Using MongoDB
to build a fast and scalable Content Repository

Some Context
What we Do and What Problems We Try to Solve

Nuxeo
we provide a Platform that developers can use to
build highly customized Content Applications
we provide components, and the tools to assemble them
everything we do is open source
various customers - various use cases


Track game builds
Electronic Flight Bags
Central repository for Models
Food industry PLM
https://github.com/nuxeo


DOCUMENT REPOSITORY


SQL based Repository - VCS

KEY Limitations of the SQL approach
-
Impedance issue
- storing Documents in tables is not easy
-
requires Caching and Lazy loading
-
Scalability
- Document repository can become very large (versions, workflows ...)
-
scaling out SQL DB is very complex (and never transparent)
-
Concurrency model
- Heavy write is an issue (Quotas, Inheritance)
- Hard to maintain good Read & Write performances

Need a different
storage model !

No SQL

Integrating MongoDB
Inside nuxeo-dbs storage adapter
FROM SQL to MongoDB Storage


Document base Storage & Mongodb

Storing Nuxeo Documents in MongoDB
{
"ecm:id":"52a7352b-041e-49ed-8676-328ce90cc103",
"ecm:primaryType":"MyFile",
"ecm:majorVersion":NumberLong(2),
"ecm:minorVersion":NumberLong(0),
"dc:title":"My Document",
"dc:contributors":[ "bob", "pete", "mary" ],
"dc:created": ISODate("2014-07-03T12:15:07+0200"),
...
"cust:primaryAddress":{
"street":"1 rue René Clair", "zip":"75018", "city":"Paris", "country":"France"},
"files:files":[
{ "name":"doc.txt", "length":1234, "mime-type":"plain/text",
"data":"0111fefdc8b14738067e54f30e568115"
},
{
"name":"doc.pdf", "length":29344, "mime-type":"application/pdf",
"data":"20f42df3221d61cb3e6ab8916b248216"
}
],
"ecm:acp":[
{
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]
}]
...
}-
40+ fields by default
- depends on config
- 18 indexes
hIERARCHY & Security
- Parent-child relationship
-
Recursion optimized through array
ecm:parentId
ecm:ancestorIds
{ ... "ecm:parentId" : "3d7efffe-e36b-44bd-8d2e-d8a70c233e9d",
"ecm:ancestorIds" : [ "00000000-0000-0000-0000-000000000000",
"4f5c0e28-86cf-47b3-8269-2db2d8055848",
"3d7efffe-e36b-44bd-8d2e-d8a70c233e9d" ] ...}- Generic ACP stored in ecm:acp field
- Precomputed Read ACLs to avoid post-filtering on search
ecm:racl: ["Management", "Supervisors", "bob"]{... "ecm:acp":[ {
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]}] ...}SEARCH
db.default.find({
$and: [
{"dc:title": { $in: ["Workspaces", "Sections"] } },
{"ecm:racl": {"$in": ["bob", "members", "Everyone"]}}
]
}
)SELECT * FROM Document WHERE dc:title = 'Sections' OR dc:title = 'Workspaces'
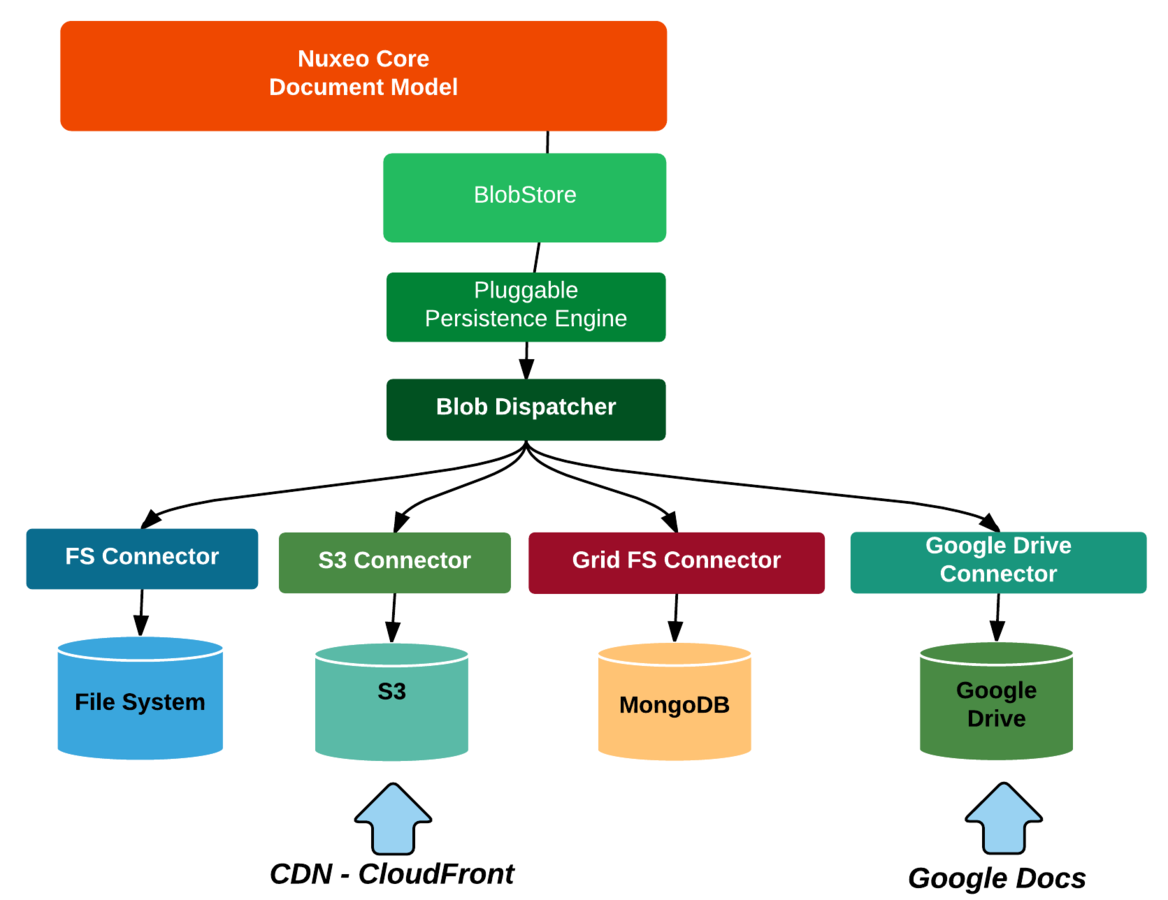
Storing Blobs
About Consistency
- Atomic Document Operations are safe
-
Large batch updates is not so much of an issue
- Multi-documents transactions are an issue
- ex: Workflows
Find a way to mitigate consistency issues
Transactions can not span across multiple documents
Mitigating consistency issues
-
Transient State Manager
- Run all operations in Memory
- Populate an Undo Log
- Recover
partial Transaction Management
-
Commit / Rollback model
-
Commit / Rollback model
-
"Read uncommited" isolation
- Need to flush transient state for queries
- "uncommited" changes are visible to others

