Apresentação
Vanilton Pinheiro

- Vanilton da Thálita 💍
- Pai do Louie 👦🏻 e Lourenzo 👶🏻
- 🎓 Bacharelado Ciência da Computação 🤓
- Especialista em Engenharia de Software e Gestão de Pessoas 🙋🏻♂️
- 👨🏻💻Pessoas e Processos na @fpf.tech 😃
- 👨🏻🏫 Professor na @fpftech.educacional


Objetivo
Formar profissionais que entendem a base física e arquitetural da computação, capazes de analisar gargalos, tomar decisões técnicas conscientes e dialogar com infraestrutura, cloud e desempenho com propriedade.


Aula 1 e 2
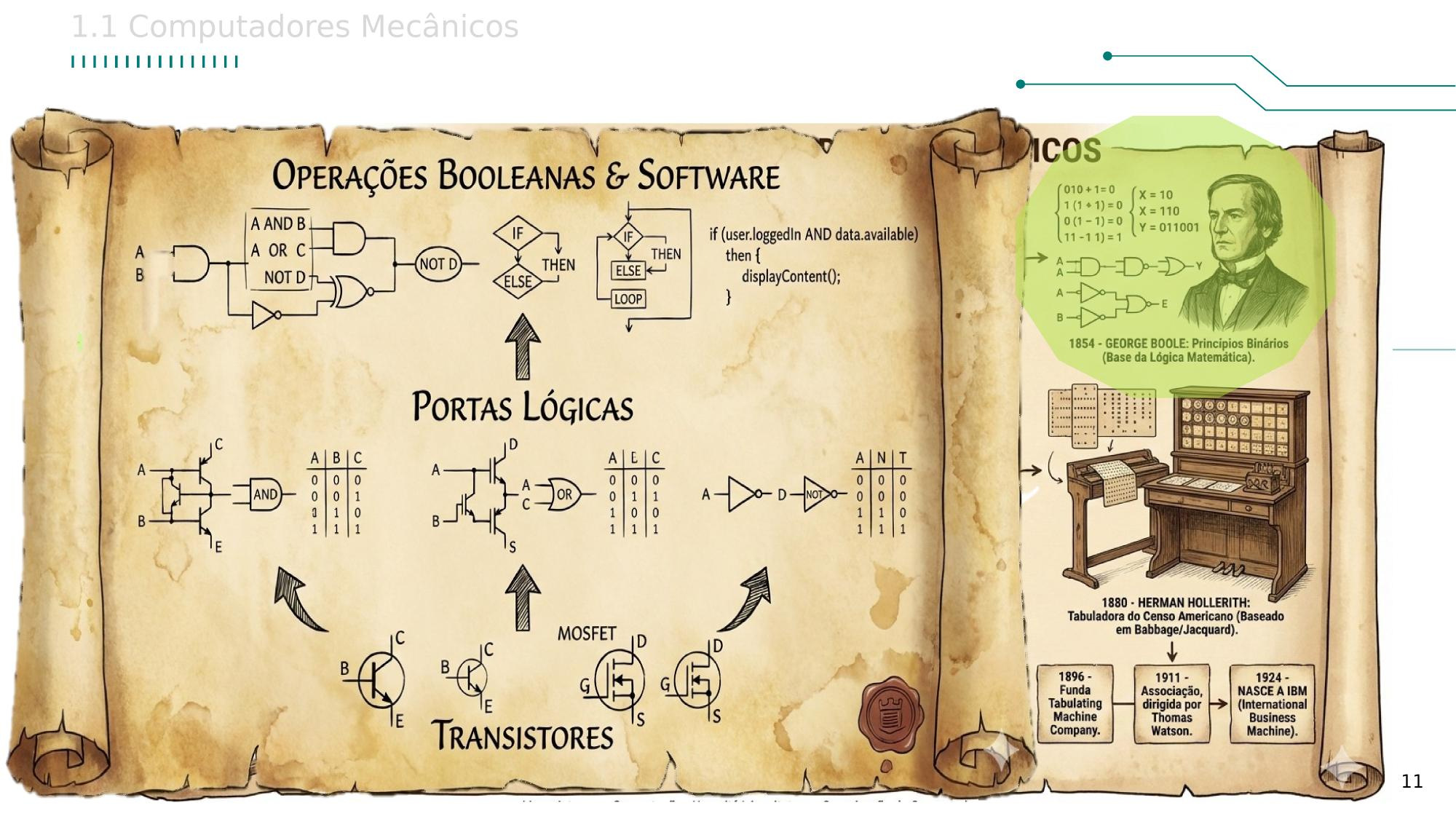
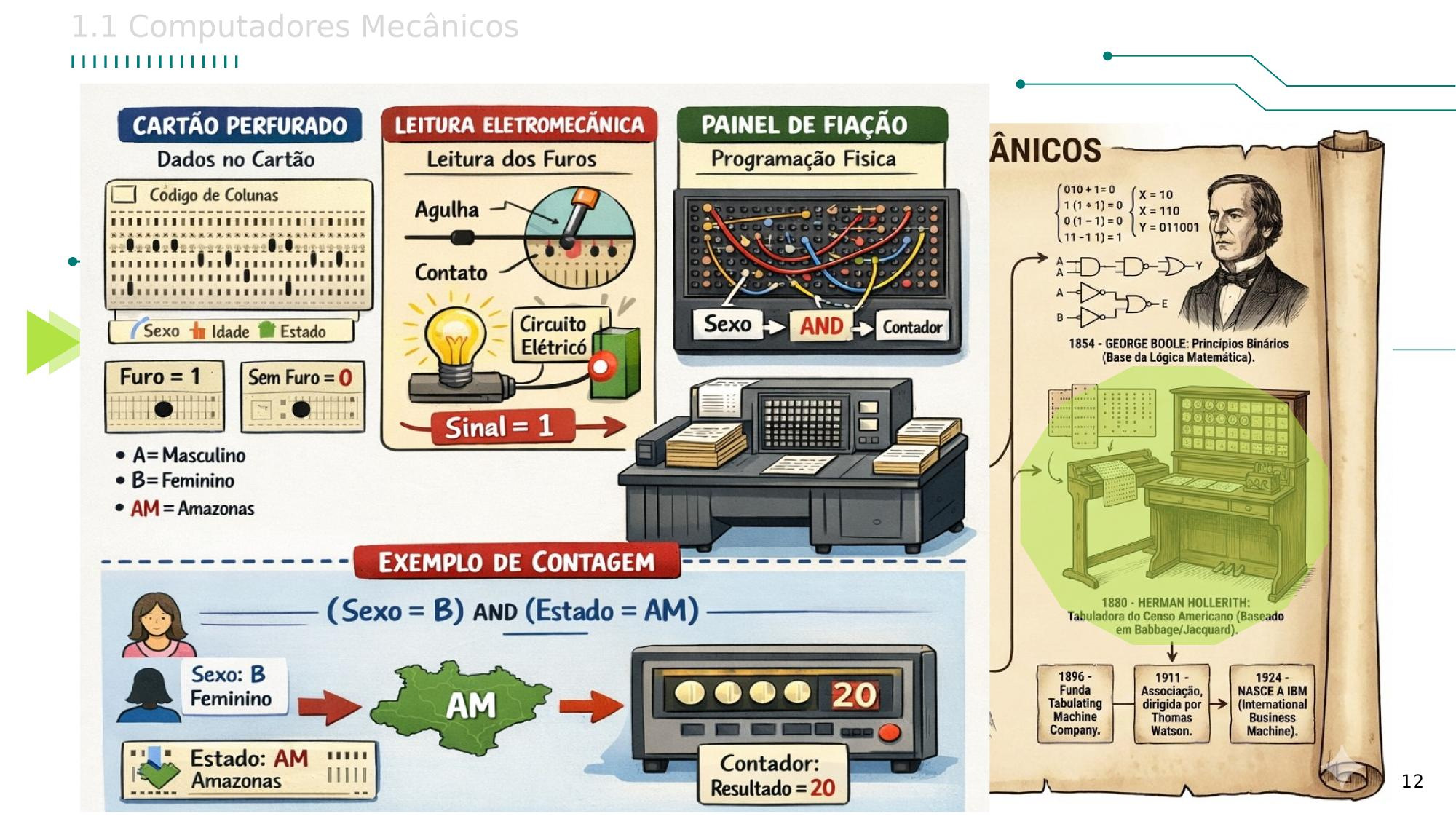
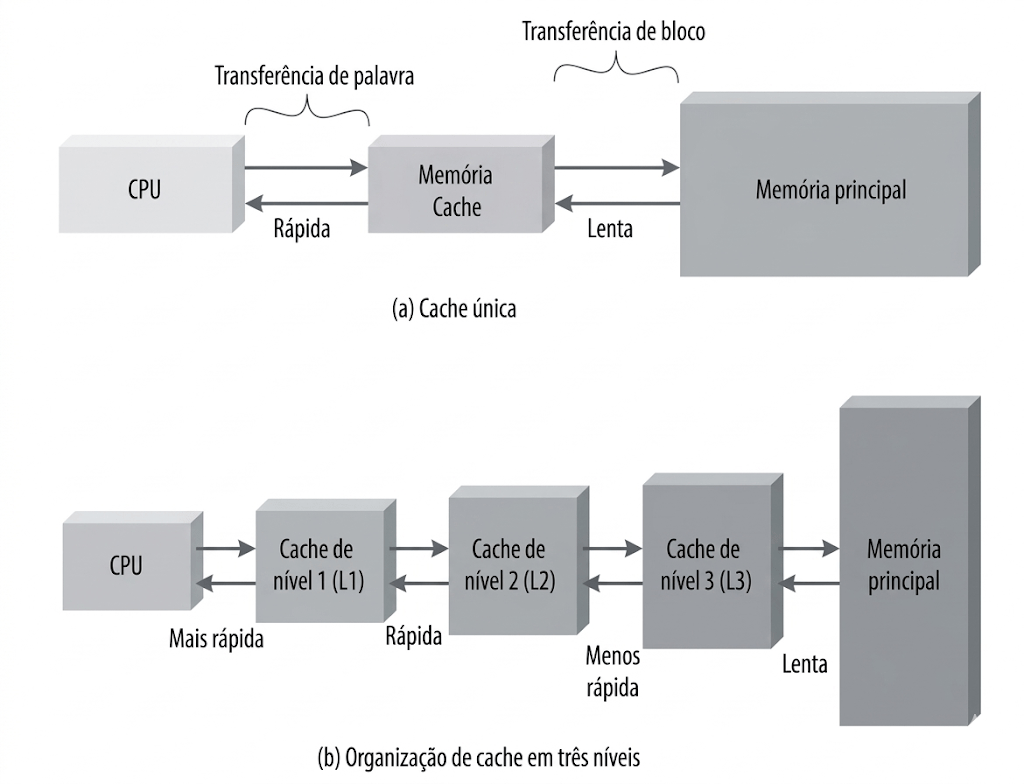
| Capítulo 1 - Introdução e Evolução OAC |
| Arquiteturas Clássicas |


























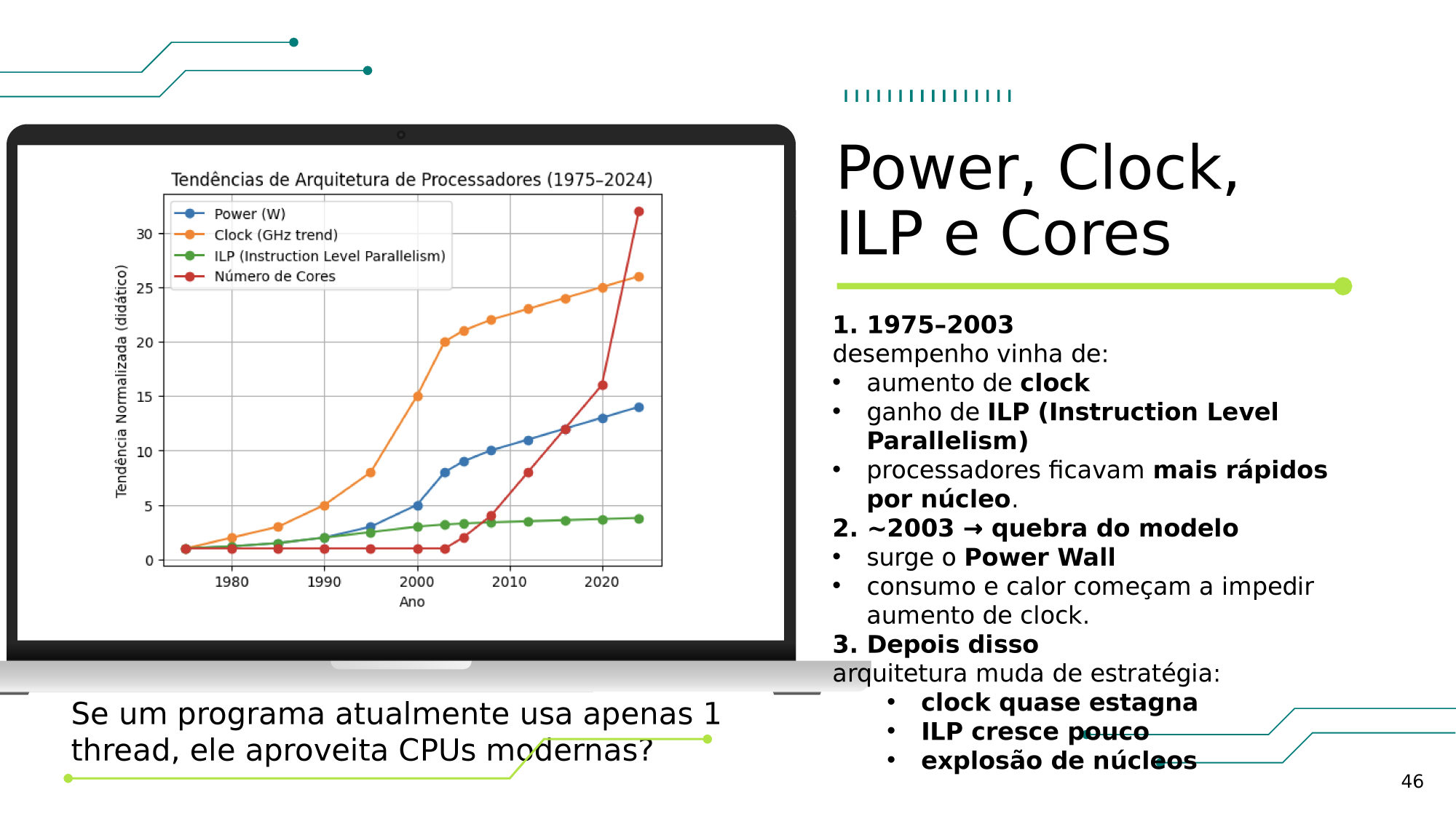


Aula 3
| Capítulo 2 - Componentes do Computador |
| CPU, memória, E/S, barramentos. |
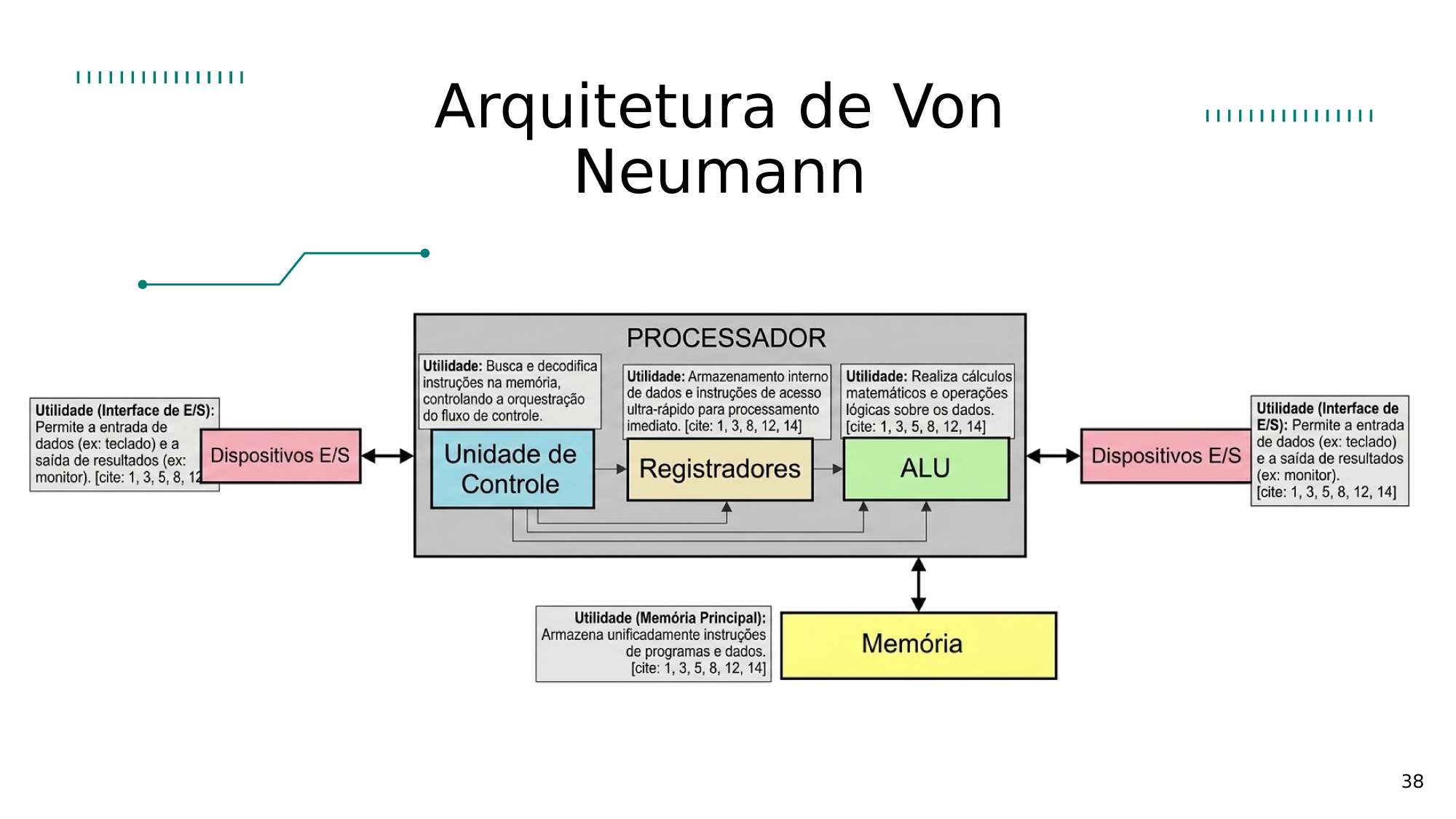
Arquitetura Básica do Computador
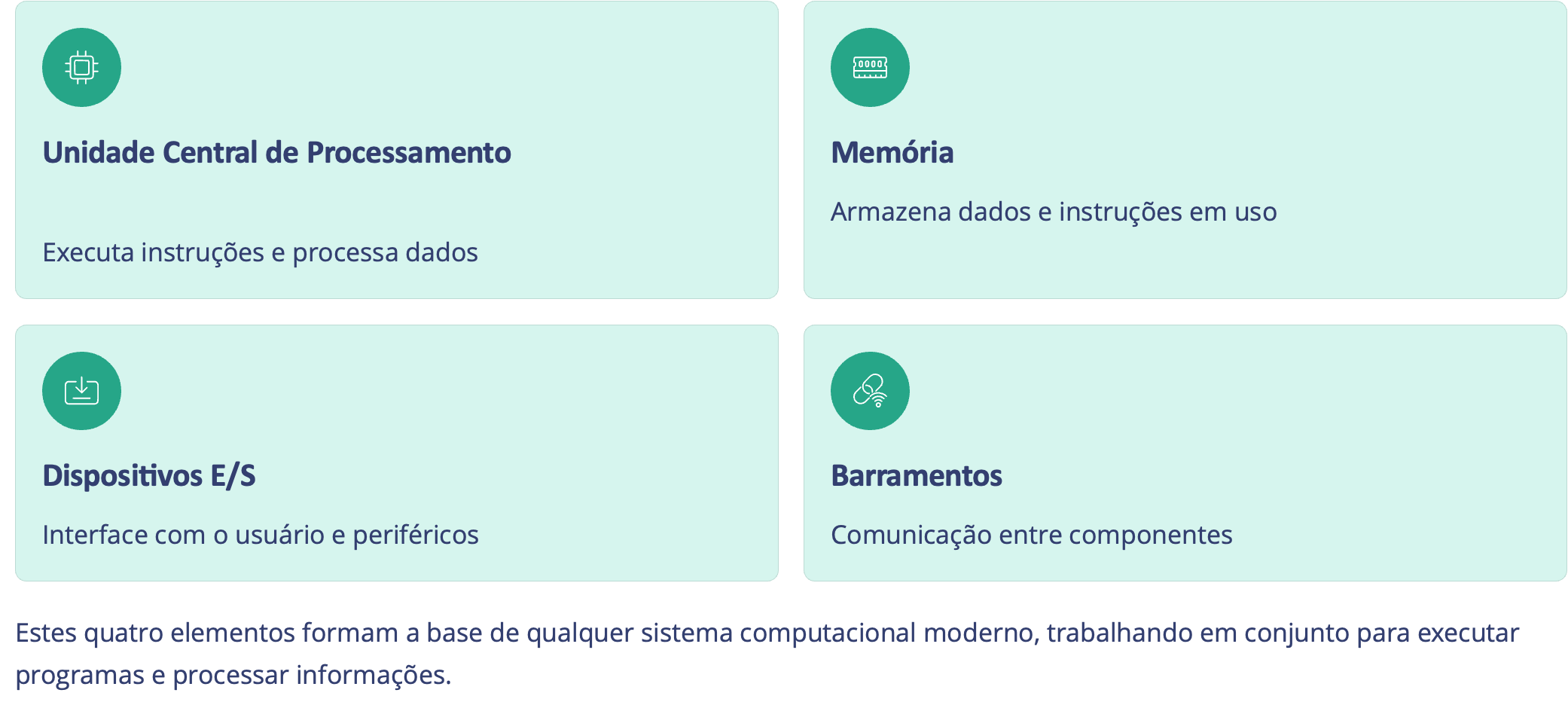
2. Componentes






