
Managing Pipelines in Test Automation
John Hill Automation Engineer - Ansible
Overview
- What are pipelines?
- Where do Test Engineers fit in the pipeline?
- Pipeline Tooling
- How to Manage Test Pipelines
- Unsolved Pipeline Management Problems
- Where the industry is trending
Where did Pipelines come from?
Out of the Continuous Delivery movement authored by Jez Humble in 2011

What does it cost to release one line of code
Deployment Pipeline
A deployment pipeline is, in essence, an automated implementation of your application's build, deploy, test, and release process.
AKA The "Ops" Pipeline
Pipelines likely came out of Operations because they were the last ones holding the baton.
What is a pipeline for the rest of us?
- A pipeline is a model which structures software development as a sequence stages
- Each stage already exists in most organizations, but pipelines enforces an automated link between them
Typical Dev Pipeline
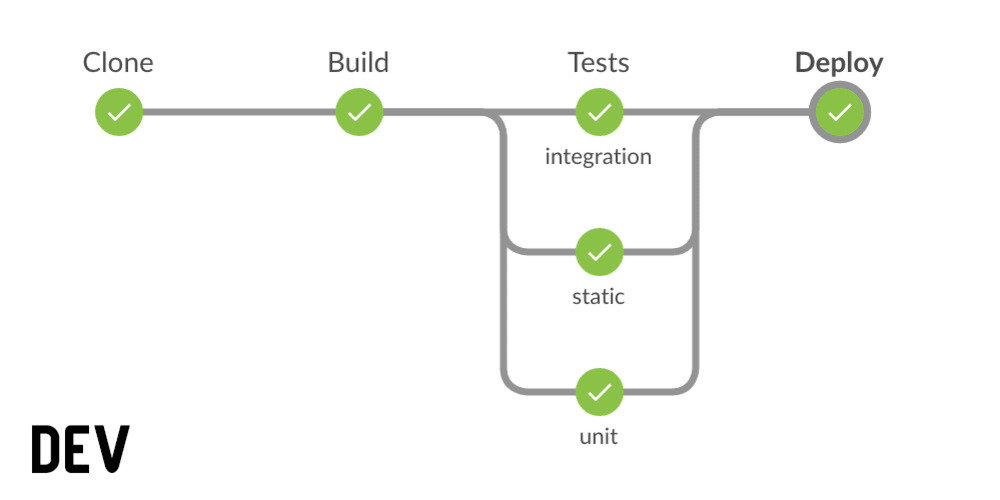
(Continuous Integration)
Anatomy of a Pipeline
- Structure
- Input = Repository in Source Control
- Stages = Packaging or Testing in between
- Links between stages
- Output = Next stage on the assembly line
- Software changes "flow" through this structure to be blocked before the output
Where do we fit as test engineers?

"Test Pipeline" or Test Stage?

Both!

What is a "Test pipeline" for a Test Engineer?
