Using MongoDB
to build a fast and scalable Content Repository

Some Context
What we Do and What Problems We Try to Solve

Nuxeo
-
Nuxeo
- we provide a Platform that developers can use to build highly customized Content Applications
- we provide components, and the tools to assemble them
-
everything we do is open source (for real)
- various customers - various use cases
- me: developer & CTO - joined the Nuxeo project 10+ years ago


Track game builds
Electronic Flight Bags
Central repository for Models
Food industry PLM
https://github.com/nuxeo


Document Oriented Database
Document Repository
Store JSON Documents
Manage Document attributes,
hierarchy, blobs, security, lifecycle, versions
DOCUMENT REPOSITORY & Storage Abstraction
-
Be able to choose the right storage
-
depending on the constraints
- Large volume, ACID constraints
-
depending on the envrionment
-
Test, Dev, Production
-
Test, Dev, Production
-
depending on the constraints
-
Make it transparent
- at the code level
- at the query level

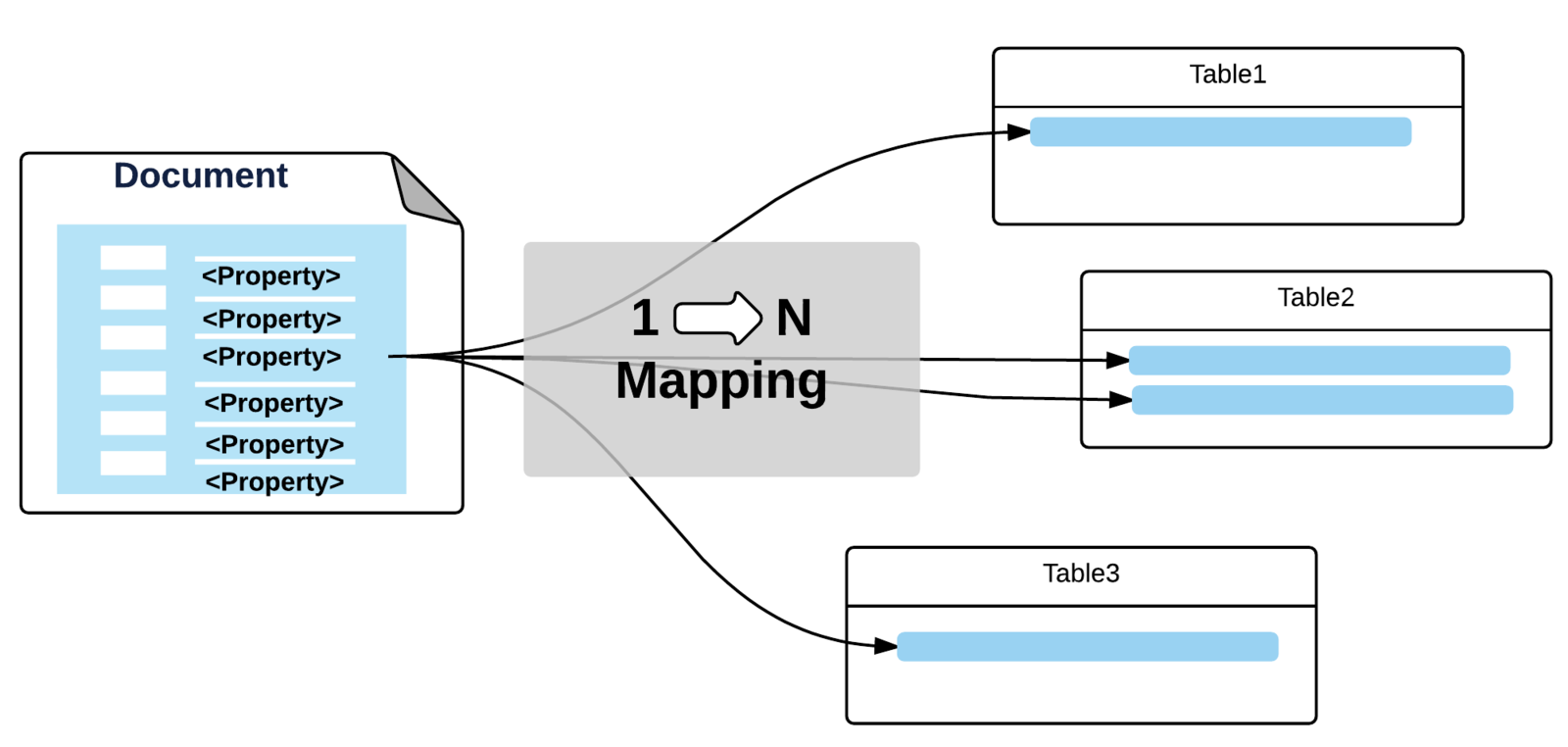
Document Repository & Model
-
Content Model
- define Types (schemas)
- define Facets (mixins)
- define Hierarchy
-
define Relationships
-
But this is not schema-less ?!
-
Applications always have an implicit schema : the model
- better manage this as a configuration than simply "hope for the best"
-
the important part is to not have to handle the schema by hand
- data structure mapping & validation
-
Applications always have an implicit schema : the model