O Cérebro da Máquina
2.1 CPU



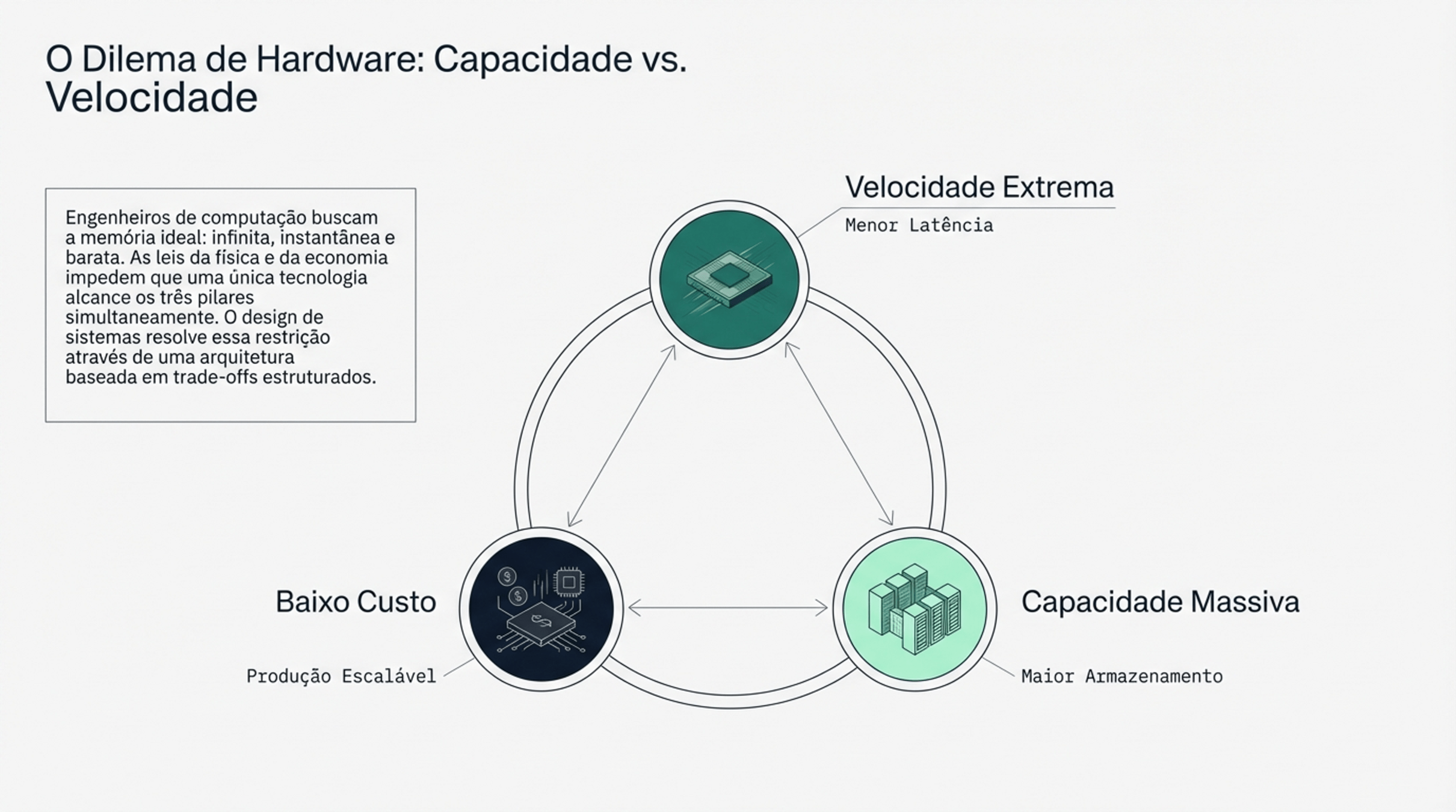
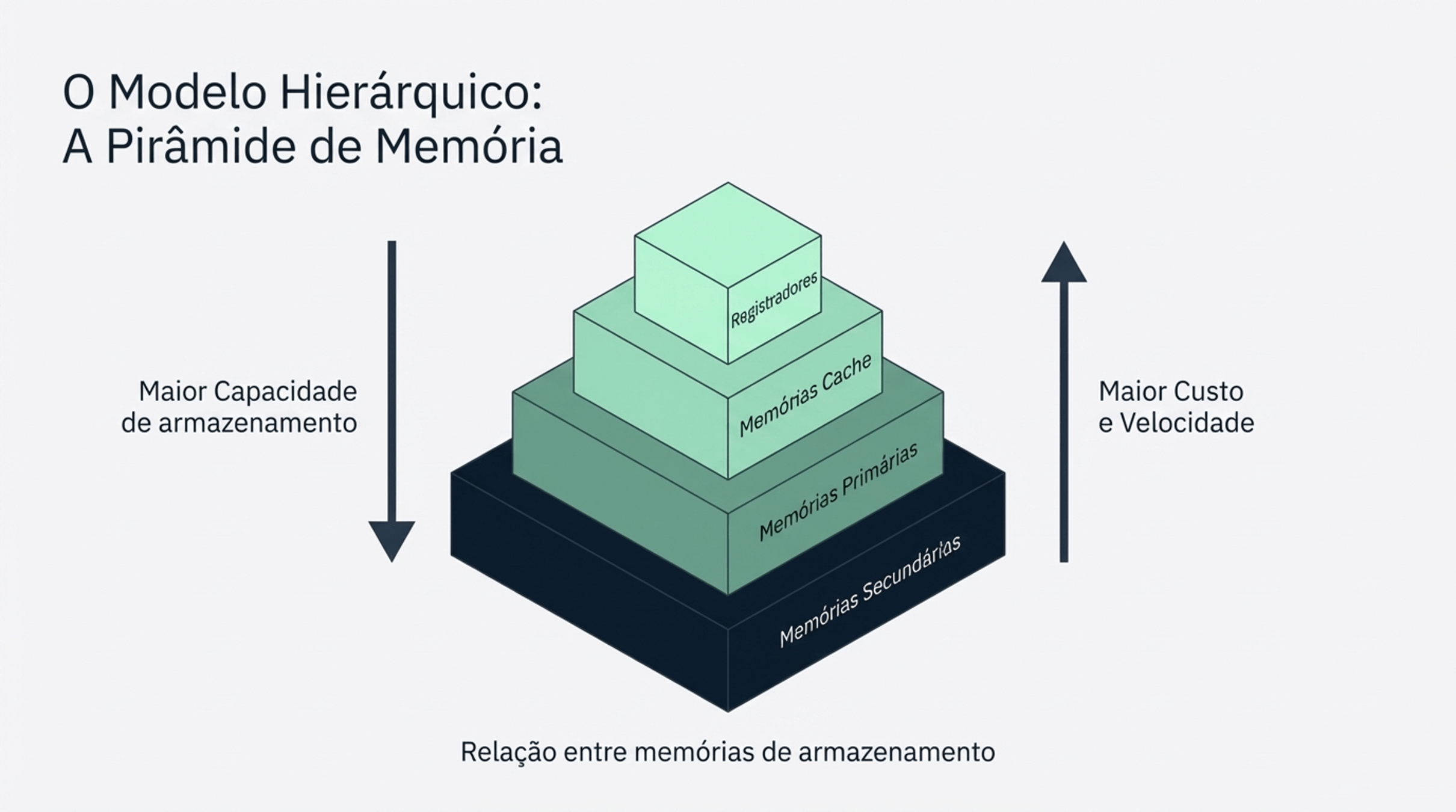
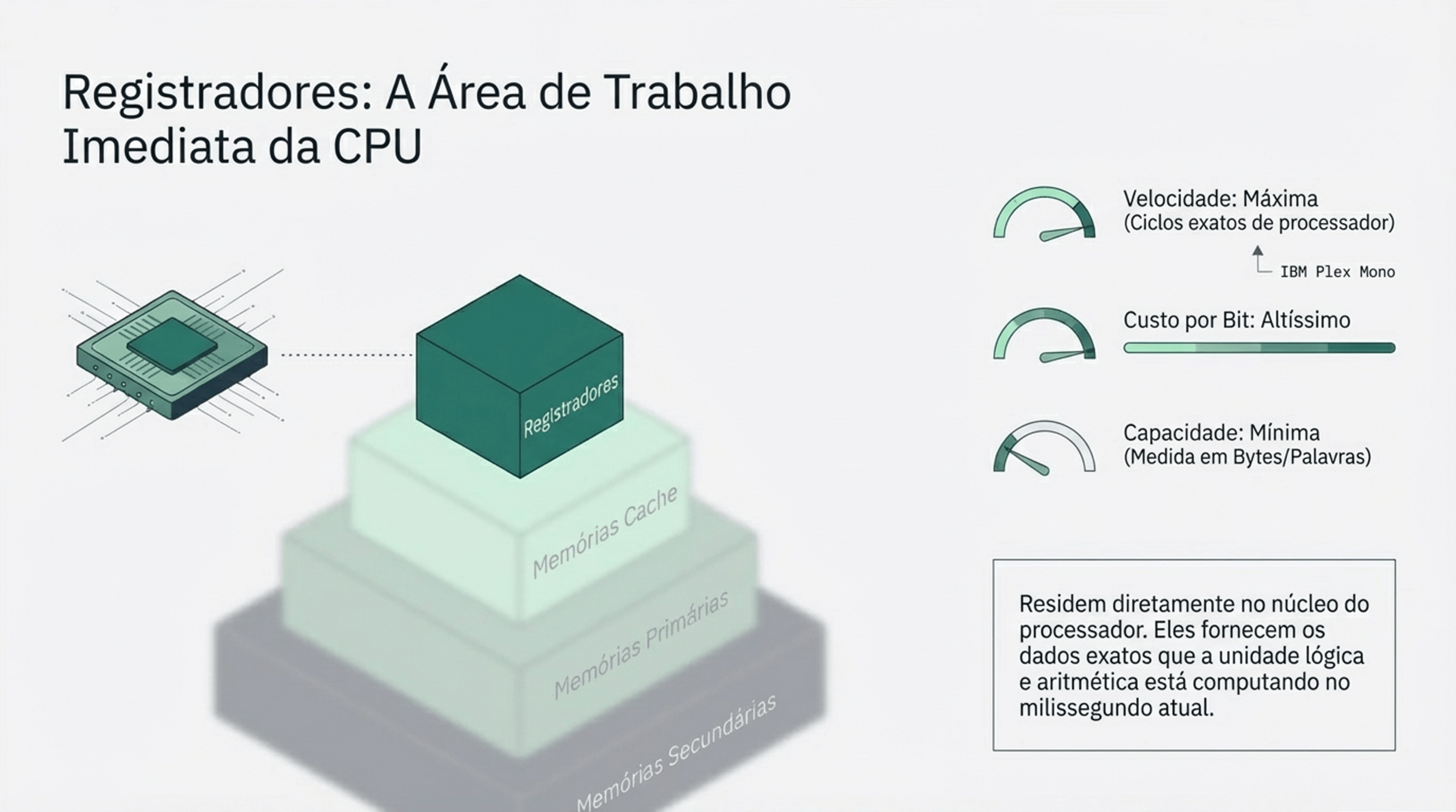
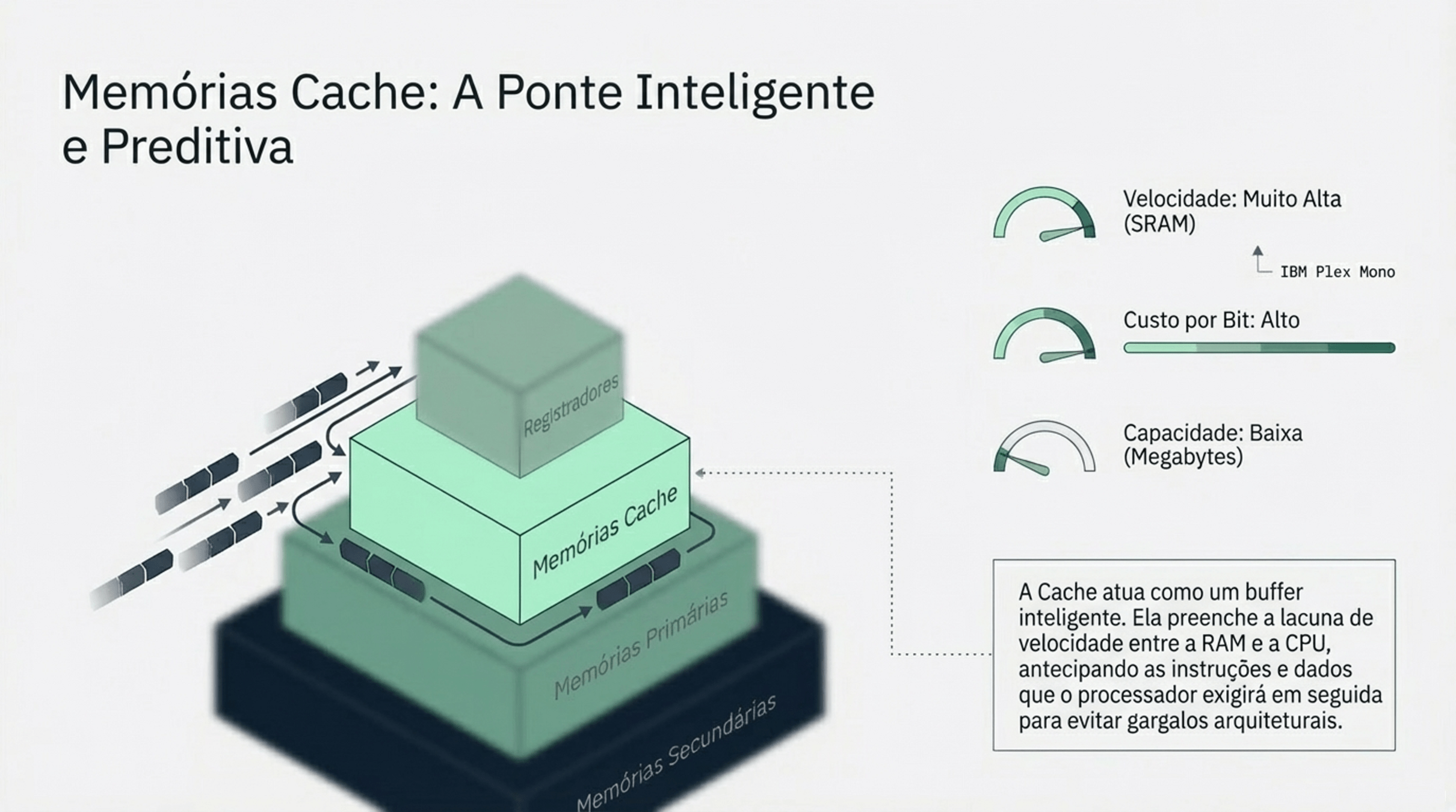
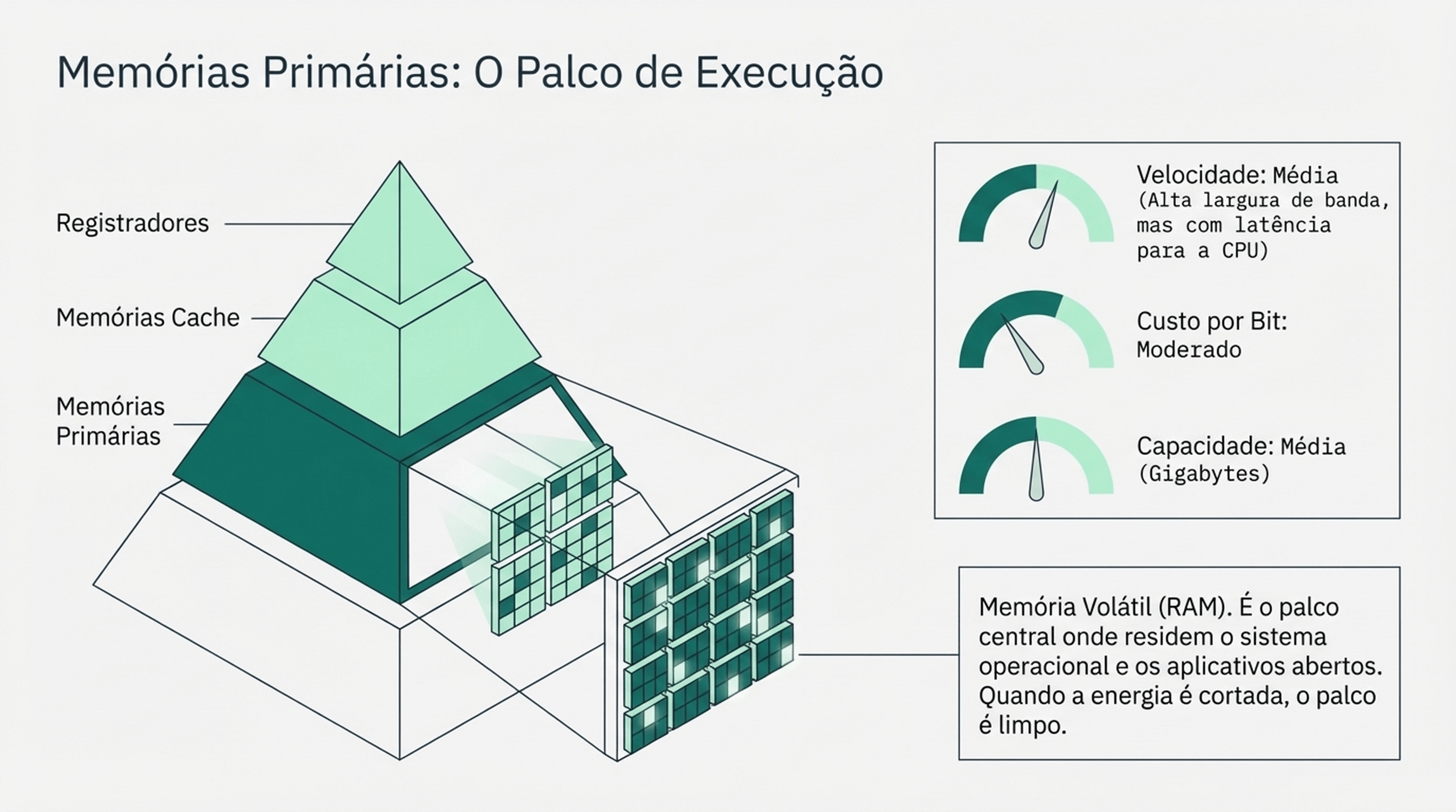
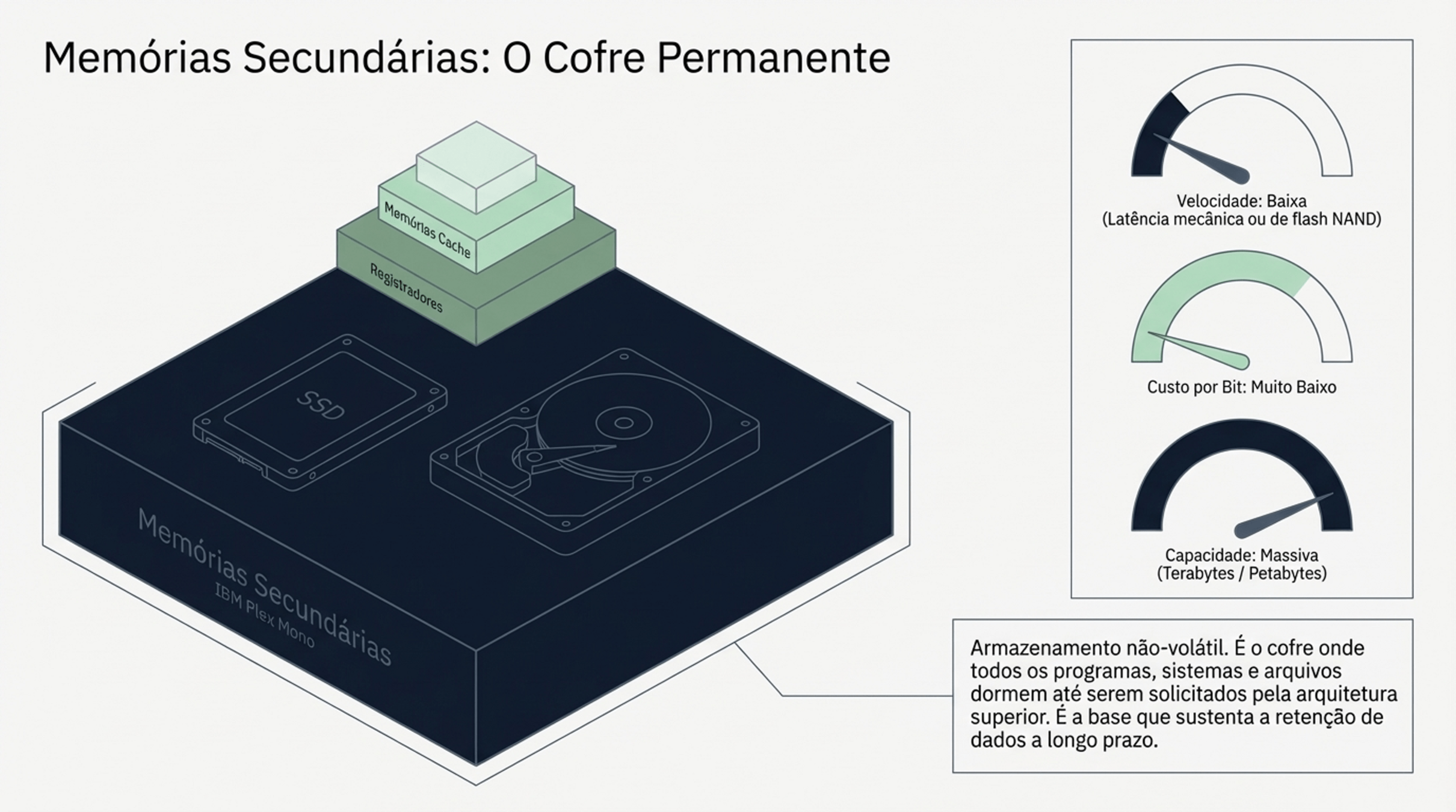
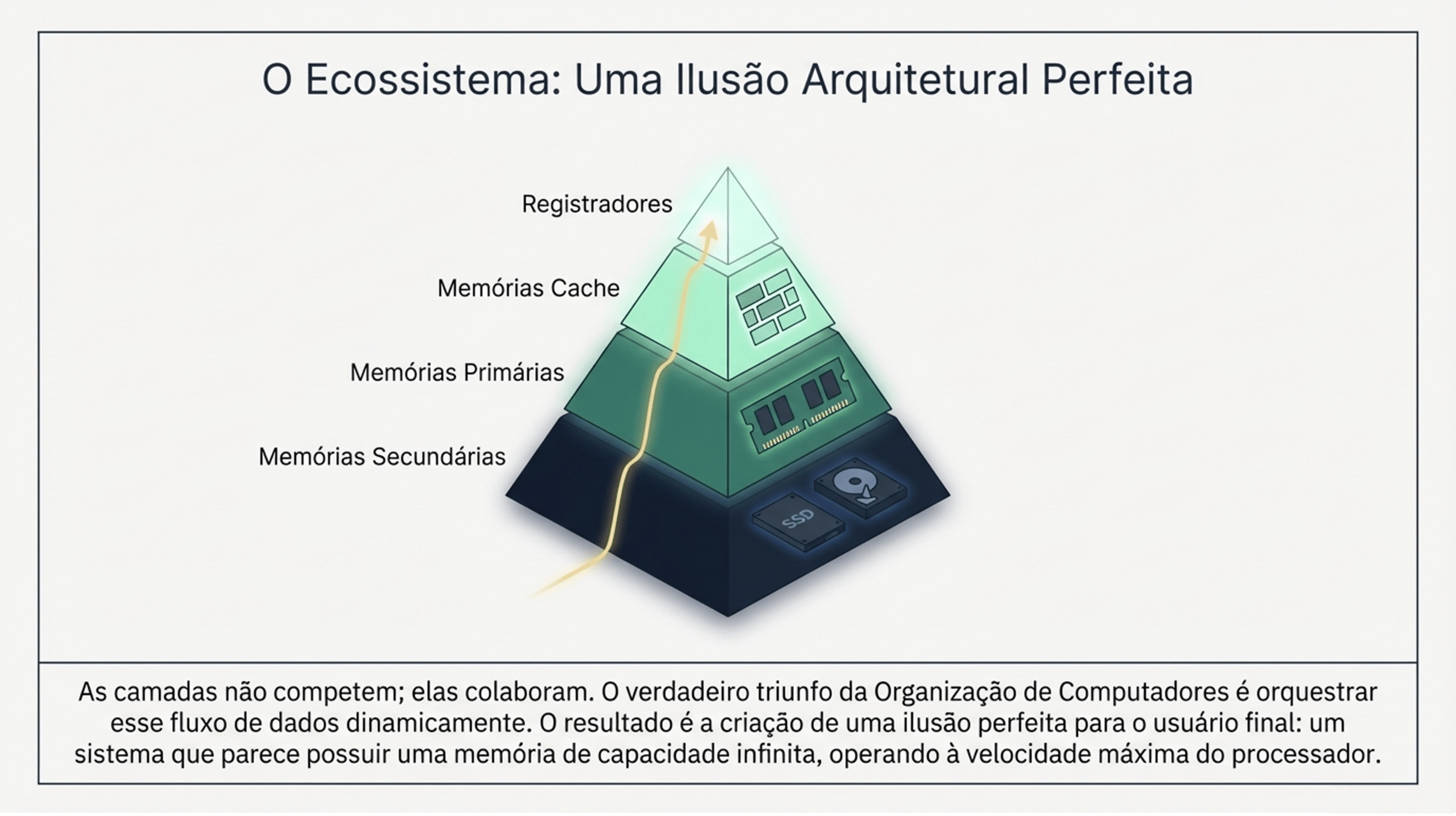
2.2 Memória
2.2 Memória
2.2 Memória
2.2 Memória
2.2 Memória
2.2 Memória
2.2 Memória
2.2 Memória
BIOS (Basic Input/Output System) chip de memória não volátil.
Antigamente, a BIOS era gravada em chips ROM (Read-Only Memory), que não podiam ser alterados. Hoje, utilizamos a Memória Flash (uma evolução da EEPROM).
-
Por que Flash? Porque ela permite que você "atualize" a BIOS (o famoso flash de BIOS) para corrigir bugs ou aceitar processadores novos, mas ainda mantém os dados gravados mesmo sem energia.
2.2 Memória
A relação com a bateria (CMOS)
- Confunde-se a memória da BIOS com a "pilha" da placa-mãe.
- Funciona assim:
- O Chip de Flash: Guarda o programa da BIOS/UEFI (permanente).
- A Memória CMOS: É uma pequena parte de memória que guarda as suas configurações personalizadas (como a hora do sistema e a ordem de boot).
- A Bateria: Serve apenas para manter o relógio rodando e alimentar a memória CMOS enquanto o PC está fora da tomada. Se a bateria acaba, a BIOS não some, mas as configurações voltam ao padrão de fábrica.
2.2 Memória
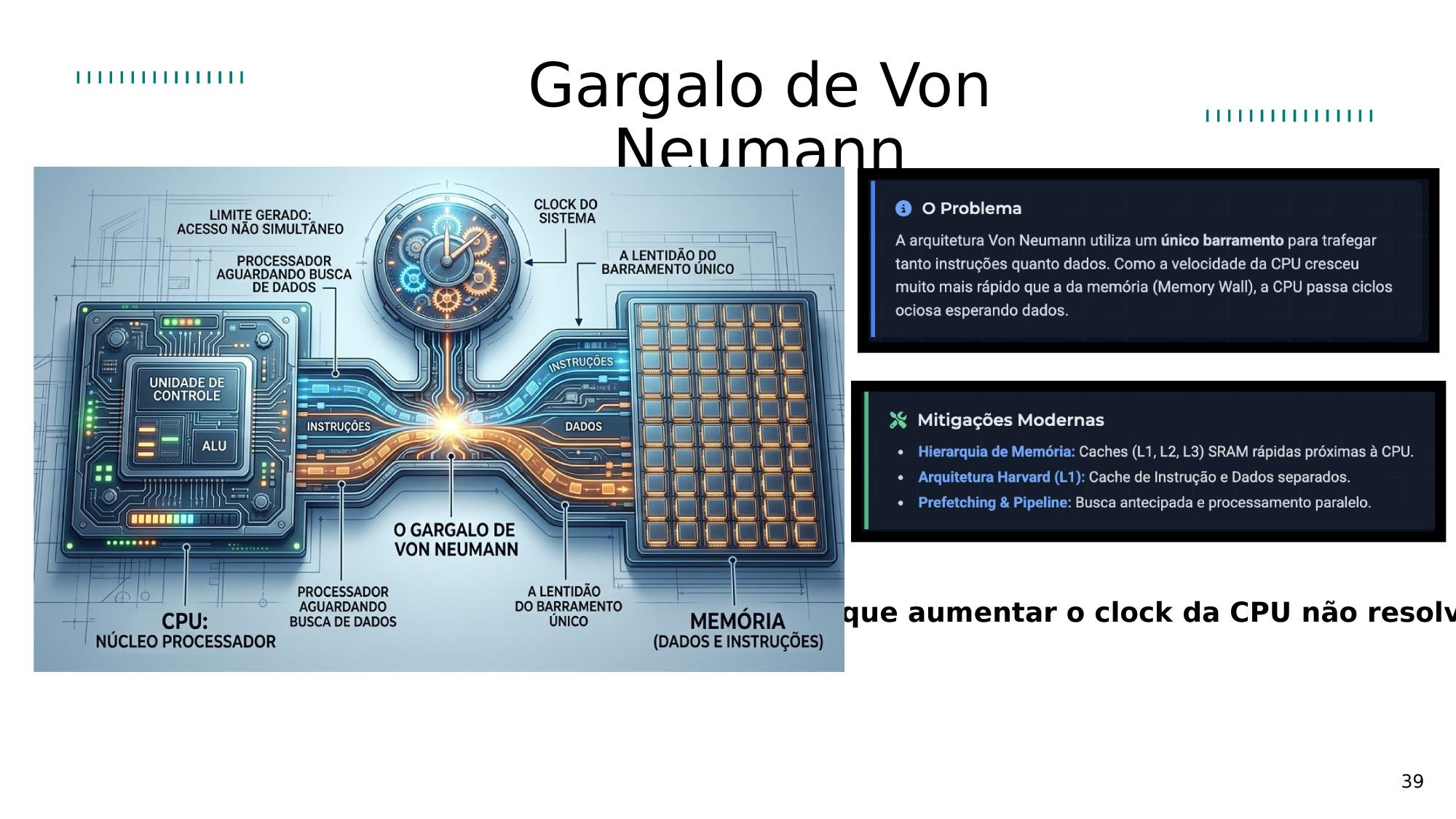
2.3 Barramentos
Comunicação dos componentes
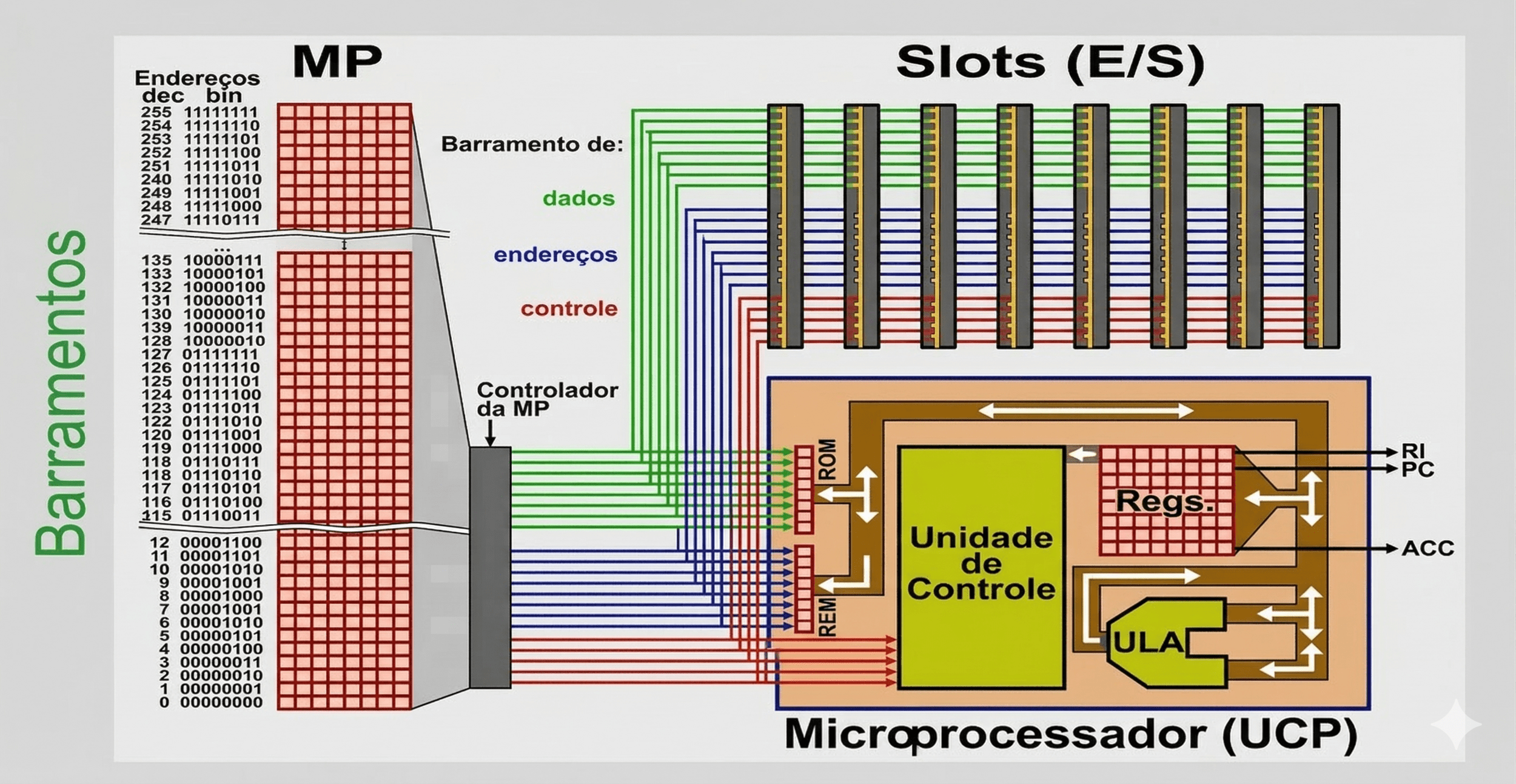
Os barramentos são canais de comunicação que transferem dados, endereços e sinais de controle entre componentes. A largura do barramento determina a taxa de transferência de dados.

