AI: 淺談機器學習
第二堂小社
機器學習
監督式學習
非監督式學習
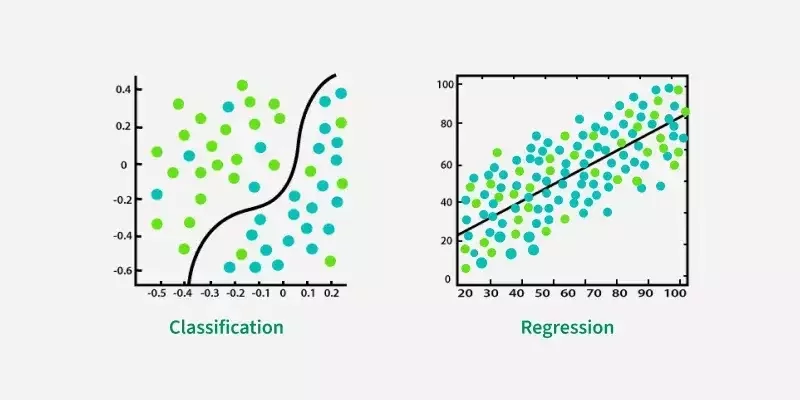
分類
迴歸
Classification
Regression
有標記的資料
無標記
非連續性的資料
連續性的資料
Machine Learning
Classification
Regression
(今天要學的)
