Intern Meeting
2023/06/30
Global Planning for Contact-rich Manipulation: Overview of Steps
Step 1. Build goal-conditioned input / output sets with contact dynamics
Step 2. Build GCS out of these input / output sets
Step 3. Experimental testing on simulation and hardware
I will share progress & attempts on this front for the meeting.
Recap of Problem
For some discrete-time system , find some tuple such that the policy stabilizes all to
It took a while to define what exactly the input/output portals refer to.
Attempt 1. Goal-conditioned Policies
Challenges & Questions:
1. How do we get these goal-conditioned (a.k.a. universal) policies?
2. How do we represent these sets?
Attempt 1. Stochastic Policy Optimization (RL)
In universal policy formulation, we can try to solve a stochastic policy optimization problem:
There is a chicken-and-egg problem between size of the sets and the ease of policy optimization.
1. How do we set the initial and goal sets? If they are too large, policy optimization is not
successful. Even if they are, there's no point since the whole point of our approach is to
decompose the problem into easier problems.
2. On the other hand, if they are too small, the resulting size of the graph is too large.
Attempt 1. Stochastic Policy Optimization (RL)
Performance of Policy Optimization with single goal
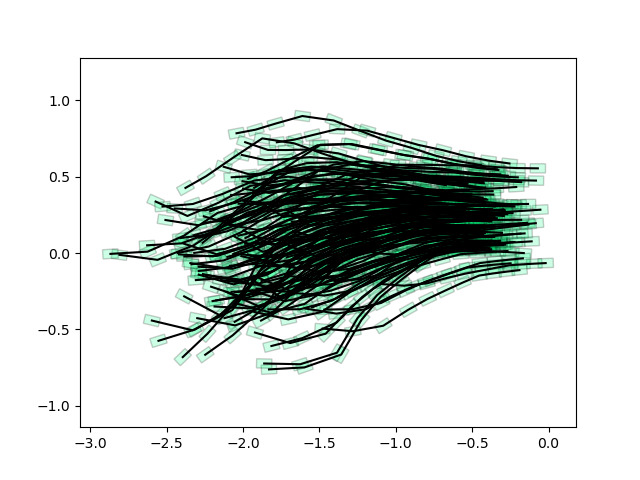
Policy with Time-varying gains and biases
Neural network policy
Not quite doing the job as well as I hoped.... Maybe because the initial set was not good?
Attempt 1. Stochastic Policy Optimization (RL)
Not quite doing the job as well as I hoped.... Maybe because the initial set was not good?
Iterative Refinement of the Initial Set
1. Solve the policy optimization problem from sample ellipsoid.
2. Perform weighted PCA on the initial set with weights
3. Sample from refined ellipsoid, repeat.
Some factors led me to abandon this route.
1. Policy optimization is a bit costly to use as an inner routine in an alternation scheme.
2. At the same time, performance of PO was not that good when we care about reaching the goal exactly.
3. Many hyperparameters. How do we set reliably temperature parameter?
4. At the time, Pang was looking into LQR solutions with more promising results!
Re-usable Parts from this attempt.
I have a pretty good single-shooting optimization algorithm for trajectory optimization!
Re-usable Parts from this attempt.
The solver supports three modes of estimating gradients
1. Policy Gradient Trick:
2. Autodiff computation graph with numerical gradients:
3. Autodiff computation graph with randomized gradients:
Inject Gaussian noise at output of the policy
Do autodiff computations on the gradient, but approximate dynamic gradients with finite differences.
Do autodiff computations on the gradient, but approximate dynamic gradients with least-squares estimation of the gradient.
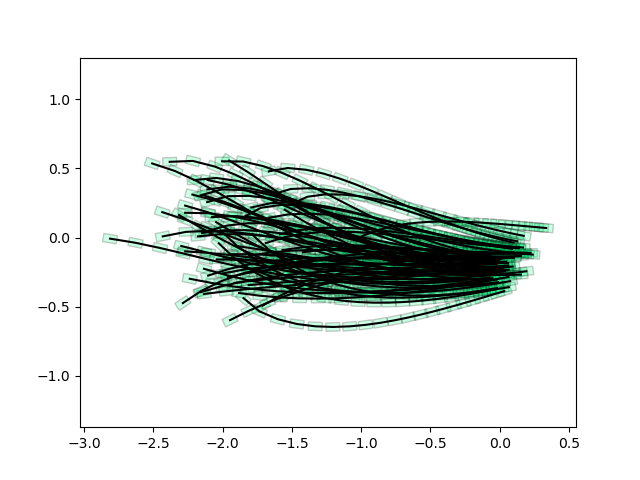
Trajopt Results
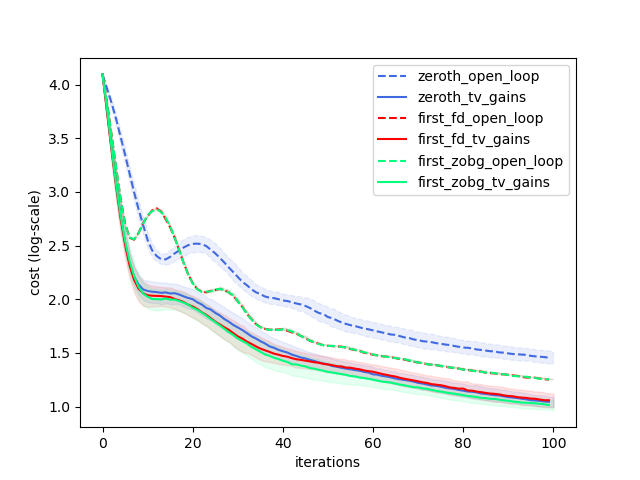
Trajopt significantly "easier" than policyopt, works quite reliably for now.
