Tools for
Human-Centric Machine Learning
@

Ville Tuulos
North Star AI, March 2019
a business
problem
predict
churn
a model
to predict
churn
data
a model
to predict
churn
data
model
data
transforms
data
model
data
transforms
results
data
model
data
transforms
results
compute
data
model
data
transforms
results
compute
schedule
action
data
data
transforms
results
compute
schedule
action
data
audits
model
model
audits
data
data
transforms
results
compute
schedule
action
data
audits
model
model
audits
data
transforms
data
audits
model
model
audits
versioning
Screenplay Analysis Using NLP

Fraud Detection
Title Portfolio Optimization
Estimate Word-of-Mouth Effects
Incremental Impact of Marketing
Classify Support Tickets
Predict Quality of Network
Content Valuation
Cluster Tweets
Intelligent Infrastructure
Machine Translation
Optimal CDN Caching

Predict Churn
Content Tagging
Optimize Production Schedules
Human-Centric?
data
model
data
transforms
results
compute
schedule
action
business
owner
data
scientist

product
engineer
data
engineer
ML
engineer
data
model
data
transforms
results
compute
schedule
action
business
owner
data
scientist
product
engineer
data
data
transforms
results
compute
schedule
action
data
audits
model
model
audits
data
transforms
data
audits
model
model
audits
versioning
data
scientist
data
data
transforms
results
compute
schedule
action
data
audits
model
model
audits
data
transforms
data
audits
model
model
audits
versioning

machine
learning
infrastructure
data
scientist

Metaflow




Notebooks: Nteract
Job Scheduler: Meson
Compute Resources: Titus
Query Engine: Spark
Data Lake: S3



{
data
compute
prototyping
ML Libraries: R, XGBoost, TF etc.
models
ML Wrapping: Metaflow
from metaflow import FlowSpec, step
class MyFlow(FlowSpec):
@step
def start(self):
self.next(self.a, self.b)
@step
def a(self):
self.next(self.join)
@step
def b(self):
self.next(self.join)
@step
def join(self, inputs):
self.next(self.end)
MyFlow()start
How to structure my code?
B
A
join
end
start
How to prototype and test
my code locally?
B
A
join
end
x=0
x+=2
x+=3
max(A.x, B.x)
@step
def start(self):
self.x = 0
self.next(self.a, self.b)
@step
def a(self):
self.x += 2
self.next(self.join)
@step
def b(self):
self.x += 3
self.next(self.join)
@step
def join(self, inputs):
self.out = max(i.x for i in inputs)
self.next(self.end)start
How to distribute work over
many parallel jobs?
A
join
end
@step
def start(self):
self.grid = [’x’,’y’,’z’]
self.next(self.a, foreach=’grid’)
@titus(memory=10000)
@step
def a(self):
self.x = ord(self.input)
self.next(self.join)
@step
def join(self, inputs):
self.out = max(i.x for i in inputs)
self.next(self.end)start
How to get access to more CPUs,
GPUs, or memory?
B
A
join
end
@titus(cpu=16, gpu=1)
@step
def a(self):
tensorflow.train()
self.next(self.join)
@titus(memory=200000)
@step
def b(self):
massive_dataframe_operation()
self.next(self.join)16 cores, 1GPU
200GB RAM
# Access Savin's runs
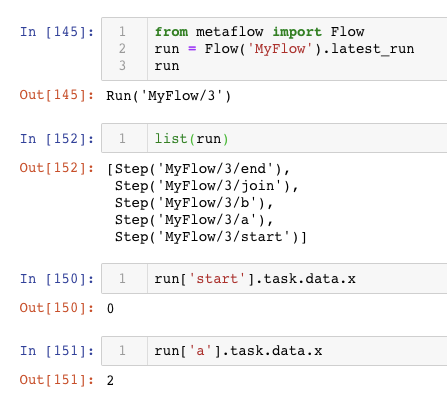
namespace('user:savin')
run = Flow('MyFlow').latest_run
print(run.id) # = 234
print(run.tags) # = ['unsampled_model']
# Access David's runs
namespace('user:david')
run = Flow('MyFlow').latest_run
print(run.id) # = 184
print(run.tags) # = ['sampled_model']
# Access everyone's runs
namespace(None)
run = Flow('MyFlow').latest_run
print(run.id) # = 184 start
How to version my results and
access results by others?
B
A
join
end
david: sampled_model
savin: unsampled_model
start
How to deploy my workflow to production?
B
A
join
end

start
How to monitor models and
examine results?
B
A
join
end
x=0
x+=2
x+=3
max(A.x, B.x)

...and much more to improve productivity of data scientists
- Deploy models as microservices
- Support for R
- High-throughput data access
- Flexible parametrization of workflows
- Isolated environments for 3rd party dependencies
- Slack bot!
1. Models are a tiny part of an end-to-end ML system.
2. With proper tooling, data scientists can own the system, end-to-end.
3. Design the tooling with a human-centric mindset.
Summary
To improve results of an ML system,
improve the productivity of humans who operate it.