所以機器怎麼分類資料?
Common classification models:
- Logistic Regression
- K- nearest neighbours (KNN)
- Support Vector Machine (SVM)
- Naive Bayes Classifier
- Linear Discrimininant Analysis (LDA)
有很多不同的方法,常見的如下
-# 今天會著重在概念的理解和 Python 實作
-# 數學請見下學期的機器學習小社
Logistic Regression
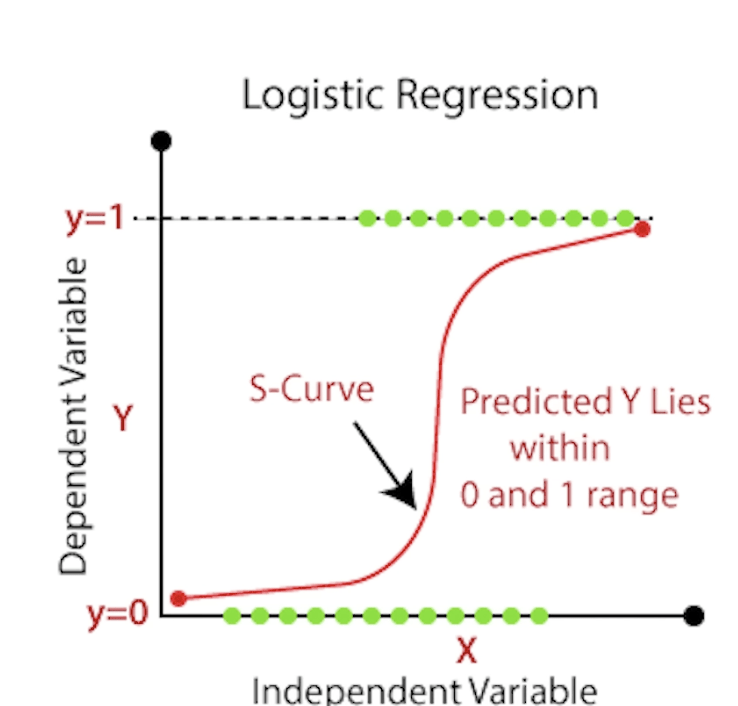
- 用於二元分類
- (只能把東西分成兩類)
- X 軸代表輸入,Y軸代表有多大的機率是 A 或 B
Sigmoid function
