
Mechanical Engineering, Carnegie Mellon University
Advisors: Prof. Burak Kara, Prof. Jessica Zhang
Weekly meeting - 01/15/26
PROPOSED WORK
- Aim 1(a): 123
- Aim 1(b): 123
- Aim 2: 123
NEXT PAPER - ICML (Int'l conference of Machine Learning)
- ABC
PROGRESS
- 123
- 123
- 123
NEXT STEPS
- 123
- 123
- 123
Proposed aims
Aim 2: Causal self attention with FLARE
AIM 1(a): rank-adaptive
AIM 1(b): conditioning mechanism
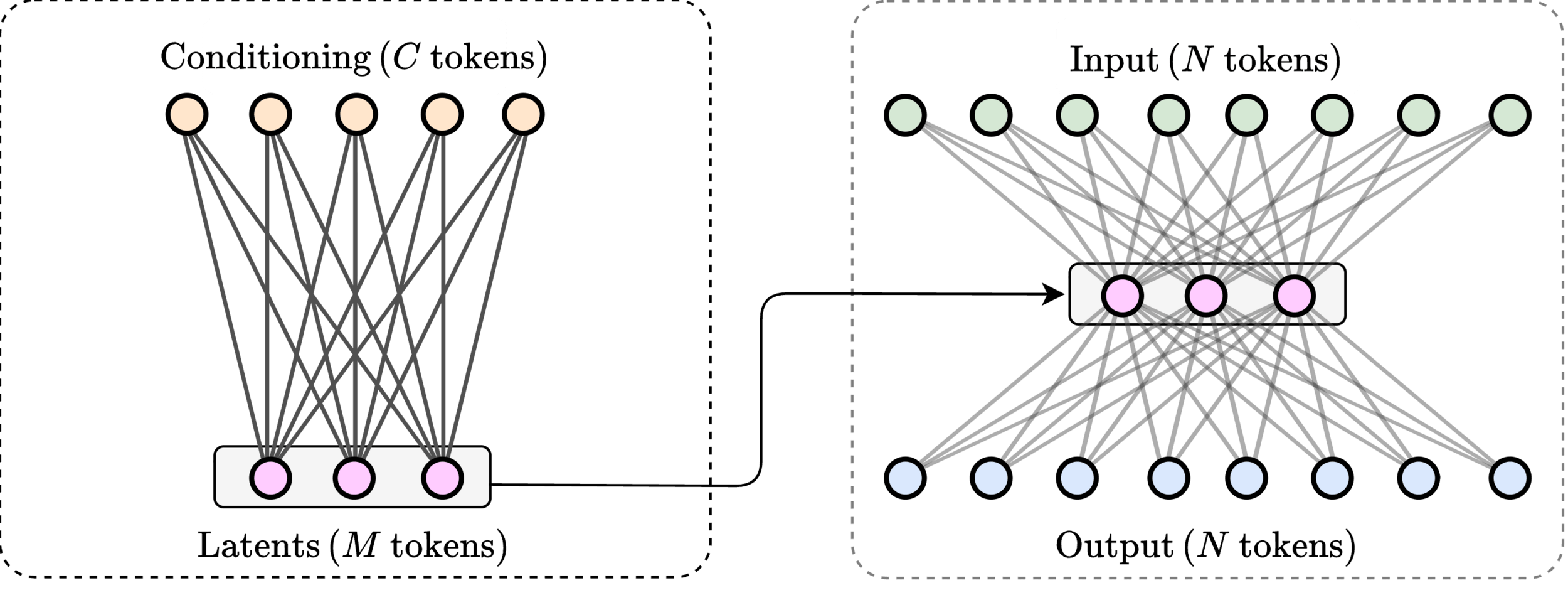
- Will focus on this last.
- Algorithm is prepared and ready for evaluation.
- No standardized benchmark suite. Evaluate in different modalities
- Diffusion: image, video generation (Datta)
- Time-series PDE problems
- Design inference algorithm (DONE) and write CUDA kernel (EASY)
- Design training algorithm and write GPU kernels (Vedant)
- Evaluate on language modeling applications
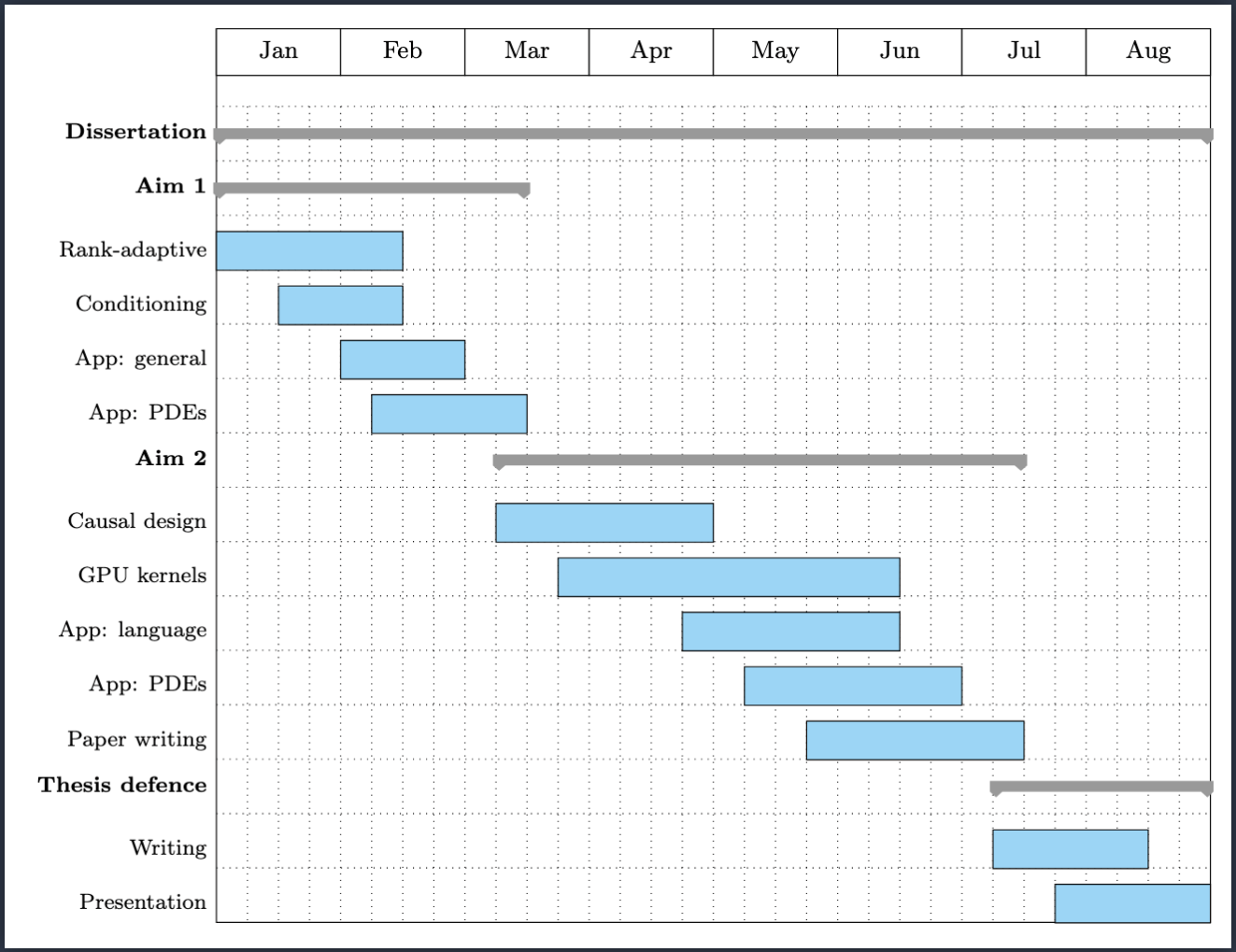
Proposed timeline
Notes
- Our algorithmic work is cut out and straightforward, which is good.