2.3 Barramentos
Comunicação dos componentes
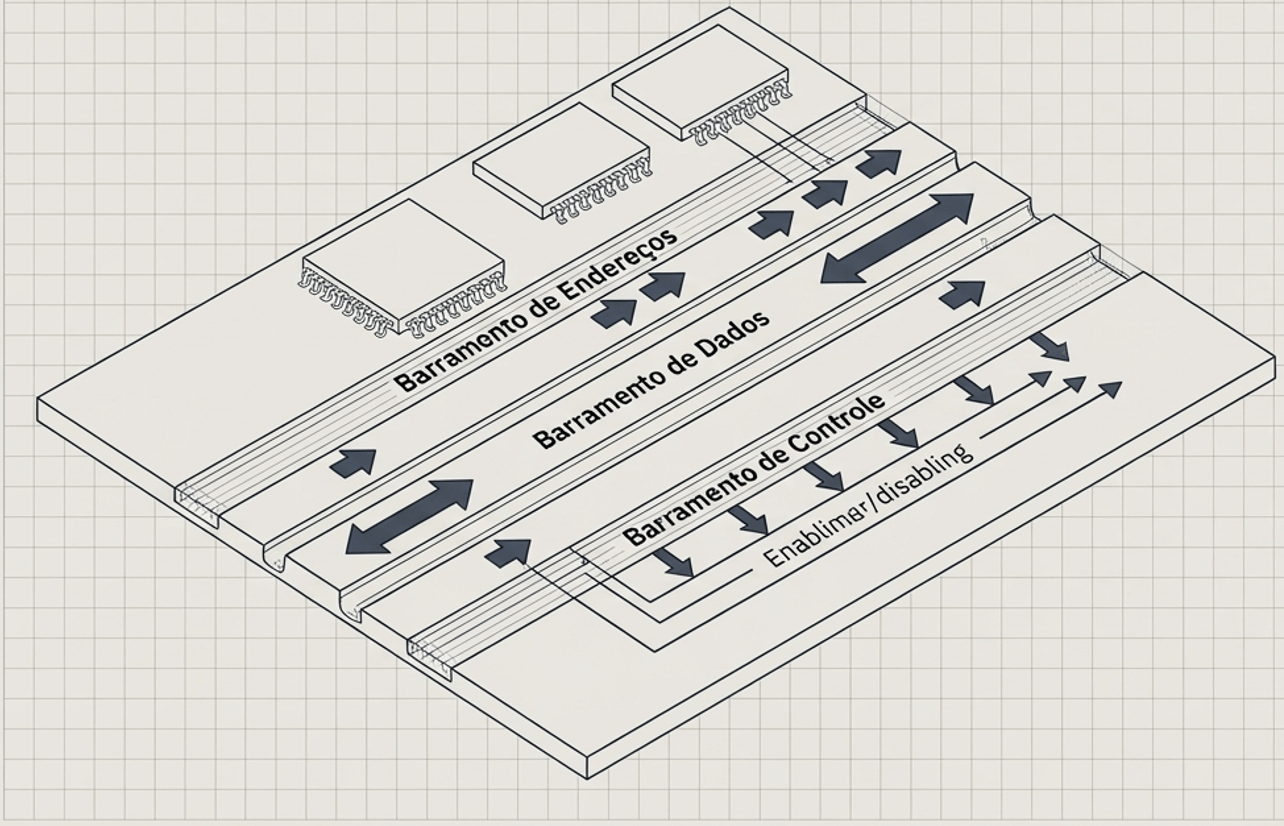

2.3 Barramentos
Comunicação dos componentes
2.4 Dispositivos de Entrada e Saída
Comunicação dos componentes

Os dispositivos E/S permitem a comunicação entre o computador e o mundo externo, facilitando a interação do usuário com o sistema.
2.4 Dispositivos de Entrada e Saída
2.4 Dispositivos de Entrada e Saída
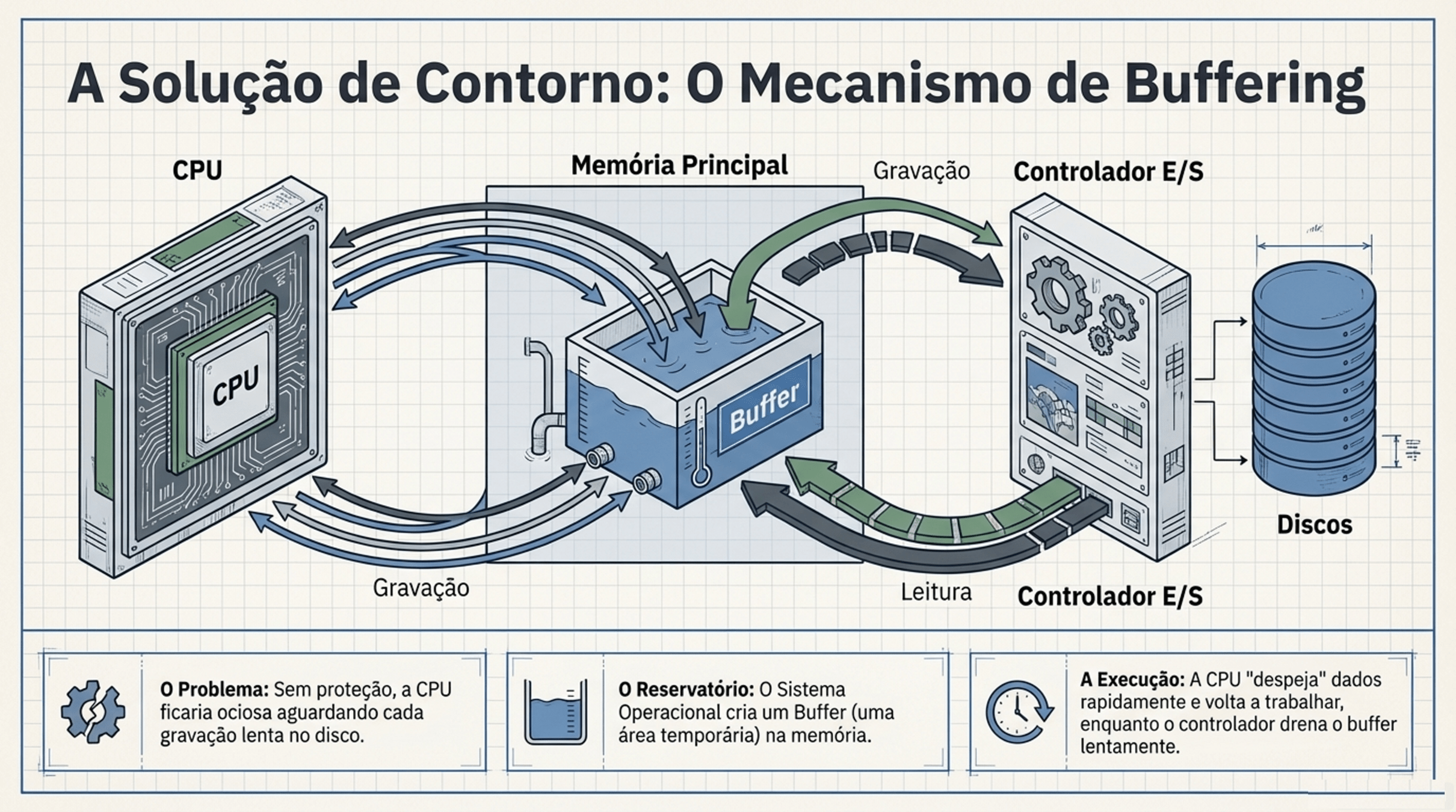
2.5 As pontes entre componentes
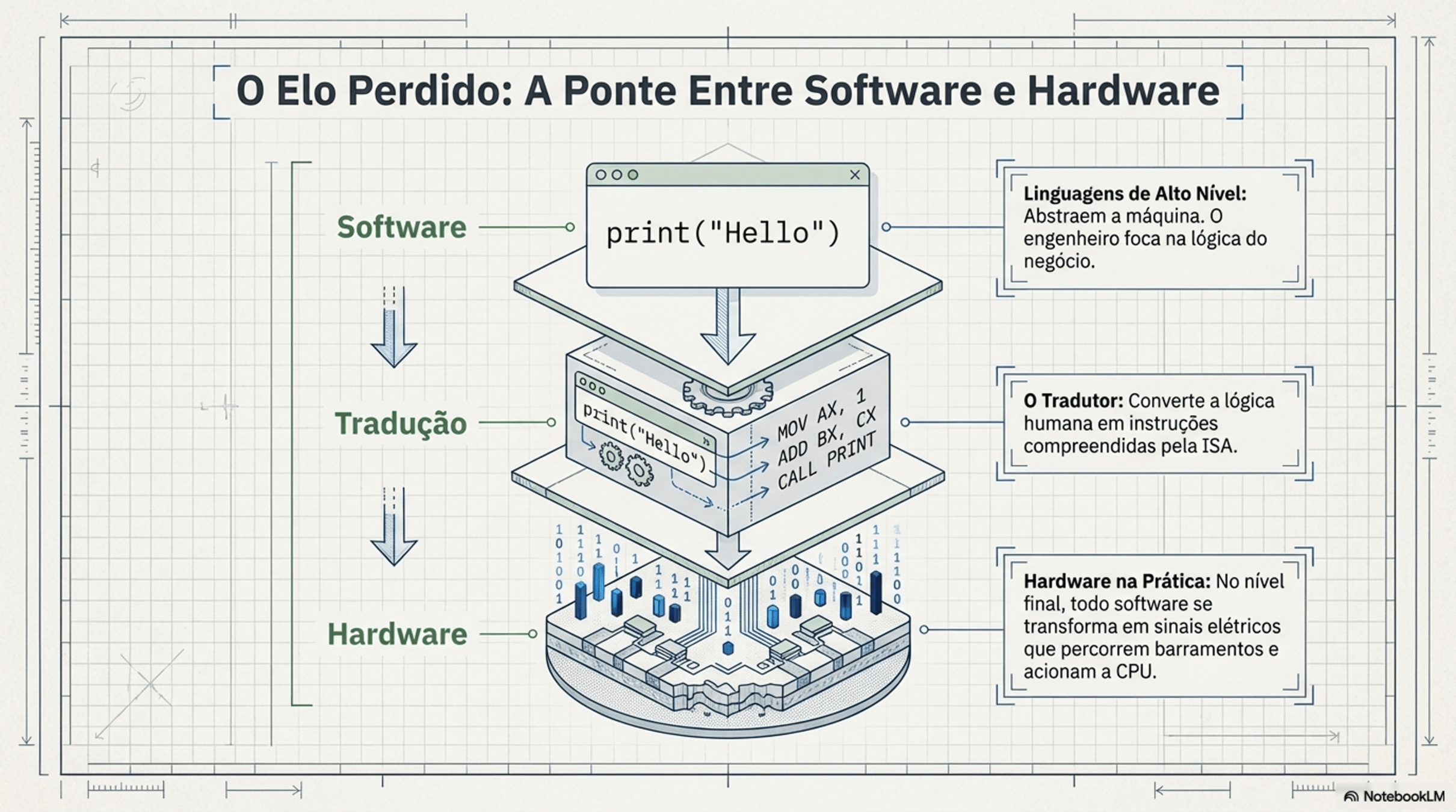
2.5 As pontes entre componentes
Do Start ao SO
Aula 4
| Capítulo 3 - ULA, UC e Registradores |
| A cozinha completa do Chef |
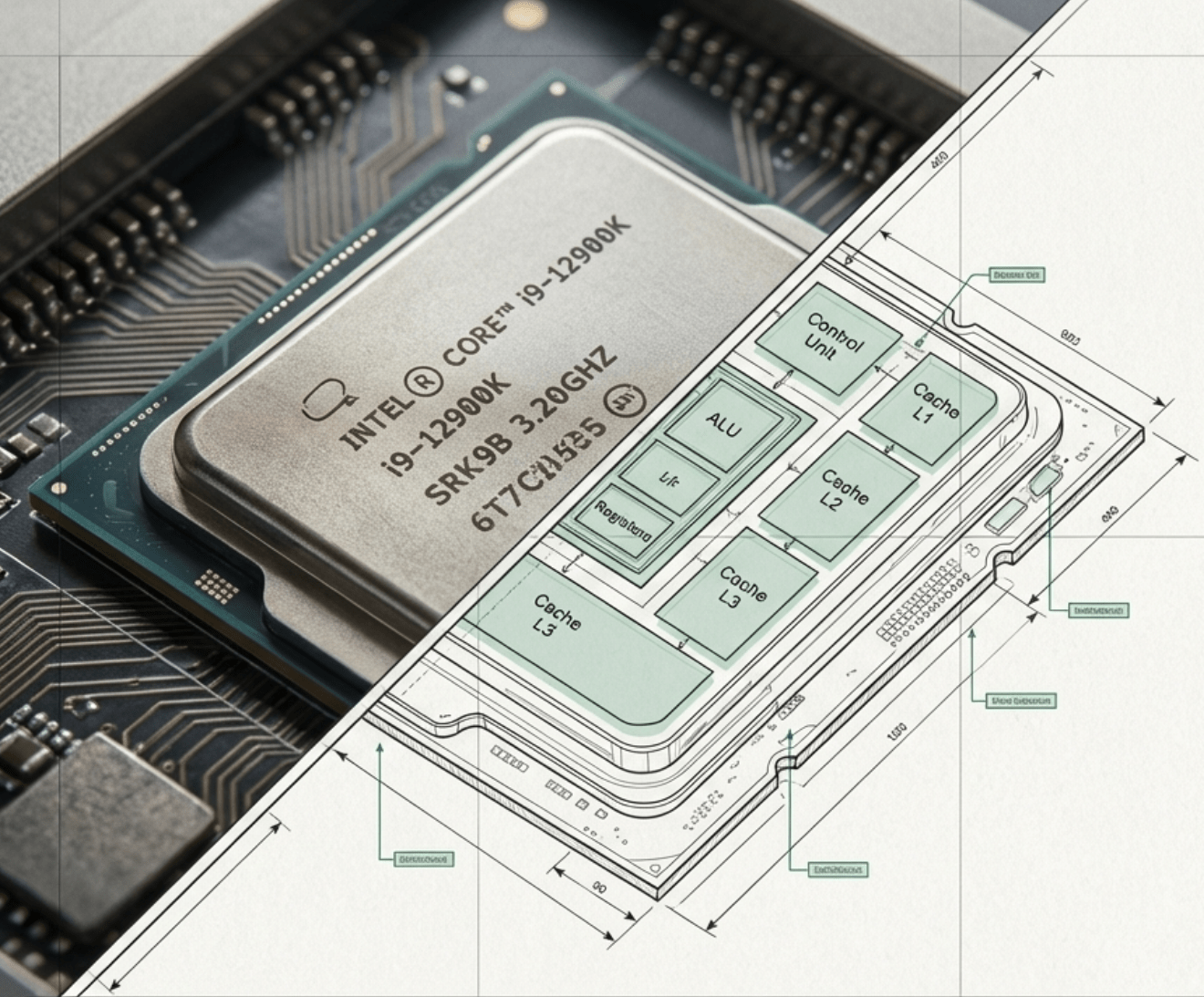
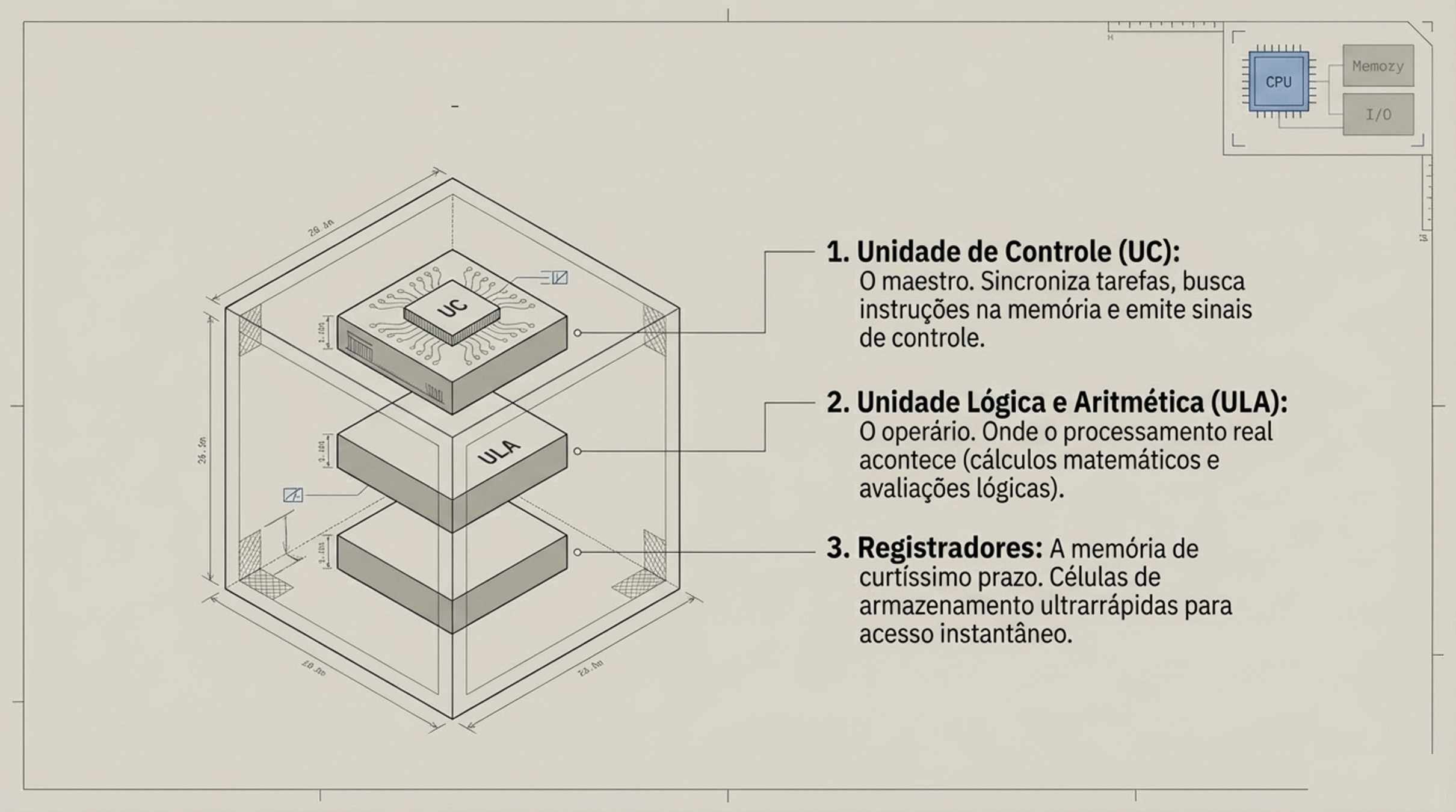
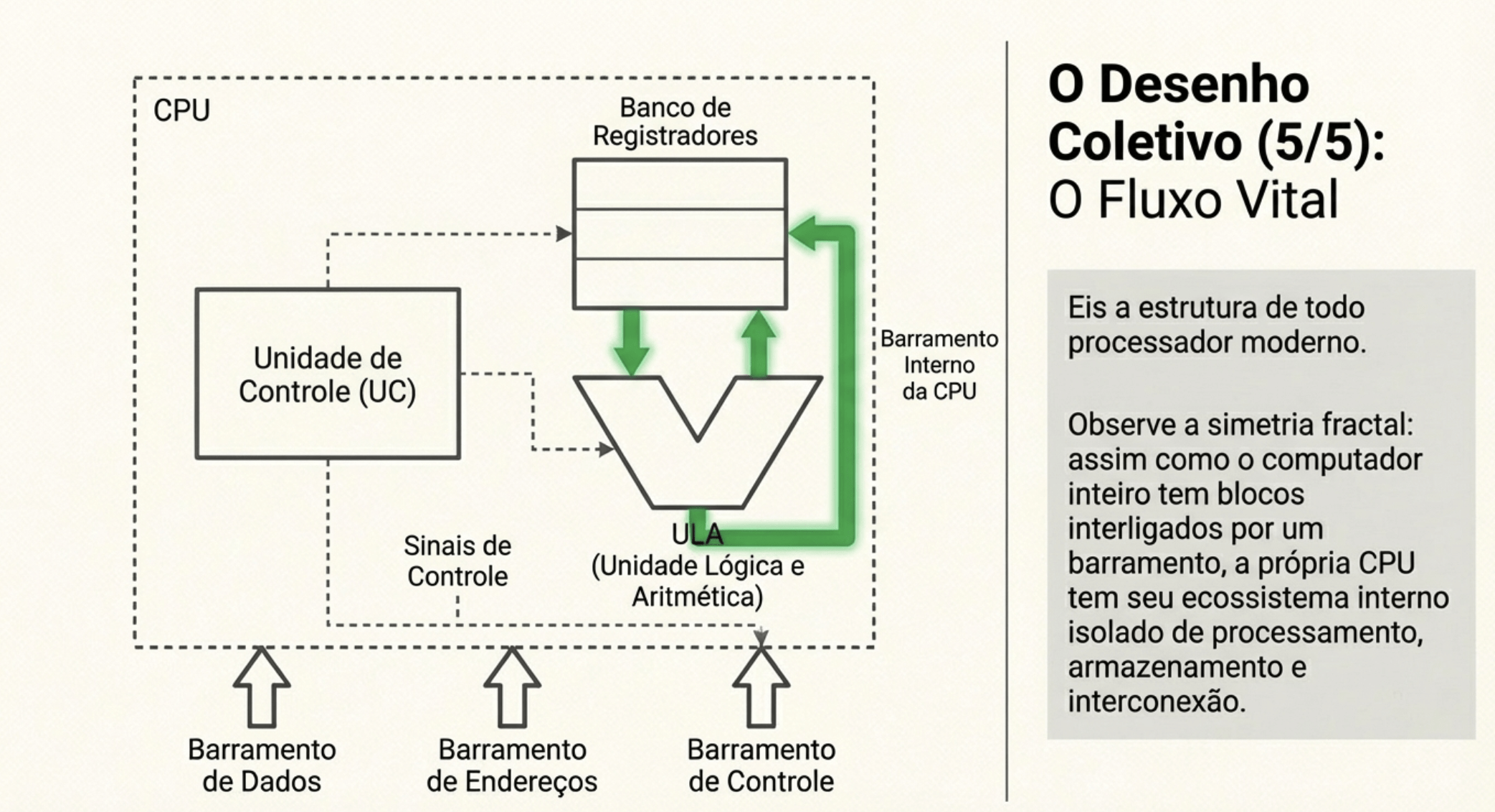
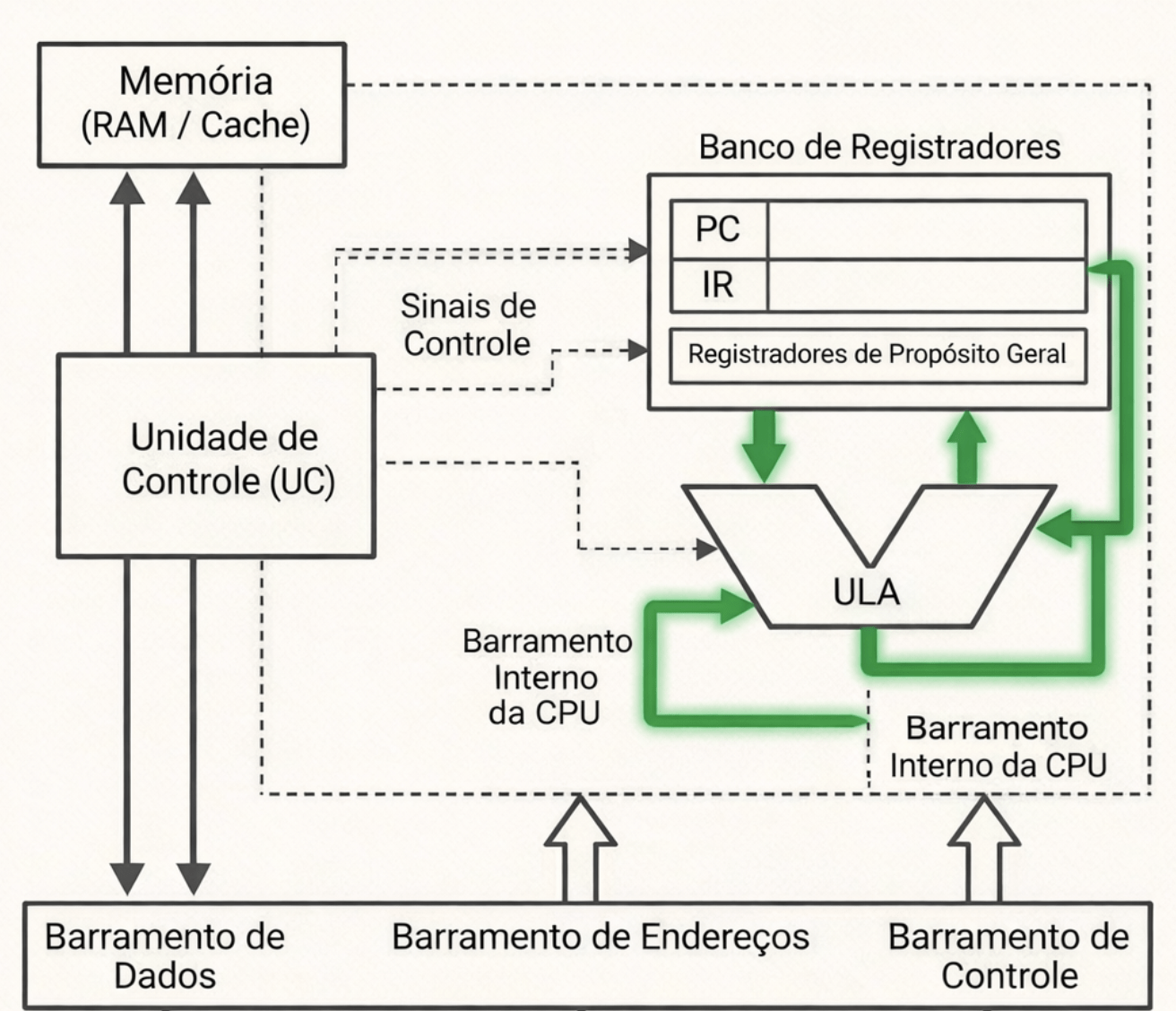
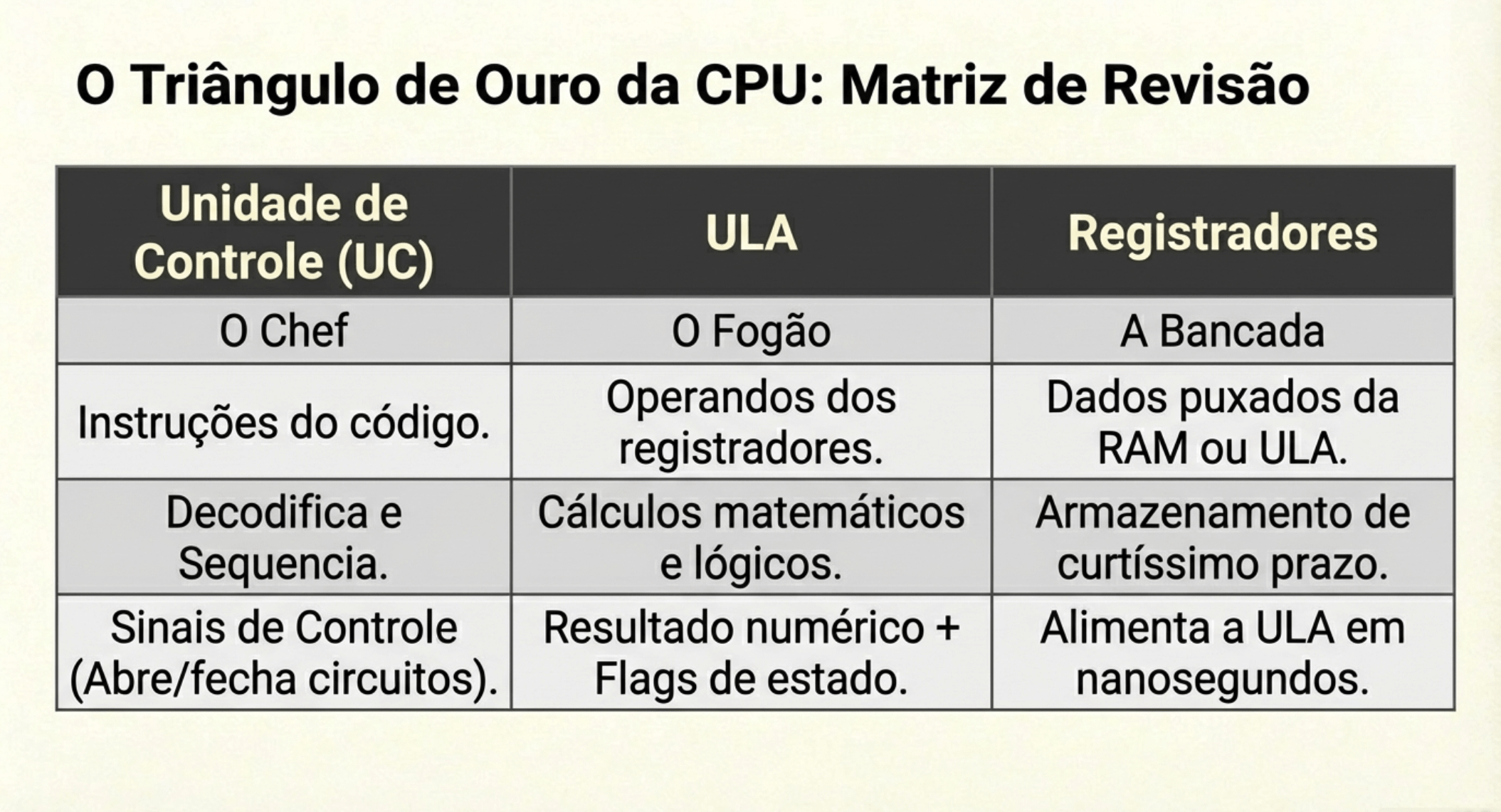
CPU
3. UC, ULA e Registradores
“Quando eu executo uma instrução, o que acontece dentro da CPU?”
CPU
3. UC, ULA e Registradores
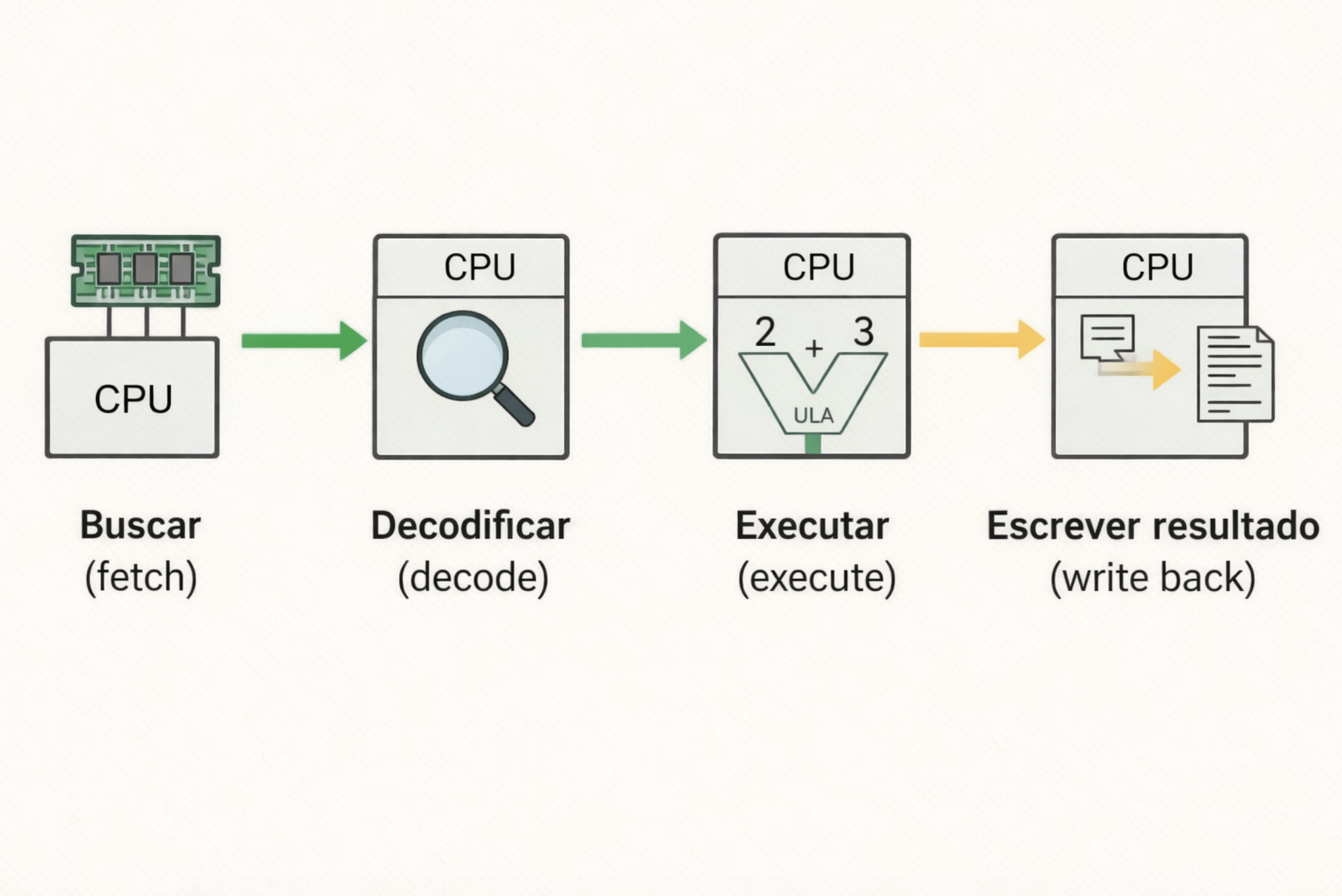
CPU
3. UC, ULA e Registradores
CPU
3. UC, ULA e Registradores
CPU
3. UC, ULA e Registradores
CPU
3. UC, ULA e Registradores