Logistic Regression
Sigmoid function
功能只是把數值轉成機率而已 (機率須為 0~1) 之間的數
Logistic Regression
Sigmoid function
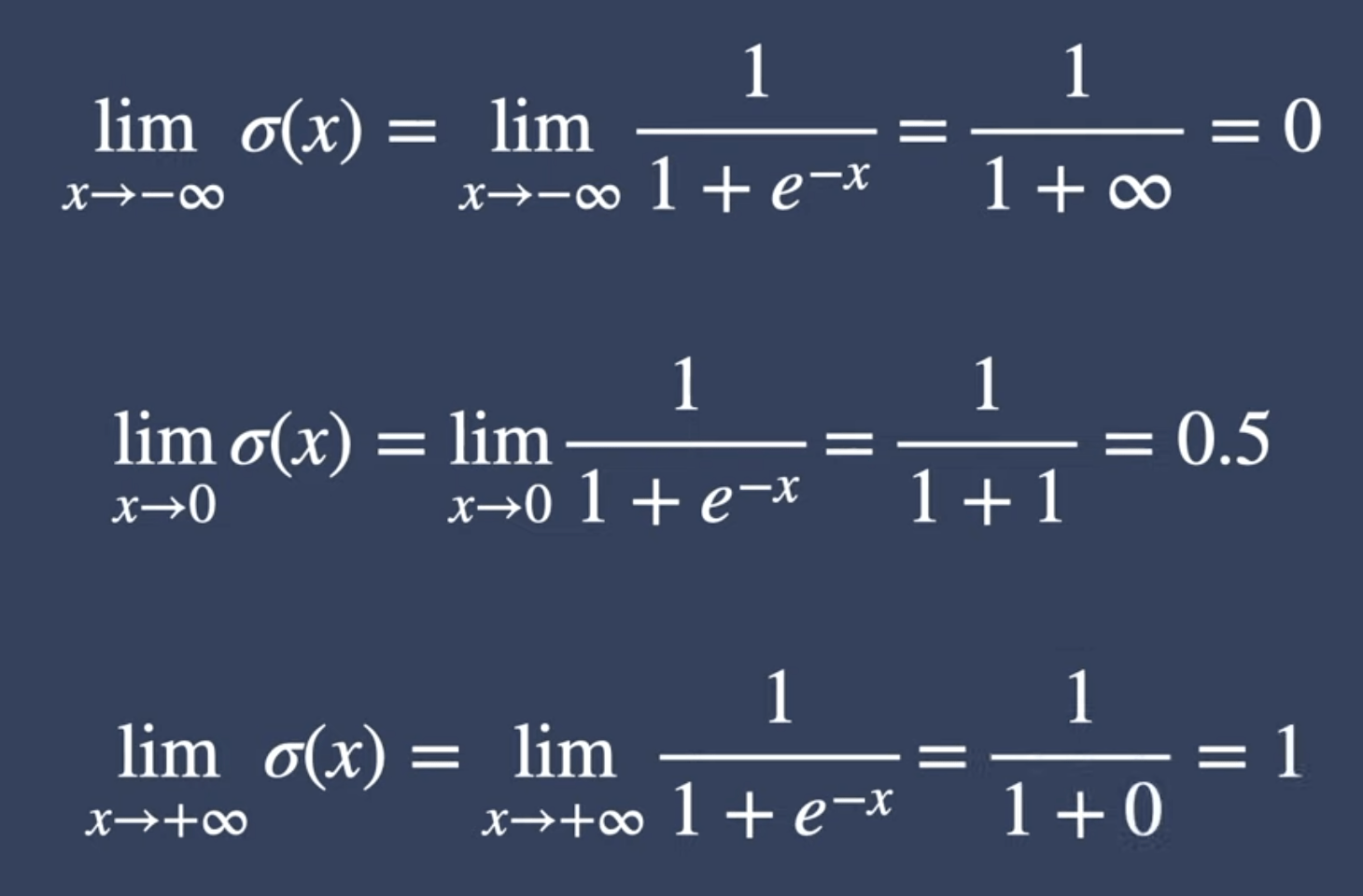
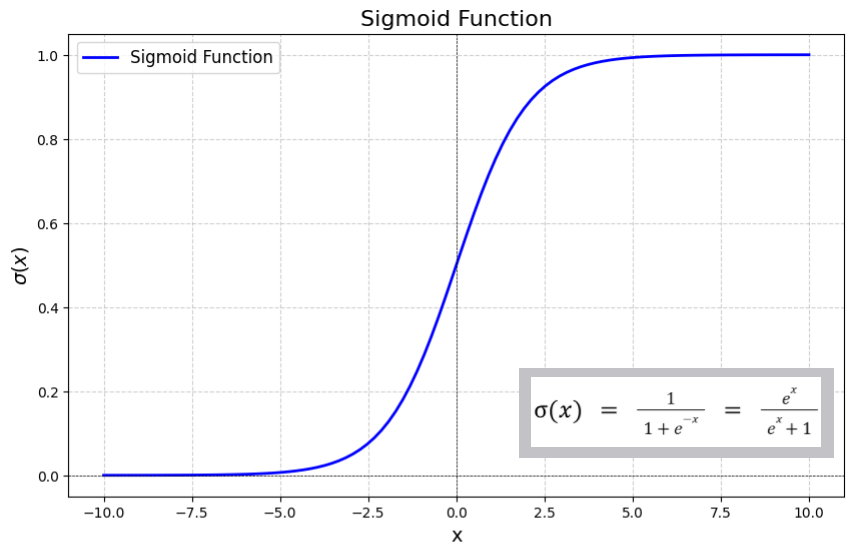
可以看圖理解一下
