Web scraping
Vitor Mattos
automatize coleta de dados da web
Fotografem, comentem, twittem!
@VitorMattosRJ







Quem sou eu?
Realizador de sonhos desde 2003
Amante de opensource
Palestrante
PHP Zend Certified Engineer ( ZEND024235 )
PHPRio ( https://telegram.me/phprio )
CTO Lyseon Tech
Redes sociais: ( VitorMattos ou VitorMattosRJ )







A Lyseon Tech é uma cooperativa de trabalho com modelo de gestão democrática, segura e eficiente composta por profissionais de T.I. altamente qualificados e experientes no mercado. Prezamos por apresentar vantagens, tanto para o cooperado como para as empresas parceiras.

O que é?
Web scraping (web harvesting or web data extraction) is a computer software technique of extracting information from websites. Usually, such software programs simulate human exploration of the World Wide Web by either implementing low-level Hypertext Transfer Protocol (HTTP), or embedding a fully-fledged web browser, such as Internet Explorer or Mozilla Firefox. - Wikipedia
Simplificando
Extrair dados de sites que não possuem API.

API
Simplificando
Extrair dados de sites que possuem API com rate-limit.

Simplificando
Coletar dados que podemos ver na internet.

O que preciso saber?
Noções básicas de HTML

O que preciso saber?
Noções básicas de HTTP

O que preciso saber?
Conhecer bem como é o fluxo para coletar os dados da fonte desejada

O site tem API, faz sentido fazer scraping?
Web Scraping não possui rate limited
O site tem API, faz sentido fazer scraping?
Podemos fazer acesso anônimo para coleta de dados
O site tem API, faz sentido fazer scraping?
Alguns dados não estão acessíveis via API
API
Porque em PHP?
Alta performance

Porque em PHP?
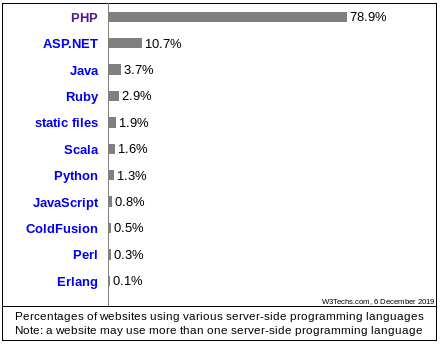
2019-12-06
Porque em PHP?
Fazer scraping utilizando uma linguagem gostosa de se programar.

Questões éticas
Se tiver API, use API

API
Questões éticas
Nunca faça um DoS
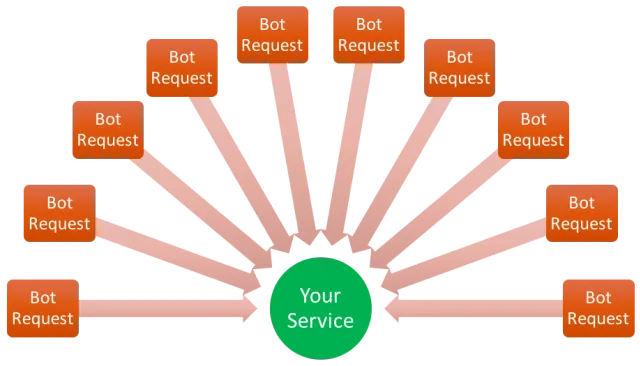
Questões éticas
Se houver, leia o ToS do site

Questões éticas
Nunca distribua dados não autorizados

Etapas do webscraping
Web Scraping segue este fluxo:
- Pegar os dados do site alvo
- Realizar o parse da informação coletada
- Tratar dados
- Armazernar informações - db, csv, text file, etc
Scraping assíncrono



Anatomia de um site
O que o computador vê?

Anatomia de um site
O que eu vejo?

Anatomia de um site
Developer tools
F12
Anatomia de um site
Developer tools
F12
Coleta de dados
Manualmente usando fopen, file_get_contents e outros
Utilizando cURL
Utilizando Guzzle
Utilizando pacotes especialistas em coleta de dados
Coleta de dados
Sites estáticos e sem JS
composer require symfony/browser-kitColeta de dados
Sites estáticos e sem JS
$client = new Client();
$crawler = $client->request('GET', '/');Fazendo uma requisição
Coleta de dados
Sites estáticos e sem JS
$crawler = $client->request('GET', '/product/123');
$link = $crawler->selectLink('Go elsewhere...')->link();
$client->click($link);Clicando em um link
Coleta de dados
Sites estáticos e sem JS
$client = new Client();
$client->request('GET', '/');
// select and click on a link
$link = $crawler->selectLink('Documentation')->link();
$client->click($link);
// go back to home page
$crawler = $client->back();
// go forward to documentation page
$crawler = $client->forward();Navegando no histórico
Coleta de dados
Sites dinâmicos com JS
composer require behat/mink-selenium2-driverColeta de dados
Sites dinâmicos com JS
$browser = 'firefox';
$url = 'http://example.com';
$mink = new Mink(array(
'selenium2' => new Session(
new Selenium2Driver($browser, null, $url)
),
));
$mink->getSession('selenium2')
->getPage()
->findLink('Chat')
->click();Manipulando dados
Funções de maipulação de string no PHP
Expressões regulares
Classes de DOM do PHP
Pacotes Composer para implementar seletores CSS e xpath
Pacotes que implementam uso de linguagem ubíqua
Manipulando dados
Seletores CSS e xpath
composer require symfony/css-selector
composer require symfony/dom-crawlerManipulando dados
Seletores CSS e xpath
$converter = new CssSelectorConverter();
var_dump($converter->toXPath('div.item > h4 > a'));Manipulando dados
Seletores CSS e xpath
$message = $crawler->filterXPath('//body/p')->text();
$crawler = $crawler
->filter('body > p')
->reduce(function (Crawler $node, $i) {
// filters every other node
return ($i % 2) == 0;
});Consumindo API
composer require symfony/http-clientConsumindo API
$client = HttpClient::create();
$response = $client->request(
'GET',
'https://api.github.com/repos/symfony/symfony-docs'
);
$statusCode = $response->getStatusCode();
// $statusCode = 200
$contentType = $response->getHeaders()['content-type'][0];
// $contentType = 'application/json'
$content = $response->getContent();
// $content = '{"id":521583, "name":"symfony-docs", ...}'
$content = $response->toArray();Salvando dados coletados
Texto
file_put_contents('dados.txt', $dados);Salvando dados coletados
Banco
Vitor Mattos
vitor@LT.coop.br
t.me/VitorMattos