Q-RAG: Long Context Multi‑Step Retrieval via Value‑Based Embedder Training
Artyom Sorokin\(^{1,2}\) Nazar Buzun\(^{1,3}\) Alexander Anokhin\(^{2}\) Egor Vedernikov\(^{2}\) Petr Anokhin\(^{1}\) Mikhail Burtsev\(^{4}\) Evgeny Burnaev\(^{1,2}\)
\(^1\)AXXX, Moscow, Russia
\(^2\)Applied AI Institute, Moscow, Russia,
\(^3\)Innopolis University, Innopolis, Russia
\(^4\)London Institute for Mathematical Sciences, London, UK

Q-RAG: Long Context Multi‑Step Retrieval via Value‑Based Embedder Training
\(^1\)AXXX, Moscow, Russia
\(^2\)Applied AI Institute, Moscow, Russia
\(^3\)Innopolis University, Innopolis, Russia
\(^4\)London Institute for Mathematical Sciences, London, UK
Artyom Sorokin\(^{1,2}\)
Nazar Buzun\(^{1,3}\)
Alexander Anokhin\(^{2}\)
Egor Vedernikov\(^{2}\)
Petr Anokhin\(^{1}\)
Mikhail Burtsev\(^{4}\)
Evgeny Burnaev\(^{1,2}\)
Motivation
Long-Context is still challenging for Large Language Models
Common approaches to addressing the long-context challenge:
- SSM, Transformers with Recurrence, Linear Attention
- Can't be combined with best LLMs
- Knowledge Graph building Agents
- Slow inference time for long context processing
- Multi-step RAG and RAG Agents
- Expensive LLM finetuning for multi-step RAG
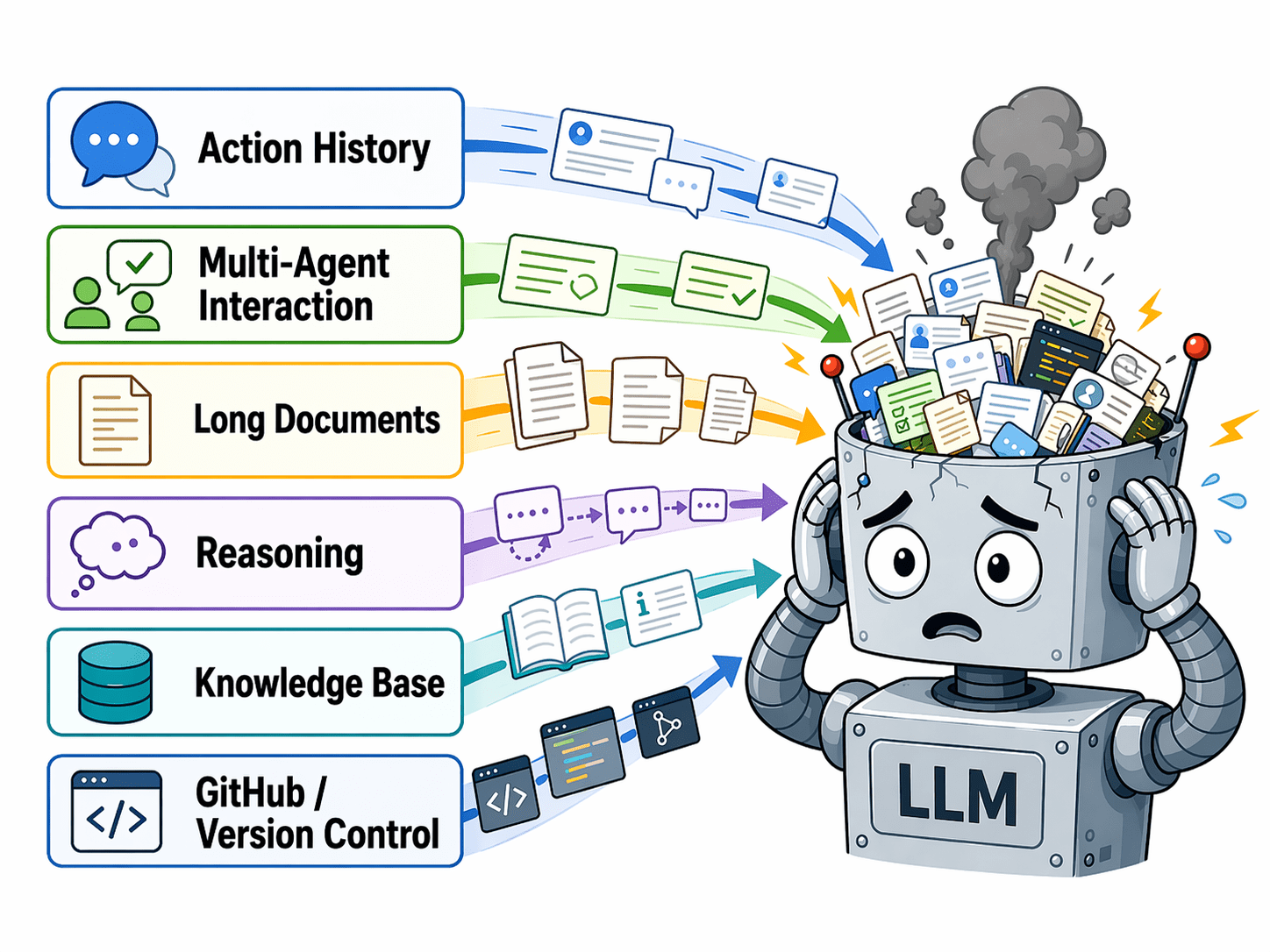