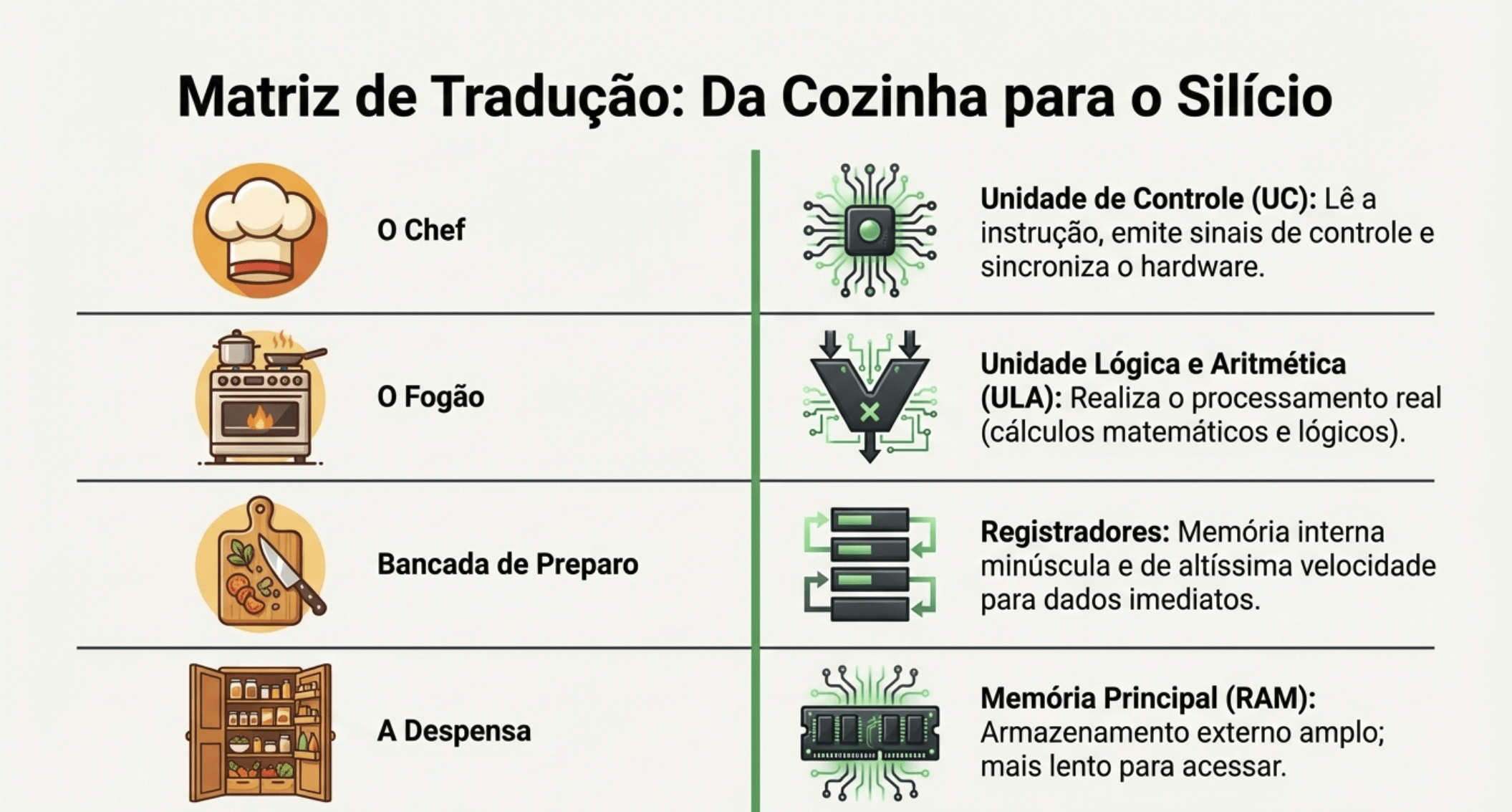
3. UC, ULA e Registradores
3. UC, ULA e Registradores
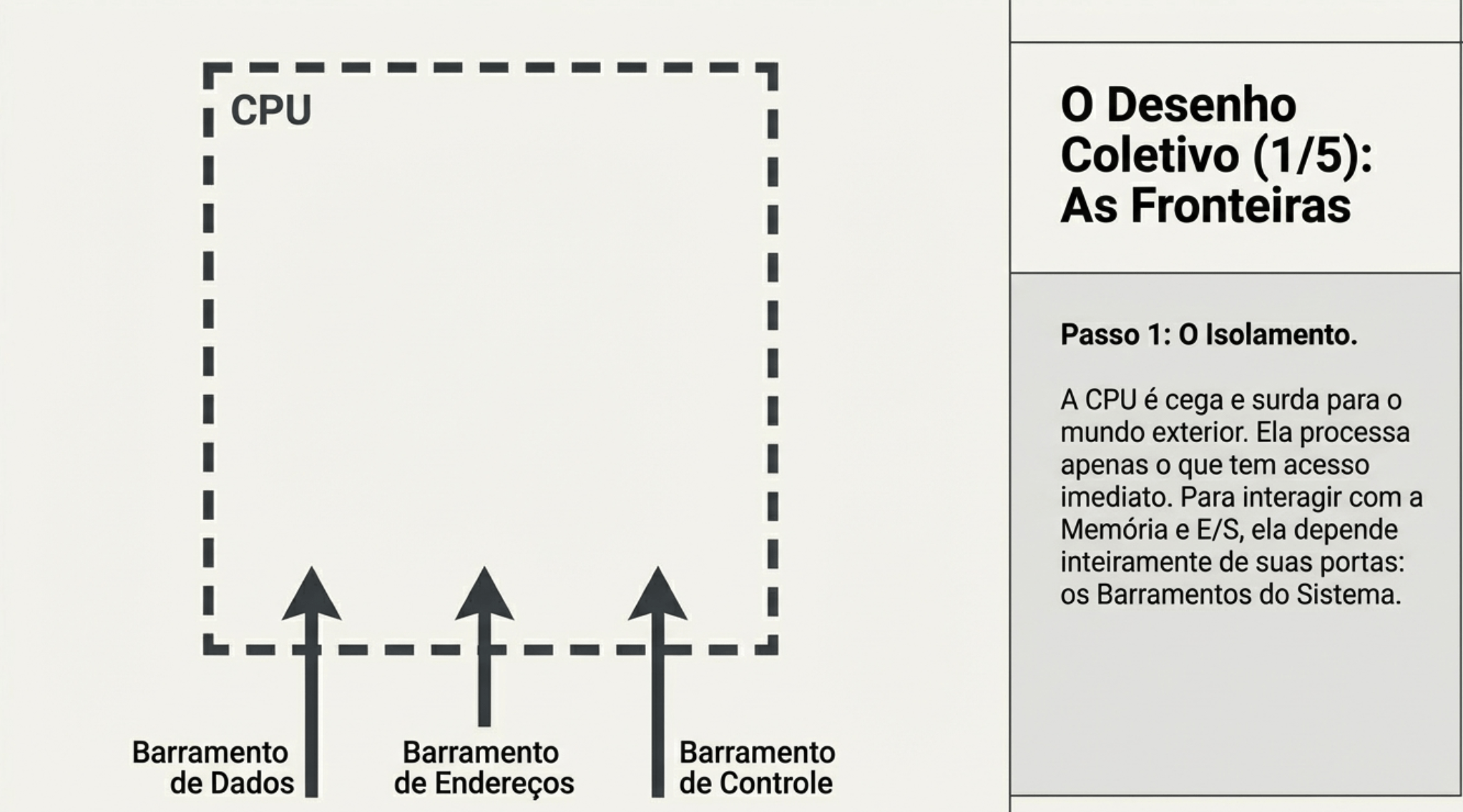
3. UC, ULA e Registradores
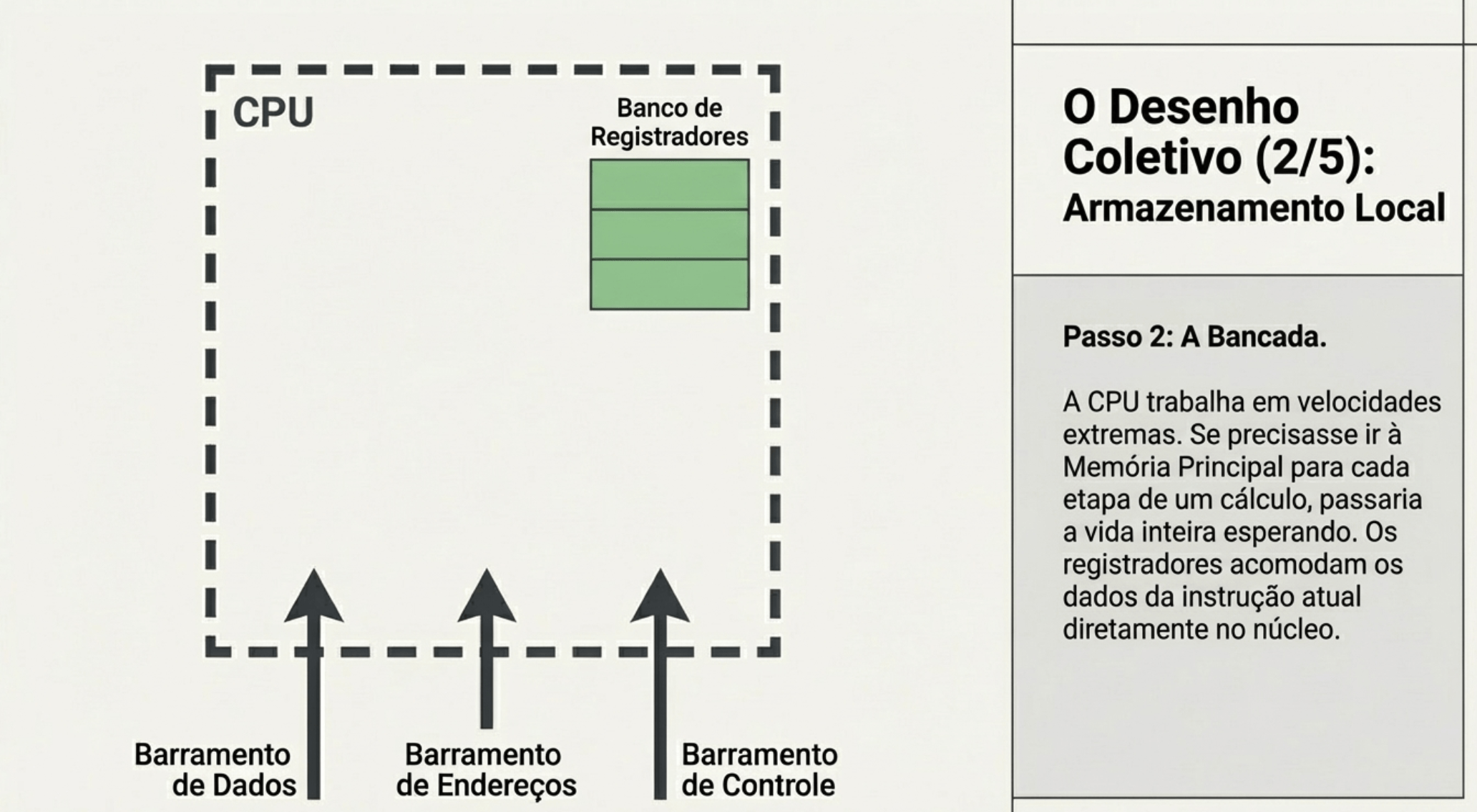
3. UC, ULA e Registradores
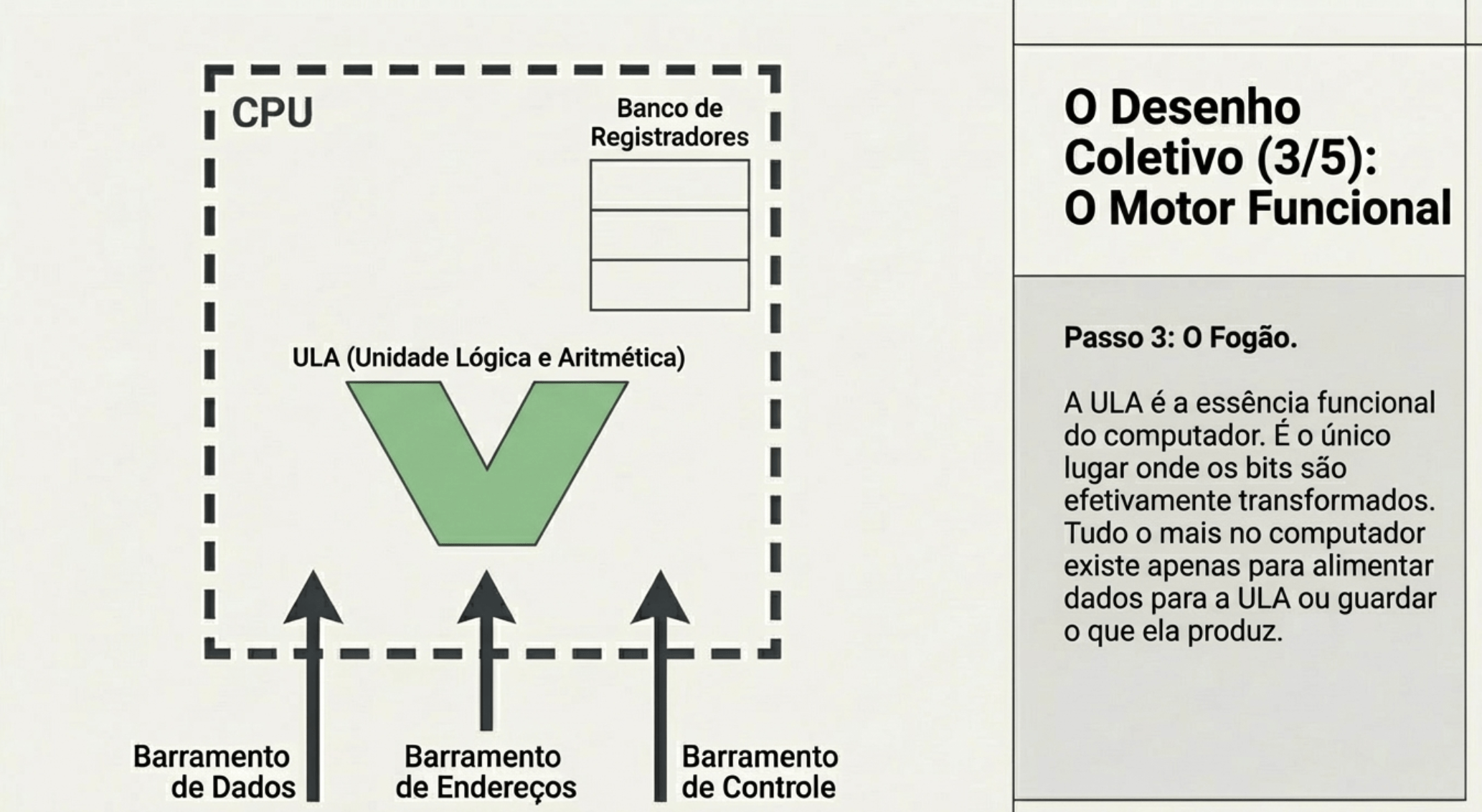
3. UC, ULA e Registradores
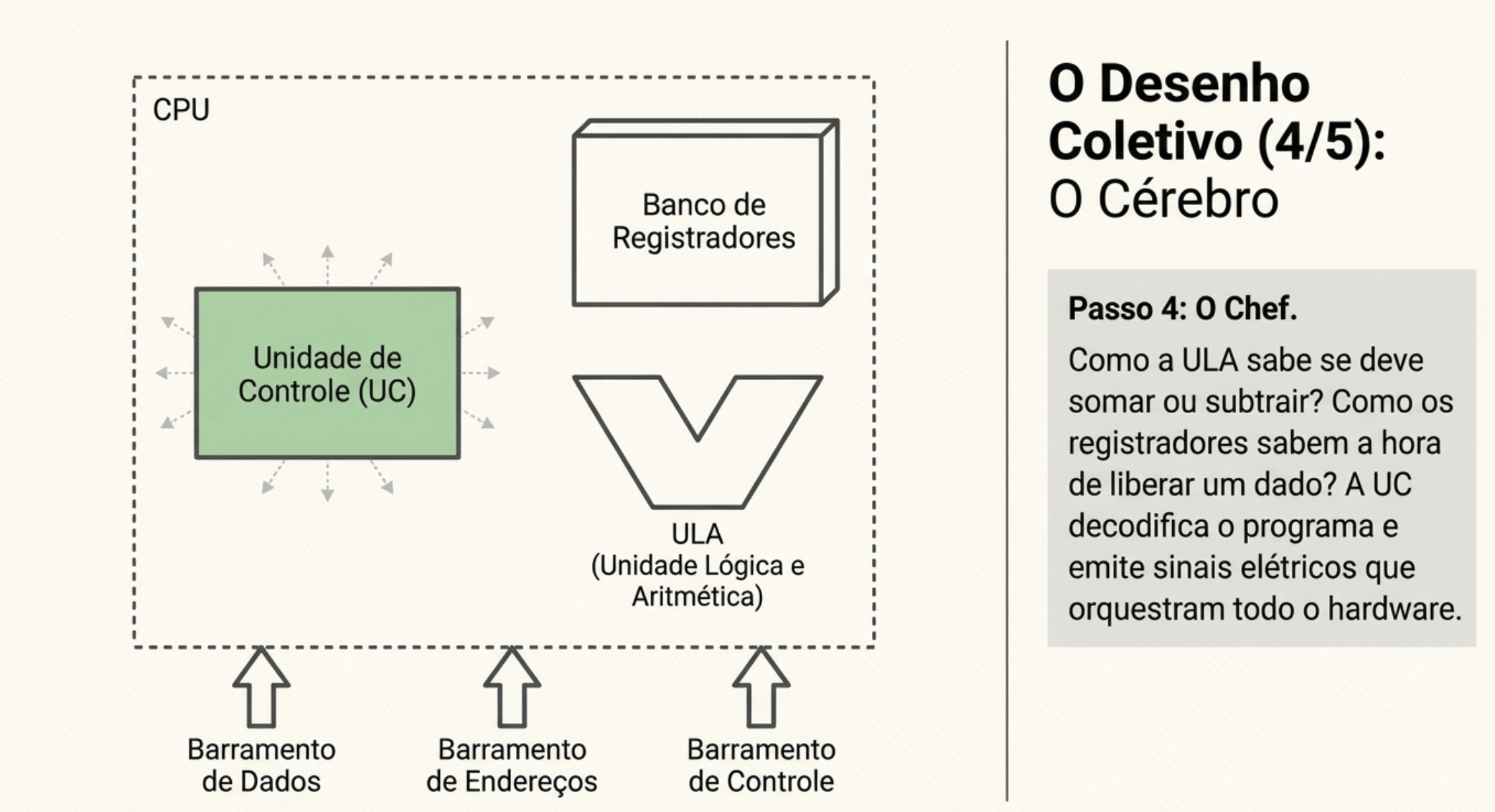
3. UC, ULA e Registradores
Instruction Register
Contador Programa
3. UC, ULA e Registradores
3. UC, ULA e Registradores
3. UC, ULA e Registradores
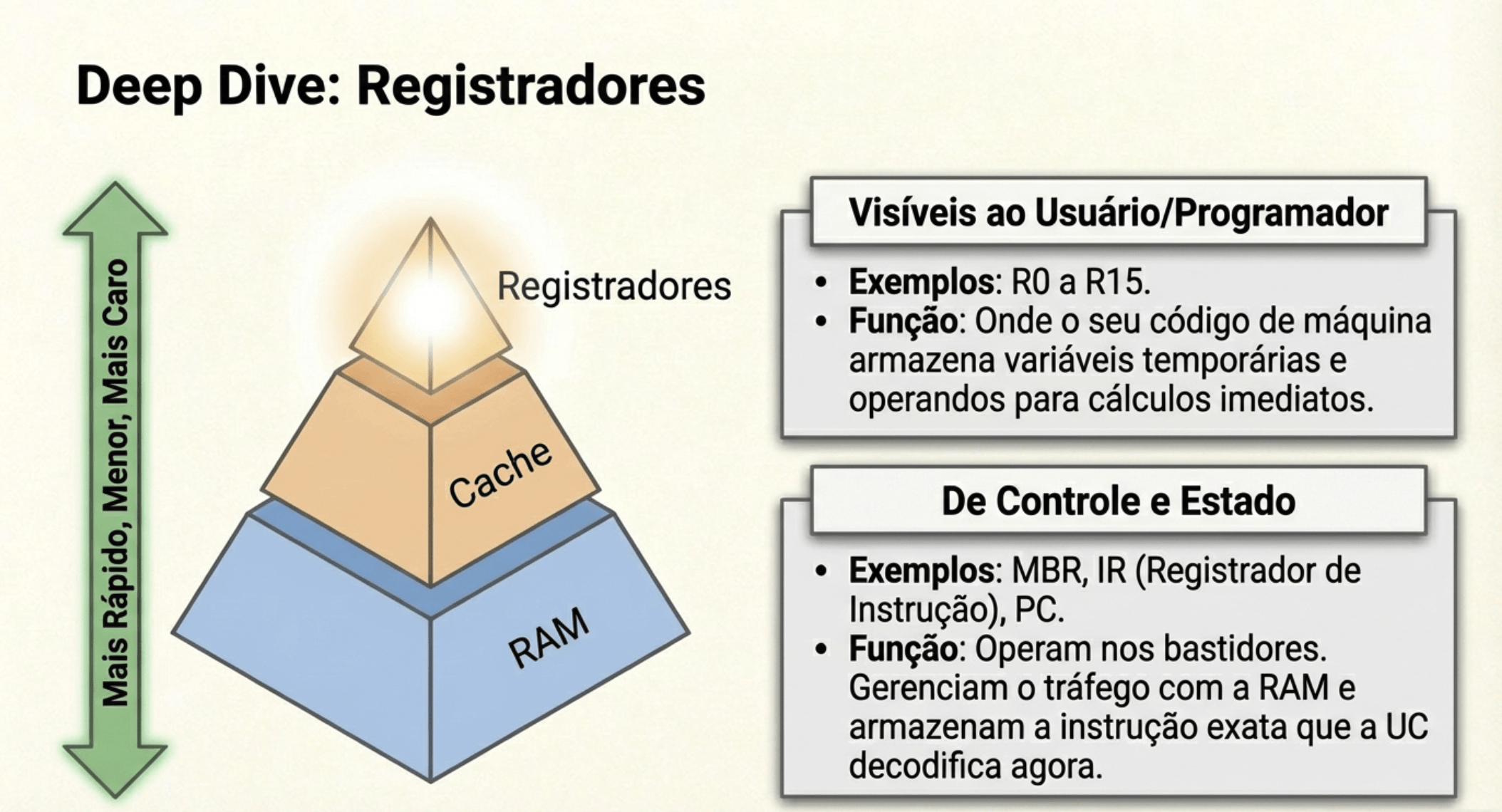
3. UC, ULA e Registradores