- Furthermore, the advantages of our methods are well laid out.
- However, learning several new domains (image/video, generation, language modeling, PDE timeseries) is hard.
- I'm spending considerable amount of time managing Datta.
- His task last semester was well bounded (hyperparameter tuning)
- This semester, I need him to write several evaluation suites for testing my algorithms on different domains.
- Ensuring correctness and that best practices are followed requires constant input and deep interactions.
Weekly meeting - 01/22/26
Progress
- Setting up experiments for aims 1, 2, 3
- Aim 1a: adaptive latent count -- test on image classification
- Aim 1b: cross-attention -- test on image/video diffusion
- Aim 2: next token prediction -- test on language modeling
- Progress
- Pipeline nearly ready for Aim 1a.
- Training was slow because of the magnitude of data loading (1.2m images). (2 days for training small models)
- We applied many tricks to bring that down to 5-10 hours.
- TODO: set up diffusion pipeline on top of vision pipeline
- Pipeline ready for Aim 2.
- got set up in a standard testing suite for efficient attention models
- Pipeline nearly ready for Aim 1a.
- ICLR notification for FLARE paper should come out today
- If rejected/ notification delayed --> submit to ICML
Setup for language modeling
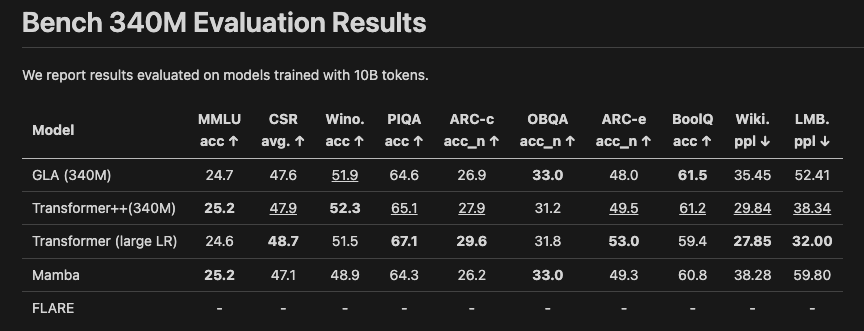
Benchmarking (model size: 340M params, context length: 2k tokens)
- Train model on a fixed pretraining dataset (10B tokens) -- 5-8 hours on 4 GPUs.
- Evaluate on several reasoning datasets.
FLARE Decoder
Advantages
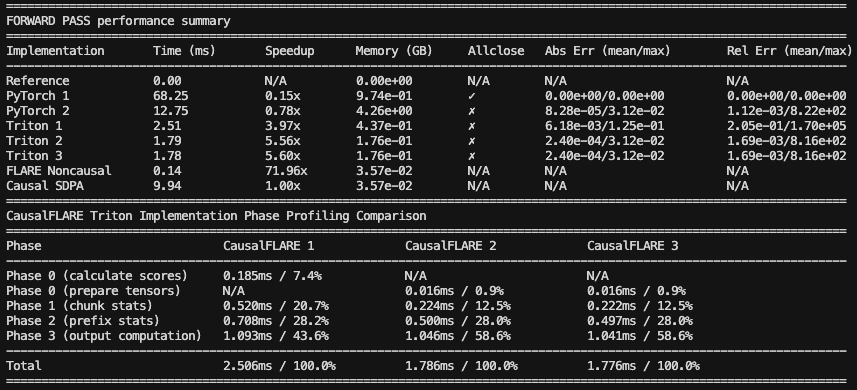
- Faster training, inference (esp. for long context)
- Drastically lower inference memory (esp. for long context)
Weekly meeting - 01/29/26
Progress
- Setting up experiments for aims 1, 2, 3
- Aim 1a: adaptive latent count -- test on image classification
- Aim 1b: cross-attention -- test on image/video diffusion
-
Aim 2: next token prediction -- test on language modeling
- Advantages: faster training, inference (esp. for long context). Drastically lower memory requirement for long context inference.
- Progress
- Submitted to ICML
- Vision transformer pipeline complete (took ~2 weeks)
- Aim 1: can test on Darcy, or image classification
- Aim 2: diffusion image generation pipeline complete. problems are too large. need greater allocation. working on it.
-
Aim 3: language model testing in progress.