機率極低和極高會推到 0 及 1 兩個極端
K - nearest neighbours (KNN)
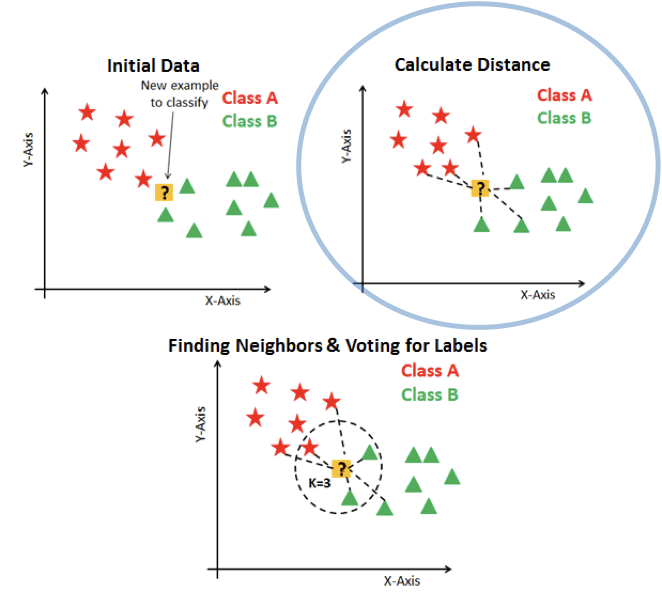
- classification 和 regression 皆可用
- 基本假設:
- 任何資料點皆為其附近 K 的資料點的平均值
K - nearest neighbours