3. UC, ULA e Registradores
3. UC, ULA e Registradores
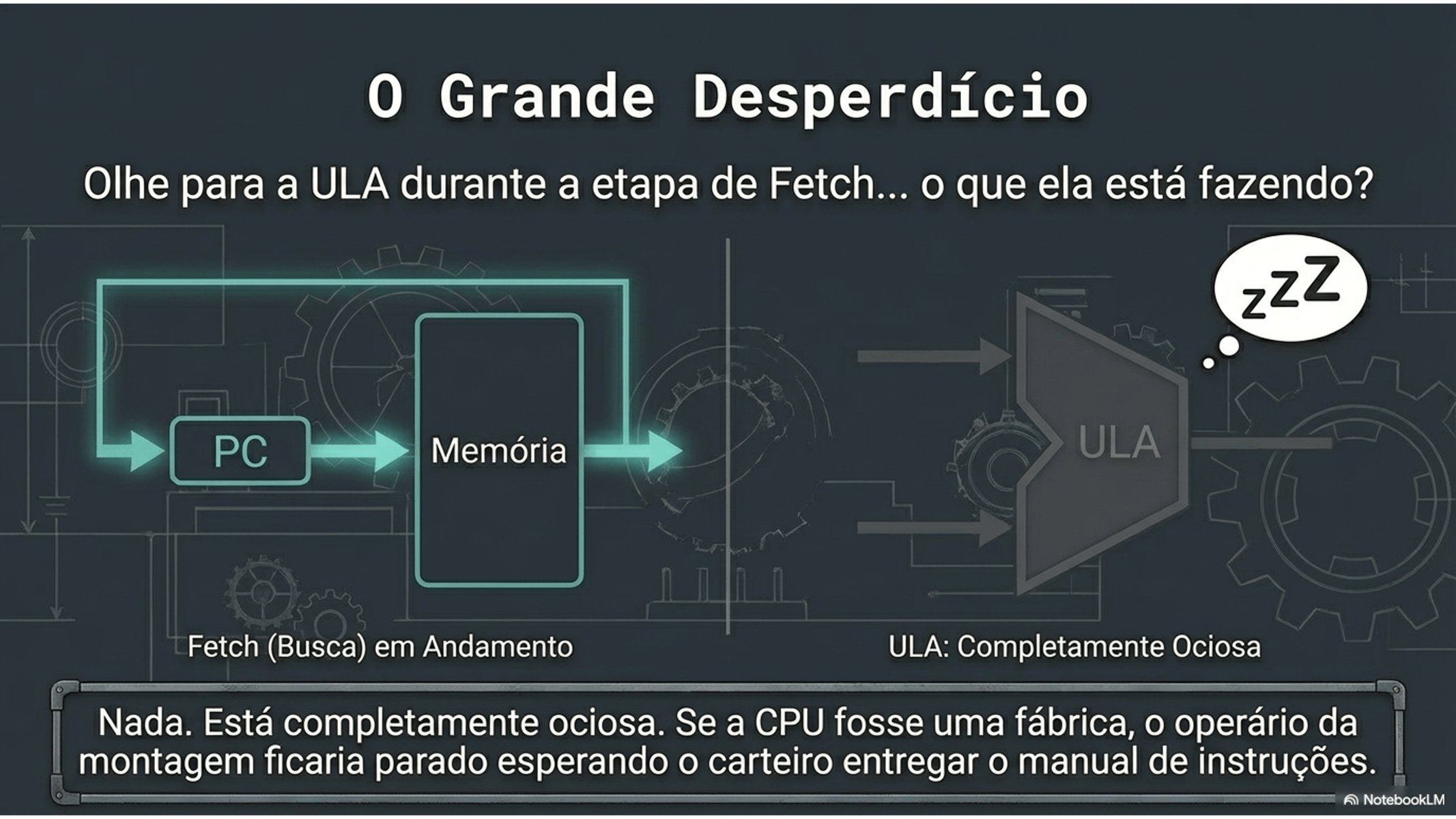
CPU sempre busca dados da memória?
“A CPU sempre busca instruções na memória.
Os dados… só quando precisa.”
3. UC, ULA e Registradores
Cada grupo vira um componente:
-
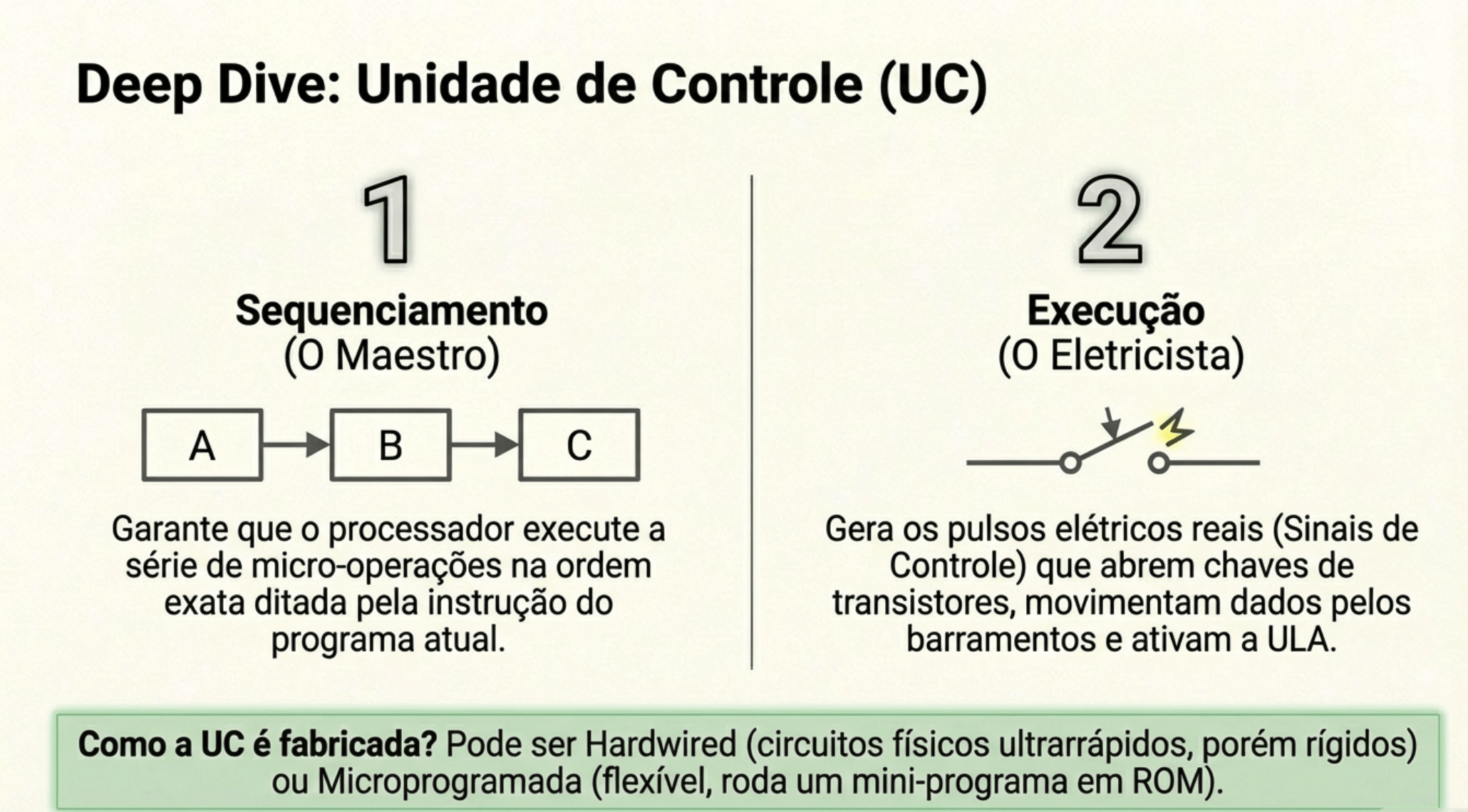
🧠 UC (Unidade de Controle)
-
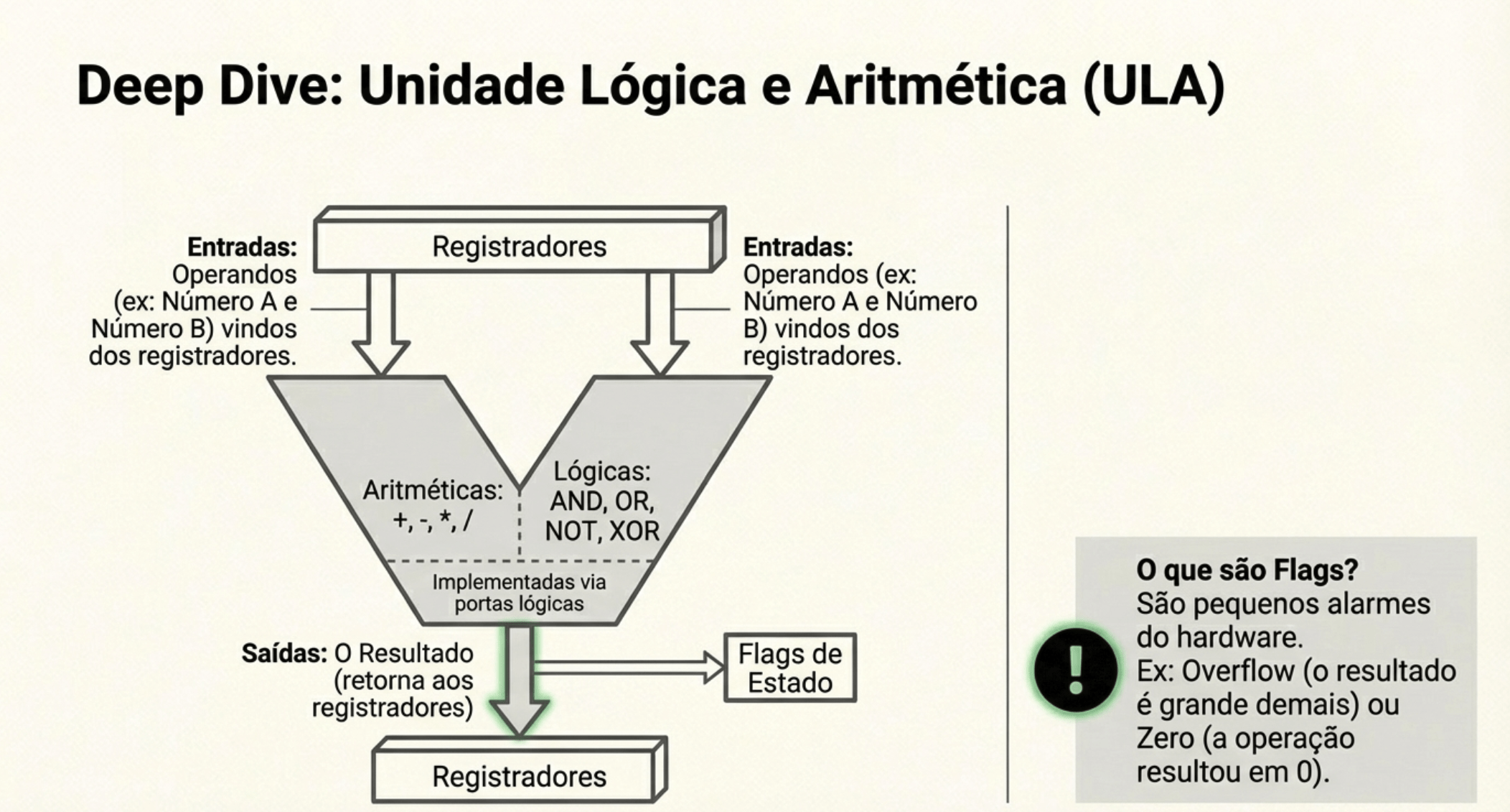
🧮 ULA
-
📦 Registradores (R1, R2, R3…)
-
💾 Memória
-
📍 PC (Program Counter)
-
📜 IR (Instruction Register)
Atividade
3. UC, ULA e Registradores
Etapa 1 — FETCH
“Quem sabe onde está a próxima instrução?”
Registrador Instrução
Contador Programa
PC -> Endereço Ex: 100 em memória
Memória RAM -> Instrução ADD R1, R2
IR -> Recebido e alocado
ADD R1, R2
Definido:
R1 = 2
R2 = 3Cenário da simulação
3. UC, ULA e Registradores
Etapa 1 — FETCH
Registrador Instrução
Contador Programa
ADD R1, R2
Definido:
R1 = 2
R2 = 3Cenário da simulação
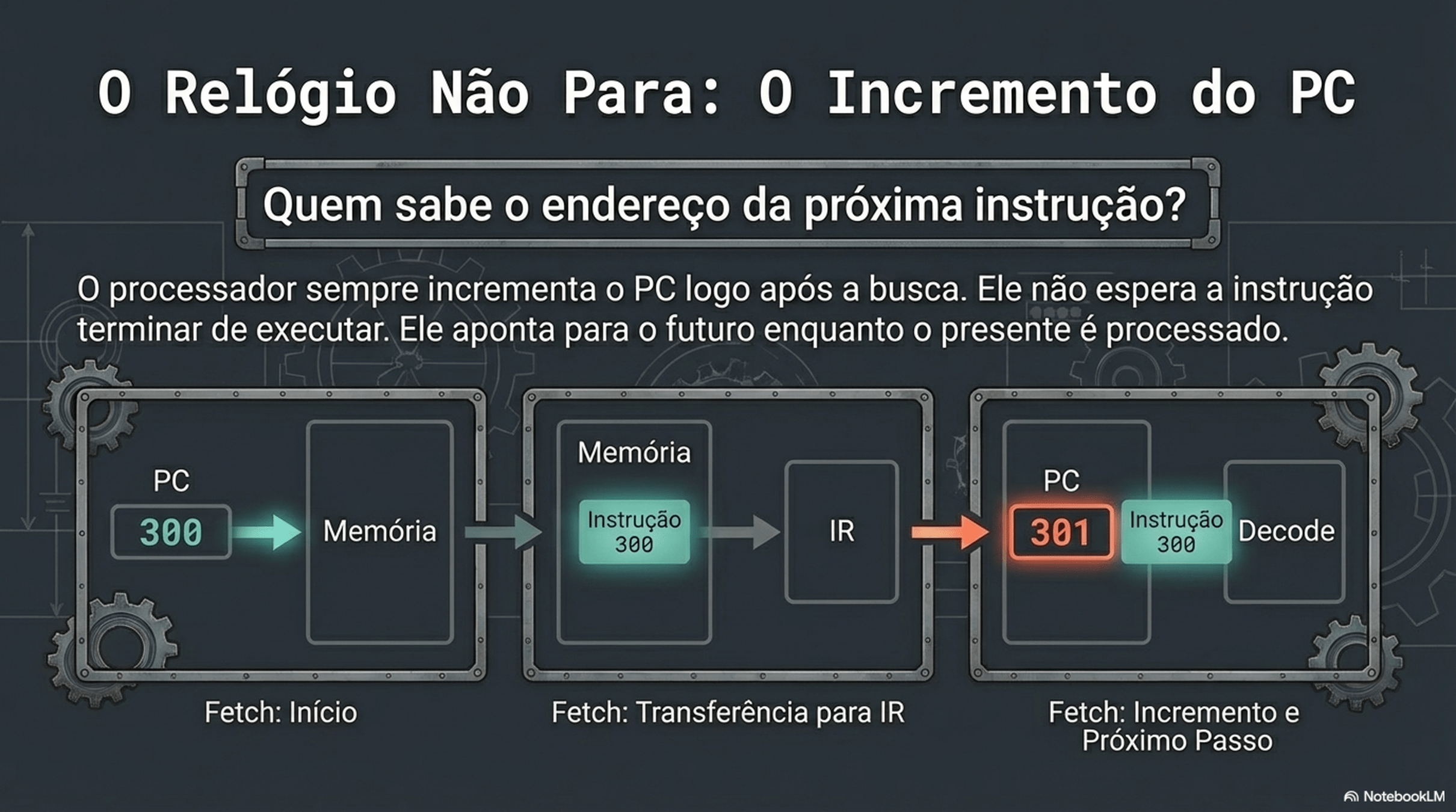
Quem incrementa o PC e quando isso acontece?
A própria CPU, sob controle da UC.
FETCH → (incrementa PC) → DECODE → EXECUTEO PC incrementa sempre sequencialmente?
O PC normalmente anda para frente, mas a UC pode mandar ele pular.
3. UC, ULA e Registradores
Etapa 1 — FETCH
Registrador Instrução
Contador Programa
int i = 0;
while (i < 3) {
i = i + 1;
}Cenário da simulação
100: LOAD R1, 0 ; i = 0
104: CMP R1, 3 ; compara i < 3
108: JGE 120 ; se i >= 3, sai do loop
112: ADD R1, R1, 1 ; i = i + 1
116: JMP 104 ; volta pro loop
120: END🔹 Estado inicial
-
PC = 100
-
R1 = ?
🔹 1 — FETCH (100)
-
PC aponta 100
-
Memória entrega:
LOAD R1, 0 -
IR recebe
➡️ UC manda executar
✔ Resultado:
-
R1 = 0
-
PC → 104
🔹 2 — FETCH (104)
-
Instrução:
CMP R1, 3
ULA:
-
Compara 0 com 3
➡️ Resultado: menor
✔ PC → 108
🔹 3 — FETCH (108)
-
JGE 120
➡️ Não (0 < 3)
✔ PC → 112
💥 Aqui tu trava e pergunta:
“Por que não pulou?”
🔹 4 — FETCH (112)
-
ADD R1, R1, 1
ULA:
-
0 + 1 = 1
✔ R1 = 1
✔ PC → 116
🔹 5 — FETCH (116)
-
JMP 104
👉 Aqui quebra o padrão
✔ PC = 104 (não 120, não 120, nem 120 — reforça isso)
3. UC, ULA e Registradores
Etapa 2 — DECODE
“Quem decide isso?”
Registrador Instrução
Contador Programa
UC entra:
-
“Isso é um ADD”
-
“Preciso de R1 e R2”
ADD R1, R2
Definido:
R1 = 2
R2 = 3Cenário da simulação
3. UC, ULA e Registradores
Etapa 3 — EXECUTE
Registrador Instrução
Contador Programa
Registradores:
-
R1 → envia 2
-
R2 → envia 3
ULA:
-
“2 + 3 = 5”
ADD R1, R2
Definido:
R1 = 2
R2 = 3Cenário da simulação
3. UC, ULA e Registradores
Etapa 4 — WRITE BACK
Registrador Instrução
Contador Programa
UC:
-
“Resultado vai pra R1”
Registrador:
-
R1 = 5
ADD R1, R2
Definido:
R1 = 2
R2 = 3Cenário da simulação
Aula 5
| Capítulo 4 - Paralelismo e Hazards |
| Desconstruindo a ilusão de processamento instantâneo |