Document Repository
- Manage Data level Security
- Document level permissions
-
Blob level permissions
-
Versioning
-
Keep track of changes
-
Keep track of changes
-
Life-Cycle
-
Define valid states
-
Define valid states
-
Blob management
- Efficient storage & CDN

History : Nuxeo repository & Storage
-
2006: Nuxeo Repository is based on ZODB (Python / Zope based)
-
This is not JSON in NoSQL, but Python serialization in ObjectDB
-
Conccurency and performances issues, Bad transaction handling
-
-
2007: Nuxeo Platform 5.1 - Apache JackRabbit (JCR based)
-
Mix SQL + Java Serialization + Lucene
-
Transaction and consistency issues
-
-
2009: Nuxeo 5.2 - Nuxeo VCS
-
SQL based repository : MVCC & ACID
-
very reliable, but some use cases can not fit in a SQL DB !
-
-
2014: Nuxeo 5.9 - Nuxeo DBS
-
Document Based Storage repository
-
MongoDB is the reference backend
-
Object DB
Document DB
SQL DB
From Sql to NoSQL
Understanding the motivations
for moving to MongoDB
SQL based Repository - VCS
Search API is the most used :
search is the main scalability challenge

KEY Limitations of the SQL approach
- Impedance issue
- storing Documents in tables is not easy
-
requires Caching and Lazy loading
-
Scalability
- Document repository can become very large (versions, workflows ...)
-
scaling out SQL DB is very complex (and never transparent)
-
Concurrency model
- Heavy write is an issue (Quotas, Inheritance)
- Hard to maintain good Read & Write performances

Need a different storage model !
From SQL to No SQL


No SQL with Mongodb
-
No Impedance issue
-
One Nuxeo Document = One MongoDB Document
-
One Nuxeo Document = One MongoDB Document
-
No Scalability issue for CRUD
-
native distributed architecture allows scale out
-
native distributed architecture allows scale out
-
No Concurrency performance issue
-
Document Level "Transactions"
-
Document Level "Transactions"
-
No application level cache is needed
- No need to manage invalidations
REALLY ?
Let's do some benchmarks of Nuxeo + MongoDB
to check that it is true!
Continuous Benchmarks
-
Low level read (fast re-indexing with elasticsearch)
-
3,500 documents/s using SQL backend
-
10,000 documents/s using MongoDB (+180%)
-
- Read via REST API (misc Read APIs)
- Update via REST API
Raw performances
Single Server
6 core HT 3.5Ghz
126 GB RAM
std hdd

Benchmarking Mass Import


SQL
with tunning


commodity hardware
SQL
Benchmarking Scale out
-
1 Nuxeo node + 1 MongoDB node
-
1900 docs/s
-
MongoDB CPU is the bottleneck (800%)
-
-
2 Nuxeo nodes + 1 MongoDB node
-
1850 docs/s
-
MongoDB CPU is the bottleneck (800%)
-
-
2 Nuxeo nodes + 2 MongoDB nodes
-
3400 docs/s when using read preferences
-



Adding one MongoDB node adds 80% throughput
Use massive read operations and queries.
Benchmarking Scale out
-
Yes: this kind of setup is possible using SQL DB too
-
But:
-
setup is usually not that simple
-
MongoDB ReplicatSet is easy
-
-
impacts at Transaction Manager level
-
read-only routing encapsulated in MongoDB client
-
-
Impact on Nuxeo

