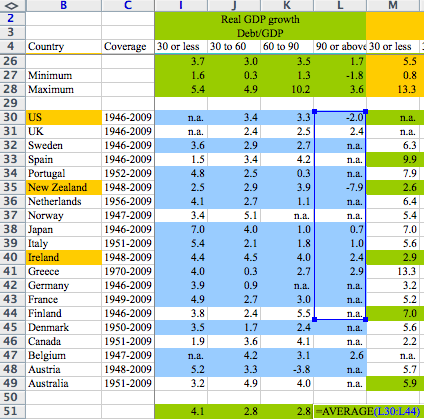
Growth in a Time of Debt?
In this paper, we exploit a new multi-country historical data set on central government debt as well as more recent data on external (public and private) debt to search for a systematic relationship between debt levels, growth and inflation. 1 Our main result is that whereas the link between growth and debt seems relatively weak at “normal” debt levels, median growth rates for countries with public debt over 90 percent of GDP are roughly one percent lower than otherwise; average (mean) growth rates are several percent lower. Surprisingly, the relationship between public debt and growth is remarkably similar across emerging markets and advanced economies. Emerging markets do face a much more binding threshold for total gross external debt (public and private)—which is almost exclusively denominated in a foreign currency. We find no systematic relationship between high debt levels and inflation for advanced economies as a group (albeit with individual country exceptions including the United States). By contrast, inflation rates are markedly higher in emerging market countries with higher public debt levels.



Research influences policy makers





Policies change society


.. but it didn't replicate!


Finding our way to Reproducibility

hang on..
Replicate or Reproduce..?

When scientists began to use digital computers to perform simulation experiments and data analysis, such attention to experimental error took back stage. Since digital computers are exact machines, practitioners apparently assumed that results obtained by computer could be trusted, provided that the principal algorithms and methods employed were suitable to the problem at hand. Little attention was paid to the correctness of implementation, potential for error, or variation introduced by system soft- and hardware, and to how difficult it could be to actually reconstruct after some years—or even weeks—how precisely one had performed a computational experiment.
Stanford geophysicist Jon Claerbout was one of the first computational scientists to address this problem (Claerbout and Karrenbach, 1992). His work was followed up by David Donoho and Victoria Stodden (Donoho et al., 2009) and introduced to a wider audience by Peng (2011).

Claerbout defined “reproducing” to mean “running the same software on the same input data and obtaining the same results” (Rougier et al., 2017), going so far as to state that “[j]udgement of the reproducibility of computationally oriented research no longer requires an expert—a clerk can do it” (Claerbout and Karrenbach, 1992). As a complement, replicating a published result is then defined to mean “writing and then running new software based on the description of a computational model or method provided in the original publication, and obtaining results that are similar enough …” (Rougier et al., 2017). I will refer to these definitions of “reproducibility” and “replicability” as Claerbout terminology; they have also been recommended in social, behavioral and economic sciences (Bollen et al., 2015).
Unfortunately, this use of “reproducing” and “replicating” is at odds with the terminology long established in experimental sciences. A standard textbook in analytical chemistry states (Miller and Miller, 2000, p. 6, emphasis in the original):
…modern convention makes a careful distinction between reproducibility and repeatability. …student A …would do the five replicate titrations in rapid succession …. The same set of [chemical] solutions and the same glassware would be used throughout, the same temperature, humidity and other laboratory conditions would remain much the same. In such circumstances, the precision measured would be the within-run precision: this is called the repeatability.
Suppose, however, that for some reason the titrations were performed by different staff on five different occasions in different laboratories, using different pieces of glassware and different batches of indicator …. This set of data would reflect the between-run precision of the method, i.e. its reproducibility.

Terminology
A variety of research communities have embraced the goal of reproducibility in experimental science. Unfortunately, the terminology in use has not been uniform. Because of this we find it necessary to define our terms. The following are inspired by the International Vocabulary for Metrology(VIM); see the Appendix for details.
-
Repeatability (Same team, same experimental setup)
-
The measurement can be obtained with stated precision by the same team using the same measurement procedure, the same measuring system, under the same operating conditions, in the same location on multiple trials. For computational experiments, this means that a researcher can reliably repeat her own computation.
-
-
Reproducibility (Different team, same experimental setup)*
-
The measurement can be obtained with stated precision by a different team using the same measurement procedure, the same measuring system, under the same operating conditions, in the same or a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using the author’s own artifacts.
-
-
Replicability (Different team, different experimental setup)*
-
The measurement can be obtained with stated precision by a different team, a different measuring system, in a different location on multiple trials. For computational experiments, this means that an independent group can obtain the same result using artifacts which they develop completely independently.
-
*As a result of discussions with the National Information Standards Organization (NISO), it was recommended that ACM harmonize its terminology and definitions with those used in the broader scientific research community, and ACM agreed with NISO’s recommendation to swap the terms “reproducibility” and “replication” with the existing definitions used by ACM as part of its artifact review and badging initiative. ACM took action to update all prior badging to ensure consistency.