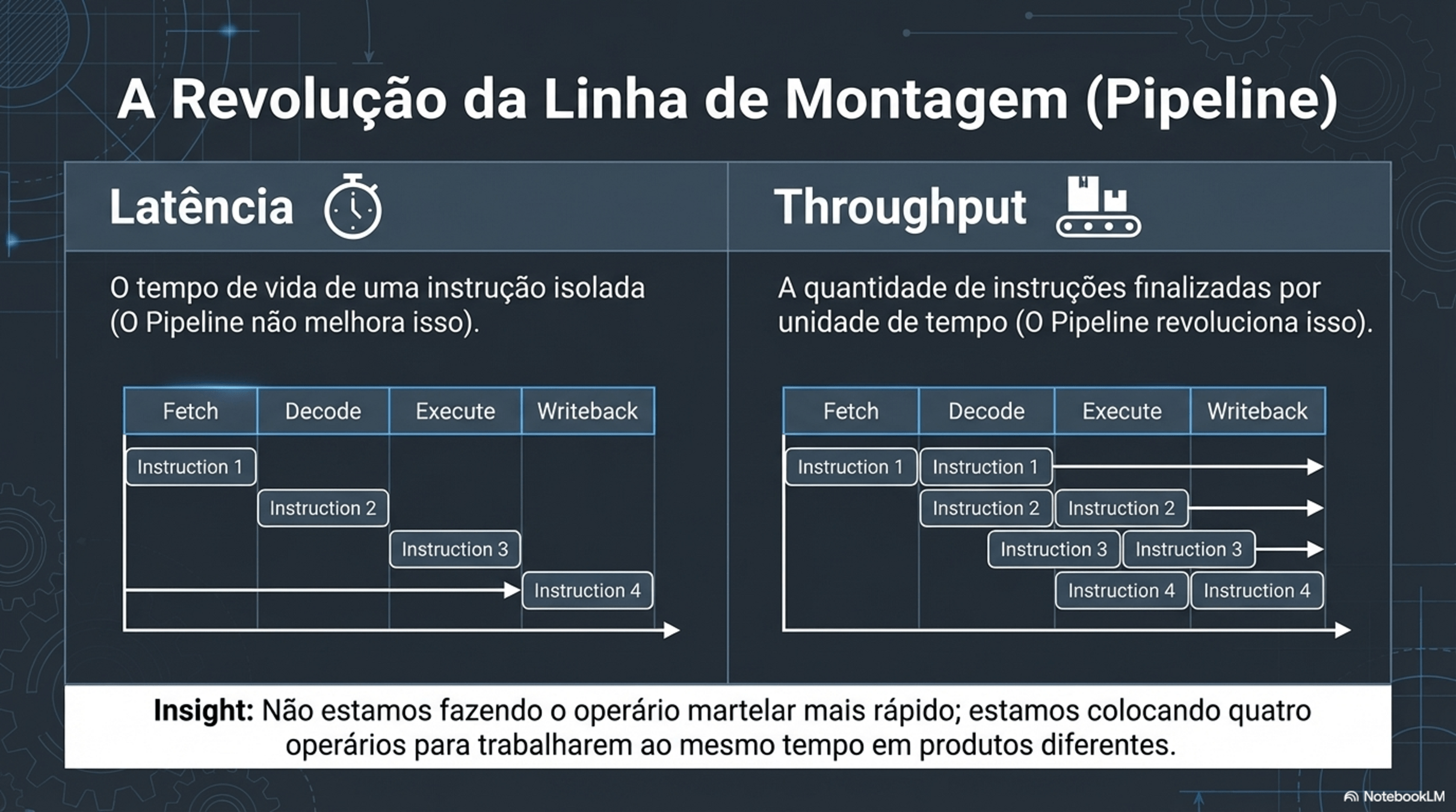
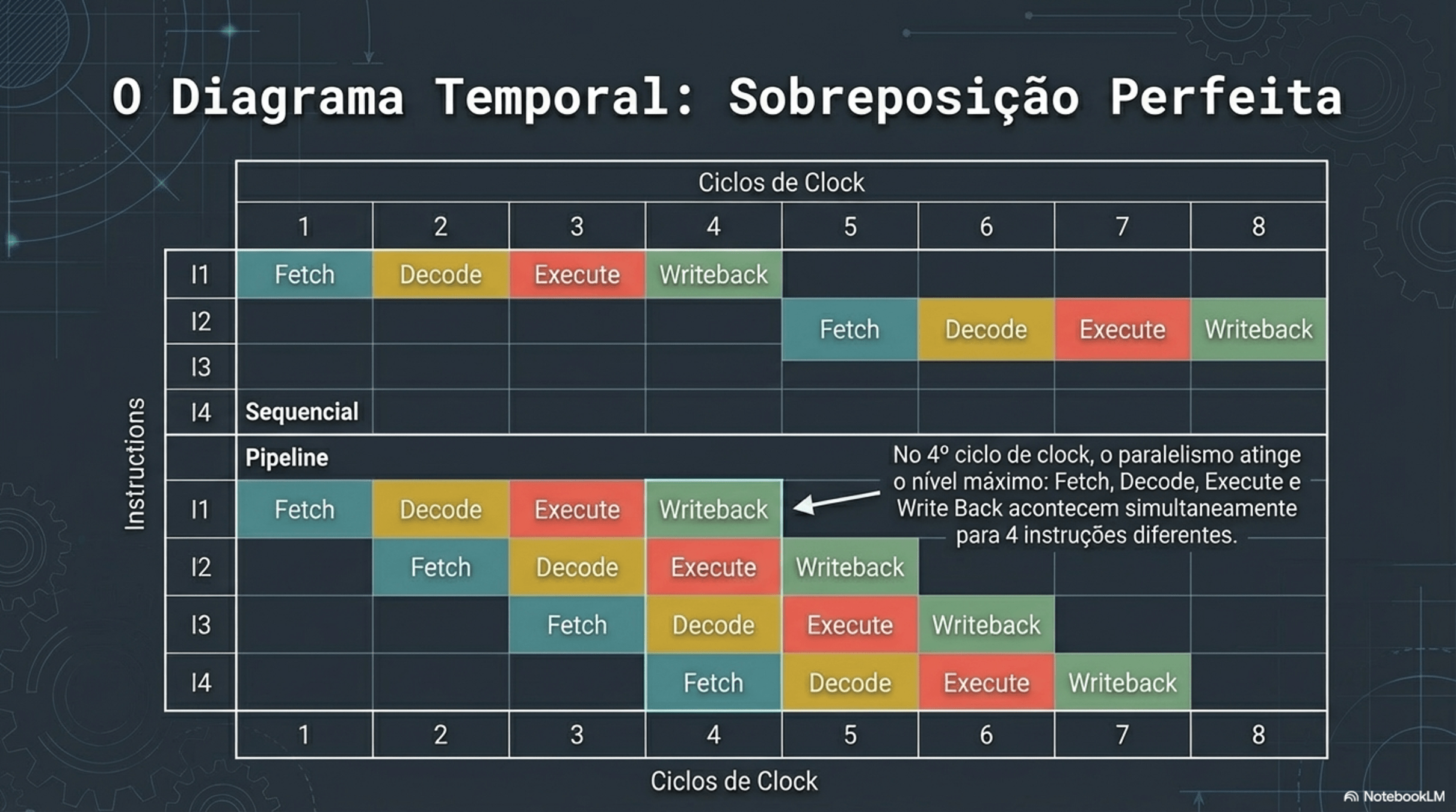
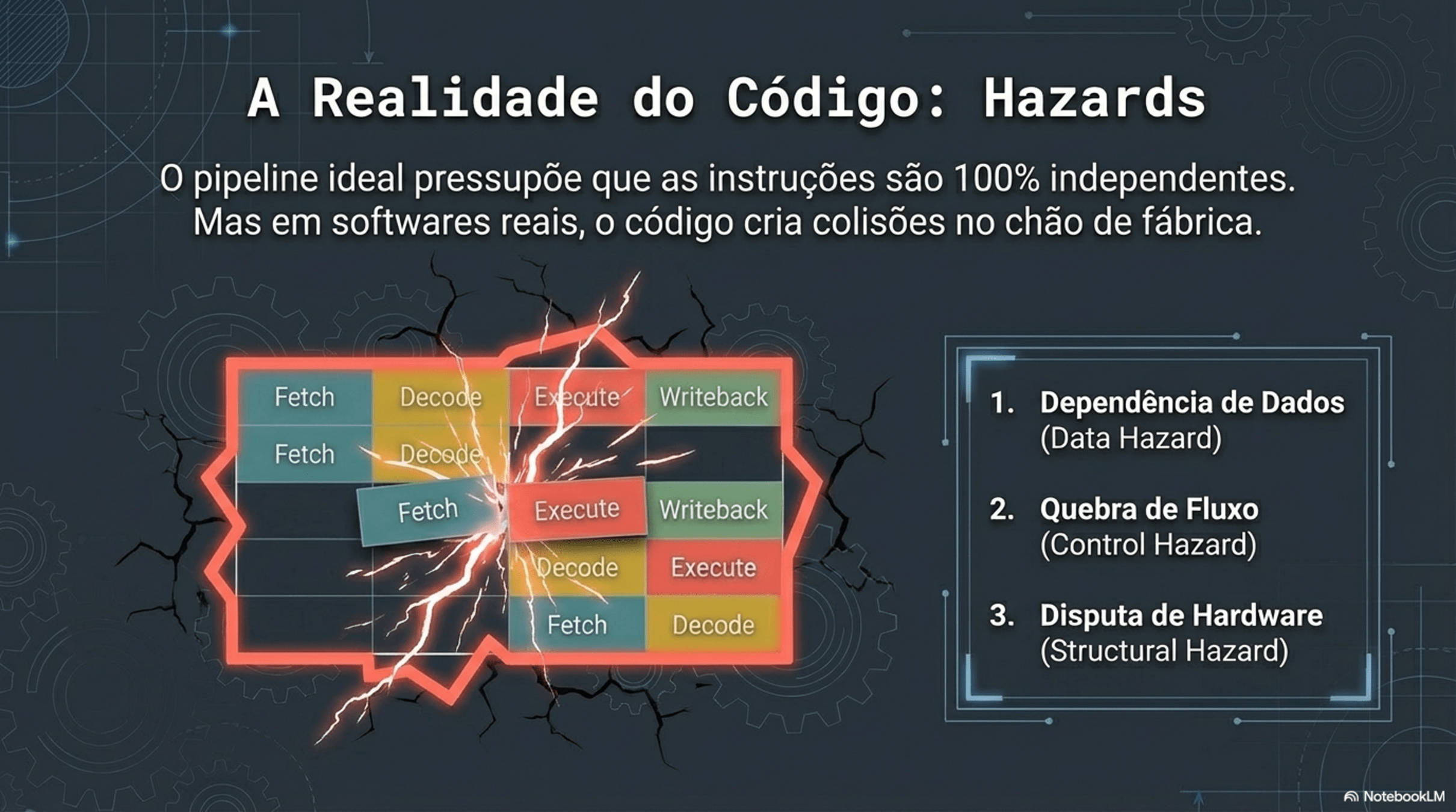
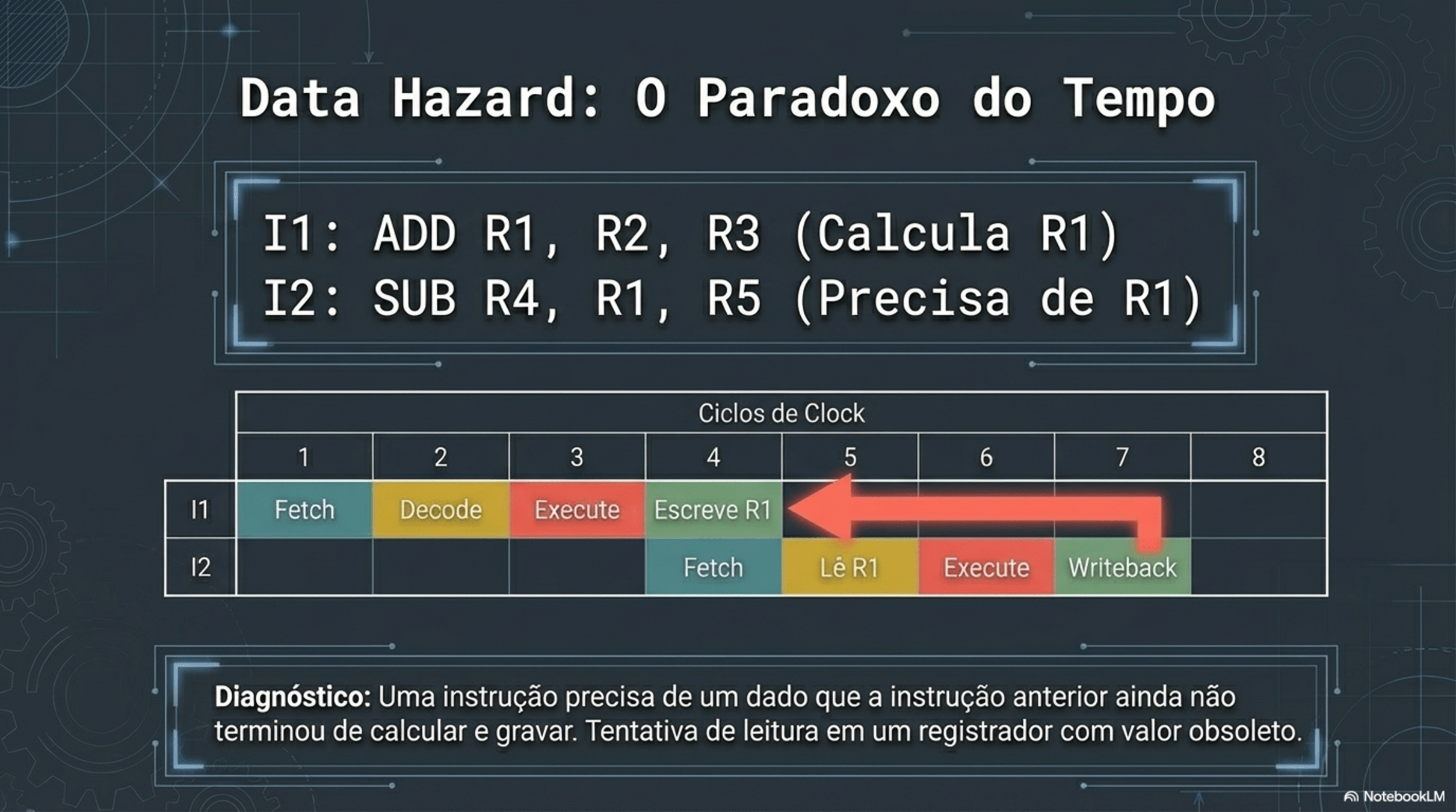
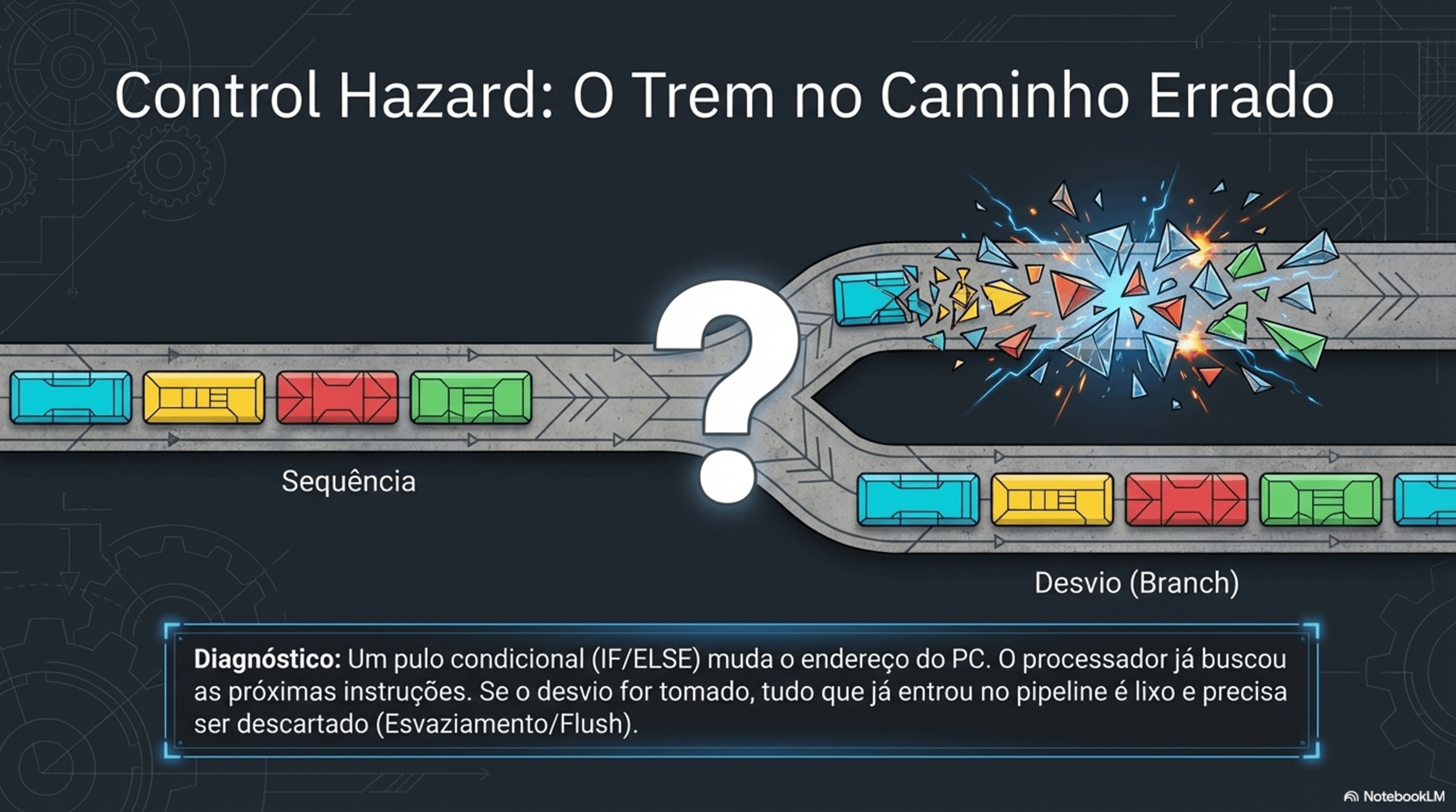
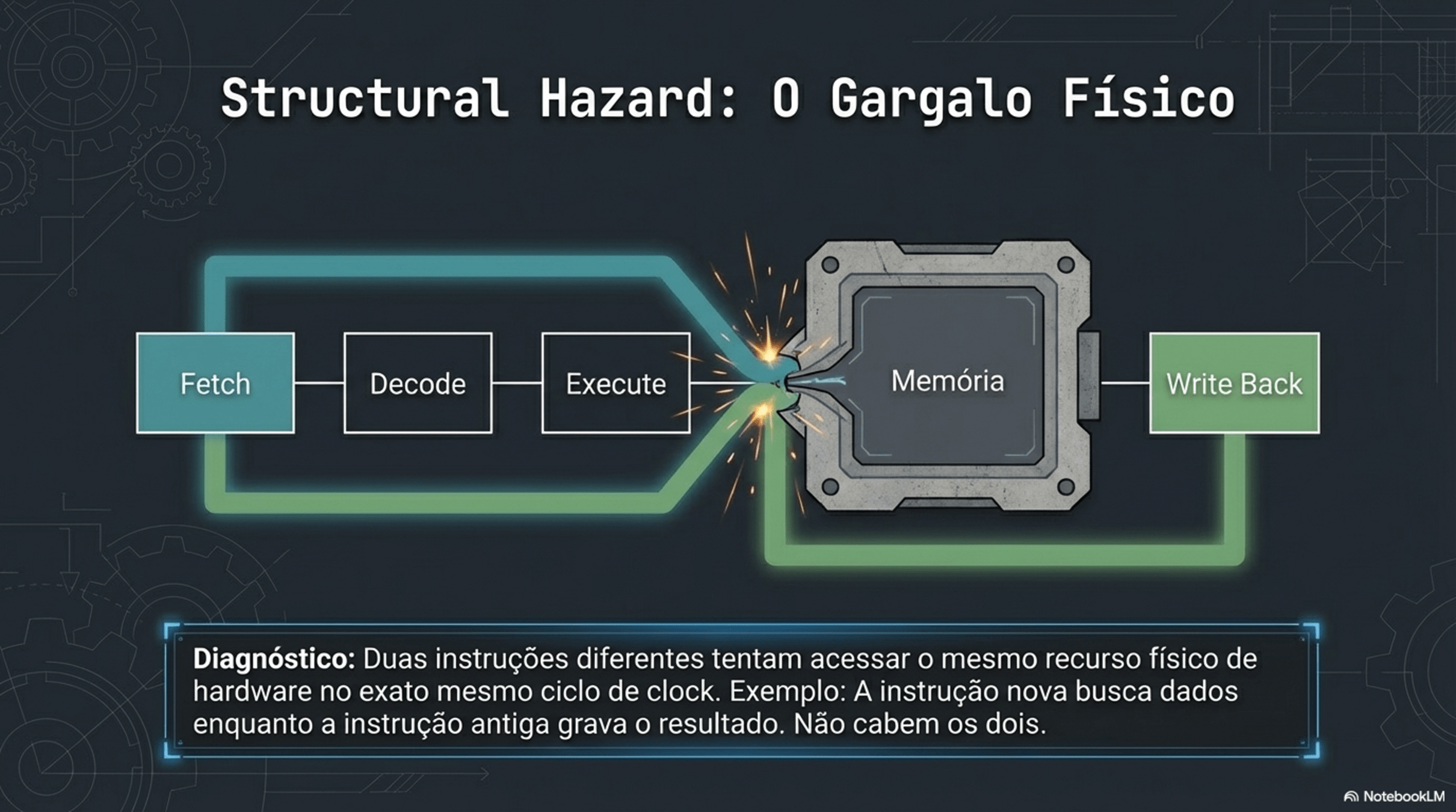
4. Paralelismo e Hazards
Registradores: são compartilhados?
Não. Cada núcleo tem seus próprios registradores.
4. Paralelismo e Hazards
O que é compartilhado então??
Memória RAM
4. Paralelismo e Hazards
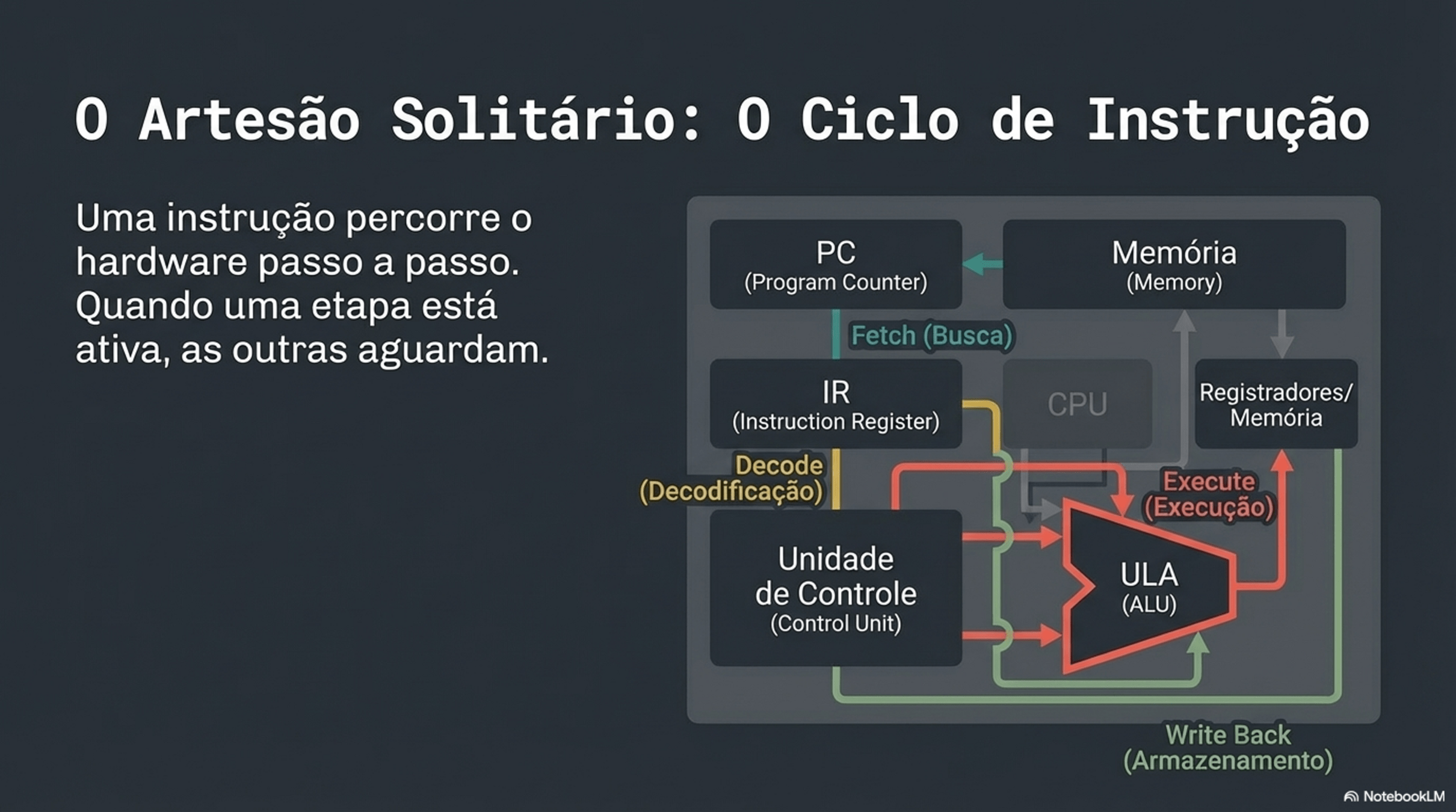
4. Paralelismo e Hazards
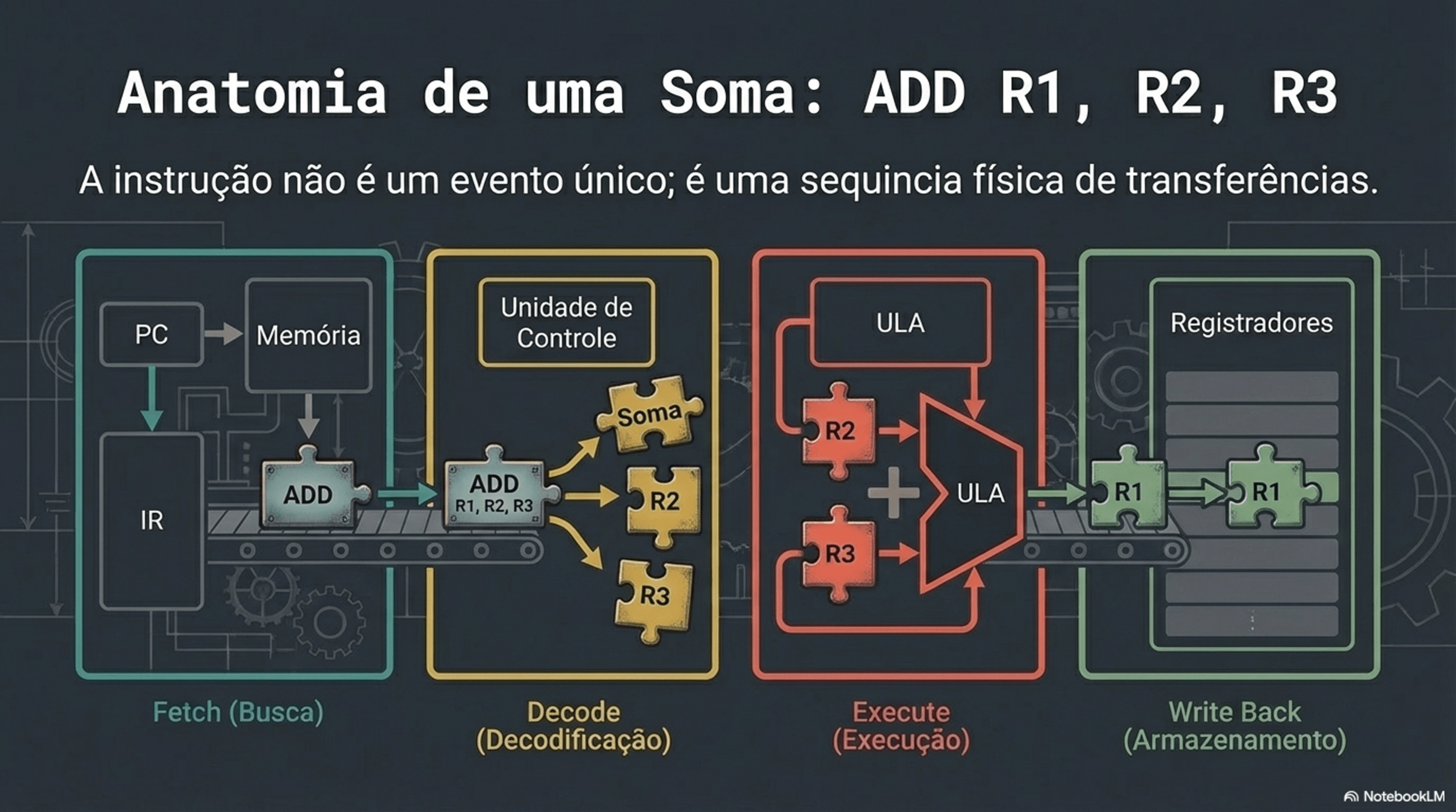
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
4. Paralelismo e Hazards
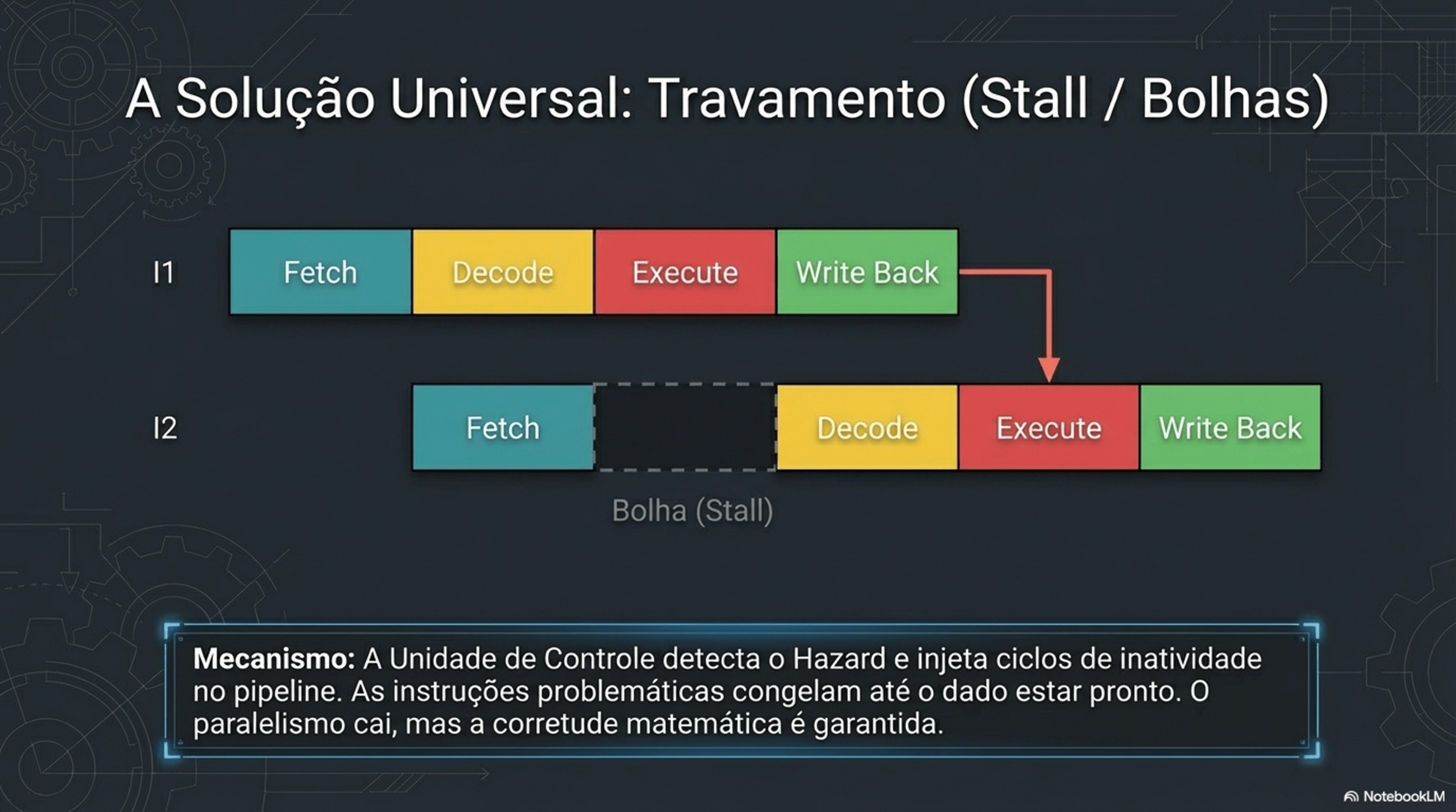
4. Paralelismo e Hazards
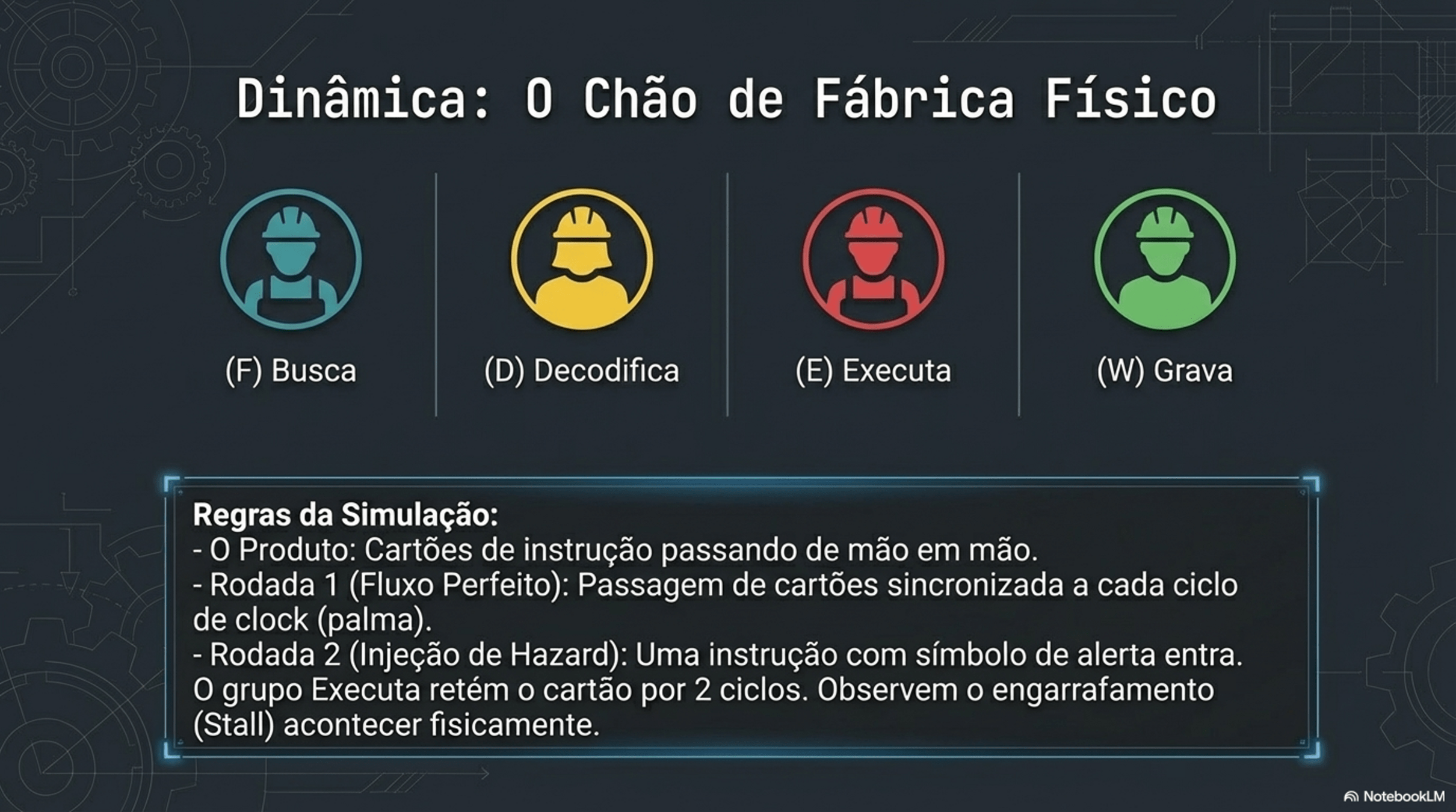
4. Paralelismo e Hazards
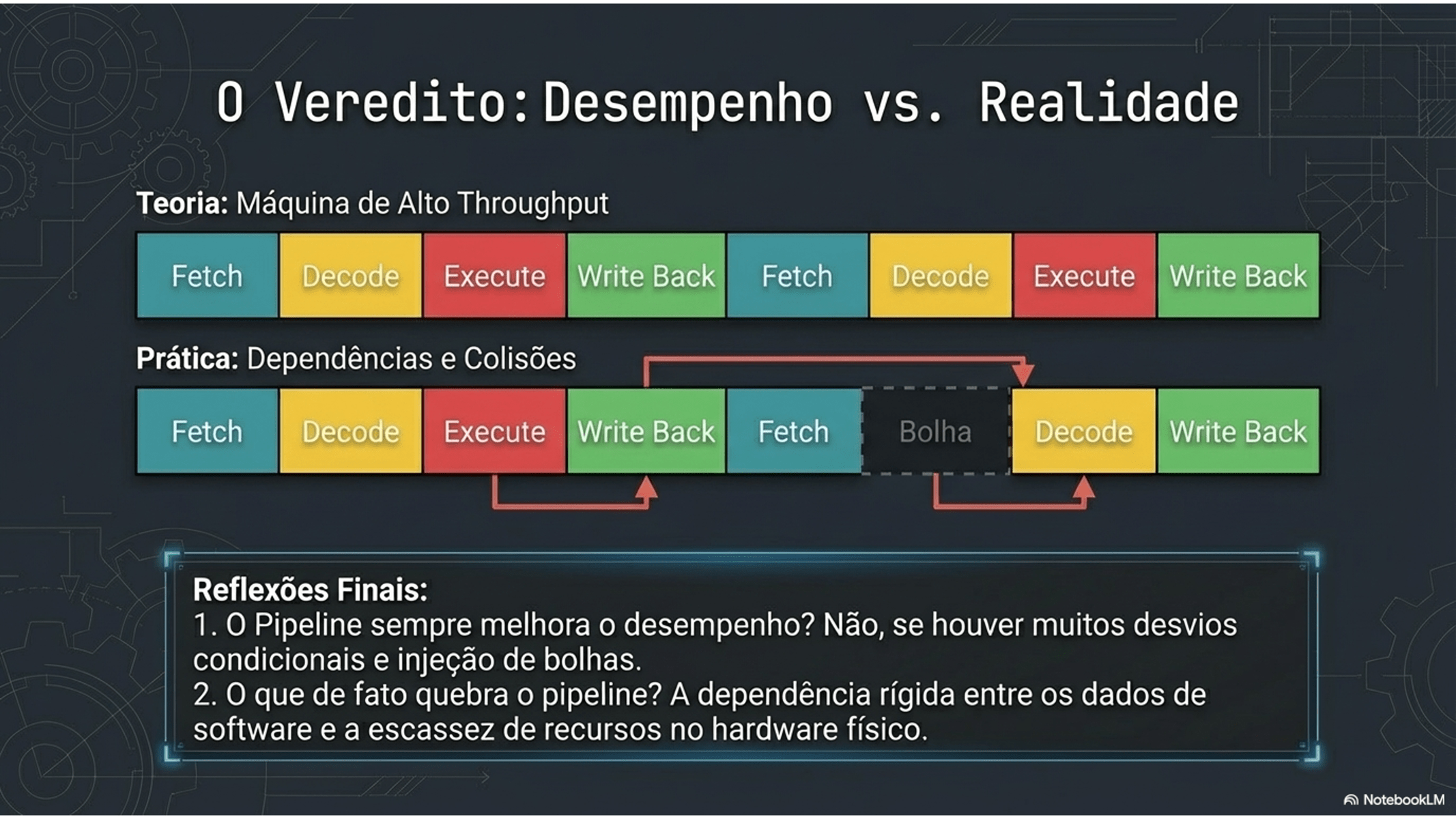
4. Paralelismo e Hazards
Aula 6
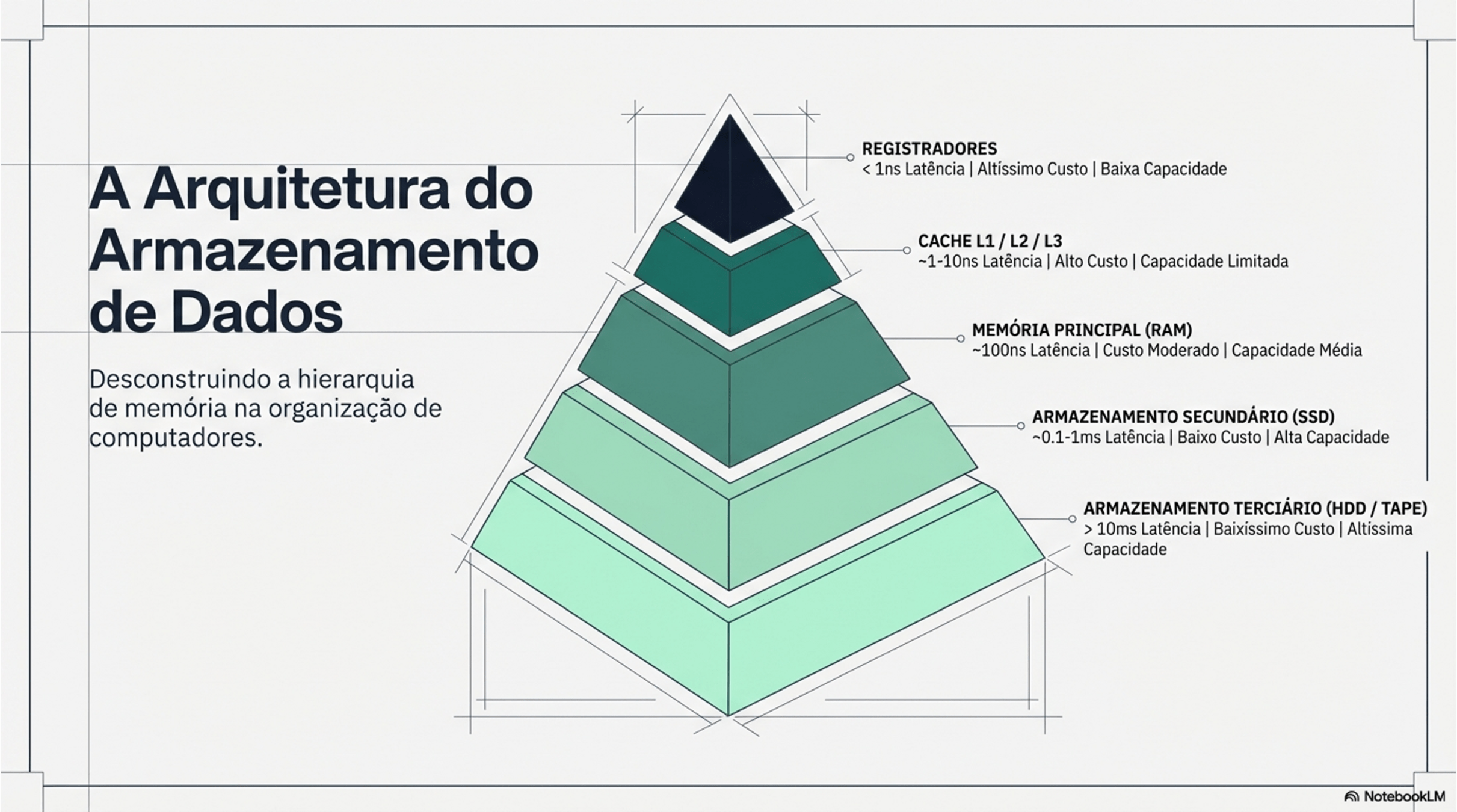
| Capítulo 5 - Cache, RAM, Armazenamento |
|
Hierarquia de Memória |

5. Cache, RAM e Armazenamento
Se SSD é muito rápido, por que a CPU ainda precisa de cache?
SSD pode ser 1000× a 100.000× mais lento que a cache
5. Cache, RAM e Armazenamento
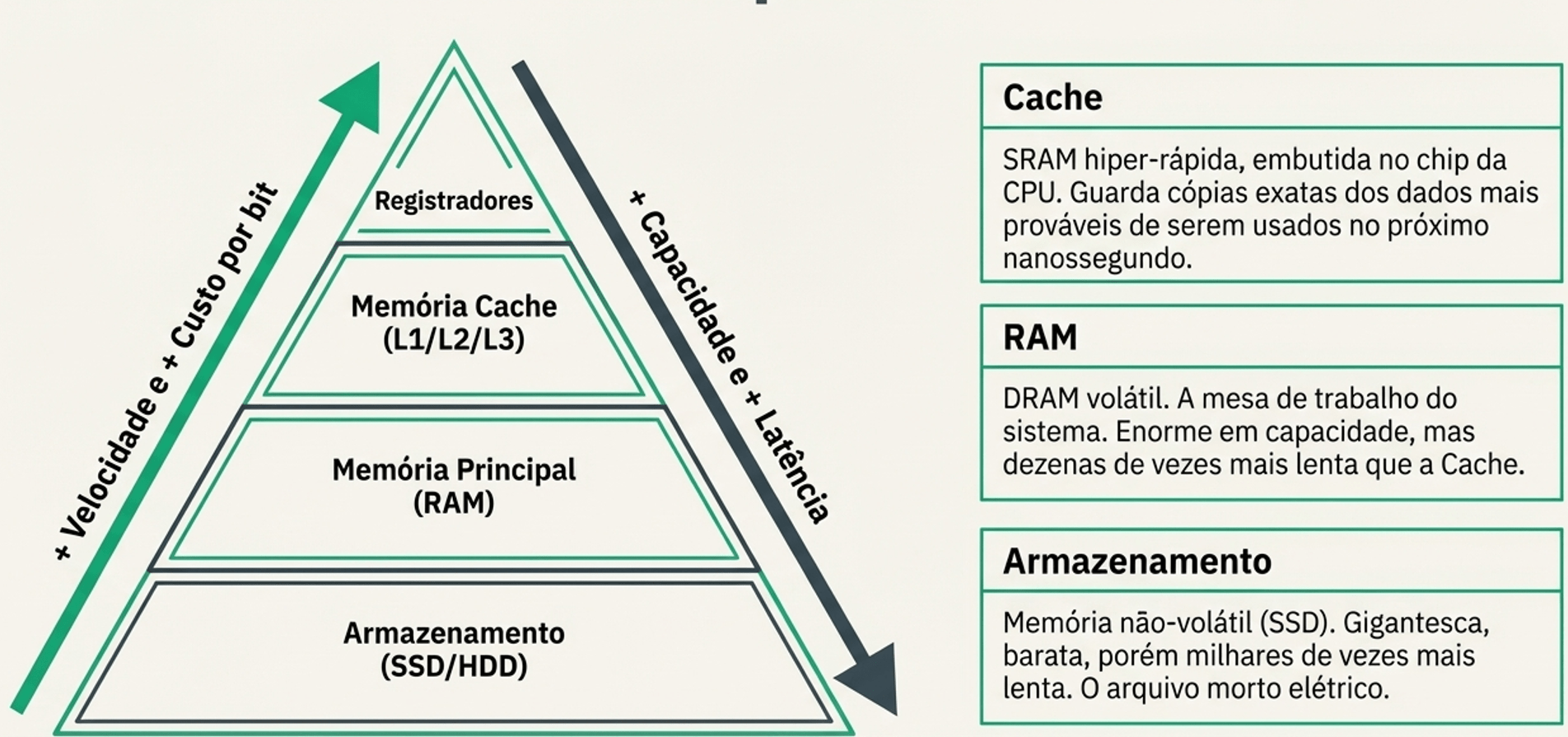
5. Cache, RAM e Armazenamento
Vamos ver o caso do PC a seguir
5. Cache, RAM e Armazenamento
PC Gamer pro meu filho jogar o jogo do peixinho