-
Faster: for both Read and Write
-
Volume: on commodity hardware
-
Architecture: scale out compliant
That's why we integrated MongoDB
let's see the technical details
Integrating MongoDB
Inside nuxeo-dbs storage adapter
Document base Storage & Mongodb

Document base Storage & Mongodb

Storing Nuxeo Documents in MongoDB
- a Nuxeo Repository is a MongoDB Collection
-
a Nuxeo Application can be connected to several repositories
-
a Nuxeo Application can be connected to several repositories
- Documents are stored using their JSON representation
-
Property names fully prefixed
- Lists as arrays of scalars
- Complex properties as sub-documents
- Complex lists as arrays of sub-documents
-
Id generated by Java UUID
• In debug mode : Counter using findAndModify, $inc and returnNew
-
Property names fully prefixed
Storing Nuxeo Documents in MongoDB
{
"ecm:id":"52a7352b-041e-49ed-8676-328ce90cc103",
"ecm:primaryType":"MyFile",
"ecm:majorVersion":NumberLong(2),
"ecm:minorVersion":NumberLong(0),
"dc:title":"My Document",
"dc:contributors":[ "bob", "pete", "mary" ],
"dc:created": ISODate("2014-07-03T12:15:07+0200"),
...
"cust:primaryAddress":{
"street":"1 rue René Clair", "zip":"75018", "city":"Paris", "country":"France"},
"files:files":[
{ "name":"doc.txt", "length":1234, "mime-type":"plain/text",
"data":"0111fefdc8b14738067e54f30e568115"
},
{
"name":"doc.pdf", "length":29344, "mime-type":"application/pdf",
"data":"20f42df3221d61cb3e6ab8916b248216"
}
],
"ecm:acp":[
{
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]
}]
...
}-
40+ fields by default
- depends on config
- 18 indexes
hIERARCHY
- Parent-child relationship
-
Recursion optimized through array
• Maintained by framework (create, delete, move, copy)
ecm:parentId
ecm:ancestorIds
{ ...
"ecm:parentId" : "3d7efffe-e36b-44bd-8d2e-d8a70c233e9d",
"ecm:ancestorIds" : [ "00000000-0000-0000-0000-000000000000",
"4f5c0e28-86cf-47b3-8269-2db2d8055848",
"3d7efffe-e36b-44bd-8d2e-d8a70c233e9d" ]
...}Security
- Generic ACP stored in ecm:acp field
- Precomputed Read ACLs to avoid post-filtering on search
• Simple set of identities having access
• Semantic restrictions on blocking
• Maintained by framework
• Search matches if intersection
ecm:racl: ["Management", "Supervisors", "bob"]db.default.find({"ecm:racl": {"$in": ["bob", "members", "Everyone"]}}){...
"ecm:acp":[ {
name:"local",
acl:[ { "grant":false, "perm":"Write", "user":"bob"},
{ "grant":true, "perm":"Read", "user":"members" } ]}]
...}SEARCH
db.default.find({
$and: [
{"dc:title": { $in: ["Workspaces", "Sections"] } },
{"ecm:racl": {"$in": ["bob", "members", "Everyone"]}}
]
}
)SELECT * FROM Document WHERE dc:title = 'Sections' OR dc:title = 'Workspaces'
Consistency Challenges
- Unitary Document Operations are safe
- No impedance issue
-
Large batch updates is not so much of an issue
-
SQL DB do not like long running transactions anyway
-
SQL DB do not like long running transactions anyway
- Multi-documents transactions are an issue
- Workflows is a typical use case
- Isolation issue
- Other transactions can see intermediate states
- Possible interleaving
Find a way to mitigate consistency issues
Transactions can not span across multiple documents


Mitigating consistency issues
-
Transient State Manager
-
Run all operations in Memory
- Flush to MongoDB as late as possible
-
Populate an Undo Log
- Replay backward in case of Rollback
-
Run all operations in Memory
- Recover partial Transaction Management
-
Commit / Rollback model
-
Commit / Rollback model
- But complete isolation is not possible
- Need to flush transient state for queries
-
"uncommited" changes are visible to others
- "read uncommited" at best
Speed vs TRANSACTIONS Reliability
- This is still far from being ACID, but
-
it converges to something consistent
- Eventually consistent
-
we improved Isolation and Atomicity
-
it converges to something consistent
- Usual trade-off between speed and consistency
- This is good enough for most use cases
-
Even in pure SQL there are some concessions on ACID
- ex : read commited vs repeatable reads

When to use MongoDB over traditional SQL ?
MongoDB repository
Typical use cases
There is not one unique solution
-
Use each storage solution for what it does the best
-
SQL DB
-
store content in an ACID way
-
consistency over availability
-
-
MongoDB
-
store content in a BASE way
-
availability over consistency
-
-
elasticsearch
-
provide powerful and scalable queries
-
-
Storage does not impact application : this can be a deployment choice!

