網頁爬蟲
PY 小社課 2025/11/06
靜態網頁爬蟲
講師 Suzy
- 北資一六 學術長



網頁爬蟲
是什麼
網頁基本結構
Requests
是個python library
實作
Beautiful Soup
又是個 python library
網頁爬蟲
一個可以幫你抓取網頁上資訊的自動化工具
網頁爬蟲 web crawler
可以爬的範圍
實務應用
較容易爬到的內容:
1. 公開資訊
2. 靜態網站的內容
如果試著偷爬付費牆後面的內容通常會失敗
可以作為個人搜集資料用,也有企業會利用爬蟲來搜集行情等
法律考量
1. 只爬公開資訊
2. 不要做可能犯法的事(干擾他人商業運作、侵犯智慧財產權等)
亂爬東西是可能被告的,請自行注意,課程講師不負責喔
網頁
網頁架構 - HTML

Hypertext Markup Language
超文本標記語言(英語:HyperText Markup Language,簡稱:HTML)是一種用於建立網頁的標準標記語言。
網頁瀏覽器可以讀取HTML檔案,並將其渲染成視覺化網頁。
=網頁的主要骨架
網頁架構 - CSS
Cascading Style Sheets
階層式樣式表(英語:Cascading Style Sheets,縮寫:CSS;又稱串樣式列表、級聯樣式表、串接樣式表、階層式樣式表)是一種用來為結構化文件(如HTML文件或XML應用)添加樣式(字型、間距和顏色等)的電腦語言
=把網頁變好看

網頁架構 - Javascript
拿來增加網頁互動性用的
可以讓網頁產生動態的變化
例如:點擊東西等
=讓使用者可以和網頁互動
Javascript 的存在會增加爬蟲的難度,今天先不會提到有 JS 的內容怎麼爬