Motivation
Long-Context is still challenging for Large Language Models
Common approaches to addressing the long-context challenge:
- SSM, Transformers with Recurrence, Linear Attention
- Can't be combined with best LLMs
- Knowledge Graph building Agents
- Slow inference time for long context processing
- Multi-step RAG and RAG Agents
- Expensive LLM finetuning for multi-step RAG
Motivation
Long-Context is still challenging for Large Language Models
Common approaches to addressing the long-context challenge:
- SSM, Transformers with Recurrence, Linear Attention
- Can't be combined with best LLMs
- Agents that build Knowledge Graphs
- Slow inference for long context processing
- Multi-step RAG and RAG agents
Motivation
Popular direction for multi-step RAG is to fine-tune an LLM to use retrieval as a tool
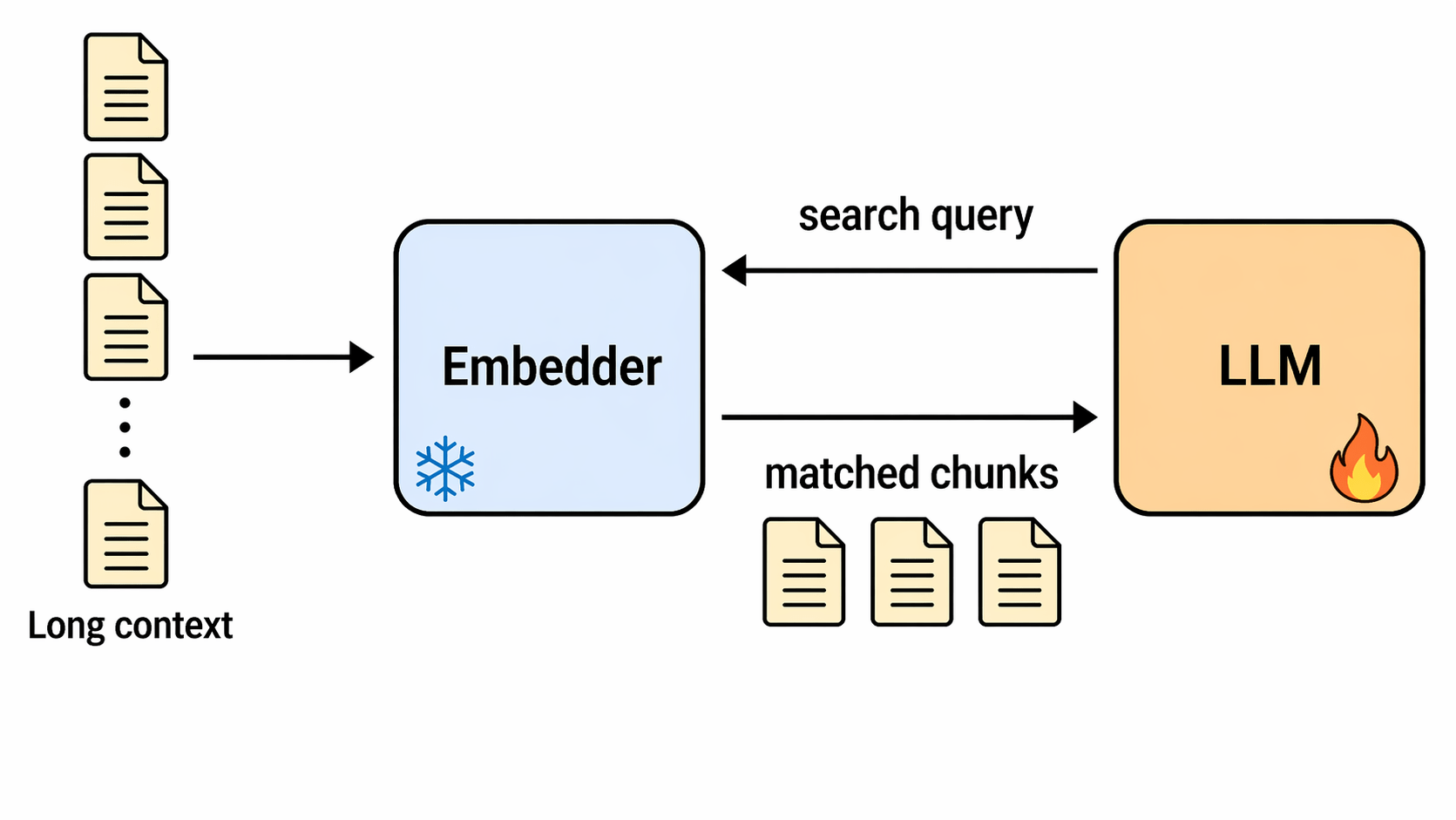
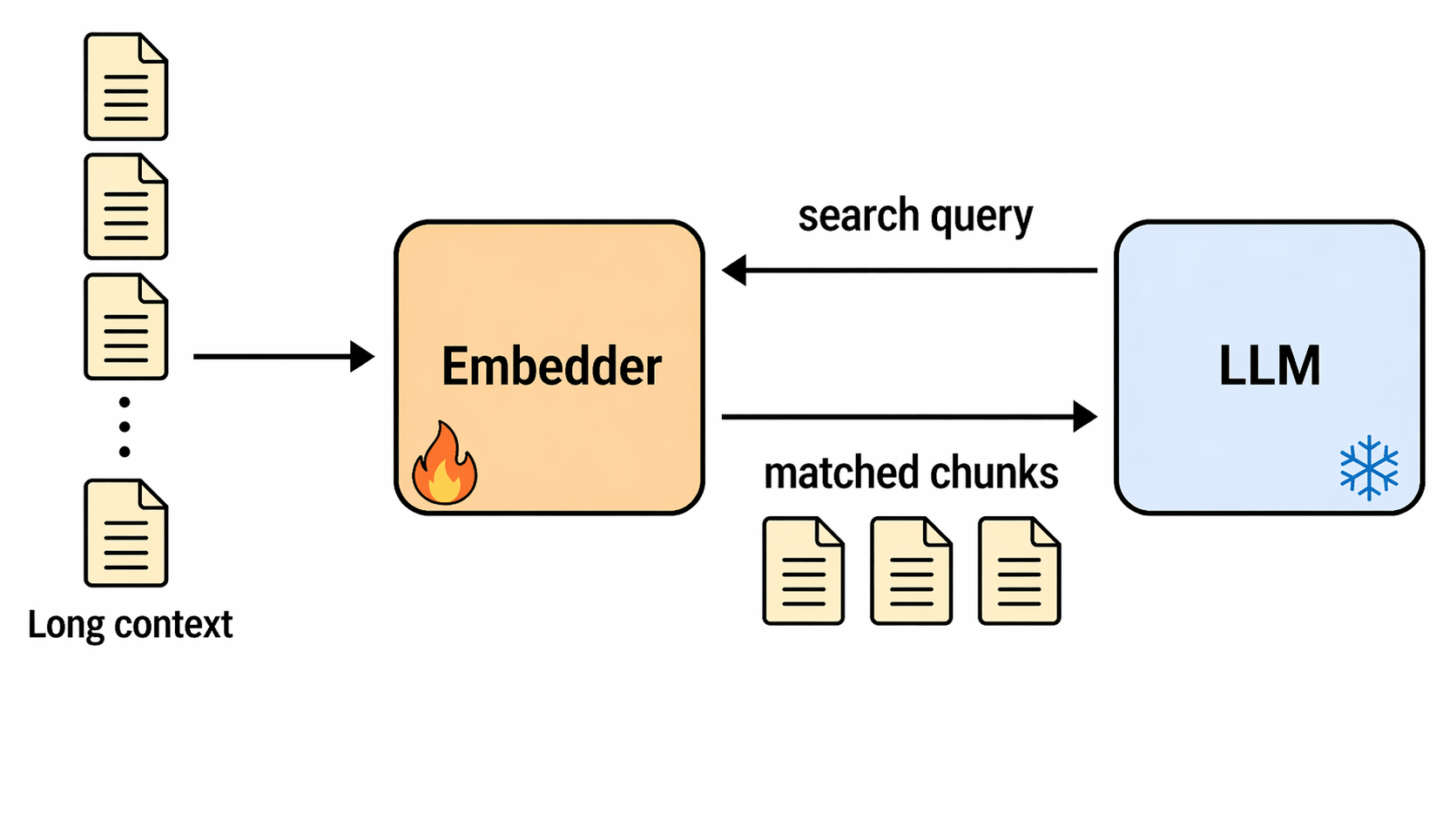
But fine-tuning LLMs can be expensive :(
Q-RAG: Main Idea
Main Idea:
- Train Embedder instead of LLM to multi-step search tasks
- Search queries are generated directly in embedding space
- Formulate multi-step RAG as an MDP
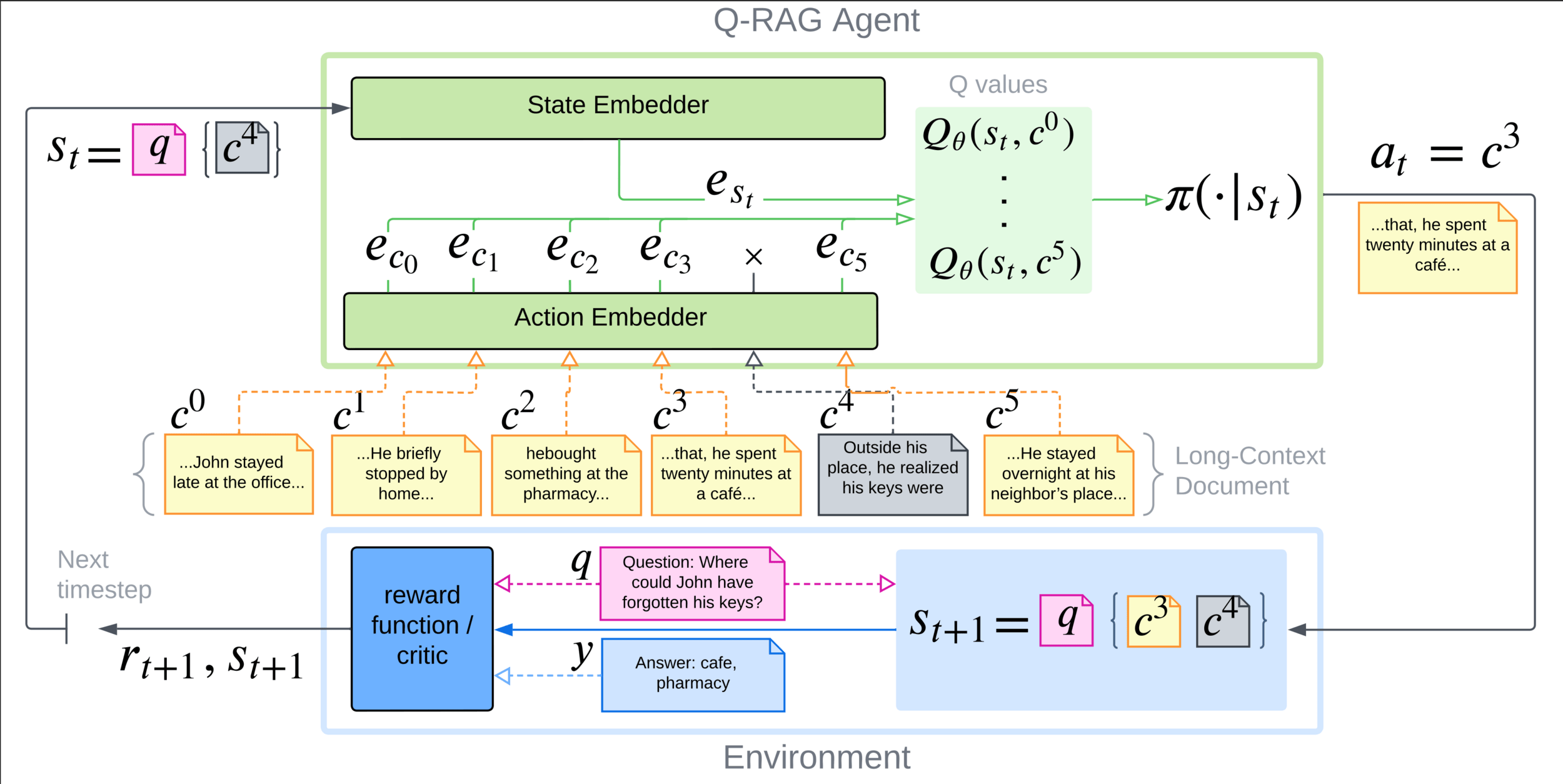
Q-RAG: retrieval as RL problem
Multi-step retrieval as RL problem:
- State: query + retrieved information.