- CUDA kernels for FWD pass, BWD pass done
- Testing small models (50M parameters)
- Noticing gradient instability
FLARE Decoder: FWD pass N=2048
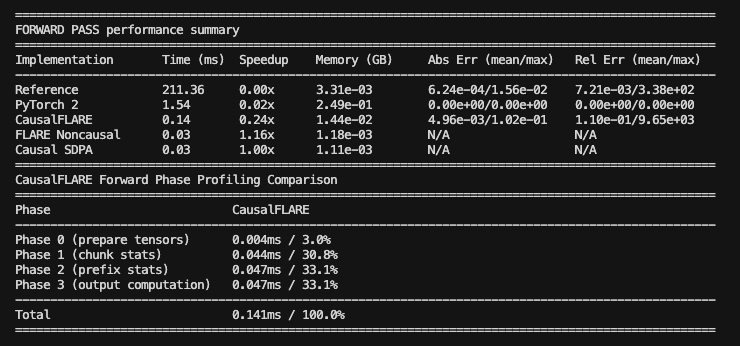
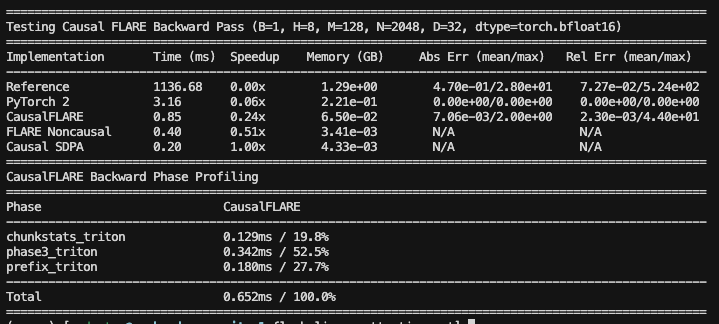
FLARE Decoder: BWD pass N=2048
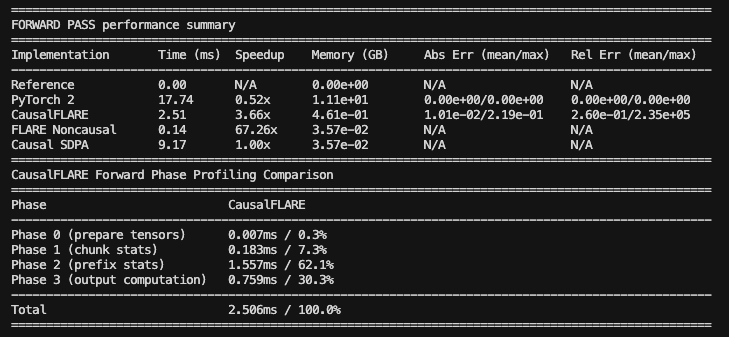
FLARE Decoder: FWD pass N=65k
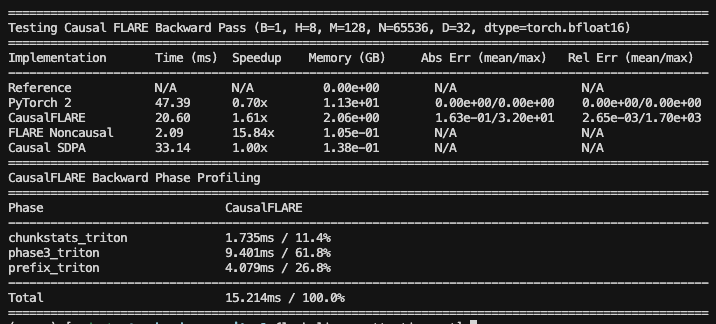
FLARE Decoder: BWD pass N=65k
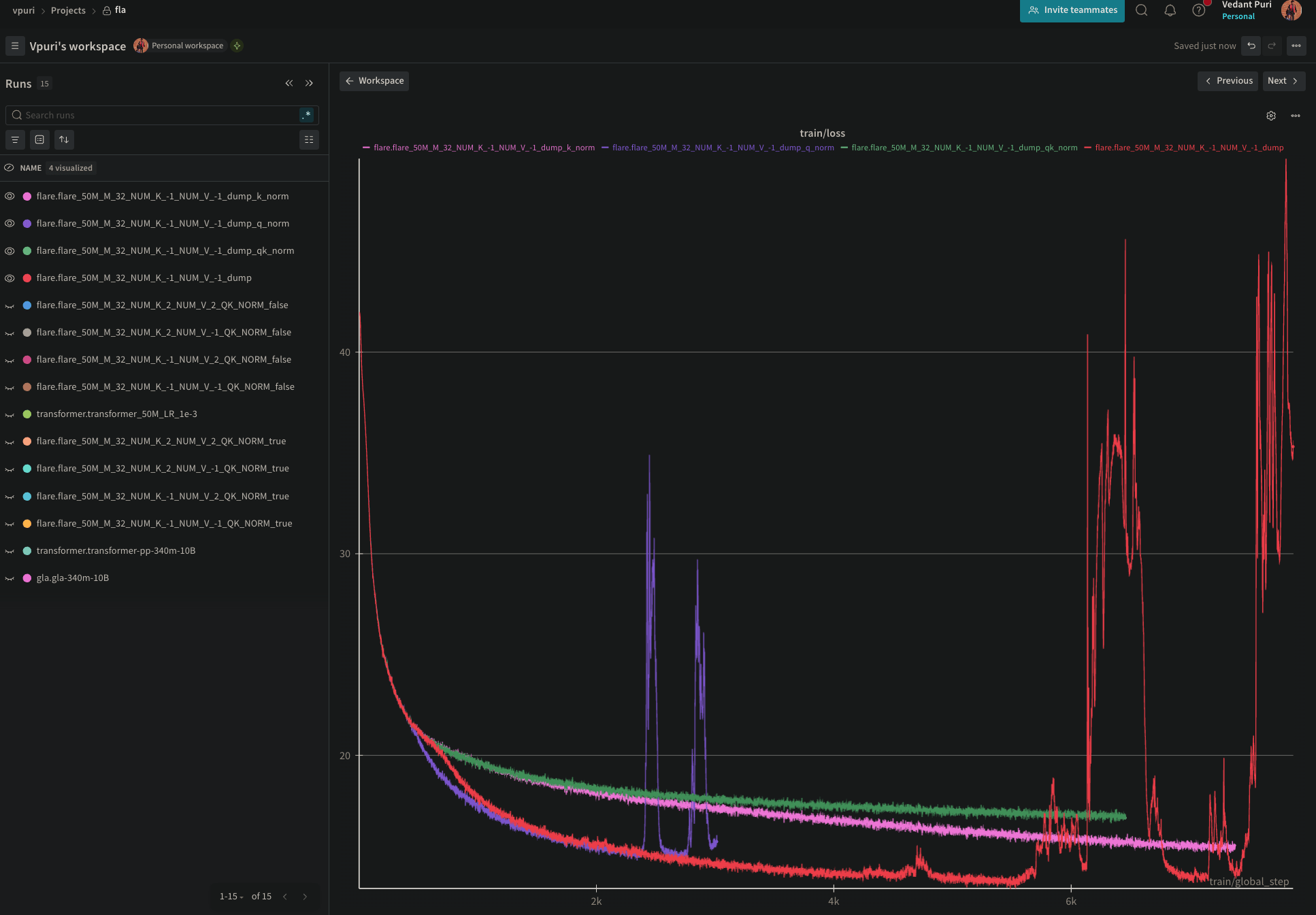
Debugging training instability
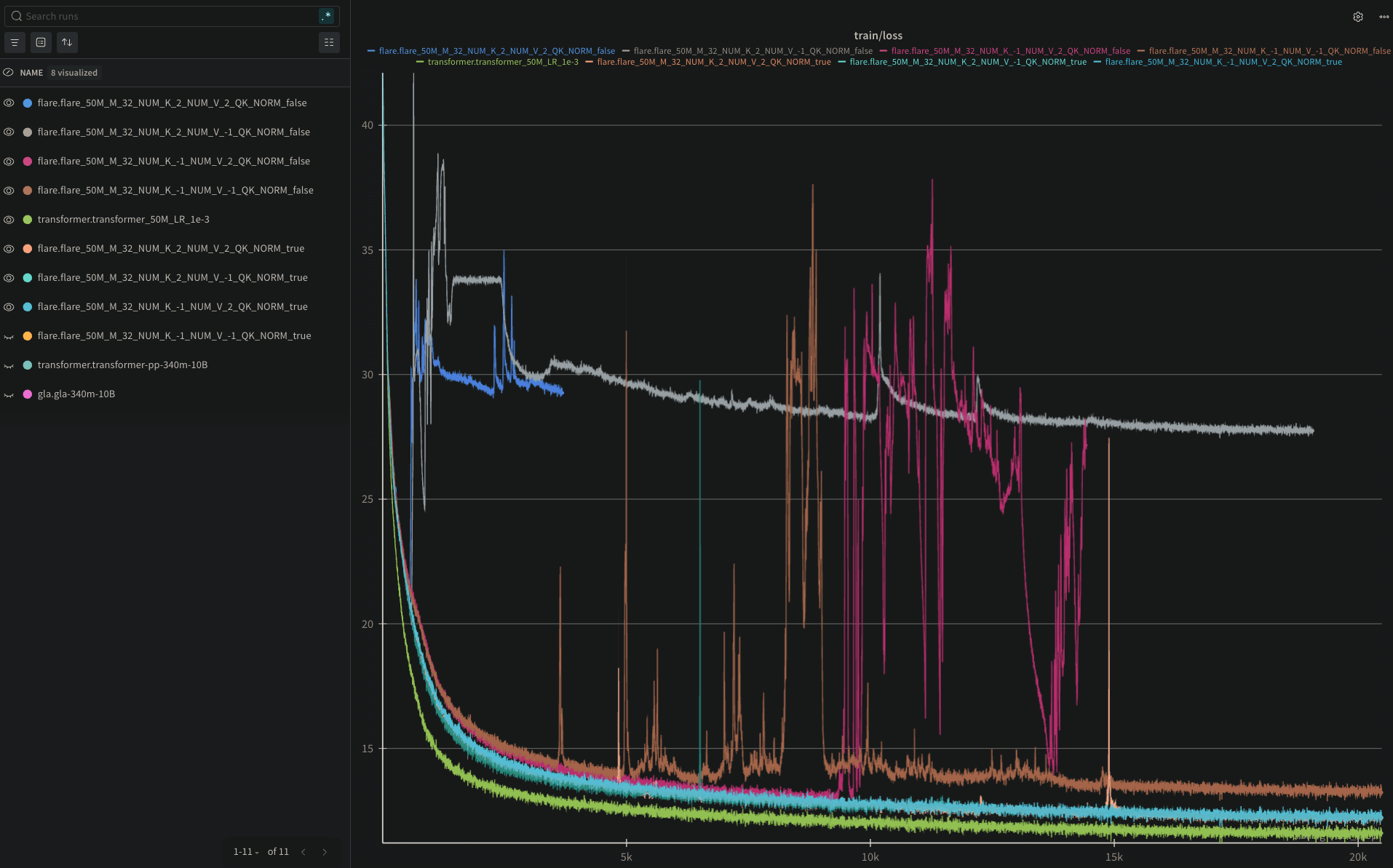
Instability removed with k-normalization, but are we losing performance?
FLARE causal update
Weekly meeting - 02/26/26
Progress
- Setting up experiments for aims 1, 2, 3
- Aim 1a: adaptive latent count -- test on image classification
- Aim 1b: cross-attention -- test on image/video diffusion
-
Aim 2: next token prediction -- test on language modeling
- Advantages: faster training, inference (esp. for long context). Drastically lower memory requirement for long context inference.
- Progress
- Submitted to ICML
- Vision transformer pipeline complete (took ~2 weeks)
- Aim 1: can test on Darcy, or image classification
- Aim 2: diffusion image generation pipeline complete. problems are too large. need greater allocation. working on it.
-
Aim 3: language model testing in progress.
- CUDA kernels for FWD pass, BWD pass done
- Testing small models (50M parameters)
- Noticing gradient instability
Manuscript summary
Memory-Efficient Causal Attention via Latent Routing (FLARE Decoder)
Target Conference: NeurIPS 2026 (May 15)
1. Contrib: Latent routing formulation of causal attention
- We introduce a new formulation of autoregressive attention as routing through a fixed-size latent space, providing a principled low-rank factorization that preserves global context while enabling prefix-sufficient state.
2. Contrib: Constant-memory autoregressive decoding algorithm
- We derive an exact decoding algorithm whose memory and compute per step are independent of sequence length while maintaining full-context modeling capability.
3. (TODO) Contrib: Linear-memory training via chunkwise recomputation algorithm
- We develop an efficient training algorithm that enables exact gradient computation with bounded memory footprint.
4. (TODO) Contrib: Optimized GPU kernels for scalable training and inference
- We provide high-performance kernels that make the proposed method practical at modern training scales.
5. (TODO) Contrib: Adaptive latent queries for content aware compression (new architecture improvement over FLARE)
- We propose dynamic latent query generation conditioned on the prefix, allowing adaptive routing and improving expressivity over static memory token approaches.