- Input = After Unit tests complete
- Stages = Regression Suites to Run
- Output = The OK to Release
What isn't a Pipeline?
- Pipelines =/= Continuous Deployment
- Hands-free Assembly line
- Zero QA
Technically...

Let's Build One
Jenkins Visual Pipeline Editor
Other Pipeline Tool Examples

Gitlab Pipeline Graph
Other Pipeline Tool Examples
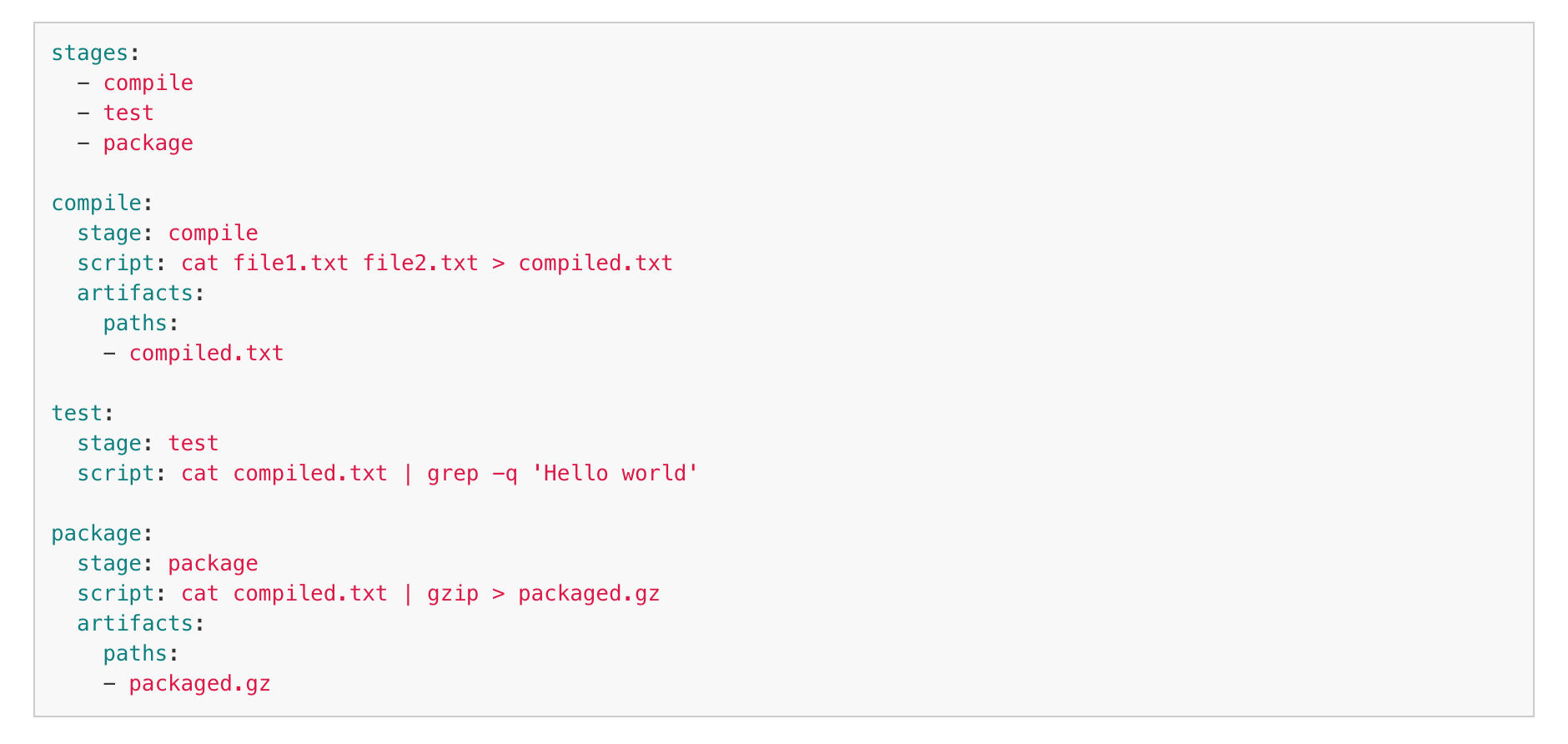
Gitlab Pipeline Code (yaml)
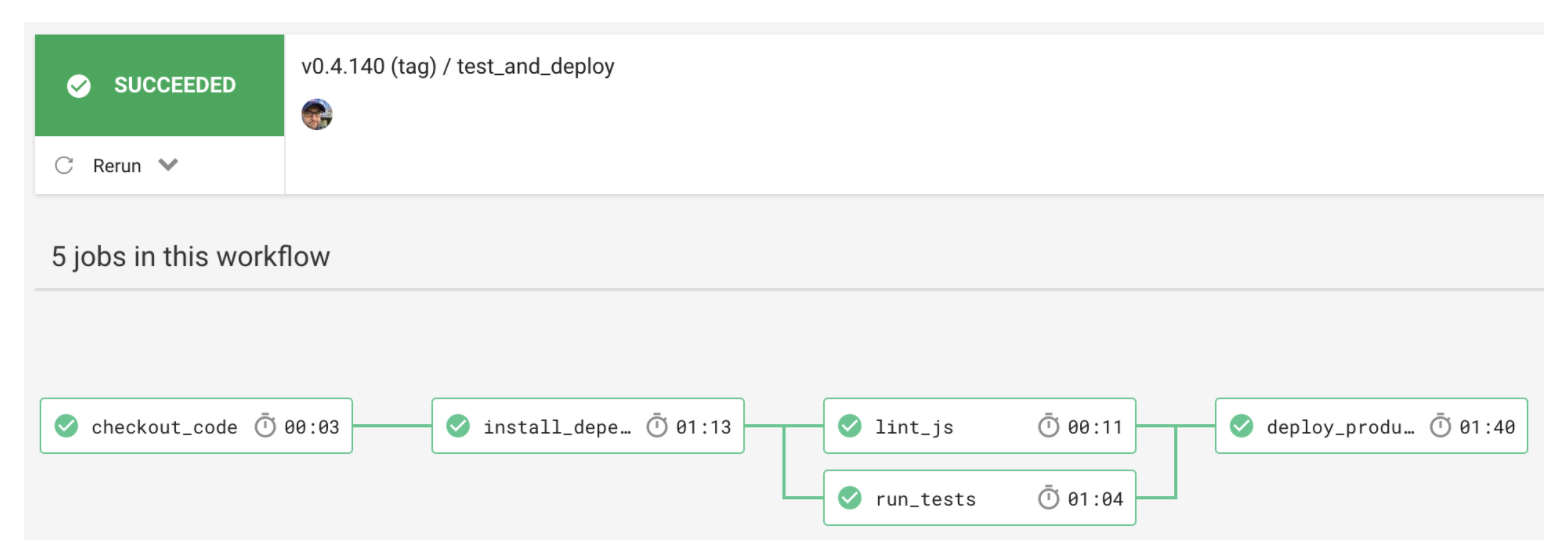
CircleCI (Workflows)
Other Pipeline Tool Examples
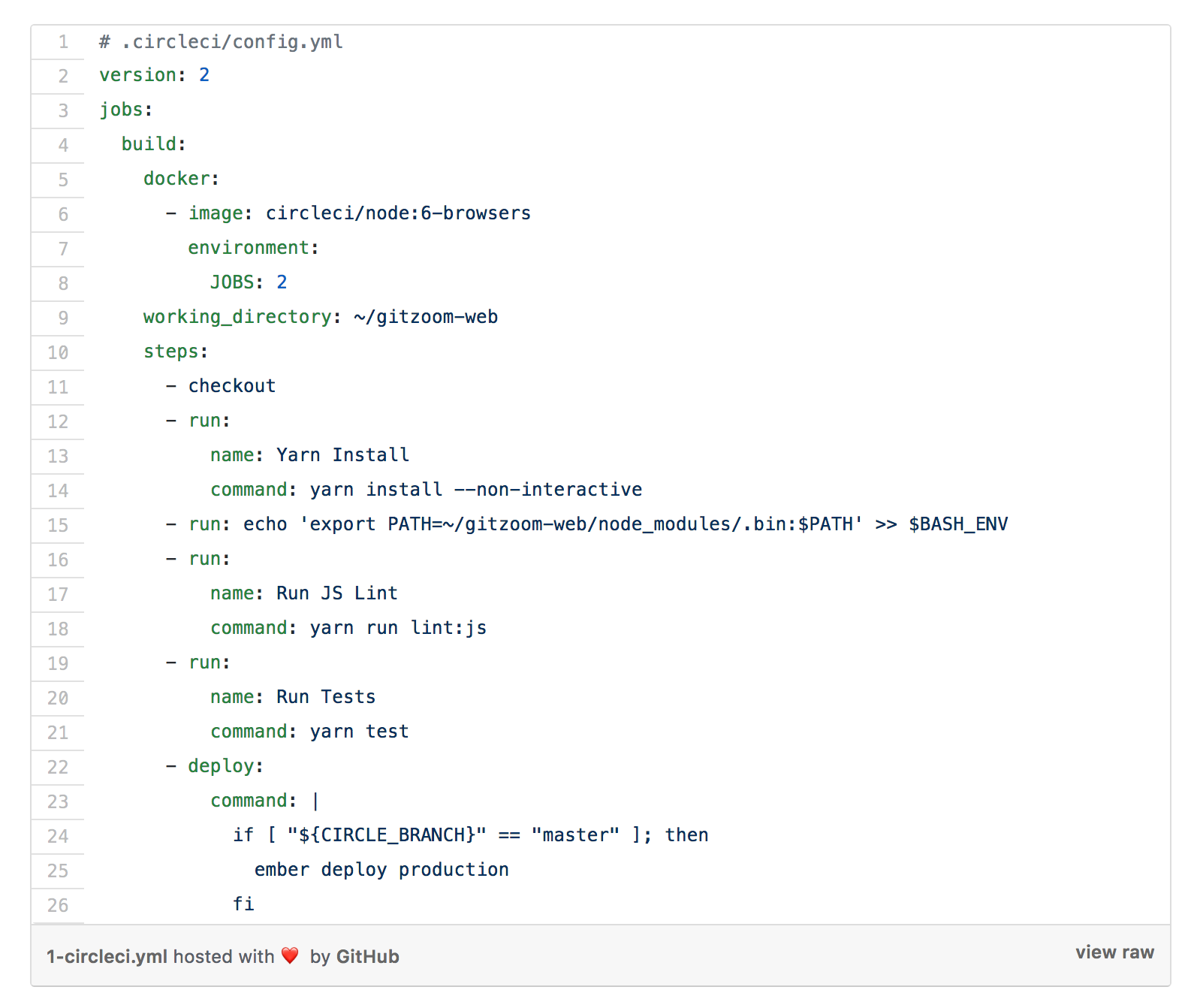
CircleCI (Workflows) (yaml)
Other Pipeline Tool Examples
Etc.
AWS CodeDeploy, AppVeyor, CodeShip, Openshift.io, Spinnaker, Shippable, GoCD, CDMove, TravisCI (beta), Drone, Heroku, Concourse CI, Lambda CD, Bitbucket