HTML
要先知道資訊會在哪,才能找東西
<!DOCTYPE html>
<html>
<head>
<title><h1> 示範網站 <h1></title>
</head>
<body>
<h2> 這是一個次標題 </h2>
<p> 這是一個段落 </p>
<a href = "https://www.google.com"> 這是一個連結 </a>
</body>
</html>
<!-- h1 到 h6 是字體由大到小喔 -->< > 是起始標籤,會對應 </ > 結束標籤
HTML
<div id="header" class="main-section"></div>
<!-- div 可以把一坨東西放在一起 --> 有時會用 = 來給予這些元素「屬性」,
今天會用到的包含:
1. id 每個元素可以有自己獨特的 id,你可以自己取
2. class 可以給予數個元素相同的 class,在做一些事情時就可以同時針對該 class 的所有元素
其他就有遇到再說吧,或是去上週五的網頁小社課
HTML
可以嘗試自己寫一個 HTML 檔案
內容包含 h1, h2, h3, p 和 a 等
寫完先存起來,晚一點會用到~
也可以參考 https://suzy12121.github.io/webscrape-sample/ 看看簡易的 HTML 結構
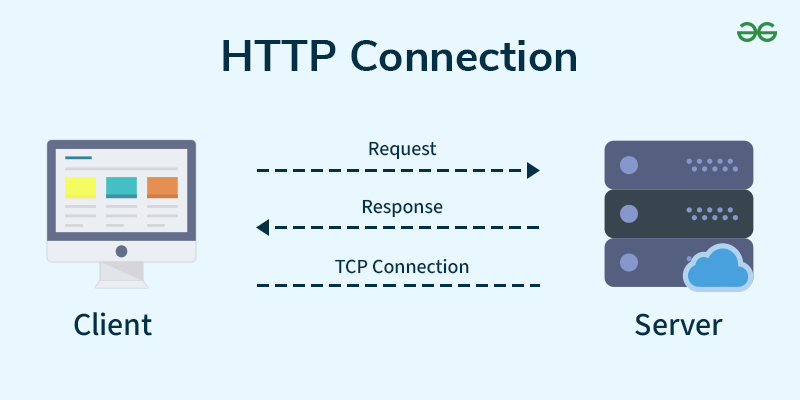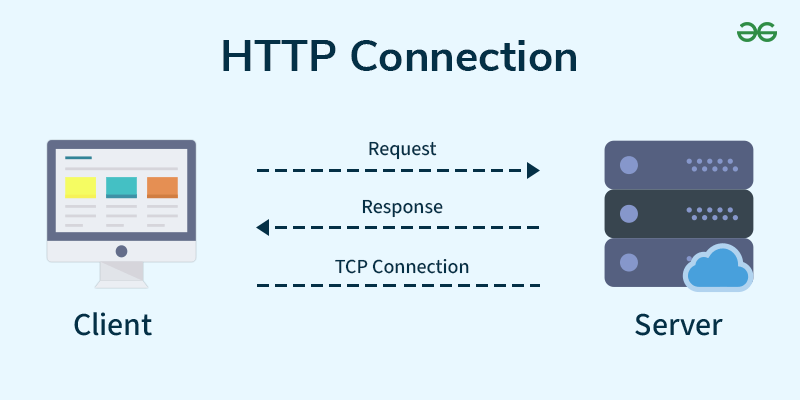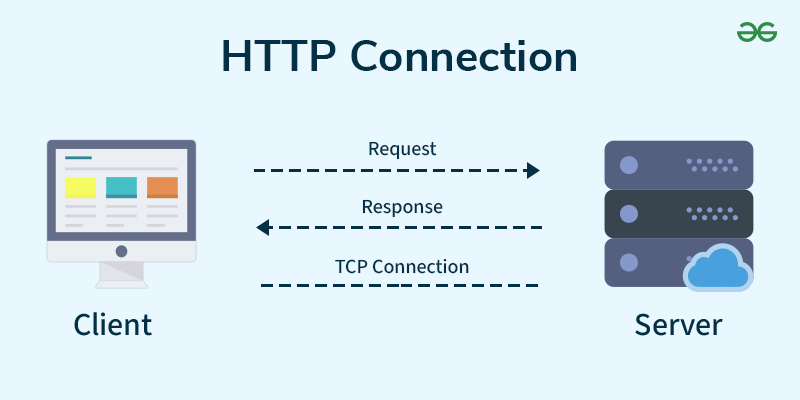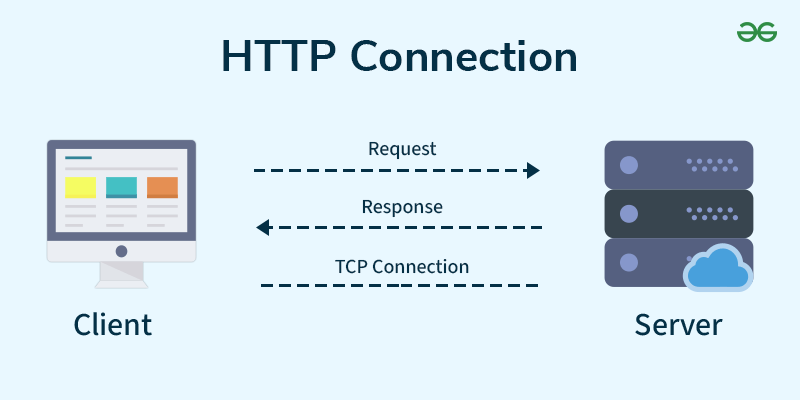
Requests
Requests
模擬你去網站看東西
pip install requests需要先把函式庫匯入
Requests
Requests
Requests 函式庫包含很多種類型的 Requests,包含 GET, POST 等等,分別針對和網站進行不同互動時使用。
import requests
r = requests.get("在這裡插入一個網址") #這樣可以送出一個 request
print(r)
print(r.content) # 輸出得到的內容- Get request: 用來取得網頁資訊
- Post Request: 用來丟東西給網頁
HTTP 狀態碼 (Status Code)
| Status code | 意思 |
|---|---|
| 2XX | 成功 |
| 3XX | 重新導向其他地方 |
| 4XX | 使用者端有問題 |
| 5XX | 伺服器端有問題 |
import requests
r = requests.get("在這裡插入一個網址") #這樣可以送出一個 request
print(r)
print(r.status_code) #輸出狀態碼處理狀態碼
為了避免程式出錯,我們可以根據不同的狀態碼做簡單處理
import requests
try:
r = requests.get("插入一個url")
response.raise_for_status()
except requests.exceptions.HTTPError as err:
print(err)requests 有內建功能 raise_for_status()
Beautiful Soup