- Actions: chunks available for retrieval
- Reward: 1.0 if all required chunks are found
- Termination: exausting retrieval budget

Q-RAG: Training
We train embedders to approximate \(Q\)-function with Inner product beween state embedding and chunk embedding:
NCE training: \(\langle s , a \rangle \rightarrow\) semantic similarity
Q-value approximation: \(\langle s , a \rangle \rightarrow\) usefulness of \(a\) given query \(s = prompt(q, a_{t-1}..., a_{0})\)
Max entropy value functions that encourage exploration:
Given \(Q_\theta\), the chunk selection probability is computed using a Boltzmann policy:
, where
Q-RAG: Architecture
Additional Q-RAG Details:
- PQN Backbone:
- No Replay Buffer
- Separate embedders for states and chunks/actions
- Adding Target Networks improves stability
- \(\lambda\)-return used as target for Q-function
Q-RAG: Architecture
Additional Q-RAG Details:
- PQN Backbone:
- No Replay Buffer
- Adding Target Networks improves stability
- \(\lambda\)-return used as target for Q-function
Relative Positional Encoding


Maps each chunk index to a continuous value, which is injected into the chunk embedding through RoPE.
- Captures position within the document
- Captures position relative to previously retrieved chunks
Properties:
- Number of chunks doesn’t influence max positional value
- Max positional value depends only on number of retrieval steps
Relative Positional Encoding
Q-RAG assigns each candidate chunk a continuous relative position \(\rho_t(i)\):
where \(b_{j} < i < b_{j+1}\)
\(b_{j}\) - closest retrieved chunk to the left
\(b_{j+1}\) - closest retrieved chunk to the right
- RoPE + \(\rho_t(i)\) is used to rotate chunk embeddings