Pipeline Tooling Benefits
Speed
- Stages automatically feed into other stages
- Free* Parallelization
(no test framework changes necessary)
Parallelization ($$$$)
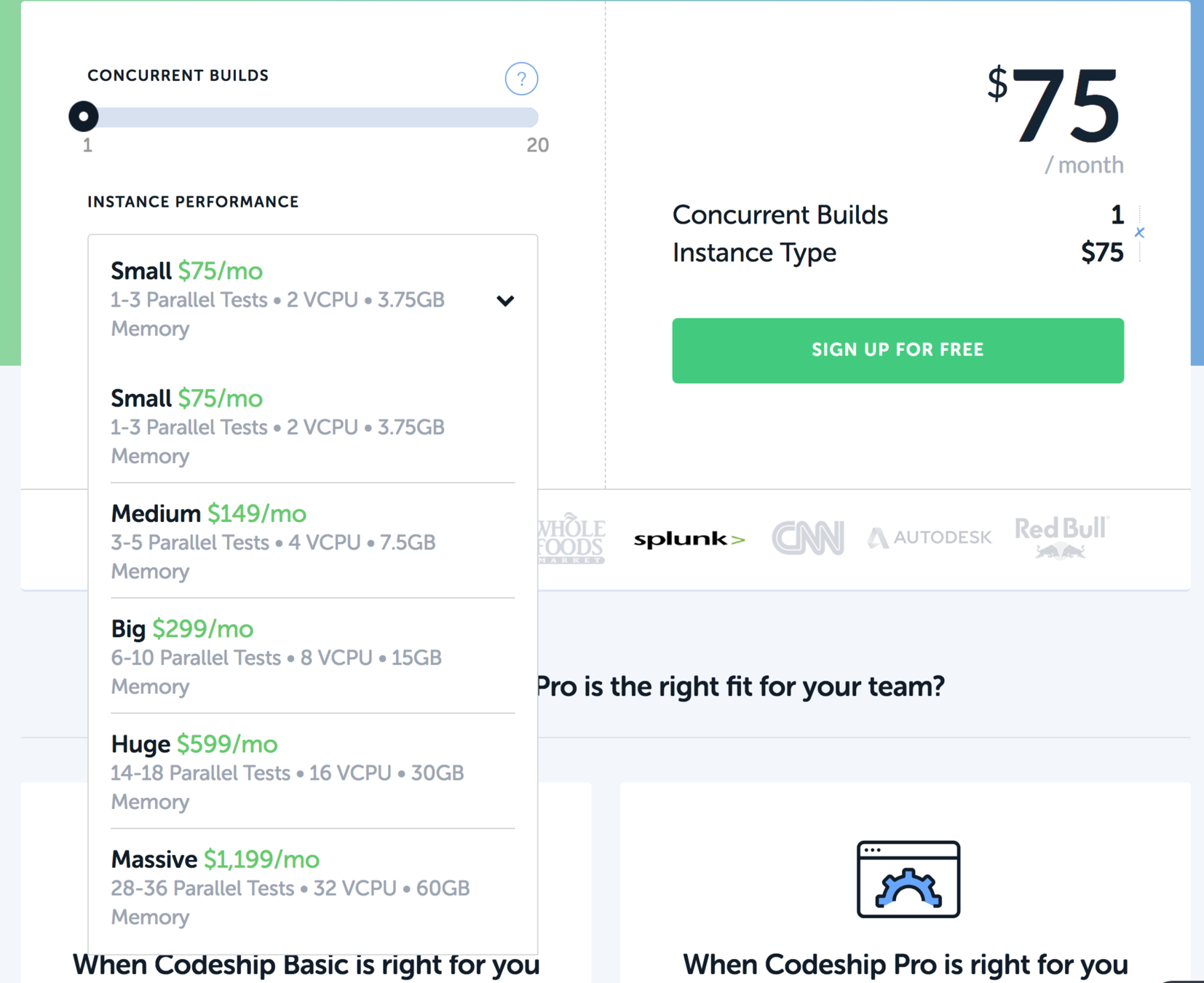
Codeship
Parallelization ($$$$)
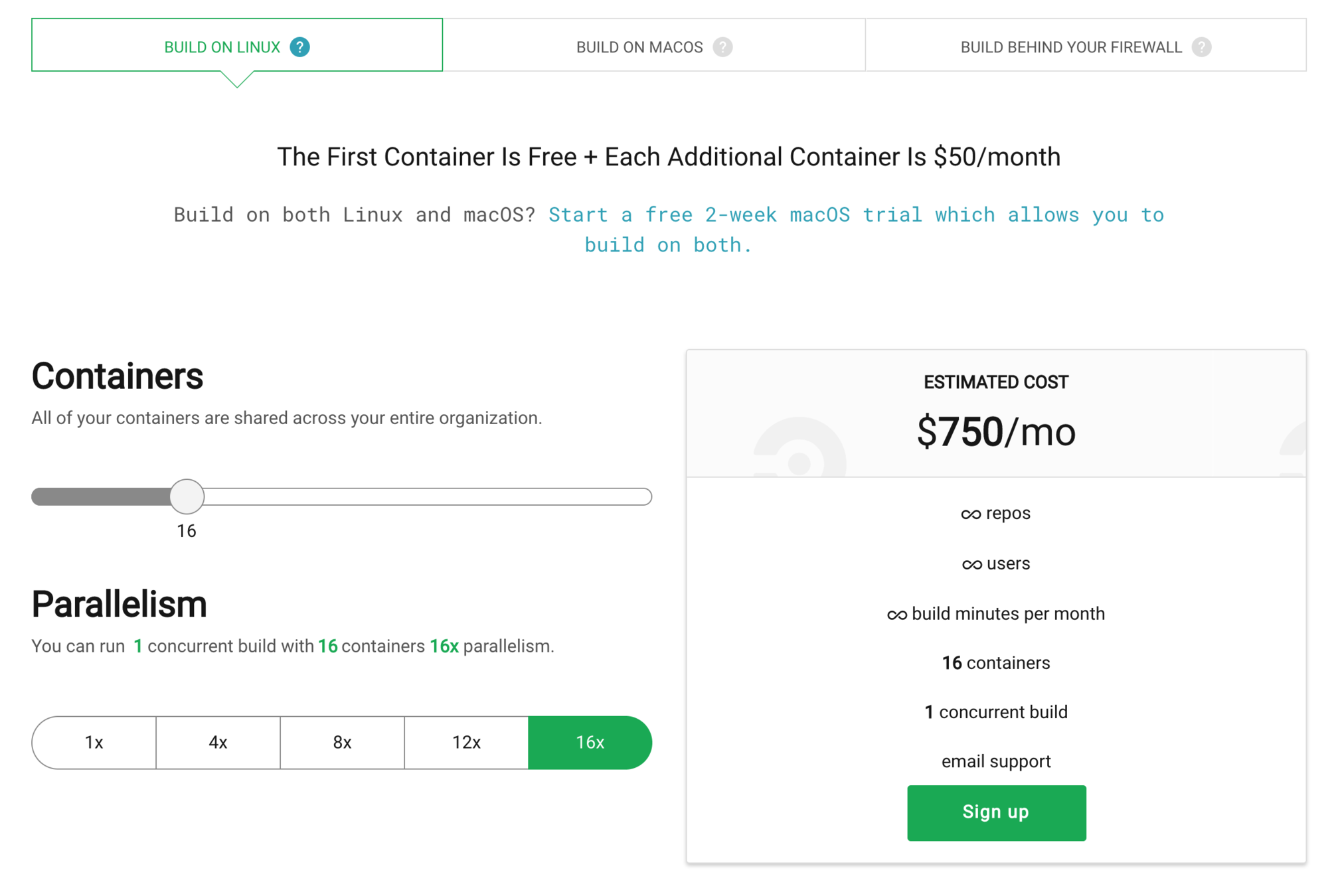
CircleCI
Isolating Functionality
Isolates Failure
- Visualize the exact step which failed and what code changed
- Lowers triage time
We can avoid correlating timestamps on a 5 MB console log - (not shown) Retry on an individual stage instead of restarting an entire build
Code
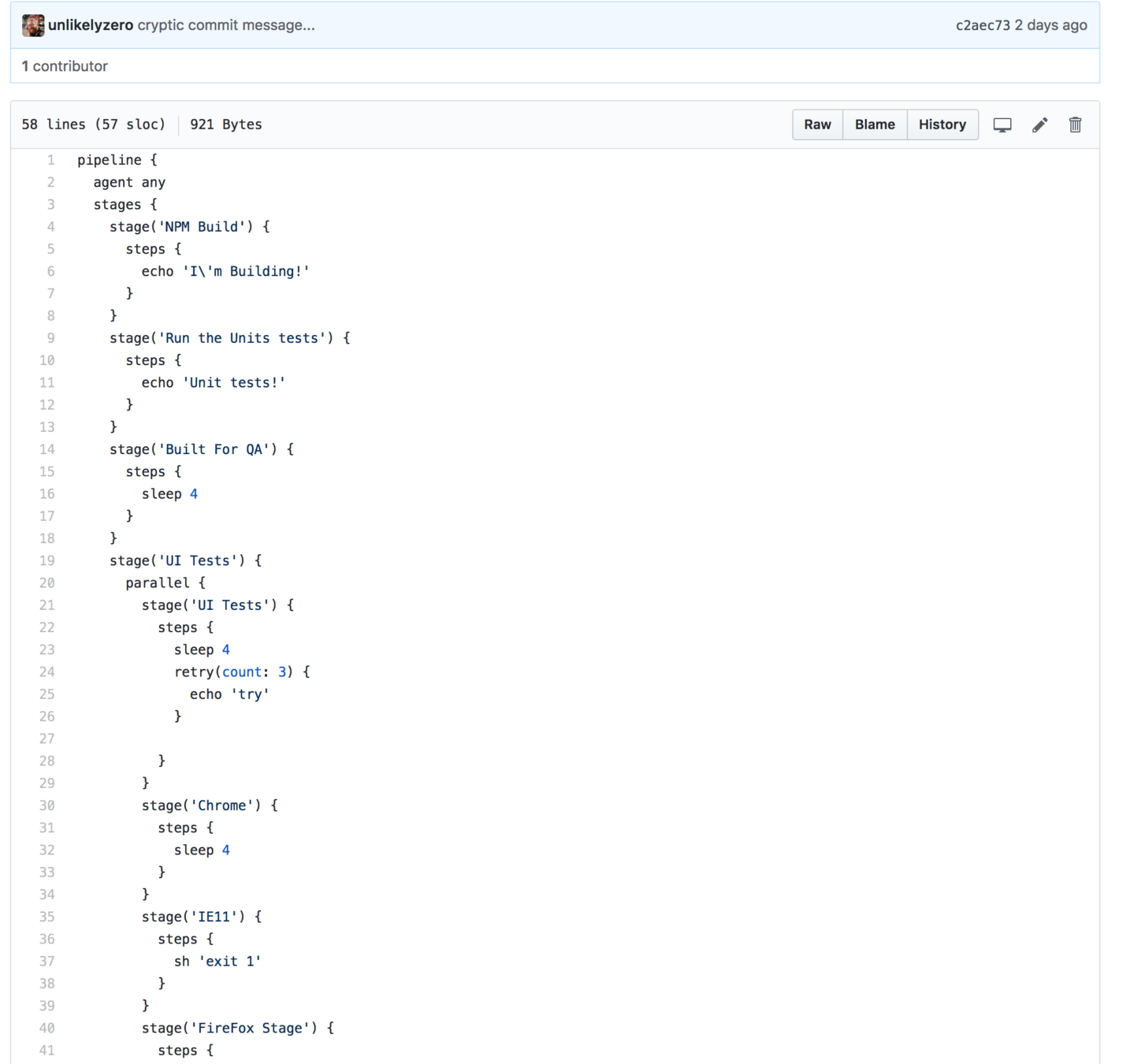
Pipeline MGMT
Audience
-
Choose your audience
-
Test results are feedback
-
Not everyone needs the same level of feedback
-
RACI
Pipeline MGMT
Pipeline "Channels"
-
Local Developers aren't the only ones making changes
-
Other features or Repositories
-
Open Source, Upstream contributors
-
Infrastructure Changes (Server, DB Upgrades)
-
Libraries and Dependencies (npm, python versions)
-
Breakages can come from anywhere -- even ourselves
(Pipelines as Code)
Pipeline MGMT
Test Speed
Not every test can run on every change.
Developers don't want to wait 12 hours to merge code PR
Pipeline MGMT
Improve Test Pipeline "Speed"
Maybe we don't run ALL the tests immediately
Demo
Test Pipeline Speedhax
-
Run the “most valuable” and fastest tests earlier in the pipeline.