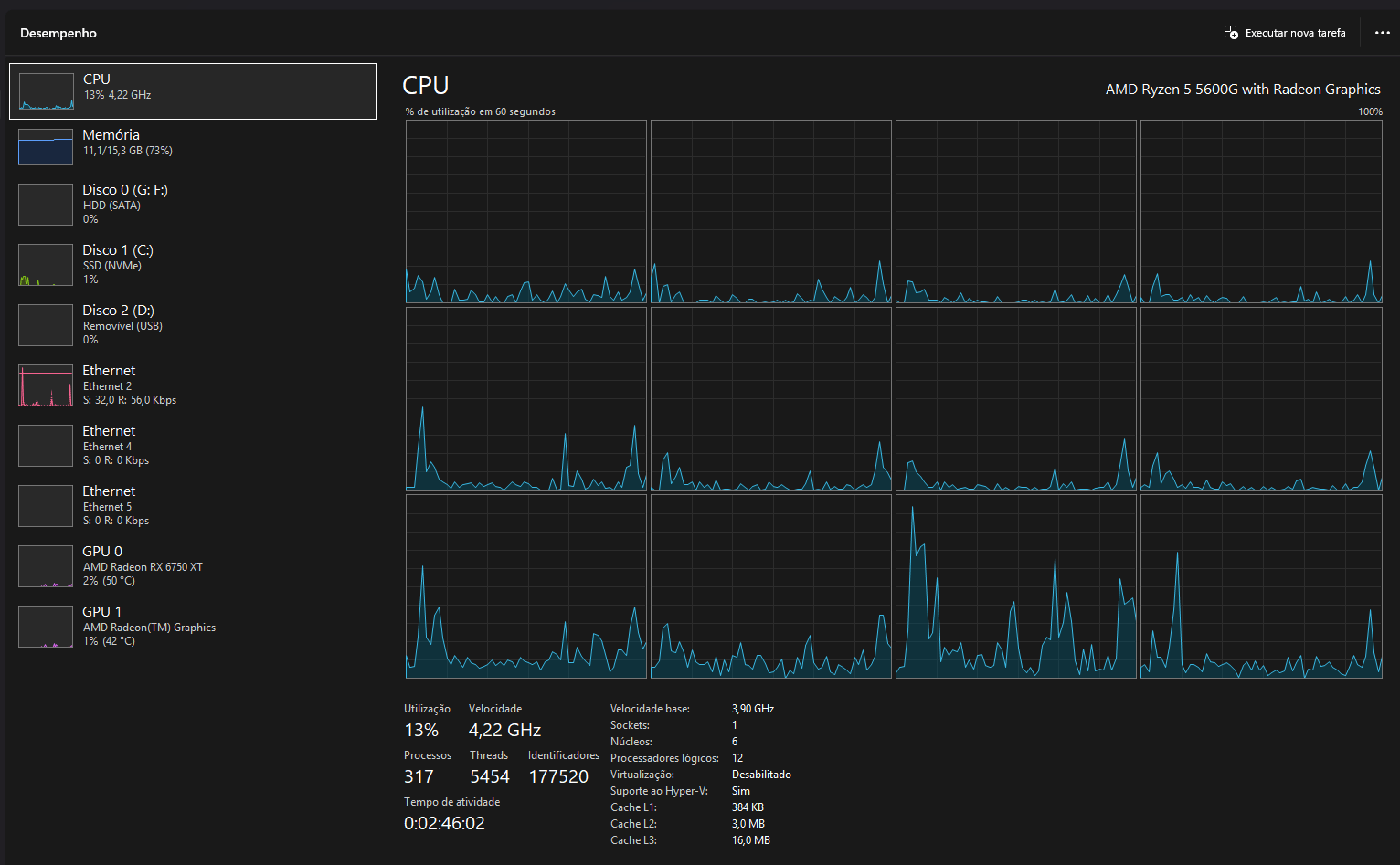
5. Cache, RAM e Armazenamento
-
1 bit -> (0 ou 1)
- 8 bits = 1 byte
- Byte representa valores (ex: número, letra, etc.)
5. Cache, RAM e Armazenamento
Bit: 1 0 1 1 0 0 1 0
└───────┬───────┘
↓
1 BYTE (8 bits)🧠 1. Bit → Byte
5. Cache, RAM e Armazenamento
BYTE: [8 bits]
WORD: [byte][byte][byte][byte][byte][byte][byte][byte]
└───────────────────── 8 bytes ──────────────────┘
= 1 WORD (64 bits)🧠 2. Byte → Palavra (Word)
Na arquitetura x64:
👉 1 palavra (word) = 64 bits = 8 bytes
| Arquitetura | Nome comum | Tamanho da palavra (word) | Bits | Bytes | Observação |
|---|---|---|---|---|---|
| x86 | 32 bits | dword (double word) | 32 | 4 | Muito usada em sistemas antigos |
| x64 | 64 bits | qword (quad word) | 64 | 8 | Padrão atual (seu caso) |
| ARM | 32 bits | word | 32 | 4 | ARM clássico (ARMv7) |
| ARM | 64 bits | word | 64 | 8 | ARM moderno (ARMv8+) |
5. Cache, RAM e Armazenamento
CACHE LINE (64 bytes):
[WORD][WORD][WORD][WORD][WORD][WORD][WORD][WORD]
→ 8 palavras (cada uma com 8 bytes)
→ Total: 64 bytes🧠 3. Palavra → Cache Line
O cache não trabalha com palavras isoladas — ele trabalha com blocos maiores:
👉 Cache line (linha de cache)
- Tamanho típico: 64 bytes
5. Cache, RAM e Armazenamento
L1 CACHE (64 KB): 64*6(núcleos) = 384Kb
[LINE][LINE][LINE][LINE]...[LINE]
Cada LINE = 64 bytes
Total ≈ 1024 linhas
Detalhando:
64 KB = 64 × 1024 = 65.536 bytes
65.536 bytes ÷ 64 bytes = 1024 linhas🧠 4. Cache Line → Cache (L1)
Agora juntando várias linhas:
👉 Exemplo: L1 (por núcleo = 64 KB)
5. Cache, RAM e Armazenamento
MEMÓRIA (RAM):
[LINE][LINE][LINE][LINE]...[LINE][LINE][LINE]
(na prática: bilhões de bytes)🧠 5. Cache → Memória (RAM)
A RAM é muito maior, organizada de forma linear:
5. Cache, RAM e Armazenamento
🎯 Conectando com cache
👉 Ou seja:
- Independente de x86, x64 ou ARM moderno:
- 1 cache line ≈ 8 palavras
| Arquitetura | Palavra | Cache line (típico) | Nº de palavras por linha |
|---|---|---|---|
| x86-64 | 8 bytes | 64 bytes | 8 palavras |
| ARM 64 | 8 bytes | 64 bytes | 8 palavras |
5. Cache, RAM e Armazenamento
🧠 Princípio da Localidade Temporal
👉 “Se você usou um dado agora, provavelmente vai usar de novo em breve.”
📌 Ideia central
- Dados acessados recentemente tendem a ser reutilizados
- O cache mantém esses dados “quentes”
5. Cache, RAM e Armazenamento
💡 Exemplo prático
👉 O vetor vetor[0] é usado mil vezes
- Primeiro acesso → pode vir da memória
- Próximos acessos → ficam no cache (L1)
🎯 Resultado
- Evita buscar na RAM várias vezes
- Ganha MUITA performance
for (int i = 0; i < 1000; i++) {
soma += vetor[0];
}| RAM |
|---|
| 101011 |
| 101010 |
| 101110 |
| 101001 |
| 101111 |
| 100111 |
| 110111 |
Cache
5. Cache, RAM e Armazenamento
📦 Princípio da Localidade Espacial
👉 “Se você acessou um endereço, provavelmente vai acessar os vizinhos.”
💡 Exemplo prático
for (int i = 0; i < 8; i++) {
soma += vetor[i];
}👉 Acessos sequenciais na memória
5. Cache, RAM e Armazenamento
🔄 O que o cache faz
Quando você acessa vetor[0]:
- Ele NÃO traz só 1 valor
- Ele carrega um bloco inteiro (cache line)
👉 Exemplo:
- Cache line = 64 bytes
- Isso equivale a:
- 8 palavras de 64 bits
Então ele já traz:
vetor[0], vetor[1], vetor[2], ..., vetor[7]🎯 Resultado
- Próximos acessos → cache hit
- Muito mais rápido
| RAM |
|---|
| 101011 |
| 101010 |
| 101110 |
| 101001 |
| 101111 |
| 100111 |
| 110111 |
Cache
5. Cache, RAM e Armazenamento
-
Acerto (Hit)
Ocorre quando o processador busca uma
palavra da cache e a encontra
-
Falha (Miss)
Ocorre quando o processador busca uma
palavra da cache e não a encontra
-
Taxa de acertos
Ta = (Na)/(Na+Nf), em que:
Ta: taxa de acertos
Na: número de acertos
Nf: número de falhas
5. Cache, RAM e Armazenamento
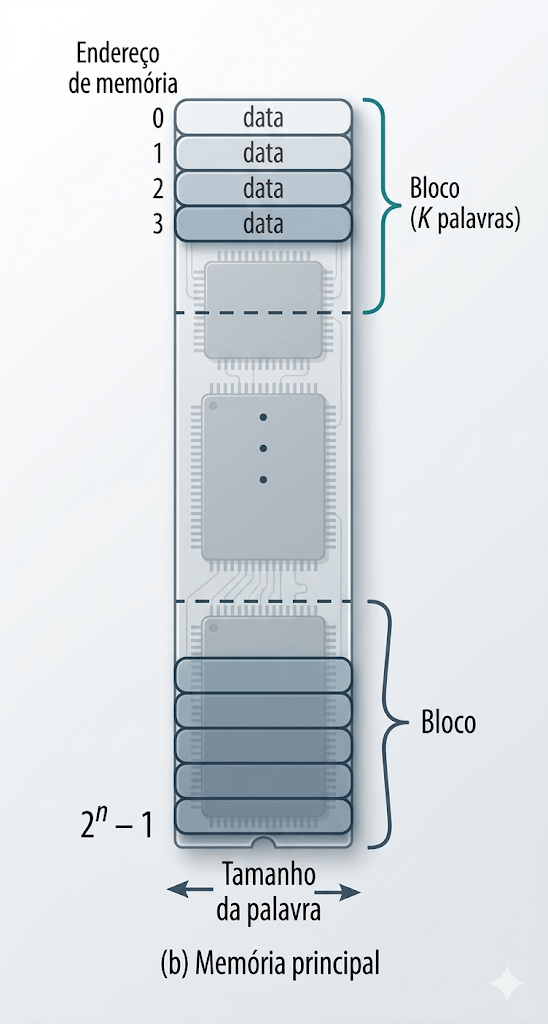
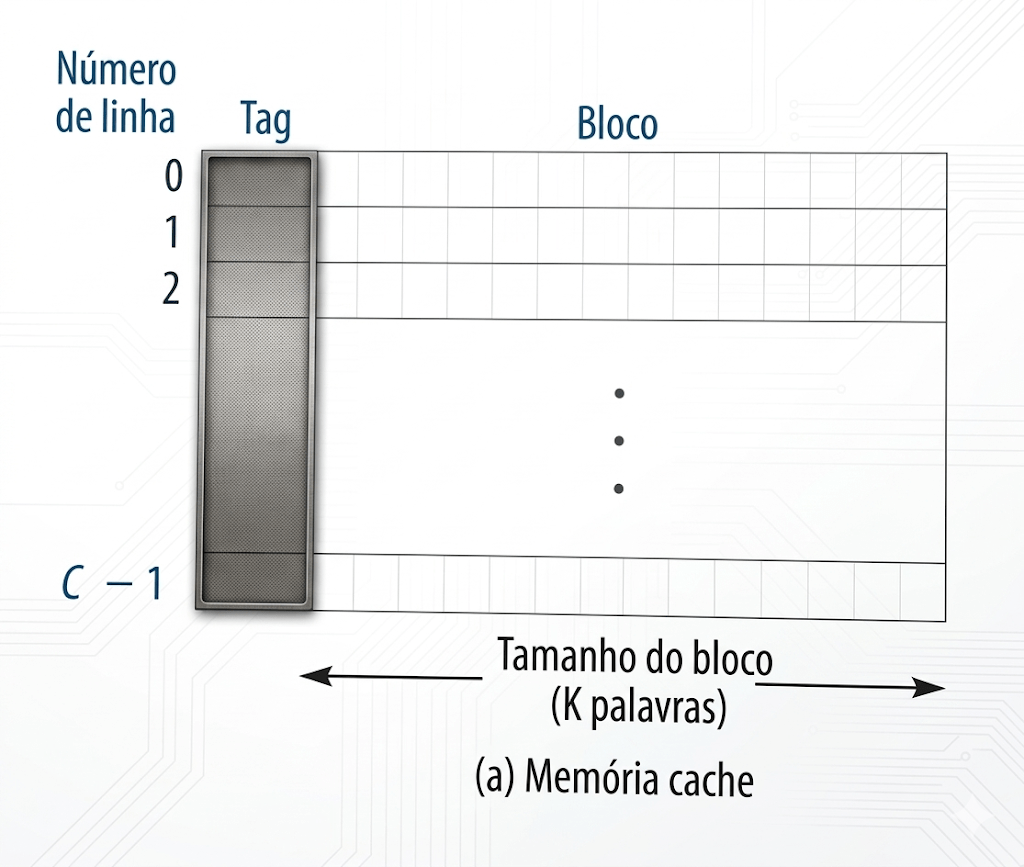
5. Cache, RAM e Armazenamento
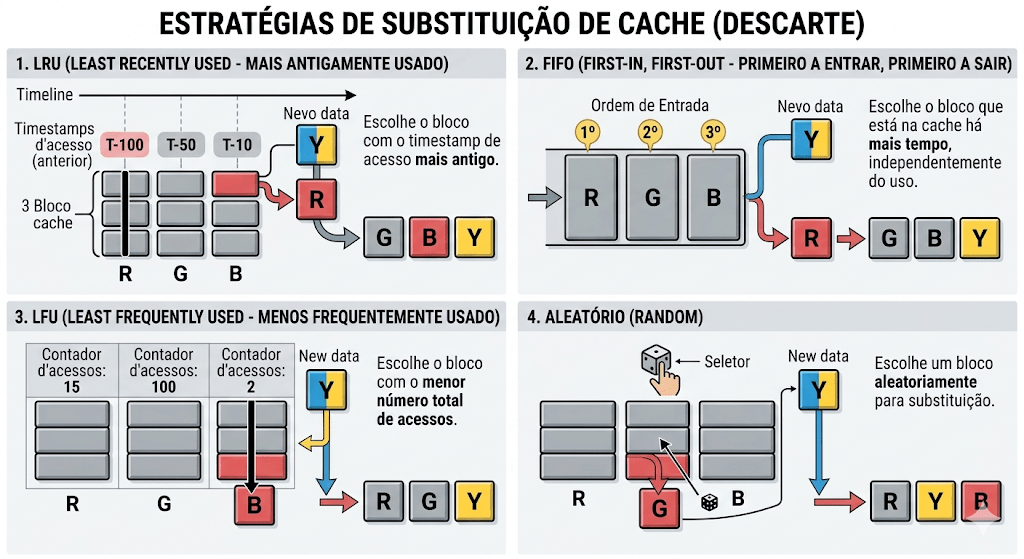
5. Cache, RAM e Armazenamento
Aula 7
| Simulado |
|
Conteúdos abordados até a Aula 6 |

Simulado
Aula 8
| Capítulo 6 - Localidade e Desempenho |
|
Temporal e Espacial |
6. Localidade e Desempenho
🧠 Código não é lento só por “fazer muita conta”. Muitas vezes ele é lento porque acessa mal a memória.
📌 Ideia central
O processador é rápido, mas depende de dados chegarem rápido. Quando o padrão de acesso à memória é ruim, o desempenho despenca.
Localidade Temporal: Refere-se à tendência do processador de acessar locais de memória que foram usados recentemente
6. Localidade e Desempenho
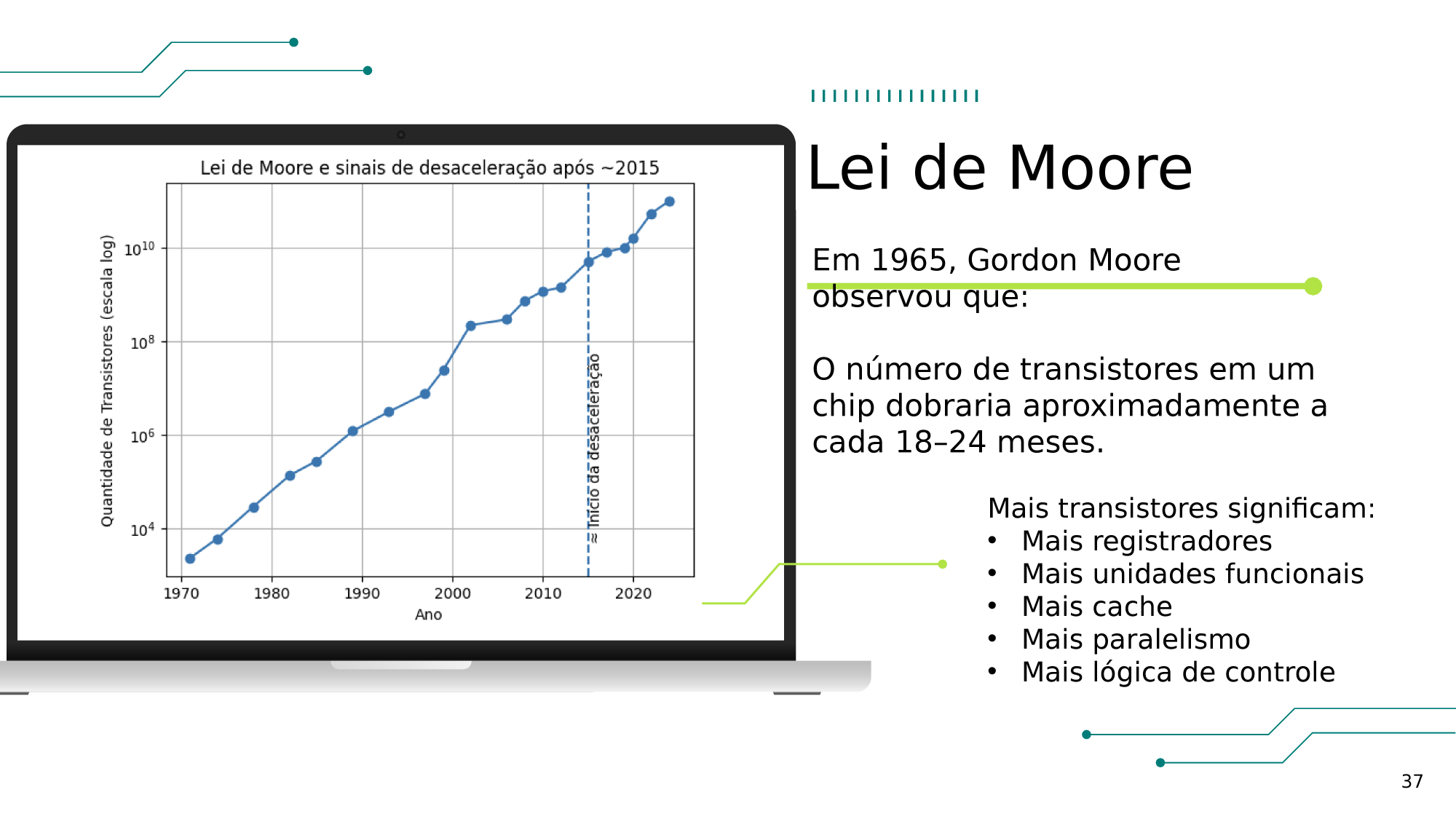
STALLINGS, W. Arquitetura e Organização de Computadores. 8. ed. São Paulo: Pearson, 2010.
Localidade Temporal
Exemplo prático na programação: A execução de loops (laços de repetição) ou chamadas de sub-rotinas, em que o processador executa o mesmo conjunto de instruções e acessa as mesmas variáveis repetidamente
6. Localidade e Desempenho
STALLINGS, W. Arquitetura e Organização de Computadores. 8. ed. São Paulo: Pearson, 2010.
Localidade Temporal
6. Localidade e Desempenho
programa
{
funcao inicio()
{
inteiro vetor[1000]
inteiro i
inteiro soma = 0
para (i = 0; i < 1000; i++)
{
vetor[i] = i
}
para (i = 0; i < 20; i++)
{
escreva("Lendo vetor[0] = ", vetor[0], "\n")
soma = soma + vetor[0]
}
escreva("\nSoma = ", soma, "\n")
}
}- Implemente o código ao lado em https://portugol.dev/
- No código ao lado onde está o conceito de localidade temporal?
Localidade Espacial: Refere-se à tendência da execução envolver uma série de locais de memória que estão fisicamente próximos (agrupados)
6. Localidade e Desempenho
STALLINGS, W. Arquitetura e Organização de Computadores. 8. ed. São Paulo: Pearson, 2010.
Localidade Espacial
Exemplo prático na programação: A execução sequencial de instruções ou o processamento de estruturas de dados contíguas, como vetores (arrays) e tabelas, percorrendo os itens em sequência
6. Localidade e Desempenho
STALLINGS, W. Arquitetura e Organização de Computadores. 8. ed. São Paulo: Pearson, 2010.
Localidade Espacial
6. Localidade e Desempenho
programa
{
funcao inicio()
{
inteiro vetor[1000]
inteiro i
inteiro soma = 0
para (i = 0; i < 1000; i++)
{
vetor[i] = i
}
para (i = 0; i < 20; i++)
{
escreva("Lendo vetor[", i, "] = ", vetor[i], "\n")
soma = soma + vetor[i]
}
escreva("\nSoma = ", soma, "\n")
}
}- Implemente o código ao lado em https://portugol.dev/
- No código ao lado onde está o conceito de localidade espacial?
Cache Miss
6. Localidade e Desempenho
programa
{
funcao inicio()
{
inteiro vetor[1000]
inteiro ordem[20]
inteiro i
inteiro soma = 0
para (i = 0; i < 1000; i++)
{
vetor[i] = i
}
ordem[0] = 10
ordem[1] = 500
ordem[2] = 3
ordem[3] = 700
ordem[4] = 25
ordem[5] = 900
ordem[6] = 1
ordem[7] = 450
ordem[8] = 100
ordem[9] = 800
ordem[10] = 2
ordem[11] = 600
ordem[12] = 30
ordem[13] = 950
ordem[14] = 4
ordem[15] = 300
ordem[16] = 50
ordem[17] = 750
ordem[18] = 5
ordem[19] = 999
para (i = 0; i < 20; i++)
{
escreva("Lendo vetor[", ordem[i], "] = ", vetor[ordem[i]], "\n")
soma = soma + vetor[ordem[i]]
}
escreva("\nSoma = ", soma, "\n")
}
}- Implemente o código ao lado em https://portugol.dev/
- No código ao lado onde podemos identificar o conceito de cache miss?
-
Dos exemplos anteriores
-
Qual reaproveita posições próximas?
-
Qual reaproveita o mesmo dado?
-
Qual tende a piorar cache?
-
6. Localidade e Desempenho
-
Exemplo 1: Consumo memória com C
6. Localidade e Desempenho
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define TAM 10000000 //10 milhões de elementos
#define REP 20
int main() {
printf("Tamanho do int: %zu bytes\n", sizeof(int));
printf("Tamanho dos elementos: %d\n", TAM);
int *vetor = malloc(TAM * sizeof(int));
int *ordem = malloc(TAM * sizeof(int));
if (vetor == NULL || ordem == NULL) {
printf("Erro ao alocar memoria\n");
free(vetor);
free(ordem);
return 1;
}
printf("%p\n", vetor); // posições de memoria
printf("%p\n", ordem);
for (int i = 0; i < TAM; i++) {
vetor[i] = i;
ordem[i] = (i * 37) % TAM;
}
volatile long long soma = 0;
clock_t inicio, fim;
// SEQUENCIAL
inicio = clock();
for (int r = 0; r < REP; r++) {
for (int i = 0; i < TAM; i++) {
soma += vetor[i];
}
}
fim = clock();
double tempo_seq = (double)(fim - inicio) / CLOCKS_PER_SEC;
// ALEATORIO
soma = 0;
inicio = clock();
for (int r = 0; r < REP; r++) {
for (int i = 0; i < TAM; i++) {
soma += vetor[ordem[i]];
}
}
fim = clock();
double tempo_rand = (double)(fim - inicio) / CLOCKS_PER_SEC;
printf("Sequencial: %.6f s\n", tempo_seq);
printf("Aleatorio : %.6f s\n", tempo_rand);
free(vetor); //Liberar o espaço de memória
free(ordem);
return 0;
}-
Exemplo 2: Consumo memória com C
6. Localidade e Desempenho
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#define TAM 10000000
#define REP 10
int main() {
printf("Tamanho do int: %zu bytes\n", sizeof(int));
double memoria_um_vetor = (TAM * sizeof(int)) / (1024.0 * 1024.0);
double memoria_total = (2 * TAM * sizeof(int)) / (1024.0 * 1024.0);
printf("Memoria de um vetor: %.2f MB\n", memoria_um_vetor);
printf("Memoria total estimada: %.2f MB\n\n", memoria_total);
int *vetor = malloc(TAM * sizeof(int));
int *ordem = malloc(TAM * sizeof(int));
if (vetor == NULL || ordem == NULL) {
printf("Erro ao alocar memoria.\n");
free(vetor);
free(ordem);
return 1;
}
printf("Endereco vetor: %p\n", (void *)vetor);
printf("Endereco ordem: %p\n\n", (void *)ordem);
clock_t inicio_init = clock();
for (int i = 0; i < TAM; i++) {
vetor[i] = i;
ordem[i] = (i * 37) % TAM;
}
clock_t fim_init = clock();
double tempo_init = (double)(fim_init - inicio_init) / CLOCKS_PER_SEC;
printf("Inicializacao concluida.\n");
printf("Tempo de inicializacao: %.6f s\n\n", tempo_init);
volatile long long soma = 0;
clock_t inicio, fim;
// -----------------------------
// FASE 1 - ACESSO SEQUENCIAL
// -----------------------------
printf("Iniciando fase sequencial...\n");
inicio = clock();
for (int r = 0; r < REP; r++) {
for (int i = 0; i < TAM; i++) {
soma += vetor[i];
}
printf(" Sequencial: repeticao %d de %d concluida\n", r + 1, REP);
}
fim = clock();
double tempo_seq = (double)(fim - inicio) / CLOCKS_PER_SEC;
printf("Fase sequencial concluida.\n");
printf("Soma sequencial: %lld\n", soma);
printf("Tempo sequencial: %.6f s\n\n", tempo_seq);
// -----------------------------
// FASE 2 - ACESSO ALEATORIO
// -----------------------------
soma = 0;
printf("Iniciando fase aleatoria...\n");
inicio = clock();
for (int r = 0; r < REP; r++) {
for (int i = 0; i < TAM; i++) {
soma += vetor[ordem[i]];
}
printf(" Aleatorio: repeticao %d de %d concluida\n", r + 1, REP);
}
fim = clock();
double tempo_rand = (double)(fim - inicio) / CLOCKS_PER_SEC;
printf("Fase aleatoria concluida.\n");
printf("Soma aleatoria: %lld\n", soma);
printf("Tempo aleatorio: %.6f s\n\n", tempo_rand);
// -----------------------------
// COMPARACAO FINAL
// -----------------------------
printf("Resumo final:\n");
printf("Tempo sequencial: %.6f s\n", tempo_seq);
printf("Tempo aleatorio : %.6f s\n", tempo_rand);
if (tempo_seq > 0) {
printf("Aleatorio / Sequencial = %.2f vezes\n", tempo_rand / tempo_seq);
}
free(vetor);
free(ordem);
return 0;
}Aula 9
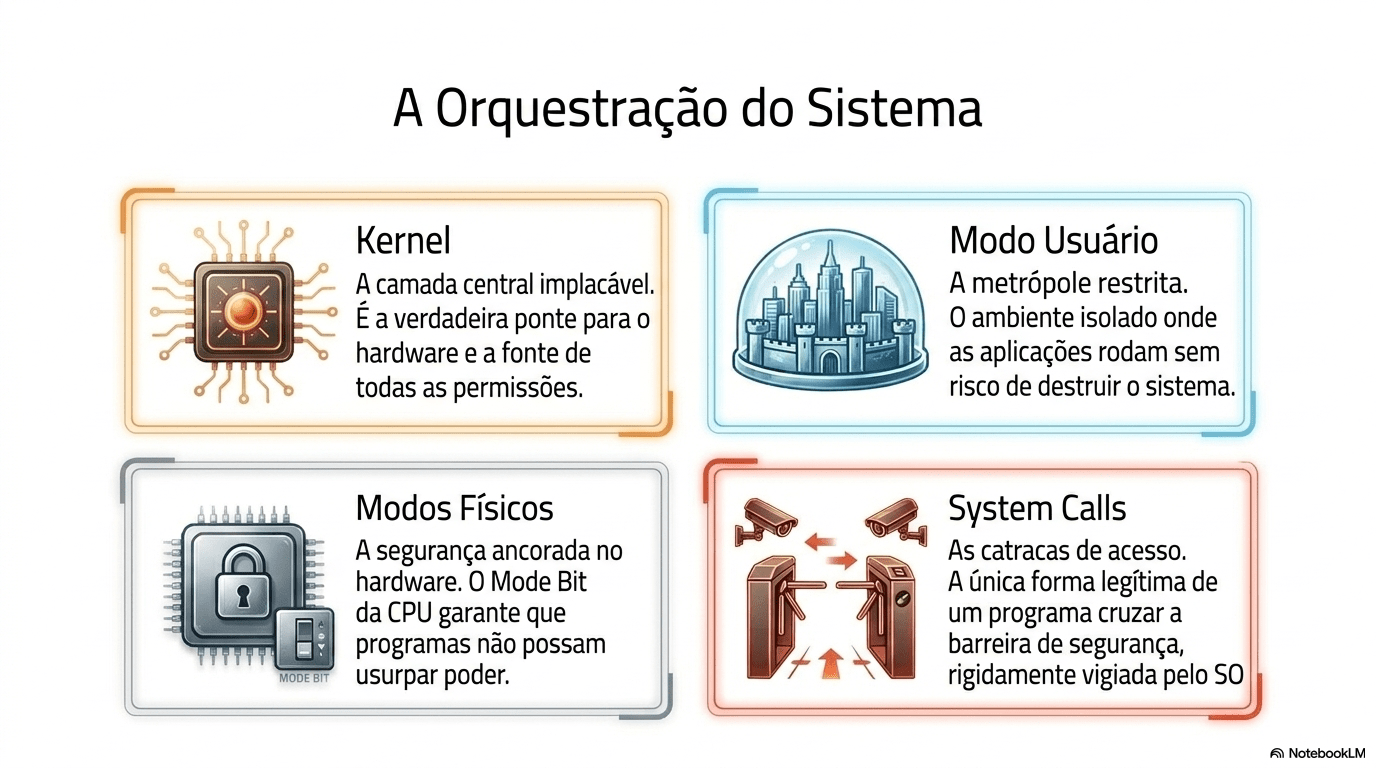
| Capítulo 7 - Sistema Operacional |
|
Kernel e Modos de Execução |