Language: Inference latency (prefill, decode) speedup (contrib 1,2)
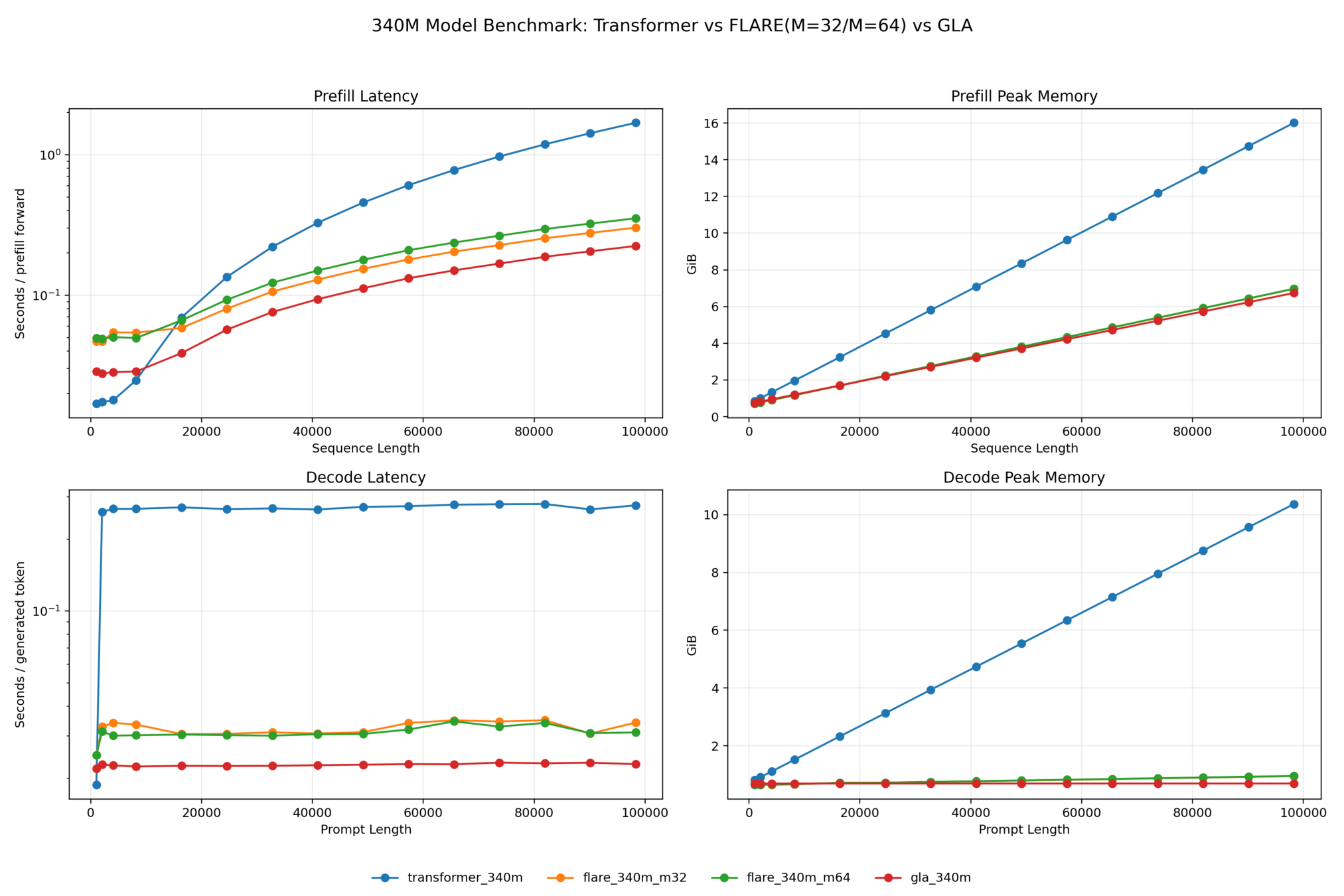
Language: Accuracy
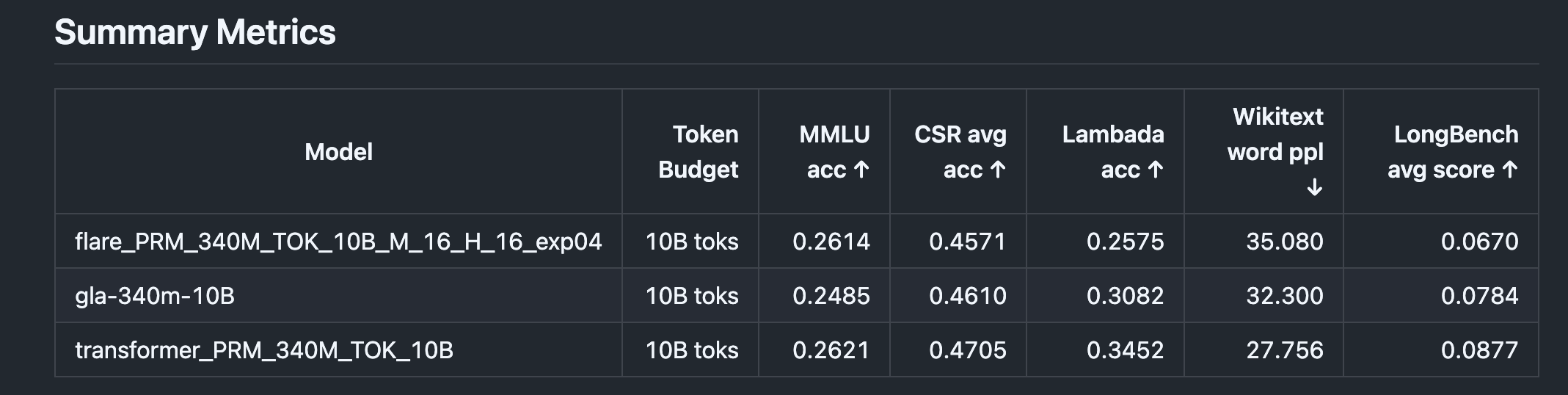

Language: challenge
- We are in the right ballpark to be competitive with other models.
- However, our accuracy is not high enough at the moment.
- Reasons
- We have only been testing with few latent tokens \(M\).
- This is because backward kernel is slow for large \(M\).
- Also, we have not been using any gating-like tricks to modulate update.
- Tasks
- Optimize kernel backward pass (see manuscript)
- Introduce gating-like tricks
- Try adaptive latents idea.
