Machine Learning 2
Multiclass Classification, Cross validation
目錄
- Review ML 0 & 1
- Classification 分類問題
- 二元分類 Binary - Logistic regression
- 多元分類 Multiclass
- Softmax
- Naive Bayes, Gaussian Naive Bayes
- Decision trees
- 交叉驗證 Cross-validation
講師 Suzy (蘇西)
- 北資一六 學術長
技能點:
- Python
- 機器學習 (機器在學習講師也在學習)
- C++ 可以說是會跟不會差不多
- 養了兩隻 Labubu

寶寶蘇西

Classification 分類問題
I. Binary 二元分類
II. Multi-class 多類別分類
Softmax function
:thonk_owo:




ok 我們要分類
ok 我們要分類
\mathbf{y}_{pear} = \begin{bmatrix} 1 \\ 0 \\ 0 \\ 0 \end{bmatrix}, \quad
\mathbf{y}_{apple} = \begin{bmatrix} 0 \\ 1 \\ 0 \\ 0 \end{bmatrix}, \quad
\mathbf{y}_{orange} = \begin{bmatrix} 0 \\ 0 \\ 1 \\ 0 \end{bmatrix}, \quad
\mathbf{y}_{banana} = \begin{bmatrix} 0 \\ 0 \\ 0 \\ 1 \end{bmatrix}
one hot vector: 把變數變得更單純,只把我們要的變數值設為「1」,
其他變數值設為「0」
\theta_1 \cdot x =0
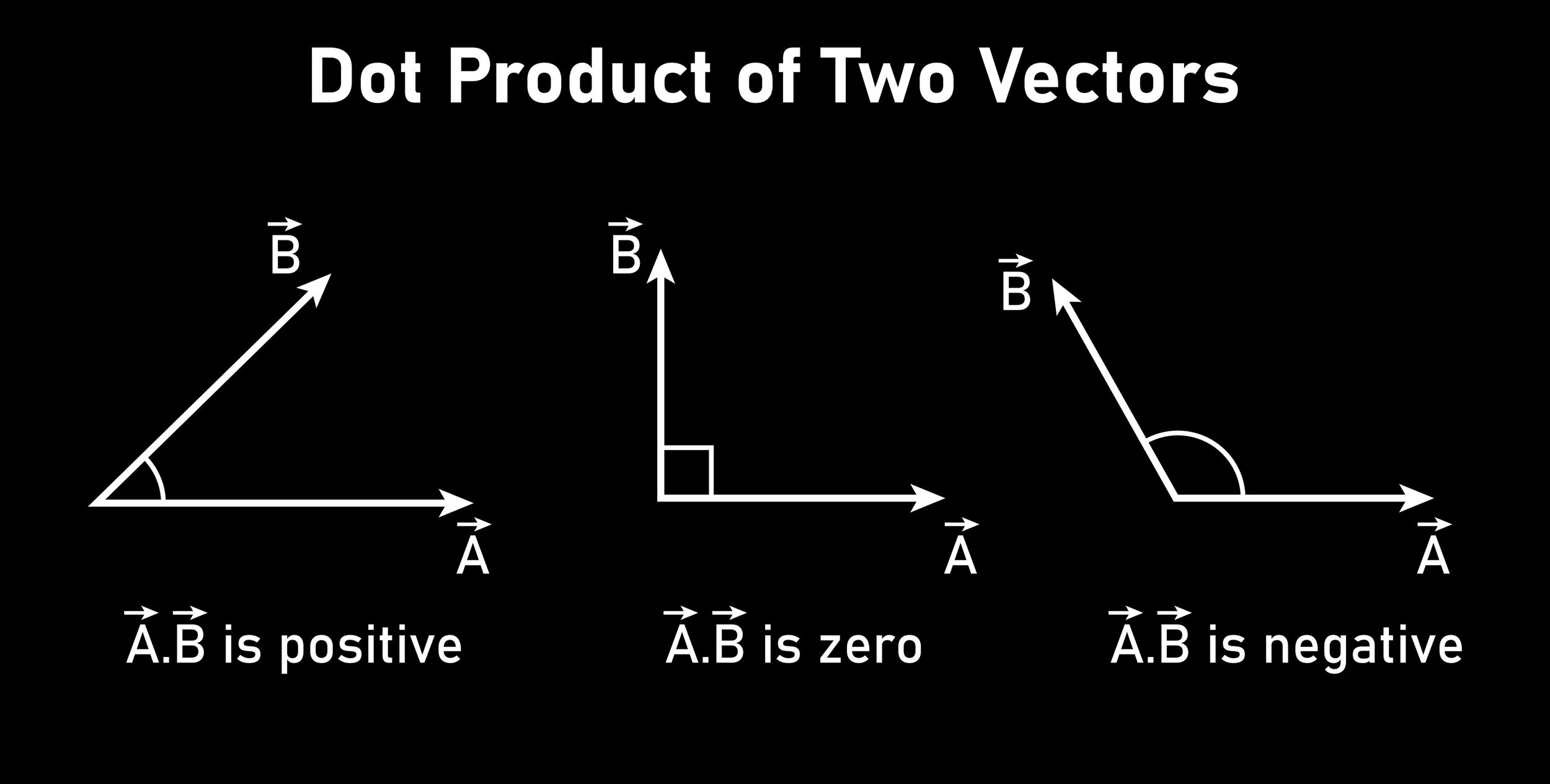
數學小知識:向量內積
(2,1) \cdot (3,4) = 2 \cdot 3 + 3 \cdot 4
例:
\theta_1 \cdot x =0
\theta_4 \cdot x =0
\theta_2 \cdot x =0
\theta_3 \cdot x =0
假設今天有一筆資料
\begin{aligned}
s_1 = \theta_1 \cdot \mathbf{x} &= (1)(2) + (2)(3) = 8 \\
s_2 = \theta_2 \cdot \mathbf{x} &= (0)(2) + (-1)(3) = -3 \\
s_3 = \theta_3 \cdot \mathbf{x} &= (-2)(2) + (1)(3) = -1 \\
s_4 = \theta_4 \cdot \mathbf{x} &= (1)(2) + (-1)(3) = -1
\end{aligned}
\mathbf{x} = \begin{bmatrix} 2 \\ 3 \end{bmatrix}, \quad
\theta_1 = \begin{bmatrix} 1 \\ 2 \end{bmatrix}, \quad
\theta_2 = \begin{bmatrix} 0 \\ -1 \end{bmatrix}, \quad
\theta_3 = \begin{bmatrix} -2 \\ 1 \end{bmatrix}, \quad
\theta_4 = \begin{bmatrix} 1 \\ -1 \end{bmatrix}
算機率
\begin{aligned}
\exp(s_1) &= e^{8} \approx 2980.96 \\
\exp(s_2) &= e^{-3} \approx 0.05 \\