1. Having closed-loop gains to optimize makes a large difference in performance.
2. First-order optimizers more performant than the policy gradient trick.
Randomized vs. Finite Differences.

Attempt 2. Forwards Reachability
For some discrete-time system , find some tuple such that the policy stabilizes all to
Attempt 1. Goal-conditioned Policies
Lessons: Directly optimizing for such policies is difficult. What if we don't ask for feedback-stabilizable set of goal points, but are willing to incorporate open-loop trajectories?
Attempt 2. Forwards Reachable Sets Robust to Disturbances on Initial Conditions
For some discrete-time system , given some set of initial conditions ,
Find where the definition is:
Attempt 2. Robust Forward Reachable Sets
Forwards Reachable Sets Robust to Disturbances on Initial Conditions
For some discrete-time system , given some set of initial conditions ,
Find where the definition is:
Attempt 2. Robust Forward Reachable Sets
Specialization to Ellipsoids on LTV systems
Set of finial conditions is characterized by Finite Impulse Response (FIR)
If is zero, the reachable set under the constraint is given by
Suppose we solve trajopt for some nominal trajectory , and describe dynamics of disturbances with time-varying linearizations along this trajectory,
where .
Note that this Minkowski sum results in a convex body with a unique minimum volume outer ellipsoid (MVOE), which can be solved with SDPs / Picard iterations. Denote this MVOE with .
Attempt 2. Robust Forward Reachable Sets
What is we want to solve for nonzero disturbances?
Let denote parameters of the MVOE such that
We can rewrite the FIR as a simple equation:
In addition, suppose that the uncertainty set for the initial condition is contained within some ellipsoid with quadratic form
What can we say about the set of such that there exists a point such that no matter what the adversary picks in , we can achieve ?
where we the image of this set through the linear map A becomes
Second Route: The Bottleneck Hypothesis
Intuition: Depending on the geometry, the intersection of all these cones for the reachable sets are necessarily bottlenecked around some location around the nominal trajectory.
Note that the true picture is far more complicated. x0 is an hyperellipsoid, and all time-slices of the cones are all hyperellipsoids.
Second Route: The Bottleneck Hypothesis
But these are far practical to compute if we fix a point.
x0: Backwards Reachable Set
Do TV-LQR along the red trajectory along its linearization, and determine ROA with line search.
x_{T+1}: Forward Reachable Set
Compute MVOE along the blue trajectory, already explained how to compute this given a fixed initial condition.
Bottleneck Hypoethesis: Suppose we fix a point and compute these forward / backward sets. Is there some initial region, rho, and gamma, such that this is the solution to the robust reachable sets problem?
Second Route: The Bottleneck Hypothesis
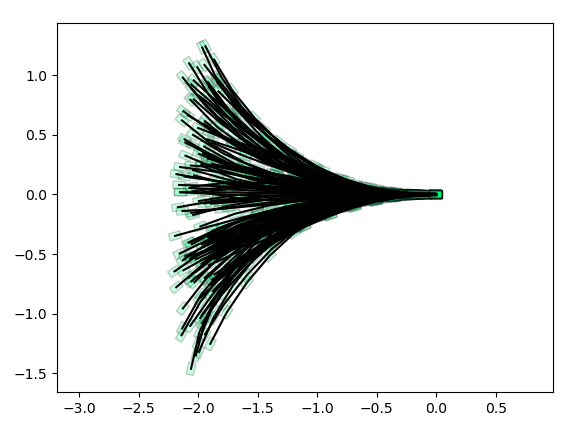
Backwards Reachable
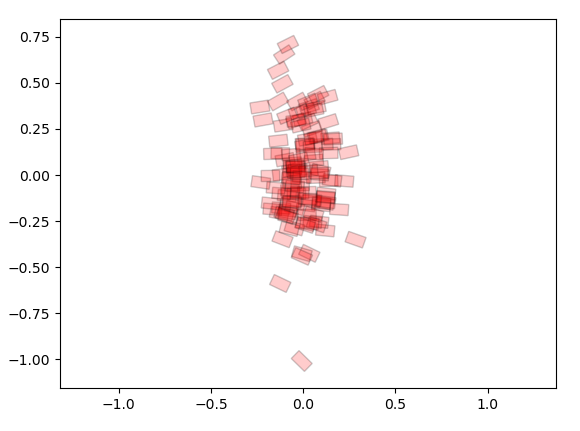
Forwards Reachable