-
"Value" is subjective
-
Let the most important tests run first and FailFast to get Faster Feedback
"Chain" Regression Runs
Test Pipeline Speedhax
-
Run the more expensive tests as a scheduled pipeline (hourly, nightly, weekly).
-
Continue to keep a collection of commits which have occurred between runs to associate change with results.
Scheduled Regression Runs
Manage Pipeline Health
Now that we're in the pipeline, we need our tests feedback to be more reliable
Measure Pipeline Reliability (Flake)

CircleCI Insights
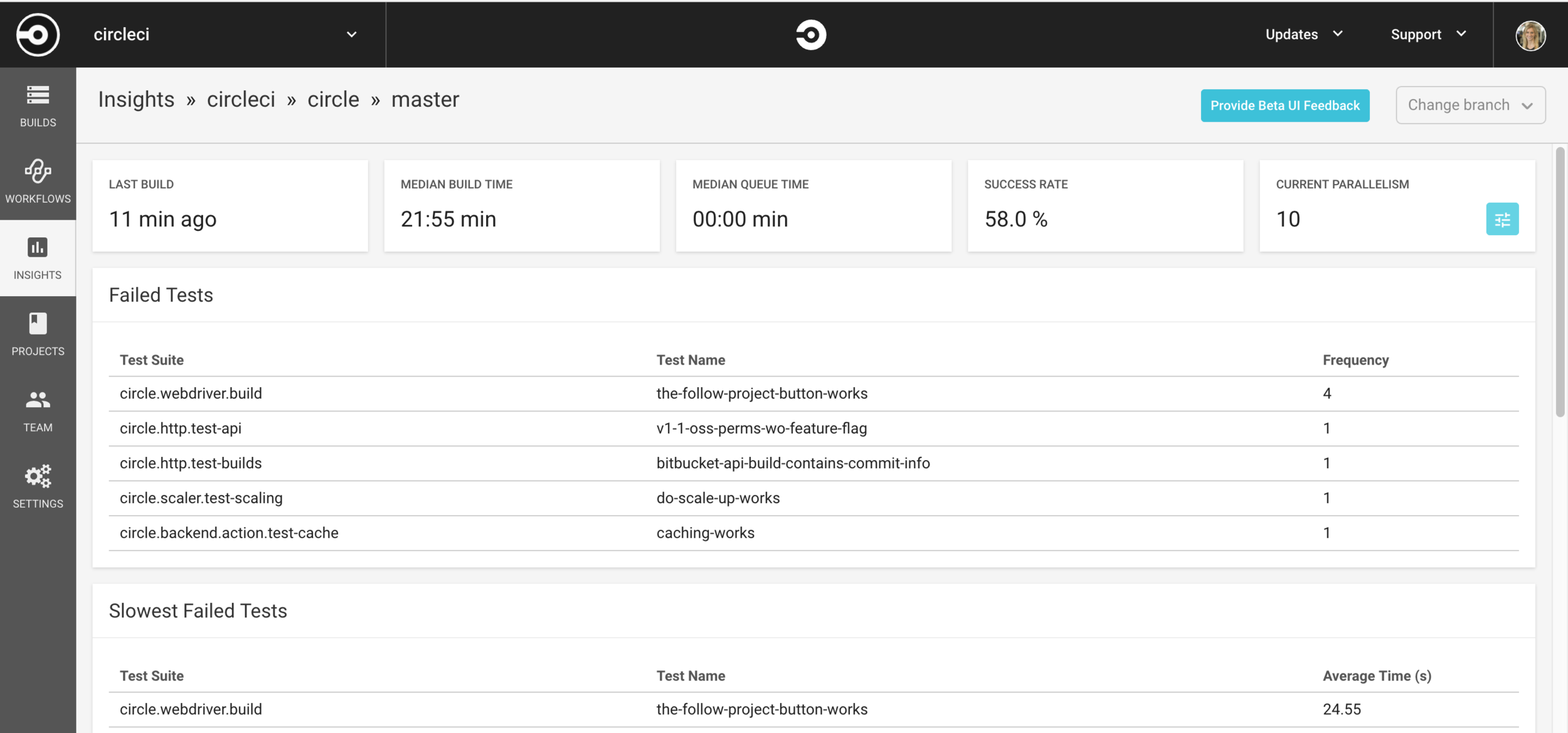
Test Promotion Pipeline
Onramp and Test Onboarding
"The Feedback Loop" Pipeline

What if the input was the output?
"The Feedback Loop" Pipeline
If the input and the output are linked, then the only thing that changes is result of the test.
Unsolved Pipeline MGMT problems

Pipeline... of Pipelines
-
Need to visualize the all pipelines
-
View health, View status....
-
Essentially a pipeline becomes another stage
Pipeline... of Pipelines
-
Vendor Solutions
-
Jenkins
*crickets*
-
We could leverage Data Engineering Tools
- but...