\exp(s_3) &= e^{-1} \approx 0.37 \\
\exp(s_4) &= e^{-1} \approx 0.37
\end{aligned}
算機率
\begin{aligned}
P(pear) &= \frac{e^{s_1}}{\sum e^{s_j}} = \frac{2980.96}{2981.75} \approx \mathbf{0.9997} \\
P(apple) &= \frac{e^{s_2}}{\sum e^{s_j}} = \frac{0.05}{2981.75} \approx \mathbf{0.000017} \\
P(orange) &= \frac{e^{s_3}}{\sum e^{s_j}} = \frac{0.37}{2981.75} \approx \mathbf{0.00012} \\
P(banana) &= \frac{e^{s_4}}{\sum e^{s_j}} = \frac{0.37}{2981.75} \approx \mathbf{0.00012}
\end{aligned}
Naive Bayes
貝氏分類器
正常信件
垃圾郵件
分類
正常信件
垃圾郵件
你好
朋友
吃飯
建北
電資
沒錢
匯款
你好
朋友
吃飯
建北
電資
沒錢
匯款
統計字詞出現次數
8
7
5
2
1
1
3
2
1
6
7
8
統計字詞出現次數
正常信件
你好
朋友
吃飯
建北
電資
沒錢
匯款
\begin{aligned}
P(\text{你好} | \text{normal}) &= \frac{8}{24} \approx 0.333 \\
P(\text{朋友} | \text{normal}) &= \frac{7}{24} \approx 0.292 \\
P(\text{吃飯} | \text{normal}) &= \frac{5}{24} \approx 0.208 \\
P(\text{建北電資} | \text{normal}) &= \frac{2}{24} \approx 0.083 \\
P(\text{沒錢} | \text{normal}) &= \frac{1}{24} \approx 0.042 \\
P(\text{匯款} | \text{normal}) &= \frac{1}{24} \approx 0.042
\end{aligned}
8
7
5
2
1
1
垃圾郵件
你好
朋友
吃飯
建北
電資
沒錢
匯款
統計字詞出現次數
\begin{aligned}
P(\text{你好} | \text{spam}) &= \frac{3}{27} \approx 0.111 \\
P(\text{朋友} | \text{spam}) &= \frac{2}{27} \approx 0.074 \\
P(\text{吃飯} | \text{spam}) &= \frac{1}{27} \approx 0.037 \\
P(\text{建北電資} | \text{spam}) &= \frac{6}{27} \approx 0.222 \\
P(\text{沒錢} | \text{spam}) &= \frac{7}{27} \approx 0.259 \\
P(\text{匯款} | \text{spam}) &= \frac{8}{27} \approx 0.296
\end{aligned}
3
2
1
6
7
8
Prior Probability
事前機率
根據 training data (無其他資訊)的情況下,預估可能是 normal 或 spam 的機率。
根據 training data (無其他資訊)的情況下,預估可能是 normal 或 spam 的機率。
training data: 8 封 normal 4 封 spam