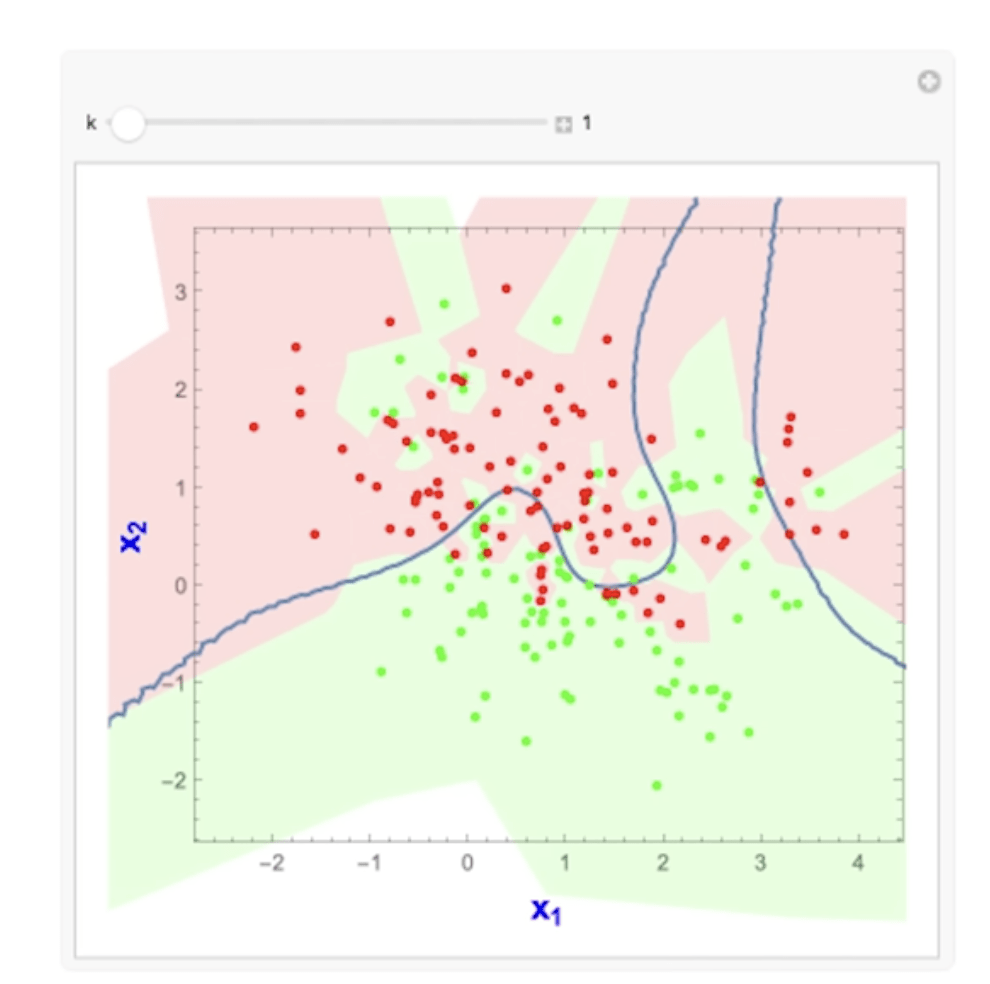
因為它沒有所謂的「方程式」
故能拿來處理複雜的狀況
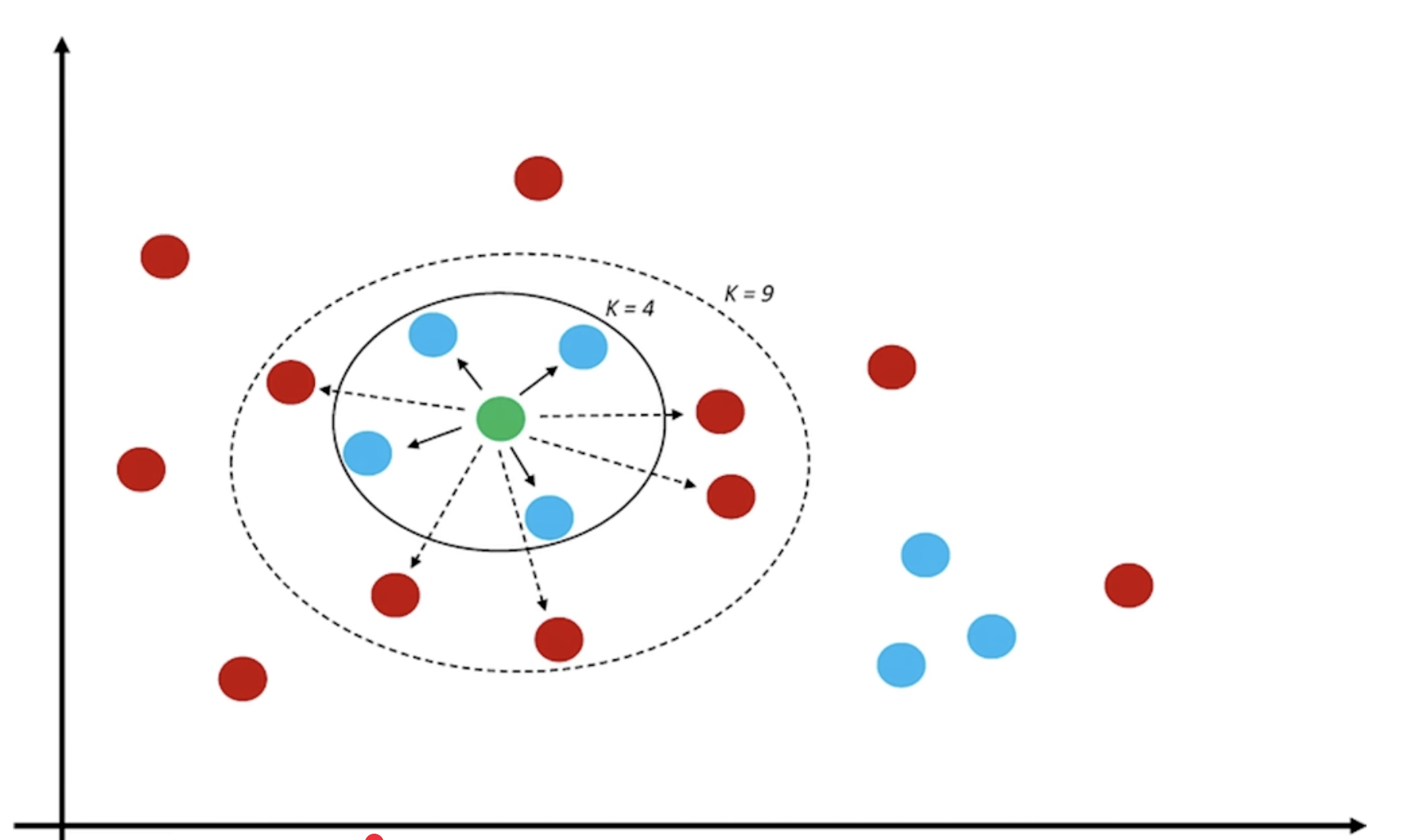
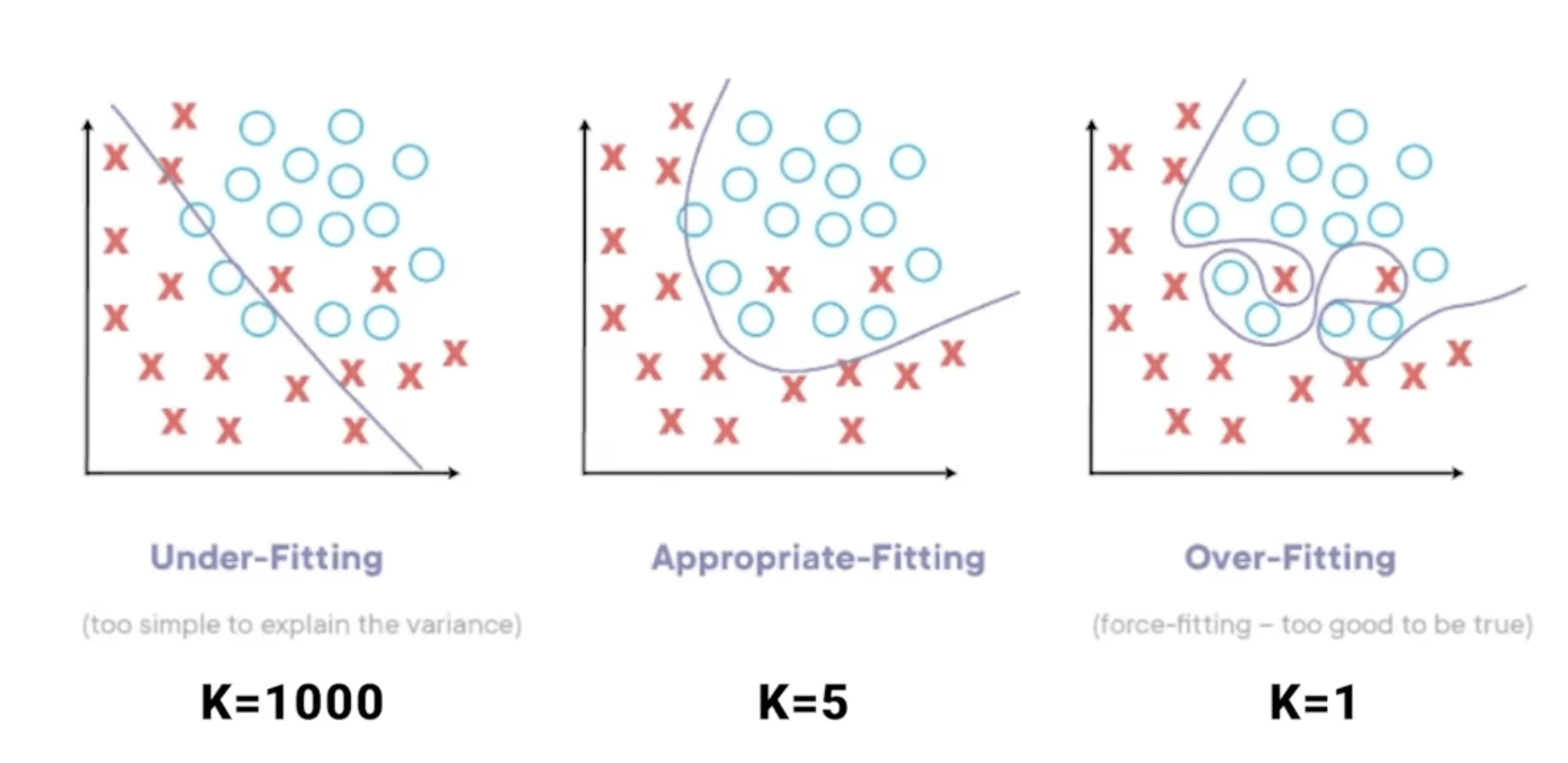
K值要選多少
看個人造詣 大部分倚靠經驗法則+多方嘗試
K 值越大越好?越小越好?