Let's Avoid Temptation

The "Ops" space is figuring this out
(again)
Waze and Microservices
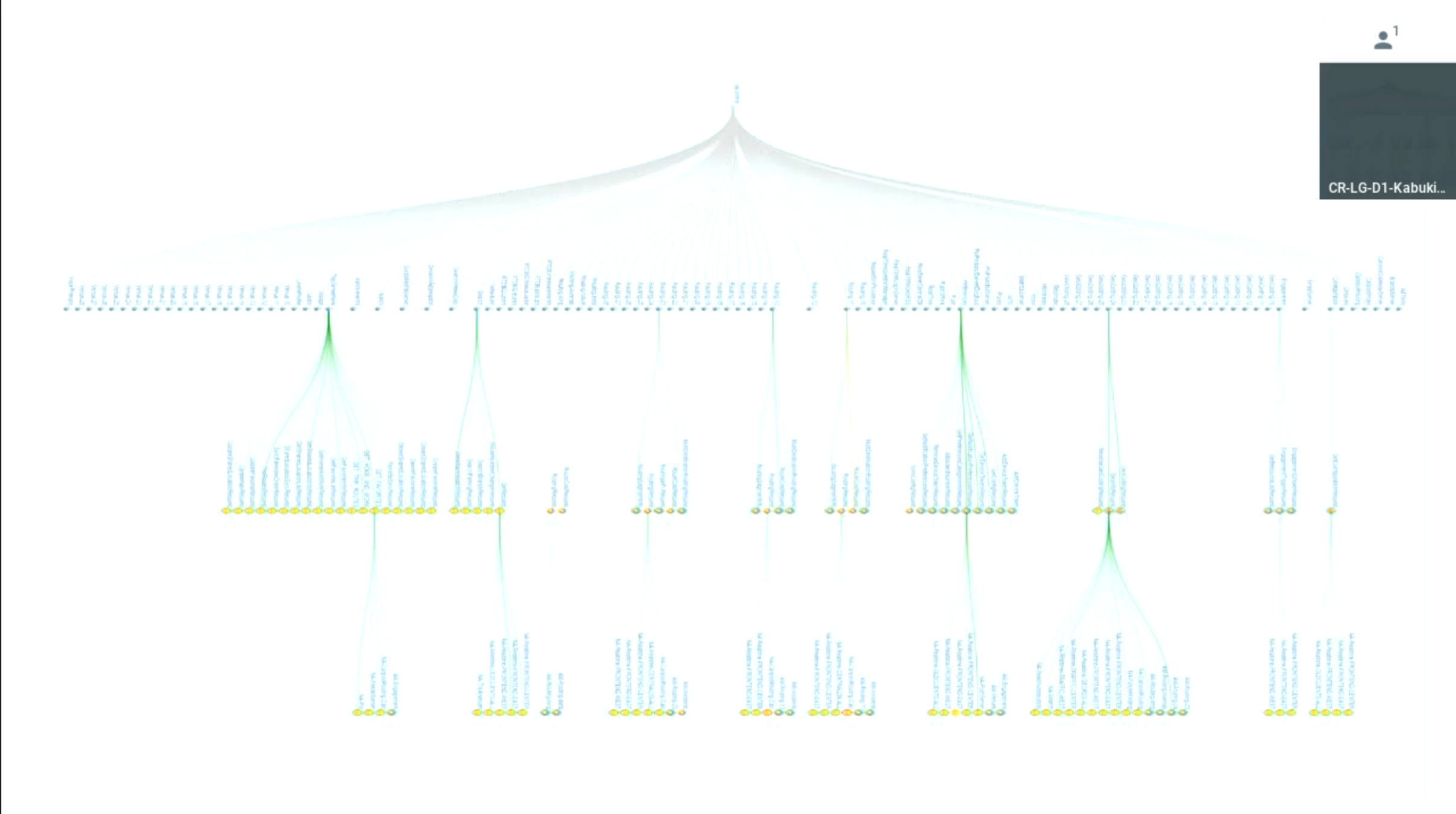
Shippable
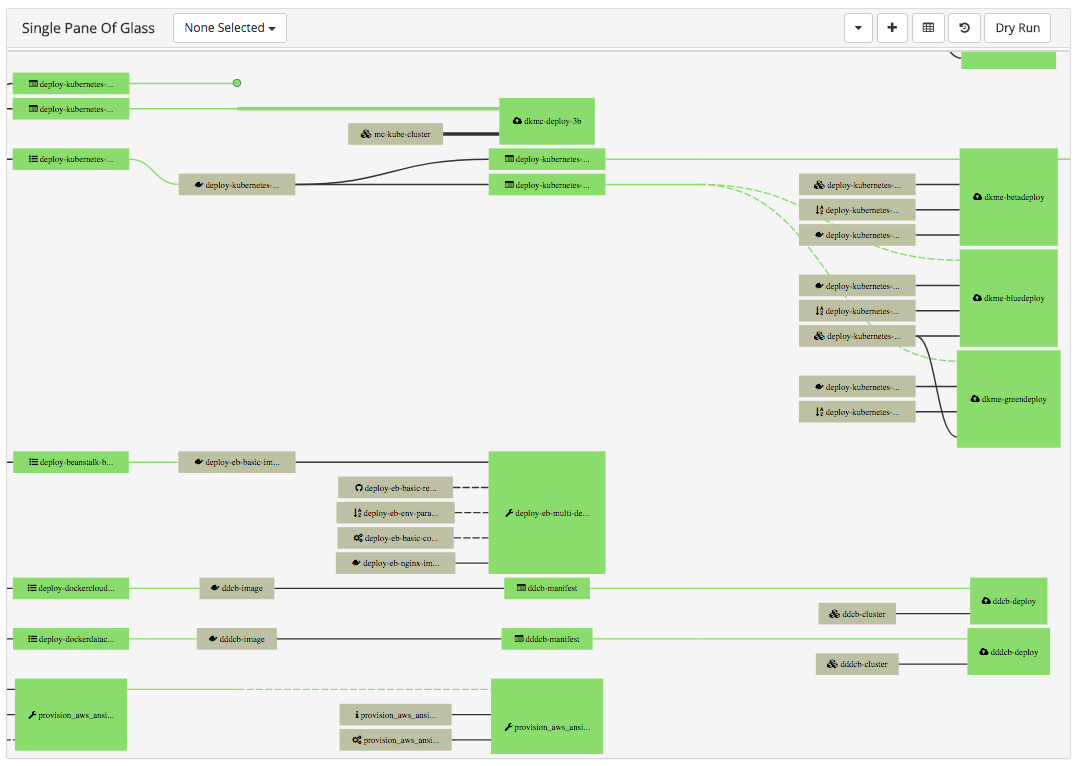
Unsolved Problems Contd.