Discuss!
What kind of changes are you likely to encounter in Data Science? What stays the same?
Would you need to repeat, reproduce or replicate?
-
Computational reproducibility: When detailed information is provided about code, software, hardware and implementation details.
-
Empirical reproducibility: When detailed information is provided about non-computational empirical scientific experiments and observations. In practice, this is enabled by making the data and details of how it was collected freely available.
-
Statistical reproducibility: When detailed information is provided, for example, about the choice of statistical tests, model parameters, and threshold values. This mostly relates to pre-registration of study design to prevent p-value hacking and other manipulations.
Steven Goodman et al. (2016) propose a new lexicon for research reproducibility with the following definitions:
• Methods reproducibility: provide sufficient detail about procedures and data so that the same procedures could be exactly repeated.
• Results reproducibility: obtain the same results from an independent study with procedures as closely matched to the original study as possible.
• Inferential reproducibility: draw the same conclusions from either an independent replication of a study or a reanalysis of the original study.
.. as summarised by Turing Way
and Plesser (2017)


More R-words please!
1. Repeatable
2. Reproducible
3. Reusable
4. Repurposable
5. Reliable
6. Referenceable
7. Re-interpretable
8. Respectful and Respectable
9. Retrievable
10. Replayable
11. Refreshable
12. Recoverable
... and Reviewable, Renderable, Recognisable, Revealable, Responsible, Recommendable, Reflective, Recursive, and Recyclable (really!)


The 21 ‘R words’ to date are grouped under six categories:
- scientific method – reproducible, repeatable, replicable, reusable
- access – referenceable, retrievable, reviewable
- understanding – replayable, reinterpretable, reprocessable
- new use – recomposable, reconstructable, repurposable
- social – reliable, respectful, reputable, revealable
- curation – recoverable, restorable, reparable, refreshable

Capturing the
computational environment



Step 0: Track your code
click~=8.1
cwl-utils==0.32
cwlprov==0.1.1
networkx==3.1
prov>=1.5.1
rocrate>=0.9,<1

Step 1: Use your language's packaging system
requirements.txt
[metadata]
name = csrankings-manchester
version = 0.1.0
license = Apache License, version 2.0 (Apache-2.0)
[options]
python_requires=>=3.10, <4
install_requires=
beautifulsoup4>=4.10
requests>=2.28.1
scholarly>=1.7.11
setup.cfg

install.packages("dplyr")install.R

Conda: data scientist's best/worst friend
name: science5
channels:
- conda-forge
dependencies:
- python
- numpy
- r
- r-dplyrenvironment.yml
$ conda env create -f environment.yml
$ conda activate datascience
(datascience) $ R
R version 4.4.1 (2024-06-14) -- "Race for Your Life"
Copyright (C) 2024 The R Foundation for Statistical Computing
Platform: x86_64-conda-linux-gnu
> library(dplyr)
Attaching package: ‘dplyr’

Containers recreate a miniature operating system install
## Step 1: Set up the computational environment
# Set the base image
FROM ubuntu:18.04
# Install packages needed to run the project
RUN apt-get update && \
apt-get install -y --no-install-recommends python3.7 python3-pip && \
rm -rf /var/lib/apt/lists/*
RUN python3 -m pip install numpy
# Prepare any directories
RUN mkdir /project
## Step 2: Include the project files in the image
COPY data/ /project/data
COPY analyse.py /project$ docker run -it analyser
root@a0eb7e496315:/# python3 project/analyse.py
hello
Virtual Machines (VMs) emulate a full computer
Text
Text
Discuss
- What reproducibility challenges could happen to your code?
- Could software packages / containers make reproducibility worse?
- What could be technical and social barriers for reproducing the computational environment?
- Why can't we just use Virtual machines?