p(N) = 0.67
p(S) = 0.33
\begin{aligned}
\text{Score}(\text{Normal}) &= P(N) \cdot P(\text{早安}|N) \cdot P(\text{朋友}|N) \\
&= 0.67 \cdot \left(\frac{1}{30}\right) \cdot \left(\frac{7+1}{30}\right) \\
&= 0.67 \cdot 0.0333 \cdot 0.2667 \\
&\approx \mathbf{0.00595} \\
\\
\text{Score}(\text{Spam}) &= P(S) \cdot P(\text{早安}|S) \cdot P(\text{朋友}|S) \\
&= 0.33 \cdot \left(\frac{1}{33}\right) \cdot \left(\frac{2+1}{33}\right) \\
&= 0.33 \cdot 0.0303 \cdot 0.0909 \\
&\approx \mathbf{0.00091}
\end{aligned}
信件內容:「早安朋友」
\begin{aligned}
\text{Score}(\text{Normal}) &= P(N) \cdot P(\text{建北}|N) \cdot P(\text{朋友}|N) \cdot P(\text{沒錢}|N) \cdot P(\text{匯款}|N) \\
&= 0.67 \cdot \left(\frac{2+1}{30}\right) \cdot \left(\frac{7+1}{30}\right) \cdot \left(\frac{1+1}{30}\right) \cdot \left(\frac{1+1}{30}\right) \\
&= 0.67 \cdot (0.1) \cdot (0.2667) \cdot (0.0667) \cdot (0.0667) \\
&\approx \mathbf{0.000080} \\
\\
\text{Score}(\text{Spam}) &= P(S) \cdot P(\text{建北}|S) \cdot P(\text{朋友}|S) \cdot P(\text{沒錢}|S) \cdot P(\text{匯款}|S) \\
&= 0.33 \cdot \left(\frac{6+1}{33}\right) \cdot \left(\frac{2+1}{33}\right) \cdot \left(\frac{7+1}{33}\right) \cdot \left(\frac{8+1}{33}\right) \\
&= 0.33 \cdot (0.2121) \cdot (0.0909) \cdot (0.2424) \cdot (0.2727) \\
&\approx \mathbf{0.000421}
\end{aligned}
信件內容:「早安,建北電資我的朋友。我沒錢,能匯款嗎」
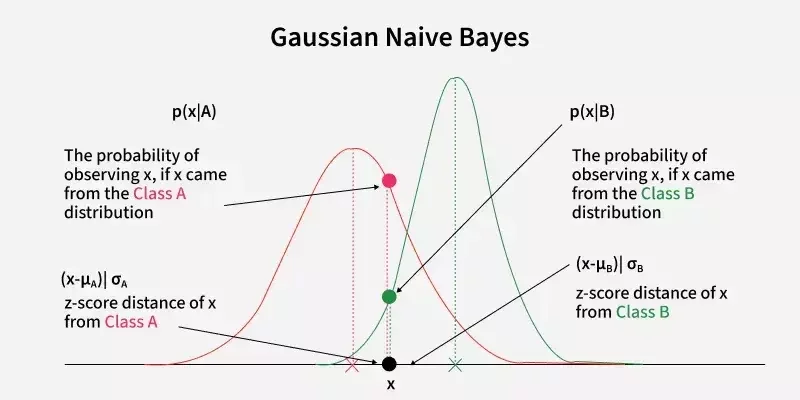
Gaussian Naive Bayes
Decision trees
決策樹 🌲
類似這種東西

電神
電神
不是電神
不是電神
不是電神
不是電神
電神
會競程
會音遊(?
睡眠時間
我們要決定哪個決策要素要放在上面的 node
吉尼不純度 Gini Impurity
G_{root} = 1 - \left[ \left(\frac{3}{6}\right)^2 + \left(\frac{3}{6}\right)^2 \right] = \mathbf{0.5}
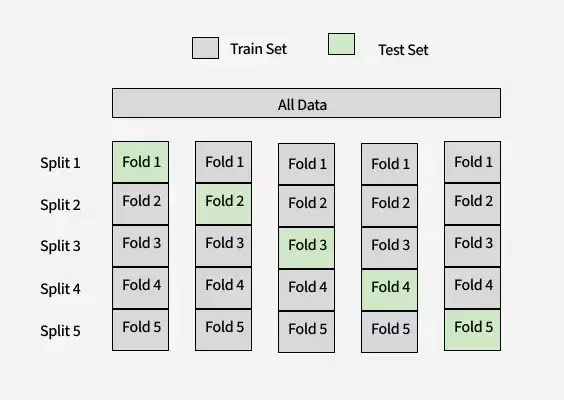
Cross validation
交叉驗證