- encodes position within the document and relative to retrieved chunks
Results: BabiLong
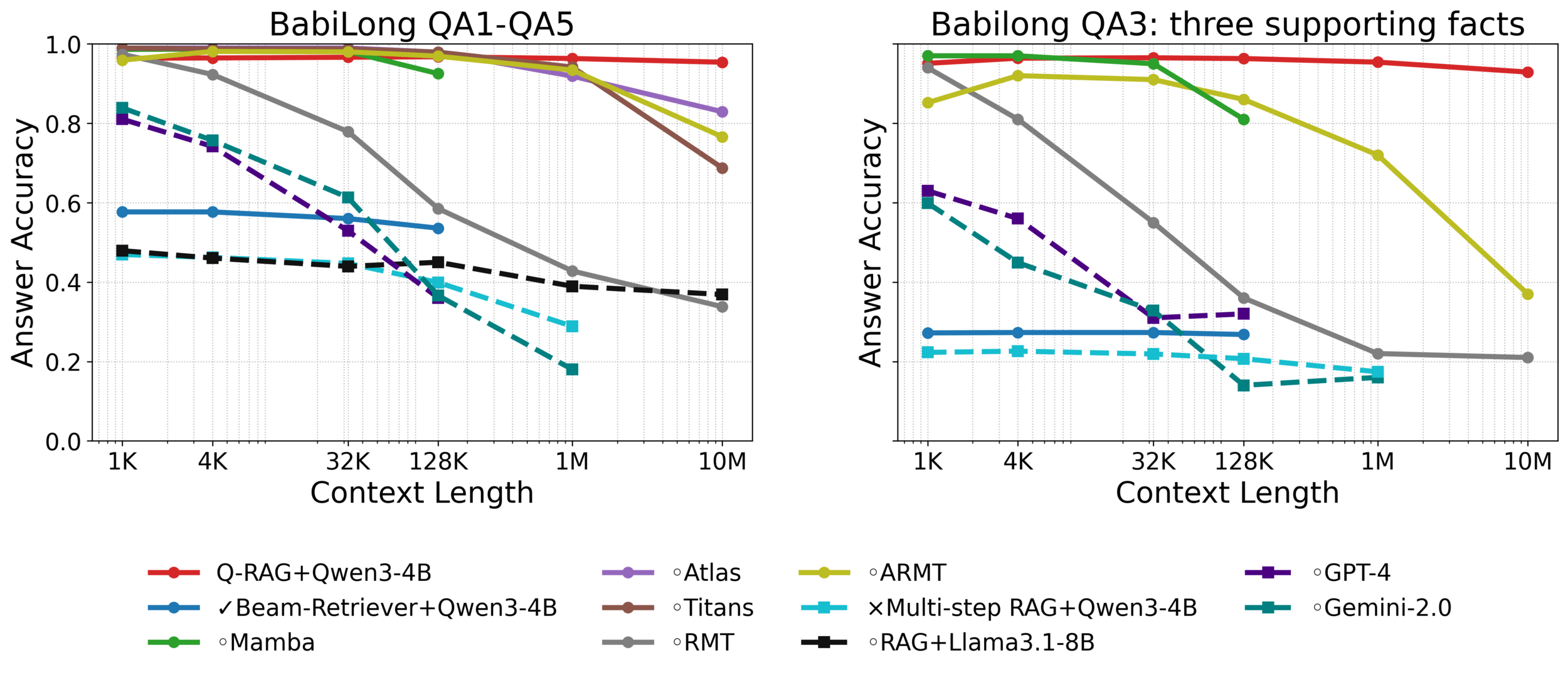
BabiLong is commonsense and temporal reasoning benchmark for ultra-long contexts
- Q-RAG achieves state of the art performance (from 128k to 10M tokens)
- The gap is bigger on harder tasks like (QA3)
Results: RULER
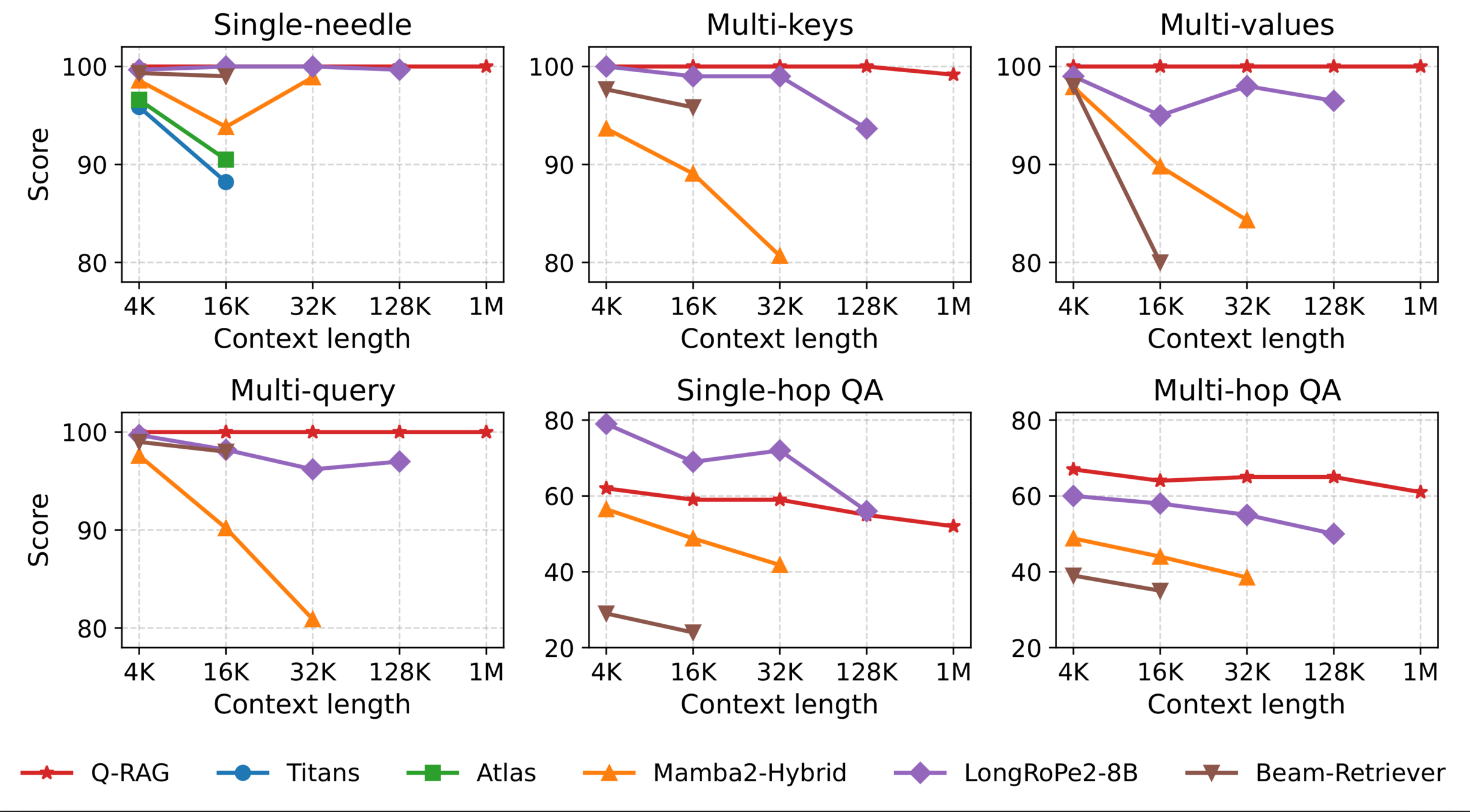
RULER benchmark:
- different types of NIAH tasks
- couple of Open domain QA tasks
Results:
- Near-perfect retrieval on NIAH
- Generalizes to 1M tokens
- Best on multi-hop QA
- Only mild degradation with length increase
Results: Open Domain QA
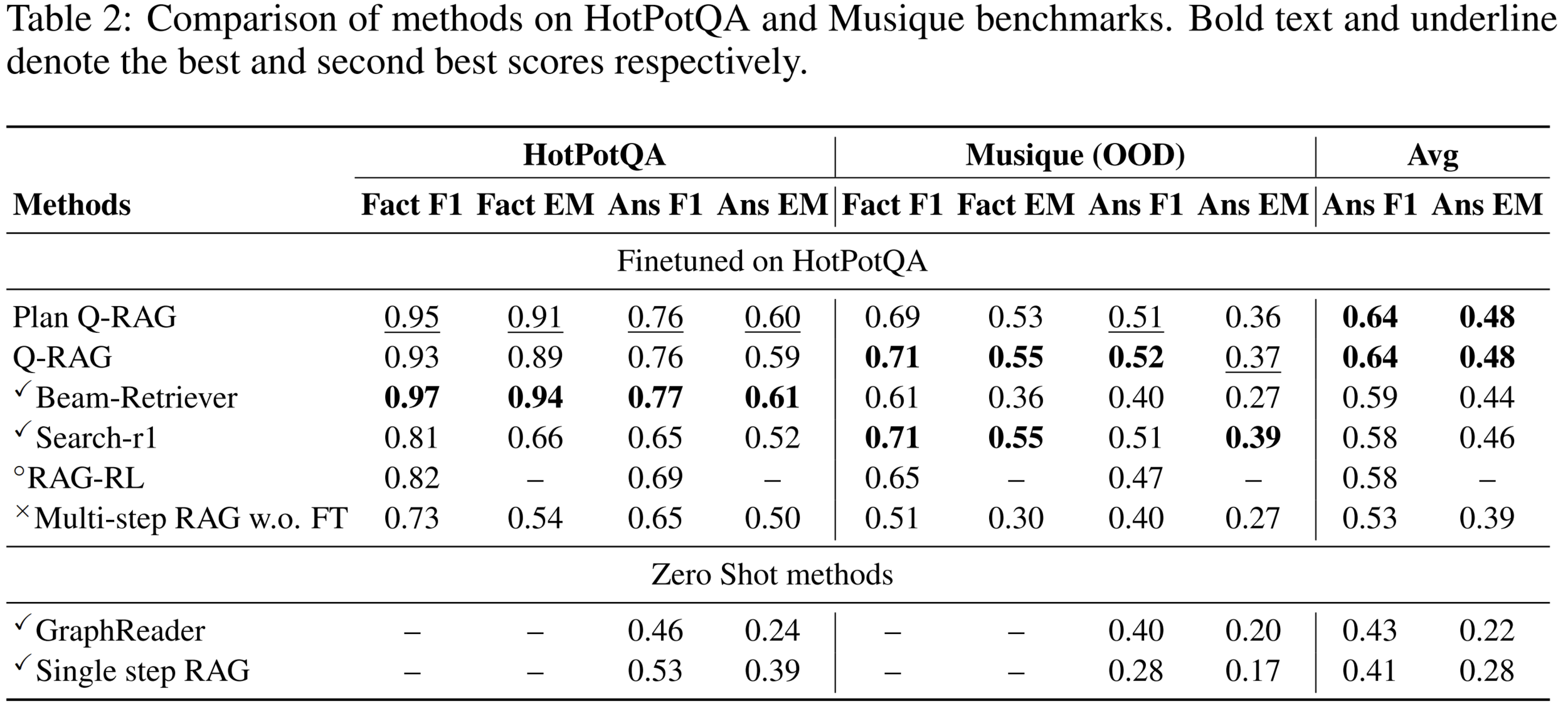
Results on Open-Domain QA
- Competitive results on HotPotQA and MuSiQue
- Cheaper training than LLM fine-tuning methods
- Faster inference than Beam Retriever and Graph based methods