Support vector machine (SVM)
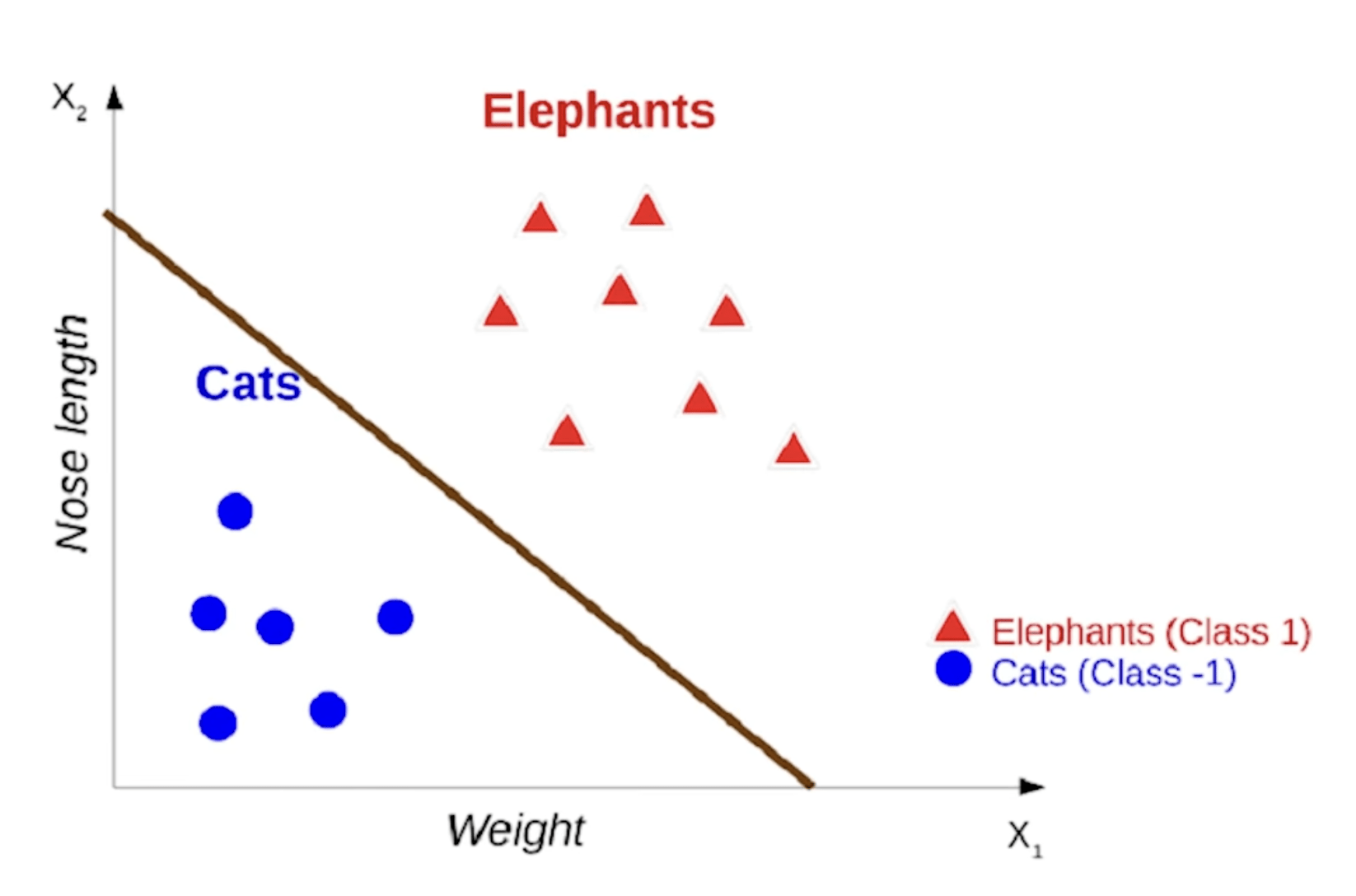
目標:找一個 「決策邊界」 Decision Boundary
把各類別分開
這個圖是在根據體重及鼻子長度
判斷是什麼動物
Support vector machine (SVM)
尋找決策邊界的方法:找到一條線,使其到各資料點的距離為最大(這樣就可以確保畫的是「最中間」的線)
Support vector machine (SVM)