- Multiple CI systems may be used
- True Scale issues haven't yet been solved
The Future
Transit Maps have the Visuals figured out
Kubernetes
-
Look towards Kubernetes to figure this out. https://prow.k8s.io/
-
Need to move away from Jenkins and Gitlab
Bot-pipelines
-
Today: Auto-test Library Channel dependencies
-
https://github.com/fabric8-updatebot/updatebot
GreenKeeper
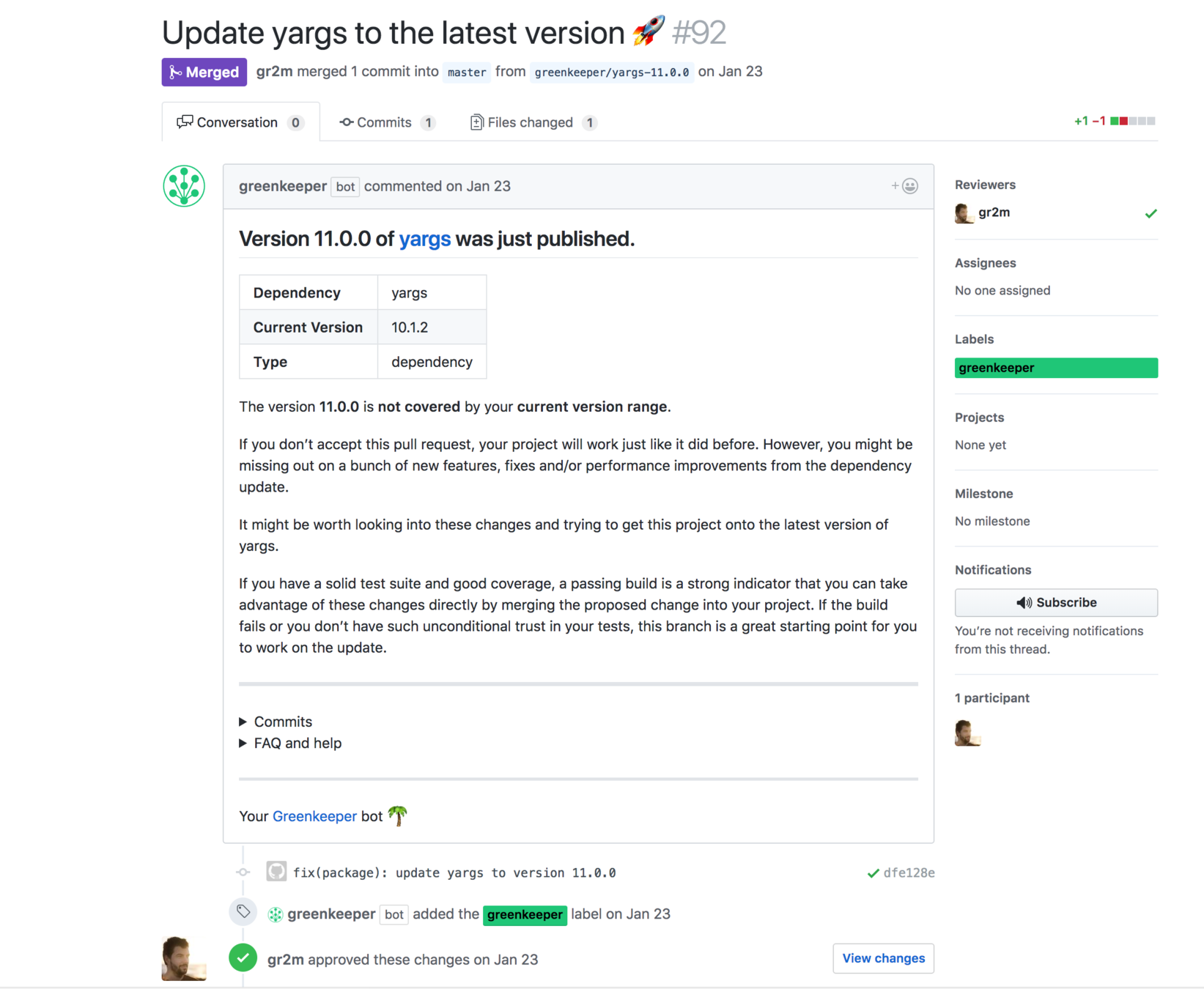
Bot-Pipelines
Logical Extension: Declare more than just upstream libraries
Conclusion
Conclusion
- What are pipelines?
- Where do Test Engineers fit in the pipeline?
- Pipeline Tooling
- How to Manage Test Pipelines
- Unsolved Pipeline Management Problems
- Where the industry is trending