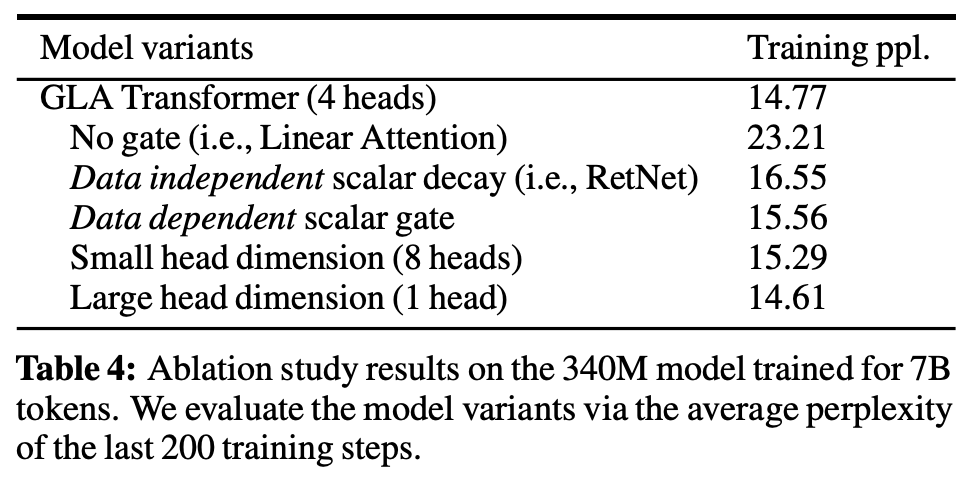
(from gated linear attn paper)
Weekly meeting - 03/05/26
Efficient Causal Attention via Latent Routing (FLARE Decoder)
- Latent routing formulation of causal attention
- Constant-memory autoregressive decoding algorithm
- Linear-memory training via chunkwise recomputation algorithm
- (TODO) Optimized GPU kernels for scalable training and inference
- (TODO) Adaptive latent queries (new architecture improvement over FLARE)
Progress
- Optimized backward pass for decoder model
- Testing ideas for: adaptive queries
- separate encoder/decoder weights
- gating
- Datta - image classification results
Loss curves
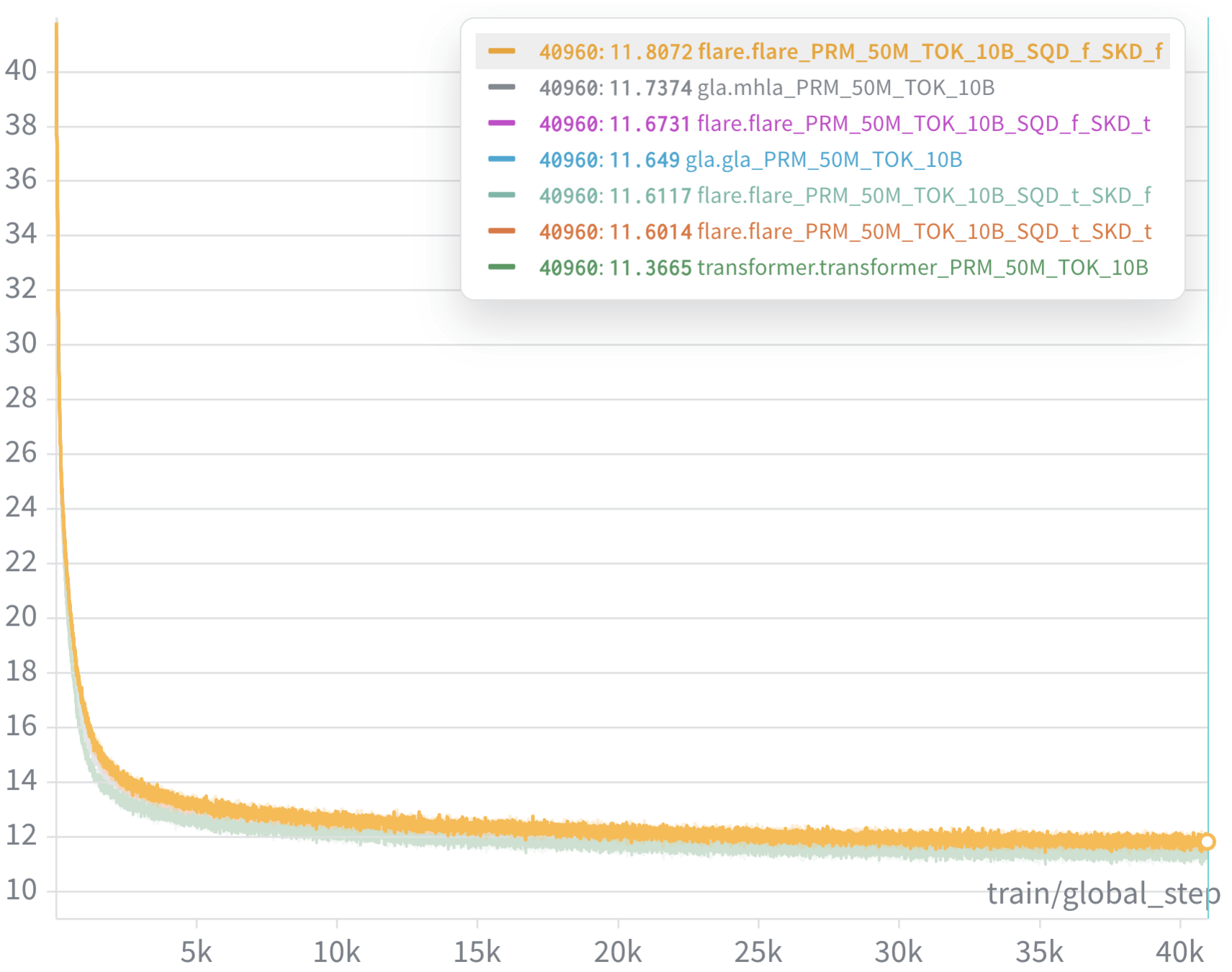
Weekly meeting - 03/12/26
Efficient Causal Attention via Latent Routing (FLARE Decoder)
- Latent routing formulation of causal attention
- Constant-memory autoregressive decoding algorithm
- Linear-memory training via chunkwise recomputation algorithm
- (TODO) Optimized GPU kernels for scalable training and inference
- (TODO) Adaptive latent queries (new architecture improvement over FLARE)
Progress
- Optimized backward pass for decoder model
- Recent modification (separate encoder/decoder weights) worked very well
- Datta - image classification results
Next steps
- Test more modifications (addition of causal convolutions, gating)
- Test block wise causal learning modeling
- with application to video diffusion, PDE timeseries
Training times for FLARE Decoder
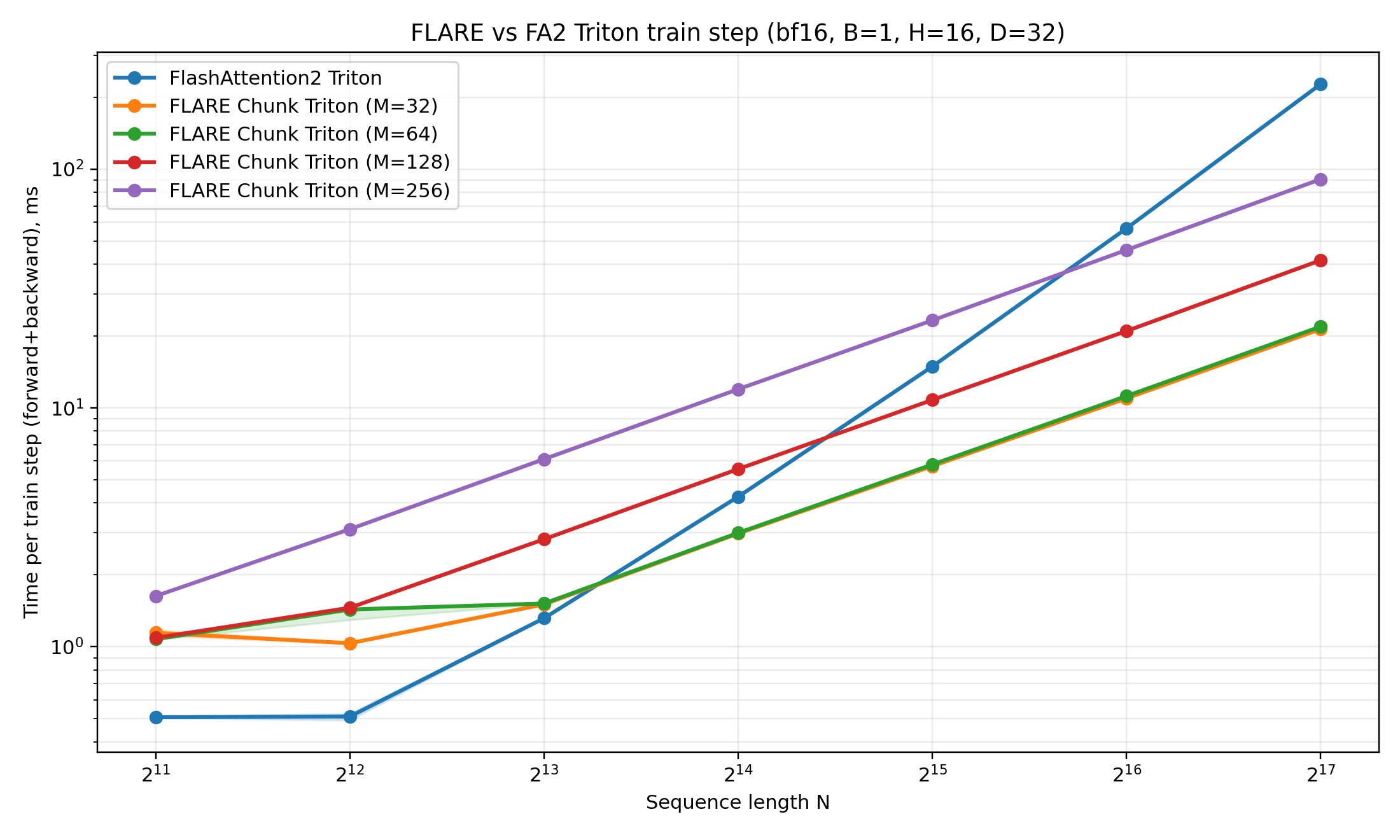
Weekly meeting - 03/19/26
Efficient Causal Attention via Latent Routing (FLARE Decoder)
- Latent routing formulation of causal attention
- Constant-memory autoregressive decoding algorithm
- Linear-memory training via chunkwise recomputation algorithm
Progress
- LANGUAGE MODELING - NIPS or ---
- Found a way to speed up the algorithm.Writing new kernels.
- Found an avenue to improve accuracy. Experiments in progress.
- PDE TIMESERIES - Eng. w. Computers
- Writing kernels for preliminary times series problems. can test on PDEBench data.