優點:因為也可以在多維空間中畫線作為 decision boundary,所以可以一次考量多種特徵來分類(例:三維空間考慮 3 個特徵)
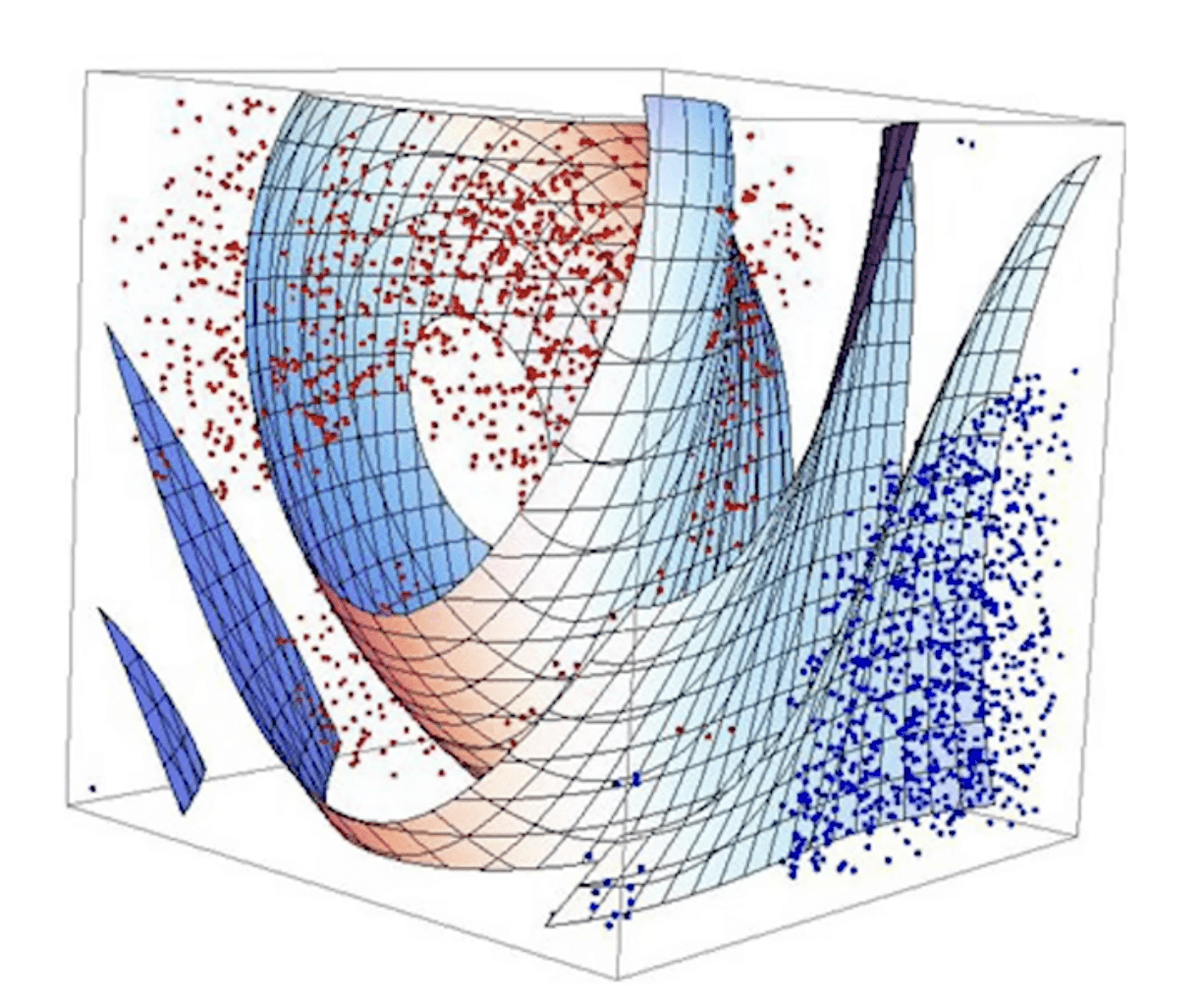
*多維空間中的 decision boundary 稱為「超平面」(hyperplane)
Linear Discriminant Analysis (LDA)
目標:找方法是數個特徵可以同時在二維平面上呈現
1. 要使兩組資料點的平均值離越遠越好
2. 而標準差分佈要越小越好
要找一種方法,使兩組資料可以越清楚地分開
小實作
Iris dataset
