Earthsys 144: Fundamentals of GIScience
Sampling & Interpolation
where is your data? gis.stanford.edu
Spatial Estimation


Spatial Interpolation
Spatial interpolation is the prediction of variables at unmeasured locations, and based on sampling of the same variables at known locations.
Spatial Prediction
Spatial prediction also involves estimation of variables at unsampled locations but differs from interpolation in that estimates are based at least in part on other variables
Spatial Sampling

Systematic Sampling

Samples are spaced at uniformly at fixed intervals.
It is usually not the most statistically efficient sampling pattern because all areas receive the same sampling intensity, regardless of the level of variation on the landscape
Random Sampling

Random sampling involves placing sample points at randomly generated XY locations. Random samples have an advantage over systematic samples in that they are unlikely to match any pattern in the landscape. However like systematic sampling random sampling does nothing to distribute samples in areas of high variation
Cluster Sampling

Cluster sampling distributes sample points around centers that are generated by some random or systematic method. Reducing travel time is the primary advantage of cluster sampling
Adaptive Sampling
Adaptive or stratified sampling is characterized by frequent sampling in variable areas and sparse sampling in uniform areas

Spatial Interpolation Methods

Nearest Neighbor

Nearest Neighbor

Fixed Radius Averaging

Fixed Radius Averaging

Fixed Radius Averaging

Inverse Distance Weighted
(IDW)

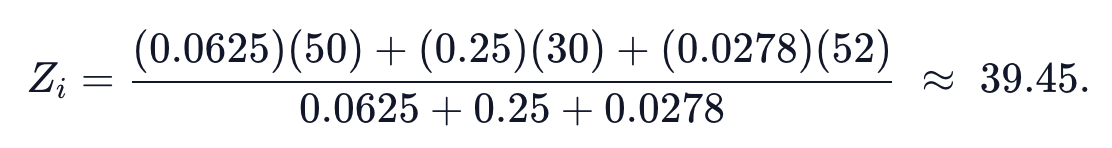
Inverse Distance Weighted
(IDW)
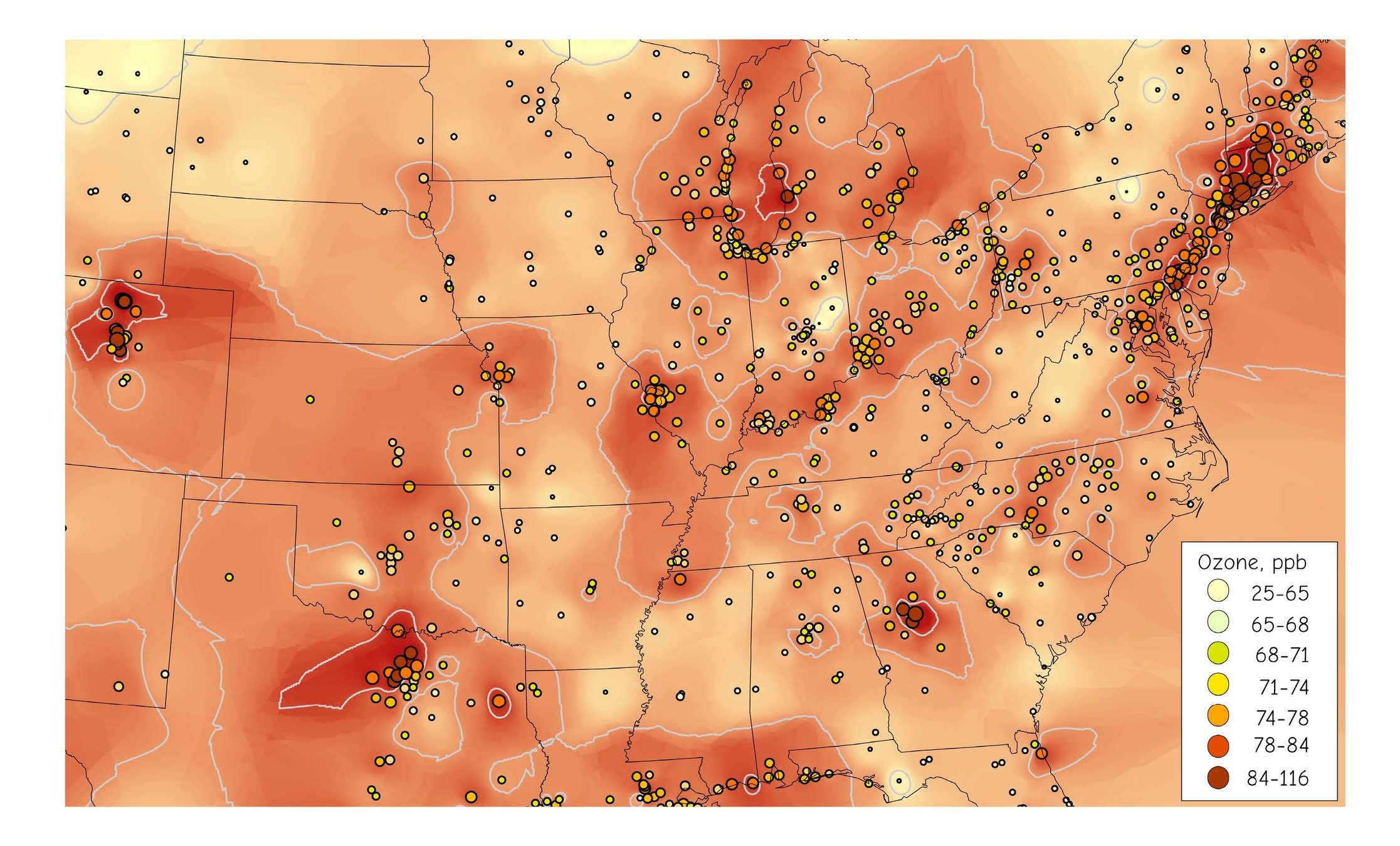