7. Sistema Operacional
🧠 Código não é lento só por “fazer muita conta”. Muitas vezes ele é lento porque acessa mal a memória.
📌 Ideia central
O processador é rápido, mas depende de dados chegarem rápido. Quando o padrão de acesso à memória é ruim, o desempenho despenca.
7. Sistema Operacional
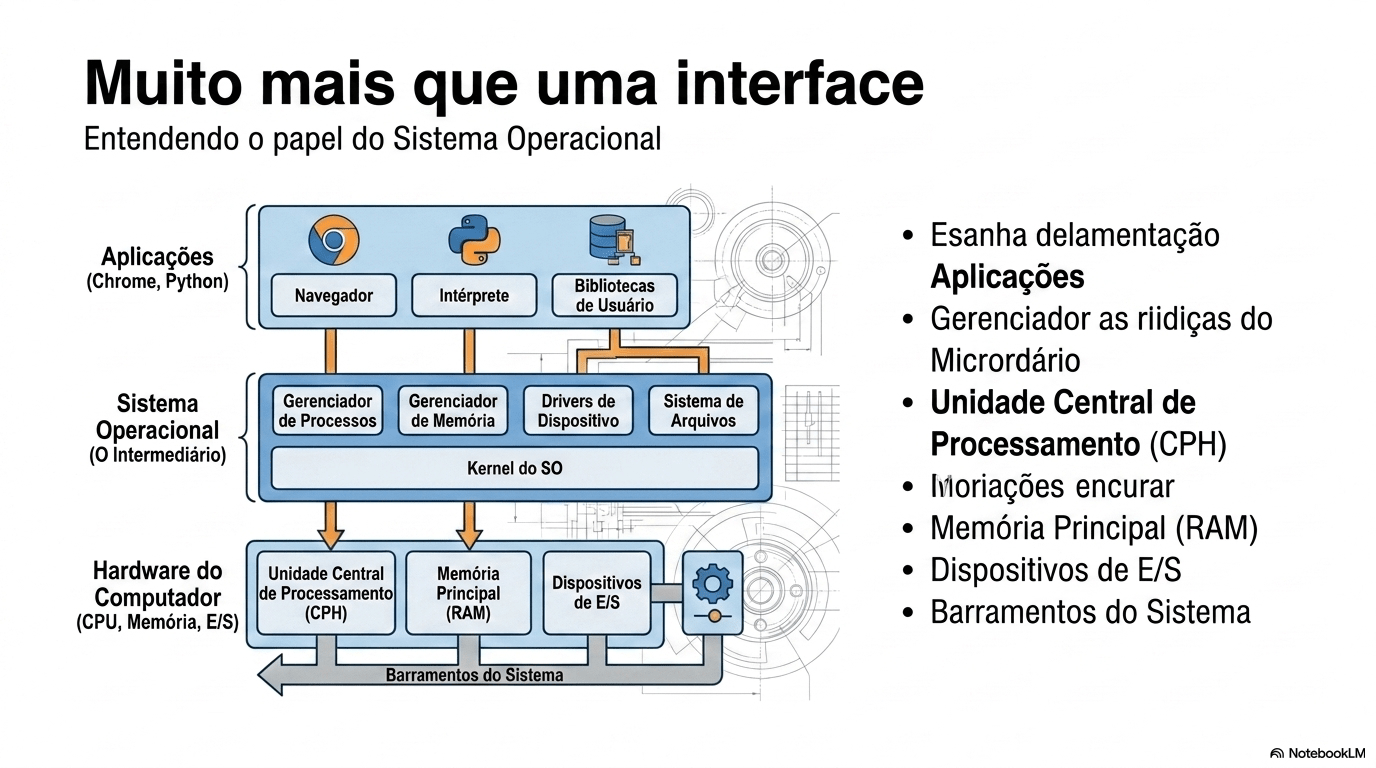

7. Sistema Operacional
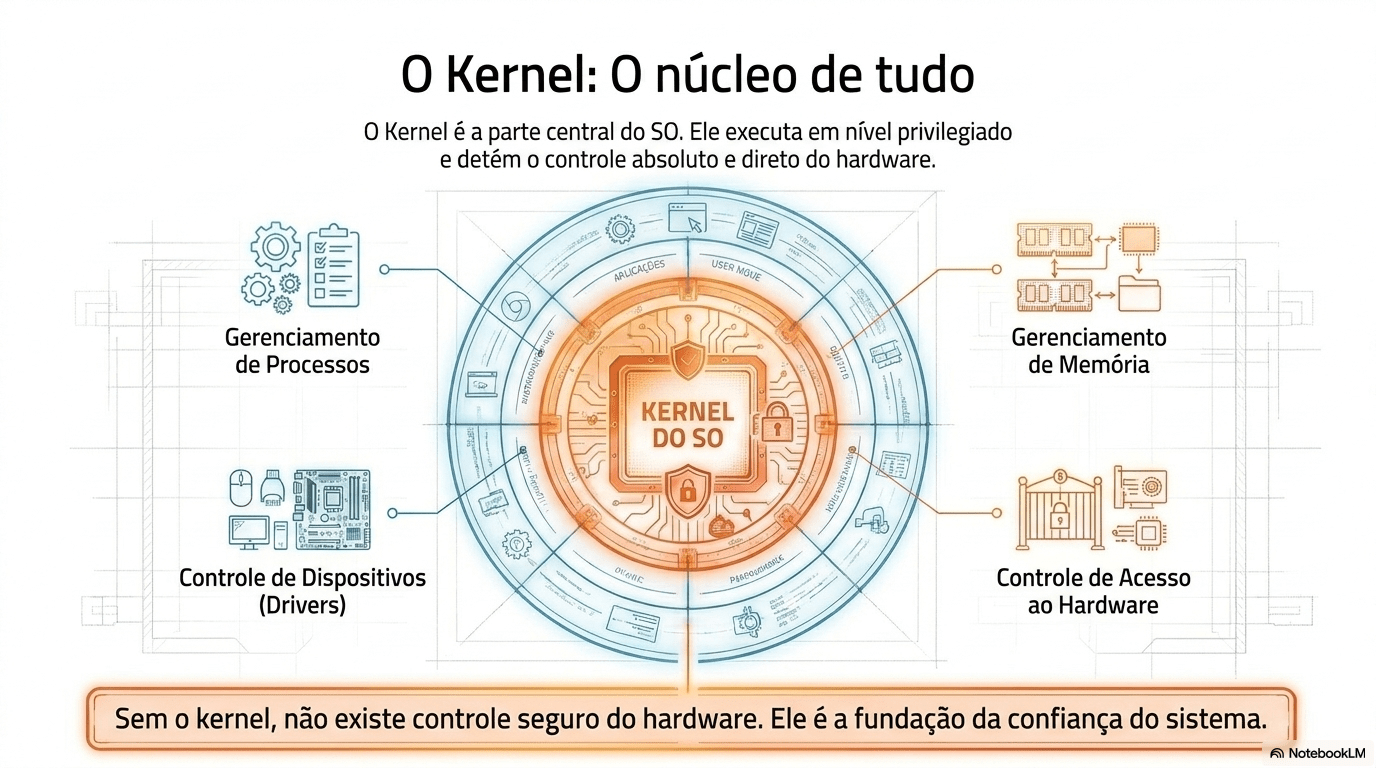
7. Sistema Operacional
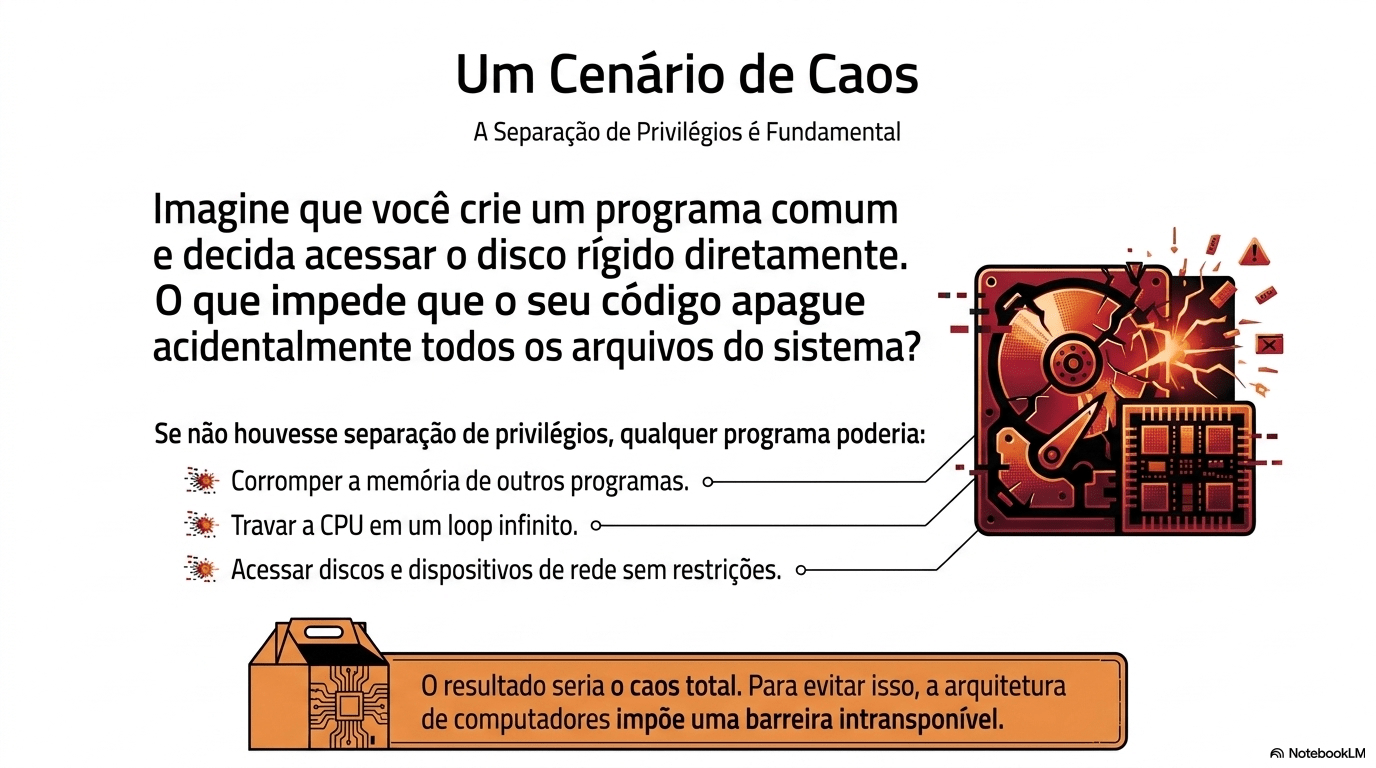
7. Sistema Operacional

7. Sistema Operacional
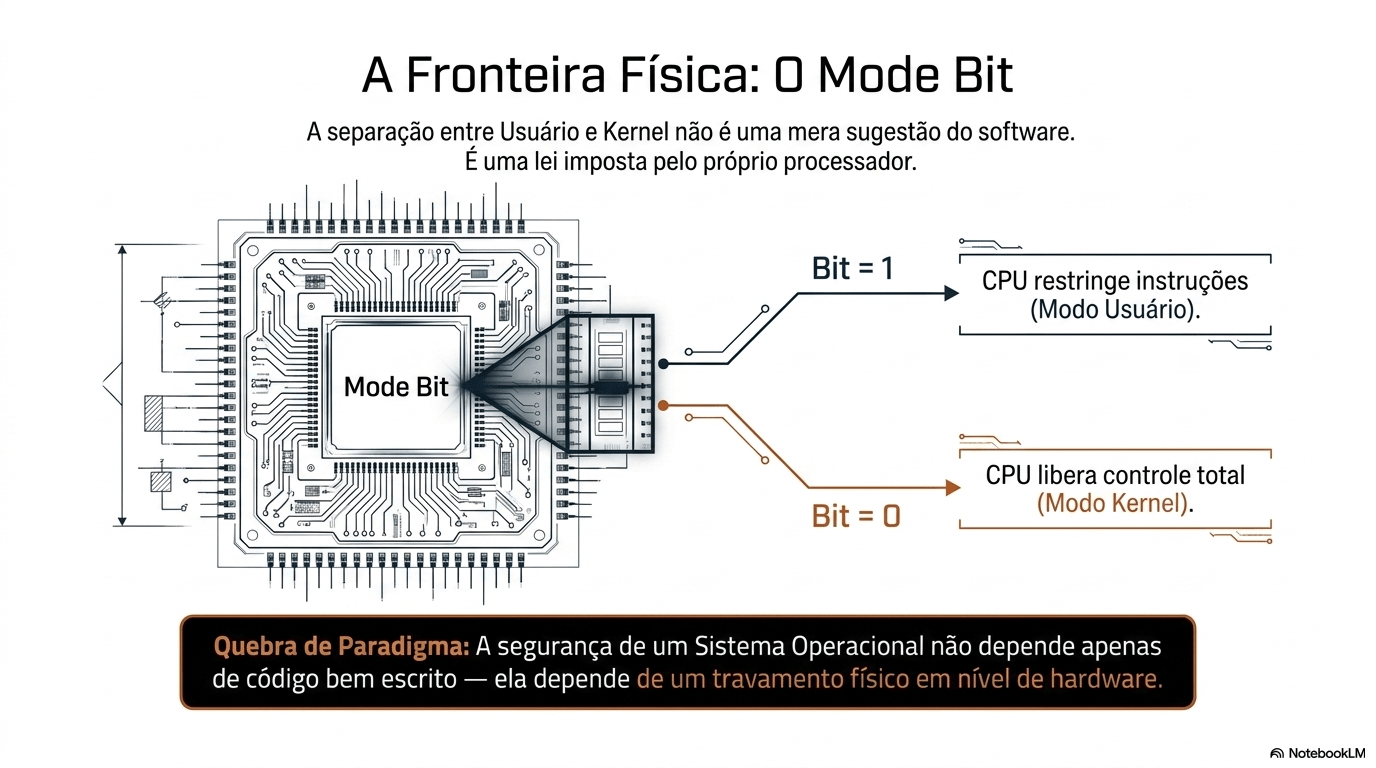
7. Sistema Operacional
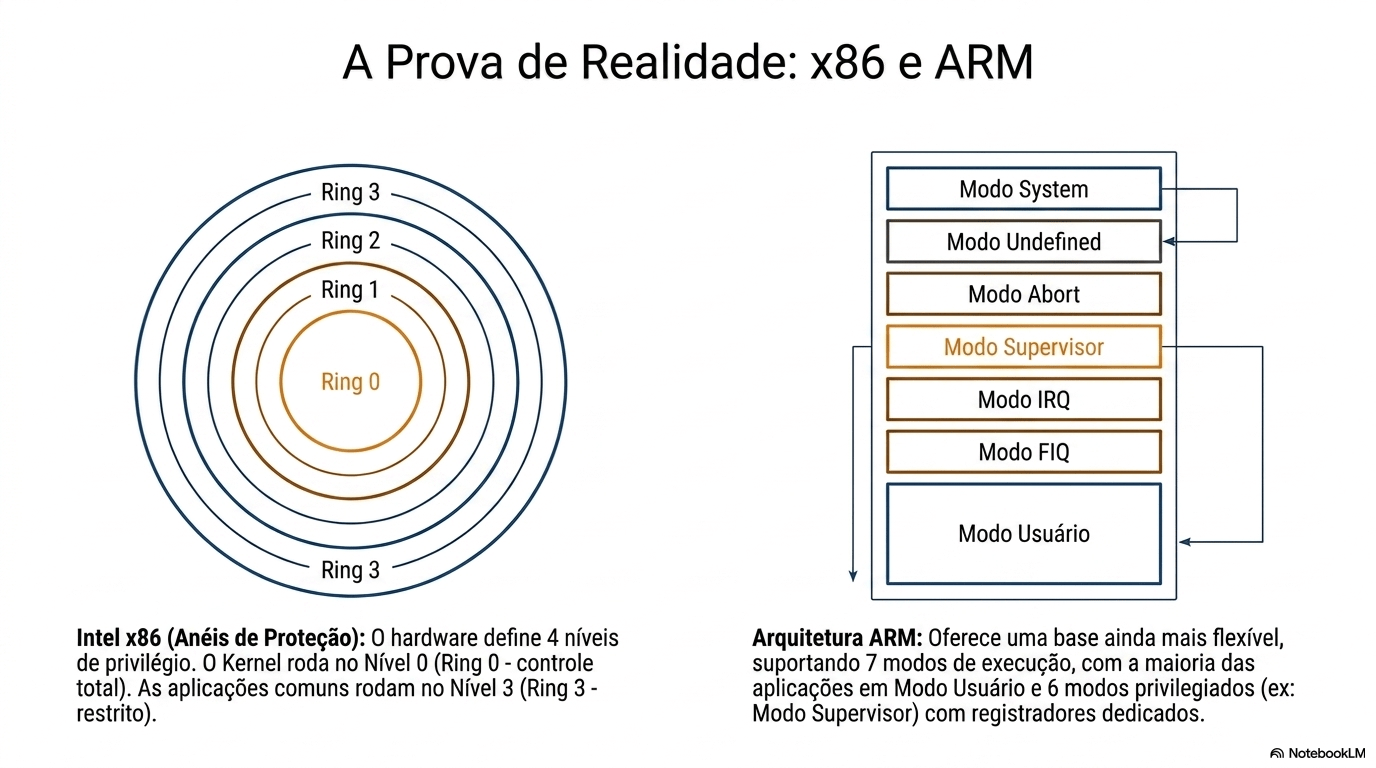
7. Sistema Operacional
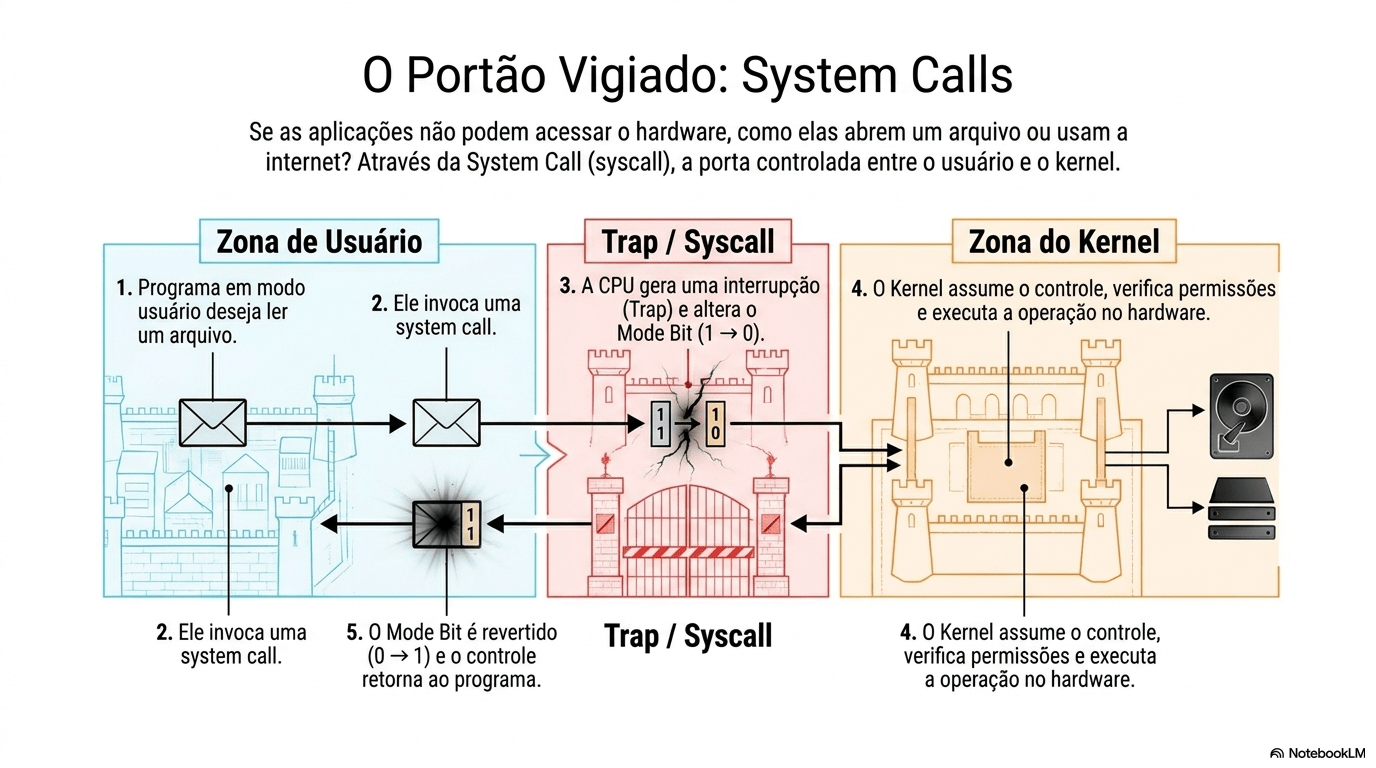
7. Sistema Operacional
Resposta: O Kernel coleta os dados físicos e os entrega ao programa
7. Sistema Operacional
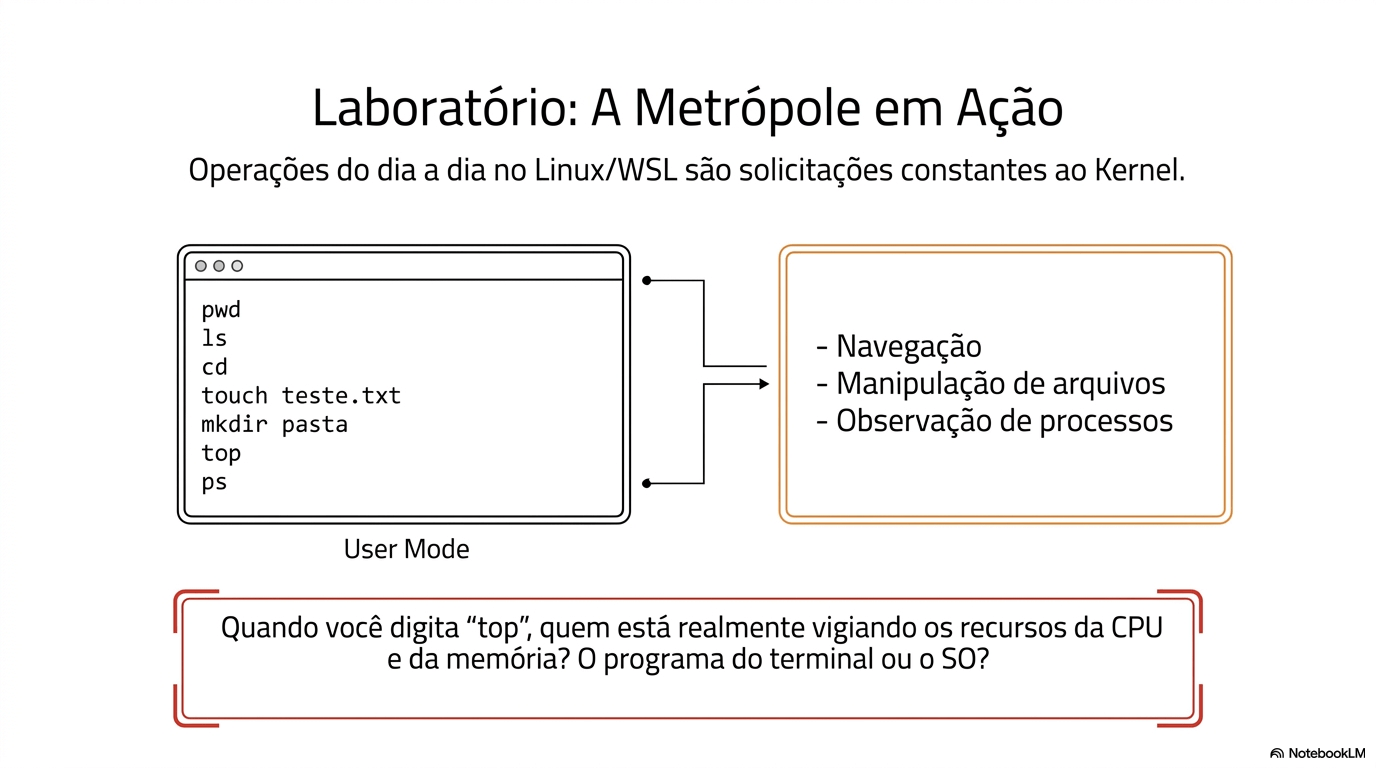
tasklist
Get-ProcessNo Windows vamos verificar processos:
Como salvar a saída de um programa em arquivo?
icacls arquivo.txt /deny Todos:R
type arquivo.txt (no CMD) ou Get-Content arquivo.txt (No PowerShell)Como alterar a permissão de um arquivo:
Agora experimente abrir o terminal no modo administrador e ler o arquivo.
icacls arquivo.txt /remove:d Todoscommando > arquivo7. Sistema Operacional
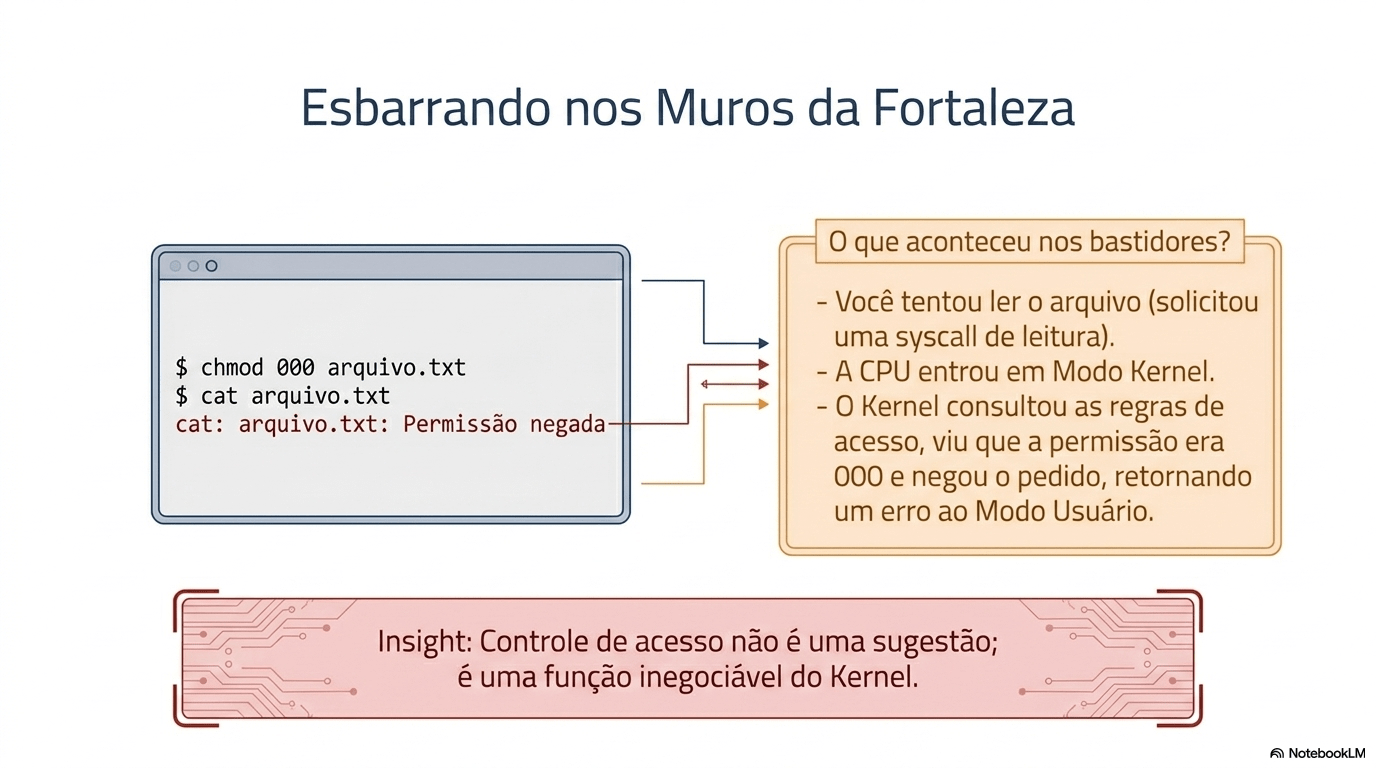
7. Sistema Operacional
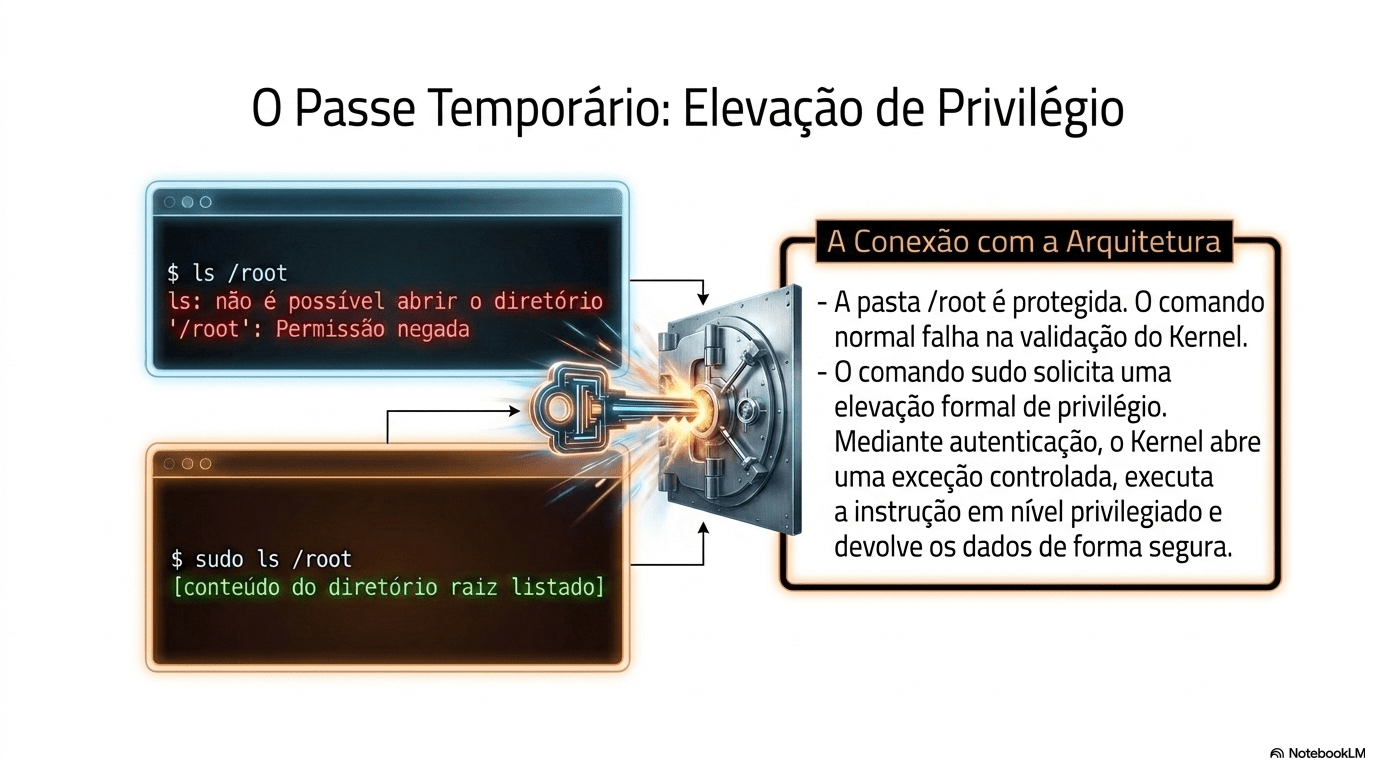
7. Sistema Operacional