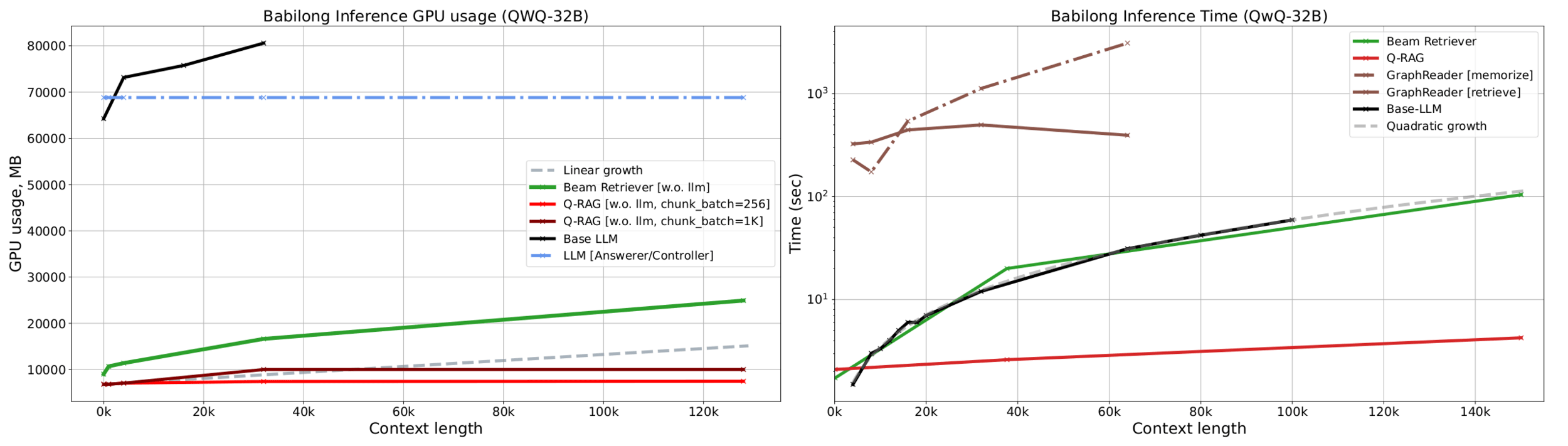
Training and Inference Cost
Q-RAG fine-tunes only the retriever/embedder and keeps the answering LLM frozen.
- Main experiments fit on a single A100-80GB GPU
- Fine-tuning of one embedder model takes around 12 hours
- Faster inference than Beam Retriever and Graph based methods

Conclusion
- Fine-tuning the embedder for multi-step retrieval is cheaper than LLM
- Competitive Quality on Open Domain QA
- State of the Art on BabiLong and RULER
- The main bottleneck is dependence on support-chunk annotations

An open question for future work:
- can generated data or LLM-based rewards remove dependence on support-chunk annotations?
Thanks For Your Attention!
CODE
PAPER
CHECKPOINTS

Contacts: griver29@gmail.com or n.buzun@seevia.ai


Thanks for your Attention!



Thanks for your Attention!