Hybrid Storage Architecture
-
MongoDB
-
store structure & streams in a BASE way
-
-
elasticsearch
-
provide powerful and scalable queries
-
-
SQL DB
-
store structures in an ACID way
-
Storage does not impact application : this can be a deployment choice!

A
tomic
C
onsistent
I
solated
D
urable
B
asic
A
vailability
S
oft state
E
ventually consistent
depends on Availability & Performances requirements
Nuxeo + MongoDB
Supercharge your Content Repository
No SQL with Mongodb
-
No Impedance issue
-
One Nuxeo Document = One MongoDB Document
-
One Nuxeo Document = One MongoDB Document
-
No Scalability issue
for CRUD
-
native distributed architecture allows scale out
-
native distributed architecture allows scale out
-
No Concurrency
performance
issue
-
Document Level "Transactions"
-
Document Level "Transactions"
-
No
application level cache is needed
- No need to manage invalidations

Is Nuxeo Fast
with mongodb ?
Nighly CI Benchmarks
Low level read
(fast re-indexing with elasticsearch)
-
3,500 documents/s using SQL backend
-
10, 000 documents/s using MongoDB
Raw Java API performances
Single Server
6 core HT 3.5Ghz
126 GB RAM
std hdd

about 3 times faster
NIGHLY CI BENCHMARKS
Raw Http API performances
Single Server
6 core HT 3.5Ghz
126 GB RAM
std hdd
Storage is no longer the bottleneck

HUGE Repository - Heavy loading
SQL DB Collapse / MongoDB handles the volume
Massive number
of documents
Automatic versioning
Write intensive
Daily Imports
Benchmarking Mass Import


SQL
with tunning


commodity hardware
SQL
7x faster
Benchmarking Read + Write


Read & Write Operations
are competing
Write Operations
are not blocked
C4.xlarge (nuxeo)
C4.2Xlarge (DB)
SQL
Data LOADING Overflow
Processing on large Document sets are an issue on SQL
Side effects of impedance miss match
Ex: Process 100,000 documents
- 750 documents/s with SQL backend (cold cache)
-
9,500 documents/s with MongoDB / mmapv1: x13
-
11,500 documents/s with MongoDB / wiredTiger: x15

lazy loading
cache trashing
Benchmarking Scale out
-
1 Nuxeo node + 1 MongoDB node
-
1900 docs/s
-
MongoDB CPU is the bottleneck (800%)
-
-
2 Nuxeo nodes + 1 MongoDB node
-
1850 docs/s
-
MongoDB CPU is the bottleneck (800%)
-
-
2 Nuxeo nodes + 2 MongoDB nodes
-
3400 docs/s when using read preferences
-



Use massive read operations and queries.


Document repository
is Fast
with MongoDB
So, Yes !
Example use case ?
VOD repository
-
Requirements:
- store videos
- manage meta-data & availability
- manage workflows
- generate thumbs & conversions
- Very Large Objects:
- lots of meta-data (dublincore, ADI, ratings ...)
- Massive daily updates
- updates on rights and availability
- Need to track all changes
- prove what was the availability for a given date
Real life project choosing Nuxeo with MongoDB backend


good use case
for MongoDB
want to use MongoDB
lots of data + lots of updates
Any Questions ?
Thank You !
https://github.com/nuxeo
http://www.nuxeo.com/careers/