???
Beautiful Soup
- 一個 Python 外部函式庫
- 可以分析網頁的 HTML 與 XML 文件,
- 將分析的結果轉換成「網頁標籤樹」( tag ) 的型態,讓資料讀取方式更接近網頁的操作語法
pip install BeautifulSoup4from bs4 import BeautifulSoup Load the webpage
r = requests.get ("https://zh.wikipedia.org/wiki/%E8%87%BA%E5%8C%97%E5%B8%82%E7%AB%8B%E7%AC%AC%E4%B8%80%E5%A5%B3%E5%AD%90%E9%AB%98%E7%B4%9A%E4%B8%AD%E5%AD%B8")
soup = BeautifulSoup(r.content, 'html parser')request 網頁的內容
並用 BeautifulSoup ( ) 把內容變成一個 BeautifulSoup 的物件
有些網站要求需要加上 HTTP 頭欄位 (headers) 才能爬
HTTP頭欄位(英語:HTTP header fields)是指在超文字傳輸協定(HTTP)的請求和回應訊息中的訊息頭部分。它們定義了一個超文字傳輸協定事務中的操作參數。
Load the webpage
例:維基百科的爬蟲規範

沒用 user agent 會被擋
要依照 robots.txt 的規定
429 就是太多 requests 了
我們可以直接看自己的瀏覽器是的 header 是什麼,然後複製過去用
在網頁中滑鼠右鍵 inspect
選 Network
從左邊欄任選一個 request
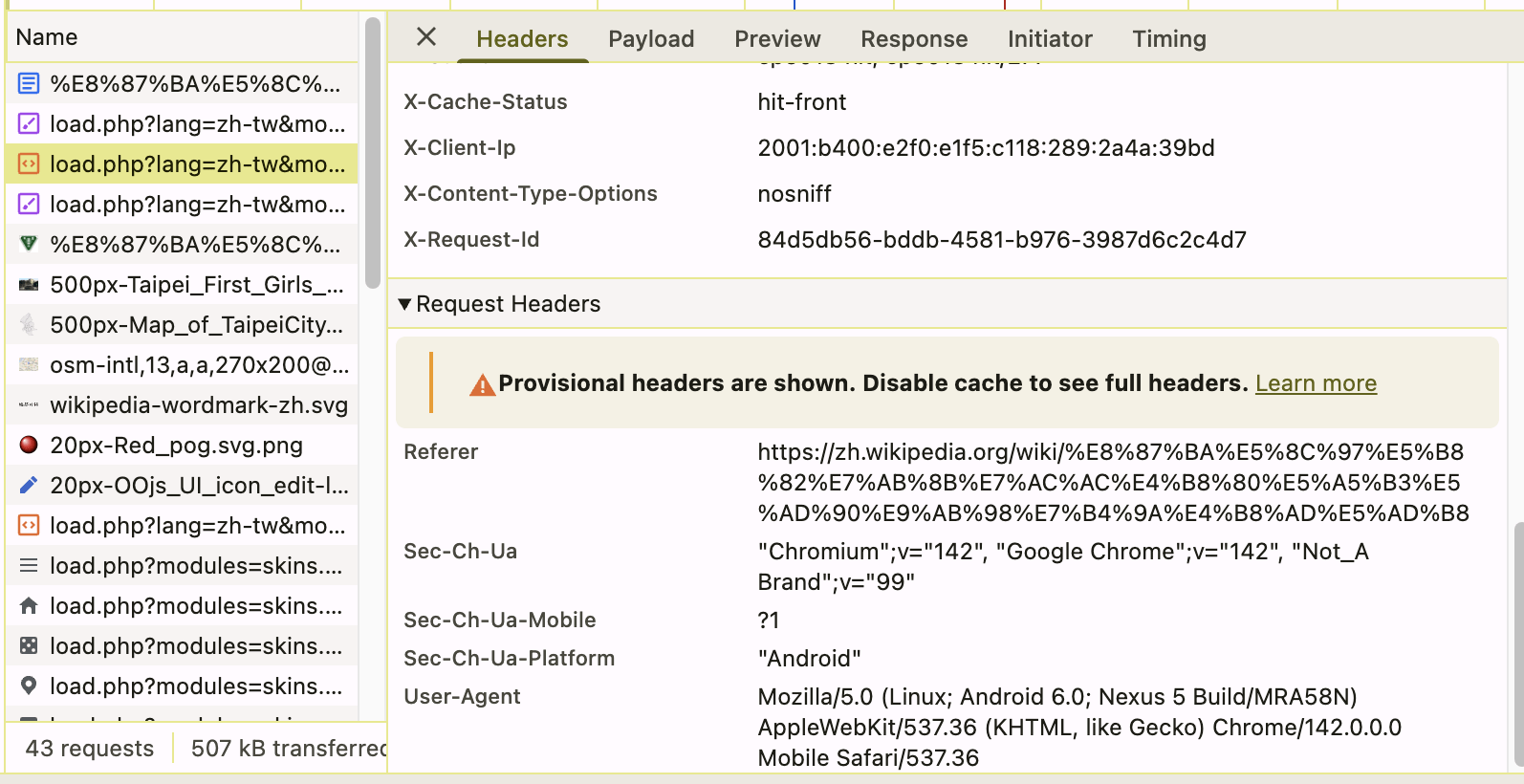
接著往下滑直到看到
Reqeust Headers
複製 User-Agent 或其他有必要的資訊
r = requests.get("url", headers={'User-Agent': 'Mozilla/5.0'})
soup = BeautifulSoup(r.content, 'html parser')Parser(解析器)是一種軟體程式,用於分析輸入的文本(例如程式碼、HTML、JSON 等)並將其轉換為一種結構化的資料表示,例如語法分析樹。它通常是編譯器、直譯器、網頁瀏覽器等軟體的重要組件,其主要功能是檢查語法,並將文本「解碼」為機器或程式更容易處理的結構。
把 HTML 內容變成一個 BeautifulSoup 的物件
網頁上的HTML
HTML parser
BeautifulSoup 可以看得懂的東西
print(soup.prettify()).prettify() 會把 HTML 對齊變好看,並變成一個字串