Atomic Consistent
Isolated Durable
Basic Availability
Soft state
Eventually consistent
Ideal use cases for Mongodb
HUGE Repository - Heavy loading
-
Massive amount of Documents
-
x00,000,000
-
Automatic versioning
- create a version for each single change
- create a version for each single change
-
x00,000,000
-
Write intensive access
- daily imports or updates
-
recursive updates (quotas, inheritance)
SQL DB collapses (on commodity hardware)
MongoDB handles the volume

Benchmarking Read + Write


Read & Write Operations
are competing
Write Operations
are not blocked
C4.xlarge (nuxeo)
C4.2Xlarge (DB)
SQL
Benchmarking Mass Import
- Import 20,000 documents
- 750 documents/s with SQL backend
- 1,400 documents/s with MongoDB/mmapv1
-
3,200 documents/s with MongoDB/wiredTiger
-
Import 100,000 documents
- 550 documents/s with SQL backend
- 1,250 documents/s with MongoDB/mmapv1
- 3,150 documents/s with MongoDB/wiredTiger
low level import on AWS

about 5x faster !
Data LOADING Overflow
-
Lot of lazy loading
- Very large Objects = lots of fragments
-
lot of lazy loading = create latency issues
-
Cache trashing issue
- SQL mapping requires caching
- read lots of documents inside a single transaction
MongoDB has no impedance mismatch
- no lazy loading
- fast loading of big documents
- no need for 2nd level cache

Side effects of impedance miss match
Benchmarking impedance effect
- Process 20,000 documents
- 700 documents/s with SQL backend (cold cache)
-
6,000 documents/s with MongoDB / mmapv1: x9
-
11,000 documents/s with MongoDB / wiredTiger: x15
-
Process 100,000 documents
- 750 documents/s with SQL backend (cold cache)
-
9,500 documents/s with MongoDB / mmapv1: x13
-
11,500 documents/s with MongoDB / wiredTiger: x15
- Process 200,000 documents
- 750 documents/s with SQL backend (cold cache)
-
14,000 documents/s with MongoDB/mmapv1: x18
-
11,000 documents/s with MongoDB/wiredTiger: x15
processing benchmark
based on a real use case

ROBUST architecture
native distributed architecture
- ReplicaSet : data redundancy & fault tolerance
- Geographically Redundant Replica Set : host data on multiple hosting sites

active
active
A REAL LIFE EXAMPLE
A real life example - Context
-
Who: US Network Carrier
-
Goal: Provide VOD services
- Requirements:
- store videos
- manage meta-data
- manage workflows
- generate thumbs
- generate conversions
- manage availability
They chose Nuxeo to build their Video repository

A real life example - Challenges
- Very Large Objects:
-
lots of meta-data (dublincore, ADI, ratings ...)
-
lots of meta-data (dublincore, ADI, ratings ...)
- Massive daily updates
-
updates on rights and availability
-
updates on rights and availability
- Need to track all changes
- prove what was the availability for a given date
looks like a good use case for MongoDB
lots of data + lots of updates


A real life example - MongoDB choice
-
because they have a good use case for MongoDB
-
Lots of large objects, lots of updates
-
Lots of large objects, lots of updates
-
because they wanted to use MongoDB
- change work habits (Opensouces, NoSQL)
- doing a project with MongoDB is cool
they chose MongoDB

they are happy with it !
Next steps
Going further with MongoDB
Next steps
- Leverage more the MongoDB Batch API
- expose similar Batch API at Nuxeo level
-
use inside DBS internal implementation
- Make Write Concerns levels configurable
-
allow to fire "async processing"
-
allow to fire "async processing"
- Use GridFS for Blob storage
- store everything inside MongoDB cluster
Any Questions ?
Thank You !
https://github.com/nuxeo
http://www.nuxeo.com/careers/