The top interpolation is using the twelve nearest points, with an exponent of two.
The lower interpolation is using the four nearest points, and an exponent of three.
Local influences are stronger as the exponent increases and the number of sample points decrease
Spline Functions



Spline Functions

Spatial Prediction
Spatial prediction also involves estimation of variables at and between sampled locations, but differs from interpolation in that estimates are based at least in part on other variables
Spatial Autocorrelation
"everything is related to everything else, but closer things are more related."
Waldo Tobler's 1st Law of Geography
Spatial Autocorrelation is the tendency of nearby objects to vary in concert with one another. High values occur together, as do low values.
Spatial Autocorrelation

Spatial Cross-correlation
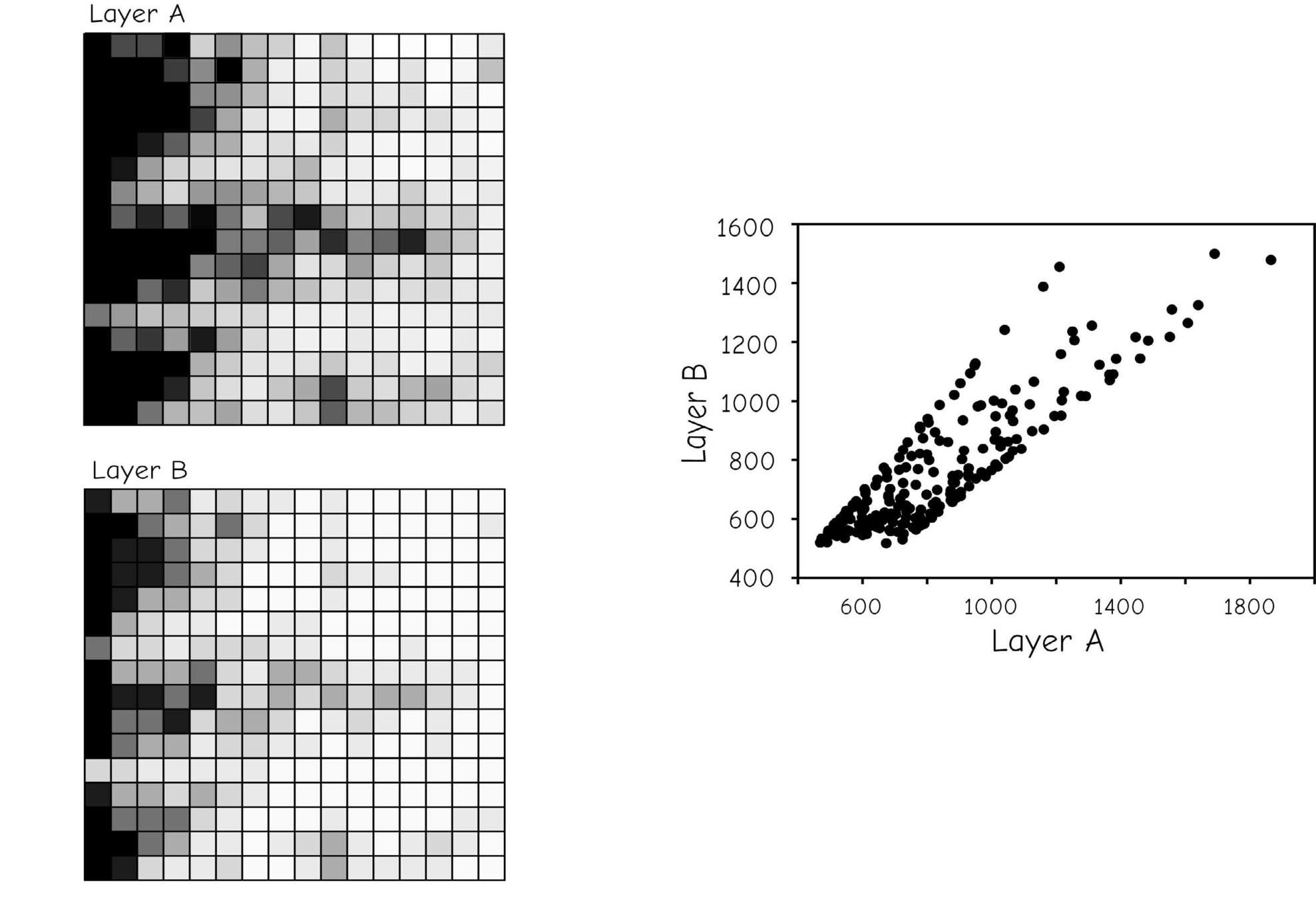
Moran's I

Trend Surfaces

Kriging and Co-Kriging

Includes three main components:
- spatial trend, an increase or decrease in a variable that depends on direction.
- local spatial autocorrelation, the tendency for points near each other to have similar values.
- random or stochastic variation, just like life.
Kriging and Co-Kriging

Kriging and Co-Kriging

Kriging and Co-Kriging

Kriging and Co-Kriging