- Formulate plan with Noelia's student Wenzhuo (in progress)
- ICML SUBMISSION
- ICML review period: MAR 24 -- 30.
- Datta - image classification results
- If reject, consider TMLR
Weekly meeting - 04/08/26
Efficient Causal Attention via Latent Routing (FLARE Decoder)
- Latent routing formulation of causal attention
- Constant-memory autoregressive decoding algorithm
- Linear-memory training via chunkwise recomputation algorithm
Progress
- LANGUAGE MODELING - NIPS or ---
- Found a way to speed up the algorithm.Writing new kernels.
- Found an avenue to improve accuracy. Experiments in progress.
- PDE TIMESERIES - Eng. w. Computers
- Writing kernels for preliminary times series problems. can test on PDEBench data.
- Formulate plan with Noelia's student Wenzhuo (in progress)
- ICML SUBMISSION
- ICML review period: MAR 24 -- 30.
- Datta - image classification results
- If reject, consider TMLR
Weekly meeting - 03/19/26
Efficient Causal Attention via Latent Routing (FLARE Decoder)
- Latent routing formulation of causal attention
- Constant-memory autoregressive decoding algorithm
- Linear-memory training via chunkwise recomputation algorithm
Progress
- LANGUAGE MODELING - NIPS or ---
- Found a way to speed up the algorithm.Writing new kernels.
- Found an avenue to improve accuracy. Experiments in progress.
- PDE TIMESERIES - Eng. w. Computers
- Writing kernels for preliminary times series problems. can test on PDEBench data.
- Formulate plan with Noelia's student Wenzhuo (in progress)
- ICML SUBMISSION
- ICML review period: MAR 24 -- 30.
- Datta - image classification results
- If reject, consider TMLR
Weekly Meeting - 4/30/26
FLARE-Connect: Topologically consistent transformers for PDE surrogate modeling on arbitrary geometries
Target: Journal publication May/June 2026
Core Idea:
- Transformers and neural operators excel due to global visibility but fail on topologically complex domains.
- Goal: Inject mesh/topology awareness into FLARE without losing its global advantage.