可以拿來 print () 出來看
first_header = soup.find("h1")
headers = soup.find_all("h1")Find
.find () 會找到該元素第一次出現的地方
.find_all () 則會找到該元素所有出現的地方,並整理成一個 list
headers_onetwo = soup.find_all(["h1", "h2"])也可以一次找很多個東西
註:這裡的 header 指的是 HTML header (頁首元素),和 HTTP request 的 header 不一樣喔
print(headers) Find
會輸出整個 HTML, 例: <h1>..... <\h1>
print(headers.string) .string 可以只拿到內容文字的部分
div = soup.find("div")
print(div.get_text())若是要輸出的東西有很多 children
就要使用 .get_text()
link = soup.find("a")
print(link['href']) 也可以輸出該元素的特定屬性
paragraphs = soup.select("p#paragrph-id")CSS selector
用 # 可以透過 id 找東西
例:找 id 是 paragrph-id 的 段落
elements = soup.select('.classname') 用 . 可以找 class 裡的東西
element = soup.select_one('a[href="https://example.com"]')
print(element.text)用 [] 可以用屬性找東西
實作
1. 把你剛剛自己寫的 HTML 打開,使用剛剛的技巧抓取內容
2. 練習抓維基百科的內文,並把不必要的內容處理乾淨
更多範例 (google colab)
提示:文章在 <p> </p> 裡面
冷知識: BeautifulSoup 為何叫 BeautifulSoup
tag soup 拿來指結構凌亂的 HTML
創辦人 Leonard Richardson 以 《愛麗絲夢遊仙境》為靈感幫這個套件取了名子

Beautiful Soup 之歌
其他爬蟲工具

Selenium
一個網頁自動化測試的套件,擁有許多網頁操作的方法
能處理動態網站(Javascript 等)
一樣都是用 Python 做

Scrapy
本身就是一個網頁爬蟲框架,提供完整的網頁爬蟲開發功能,執行速度快,但較難上手
一定要用爬蟲嗎
其實不一定,部分網站會提供自己的 API (Application Programming Interface) ,使用起來可能較方便

(滿貼切的梗圖(?