Contributions:
- Identify a hidden failure mode in transformer-based neural operators: topologically rich geometries.
- Propose Connectivity-Grounded FLARE: Hybrid architecture combining
- global low-rank attention (FLARE)
- local topology-aware propagation (graph / mesh)
Method:
- Constrain attention to topologically connected/closeby regions
- Condition on boundary shape information
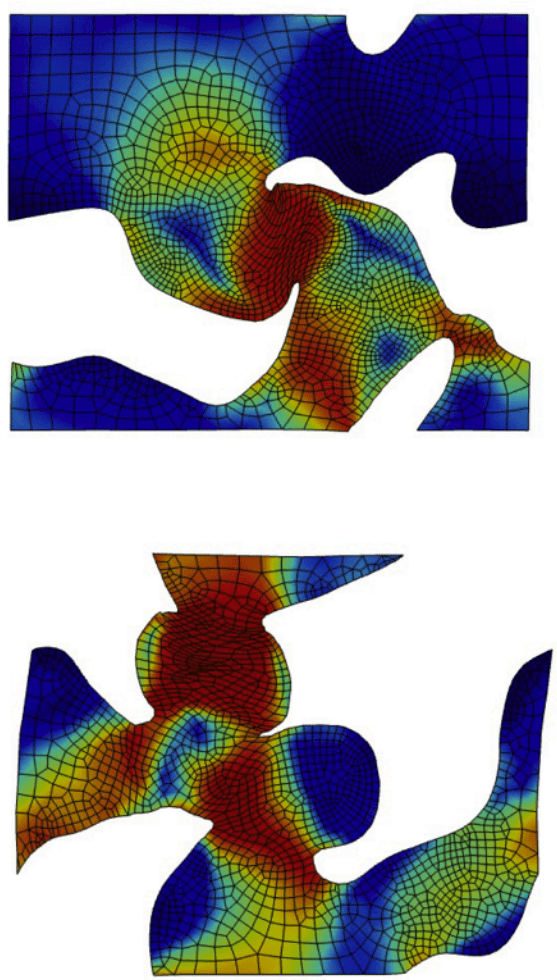
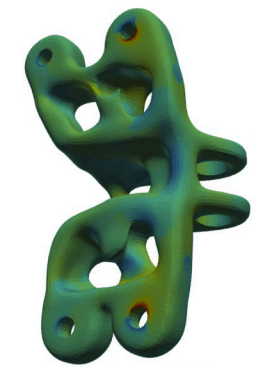
Jet Engine Bracket (50k points)
Periodic Unit Cell (10k points)
Method
Conditioning mechanism for incorporating boundary information
- Algorithm is prepared and ready for evaluation.
- No standardized benchmark suite. Evaluate in different modalities
- Diffusion: image, video generation
- Time-series PDE problems
Constrain attention to topologically connected/close-by clusters
Proposed idea
Transformer-based neural operators achieve strong performance by learning global geometry-to-field mappings, but they implicitly rely on Euclidean proximity and attention to infer physical interactions. This becomes problematic in highly nonconvex or topology-rich domains (e.g., microstructures with holes, thin ligaments, or closely spaced but disconnected regions), where spatial closeness does not imply physical connectivity. As a result, these models can introduce subtle but important errors, such as smoothing stress across voids or misrepresenting load paths, despite maintaining low global error metrics.
We propose a connectivity-grounded FLARE, which augments FLARE’s global low-rank attention with explicit mesh-topology information. Instead of replacing global attention, the model incorporates local graph-based structure (derived from mesh connectivity or geometric neighborhoods) to constrain or guide information flow. This hybrid design preserves FLARE’s scalability and global reasoning while enforcing physically meaningful locality where it matters. The key hypothesis is that explicit topology grounding improves robustness in nonconvex geometries and stress-concentration regions, leading to better generalization under topology shifts without sacrificing global accuracy.
Invariant position embeddings
- Adjacency matrix \(A \) \((N, N)\)
- Laplacian \(L = I - D^{-1/2} A D^{-1/2}\)
- Eigen decomposition \( L \approx V \Lambda V^T,\) with \(V\, (N, K)\)
- Naive position embedding: \(PE_k(i) = v_k(i)\)
- Problem: eigen set is non-unique
- If \(v\) is an eigenvector, \(\alpha v\) is also an eigenvector \( L(\alpha v) = \lambda(\alpha v)\)
- If eigenvalue is repeated, i.e., \( Lv_1 = \lambda v_1, \, Lv_2 = \lambda v_2\) then \((\alpha v_1 + \beta v_2)\) is also an eigenvalue: \( L (\alpha v_1 + \beta v_2) = \lambda (\alpha v_1 + \beta v_2)\)
Invariant position embeddings
- Given: \( L \approx V \Lambda V^T,\) with \(V\, (N, K)\)
- Task: Design \(PE = f(V, \Lambda)\) of size \((N, C)\).
- Naive: \(PE_k(i) = v_k(i)\)
- Problem: \(\alpha v\), \((\alpha v_1 + \beta v_2)\) are valid eigenvectors.
- Solution:
- Demand \(V\) is orthonormal (magnitude control)
- Consider \(v^2\) in place of of \(v\) (sign invariant)
- Consider \(PE_k(i) = v_{k_1}^2 + \cdots + v_{k_d}^2 \) for repeated eigenvalues (order invariant)
- Papers: \(PE_k(i) = v_{k_1}^2(i) + ...\)
Invariant position embeddings
- l1, l2, l3, l4, l5
- PE [N, 5]
- V [N, 5]
- PE = V
- l1=l2
- PE[:, 1] = v1^2 + v2^2
- PE[:, 2] = v1^2 + v2^2
Invariant position embeddings
- \(PE_k(i) = v_{k_1}^2 + \cdots + v_{k_d}^2 \) for repeated eigenvalues (order, sign, magnitude invariant)
- In finite precision math, repeated eigenvalues are hard to capture.
- Solution:
- \(PE_\ell(i) = \sum_{k=1}^K h_\ell(\lambda_k) v_k(i)v_k(i)\)
- Here, \(h_j\) is a sharp gaussian filter around \(\lambda_j\).
- Matrix \(B_j = V \cdot \text{diag}(h_j(\lambda)) \cdot V^T\) \((N, N)\)
- is the true invariant object per eigenvalue
- Our solution:
- \(PE_j = (B_j \odot M) \cdot q\) of size \((N, C)\)